Вопросы для собеседования аналитика данных — как подготовиться и что спрашивают работодатели
Собеседование на позицию аналитика данных — это не экзамен на знание синтаксиса SQL (хотя и его тоже проверят, не сомневайтесь). Это попытка работодателя понять, как вы мыслите, умеете ли задавать правильные вопросы и можете ли вы объяснить бизнесу, почему конверсия упала на 15%, не погружаясь в дебри технической терминологии.

Типовые вопросы на собеседованиях делятся на несколько блоков: SQL (куда без него), Python (если компания им пользуется), статистика (для тех, кто занимается A/B-тестами), продуктовые задачи (где проверяют вашу способность думать, а не гуглить). Работодатели смотрят не только на то, знаете ли вы разницу между INNER JOIN и LEFT JOIN, но и на то, как вы рассуждаете, когда сталкиваетесь с аномалией в данных или противоречивой метрикой.
Цели этой статьи:
- Подготовить вас к техническим и продуктовым вопросам.
- Помочь повторить ключевые темы перед интервью.
- Дать инструменты для самопроверки и структурированной подготовки.
Поехали разбираться, что же на самом деле хотят услышать от вас на собеседовании.
- Кто такой аналитик данных и какие навыки нужны на собеседовании
- Основные темы и вопросы на собеседовании аналитика данных
- Поведение на собеседовании и советы от экспертов
- Что делать, если вы начинающий аналитик без опыта
- 15 типовых вопросов работодателей аналитикам данных
- Как готовиться к собеседованию аналитика данных: чек-лист
- Заключение
- Рекомендуем посмотреть курсы по системной аналитике
Кто такой аналитик данных и какие навыки нужны на собеседовании
Аналитик данных — это человек, который превращает кучу цифр в понятные для бизнеса выводы. Звучит просто, но на практике это означает, что вы должны уметь собирать данные из разных источников (часто криво настроенных), обрабатывать их так, чтобы они не врали, визуализировать результаты в виде дашбордов, которые не вызовут у руководства головную боль, и — самое главное — интерпретировать всё это таким образом, чтобы бизнес понял, что делать дальше.
Ключевые задачи аналитика, которые работодатели держат в голове во время собеседования:
- Сбор данных из баз, API, таблиц и прочих источников (иногда приходится выковыривать информацию из Excel-файлов, присланных по почте в 2 часа ночи).
- Обработка и очистка данных — потому что реальные данные всегда грязные, с пропусками и дубликатами.
- Визуализация в BI-инструментах типа Tableau или Power BI.
- Интерпретация результатов и формулирование рекомендаций для продукта или маркетинга.
На собеседовании проверяют две большие группы навыков: технические (hard skills) и мягкие (soft skills). Первые — это ваша способность писать запросы и строить графики. Вторые — умение объяснить директору по маркетингу, почему его любимая метрика на самом деле ничего не показывает.
Технические навыки:
- SQL — абсолютная база, без которой вас даже не позовут на второй этап.
- Python — для более сложной обработки данных (хотя не везде требуется).
- Excel — да-да, в 2025 году его всё ещё спрашивают, и многие компании до сих пор живут в сводных таблицах.
- BI-инструменты — Tableau, Power BI, DataLens и другие системы визуализации.
Мягкие навыки:
- Аналитическое мышление — умение видеть аномалии, задавать правильные вопросы и копать глубже.
- Коммуникация — способность переводить с технического на человеческий язык.
- Бизнес-ориентированность — понимание, какие метрики действительно важны для компании, а какие просто красиво выглядят в презентации.
Вот небольшая таблица, которая показывает связь между навыками и тем, как их проверяют:
| Навык | Что проверяют на собеседовании | Пример вопроса |
|---|---|---|
| SQL | Знание синтаксиса, оконных функций, JOIN-ов | «Напишите запрос для расчёта скользящего среднего за 7 дней» |
| Python | Работа с Pandas, обработка данных | «Как удалить дубликаты из DataFrame?» |
| Статистика | Понимание A/B-тестов, p-value | «Почему нельзя останавливать тест раньше времени?» |
| Аналитическое мышление | Способность находить причины аномалий | «Retention упал на 20%. Ваши действия?» |
| Коммуникация | Умение структурировать ответ | «Объясните, что такое конверсия, как будто я не из IT» |
Работодатели понимают, что джуниор не будет знать всё идеально. Но они хотят видеть, что вы умеете учиться, задавать вопросы и не паникуете, когда сталкиваетесь с незнакомой задачей. Кстати, именно поэтому на собеседованиях часто задают вопросы, на которые не существует однозначного правильного ответа — просто чтобы посмотреть, как вы рассуждаете.
Основные темы и вопросы на собеседовании аналитика данных
Теперь переходим к самому интересному — конкретным вопросам, которые вам зададут. Я разбил их по тематическим блокам, чтобы вы могли систематически подготовиться и не пропустить ничего важного. Каждый блок — это отдельная проверка ваших знаний, и работодатели обычно проходятся по всем (или почти всем) из них, в зависимости от специфики позиции.
Excel — базовые функции и аналитические инструменты
Да, я знаю, что вы ожидали сразу погрузиться в SQL и Python. Но реальность такова, что многие компании до сих пор живут в Excel, и даже если вы будете писать сложные запросы на Python, вас всё равно спросят про ВПР (или VLOOKUP, если хотите звучать по-английски солиднее).
Типовые вопросы:
- Умеете ли вы применять ВПР (VLOOKUP) для объединения данных из разных таблиц?
- Как работать со сводными таблицами (Pivot Tables)?
- Какие функции используете для фильтрации и сортировки больших массивов данных?
