Транзакции в базах данных: что это такое, как работают и зачем нужны на практике
Давайте начнем с базового определения. Транзакция в базе данных — это последовательность операций, которая выполняется как единое целое: либо все операции завершаются успешно, либо ни одна из них не применяется. Звучит просто, не правда ли? Однако за этой простотой скрывается один из фундаментальных механизмов, обеспечивающих надежность современных информационных систем.

В чем же принципиальная разница между обычным запросом и транзакцией? Одиночный SQL-запрос — это атомарная операция сама по себе: например, UPDATE либо изменит нужную строку, либо завершится с ошибкой. Транзакция же объединяет несколько таких запросов в логическую группу, которая должна выполниться целиком. Можно сказать, что если запрос — это кирпич, то транзакция — это целая стена, которая либо стоит прочно, либо не построена вовсе.
Зачем это нужно? Представим ситуацию: приложение выполняет серию операций, где каждый следующий шаг зависит от предыдущего. Без транзакций система рискует оказаться в промежуточном, несогласованном состоянии — когда часть операций выполнена, а часть нет. Транзакции решают эту проблему, гарантируя несколько ключевых свойств:
- Единство операций — все действия внутри транзакции рассматриваются как одно целое.
- Принцип «всё или ничего» — либо применяются все изменения, либо система откатывается к исходному состоянию.
- Защита от частичного выполнения — невозможно застрять «на полпути».
Эти свойства делают транзакции незаменимым инструментом для обеспечения целостности данных в критически важных бизнес-процессах.
- Зачем нужны транзакции: ключевые задачи и риски без них
- Как работает: механизм выполнения
- ACID: свойства транзакций и их роль в целостности данных
- Уровни изоляции
- Блокировки в транзакциях: зачем нужны и как работают
- Примеры транзакций в реальных сценариях
- Транзакции и CAP-теорема
- Заключение
- Рекомендуем посмотреть курсы по SQL
Зачем нужны транзакции: ключевые задачи и риски без них
Теперь рассмотрим, какие практические проблемы возникают, когда мы пытаемся обойтись без этих операций. На первый взгляд может показаться, что последовательное выполнение нескольких SQL-команд — вполне достаточное решение. Однако реальность оказывается значительно сложнее.
Представим классический банковский перевод: необходимо списать 5000 рублей со счета клиента A и зачислить их на счет клиента B. Без использования транзакции это три отдельные операции: проверка баланса, списание средств и зачисление. Что произойдет, если после списания денег со счета A произойдет сбой — отключится питание, упадет сервер или возникнет ошибка в коде? Деньги исчезнут в никуда: с одного счета они уже ушли, а на другой так и не поступили. Для банковской системы такой сценарий абсолютно неприемлем.
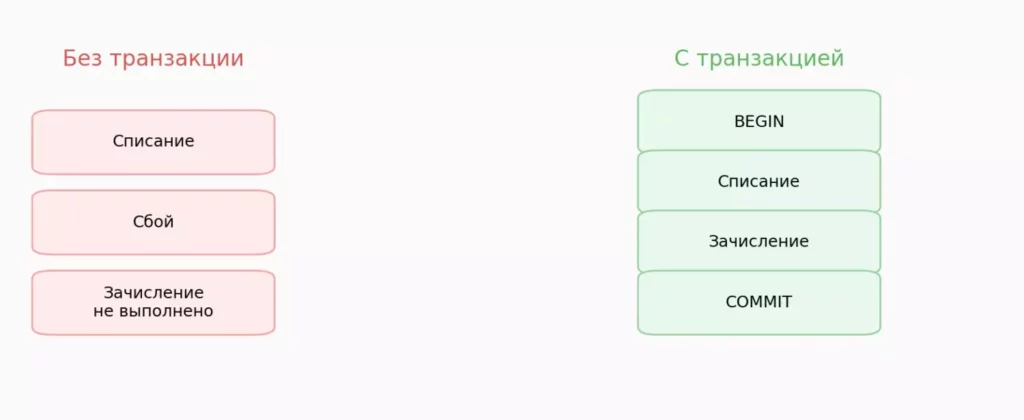
Слева показан сценарий без транзакции, где сбой приводит к потере данных. Справа — корректный вариант с транзакцией, в котором изменения либо фиксируются полностью, либо откатываются целиком.
