Тестирование стабильности: что это, зачем и как проводить
В мире современных технологий, где приложения и сервисы работают круглосуточно, обслуживая миллионы пользователей, вопрос стабильности системы становится критически важным. Представьте ситуацию: ваш сервис успешно справляется с обычной нагрузкой, но через несколько недель непрерывной работы начинает «тормозить» или вовсе выходить из строя.

Именно для предотвращения подобных сценариев мы проводим тестирование стабильности — комплексную проверку способности системы работать надежно в течение длительного времени при различных условиях нагрузки.
- Что такое тестирование стабильности
- Зачем проводить
- Виды
- Проблемы, выявляемые при нестабильной работе
- Метрики и показатели стабильности
- Этапы проведения тестирования стабильности
- Инструменты для тестирования стабильности
- Практические рекомендации и советы
- Заключение
- Рекомендуем посмотреть курсы по QA-тестированию
Что такое тестирование стабильности
Это специализированный вид тестирования, направленный на проверку способности системы поддерживать стабильную работу в течение продолжительного времени при различных условиях эксплуатации. В отличие от функциональных тестов, которые проверяют корректность работы отдельных компонентов, стабильностное тестирование фокусируется на поведении системы как единого целого в долгосрочной перспективе.
Ключевые характеристики стабильной системы включают способность поддерживать постоянную производительность, отсутствие деградации функций со временем и устойчивость к накоплению ошибок. Мы говорим о системе как о стабильной, когда она демонстрирует предсказуемое поведение независимо от продолжительности работы — будь то час, день или месяц непрерывного функционирования.
Важно понимать, что ТС не заменяет другие виды тестирования, а дополняет их. Если нагрузочное показывает, как система ведет себя при пиковых нагрузках в короткий период, то стабильностное раскрывает картину долгосрочного поведения при постоянной или периодически изменяющейся нагрузке.
Практика показывает, что многие проблемы проявляются только после длительного периода работы — например, постепенное заполнение памяти неиспользуемыми объектами или накопление временных файлов, которые в итоге могут привести к критическим сбоям системы.
Отличие от нагрузочного
Часто тестирование стабильности путают с нагрузочным, однако между ними существуют принципиальные различия:
| Критерий | Нагрузочное | Тестирование стабильности |
|---|---|---|
| Цель | Проверка поведения при пиковых нагрузках | Проверка долгосрочной надежности |
| Продолжительность | Краткосрочное (часы) | Долгосрочное (дни/недели) |
| Тип нагрузки | Переменная, часто максимальная | Постоянная, близкая к рабочей |
| Фокус анализа | Пропускная способность, время отклика | Утечки памяти, деградация производительности |
Нагрузочное отвечает на вопрос «сколько выдержит?», а тестирование стабильности — «как долго продержится?».
Зачем проводить
В эпоху цифровой экономики стабильность IT-систем напрямую влияет на бизнес-показатели компании. Согласно нашим наблюдениям, даже кратковременные сбои могут привести к значительным финансовым потерям и репутационным рискам. Представьте ситуацию: система интернет-банкинга «падает» в пиковые часы или платформа электронной коммерции становится недоступной в период распродаж.
ТС позволяет нам предотвратить подобные сценарии, выявляя потенциальные проблемы до их проявления в продуктивной среде. Это особенно критично для систем, которые должны работать в режиме 24/7 — серверов баз данных, веб-приложений, микросервисной архитектуры.
Ключевые причины проведения:
- Обеспечение непрерывности бизнес-процессов и предотвращение простоев.
- Оптимизация использования ресурсов и планирование масштабирования.
- Поддержание репутации компании и доверия пользователей.
- Снижение затрат на экстренное устранение неполадок.
- Соответствие требованиям SLA и регулятивным стандартам.
Инвестиции в ТС окупаются многократно через предотвращение критических сбоев и обеспечение предсказуемой производительности системы.
Виды
Тестирование стабильности включает несколько специализированных подходов, каждый из которых фокусируется на определенных аспектах поведения системы.
Классификация видов основывается на характере нагрузки, продолжительности тестирования и целях исследования. Каждый вид выявляет специфические проблемы, которые могут оставаться незамеченными при других подходах.
Нагрузочное
Этот вид проверяет поведение системы при постепенном увеличении нагрузки до ожидаемых пиковых значений. Мы моделируем реальные сценарии использования, постепенно наращивая количество одновременных пользователей или транзакций.
Основные сценарии:
- Имитация роста числа активных пользователей в течение рабочего дня.