- Знакомы ли с условным форматированием для визуального выделения аномалий?
Пример вопроса:
«Какие функции используете для объединения таблиц, если ключевое поле находится в разных столбцах?»
Честно говоря, про Excel спрашивают скорее для галочки — предполагается, что базу знает каждый, кто хоть раз открывал таблицу. Но если вы внезапно не знаете, что такое сводная таблица, это может стать красным флагом. Чаще всего эти навыки не проверяют практическими заданиями, достаточно устного подтверждения, что вы с этим работали.
Совет:
Освежите в памяти функции ВПР, ИНДЕКС+ПОИСКПОЗ (INDEX+MATCH), а также базовые приёмы работы со сводными таблицами. Это займёт полчаса, но избавит вас от неловкости на собеседовании.
SQL — основа любой аналитики
SQL — это язык, без которого аналитик данных просто не существует. Можно не знать Python, можно обходиться без сложной статистики, но если вы не умеете писать запросы к базе данных, то вы не аналитик, а человек, который смотрит на таблицы с грустным выражением лица. SQL проверяют всегда, и проверяют тщательно — от базовых JOIN-ов до оконных функций и подзапросов.
Типовые вопросы:
- На каком диалекте SQL пишете? Какие программы используете? — Здесь хотят понять, работали ли вы с PostgreSQL, MySQL, MS SQL Server или чем-то экзотическим. Также могут спросить про интерфейсы: DBeaver, DataGrip, pgAdmin.
- Какие типы JOIN-ов знаете? — Все помнят INNER и LEFT, но не забывайте про RIGHT, FULL OUTER, CROSS и SELF JOIN. Последние два часто становятся сюрпризом для джунов.
- Использовали ли подзапросы и вложенные конструкции? — Проверяют, можете ли вы строить сложные запросы, когда нужно сначала что-то посчитать, а потом использовать результат в основном запросе.
- Что такое оконные функции? Для чего они используются? — Классика жанра. Оконные функции (ROW_NUMBER, RANK, LAG, LEAD) позволяют делать расчёты по группам без агрегации всей таблицы. Пример: рассчитать скользящее среднее или найти предыдущее значение для каждой строки.
- В каком порядке выполняется SQL-запрос? — Это не тот порядок, в котором вы его пишете (SELECT → FROM → WHERE), а реальный порядок выполнения движком базы данных: FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY → LIMIT. Многие спотыкаются на этом вопросе.
- В чём разница между WHERE и HAVING? — WHERE фильтрует строки до агрегации, HAVING — после. Если вы это перепутаете, запрос либо не выполнится, либо вернёт не те данные.
- Как оптимизировать медленный запрос? — Здесь смотрят на ваше понимание индексов, EXPLAIN-планов и умение не писать SELECT * для таблицы на миллион строк.
Пример устной логической задачки:
«У вас есть две таблицы — пользователи и их покупки. Как найти пользователей, которые ничего не купили?» (Правильный ответ: LEFT JOIN с проверкой на NULL в таблице покупок.)
Совет перед собеседованием:
Повторите разницу между типами JOIN-ов на практике (нарисуйте диаграммы Венна, если нужно), прорешайте несколько задач с оконными функциями на LeetCode или HackerRank, и обязательно вспомните порядок выполнения запроса — это один из любимых вопросов интервьюеров, которые хотят проверить глубину понимания, а не просто знание синтаксиса.
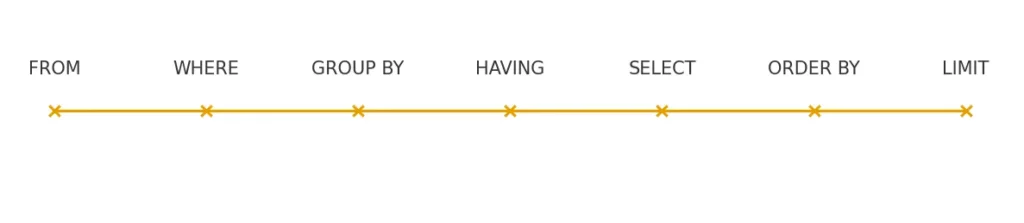
График показывает реальный порядок выполнения SQL-запроса движком базы данных. Помогает визуально закрепить один из самых частых вопросов на собеседованиях.
Python — обработка и анализ данных
Python для аналитика данных — это как швейцарский нож: не всегда нужен, но когда нужен, то очень сильно. Далеко не все компании требуют от джунов знание Python (многие обходятся SQL и BI-инструментами), поэтому перед собеседованием обязательно загляните в вакансию и посмотрите, упоминается ли этот навык. Если да — готовьтесь, потому что спросят обязательно.
Типовые вопросы:
- Какие библиотеки используете для работы с данными? — Базовый набор: Pandas (для работы с таблицами), NumPy (для математических операций), Matplotlib и Seaborn (для визуализации). Если упомянете SciPy или Plotly — будет плюсом.
- Какие типы данных бывают в Python? — Строки (str), числа (int, float), списки (list), кортежи (tuple), словари (dict), множества (set). Могут спросить про операции между разными типами — например, что будет, если сложить строку и число (спойлер: будет ошибка).
- С какими форматами данных работали? — CSV, JSON, XLSX, TXT, иногда Parquet или XML. Здесь проверяют, умеете ли вы загружать данные из разных источников и понимаете ли специфику каждого формата.
- Чем отличаются Series и DataFrame в Pandas? — Series — это одномерная структура (столбец), DataFrame — двумерная (таблица). Простой вопрос, но многие путаются.
