Что такое Hadoop и почему аналитику данных полезно уметь с ним работать
В эпоху цифровой трансформации мы сталкиваемся с парадоксом: чем больше данных генерируют наши системы, тем сложнее становится извлечь из них практическую пользу. По прогнозам аналитиков, к 2025 году объем генерируемых в мире данных превысит 180 зеттабайт (180 триллионов гигабайт). При этом традиционные подходы к обработке данных оказываются беспомощными перед такими объемами.

Именно для решения подобных задач в середине 2000-х годов была создана экосистема Apache Hadoop. В отличие от традиционных систем управления базами данных, которые требуют структурированной информации и мощного централизованного оборудования, Hadoop предложил радикально иной подход: распределить данные и вычисления по множеству обычных серверов, работающих как единое целое.
- Что такое Apache Hadoop
- Архитектура и компоненты
- Экосистема Hadoop — смежные технологии
- Hadoop и концепция Data Lake
- Области применения
- Почему Hadoop важен бизнесу
- Сравнение Hadoop и современных альтернатив (Spark и др.)
- Примеры реальных кейсов
- Заключение
- Рекомендуем посмотреть курсы по системной аналитике
Что такое Apache Hadoop
Apache Hadoop представляет собой open-source платформу, написанную на языке Java и предназначенную для распределенного хранения и обработки больших данных. В отличие от традиционных систем, которые концентрируют вычислительные ресурсы в одном месте, Хадуп строится на принципе горизонтального масштабирования — добавления новых узлов для увеличения производительности системы.
Главная страница Hadoop.
Название платформы имеет довольно забавную историю: оно происходит от имени игрушечного желтого слоненка, принадлежавшего сыну одного из создателей проекта, Дага Каттинга. Этот факт хорошо отражает философию open-source сообщества, где даже серьезные технологические решения могут иметь неформальные корни.
Краткая хронология развития Hadoop
2003-2005 годы: Зарождение идеи Даг Каттинг и Майк Кафарелла работают над поисковой системой Nutch, основанной на концепции MapReduce от Google. Именно эта работа заложила фундамент будущей платформы.
2006 год: Рождение Hadoop Yahoo предложила Каттингу возглавить команду разработки инфраструктуры распределенных вычислений. Проект официально получил название Хадуп и начал развиваться как самостоятельная платформа.
2008 год: Первый прорыв На базе Hadoop в Yahoo запускается поисковая система. В том же году проект становится частью Apache Software Foundation. Кластер из 910 узлов устанавливает мировой рекорд, обработав 1 терабайт за 209 секунд — результат, который привлек внимание всей индустрии.
2008-2010 годы: Массовое признание Крупнейшие технологические компании начинают активно использовать Хадуп: Facebook* для анализа пользовательского поведения, The New York Times для оцифровки архивов, Last.fm для рекомендательных систем, Amazon для облачных сервисов.
*принадлежит компании Meta, деятельность которой признана экстремистской в РФ
2010-2015 годы: Формирование экосистемы Вокруг Хадуп развивается целая экосистема инструментов: Hive для SQL-подобных запросов, Pig для анализа, HBase для NoSQL-хранения, Apache Spark для обработки в памяти.
2015-настоящее время: Эволюция и интеграция Hadoop продолжает развиваться, интегрируясь с облачными платформами, машинным обучением и современными аналитическими инструментами. При этом некоторые его компоненты постепенно заменяются более производительными решениями вроде Apache Spark.
Сегодня Хадуп остается одной из ключевых технологий в мире больших данных, хотя его роль эволюционирует от монолитной платформы к набору взаимодополняющих инструментов. Понимание принципов работы Hadoop критически важно для специалистов, работающих с большим объемом информации, поскольку многие современные решения так или иначе основаны на концепциях, впервые реализованных в этой платформе.
Архитектура и компоненты
Архитектура Хадуп строится на четырех основных компонентах, каждый из которых решает определенную задачу в процессе обработки большой информации. Понимание принципов работы этих компонентов критически важно для эффективного использования платформы — именно их взаимодействие обеспечивает те преимущества, за которые Hadoop ценят в индустрии.
HDFS (Hadoop Distributed File System)
HDFS представляет собой распределенную файловую систему, специально разработанную для работы с большими объемами информации. В отличие от традиционных файловых систем, которые хранят файлы на одном физическом носителе, HDFS распределяет данные по множеству узлов кластера.