- Проверка обработки пиковых нагрузок в период акций или распродаж.
- Тестирование масштабируемости при расширении пользовательской базы.
Нагрузочное помогает выявить узкие места в архитектуре, определить пределы производительности и спланировать необходимые ресурсы для обеспечения стабильной работы.
Стресс-тестирование
Оно направлено на проверку поведения системы в экстремальных условиях, когда нагрузка превышает расчетные параметры. Мы намеренно создаем критические ситуации, чтобы понять границы отказоустойчивости и механизмы восстановления системы.
Типичные сценарии стресс-тестирования:
- Превышение максимального количества одновременных подключений.
- Ограничение доступных ресурсов (память, процессорное время, дисковое пространство).
- Имитация отказов компонентов инфраструктуры.
Результаты стресс-тестирования показывают, насколько graceful будет деградация системы при критических нагрузках и как быстро она сможет восстановиться после устранения проблем.
Тестирование долговременной стабильности
Этот вид тестирования фокусируется на выявлении проблем, которые проявляются только после продолжительной работы системы. Мы запускаем систему под постоянной нагрузкой на протяжении дней или недель, отслеживая ключевые метрики производительности.
Долговременное тестирование особенно эффективно для обнаружения утечек памяти, постепенной деградации производительности и накопления системных ошибок. Представьте график, где по оси X отложено время работы системы, а по оси Y — использование памяти: при наличии утечек мы увидим постоянный рост потребления ресурсов, который в итоге приведет к критическому состоянию.
Ключевые проблемы, выявляемые долговременным тестированием:
- Утечки памяти в коде приложения или используемых библиотеках.
- Накопление временных файлов и неочищенных кэшей.
- Деградация производительности базы данных из-за фрагментации.
- Проблемы со сборкой мусора в языках с автоматическим управлением памятью.
Проблемы, выявляемые при нестабильной работе
Нестабильная работа системы проявляется через характерные симптомы, которые часто развиваются постепенно и могут оставаться незамеченными до критического момента. Понимание этих проблем помогает нам не только их предотвратить, но и быстрее диагностировать при возникновении.
Основные типы проблем и их последствия:
| Тип проблемы | Проявление | Последствия для бизнеса |
|---|---|---|
| Утечки памяти | Постоянный рост потребления RAM | Замедление работы, eventual crash |
| Деградация производительности | Увеличение времени отклика | Снижение пользовательского опыта |
| Потеря функциональности | Отказ отдельных компонентов | Ограничение возможностей системы |
| Накопление ошибок | Рост количества исключений в логах | Нестабильное поведение системы |
| Блокировки ресурсов | Deadlock‘и и long-running транзакции | Зависание операций |
Особенно коварны проблемы, которые проявляются не сразу — система может месяцами работать стабильно, а затем внезапно выйти из строя из-за накопившихся проблем. Именно поэтому регулярное тестирование стабильности становится критически важным элементом жизненного цикла разработки.
Метрики и показатели стабильности
Эффективное тестирование стабильности невозможно без четкого понимания того, какие метрики следует отслеживать и как интерпретировать их изменения. Правильно выбранные показатели служат своеобразными «индикаторами здоровья» системы, позволяя нам заблаговременно выявлять потенциальные проблемы.
Ключевые метрики можно разделить на несколько категорий в зависимости от аспектов системы, которые они характеризуют. Важно понимать, что изолированный анализ отдельных показателей может ввести в заблуждение — истинная картина стабильности раскрывается через комплексный мониторинг взаимосвязанных метрик.
| Категория метрик | Показатель | Описание | Критические значения |
|---|---|---|---|
| Производительность | Время отклика (Response Time) | Среднее время обработки запроса | Рост более 50% от базового |
| Пропускная способность (Throughput) | Количество обработанных запросов/сек | Снижение более 20% | |
| Ресурсы системы | Использование CPU | Процент загрузки процессора | Постоянно выше 80% |
| Потребление памяти | Объем используемой RAM | Постоянный рост без освобождения | |
| Дисковые операции | I/O операций в секунду | Превышение лимитов диска | |
| Приложение | Количество активных соединений | Число одновременных подключений | Приближение к лимиту пула |
| Количество ошибок | Частота исключений и сбоев | Рост более чем в 2 раза |
Анализ трендов этих метрик во времени часто оказывается более информативным, чем абсолютные значения — постепенное ухудшение показателей может сигнализировать о назревающих проблемах задолго до критической ситуации.