- Как обработать пропущенные значения? — Методы fillna(), dropna(), interpolate(). Работодатель хочет понять, знаете ли вы, что делать с грязными данными (а они всегда грязные).
- Как объединить два DataFrame? — Функции merge() и concat(). Это аналог JOIN в SQL, только в Python.
Пример вопроса:
«У вас есть DataFrame с продажами. Как найти топ-10 товаров по выручке?» (Ответ: группировка по товару, суммирование выручки, сортировка и срез.)
Вот небольшая таблица с основными библиотеками:
| Библиотека | Для чего используется |
|---|---|
| Pandas | Работа с таблицами, фильтрация, группировка, агрегация |
| NumPy | Математические операции, работа с массивами |
| Matplotlib | Базовая визуализация данных |
| Seaborn | Более красивая статистическая визуализация |
| SciPy | Продвинутая статистика и научные вычисления |
Совет:
Если Python не указан в требованиях вакансии, но вы им владеете — всё равно упомяните. Это всегда плюс. А если указан, но вы знаете только основы — так и говорите честно, но покажите готовность учиться (и желательно приведите пример учебного проекта, где вы его применяли).
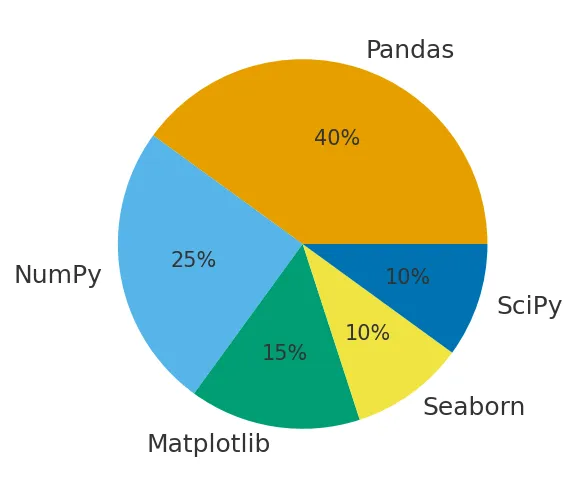
Круговая диаграмма показывает относительную частоту использования библиотек в аналитике данных. Помогает новичку понять, какие инструменты действительно важны на старте.
Статистика и A/B-тестирование
Статистика — это та область, которая отделяет аналитика, который просто строит графики, от аналитика, который понимает, можно ли доверять этим графикам. Не все компании требуют глубоких знаний статистики от джунов (особенно если вы не занимаетесь A/B-тестами), но если можете ответить на базовые вопросы — это серьёзное преимущество. Работодатели любят проверять, понимаете ли вы разницу между корреляцией и причинно-следственной связью, или для вас это просто красивые слова.
Типовые вопросы:
- Что такое p-value? — Это вероятность получить наблюдаемый результат (или более экстремальный) при условии, что нулевая гипотеза верна. Звучит сложно, но по сути это ответ на вопрос: «Насколько случаен наш результат?» Обычно порог — 0.05 (5%).
- Что такое доверительный интервал? — Диапазон значений, в котором с определённой вероятностью (например, 95%) находится истинное значение параметра. Например, если средний чек составляет 1000 рублей с доверительным интервалом [950, 1050], это значит, что мы на 95% уверены, что реальное среднее лежит в этом диапазоне.
- Что такое дисперсия и стандартное отклонение? — Дисперсия показывает, насколько данные разбросаны относительно среднего. Стандартное отклонение — это квадратный корень из дисперсии, и его проще интерпретировать, потому что оно в тех же единицах, что и исходные данные.
- Назовите меры центральной тенденции. — Среднее (mean), медиана (median), мода (mode). Классический вопрос, который проверяет базу. Также могут спросить, когда лучше использовать медиану вместо среднего (ответ: когда есть выбросы).
- Какие методы проверки гипотез в A/B-тестах знаете? — t-тест (для сравнения средних), z-тест (для больших выборок), хи-квадрат (для категориальных данных), тест Манна-Уитни (непараметрический аналог t-теста).
- Что такое ошибки первого и второго рода? — Ошибка первого рода (ложноположительный результат) — это когда мы отвергли нулевую гипотезу, хотя она верна. Ошибка второго рода (ложноотрицательный результат) — когда мы не отвергли нулевую гипотезу, хотя она неверна. В контексте A/B-теста: первая ошибка — это признать изменение эффективным, когда оно не работает; вторая — не заметить работающее изменение.
Пример вопроса:
«Почему p-value < 0.05 считается значимым?» — Это просто договорённость, принятая в научном сообществе. Порог 0.05 означает, что мы готовы ошибиться в 5% случаев, признав результат значимым, когда он случаен.
Совет:
Если статистика для вас тёмный лес, хотя бы выучите определения основных терминов и поймите логику A/B-тестирования. Работодатели часто не ждут от джунов глубокого знания, но хотят видеть, что вы понимаете принципы — например, почему нельзя останавливать тест досрочно, даже если результаты уже выглядят значимыми (потому что это увеличивает вероятность ошибки первого рода).
