Агрегатные функции в SQL: что это, зачем нужны и как использовать
В мире баз данных агрегатные функции играют роль мощного аналитического инструмента, который позволяет нам извлекать ценную информацию из массивов данных.

По своей сути, агрегатные функции — это специальные операторы, которые обрабатывают группу строк в таблице и возвращают единое обобщенное значение.
- Что такое агрегатные функции и зачем они нужны
- Основные агрегатные функции SQL
- Расширенные агрегатные функции
- Как работают агрегатные функции с NULL
- Модификаторы DISTINCT и ALL
- Группировка данных: GROUP BY
- Фильтрация по агрегатам: оператор HAVING
- Частые ошибки и как их избежать
- Примеры запросов с агрегатными функциями
- Заключение
- Рекомендуем посмотреть курсы по SQL
Что такое агрегатные функции и зачем они нужны
Чем же они принципиально отличаются от обычных скалярных функций? Если скалярная функция работает по принципу «один к одному» — берет одно значение и возвращает одно значение (например, функция ABS(), которая возвращает абсолютное значение числа), то агрегатные функции работают по принципу «многие к одному». Они могут обработать ноль, одну или множество строк и в результате вернуть единственное значение.
Агрегатные функции обладают важными характеристиками: они детерминированы (одинаковые данные всегда дают одинаковый результат) и в большинстве случаев игнорируют NULL-значения. Эти свойства делают их надежным инструментом для создания отчетов, построения аналитических дашбордов и вычисления описательной статистики.
В современном мире data-driven решений агрегатные функции становятся незаменимым инструментом для бизнес-аналитиков, продуктовых менеджеров и всех, кто работает с большими объемами данных. Они позволяют быстро получить ответы на вопросы вроде «Сколько у нас клиентов?», «Какова средняя сумма заказа?» или «Кто наш самый активный пользователь?».
Основные агрегатные функции SQL
Рассмотрим пять фундаментальных агрегатных функций, которые составляют основу аналитической работы с данными. Каждая из них решает определенный класс задач и имеет свои особенности применения.
COUNT
Функция COUNT — это, пожалуй, самая универсальная из агрегатных функций. Она подсчитывает количество строк в выборке, но имеет несколько важных вариантов использования.
-- Подсчет всех строк в таблице SELECT COUNT(*) FROM employees; -- Подсчет строк с непустыми значениями в конкретном столбце SELECT COUNT(salary) FROM employees; -- Подсчет уникальных значений SELECT COUNT(DISTINCT department) FROM employees;
Особенность COUNT(*) заключается в том, что она учитывает абсолютно все строки, включая те, где все поля содержат NULL. В то время как COUNT(column_name) игнорирует строки с NULL-значениями в указанном столбце.
SUM
Функция SUM вычисляет сумму всех числовых значений в столбце. Важно помнить, что она работает исключительно с числовыми типами данных и автоматически игнорирует NULL-значения.
-- Общая сумма зарплат всех сотрудников SELECT SUM(salary) FROM employees; -- Сумма продаж по конкретному региону SELECT SUM(amount) FROM sales WHERE region = 'North';
AVG
Функция AVG рассчитывает среднее арифметическое значений в столбце. При этом NULL-значения исключаются из расчета — как из числителя, так и из знаменателя.
-- Средняя зарплата сотрудников SELECT AVG(salary) FROM employees; -- Если в столбце salary есть NULL, они не участвуют в расчете -- Например: (1000 + 2000 + 3000) / 3, а не / 4, если четвертое значение NULL
MIN и MAX
Функции MIN и MAX находят соответственно минимальное и максимальное значения в столбце. Интересная особенность этих функций — они работают не только с числами, но и со строками (сортировка по алфавиту) и датами.