Ключевая особенность HDFS — принцип репликации. Каждый блок (обычно размером 128 или 256 МБ) автоматически копируется на несколько узлов, что обеспечивает отказоустойчивость системы. Если один из серверов выходит из строя, система продолжает работать, используя копии данных с других узлов. По умолчанию коэффициент репликации равен трем, что означает существование трех копий каждого блока в разных местах кластера.
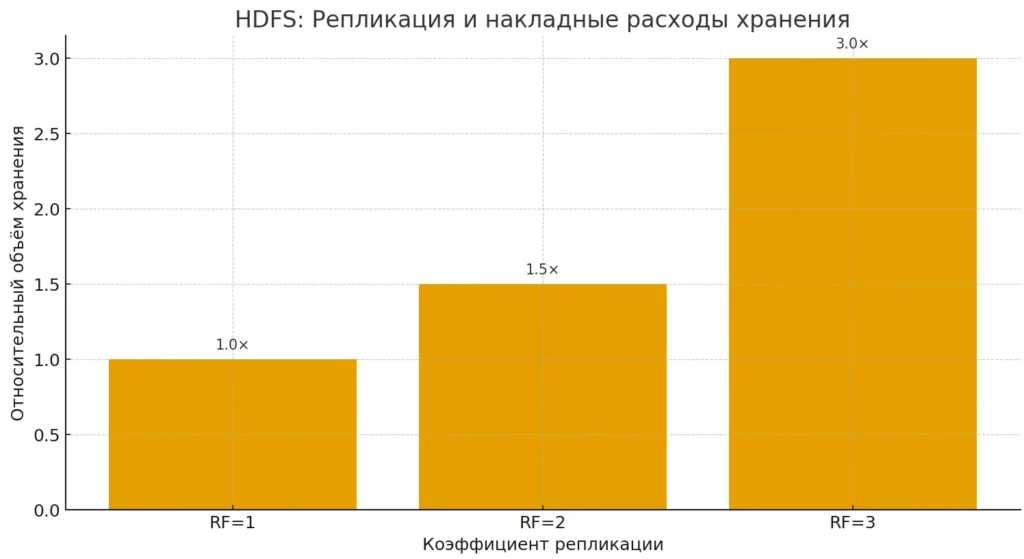
Диаграмма показывает, как растут накладные расходы хранения при увеличении коэффициента репликации. Это помогает быстро связать отказоустойчивость и стоимость места.
Архитектура HDFS следует модели «мастер-рабочий». NameNode выступает в роли мастера, контролируя метаданные файловой системы — информацию о том, где именно хранятся блоки информации. DataNode являются рабочими узлами, которые физически хранят информацию и выполняют операции чтения и записи по команде NameNode.
Важно понимать, что HDFS оптимизирована для последовательного чтения больших файлов, а не для произвольного доступа к небольшим фрагментам данных. Это делает ее идеальной для аналитических задач, но менее подходящей для транзакционных систем.
YARN (Yet Another Resource Negotiator)
YARN служит операционной системой для кластера Хадуп, управляя вычислительными ресурсами и планируя выполнение задач. До появления YARN в версии Hadoop 2.0 функции управления ресурсами были тесно связаны с MapReduce, что ограничивало гибкость платформы.
Центральным компонентом YARN является ResourceManager — служба, которая отслеживает доступные ресурсы кластера (процессорное время, память) и распределяет их между приложениями. На каждом узле работает NodeManager, который контролирует использование ресурсов на локальном уровне и взаимодействует с ResourceManager.
Когда приложение запрашивает ресурсы, YARN создает специальный контейнер — изолированную среду выполнения с выделенным количеством памяти и процессорного времени. Это позволяет различным приложениям (MapReduce, Spark, Hive) работать на одном кластере без конфликтов.
YARN поддерживает несколько стратегий планирования задач: FIFO (первый пришел — первый ушел), Fair Scheduler (справедливое распределение) и Capacity Scheduler (распределение по квотам). Выбор стратегии зависит от специфики использования кластера и приоритетов организации.
MapReduce
MapReduce представляет собой программную модель для обработки больших данных, основанную на функциональном программировании. Концепция заключается в разделении сложной задачи на две простые операции: Map (отображение) и Reduce (свертка).