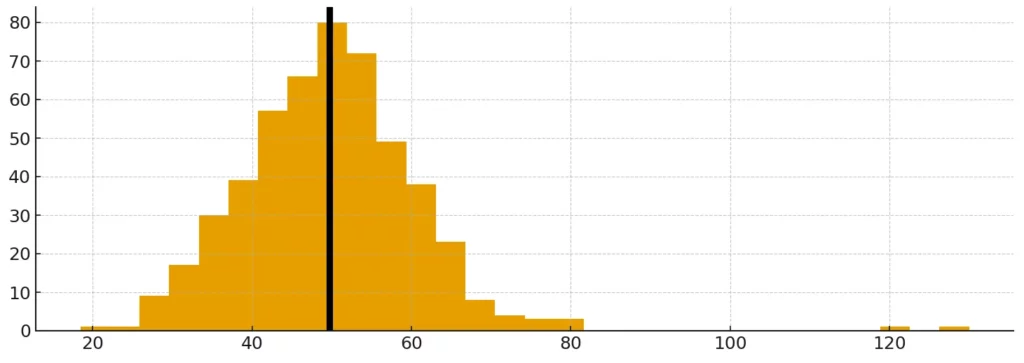
mean vs median
Гистограмма с линиями среднего, медианы и моды демонстрирует, как выбросы искажают среднее значение. Это помогает понять, почему медиана надёжнее в «грязных» выборках.
Метрики и визуализация
Метрики — это язык, на котором аналитик общается с бизнесом. Вы можете писать гениальные SQL-запросы и строить сложные модели, но если не понимаете, что такое retention и почему ARPU важнее количества скачиваний, то ваша ценность для компании стремится к нулю. А визуализация — это способ донести свои находки до тех, кто не хочет (и не должен) разбираться в ваших запросах и формулах.
Продуктовые метрики, которые обязательно нужно знать:
- DAU/MAU (Daily/Monthly Active Users) — количество активных пользователей за день или месяц. Базовая метрика вовлечённости.
- Retention — процент пользователей, которые вернулись в продукт через определённое время (например, на 7-й или 30-й день). Один из главных показателей здоровья продукта.
- ARPU (Average Revenue Per User) — средняя выручка на одного пользователя. Показывает, сколько денег приносит каждый клиент.
- Конверсия — процент пользователей, совершивших целевое действие (регистрация, покупка, подписка). Может быть конверсия из визита в регистрацию, из регистрации в покупку и так далее.
- LTV (Lifetime Value) — общая выручка, которую компания получит от пользователя за всё время его жизни в продукте.
- Churn Rate — процент пользователей, которые перестали пользоваться продуктом. Обратная сторона retention.
Типовые вопросы:
- Какие продуктовые метрики знаете? — Не надо перечислять всё, что вы когда-либо слышали. Лучше назовите 5–7 ключевых метрик и покажите понимание, когда какую использовать.
- Как выбрать правильную метрику для оценки маркетинговой кампании? — Зависит от цели кампании. Если цель — привлечение новых пользователей, смотрим на CAC (Customer Acquisition Cost) и конверсию. Если цель — удержание, то на retention и повторные покупки.
- Какие дашборды строили? Какими инструментами пользуетесь? — Tableau, Power BI, DataLens, Metabase, Redash — всё зависит от компании. Главное — показать, что вы понимаете разницу между дашбордом для ежедневного мониторинга и отчётом для презентации топ-менеджменту.
BI-инструменты и их особенности:
- Tableau — мощный и гибкий, но дорогой и с крутой кривой обучения.
- Power BI — интеграция с экосистемой Microsoft, популярен в крупных корпорациях.
- DataLens — российский продукт от Яндекса, бесплатный и простой для старта.
- Metabase — опенсорс, лёгкий в освоении, подходит для небольших команд.
Пример вопроса:
«Retention упал на 15% за последний месяц. Ваши действия?» — Здесь проверяют не столько знание метрик, сколько способность структурировать анализ: сегментировать пользователей, проверить изменения в продукте, посмотреть на когорты, сравнить с предыдущими периодами.
Совет:
Перед собеседованием зайдите на сайт компании, попробуйте их продукт и подумайте, какие метрики там могут быть важны. Если это e-commerce — готовьте ответы про конверсию и средний чек. Если SaaS — про retention и MRR (Monthly Recurring Revenue). Это покажет, что вы не просто учили определения, а думали о специфике бизнеса.
Продуктовые задачи и кейсы
Продуктовые задачи — это та часть собеседования, где проверяют не ваши знания синтаксиса или формул, a способность думать. Здесь нет единственно правильного ответа, и это пугает джунов больше всего. Работодатели специально подкидывают кейсы с противоречиями, аномалиями или недостающими данными, чтобы посмотреть, как вы рассуждаете, какие вопросы задаёте и насколько структурированно подходите к анализу.
Цель таких задач — не услышать от вас волшебное решение (его может и не быть), а увидеть логику вашего мышления. Можете ли вы сформулировать гипотезы? Понимаете ли, какие данные нужно запросить для проверки? Умеете ли вы отсекать маловероятные варианты и фокусироваться на реалистичных?
Классический пример задачи на противоречивые метрики:
Вы анализируете воронку регистрации пользователей в мобильном приложении:
📥 Установка приложения — 10 000 пользователей
👋 Первый вход в приложение — 9 500 пользователей
✅ Регистрация аккаунта — 12 000 пользователей
Вопрос:
Что может объяснить ситуацию, при которой на финальном шаге воронки оказывается больше пользователей, чем на предыдущих?
Как рассуждать:
Первое, что приходит в голову — ошибка в данных или логике сбора событий. Но давайте копнём глубже и сформулируем несколько гипотез:
- Множественная регистрация с одного устройства — один пользователь мог создать несколько аккаунтов (например, тестировал функционал или создавал фейковые профили).
- Веб-версия или десктоп — возможно, регистрация доступна не только через мобильное приложение, но и через сайт. Тогда часть пользователей регистрируется там, не устанавливая приложение.
- Переустановка приложения — пользователь установил приложение, удалил его, потом установил снова. Событие «Установка» учитывается один раз (по уникальному ID устройства), а «Регистрация» может быть новой.