-- Минимальная и максимальная зарплата SELECT MIN(salary), MAX(salary) FROM employees; -- Первый и последний сотрудник по алфавиту SELECT MIN(employee_name), MAX(employee_name) FROM employees; -- Самая ранняя и самая поздняя дата найма SELECT MIN(hire_date), MAX(hire_date) FROM employees;
Все эти функции образуют основу для более сложных аналитических запросов и часто комбинируются с операторами GROUP BY и HAVING для создания детализированных отчетов по различным группам данных.
Расширенные агрегатные функции
Помимо базовых агрегатных функций, SQL предлагает ряд специализированных инструментов, которые решают более узкие, но важные задачи. Эти функции особенно востребованы при работе с большими объемами данных и в сценариях, где производительность играет критическую роль.
APPROX_COUNT_DISTINCT
В эпоху больших данных точный подсчет уникальных значений может стать узким местом производительности. Функция APPROX_COUNT_DISTINCT предлагает компромиссное решение — она возвращает приблизительное количество уникальных значений, используя значительно меньше памяти.
-- Приблизительное количество уникальных клиентов SELECT APPROX_COUNT_DISTINCT(customer_id) AS approx_customers FROM orders;
Эта функция особенно эффективна для таблиц с миллионами строк, где точность в 95-99% вполне приемлема, а выигрыш в производительности существенен.
COUNT_BIG
Когда обычная функция COUNT достигает своих пределов (максимальное значение INT), на помощь приходит COUNT_BIG. Она возвращает значение типа BIGINT, что позволяет работать с таблицами, содержащими миллиарды строк.
-- Подсчет строк в очень больших таблицах SELECT COUNT_BIG(*) AS total_rows FROM large_transaction_table;
CHECKSUM_AGG
Функция CHECKSUM_AGG вычисляет контрольную сумму для набора значений — полезный инструмент для быстрого сравнения выборок данных или обнаружения изменений.
-- Контрольная сумма для проверки целостности данных SELECT CHECKSUM_AGG(salary) AS salary_checksum FROM employees;
Если данные в таблице изменились, контрольная сумма тоже изменится, что позволяет быстро обнаружить модификации без построчного сравнения.
GROUPING
Функция GROUPING используется совместно с операторами ROLLUP и CUBE для определения того, является ли строка результирующего набора агрегированной. Она возвращает 1, если строка представляет итоговое значение, и 0 — если это обычная группировка.
-- Использование с ROLLUP для создания промежуточных итогов SELECT department, SUM(salary) as total_salary, GROUPING(department) as is_total FROM employees GROUP BY ROLLUP(department);
Эти расширенные функции демонстрируют гибкость SQL как аналитического инструмента, способного адаптироваться к различным требованиям производительности и сложности данных.
Как работают агрегатные функции с NULL
Работа с NULL-значениями — один из наиболее важных аспектов использования агрегатных функций, который часто становится источником неожиданных результатов для начинающих разработчиков. Понимание этих принципов критически важно для корректной интерпретации результатов аналитических запросов.
Большинство агрегатных функций следуют простому правилу: они игнорируют NULL-значения при вычислениях. Однако есть важное исключение — функция COUNT(*), которая подсчитывает все строки независимо от содержимого.COUNT vs NULL
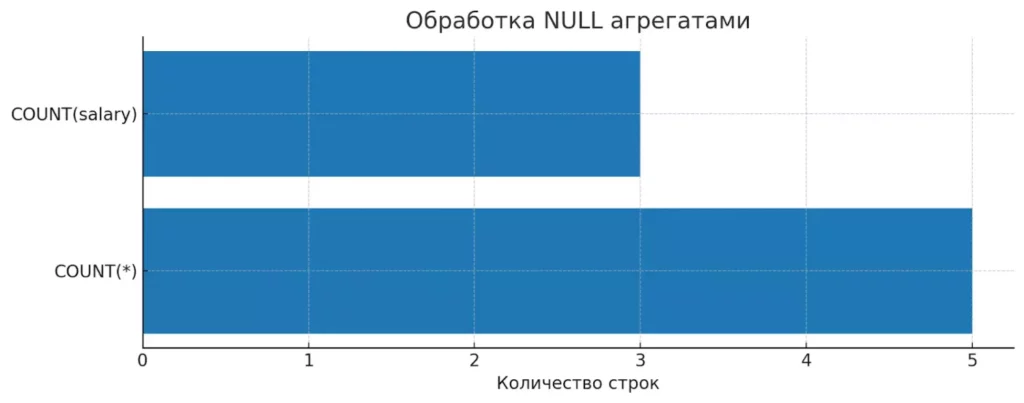
Сравнение COUNT(*) и COUNT(salary) показывает, как NULL влияет на результаты. COUNT(*) учитывает все строки, а COUNT(column) игнорирует NULL-значения.