Этапы проведения тестирования стабильности
Эффективное тестирование стабильности требует системного подхода и четкого планирования. Каждый этап процесса имеет свои специфические задачи и критерии успешности, а пропуск любого из них может существенно снизить качество результатов.
Практика показывает, что наиболее успешными оказываются проекты, где тестирование стабильности интегрировано в общий процесс разработки с самого начала, а не рассматривается как отдельная активность перед релизом.
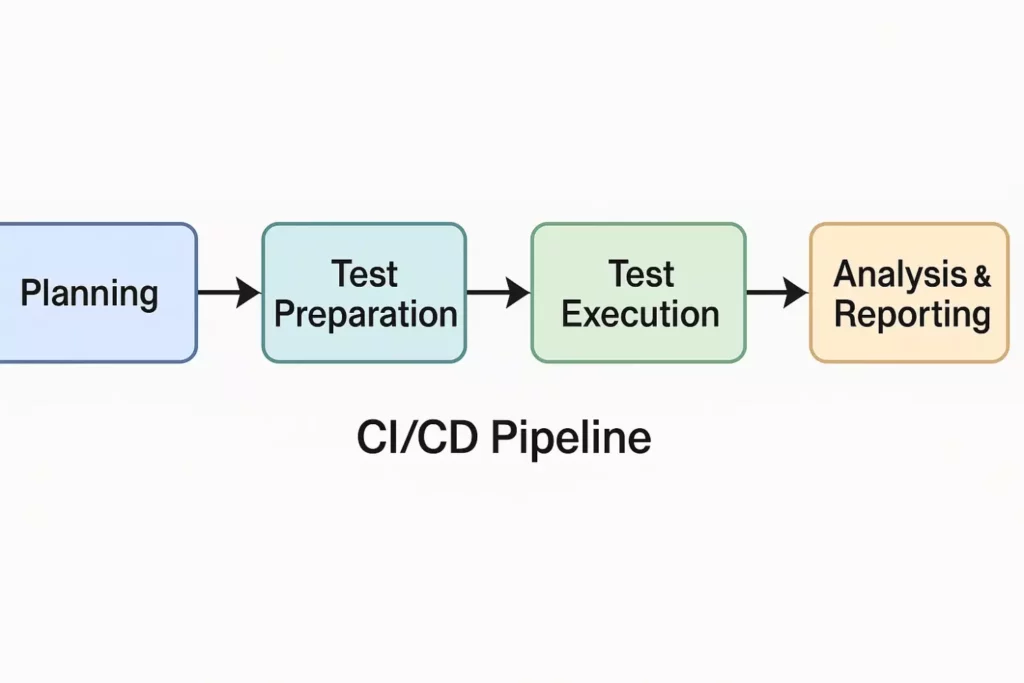
Схема отображает ключевые этапы процесса: Планирование → Подготовка → Выполнение → Анализ и отчётность. Она помогает быстро увидеть логику последовательности шагов, которые вы детально описываете в тексте.
Планирование теста
Этап планирования закладывает фундамент для всего процесса тестирования. Мы определяем конкретные цели (например, проверка работы системы в течение 72 часов при 80% от максимальной нагрузки), разрабатываем сценарии использования и устанавливаем критерии успешности.
Ключевые вопросы планирования:
- Какие компоненты системы критически важны для тестирования?
- Какая продолжительность тестирования необходима для выявления проблем?
- Какие метрики будут индикаторами успешности или неудачи теста?
Подготовка команды и ресурсов
Успешное тестирование стабильности требует не только технических ресурсов, но и правильно подготовленной команды. Мы распределяем роли между участниками (инженеры по тестированию производительности, системные администраторы, разработчики), настраиваем инструменты мониторинга и подготавливаем тестовую среду, максимально приближенную к продуктивной.
Критически важно обеспечить изоляцию тестовой среды и стабильность инфраструктуры — внешние факторы не должны влиять на результаты тестирования.
Проведение теста
На этапе выполнения мы запускаем подготовленные сценарии и осуществляем непрерывный мониторинг системы. Особое внимание уделяется автоматизации сбора метрик и настройке алертов для критических ситуаций.
Важно поддерживать постоянную готовность к вмешательству — если система приближается к критическому состоянию, тест может потребовать досрочной остановки для предотвращения серьезных последствий.
Анализ результатов и отчётность
Заключительный этап включает глубокий анализ собранных данных, выявление закономерностей и формулирование конкретных рекомендаций. Мы интерпретируем тренды метрик, определяем root cause обнаруженных проблем и разрабатываем план исправления.