На этапе Map входная информация разбивается на независимые фрагменты, которые обрабатываются параллельно на разных узлах кластера. Каждый Map-процесс принимает часть данных, выполняет над ними определенные операции (фильтрацию, преобразование, извлечение) и выдает результат в виде пар «ключ-значение».
Между Map и Reduce происходит фаза Shuffle — данные перераспределяются между узлами таким образом, чтобы все значения с одинаковыми ключами оказались на одном узле. Это критически важный этап, который часто становится узким местом производительности.
На этапе Reduce информация с одинаковыми ключами обрабатывается совместно — агрегируется, суммируется, группируется. Результат операции Reduce и является финальным выходом задачи MapReduce.
Классический пример MapReduce — подсчет частоты слов в большом тексте. Map-функция извлекает отдельные слова и присваивает каждому значение 1. Reduce-функция суммирует все единицы для каждого уникального слова, получая итоговую частоту.
Hadoop Common
Hadoop Common представляет собой набор библиотек, утилит и API, которые используются всеми остальными компонентами экосистемы. Это фундамент, на котором строится вся платформа.
Common Configuration обеспечивает единообразный подход к настройке всех компонентов через XML-файлы. Это позволяет централизованно управлять параметрами кластера и легко адаптировать систему под различные сценарии использования.
Common I/O предоставляет абстракции для работы с различными файловыми системами — не только HDFS, но и традиционными локальными системами, Amazon S3, Azure Blob Storage. Благодаря этому приложения могут прозрачно работать с информацией независимо от места ее физического хранения.
Common Security включает механизмы аутентификации и авторизации, основанные на протоколе Kerberos. Это особенно важно для корпоративных развертываний, где необходимо обеспечить контроль доступа к чувствительным данным.
Взаимодействие всех четырех компонентов создает мощную платформу для работы с большими данными. HDFS обеспечивает надежное хранение, YARN управляет ресурсами, MapReduce предоставляет модель вычислений, а Common связывает все воедино. Понимание этой архитектуры — ключ к эффективному использованию Хадуп в реальных проектах.
Экосистема Hadoop — смежные технологии
Одна из ключевых особенностей заключается в том, что это не просто единая платформа, а целая экосистема взаимосвязанных инструментов. За годы развития вокруг основных компонентов сформировался богатый набор специализированных решений, каждое из которых решает определенные задачи в области работы с большим объемом информации. Понимание этой экосистемы критически важно для практического применения Хадуп в реальных проектах.
Apache Hive — SQL для больших данных
Hive представляет собой хранилище, построенное поверх Хадуп, которое позволяет использовать SQL-подобный язык запросов (HQL) для работы с большими массивами информации. Фактически Hive выступает мостом между традиционным миром реляционных БД и распределенными вычислениями Hadoop.
Когда аналитик пишет запрос на HQL, Hive автоматически транслирует его в серию MapReduce-задач (или задач для других движков вычислений, таких как Spark). Это позволяет специалистам, знакомым с SQL, работать с терабайтами информации без необходимости изучения сложных парадигм программирования MapReduce.
Важная особенность Hive — поддержка схемы при чтении (schema-on-read), в отличие от традиционных БД со схемой при записи. Это означает, что данные могут быть загружены в HDFS в любом формате, а структура применяется только при выполнении запроса. Такой подход обеспечивает гибкость при работе с разнородными источниками данных.
Apache Pig — платформа для анализа данных
Pig предоставляет высокоуровневый язык Pig Latin для описания потоков обработки информации. В отличие от декларативного SQL-подобного синтаксиса Hive, Pig Latin использует процедурный подход, позволяя программистам более детально контролировать логику обработки.
Pig особенно эффективен для задач извлечения, трансформации и загрузки информации (ETL). Он может работать с полуструктурированными данными, автоматически обрабатывать отсутствующие поля и адаптироваться к изменениям в структуре входной информации. Это делает Pig популярным инструментом для подготовки «сырых» данных к последующему анализу.
HBase — распределенная NoSQL БД
HBase представляет собой колоночную NoSQL базу данных, построенную поверх HDFS и предназначенную для работы в реальном времени с большими объемами информации. В отличие от пакетной обработки MapReduce, HBase обеспечивает произвольный доступ к данным с низкой задержкой.