Аналогичная ситуация возникает в интернет-магазинах при оформлении заказа: система должна зарезервировать товар на складе, создать запись о заказе, обновить статус товара и зафиксировать списание средств. Если операция прервется на любом этапе, возникнет хаос — клиент может оплатить несуществующий заказ или товар окажется зарезервирован без соответствующего заказа.
Складская логистика также критически зависит от операций: перемещение товара между складами требует одновременного списания с одного и зачисления на другой. Без атомарности таких операций компания может столкнуться с «телепортацией» товаров — когда учетная система показывает, что товар существует в двух местах одновременно или не существует нигде.
Какие конкретные проблемы возникают без транзакций?
- Частичное выполнение операций — система застревает в промежуточном состоянии, когда часть изменений применена, а часть нет.
- Потеря данных — критически важная информация может исчезнуть при сбоях.
- Гонки данных (race conditions) — параллельные процессы конфликтуют, перезаписывая изменения друг друга.
- Нарушение бизнес-логики — состояние системы перестает соответствовать реальности.
- Невозможность отката — нет механизма для возврата к корректному состоянию при ошибке.
Как мы видим, транзакции — это не просто техническая особенность СУБД, а фундаментальная защита от катастрофических сценариев в бизнес-приложениях.
Майнд-карта показывает ключевые аспекты работы с транзакциями и связи между ними. Она помогает быстро сориентироваться в теме и понять, как практические задачи, механизм выполнения, свойства ACID и уровни изоляции связаны между собой.
Как работает: механизм выполнения
Разберемся в механике — как именно СУБД обеспечивает их корректную работу и что происходит на каждом этапе выполнения.
Жизненный цикл транзакции достаточно прямолинеен и состоит из нескольких ключевых фаз. Сначала мы явно объявляем начало транзакции, затем выполняем необходимые SQL-операции, и наконец — фиксируем изменения или откатываем их в случае проблем. Звучит просто, но за этой простотой скрывается сложная работа системы управления базой данных.
Когда мы открываем операцию командой BEGIN, СУБД создает своего рода «изолированное пространство» для всех последующих действий. Все изменения, которые мы вносим внутри этого пространства, остаются невидимыми для других процессов до момента фиксации. База данных ведет подробный журнал (transaction log) всех операций — это позволяет в любой момент откатить изменения или восстановить их после сбоя.
Пошагово процесс выглядит следующим образом. После выполнения BEGIN мы последовательно выполняем нужные запросы — SELECT, UPDATE, INSERT, DELETE. СУБД фиксирует все изменения во временных структурах данных, но не применяет их окончательно. Если на каком-то этапе возникает ошибка — синтаксическая, нарушение ограничений целостности или системный сбой — вся транзакция автоматически откатывается. Если же все операции выполнены успешно, команда COMMIT делает изменения постоянными и видимыми для всех пользователей системы.
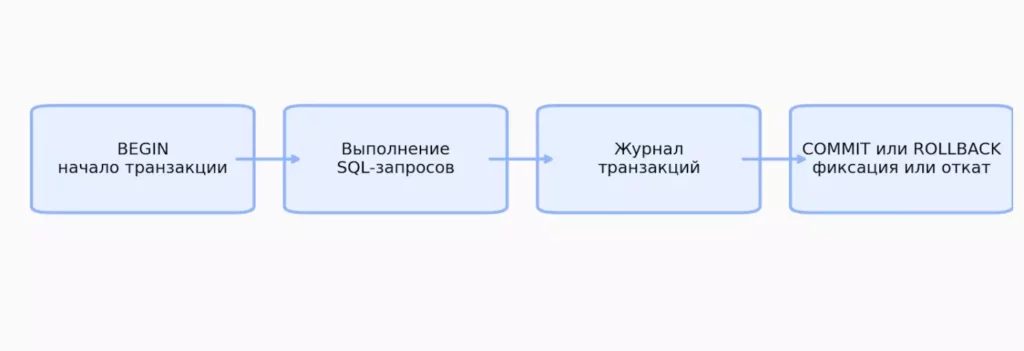
Диаграмма показывает последовательное выполнение транзакции в базе данных — от её начала до фиксации или отката изменений. Все этапы идут слева направо, что отражает реальный порядок работы СУБД и упрощает восприятие процесса.