Рассмотрим практический пример с таблицей сотрудников:
-- Таблица employees с NULL-значениями в столбце salary | name | department | salary | |---------|------------|--------| | Alice | IT | 5000 | | Bob | IT | NULL | | Carol | HR | 4000 | | David | HR | NULL | | Eve | IT | 6000 |
Теперь посмотрим, как различные функции обрабатывают эти данные:
SELECT COUNT(*) as total_employees, -- Результат: 5 COUNT(salary) as employees_with_salary, -- Результат: 3 SUM(salary) as total_salary, -- Результат: 15000 AVG(salary) as average_salary -- Результат: 5000 FROM employees;
Обратите внимание на ключевой момент: функция AVG вычисляет среднее как (5000 + 4000 + 6000) / 3 = 5000, а не как 15000 / 5 = 3000. NULL-значения исключаются как из суммы, так и из количества элементов для усреднения.
Эта особенность может привести к неожиданным результатам в аналитических отчетах. Например, если мы хотим рассчитать среднюю зарплату с учетом сотрудников без указанной зарплаты как «нулевую», нам потребуется использовать функцию COALESCE или ISNULL для замены NULL на 0 перед применением агрегатной функции.
Понимание этого поведения особенно важно при работе с неполными наборами данных, что часто встречается в реальных бизнес-сценариях.
Модификаторы DISTINCT и ALL
Модификаторы DISTINCT и ALL предоставляют нам дополнительный контроль над тем, как агрегатные функции обрабатывают дубликаты в данных. Эти инструменты особенно важны в сценариях, где точность подсчета уникальных значений критична для бизнес-логики.SUM с DISTINCT
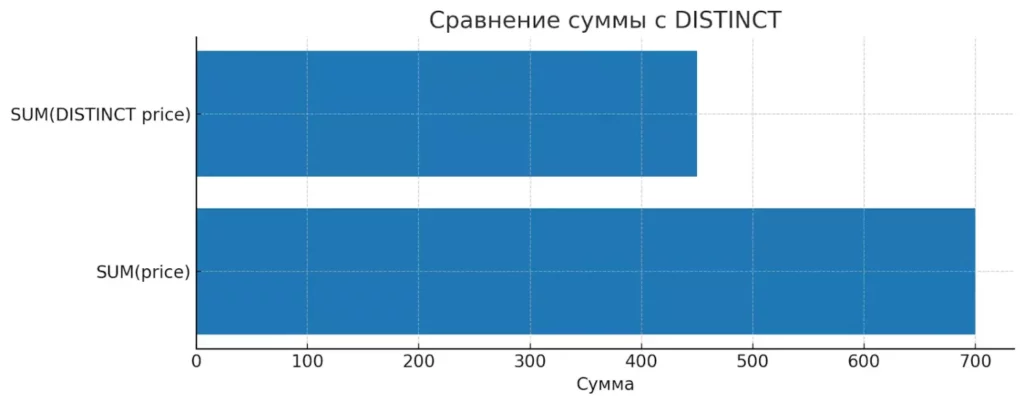
SUM(price) складывает все значения, включая повторы. SUM(DISTINCT price) — только уникальные. Отличие в 250 демонстрирует влияние дубликатов на расчёты.