Архитектура HBase основана на модели Google BigTable — данные организованы в виде разреженных, многомерных таблиц, где строки сортируются по ключу, а столбцы группируются в семейства. Это обеспечивает высокую производительность для операций чтения и записи отдельных записей, что критически важно для веб-приложений и системах реального времени.
Apache ZooKeeper — координация распределенных систем
ZooKeeper выполняет роль центрального сервиса координации для распределенных приложений. Он предоставляет простые примитивы для синхронизации, управления конфигурацией, именования сервисов и группирования узлов.
В контексте Hadoop ZooKeeper используется для обеспечения высокой доступности критически важных компонентов, таких как NameNode в HDFS или ResourceManager в YARN. При отказе основного узла ZooKeeper автоматически переключает нагрузку на резервный, минимизируя время простоя системы.
Apache Oozie — управление рабочими процессами
Oozie представляет собой систему планирования и координации рабочих процессов для Хадуп. Он позволяет определять сложные последовательности задач, включающие MapReduce, Pig, Hive и другие операции, с поддержкой условного выполнения, параллелизма и обработки ошибок.
Рабочие процессы в Oozie описываются в виде направленных ациклических графов (DAG), где узлы представляют задачи, а ребра — зависимости между ними. Это обеспечивает гибкость в создании сложных пайплайнов обработки информации с автоматическим мониторингом и восстановлением после сбоев.
Apache Spark — следующее поколение
Spark заслуживает особого внимания как технология, которая во многих сценариях превосходит классический MapReduce. Основное преимущество Spark — возможность выполнения вычислений в оперативной памяти, что обеспечивает производительность в 10-100 раз выше для итеративных алгоритмов.
Spark предоставляет унифицированные API на языках Java, Scala, Python и R, что делает его доступным для широкого круга разработчиков. Платформа включает специализированные библиотеки: Spark SQL для работы с структурированными данными, Spark Streaming для обработки потоков в реальном времени, MLlib для машинного обучения и GraphX для анализа графов.
Важно отметить, что Spark может работать не только с YARN, но и с другими менеджерами ресурсов, включая собственный Standalone режим и Apache Mesos. Это обеспечивает гибкость развертывания и интеграцию с существующей инфраструктурой.
| Инструмент | Назначение | Интерфейс | Тип обработки |
| Hive | SQL-запросы к большим данным | HQL (SQL-подобный) | Пакетная |
| Pig | ETL и анализ информации | Pig Latin | Пакетная |
| HBase | NoSQL БД | Java API, REST | Реального времени |
| Spark | Универсальные вычисления | Java, Scala, Python, R | Пакетная, потоковая |
| ZooKeeper | Координация сервисов | Java API | Сервисная |
| Oozie | Управление процессами | XML DSL | Планирование |
Экосистема Хадуп продолжает развиваться, и сегодня мы наблюдаем тенденцию к специализации инструментов. Вместо попыток создать универсальное решение, разработчики фокусируются на оптимизации конкретных аспектов работы с информацией. Это позволяет организациям выбирать оптимальную комбинацию технологий для своих специфических задач.
Hadoop и концепция Data Lake
Концепция Data Lake (озера данных) неразрывно связана с развитием Хадуп и представляет собой архитектурный подход к хранению информации, который кардинально отличается от традиционных подходов. Если классические хранилища данных (Data Warehouse) требуют предварительного определения структуры и схемы, то Data Lake позволяет сохранять информацию в ее исходном виде — будь то структурированные таблицы, полуструктурированные JSON-файлы или неструктурированные медиафайлы.
Философия Data Lake
Основная идея Data Lake заключается в принципе «сначала сохрани, потом разберись». Вместо того чтобы тратить месяцы на проектирование схемы и ETL-процессов, организации могут немедленно начать собирать всю доступную информацию. Структура и смысл информации определяются позже, на этапе анализа — отсюда термин «схема при чтении» (schema-on-read).
Хадуп обеспечивает технологическую основу для реализации этой концепции. HDFS позволяет экономично хранить петабайты разнородных данных, а экосистема инструментов предоставляет гибкие возможности для их последующей обработки. При этом система остается масштабируемой — добавление новых источников не требует пересмотра всей архитектуры.