Качественный отчет должен содержать не только технические детали, но и оценку влияния выявленных проблем на бизнес-процессы, а также приоритизированный список рекомендаций по улучшению стабильности системы.
Инструменты для тестирования стабильности
Выбор подходящих инструментов может существенно повлиять на эффективность тестирования стабильности. Современный рынок предлагает широкий спектр решений — от open-source продуктов до корпоративных платформ с расширенными возможностями аналитики.
При выборе инструмента мы руководствуемся несколькими ключевыми критериями: поддержка протоколов и технологий вашей системы, масштабируемость для генерации необходимой нагрузки, качество отчетности и интеграция с существующей инфраструктурой мониторинга.
Популярные инструменты и их характеристики:
| Инструмент | Тип | Основные преимущества | Подходит для |
|---|---|---|---|
| Apache JMeter | Open-source | Простота использования, GUI, широкая поддержка протоколов | Веб-приложения, API, базы данных |
| Gatling | Open-source/Commercial | Высокая производительность, Scala DSL, детальные отчеты | Высоконагруженные HTTP-сервисы |
| LoadRunner | Commercial | Корпоративные возможности, поддержка legacy-систем | Крупные enterprise-проекты |
| K6 | Open-source | JavaScript API, cloud-ready, DevOps integration | Современные микросервисные архитектуры |
Для мониторинга системных ресурсов рекомендуем дополнять инструменты нагрузочного тестирования специализированными решениями: Prometheus + Grafana для метрик, ELK Stack для логов, APM-решения вроде New Relic или AppDynamics для глубокого анализа производительности приложений.
Главная страница JMeter. Интерфейс с Test Plan и Thread Group.
Важно помнить: инструмент — это только средство достижения цели. Ключевую роль играет правильная методология и понимание специфики тестируемой системы.
Практические рекомендации и советы
Успешное внедрение тестирования стабильности в процессы разработки требует не только технических знаний, но и понимания организационных аспектов. Наш опыт показывает, что наиболее эффективными оказываются подходы, которые интегрируют тестирование стабильности в общую культуру качества компании.
Частота проведения тестирования должна соответствовать интенсивности изменений в системе. Для активно развивающихся проектов рекомендуем еженедельные краткосрочные тесты стабильности и ежемесячные расширенные проверки. Критически важные системы требуют непрерывного мониторинга стабильности в продуктивной среде.
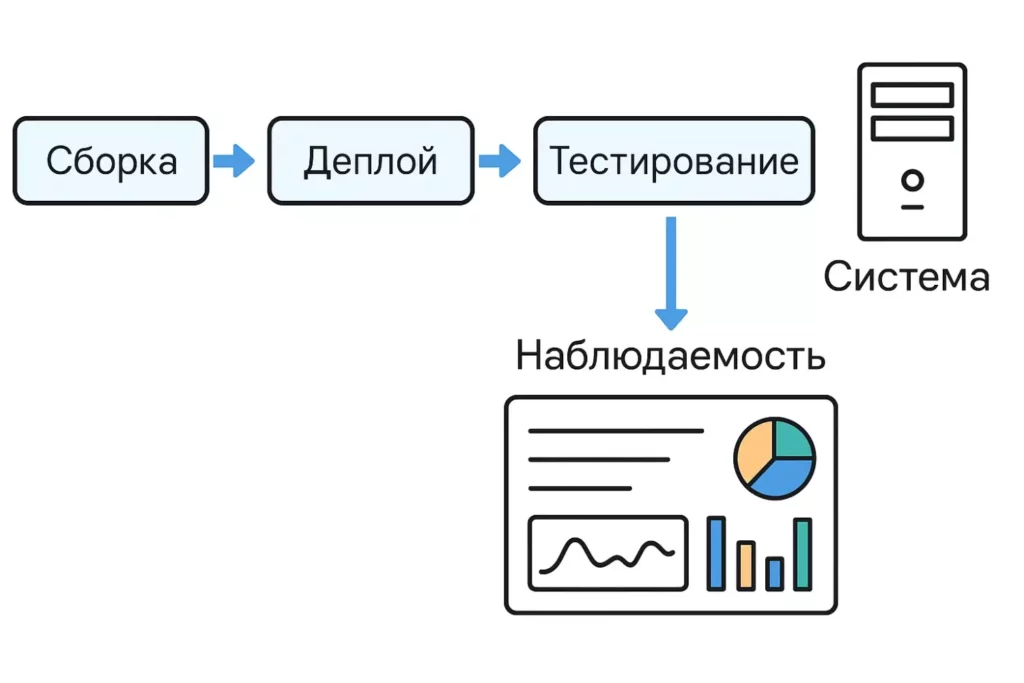
Схема показывает, как тестирование стабильности встраивается в CI/CD-процесс (Сборка → Деплой → Тестирование) и связывается с системами наблюдаемости. Дашборды помогают отслеживать ключевые метрики в реальном времени и быстро выявлять отклонения.
