Apache Cassandra — что это, преимущества и недостатки
В эпоху Big Data вопрос выбора правильной базы данных становится критически важным. Системы аналитики, высоконагруженные приложения и отказоустойчивые решения требуют особого подхода к хранению и обработке данных.

Apache Cassandra — одно из решений, которое активно обсуждается в сообществе разработчиков и архитекторов данных. Эта NoSQL-система обещает линейное масштабирование, высокую доступность и производительность на уровне терабайтов информации. Однако насколько оправданы такие амбициозные заявления?
В этой статье мы разберем архитектуру Cassandra, проанализируем ее реальные преимущества и подводные камни, а также поможем понять — когда эта технология действительно оправдает ваши ожидания.
- Что такое колоночные базы данных
- Что такое Apache Cassandra
- Преимущества Apache Cassandra
- Недостатки Apache Cassandra
- Когда и кому стоит использовать Cassandra
- Альтернативы Apache Cassandra
- Пример работы с Cassandra (код)
- Заключение
- Рекомендуем посмотреть курсы по backend разработке
Что такое колоночные базы данных
Чтобы понять специфику Apache Cassandra, нам необходимо разобраться с фундаментальными принципами колоночных БД. Эта архитектура кардинально отличается от привычных реляционных систем и определяет многие особенности поведения Cassandra.

Скриншот официального сайта Apache Cassandra.
Строчные vs колоночные базы — архитектурные различия
Традиционные реляционные БД организуют информацию по строкам — каждая запись хранится как непрерывный блок данных, содержащий все столбцы. Представьте таблицу сотрудников: информация о каждом человеке (имя, возраст, зарплата, отдел) физически располагается рядом на диске.
Колоночные системы кардинально меняют этот подход. Здесь информация группируется по столбцам — все значения одного поля хранятся вместе, независимо от того, к каким записям они относятся. В нашем примере все имена будут в одном блоке, все возрасты — в другом, и так далее.
Почему они быстрее — работа только с нужными столбцами
Основное преимущество колоночной архитектуры проявляется при аналитических запросах. Когда нам нужно вычислить среднюю зарплату по компании, строчная база должна прочитать всю таблицу целиком — ведь информация о зарплатах «размазана» по всему файлу вместе с именами, адресами и прочими данными.
Колоночная система в той же ситуации обращается только к блоку, содержащему зарплаты. Это кардинально сокращает объем операций ввода-вывода и ускоряет обработку запросов в десятки раз.
Почему эффективнее — сжатие, экономия памяти, гибкость схемы
Колоночное хранение открывает дополнительные возможности для оптимизации. Данные одного типа в столбце часто имеют схожие паттерны, что позволяет достичь впечатляющих коэффициентов сжатия. Столбец с датами или числовыми значениями сжимается гораздо эффективнее, чем смешанные строковые данные.
Кроме того, колоночные системы естественным образом поддерживают разреженные таблицы — ситуации, когда разные записи содержат различные наборы столбцов. В строчной базе пустые поля все равно занимают место, в колоночной — просто отсутствуют.
| Аспект | Строчные СУБД | Колоночные СУБД |
|---|---|---|
| Организация данных | По строкам (записям) | По столбцам (полям) |
| Аналитические запросы | Медленные (чтение всей строки) | Быстрые (только нужные столбцы) |
| OLTP-операции | Оптимальные | Менее эффективные |
| Сжатие данных | Низкий коэффициент | Высокий коэффициент |
| Разреженные таблицы | Неэффективны | Естественная поддержка |
| Гибкость схемы | Ограниченная | Высокая |
Однако важно понимать: колоночная архитектура — не универсальное решение. Она оптимизирована для аналитических нагрузок и может проигрывать строчным системам в транзакционных сценариях, где часто требуется работа с полными записями.
Что такое Apache Cassandra
Apache Cassandra — это распределенная NoSQL БД с открытым исходным кодом, специально созданная для работы с большими объемами данных в высоконагруженных системах. Изначально разработанная в Facebook* для решения задач масштабирования (позже проект был передан в Apache Software Foundation), Cassandra сегодня используется такими гигантами как Netflix, Apple, Instagram* и Spotify.