Важно понимать: атомарность обеспечивается не магическим образом, а благодаря сложной внутренней механике СУБД. Система отслеживает блокировки, управляет журналом операций, координирует доступ к данным и гарантирует, что либо все изменения будут применены, либо ни одно из них не повлияет на состояние базы.
Основные команды
Рассмотрим три ключевые команды, которые составляют основу работы:
- BEGIN (или START TRANSACTION) — открывает новую операцию и сообщает СУБД, что все последующие операции должны рассматриваться как единое целое. С этого момента система начинает отслеживать все изменения в специальном журнале.
- COMMIT — фиксирует все изменения, сделанные внутри операции, делая их постоянными и видимыми для других пользователей. После выполнения этой команды откат становится невозможным — данные уже записаны на диск и считаются надежно сохраненными.
- ROLLBACK — отменяет все операции, выполненные после BEGIN, возвращая базу данных в состояние, которое было до начала транзакции. Эту команду можно использовать как при ошибках, так и по логике приложения — например, когда бизнес-правила требуют отмены операции.
Эта триада команд дает разработчику полный контроль над процессом изменения данных, позволяя гибко управлять целостностью информации в любых сценариях.
ACID: свойства транзакций и их роль в целостности данных
Мы подошли к одному из фундаментальных понятий теории баз данных — аббревиатуре ACID. Этот акроним объединяет четыре ключевых свойства, которые должна гарантировать любая надежная транзакционная система. Можно сказать, что ACID — это своего рода конституция, набор принципов, которые превращают обычную последовательность операций в надежный механизм защиты данных.
Интересно, что эти свойства были сформулированы еще в конце 1970-х годов, но остаются актуальными и сегодня — несмотря на все изменения в архитектуре систем и появление новых парадигм хранения данных. Давайте разберем каждое свойство подробнее.
Атомарность (Atomicity)
Атомарность — это гарантия, что транзакция выполняется по принципу «всё или ничего». Либо все операции внутри нее завершаются успешно и их результаты фиксируются, либо ни одна из них не оказывает влияния на состояние базы данных. Промежуточных вариантов не существует.
Вернемся к примеру с банковским переводом. Представим таблицу счетов, где у пользователя с user_id = 10 на счету 100 рублей, и у пользователя с user_id = 30 также 100 рублей. Нам нужно перевести 50 рублей от первого ко второму. Без транзакции мы выполняем операцию списания, и в этот момент происходит сбой — отключается питание или система перезагружается. Результат? Первый пользователь лишился 50 рублей, а второй их так и не получил. Деньги буквально исчезли в цифровой пустоте.
Атомарность решает эту проблему радикально: если операция не завершилась командой COMMIT, все изменения автоматически откатываются. СУБД отслеживает каждую операцию и в случае любого сбоя возвращает данные в исходное состояние. Это происходит независимо от причины прерывания — будь то ошибка в коде, нарушение ограничений целостности или аппаратный сбой.
Согласованность (Consistency)
Согласованность гарантирует, что любая завершенная операция переводит базу данных из одного корректного состояния в другое корректное состояние. Ключевое слово здесь — «корректное»: данные должны соответствовать всем определенным правилам, ограничениям и бизнес-логике.
Важный нюанс: внутри операции данные могут временно оказаться несогласованными. В нашем примере с переводом денег есть момент, когда средства уже списаны с одного счета, но еще не зачислены на другой — общая сумма в системе временно уменьшилась. Это нормально и допустимо, потому что эти промежуточные состояния невидимы для внешних наблюдателей. Важно лишь то, что после завершения транзакции всё встает на свои места: деньги перемещены, и суммы сходятся.
Стоит отметить, что обеспечение согласованности — это не только задача СУБД. База данных может контролировать технические ограничения: внешние ключи, проверки типов данных, уникальность значений. Однако бизнес-логику должны обеспечивать программисты, пишущие код приложения. Если правила бизнеса гласят, что нельзя продать больше товара, чем есть на складе, — эту проверку нужно явно реализовать в коде транзакции.