- Проблемы с атрибуцией событий — события «Установка» и «Регистрация» могут отслеживаться разными системами аналитики (например, AppsFlyer для установок и внутренняя аналитика для регистраций), и где-то происходит рассинхронизация.
- Временной лаг — данные собираются за разные периоды или с задержкой. Например, установки считаются по дате загрузки, а регистрации — по дате завершения процесса, который мог растянуться на несколько дней.
Какие вопросы нужно задать:
- Доступна ли регистрация через другие каналы (веб, десктоп)?
- Как именно считается событие «Установка» — по первому запуску или по загрузке из store?
- Есть ли дедупликация пользователей по device_id или user_id?
- Какой временной период анализируется и совпадает ли он для всех этапов воронки?
- Могут ли пользователи создавать несколько аккаунтов?
Второй пример кейса — падение метрики:
«Конверсия в покупку упала на 20% за неделю. Что будете делать?»
Структура рассуждений:
- Проверить, не было ли технических проблем (сломалась кнопка оплаты, упал платёжный шлюз).
- Посмотреть на сегменты — может, упала конверсия только у определённой группы пользователей (новые/старые, iOS/Android, конкретные регионы).
- Сравнить с предыдущими периодами — может, это сезонность или эффект внешних факторов (праздники, конкуренты запустили акцию).
- Проверить изменения в продукте — может, на прошлой неделе был релиз, который сломал пользовательский опыт.
- Посмотреть на воронку целиком — может, конверсия упала не на этапе покупки, а раньше, и к корзине просто доходит меньше людей.
Совет:
В продуктовых задачах главное — не молчать и не пытаться сразу выдать идеальный ответ. Думайте вслух, формулируйте гипотезы, задавайте уточняющие вопросы. Интервьюер хочет видеть процесс вашего мышления, а не финальную цифру. И помните: фраза «Мне нужно больше данных, чтобы ответить точно» — это не слабость, а признак зрелого аналитика.
Поведение на собеседовании и советы от экспертов
Техническая подготовка — это только половина успеха. Вторая половина — это то, как вы себя ведёте на самом собеседовании. Можно знать SQL на уровне senior-разработчика, но провалиться из-за того, что вы не смогли внятно объяснить свой подход или начали нервничать и путаться в простых вещах. Собеседование — это не экзамен, где нужно вызубрить правильные ответы. Это диалог, в котором работодатель пытается понять, сможете ли вы решать их задачи и работать в их команде.
Давайте разберём три ключевых этапа: что делать до собеседования, как вести себя во время интервью и что важно сделать после него.

На иллюстрации изображена сцена собеседования: кандидат общается с интервьюерами в спокойной офисной обстановке. Такая визуализация помогает читателю представить реальную атмосферу интервью аналитика данных и лучше понять контекст обсуждаемой темы.
До собеседования: подготовка решает всё
Изучите компанию и продукт.
Это кажется очевидным, но многие кандидаты приходят на собеседование, не потратив даже 15 минут на то, чтобы зайти на сайт компании или скачать их приложение. А потом удивляются, когда их спрашивают: «Какие метрики, по вашему мнению, важны для нашего продукта?» — и они не могут сказать ничего конкретного. Зарегистрируйтесь в их сервисе, пощёлкайте интерфейс, почитайте отзывы — это даст вам контекст и покажет интервьюеру, что вы не просто ищете любую работу, а заинтересованы именно в этой позиции.
Подготовьте вопросы.
Собеседование — это дорога с двусторонним движением. Вы тоже выбираете компанию, а не только вас выбирают. Подготовьте 3–5 вопросов о команде, процессах, инструментах, задачах. Например: «Какие инструменты аналитики используются в команде?», «Как строится взаимодействие аналитиков с продуктовыми менеджерами?», «Какие задачи будут приоритетными в первые месяцы работы?». Отсутствие вопросов с вашей стороны может выглядеть как незаинтересованность.
Повторите базу.
Освежите в памяти ключевые темы: SQL (особенно JOIN-ы и оконные функции), основные метрики, работу с Pandas (если Python в требованиях). Не пытайтесь за день до собеседования выучить всё с нуля — лучше сосредоточьтесь на том, что уже знаете, и уберите пробелы в базовых вещах.
Во время собеседования: честность и структура
Будьте честными.
Если не знаете ответа на вопрос — так и скажите. Фраза «Я не работал с этим инструментом, но готов быстро разобраться» звучит гораздо лучше, чем попытка придумать что-то на ходу и запутаться в собственных словах. Интервьюеры чувствуют блеф, и это моментально снижает доверие к вам.
Структурируйте свои ответы.
Особенно это касается продуктовых задач и кейсов. Не начинайте сразу выдавать решение — сначала уточните условия, задайте вопросы, сформулируйте гипотезы, объясните логику. Например: «Сначала я бы проверил, нет ли технических проблем. Затем посмотрел на сегментацию пользователей. После этого сравнил бы с историческими данными». Это показывает системность мышления.
Не проваливайтесь в детали без необходимости.
Если вас спрашивают про общий подход, не надо сразу писать код на 50 строк или погружаться в нюансы конкретной библиотеки. Дайте сначала высокоуровневый ответ, а уже потом, если попросят, углубляйтесь в детали. Умение объяснять сложное простым языком — один из ключевых навыков аналитика.
Думайте вслух.
В технических задачах и кейсах интервьюер хочет видеть процесс вашего мышления. Даже если вы не уверены в ответе, озвучивайте свои мысли: «Мне кажется, здесь можно использовать LEFT JOIN, потому что нам нужны все записи из первой таблицы, даже если во второй нет совпадений». Это даёт интервьюеру возможность направить вас, если вы идёте не туда, и показывает вашу способность рассуждать логически.