Потоковая и батч-обработка в Data Lake
Data Lake поддерживает два основных режима обработки, каждый из которых имеет свои преимущества и области применения.
Батч-обработка (пакетная обработка) представляет собой классический подход, при котором информация накапливается в течение определенного периода, а затем обрабатывается единым блоком. Этот режим оптимален для задач, не требующих немедленного результата: ежедневные отчеты, анализ исторических трендов, обучение моделей машинного обучения. MapReduce и Spark в батч-режиме обеспечивают высокую пропускную способность при обработке больших объемов данных.
Потоковая обработка (stream processing) работает с информацией в реальном времени, обрабатывая каждое событие по мере его поступления. Такой подход критически важен для систем мониторинга, обнаружения мошенничества, персонализации в реальном времени. Apache Spark Streaming, Apache Kafka и Apache Storm представляют собой ключевые технологии для реализации потоковой обработки в экосистеме Хадуп.
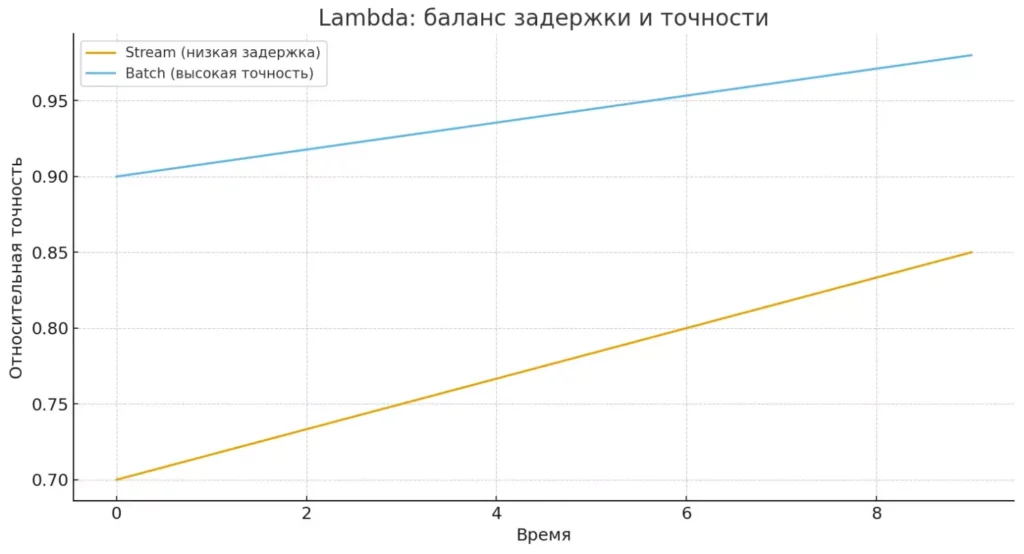
Линейный график сравнивает условную точность stream и batch-подходов по времени. Он иллюстрирует компромисс: минимальная задержка против максимальной точности.
Современные архитектуры Data Lake часто используют гибридный подход, известный как Lambda Architecture. В этой модели потоковая обработка обеспечивает быстрые приблизительные результаты, а батч-обработка — точные результаты с некоторой задержкой. Результаты обеих обработок объединяются в служебном слое, предоставляющем единый интерфейс для конечных пользователей.
Практические преимущества Data Lake на Hadoop
Гибкость схемы позволяет организациям адаптироваться к изменяющимся требованиям бизнеса без дорогостоящих миграций. Новые атрибуты могут быть добавлены без влияния на существующие процессы, а эксперименты с различными подходами к анализу не требуют создания отдельных копий данных.
Экономическая эффективность достигается за счет использования обычного серверного оборудования вместо дорогих специализированных систем. Стоимость хранения терабайта информации в HDFS значительно ниже по сравнению с традиционными корпоративными хранилищами.
Единая платформа для различных типов анализа устраняет необходимость в множественных специализированных системах. SQL-аналитики могут работать через Hive, специалисты по машинному обучению — через Spark MLlib, а разработчики — через нативные API различных компонентов экосистемы.
Data Lake на основе Hadoop становится фундаментом для современных аналитических платформ, обеспечивая организациям возможность извлекать ценность из всех доступных данных, независимо от их формата и структуры. Это особенно важно в эпоху, когда конкурентные преимущества все чаще основываются на способности быстро превращать разрозненную информацию в практические инсайты.