Изолированность (Isolation)
Изолированность означает, что параллельно выполняющиеся операции не должны влиять друг на друга. Идеальная изоляция предполагает, что каждая транзакция работает так, будто она единственная в системе — не видит незафиксированных изменений других транзакций и не испытывает их влияния на свои результаты.
В реальности полная изоляция — дорогое удовольствие с точки зрения производительности. Если строго изолировать все операции, система фактически будет выполнять их последовательно, что неприемлемо для высоконагруженных приложений. Поэтому современные СУБД предлагают различные уровни изолированности — от минимального (Read Uncommitted) до максимального (Serializable).
Более низкие уровни изоляции позволяют достичь большей производительности, но создают риск специфических проблем: грязных чтений, неповторяющихся чтений или фантомных строк. Выбор подходящего уровня изоляции — это всегда компромисс между надежностью и скоростью работы системы. Разработчик должен понимать, какие аномалии может допустить его приложение без ущерба для бизнес-логики.
Устойчивость (Durability)
Устойчивость гарантирует, что после успешного завершения операции (выполнения COMMIT) все сделанные изменения останутся в базе данных навсегда — независимо от любых последующих сбоев. Даже если сразу после подтверждения транзакции отключится электричество, выйдет из строя жесткий диск или произойдет другая катастрофа, данные не пропадут.
Как это достигается? СУБД использует журнал операций (write-ahead log), который записывается на диск до того, как изменения применяются к основным файлам данных. Когда пользователь получает подтверждение о выполнении транзакции, система уже гарантировала физическую запись всех изменений. После восстановления работы СУБД может воспроизвести все зафиксированные операции из журнала и вернуть базу в корректное состояние.
Это свойство критически важно для доверия к системе. Представим интернет-магазин: клиент оплатил заказ, получил подтверждение, и тут же произошел сбой сервера. Благодаря устойчивости, после перезапуска система «помнит» о заказе и не теряет ни оплату, ни информацию о заказанных товарах. Если бы это свойство не гарантировалось, ни один критически важный бизнес-процесс не мог бы полагаться на базы данных.
Уровни изоляции
Мы уже упомянули, что полная изоляция транзакций — это дорогостоящее требование с точки зрения производительности. На практике большинство систем не нуждаются в абсолютной изоляции для всех операций, и здесь на помощь приходит концепция уровней изолированности.
Идея проста: разработчик может явно указать СУБД, насколько строго должна быть изолирована конкретная операция. Высокий уровень изоляции максимально защищает от аномалий и конфликтов, но замедляет работу системы из-за необходимости блокировать больше ресурсов. Низкий уровень позволяет транзакциям работать быстрее и параллельнее, но создает риск различных проблем чтения данных.
Какие конкретные проблемы возникают при недостаточной изоляции? Существуют три классические аномалии: грязное чтение (dirty read) — когда транзакция видит незафиксированные изменения другой операции; неповторяющееся чтение (non-repeatable read) — когда повторный запрос внутри одной операции возвращает разные результаты из-за изменений, внесенных другими транзакциями; и фантомное чтение (phantom read) — когда в результате повторного запроса появляются или исчезают строки.
Стандарт SQL определяет четыре уровня изоляции, каждый из которых защищает от определенного набора аномалий.
- Read Uncommitted. Самый низкий уровень изоляции, который практически не обеспечивает защиты. Транзакция может читать данные, которые еще не зафиксированы другими операциями — так называемые «грязные данные». Это самый быстрый режим, но и самый рискованный: если транзакция, внесшая изменения, откатится, мы получим информацию, которая никогда не существовала в согласованном состоянии базы.
- Read Committed. Уровень по умолчанию во многих СУБД, включая PostgreSQL. Гарантирует, что операция видит только зафиксированные данные — грязные чтения невозможны. Однако если другая транзакция изменит и зафиксирует данные в процессе нашей работы, повторный запрос вернет уже новые значения. Для большинства приложений этот уровень — оптимальный баланс между надежностью и производительностью.
- Repeatable Read. Обеспечивает более строгую изоляцию: все данные, прочитанные в начале операции, остаются неизменными до ее завершения. Если мы дважды читаем одну и ту же строку, мы гарантированно получим одинаковые значения. Однако могут возникнуть фантомные строки — когда другая транзакция добавляет новые записи, соответствующие критериям нашего запроса.