Модификатор ALL является значением по умолчанию и включает в обработку все значения, включая дубликаты. Модификатор DISTINCT, напротив, исключает повторяющиеся значения перед применением агрегатной функции.
-- Подсчет всех заказов (включая дубликаты по сумме) SELECT COUNT(ALL order_amount) FROM orders; -- Подсчет уникальных сумм заказов SELECT COUNT(DISTINCT order_amount) FROM orders; -- Сумма всех заказов SELECT SUM(ALL order_amount) FROM orders; -- Сумма уникальных сумм заказов (исключая дубликаты) SELECT SUM(DISTINCT order_amount) FROM orders;
Рассмотрим практический пример с таблицей продаж:
| product_id | price | |------------|-------| | 1 | 100 | | 2 | 150 | | 3 | 100 | | 4 | 200 | | 5 | 150 |
В этом случае SUM(price) вернет 700, а SUM(DISTINCT price) — только 450 (100 + 150 + 200), поскольку дубликаты исключаются из расчета.
Модификатор DISTINCT особенно полезен при анализе уникальных характеристик данных — например, при подсчете количества различных городов, в которых проживают клиенты, или определении диапазона цен на товары без учета повторений.
Группировка данных: GROUP BY
Истинная мощь агрегатных функций раскрывается при их использовании совместно с оператором GROUP BY. Этот оператор позволяет разделить данные на группы по определенным критериям и применить агрегатные функции к каждой группе отдельно.
Прежде чем углубиться в механизм группировки, важно отметить: агрегатные функции прекрасно работают и без оператора GROUP BY, обрабатывая всю таблицу как единую группу. Например, запрос SELECT COUNT(*) FROM employees подсчитает общее количество сотрудников, а SELECT AVG(salary) FROM employees — среднюю зарплату по всей компании.
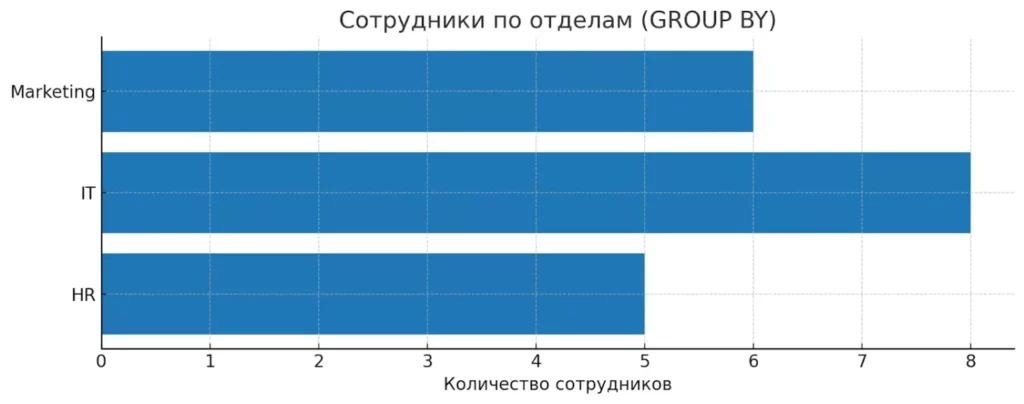
Пример использования GROUP BY для подсчета сотрудников в разных отделах. Каждая группа — отдельная «папка» для анализа агрегатными функциями.
Однако истинная мощь агрегатных функций раскрывается при их использовании совместно с оператором GROUP BY. Этот оператор позволяет разделить данные на группы по определенным критериям и применить агрегатные функции к каждой группе отдельно.
GROUP BY также открывает возможности для создания сложных аналитических отчетов, таких как анализ трендов продаж по месяцам, сравнение производительности различных подразделений или выявление наиболее популярных товарных категорий.
Принцип работы GROUP BY можно сравнить с сортировкой документов по папкам: мы группируем строки с одинаковыми значениями в указанных столбцах, а затем для каждой «папки» вычисляем агрегированные показатели.