После собеседования: работа над ошибками
- Запросите обратную связь. Даже если вам отказали, попросите фидбек — что было хорошо, а где вы споткнулись. Не все компании дают развёрнутую обратную связь, но попытаться стоит. Это поможет вам подготовиться к следующим собеседованиям.
- Проанализируйте свои ошибки. Сразу после интервью запишите, какие вопросы вызвали у вас сложности, где вы не смогли ответить или ответили невнятно. Это ваш личный список тем для проработки перед следующим собеседованием.
- Не зацикливайтесь на неудачах. Провалить несколько собеседований — это нормально. Даже опытные специалисты иногда не проходят, потому что не подошли по культуре компании или просто не повезло с интервьюером. Главное — извлекать уроки и идти дальше.
Что делать, если вы начинающий аналитик без опыта
Отсутствие опыта — это не приговор, а просто стартовая точка, с которой начинали абсолютно все (включая тех, кто сейчас сидит напротив вас на собеседовании и задаёт каверзные вопросы про оконные функции). Работодатели понимают, что джуниор — это человек, который ещё не работал в продакшене, но они хотят видеть, что вы способны учиться, что у вас есть базовые навыки и — самое главное — что вы реально хотите работать аналитиком, а не просто ищете любую работу в IT.
Как компенсировать отсутствие опыта
Учебные проекты — ваше главное оружие.
Если вы прошли курсы или учились самостоятельно, у вас наверняка есть несколько проектов: анализ данных интернет-магазина, прогноз оттока клиентов, исследование поведения пользователей. Не стесняйтесь выкладывать их на GitHub или в портфолио и рассказывать о них так, как будто это были реальные рабочие задачи. Работодателю важно увидеть, что вы умеете применять знания на практике, а не просто решали тестовые задачки из учебника.
Kaggle и другие платформы для практики.
Соревнования на Kaggle, задачи на LeetCode (для SQL), хакатоны — всё это можно (и нужно) упоминать как опыт. Особенно если вы заняли какое-то место в соревновании или получили высокий рейтинг. Это показывает, что вы не просто учились, а проверяли свои навыки в конкурентной среде.
Стажировки и волонтёрские проекты.
Даже неоплачиваемая стажировка или работа над открытым проектом даёт вам реальный опыт взаимодействия с данными, командой и бизнес-задачами. Если есть возможность — берите любую стажировку, где вы будете работать с данными. Три месяца реального опыта стоят больше, чем год теоретического обучения.
Личные pet-проекты.
Проанализировали данные своих расходов за год и построили дашборд? Собрали данные о квартирах в вашем городе и посчитали, как цена зависит от района? Отлично — это тоже опыт, и о нём можно рассказать на собеседовании. Главное — покажите, что вы применяете аналитику не только в учебных задачах, но и в реальной жизни.
Как говорить о смене профессии
Если вы пришли в аналитику из другой сферы (бухгалтерия, маркетинг, преподавание, продажи) — это не минус, а часто даже плюс. У вас уже есть опыт работы в какой-то индустрии, и это может стать вашим преимуществом. Например, бывший маркетолог лучше понимает метрики привлечения и удержания клиентов, а бывший бухгалтер привык к работе с большими массивами данных и вниманию к деталям.
На собеседовании объясните, почему вы решили сменить профессию, но не делайте акцент на том, что «старая работа надоела» или «хочу больше зарабатывать». Лучше скажите, что вас всегда интересовала работа с данными, вы начали изучать тему самостоятельно, поняли, что это ваше, и теперь готовы развиваться в этом направлении. Покажите, что переход был осознанным, а не спонтанным решением.
Как представить учебный проект как реальный кейс
Вот пример, как можно рассказать о своём учебном проекте так, чтобы он звучал убедительно:
Плохой вариант:
«Я делал учебный проект по анализу данных интернет-магазина. Там были таблицы с заказами и клиентами. Я посчитал среднюю выручку и построил графики».
Хороший вариант:
«Я анализировал данные интернет-магазина, чтобы понять, какие категории товаров приносят больше всего выручки и как меняется поведение клиентов в зависимости от сезонности. Для этого я написал SQL-запросы для агрегации данных по категориям и периодам, использовал Python (Pandas) для расчёта RFM-сегментации клиентов и построил дашборд в Tableau, чтобы визуализировать динамику продаж. В результате выявил, что 20% клиентов приносят 60% выручки, и предложил гипотезу о внедрении программы лояльности для этой группы».
Видите разницу? Второй вариант показывает не просто факт выполнения проекта, а структуру мышления, используемые инструменты и конкретные выводы. Именно так нужно презентовать свои учебные кейсы — как реальные аналитические задачи с гипотезами, инсайтами и рекомендациями.
Рекомендации для начинающих
- Не врите про опыт, но и не принижайте то, что у вас есть. Учебный проект — это тоже проект.
- Будьте готовы показать код или дашборд. Если говорите, что делали анализ на Python — держите ссылку на GitHub под рукой.
- Подчёркивайте желание учиться. Фраза «Я быстро разбираюсь в новых инструментах» должна подкрепляться примерами — расскажите, как за неделю освоили новую библиотеку или разобрались в незнакомой базе данных.
- Не бойтесь позиций стажёра или junior. Лучше начать с низкой позиции и вырасти, чем годами ждать идеальной вакансии с завышенными требованиями.
15 типовых вопросов работодателей аналитикам данных
Теперь соберём всё вместе — вот список из пятнадцати вопросов, которые чаще всего встречаются на собеседованиях для начинающих аналитиков данных. Это выжимка из всех тематических блоков, которые мы разобрали выше. Держите этот список под рукой при подготовке — если вы уверенно отвечаете на эти вопросы, значит, базовая подготовка у вас в порядке.