- Serializable. Максимальный уровень изоляции, который полностью эмулирует последовательное выполнение транзакций. Никакие аномалии невозможны, но достигается это ценой значительного снижения производительности и увеличения вероятности конфликтов, требующих повторного выполнения операций.
Выбор уровня изоляции — это всегда компромисс, который должен учитывать специфику конкретного приложения и критичность обрабатываемых данных.
Блокировки в транзакциях: зачем нужны и как работают
Изоляция не возникает сама по себе — за ней стоит сложный механизм блокировок, который СУБД использует для координации доступа к данным. По сути, блокировки — это способ сообщить другим операциям: «Эти данные сейчас используются, подождите или работайте с другими записями».
Зачем вообще нужны блокировки? Представим ситуацию: две операции одновременно пытаются изменить один и тот же счет в банке. Без механизма координации обе прочитают текущий баланс, выполнят свои вычисления и запишут результат — при этом одно из изменений будет потеряно. Блокировки предотвращают такие конфликты, заставляя транзакции ждать своей очереди для доступа к конкретным строкам или таблицам.
Существуют два основных типа блокировок: разделяемые (shared locks) и исключительные (exclusive locks). Разделяемая блокировка устанавливается при чтении данных и позволяет другим транзакциям также читать эти же данные, но запрещает их изменение. Можно сказать, что это режим «смотреть можно, трогать нельзя». Исключительная блокировка возникает при изменении данных и запрещает любой доступ — ни читать, ни записывать другие транзакции не могут, пока она не будет снята.
Связь между блокировками и уровнями изоляции прямая: чем выше уровень изоляции, тем больше блокировок устанавливает СУБД и тем дольше они удерживаются. На уровне Serializable система может блокировать целые диапазоны строк или даже таблицы целиком, тогда как Read Committed ограничивается минимально необходимыми блокировками на уровне отдельных записей.
Основные виды блокировок включают:
- Блокировки строк (row-level locks) — самый детальный уровень, блокируют только конкретные строки таблицы.
- Блокировки страниц (page-level locks) — блокируют целые страницы данных в памяти.
- Блокировки таблиц (table-level locks) — блокируют всю таблицу целиком, самый грубый механизм.
- Намеренные блокировки (intention locks) — сигнализируют о намерении заблокировать нижележащие уровни.
Важно понимать, что блокировки — это не просто техническая деталь реализации, а фундаментальный компромисс между целостностью данных и производительностью системы.
Примеры транзакций в реальных сценариях
Теория становится понятнее, когда мы видим ее применение на практике. Рассмотрим несколько типичных ситуаций, где операции играют критическую роль в обеспечении целостности данных.
Пример 1: Денежный перевод
Классический сценарий — перевод средств между счетами. Допустим, у нас есть таблица accounts с двумя пользователями: у первого (user_id = 10) на счету 100 рублей, у второго (user_id = 30) также 100 рублей. Нам нужно перевести 50 рублей от первого ко второму.
Без транзакции процесс выглядел бы как три отдельных запроса: сначала проверяем баланс отправителя, затем списываем деньги, затем зачисляем получателю. Проблема в том, что между любыми двумя операциями может произойти сбой, и данные окажутся несогласованными.
С транзакцией код выглядит следующим образом:
BEGIN; SELECT amount FROM accounts WHERE user_id = 10; UPDATE accounts SET amount = amount - 50 WHERE user_id = 10; UPDATE accounts SET amount = amount + 50 WHERE user_id = 30; COMMIT;
Что здесь происходит? После BEGIN СУБД начинает отслеживать все изменения. Первый SELECT проверяет текущий баланс (хотя в реальном коде мы могли бы добавить проверку достаточности средств). Затем два UPDATE изменяют балансы счетов — но эти изменения пока существуют только в контексте нашей транзакции. Наконец, COMMIT делает изменения постоянными: теперь у первого пользователя 50 рублей, у второго — 150. Если бы на любом этапе возникла ошибка, все откатилось бы автоматически.
Пример 2: Интернет-магазин
Оформление заказа в интернет-магазине — еще более сложная операция, требующая изменений в нескольких таблицах. Необходимо создать запись о заказе, зарезервировать товары на складе, обновить статусы товаров и зафиксировать оплату.