-- Количество сотрудников по отделам SELECT department, COUNT(*) as employee_count FROM employees GROUP BY department; -- Средняя зарплата по отделам SELECT department, AVG(salary) as avg_salary FROM employees GROUP BY department;
Рассмотрим более сложный пример с таблицей продаж:
| product_id | category | region | amount | |------------|----------|--------|--------| | 1 | Electronics | North | 1000 | | 2 | Clothing | South | 500 | | 3 | Electronics | North | 1500 | | 4 | Clothing | North | 300 | | 5 | Electronics | South | 800 |
Мы можем группировать данные по нескольким столбцам одновременно:
-- Продажи по категориям и регионам SELECT category, region, COUNT(*) as sales_count, SUM(amount) as total_sales, AVG(amount) as avg_sale FROM sales GROUP BY category, region ORDER BY category, region;
Результат покажет агрегированные данные для каждой уникальной комбинации категории и региона.
Важное правило при использовании GROUP BY: все столбцы в SELECT, которые не являются агрегатными функциями, должны присутствовать в GROUP BY. Это логично — мы не можем выбрать конкретное значение из группы строк без агрегации.
Принцип работы GROUP BY можно сравнить с сортировкой документов по папкам: мы группируем строки с одинаковыми значениями в указанных столбцах, а затем для каждой «папки» вычисляем агрегированные показатели.
-- Количество сотрудников по отделам SELECT department, COUNT(*) as employee_count FROM employees GROUP BY department; -- Средняя зарплата по отделам SELECT department, AVG(salary) as avg_salary FROM employees GROUP BY department;
Рассмотрим более сложный пример с таблицей продаж:
| product_id | category | region | amount |
| 1 | Electronics | North | 1000 |
| 2 | Clothing | South | 500 |
| 3 | Electronics | North | 1500 |
| 4 | Clothing | North | 300 |
| 5 | Electronics | South | 800 |
Мы можем группировать данные по нескольким столбцам одновременно:
-- Продажи по категориям и регионам SELECT category, region, COUNT(*) as sales_count, SUM(amount) as total_sales, AVG(amount) as avg_sale FROM sales GROUP BY category, region ORDER BY category, region;
Особенно полезным оказывается сочетание группировки с подсчетом уникальных значений. Если необходимо посчитать уникальные значения в каждой группе, используйте COUNT(DISTINCT):
-- Количество уникальных клиентов по регионам SELECT region, COUNT(DISTINCT customer_id) as unique_customers FROM orders GROUP BY region; -- Количество различных товарных категорий по городам SELECT city, COUNT(DISTINCT category) as category_diversity FROM store_inventory GROUP BY city;
Эта комбинация особенно ценна в аналитических сценариях — например, для определения разнообразия продуктовой линейки в каждом магазине или количества уникальных посетителей различных разделов сайта.
Визуализация логики GROUP BY:
Исходные данные: Группировка по department: Применение COUNT(*): +--------+-------------+ +--------+ +--------+-------+ | name | department | | IT | Alice, Bob, Eve | IT | 3 | +--------+-------------+ | | +--------+-------+ | Alice | IT | | HR | Carol, David | HR | 2 | | Bob | IT | +--------+ +--------+-------+ | Carol | HR | | David | HR | Строки разбиваются на группы по | Eve | IT | значению department, затем к +--------+-------------+ каждой группе применяется COUNT(*)
На схеме видно, как строки разбиваются на группы по department, и к каждой применяется COUNT(*). Этот механизм работает аналогично для всех агрегатных функций.
Важное правило при использовании GROUP BY: все столбцы в SELECT, которые не являются агрегатными функциями, должны присутствовать в GROUP BY. Это логично — мы не можем выбрать конкретное значение из группы строк без агрегации.
GROUP BY также открывает возможности для создания сложных аналитических отчетов, таких как анализ трендов продаж по месяцам, сравнение производительности различных подразделений или выявление наиболее популярных товарных категорий.