- Что такое оконные функции в SQL и для чего они используются?
Оконные функции (ROW_NUMBER, RANK, LAG, LEAD, SUM OVER) позволяют выполнять вычисления по группам строк без агрегации всей таблицы. Используются для расчёта скользящих средних, ранжирования, поиска предыдущих/следующих значений. - В каком порядке выполняется SQL-запрос?
Не в том порядке, в котором мы его пишем. Реальный порядок: FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY → LIMIT. Это важно понимать для правильной фильтрации и агрегации данных. - Какие типы JOIN-ов вы знаете?
INNER JOIN (пересечение), LEFT JOIN (все из левой таблицы), RIGHT JOIN (все из правой), FULL OUTER JOIN (все из обеих таблиц), CROSS JOIN (декартово произведение), SELF JOIN (соединение таблицы с самой собой). - В чём разница между WHERE и HAVING?
WHERE фильтрует строки до агрегации, HAVING — после. Например, WHERE используется для отбора конкретных пользователей, а HAVING — для фильтрации групп после GROUP BY. - Как работает метод fillna() в Pandas?
Заполняет пропущенные значения (NaN) в DataFrame. Можно заполнить конкретным значением, средним, медианой или использовать метод forward fill / backward fill для заполнения предыдущими/следующими значениями. - Чем отличаются Series и DataFrame в Pandas?
Series — это одномерная структура данных (по сути, столбец). DataFrame — двумерная структура (таблица с несколькими столбцами). DataFrame можно представить как коллекцию Series. - Что такое p-value и что означает p-value < 0.05?
P-value — это вероятность получить наблюдаемый результат при условии, что нулевая гипотеза верна. Значение меньше 0.05 означает статистическую значимость результата с уровнем достоверности 95% (но это просто договорённость, а не абсолютная истина). - Назовите меры центральной тенденции.
Среднее (mean), медиана (median), мода (mode). Среднее чувствительно к выбросам, медиана — нет, поэтому для данных с аномалиями лучше использовать медиану. - Что такое доверительный интервал?
Диапазон значений, в котором с заданной вероятностью (обычно 95%) находится истинное значение параметра. Например, средний чек 1000 ± 50 рублей с 95% доверительным интервалом. - Какие продуктовые метрики вы знаете?
DAU/MAU (активные пользователи), Retention (возврат пользователей), ARPU (средняя выручка на пользователя), Conversion (конверсия в целевое действие), LTV (пожизненная ценность клиента), Churn Rate (отток пользователей). - Как вы выберете метрику для оценки эффективности маркетинговой кампании?
Зависит от цели кампании. Для привлечения — CAC (стоимость привлечения) и конверсия в регистрацию. Для удержания — retention и повторные покупки. Для монетизации — ARPU и LTV. - Что такое retention и как его считать?
Retention — это процент пользователей, которые вернулись в продукт через определённое время после первого использования. Считается как (пользователи, вернувшиеся на N-й день) / (пользователи, пришедшие в день 0) × 100%. - Какие библиотеки Python вы используете для анализа данных?
Pandas (работа с таблицами), NumPy (математические операции), Matplotlib и Seaborn (визуализация), SciPy (статистика), иногда Plotly (интерактивная визуализация). - С какими форматами данных вам приходилось работать?
CSV (самый частый), JSON (для API и логов), XLSX (Excel-файлы), TXT (текстовые логи), иногда Parquet (для больших объёмов данных) и XML. - Конверсия в покупку упала на 20%. Ваши действия?
Сначала проверю технические проблемы (не сломался ли функционал). Затем посмотрю на сегментацию — может, упала только у определённой группы пользователей. Сравню с предыдущими периодами (сезонность?). Проверю изменения в продукте и воронку целиком. Задам вопросы команде — были ли релизы, изменения в маркетинге, внешние факторы.
Как готовиться к собеседованию аналитика данных: чек-лист
Подготовка к собеседованию — это не магия и не удача. Это систематическая работа над конкретными блоками знаний и навыков. Вот чек-лист, который поможет вам структурировать процесс подготовки и ничего не упустить. Распечатайте его, повесьте на стену или сохраните в заметках — и методично отмечайте пункты по мере выполнения.