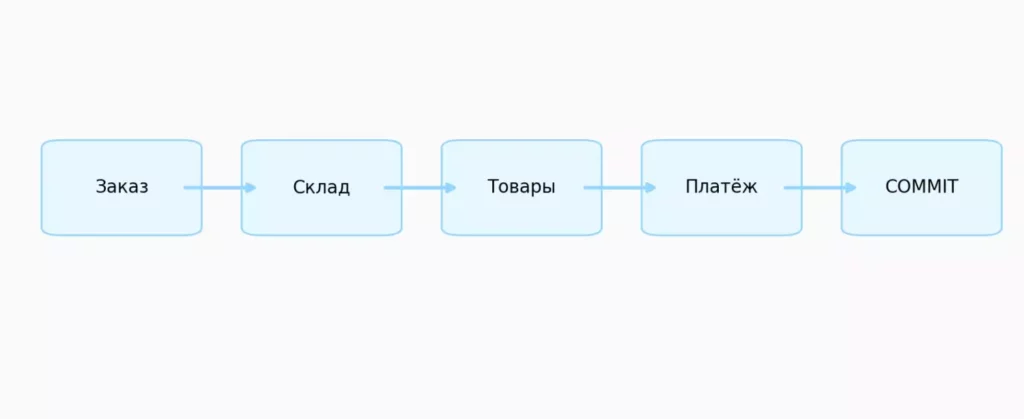
Иллюстрация показывает, как одна транзакция затрагивает несколько подсистем интернет-магазина. Все шаги выполняются как единое целое и подтверждаются только после успешного завершения.
BEGIN; INSERT INTO orders (user_id, total_amount, status) VALUES (100, 5000, 'pending'); UPDATE products SET stock = stock - 1 WHERE product_id = 42; UPDATE products SET reserved = reserved + 1 WHERE product_id = 42; INSERT INTO order_items (order_id, product_id, quantity) VALUES (LAST_INSERT_ID(), 42, 1); UPDATE payments SET status = 'completed' WHERE payment_id = 777; COMMIT;
Здесь критически важна атомарность: если хотя бы одна операция не выполнится (например, товара не окажется на складе), весь заказ должен быть отменен. Представьте ситуацию, когда оплата прошла, но товар не зарезервировался — это прямой путь к конфликтам с клиентами и операционным проблемам.
Пример 3: Ошибка и ROLLBACK
Иногда транзакцию нужно откатить не из-за технической ошибки, а по бизнес-логике. Например, мы обнаруживаем, что у пользователя недостаточно средств уже после начала транзакции:
BEGIN; UPDATE accounts SET amount = amount - 5000 WHERE user_id = 10; -- Проверяем баланс в коде приложения -- Обнаруживаем, что баланс стал отрицательным ROLLBACK;
Команда ROLLBACK явно отменяет все изменения, вернув счет к исходному состоянию. Это дает разработчикам гибкость в реализации сложной бизнес-логики: можно выполнить несколько операций, проверить промежуточный результат и принять решение о фиксации или отмене.
Эти примеры показывают, что операции — не абстрактная теория, а практический инструмент, без которого невозможна разработка надежных бизнес-приложений.
Транзакции и CAP-теорема
До этого момента мы обсуждали транзакции в контексте одной базы данных на одном сервере. Однако современные системы часто оказываются распределенными — данные хранятся на множестве серверов, расположенных в разных дата-центрах, а иногда и на разных континентах. Здесь возникает интересный вопрос: можно ли в такой среде гарантировать те же свойства ACID, что и в обычной реляционной базе?
Ответ дает знаменитая CAP-теорема, которая утверждает: распределенная система может одновременно обеспечить только два из трех свойств — согласованность (Consistency), доступность (Availability) и устойчивость к разделению (Partition tolerance). Это означает, что в условиях сетевых разделений (когда связь между узлами нарушается) приходится выбирать между согласованностью данных и доступностью системы.
Классические реляционные СУБД с поддержкой ACID выбирают согласованность: если невозможно гарантировать корректное выполнение транзакции на всех узлах, система откажется выполнять операцию. Многие современные NoSQL-решения выбирают другой путь — жертвуют немедленной согласованностью ради доступности, используя модель «eventual consistency» (конечная согласованность). В такой модели данные могут временно находиться в несогласованном состоянии на разных узлах, но в конечном итоге синхронизируются.