*компания Meta признана экстремистской в РФ
Главная особенность Cassandra заключается в том, что она объединяет принципы колоночного хранения с распределенной архитектурой, создавая систему, способную линейно масштабироваться до тысяч узлов при сохранении высокой производительности.
Архитектурные принципы
В основе Cassandra лежит peer-to-peer архитектура — принципиально иной подход по сравнению с традиционными системами master-slave. Здесь нет центрального сервера, отказ которого может парализовать весь кластер. Каждый узел равноправен и может обрабатывать запросы клиентов.
Эта архитектура строится на нескольких ключевых принципах. Во-первых, принцип eventual consistency (согласованность в конечном счете) — система жертвует немедленной консистентностью ради доступности и устойчивости к разделению сети. Во-вторых, принцип tunable consistency — пользователи могут настраивать уровень согласованности для каждой операции, балансируя между производительностью и надежностью.
Распределение данных и репликация
Cassandra использует механизм consistent hashing (последовательное хеширование) для равномерного распределения данных по узлам кластера. Каждый узел получает диапазон ключей, за которые он отвечает, а данные автоматически направляются на соответствующие узлы на основе хеш-функции от ключа записи.
Система поддерживает настраиваемую репликацию — каждая запись может храниться на нескольких узлах одновременно. Пользователи определяют replication factor (коэффициент репликации) и стратегию размещения реплик. Например, можно настроить хранение трех копий данных в разных центрах обработки информации для максимальной отказоустойчивости.
При выходе узла из строя система продолжает работу благодаря нескольким механизмам восстановления: read repair (восстановление при чтении), hinted handoff (отложенная доставка) и anti-entropy repair (регулярная синхронизация). Эти механизмы гарантируют, что временные сбои не приводят к потере данных.
Добавление новых узлов происходит динамически — система автоматически перебалансирует информацию и включает новые узлы в обработку запросов без остановки сервиса. Это позволяет масштабировать кластер «на лету» в зависимости от изменения нагрузки.
Преимущества Apache Cassandra
Архитектурные решения Cassandra обеспечивают ей ряд значительных преимуществ, особенно критичных для современных высоконагруженных систем. Рассмотрим ключевые достоинства, которые делают эту БД привлекательным выбором для многих проектов.
- Масштабируемость и высокая доступность. Отсутствие центрального сервера (master node) устраняет единую точку отказа — проблему, характерную для систем типа HBase. Новые узлы добавляются в кластер без остановки сервиса и ручного вмешательства. Система может масштабироваться линейно до тысяч узлов, при этом производительность растет пропорционально количеству оборудования.
- Гибкая схема данных. Система поддерживает до двух миллионов столбцов в одной таблице и позволяет определять различные наборы столбцов для строк в одной таблице. Такой подход эффективно решает проблему разреженных таблиц — типичную ситуацию в Big Data проектах.
- SQL-подобный язык запросов (CQL). Cassandra Query Language обеспечивает привычный синтаксис для разработчиков, знакомых с SQL, поддерживая основные операции SELECT, UPDATE и работу с пространствами имен. Драйверы реализованы для всех популярных языков программирования.
- Расширяемость функциональности. Начиная с версии 2.1 поддерживаются пользовательские типы данных (UDT), а версия 2.2 добавила возможность создания хранимых процедур и агрегатных функций. Это позволяет адаптировать систему под специфические требования проектов.
- Настраиваемая согласованность. Пользователи могут задавать уровень консистентности для каждой операции — от ANY (минимальная задержка) до ALL (максимальная надежность). Популярный уровень QUORUM требует подтверждения от большинства реплик, обеспечивая баланс производительности и надежности.
- Автоматическое разрешение конфликтов. Система хранит временные метки для каждого столбца, что позволяет автоматически разрешать конфликты при одновременных изменениях данных. Побеждает запись с более поздней временной меткой.
- Комплексная безопасность. Поддержка аутентификации, ролевой модели доступа и шифрованного соединения по SSL обеспечивает корпоративный уровень безопасности данных.
- ACID на уровне записи. Хотя Cassandra не поддерживает транзакции между записями, она гарантирует ACID-свойства для операций с одним ключом — все столбцы записи будут обновлены атомарно с обеспечением изолированности и долговечности.