Ключевые рекомендации для эффективного тестирования:
- Автоматизация и CI/CD интеграция: включайте базовые проверки стабильности в pipeline развертывания.
- Мониторинг трендов: ведите историческую базу метрик для выявления долгосрочных тенденций.
- Проактивный подход: не ждите проблем в продакшене — регулярно тестируйте стабильность на dev/staging средах.
- Документирование: фиксируйте обнаруженные проблемы и способы их решения для формирования knowledge base.
- Обучение команды: инвестируйте в развитие экспертизы команды в области performance engineering.
Визуализация результатов играет критическую роль в принятии решений. Создавайте дашборды, которые отображают ключевые метрики в режиме реального времени и позволяют быстро идентифицировать аномалии. Помните: данные без интерпретации не имеют ценности для бизнеса.
Заключение
Тестирование стабильности перестало быть опциональной активностью — в современном мире цифровых сервисов оно становится неотъемлемой частью процесса обеспечения качества. Компании, которые пренебрегают этим аспектом, рискуют столкнуться с критическими сбоями в самые неподходящие моменты.
- Тестирование стабильности выявляет долгосрочные проблемы. Это позволяет предотвратить сбои, которые возникают не сразу, а через часы или дни работы.
- Оно отличается от нагрузочного теста. Главный фокус — не максимальная нагрузка, а длительное стабильное поведение системы.
- Стабильность измеряется набором метрик. Ключевые показатели — время отклика, использование CPU и памяти, количество ошибок.
- Процесс тестирования включает 4 этапа. Сюда входят планирование, подготовка, выполнение и анализ результатов.
- В работе используются специализированные инструменты. Среди них — JMeter, Gatling, K6, Prometheus и другие.
- Внедрение тестирования в CI/CD повышает надежность системы. Это снижает риски простоев, нарушения SLA и репутационных потерь.
Если вы только начинаете осваивать профессию тестировщика, рекомендуем обратить внимание на подборку курсов по QA-тестированию. В них вы найдёте как теоретические основы, так и практические задания для реальных проектов.
Рекомендуем посмотреть курсы по QA-тестированию
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Автоматизированное тестирование на Python
|
Eduson Academy
114 отзывов
|
Цена
88 800 ₽
|
От
7 400 ₽/мес
0% на 24 месяца
|
Длительность
6 месяцев
|
Старт
в любое время
|
Подробнее |
|
Тестировщик ПО
|
Нетология
46 отзывов
|
Цена
105 000 ₽
184 200 ₽
с промокодом kursy-online
|
От
3 070 ₽/мес
Без переплат на 2 года.
4 805 ₽/мес
|
Длительность
6 месяцев
|
Старт
3 апреля
|
Подробнее |
|
Тестировщик мобильных игр
|
XYZ School
21 отзыв
|
Цена
90 300 ₽
129 000 ₽
Ещё -14% по промокоду
|
От
6 000 ₽/мес
|
Длительность
4 месяца
|
Старт
26 марта
|
Подробнее |
|
Тестировщик ПО
|
Eduson Academy
114 отзывов
|
Цена
110 200 ₽
|
От
4 591 ₽/мес
Беспроцентная. На 1 год.
|
Длительность
4 месяца
|
Старт
6 апреля
|
Подробнее |
|
Профессия Инженер по автоматизации тестирования
|
Skillbox
232 отзыва
|
Цена
138 372 ₽
276 744 ₽
Ещё -20% по промокоду
|
От
5 766 ₽/мес
Без переплат на 2 года.
|
Длительность
4 месяца
|
Старт
23 марта
|
Подробнее |

OTUS vs ProductStar: куда идти технарю, чтобы стать продактом — честное сравнение подходов
OTUS или ProductStar — что выбрать, если вы хотите перейти в продакт-менеджмент? Разбираем разницу в обучении, практике и результате, чтобы вы не потратили время зря.

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.

OTUS vs GeekBrains для backend: где строже к качеству кода и полезнее ревью
OTUS или GeekBrains — где обучение backend-разработке даёт более строгий подход к качеству кода? Разбираем, как устроено code review, какие инженерные практики используют школы и как проверить уровень ревью до оплаты курса.