Области применения
Универсальность Хадуп позволяет применять эту платформу в самых разных отраслях, где организации сталкиваются с необходимостью обработки больших объемов информации. Рассмотрим, как различные индустрии используют возможности экосистемы Хадуп для решения своих специфических задач и получения конкурентных преимуществ.
Ритейл: персонализация и оптимизация
Розничная торговля генерирует огромные массивы информации: транзакции покупок, поведение на веб-сайтах, данные программ лояльности, информация о движении товаров. Hadoop позволяет ритейлерам превращать эту информацию в практические инсайты.
Персонализация рекомендаций стала одним из ключевых применений больших данных в ритейле. Системы на базе Хадуп анализируют историю покупок, просмотры товаров, сезонные предпочтения и демографическая информация для формирования индивидуальных предложений. Крупные e-commerce платформы используют алгоритмы коллаборативной фильтрации, обрабатывающие миллиарды взаимодействий пользователей с товарами.
Прогнозирование спроса и управление ассортиментом требует анализа множественных факторов: исторических продаж, сезонности, погодных условий, экономических трендов, активности конкурентов. Hadoop позволяет консолидировать эти разнородные источники информации и применять сложные алгоритмы машинного обучения для точного планирования закупок и размещения товаров.
Анализ корзины покупок помогает выявлять скрытые связи между товарами, оптимизировать выкладку в магазинах и формировать кросс-продажи. Алгоритмы поиска ассоциативных правил, реализованные в Spark MLlib, обрабатывают миллионы транзакций для выявления паттернов покупательского поведения.
Финансы и банки: риски и безопасность
Финансовая индустрия была одной из первых, кто осознал потенциал больших данных для улучшения операционной эффективности и управления рисками. Банки и финансовые институты используют Хадуп для решения критически важных задач.
Обнаружение мошенничества в реальном времени требует анализа миллионов транзакций на предмет аномальных паттернов. Системы на базе Hadoop и Spark Streaming анализируют такие факторы, как геолокация транзакции, время проведения, сумма, тип мерчанта, историческое поведение клиента. Машинное обучение позволяет адаптироваться к новым типам мошеннических схем без ручного вмешательства.
Кредитный скоринг эволюционировал от простых статистических моделей к сложным алгоритмам, учитывающим сотни переменных. Хадуп позволяет интегрировать традиционные кредитные данные с альтернативными источниками: социальными сетями, мобильными платежами, геолокационной информацией. Это особенно важно для оценки кредитоспособности клиентов с ограниченной кредитной историей.
Управление рыночными рисками требует обработки огромных объемов рыночной информацией в реальном времени. Хадуп используется для бэк-тестирования торговых стратегий на исторических данных, расчета Value-at-Risk для сложных портфелей, стресс-тестирования в соответствии с регулятивными требованиями.
Алгоритмическая торговля полагается на быструю обработку рыночных данных и выполнение сложных математических моделей. High-frequency trading фирмы используют Hadoop для анализа исторических паттернов, оптимизации торговых алгоритмов и управления рисками портфеля.
Производство: IoT и предиктивное обслуживание
Промышленный интернет вещей (IIoT) генерирует беспрецедентные объемы информации от датчиков, установленных на производственном оборудовании. Хадуп обеспечивает инфраструктуру для сбора, хранения и анализа этой информации.
Предиктивное обслуживание оборудования использует информацию от вибрационных датчиков, датчиков температуры, давления, энергопотребления для прогнозирования отказов до их возникновения. Алгоритмы машинного обучения, работающие на кластерах Хадуп, анализируют временные ряды показателей оборудования и выявляют предвестники неисправностей.
Контроль качества продукции интегрирует информацию от систем компьютерного зрения, спектроскопии, измерительных приборов. Hadoop позволяет обрабатывать изображения высокого разрешения, спектральные данные, результаты химических анализов для выявления дефектов и оптимизации производственных процессов.
Оптимизация энергопотребления использует информацию от smart-счетчиков, погодных станций, систем управления зданиями. Алгоритмы на базе Хадуп анализируют паттерны потребления энергии и автоматически корректируют работу оборудования для минимизации затрат.
Здравоохранение: данные пациентов и исследования
Здравоохранение переживает революцию больших данных, где Hadoop играет ключевую роль в обработке медицинских изображений, геномных данных, электронных медицинских карт.