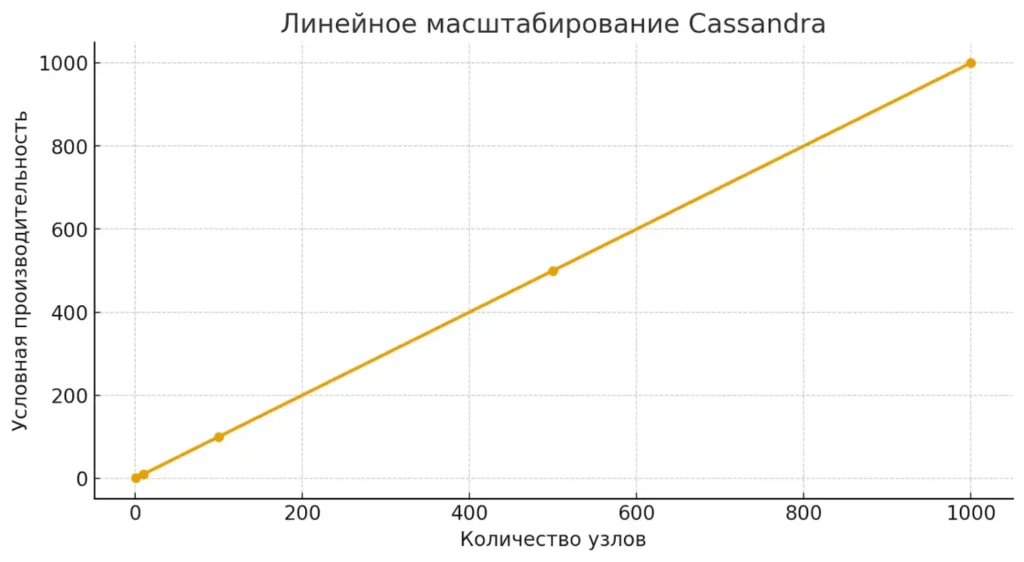
Cassandra демонстрирует линейный рост производительности при увеличении числа узлов. Это главное преимущество, позволяющее обслуживать кластеры из тысяч серверов без потери скорости.
Недостатки Apache Cassandra
Несмотря на впечатляющие возможности, Cassandra имеет ряд существенных ограничений, которые могут стать критичными для определенных типов проектов. Понимание этих недостатков поможет принять взвешенное решение о целесообразности использования данной технологии.
- Ограничения языка запросов CQL. Несмотря на схожесть с SQL, CQL значительно урезан в функциональности. Операции INSERT и UPDATE по сути идентичны, что может сбивать с толку разработчиков. Критичное ограничение — отсутствие операций соединения (JOIN). Для объединения данных из разных семейств столбцов приходится извлекать и объединять информацию программно, что крайне затратно для больших наборов данных.
- Высокие накладные расходы на денормализацию. SELECT-driven подход к проектированию информации требует создания отдельной таблицы практически под каждый запрос. Это приводит к значительному дублированию данных и усложняет поддержание их актуальности. В некоторых случаях объем хранимой информации может увеличиваться в разы по сравнению с нормализованной схемой.
- Строгие требования к уникальности ключей. Каждый ключ должен быть уникальным в своей области действия. Повторное использование ключа приведет к перезаписи данных без предупреждения. Хотя проблема решается составными ключами или добавлением временных меток, это усложняет проектирование схемы данных.
- Ограниченные возможности поиска и индексации. Полнотекстовый поиск не встроен в архитектуру системы и реализуется через внешние решения. Вторичные индексы имеют существенные функциональные ограничения и могут негативно влиять на производительность. Часто приходится строить собственные индексы с помощью денормализации и секционирования.
- Сложности с типом данных Counter. Столбцы-счетчики нельзя сортировать, индексировать или использовать совместно с другими типами данных в одной строке. Эти ограничения существенно сужают сценарии применения счетчиков в практических задачах.
- Высокая сложность администрирования. Cassandra требует глубокого понимания внутренних механизмов для правильной настройки и оптимизации. Мониторинг состояния кластера, настройка репликации, балансировка нагрузки — все это требует специализированных знаний и опыта.
- Серьезные требования к аппаратному обеспечению. Для оптимальной производительности система требует значительных объемов оперативной памяти и высокопроизводительных дисков. Экономия на «железе» может привести к неприемлемому падению производительности, что делает решение дорогостоящим для небольших проектов.