Фильтрация по агрегатам: оператор HAVING
После группировки данных и вычисления агрегатных значений часто возникает необходимость отфильтровать результаты на основе этих вычисленных показателей. Именно здесь на сцену выходит оператор HAVING — специализированный инструмент для фильтрации сгруппированных данных.
Ключевое отличие HAVING от WHERE заключается в порядке их выполнения: WHERE фильтрует строки до группировки, а HAVING — после. Это означает, что WHERE работает с исходными данными, а HAVING — с результатами агрегатных функций.
-- WHERE фильтрует до группировки SELECT department, AVG(salary) as avg_salary FROM employees WHERE hire_date > '2020-01-01' -- Сначала отбираем недавно нанятых GROUP BY department HAVING AVG(salary) > 50000; -- Затем оставляем отделы с высокой средней зарплатой
Рассмотрим практический пример анализа продаж:
-- Найти категории товаров с общими продажами более 10000 -- и количеством сделок более 5 SELECT category, COUNT(*) as transaction_count, SUM(amount) as total_sales FROM sales GROUP BY category HAVING COUNT(*) > 5 AND SUM(amount) > 10000;
HAVING позволяет создавать сложные условия фильтрации:
-- Отделы, где разница между максимальной и минимальной зарплатой превышает 20000 SELECT department, COUNT(*) as employee_count, MIN(salary) as min_salary, MAX(salary) as max_salary, (MAX(salary) - MIN(salary)) as salary_range FROM employees GROUP BY department HAVING (MAX(salary) - MIN(salary)) > 20000;
Важно понимать, что в условиях HAVING можно использовать как агрегатные функции, так и столбцы из GROUP BY. Это делает HAVING мощным инструментом для создания детализированных аналитических фильтров, которые помогают выявлять аномалии, тенденции и закономерности в сгруппированных данных.
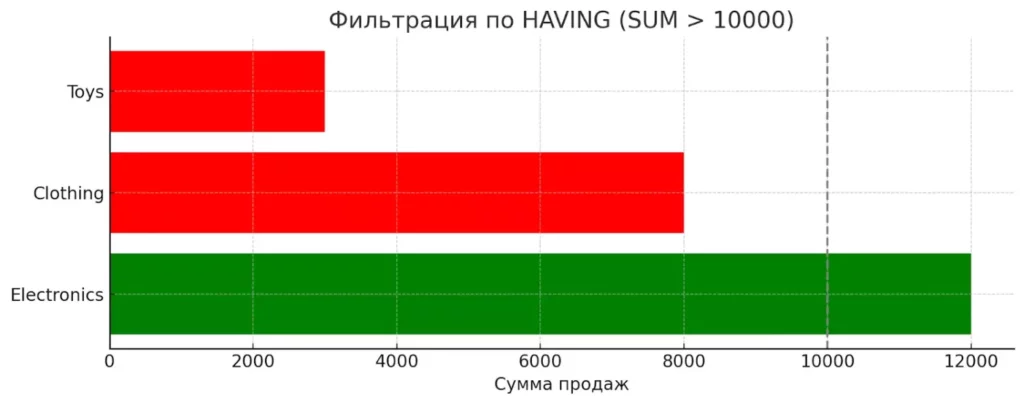
Только категория Electronics прошла фильтр HAVING SUM(amount) > 10000. Серые и цветные элементы помогают быстро отследить, кто остался вне выборки.
Частые ошибки и как их избежать
При работе с агрегатными функциями даже опытные разработчики иногда допускают ошибки, которые могут привести к некорректным результатам или полному отказу запроса. Рассмотрим наиболее распространенные проблемы и способы их решения.