Анализ медицинских изображений требует обработки терабайтов данных от МРТ, КТ, рентгеновских снимков. Системы на базе Хадуп и deep learning библиотек помогают радиологам выявлять патологии, отслеживать прогрессирование заболеваний, планировать лечение.
Геномика и персонализированная медицина используют Хадуп для анализа ДНК-последовательностей, выявления генетических мутаций, разработки таргетной терапии. Обработка полного генома человека требует значительных вычислительных ресурсов, которые эффективно предоставляет кластер Hadoop.
Эпидемиологические исследования консолидируют информацию от множественных источников: больниц, лабораторий, страховых компаний, государственных регистров. Хадуп позволяет анализировать факторы риска заболеваний, эффективность лечения, распространение эпидемий на популяционном уровне.
Телекоммуникации: трафик и качество услуг
Телекоммуникационные компании генерируют огромные объемы данных о звонках, SMS, интернет-трафике, местоположении абонентов. Hadoop обеспечивает инфраструктуру для монетизации этой информации.
Анализ сетевого трафика помогает операторам оптимизировать пропускную способность, планировать расширение сети, выявлять узкие места. Real-time аналитика на базе Spark Streaming позволяет автоматически перераспределять нагрузку между базовыми станциями.
Предотвращение оттока клиентов (churn prevention) использует машинное обучение для выявления абонентов, склонных к смене оператора. Модели анализируют паттерны использования услуг, жалобы в службу поддержки, конкурентные предложения для своевременного вмешательства.
Персонализация тарифных планов основывается на детальном анализе потребления услуг каждым абонентом. Хадуп позволяет сегментировать клиентскую базу и разрабатывать индивидуальные предложения, максимизирующие ARPU (средний доход на пользователя).
| Отрасль | Основные задачи | Типы информации | Примеры применения |
| Ритейл | Персонализация, прогнозирование спроса | Транзакции, веб-логи, программы лояльности | Рекомендательные системы, управление ассортиментом |
| Финансы | Риск-менеджмент, обнаружение мошенничества | Транзакции, рыночные данные, кредитные истории | Скоринг, алгоритмическая торговля |
| Производство | Предиктивное обслуживание, контроль качества | IoT-датчики, изображения, энергопотребление | Мониторинг оборудования, оптимизация процессов |
| Здравоохранение | Диагностика, персонализированная медицина | Медизображения, геномные данные, ЭМК | Анализ снимков, геномика |
| Телеком | Оптимизация сети, предотвращение оттока | Логи звонков, трафик, геолокация | Анализ трафика, churn prevention |
Бар-чарт суммирует интенсивность использования больших данных по пяти ключевым отраслям (условные баллы). Это помогает читателю «свернуть» длинный список кейсов
Разнообразие применений Hadoop демонстрирует универсальность платформы и ее способность адаптироваться к специфическим потребностям различных отраслей. При этом успех внедрения зависит не только от технических возможностей, но и от понимания бизнес-процессов и умения правильно формулировать задачи для анализа информации.
Почему Hadoop важен бизнесу
В эпоху цифровой трансформации способность организации эффективно работать с большими данными становится критическим фактором конкурентоспособности. Хадуп предоставляет не просто технологическую платформу, а стратегическое преимущество, которое проявляется в нескольких ключевых аспектах деятельности современного бизнеса.
Экономическая эффективность и масштабируемость
Традиционные корпоративные системы управления информацией требуют значительных инвестиций в специализированное оборудование и лицензионное программное обеспечение. Хадуп кардинально меняет эту экономику, позволяя строить мощные аналитические системы на базе обычных серверов. Стоимость хранения терабайта данных в HDFS может быть в 10-20 раз ниже по сравнению с традиционными корпоративными хранилищами.