Эти ограничения не делают Cassandra плохим выбором, но четко определяют границы ее применимости. Успех проекта во многом зависит от того, насколько архитектурные особенности системы соответствуют специфике решаемых задач.
Когда и кому стоит использовать Cassandra
Выбор Cassandra как основной системы хранения данных должен основываться на тщательном анализе требований проекта. Эта технология показывает выдающиеся результаты в определенных сценариях, но может оказаться излишне сложной или неэффективной в других ситуациях.
Ключевые факторы выбора
При оценке целесообразности использования Cassandra следует проанализировать несколько критических аспектов. Тип рабочей нагрузки играет определяющую роль — система оптимизирована для интенсивной записи и простых запросов чтения. Если ваше приложение требует сложных аналитических запросов с агрегированием, стоит рассмотреть специализированные решения типа VerticA или ClickHouse.
Требования к согласованности данных — еще один ключевой фактор. Cassandra ориентирована на модель eventual consistency, что подходит для приложений, где небольшие задержки в синхронизации данных приемлемы. Для систем с жесткими требованиями к консистентности лучше выбрать HBase или Google Bigtable.
Объемы данных и планы масштабирования критически важны. Если ваш датасет помещается на одной машине и в обозримом будущем не превысит терабайт, традиционные реляционные базы могут оказаться проще и эффективнее. Cassandra раскрывает потенциал при работе с петабайтами информации и необходимости горизонтального масштабирования.
Идеальные сценарии применения
Cassandra превосходно подходит для систем с большими объемами данных временных рядов — логи серверов, метрики мониторинга, данные IoT-устройств. Равномерная нагрузка по записи и простые запросы по времени идеально соответствуют архитектурным особенностям системы
Высоконагруженные веб-приложения с географически распределенными пользователями — еще одна сильная сторона Cassandra. Возможность развернуть кластер в нескольких дата-центрах и обеспечить низкую задержку для пользователей из разных регионов делает систему привлекательной для глобальных сервисов.
Системы обмена сообщениями и социальные платформы также находят в Cassandra подходящее решение. Гибкая схема данных позволяет эффективно хранить разнородную информацию о пользователях, а высокая производительность записи справляется с пиковыми нагрузками.
Когда лучше выбрать альтернативы
Для аналитических задач с частыми агрегациями и сложными запросами ClickHouse или Apache Druid покажут значительно лучшие результаты. Эти системы специально оптимизированы под OLAP-нагрузки и обеспечивают на порядки более высокую производительность аналитических запросов.
При необходимости строгой консистентности данных стоит рассмотреть HBase (интеграция с экосистемой Hadoop) или Google Bigtable (полностью управляемый сервис). Транзакционные системы с частыми обновлениями по-прежнему лучше работают с традиционными реляционными базами.
| Сценарий | Cassandra | Лучшая альтернатива |
|---|---|---|
| Интенсивная запись, простое чтение | ✅ Отлично | — |
| Сложная аналитика | ❌ Не подходит | ClickHouse, Vertica |
| Строгая консистентность | ❌ Ограниченно | HBase, Bigtable |
| Транзакционные системы | ❌ Не подходит | PostgreSQL, MySQL |
| Небольшие объемы данных | ❌ Избыточно | Традиционные СУБД |
Альтернативы Apache Cassandra
Рынок колоночных и распределенных баз данных предлагает несколько серьезных альтернатив Cassandra, каждая из которых имеет свои архитектурные особенности и оптимальные сценарии применения.
Apache HBase — строгая консистентность и Hadoo
Apache HBase представляет собой распределенную колоночную базу данных, построенную поверх файловой системы Hadoop (HDFS). Главное отличие от Cassandra — строгая консистентность данных и master-slave архитектура.
Распределенная колоночная базу данных Apache HBase.
HBase превосходно подходит для ad-hoc запросов благодаря более гибкой модели данных. Система поддерживает сложные типы данных — массивы, map-структуры и вложенные объекты, что упрощает моделирование сложных предметных областей. Интеграция с экосистемой Hadoop обеспечивает естественную работу с инструментами типа Apache Spark и Apache Hive для обработки больших данных.