Ошибка 1: Неагрегатные поля вне GROUP BY
Самая частая ошибка — включение в SELECT столбцов, которые не участвуют в группировке и не являются агрегатными функциями:
-- Неправильно: SELECT department, employee_name, COUNT(*) FROM employees GROUP BY department; -- Правильно: SELECT department, COUNT(*) FROM employees GROUP BY department;
Ошибка 2: Неверное использование WHERE вместо HAVING
Попытка фильтровать агрегированные результаты через WHERE приводит к ошибке:
-- Неправильно: SELECT department, AVG(salary) FROM employees GROUP BY department WHERE AVG(salary) > 50000; -- Правильно: SELECT department, AVG(salary) FROM employees GROUP BY department HAVING AVG(salary) > 50000;
Ошибка 3: Забытый DISTINCT при подсчете уникальных значений
Когда требуется подсчитать уникальные значения, важно не забывать модификатор DISTINCT:
-- Может дать неправильный результат: SELECT COUNT(customer_id) FROM orders; -- Считает все заказы -- Правильно для подсчета уникальных клиентов: SELECT COUNT(DISTINCT customer_id) FROM orders;
Ошибка 4: Неправильная интерпретация NULL-значений
Непонимание того, как агрегатные функции обрабатывают NULL, может исказить результаты:
-- Если нужно учесть NULL как 0: SELECT AVG(COALESCE(rating, 0)) FROM reviews; -- Вместо простого: SELECT AVG(rating) FROM reviews; -- Исключает NULL из расчета
Ошибка 5: Неоптимальные запросы с множественными агрегациями
Иногда разработчики создают неэффективные запросы, когда можно обойтись одним:
-- Неэффективно (множественные проходы по таблице): SELECT (SELECT COUNT(*) FROM orders) as total_orders, (SELECT SUM(amount) FROM orders) as total_amount; -- Эффективно (один проход): SELECT COUNT(*) as total_orders, SUM(amount) as total_amount FROM orders;
Понимание этих типичных ошибок поможет создавать более надежные и производительные SQL-запросы.
Примеры запросов с агрегатными функциями
Рассмотрим практические сценарии использования агрегатных функций, которые часто встречаются в реальных проектах. Эти примеры демонстрируют, как теоретические знания применяются для решения конкретных бизнес-задач.
Пример 1: Подсчет количества клиентов по странам
Предположим, у нас есть таблица клиентов с информацией о их местоположении:
| customer_id | name | country | registration_date | |-------------|----------|------------|-------------------| | 1 | Alice | USA | 2023-01-15 | | 2 | Bob | Canada | 2023-02-20 | | 3 | Carol | USA | 2023-01-25 | | 4 | David | Germany | 2023-03-10 | | 5 | Eve | Canada | 2023-02-28 |
Запрос для анализа географического распределения клиентов:
SELECT country, COUNT(*) as customer_count, COUNT(*) * 100.0 / (SELECT COUNT(*) FROM customers) as percentage FROM customers GROUP BY country ORDER BY customer_count DESC;
Результат:
| country | customer_count | percentage |
| USA | 2 | 40.0 |
| Canada | 2 | 40.0 |
| Germany | 1 | 20.0 |
Пример 2: Средняя цена товаров по категориям
Таблица товаров с ценовой информацией:
| product_id | name | category | price | |------------|-------------|-------------|-------| | 1 | Laptop | Electronics | 1200 | | 2 | T-shirt | Clothing | 25 | | 3 | Smartphone | Electronics | 800 | | 4 | Jeans | Clothing | 60 | | 5 | Tablet | Electronics | 450 |
Анализ ценовых характеристик по категориям:
SELECT category, COUNT(*) as product_count, ROUND(AVG(price), 2) as avg_price, MIN(price) as min_price, MAX(price) as max_price, ROUND(MAX(price) - MIN(price), 2) as price_range FROM products GROUP BY category ORDER BY avg_price DESC;
Результат:
| category | product_count | avg_price | min_price | max_price | price_range |
| Electronics | 3 | 816.67 | 450 | 1200 | 750 |
| Clothing | 2 | 42.50 | 25 | 60 | 35 |
Пример 3: Анализ зарплат сотрудников
Таблица сотрудников для HR-аналитики:
SELECT department, COUNT(*) as employee_count, ROUND(AVG(salary), 0) as avg_salary, MIN(salary) as min_salary, MAX(salary) as max_salary FROM employees WHERE salary IS NOT NULL GROUP BY department HAVING COUNT(*) >= 2 -- Показываем только отделы с минимум 2 сотрудниками ORDER BY avg_salary DESC;
Эти примеры демонстрируют, как агрегатные функции помогают превратить сырые данные в ценную бизнес-информацию, позволяя принимать обоснованные решения на основе количественного анализа.