Это не означает, что один подход лучше другого — скорее, это разные инструменты для разных задач. Для банковских операций критична немедленная согласованность, и классические транзакции незаменимы. Для социальных сетей, где важнее доступность и масштабируемость, конечная согласованность может быть приемлемым компромиссом. Понимание этих ограничений помогает архитекторам систем делать осознанный выбор технологий под конкретные бизнес-требования.
Заключение
Мы прошли путь от базового определения транзакций до сложных концепций изоляции и распределенных систем. Теперь становится очевидным, что это не просто техническая особенность баз данных, а фундаментальный механизм обеспечения надежности любого серьезного приложения. Подведем итоги:
- Транзакция в базе данных — это логическая группа операций. Она гарантирует, что изменения будут применены либо полностью, либо не будут применены вовсе.
- Использование транзакций защищает систему от частичного выполнения операций. Это особенно критично для финансовых, торговых и учетных систем.
- Механизм BEGIN, COMMIT и ROLLBACK позволяет управлять изменениями данных. Разработчик может явно зафиксировать или отменить результат выполнения запросов.
- Свойства ACID обеспечивают надежность транзакций. Они отвечают за атомарность, согласованность, изоляцию и устойчивость данных.
- Уровни изоляции помогают балансировать между производительностью и целостностью данных. Выбор уровня зависит от бизнес-задач и допустимых рисков.
- Блокировки играют ключевую роль в параллельной работе транзакций. Они предотвращают конфликты и потерю данных при одновременном доступе.
Если вы только начинаете осваивать профессию backend-разработчика или работу с базами данных, рекомендуем обратить внимание на подборку курсов по SQL и СУБД. В них есть теоретическая и практическая часть, которая помогает разобраться в транзакциях, уровнях изоляции и реальных сценариях работы с данными.
Рекомендуем посмотреть курсы по SQL
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
SQL с нуля для анализа данных
|
Eduson Academy
100 отзывов
|
Цена
Ещё -5% по промокоду
42 624 ₽
|
От
3 552 ₽/мес
Беспроцентная. На 1 год.
|
Длительность
1 месяц
|
Старт
10 января
|
Ссылка на курсПодробнее |
|
Продвинутый SQL
|
Нетология
45 отзывов
|
Цена
с промокодом kursy-online
40 200 ₽
77 018 ₽
|
От
2 353 ₽/мес
Рассрочка на 1 год.
|
Длительность
1 месяц
|
Старт
26 января
2 раза в неделю по будням
|
Ссылка на курсПодробнее |
|
SQL-разработчик
|
Eduson Academy
100 отзывов
|
Цена
Ещё -5% по промокоду
63 996 ₽
|
От
5 333 ₽/мес
0% на 12 месяцев
|
Длительность
6 месяцев
|
Старт
12 января
|
Ссылка на курсПодробнее |

Что такое Business Model Canvas
Что делает методику Александра Остервальдера настолько популярной среди предпринимателей? В статье вы найдете простое объяснение, как составить бизнес-модель по Canvas, чтобы увидеть свой проект целиком и понять, где кроются точки роста.

Жизненный цикл компании: как распознать свой этап и управлять развитием бизнеса
Жизненный цикл компании — это последовательность этапов, которые проходят почти все организации. Как понять, где вы находитесь сейчас, и какие решения помогут двигаться дальше? В статье вы найдёте простые пояснения, примеры и советы, которые помогут разобраться в логике развития бизнеса.

Референс-лист компании: что это такое, зачем нужен и как правильно его составить
Что такое референс-лист компании и почему он стал обязательной частью коммерческих материалов? В этом разборе объясняем, как документ помогает показать опыт, какие данные действительно важны и как оформить кейсы так, чтобы клиент быстро понял вашу ценность. Материал подойдёт тем, кто хочет улучшить презентацию своих проектов и повысить доверие к бренду.

Что такое NGFW
Хотите понять, почему NGFW считается стандартом безопасности для бизнеса? В этой статье объясняем простыми словами, как работает межсетевой экран нового поколения и чем он лучше классических решений.