Технические навыки
☐ Повторить SQL: JOIN-ы всех типов, подзапросы, оконные функции, агрегации, порядок выполнения запроса
☐ Прорешать 10–15 задач на SQL на платформах типа LeetCode, HackerRank или SQLZoo
☐ Освежить Python (если требуется): Pandas (фильтрация, группировка, объединение таблиц), работа с пропусками, базовая визуализация
☐ Повторить основы статистики: p-value, доверительные интервалы, меры центральной тенденции, A/B-тесты
☐ Вспомнить функции Excel: ВПР, сводные таблицы, базовые формулы
Продуктовые знания
☐ Изучить компанию и продукт: зарегистрироваться, протестировать основной функционал, почитать отзывы
☐ Определить ключевые метрики для этого типа продукта (e-commerce, SaaS, медиа, fintech — у каждого свои приоритеты)
☐ Подумать над возможными задачами: какие вопросы может решать аналитик в этой компании
☐ Подготовить 3–5 вопросов для работодателя о команде, процессах, инструментах и задачах
Портфолио и кейсы
☐ Подготовить 2–3 проекта для рассказа: учебные, pet-проекты, Kaggle — главное, чтобы вы могли объяснить задачу, подход и результаты
☐ Выложить код на GitHub (если есть) и держать ссылки под рукой
☐ Потренироваться рассказывать о проектах вслух — структурно, без лишних деталей, с акцентом на бизнес-ценность
☐ Придумать ответ на вопрос «Почему вы хотите работать аналитиком?» — искренний, но профессиональный
Техническая подготовка к интервью
☐ Проверить оборудование для онлайн-интервью: микрофон, камеру, интернет, тихое место без отвлекающих факторов
☐ Установить необходимые программы (Zoom, Teams, Skype — что используют в компании)
☐ Приготовить ручку и бумагу для записей во время интервью (или открыть блокнот на компьютере)
☐ Положить рядом воду — нервничать на собеседовании нормально, сухость во рту тоже
Психологическая подготовка
☐ Выспаться накануне — это звучит банально, но усталость убивает вашу способность ясно мыслить
☐ Повторить основные темы за день до собеседования, но не пытаться выучить что-то новое в последний момент
☐ Напомнить себе, что собеседование — это диалог, а не экзамен, и вы тоже выбираете компанию
☐ Подготовиться к отказу морально — даже если не получится с первого раза, это опыт и возможность понять, над чем работать
После собеседования
☐ Записать вопросы, которые вызвали затруднения, сразу после интервью, пока всё свежо в памяти
☐ Запросить обратную связь у рекрутера или интервьюера (даже если получили отказ)
☐ Проанализировать свои ошибки и добавить их в список тем для изучения перед следующим собеседованием
☐ Не зацикливаться на неудачах — провал на одном собеседовании не делает вас плохим специалистом
Заключение
Собеседование на позицию аналитика данных — это проверка не только ваших технических знаний, но и способности думать, задавать правильные вопросы и объяснять сложные вещи простым языком. Работодатели понимают, что джуниор не будет идеальным специалистом с первого дня, но они хотят видеть потенциал, желание учиться и базовое понимание того, как работает аналитика в реальных условиях (а не только в учебных задачках). Подведем итоги:
- Подготовка по SQL обязательна. Работодатели оценивают умение применять JOIN-ы, оконные функции и писать оптимальные запросы.
- Знание Python усиливает кандидата. Особенно важны навыки работы с Pandas и обработки данных.
- Статистика помогает отличать случайность от закономерности. Базовые понятия, вроде p-value и доверительных интервалов, делают ответы уверенными.
- Понимание продуктовых метрик показывает зрелое аналитическое мышление. Это помогает объяснять причины изменений в данных и формулировать гипотезы.
- Практические кейсы раскрывают ход мысли кандидата. Интервьюеры оценивают не факты, а логику и структурность рассуждений.
- Поведение на собеседовании не менее важно. Честность, ясность формулировок и умение задавать уточняющие вопросы повышают шансы на успех.
- Даже без опыта можно пройти интервью. Учебные проекты, пет-кейсы и участие в соревнованиях создают рабочее портфолио.
Рекомендуем обратить внимание на подборку курсов по системной аналитике, особенно если вы только начинаете осваивать профессию. В них есть и теоретическая, и практическая часть, которая помогает быстрее понять логику реальной работы. Такой формат позволяет уверенно подготовиться к вопросам собеседования и собрать первое портфолио.
Рекомендуем посмотреть курсы по системной аналитике
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Аналитик данных
|
Eduson Academy
114 отзывов
|
Цена
109 900 ₽
|
От
9 158 ₽/мес
Беспроцентная. На 1 год.
|
Длительность
6 месяцев
|
Старт
31 марта
|
Подробнее |
|
Системный аналитик PRO
|
Нетология
46 отзывов
|
Цена
79 800 ₽
140 000 ₽
с промокодом kursy-online
|
От
3 500 ₽/мес
Рассрочка на 2 года.
|
Длительность
10 месяцев
|
Старт
13 апреля
|
Подробнее |
|
Системный аналитик с нуля
|
Stepik
33 отзыва
|
Цена
4 500 ₽
|
|
Длительность
1 неделя
|
Старт
в любое время
|
Подробнее |
|
Системный аналитик с нуля до PRO
|
Eduson Academy
114 отзывов
|
Цена
109 900 ₽
257 760 ₽
Ещё -12% по промокоду
|
От
4 579 ₽/мес
10 740 ₽/мес
|
Длительность
6 месяцев
|
Старт
в любое время
|
Подробнее |

Яндекс Практикум vs Bang Bang Education: сравниваем методологию и упаковку кейсов для UX-исследователей
UX-исследования — с чего начать и какой курс выбрать? Разбираем методологию, формат обучения и портфолио, чтобы вы не ошиблись с выбором.

Яндекс Практикум vs Stepik: SQL с нуля — что быстрее даёт навык «решать задачи», а не «знать команды»
Stepik или Яндекс Практикум — где быстрее освоить SQL-аналитику и научиться решать реальные задачи? Разбираем формат обучения, типы практики и ключевые различия платформ, которые влияют на скорость роста навыка.

Яндекс Практикум vs Karpov.Courses: A/B — где понятнее, а где глубже и строже
Выбор между курсами по A/B тестированию от Яндекс Практикум и Karpov может быть непростым. Узнайте, какой из них лучше соответствует вашим целям и ожиданиям. В статье мы детально разберем их особенности, включая теоретическую и практическую части курсов, чтобы помочь вам сделать правильный выбор!

Яндекс Практикум vs GeekBrains: фронтенд — где лучше база и где быстрее выход на первые проекты
Ищете лучший курс по фронтенду, но не знаете, какой выбрать? В нашей статье вы найдете подробное сравнение программ Яндекс Практикума и GeekBrains — прочитайте и выберите подходящий курс для своего старта!