Заключение
Агрегатные функции SQL представляют собой незаменимый инструментарий для современной аналитики данных. Они позволяют трансформировать массивы сырой информации в структурированные отчеты, которые становятся основой для принятия стратегических решений в любой организации. Подведем итоги:
- Агрегатные функции SQL обобщают данные и ускоряют анализ. Это позволяет быстро получать ключевую статистику по любым срезам и принимать решения на основе фактов.
- Работа с NULL и различие между COUNT(*) и COUNT(column) — частый источник ошибок. Важно понимать, как агрегатные функции обрабатывают отсутствующие значения, чтобы не искажать результаты анализа.
- Использование GROUP BY и HAVING расширяет возможности аналитики. Они позволяют строить сложные отчёты и применять фильтры к сгруппированным данным для более детальной выборки.
- Модификаторы DISTINCT и ALL влияют на точность вычислений. Осознанное применение этих инструментов помогает корректно подсчитывать уникальные значения и управлять дубликатами.
- Типовые ошибки при работе с агрегатами можно избежать. Следует включать только агрегируемые поля в SELECT и правильно использовать WHERE и HAVING для фильтрации.
Рекомендуем обратить внимание на подборку курсов по SQL — особенно если вы только начинаете осваивать профессию аналитика или разработчика. В каждом курсе собраны теоретические основы и практические задания для закрепления навыков работы с данными.
Рекомендуем посмотреть курсы по SQL
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
SQL с нуля для анализа данных
|
Eduson Academy
111 отзывов
|
Цена
49 900 ₽
|
От
4 158 ₽/мес
Беспроцентная. На 1 год.
|
Длительность
1 месяц
|
Старт
5 марта
|
Подробнее |
|
Продвинутый SQL
|
Нетология
46 отзывов
|
Цена
41 600 ₽
77 018 ₽
с промокодом kursy-online
|
От
2 567 ₽/мес
Рассрочка на 1 год.
|
Длительность
1 месяц
|
Старт
26 марта
2 раза в неделю по будням
|
Подробнее |
|
SQL-разработчик
|
Eduson Academy
111 отзывов
|
Цена
89 900 ₽
|
От
7 492 ₽/мес
0% на 12 месяцев
|
Длительность
6 месяцев
|
Старт
9 марта
|
Подробнее |

Нейросеть для дизайна интерьера: обзор лучших AI-инструментов
Какая нейросеть для создания дизайна интерьера действительно работает, а какая просто обещает? В этом обзоре — честный разбор, сравнение и советы

Pixel Perfect вёрстка: что это такое, как работает и как сделать сайт точным до пикселя
Pixel perfect: что это и зачем разработчику стремиться к точности до пикселя? Покажем процесс проверки верстки, разберём инструменты и типичные ошибки.

Полное руководство по хешированию в Python: алгоритмы, примеры, безопасность, пароли
Хеширование в python используется гораздо чаще, чем кажется на первый взгляд. Как работают хеш-функции, почему hash() нельзя применять для безопасности и какие алгоритмы подходят для реальных задач?

Контекстная реклама: главные ошибки и как их не совершить
Контекстная реклама — мощный инструмент, но только если настроена правильно. Рассказываем, какие ошибки встречаются чаще всего и как от них избавиться без лишних затрат.