Однако строгая консистентность достигается за счет производительности и отказоустойчивости — выход из строя master-узла может парализовать весь кластер до восстановления.
Google Bigtable — полностью управляемый облачный сервис
Google Cloud Bigtable — это полностью управляемый NoSQL-сервис, оптимизированный для обработки петабайтов данных в реальном времени. Система обеспечивает строгую консистентность и автоматическое масштабирование без участия администраторов.
Главная страница Google Cloud Bigtable.
Основные преимущества Bigtable — глубокая интеграция с экосистемой Google Cloud Platform и отсутствие операционных издержек на управление инфраструктурой. Google берет на себя задачи резервного копирования, масштабирования, мониторинга и обновлений системы.
Однако vendor lock-in и стоимость могут стать критичными факторами для многих проектов, особенно при работе с большими объемами данных.
ScyllaDB
ScyllaDB позиционирует себя как drop-in замена для Cassandra с кардинально улучшенными характеристиками производительности. Система написана на C++ вместо Java и использует современные техники системного программирования.
ScyllaDB: drop-in замена для Cassandra.
ScyllaDB демонстрирует в несколько раз большую пропускную способность при меньших задержках по сравнению с Cassandra. Более эффективное использование процессора и памяти позволяет сократить количество серверов в кластере при той же нагрузке.
Дополнительное преимущество — встроенная поддержка аналитики в реальном времени через механизм Materialized Views, который автоматически создает и поддерживает вторичные индексы для ускорения доступа к данным.
Совместимость с Cassandra на уровне протокола и CQL облегчает миграцию существующих проектов, хотя некоторые специфичные для Cassandra функции могут требовать адаптации.
Пример работы с Cassandra (код)
Для понимания практических аспектов работы с Apache Cassandra рассмотрим базовый пример использования Python-драйвера. Этот код демонстрирует основные операции — от подключения к кластеру до выполнения CRUD-операций.
from cassandra.cluster import Cluster
# Подключение к кластеру Cassandra
# Создаем объект Cluster с адресами узлов в кластере
cluster = Cluster(['cassandra-node-1', 'cassandra-node-2', 'cassandra-node-3'])
# Создаем сессию с указанием пространства ключей (keyspace)
session = cluster.connect('user_data')
# Создание таблицы
# В Cassandra таблицы создаются с обязательным указанием PRIMARY KEY
session.execute("""
CREATE TABLE IF NOT EXISTS users (
id int PRIMARY KEY,
name text,
email text,
created_at timestamp
)
""")
# Вставка данных
# В Cassandra INSERT и UPDATE -- это по сути одна операция
session.execute("""
INSERT INTO users (id, name, email, created_at)
VALUES (%s, %s, %s, %s)
""", (1, 'Alice Johnson', 'alice@example.com', '2024-01-15 10:30:00'))
# Вставка нескольких записей
users_data = [
(2, 'Bob Smith', 'bob@example.com', '2024-01-16 14:20:00'),
(3, 'Carol Davis', 'carol@example.com', '2024-01-17 09:15:00')
]
for user in users_data:
session.execute("""
INSERT INTO users (id, name, email, created_at)
VALUES (%s, %s, %s, %s)
""", user)
# Чтение данных
# Простая выборка всех записей
rows = session.execute("SELECT * FROM users")
print("Все пользователи:")
for row in rows:
print(f"ID: {row.id}, Name: {row.name}, Email: {row.email}")
# Выборка с условием по PRIMARY KEY
user = session.execute("SELECT * FROM users WHERE id = %s", (1,))
for row in user:
print(f"Найден пользователь: {row.name}")
# Обновление данных
# Обновляем email для пользователя с id = 1
session.execute("""
UPDATE users
SET email = %s, created_at = %s
WHERE id = %s
""", ('alice.new@example.com', '2024-01-20 16:45:00', 1))
# Удаление данных
# Удаляем пользователя по PRIMARY KEY
session.execute("DELETE FROM users WHERE id = %s", (3,))
# Корректное закрытие соединения
cluster.shutdown()
Важные особенности работы с Cassandra, отраженные в коде: все операции модификации требуют указания PRIMARY KEY в условии WHERE; отсутствует различие между INSERT и UPDATE — система автоматически определяет, создавать новую запись или обновлять существующую; параметризованные запросы обязательны для предотвращения инъекций и оптимизации производительности.
При работе с производственными системами рекомендуется использовать prepared statements для часто выполняемых запросов и настраивать уровни консистентности в зависимости от требований приложения.
Заключение
Анализ возможностей и ограничений Apache Cassandra позволяет сформулировать четкие рекомендации по применению этой технологии в реальных проектах. Подведем итоги:
- Apache Cassandra — распределённая NoSQL база данных. Она обеспечивает масштабируемость и высокую доступность.
- Преимущества Cassandra — высокая скорость записи и гибкая модель данных. Эти факторы делают её востребованной в проектах с большими нагрузками.
- Недостатки системы — урезанный язык запросов, сложность администрирования и дорогая инфраструктура. Эти ограничения важно учитывать перед внедрением.
- Оптимальное применение Cassandra — системы логов, IoT и глобальные сервисы. В задачах аналитики и строгой консистентности лучше выбрать другие решения.
Если вы только начинаете осваивать работу с распределёнными базами данных, рекомендуем обратить внимание на подборку курсов по Backend-разработке. В них вы найдёте теоретические основы и практические примеры, которые помогут глубже понять архитектуру и научиться эффективно применять систему. Такие курсы подойдут как новичкам, так и специалистам, которые хотят развить навыки в области работы с Big Data.
Рекомендуем посмотреть курсы по backend разработке
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
IT-специалист с нуля
|
Eduson Academy
114 отзывов
|
Цена
122 500 ₽
|
От
10 208 ₽/мес
0% на 24 месяца
11 239 ₽/мес
|
Длительность
12 месяцев
|
Старт
24 марта
|
Подробнее |
|
Бэкенд-разработчик
|
HTML Academy
34 отзыва
|
Цена
30 600 ₽
46 000 ₽
|
От
1 700 ₽/мес
На 18 месяцев
2 453 ₽/мес
|
Длительность
11 месяцев
|
Старт
в любое время
|
Подробнее |
|
Веб-разработчик с нуля
|
Нетология
46 отзывов
|
Цена
163 300 ₽
302 470 ₽
с промокодом kursy-online
|
От
5 041 ₽/мес
Без переплат на 2 года.
7 222 ₽/мес
|
Длительность
17 месяцев
|
Старт
5 апреля
|
Подробнее |
|
FastAPI — погружение в backend разработку на Python
|
Stepik
33 отзыва
|
Цена
250 000 ₽
|
|
Длительность
4 месяца
|
Старт
в любое время
|
Подробнее |
|
Профессия Fullstack-разработчик на Python
|
Skillbox
232 отзыва
|
Цена
146 073 ₽
292 147 ₽
Ещё -20% по промокоду
|
От
4 296 ₽/мес
|
Длительность
12 месяцев
|
Старт
19 марта
|
Подробнее |

Яндекс Практикум vs Bang Bang Education: сравниваем методологию и упаковку кейсов для UX-исследователей
UX-исследования — с чего начать и какой курс выбрать? Разбираем методологию, формат обучения и портфолио, чтобы вы не ошиблись с выбором.

Яндекс Практикум vs Stepik: SQL с нуля — что быстрее даёт навык «решать задачи», а не «знать команды»
Stepik или Яндекс Практикум — где быстрее освоить SQL-аналитику и научиться решать реальные задачи? Разбираем формат обучения, типы практики и ключевые различия платформ, которые влияют на скорость роста навыка.

Яндекс Практикум vs Karpov.Courses: A/B — где понятнее, а где глубже и строже
Выбор между курсами по A/B тестированию от Яндекс Практикум и Karpov может быть непростым. Узнайте, какой из них лучше соответствует вашим целям и ожиданиям. В статье мы детально разберем их особенности, включая теоретическую и практическую части курсов, чтобы помочь вам сделать правильный выбор!

Яндекс Практикум vs GeekBrains: фронтенд — где лучше база и где быстрее выход на первые проекты
Ищете лучший курс по фронтенду, но не знаете, какой выбрать? В нашей статье вы найдете подробное сравнение программ Яндекс Практикума и GeekBrains — прочитайте и выберите подходящий курс для своего старта!