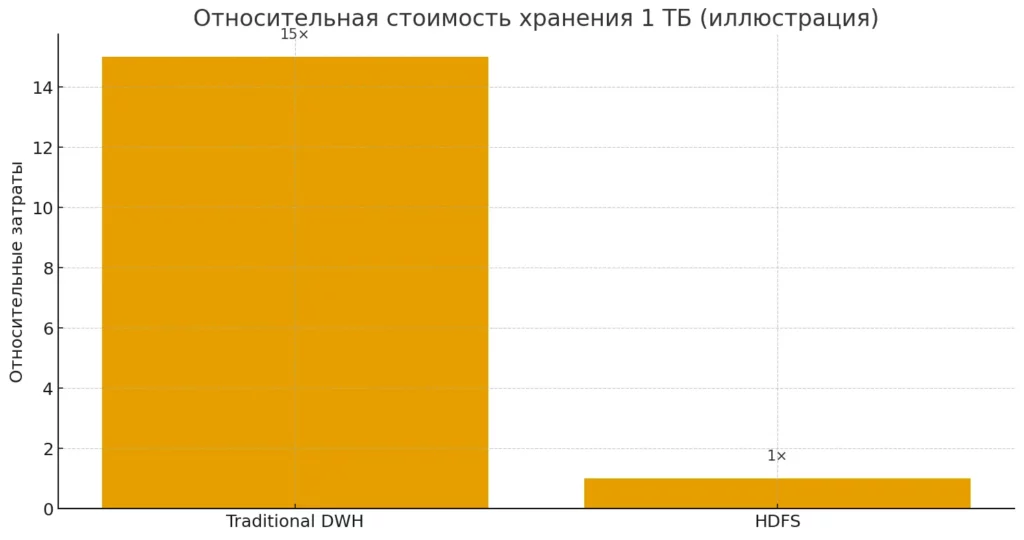
Условное сравнение относительной стоимости хранения 1 ТБ в традиционном DWH и в HDFS. Подчёркивает экономическую мотивацию горизонтального масштабирования.
Горизонтальная масштабируемость Hadoop означает, что организации могут начать с небольшого кластера и постепенно наращивать мощности по мере роста объемов информации. При этом не требуется замена существующего оборудования — новые узлы просто добавляются к кластеру, автоматически увеличивая его производительность.
Открытый исходный код исключает расходы на лицензирование и предоставляет полный контроль над технологическим стеком. Компании могут адаптировать платформу под свои специфические потребности, не завися от решений вендоров корпоративного ПО.
Работа с неструктурированными данными
Современные организации сталкиваются с тем, что значительная часть их информации существует в неструктурированном виде: документы, электронные письма, изображения, видео, логи приложений, социальные сети. Традиционные реляционные БД не способны эффективно работать с такой информацией.
Хадуп устраняет это ограничение, позволяя хранить и обрабатывать информацию в любом формате. Это открывает новые возможности для анализа: обработка изображений с помощью компьютерного зрения, анализ тональности текстов, извлечение инсайтов из видеоконтента. Компании получают возможность монетизировать ранее недоступные источники данных.
Отказоустойчивость и надежность
Встроенная отказоустойчивость Hadoop обеспечивает непрерывность бизнес-процессов даже при сбоях оборудования. Автоматическая репликация данных и переключение задач на работающие узлы происходит без вмешательства администраторов. Это критически важно для организаций, где простой аналитических систем может привести к значительным финансовым потерям.
Кадровые требования и экспертиза
Успешное внедрение Хадуп требует формирования команды специалистов с различными компетенциями:
Data Engineers отвечают за построение и поддержку инфраструктуры данных. Они настраивают кластеры Hadoop, разрабатывают ETL-процессы, обеспечивают интеграцию с источниками информации. Требуется глубокое понимание архитектуры Hadoop, опыт работы с Linux-системами, знание языков программирования Java и Python.
Data Scientists разрабатывают аналитические модели и алгоритмы машинного обучения. Им необходимо понимание статистики, математики, а также практические навыки работы с Spark, R, Python. Важно умение переводить бизнес-задачи в аналитические модели и интерпретировать результаты.
Data Analysts работают с готовыми данными, создавая отчеты и дашборды для бизнес-пользователей. Основные инструменты — Hive для выполнения SQL-запросов, различные BI-платформы для визуализации. Требуется понимание предметной области и навыки работы с информацией.
DevOps Engineers обеспечивают надежность и производительность кластеров. Они мониторят состояние системы, автоматизируют развертывание, управляют ресурсами. Критически важны навыки администрирования Linux, понимание сетевых технологий, опыт работы с системами мониторинга.
Трансформация бизнес-процессов
Хадуп не просто решает технические задачи — он трансформирует подход к принятию решений в организации. Вместо интуитивных решений компании получают возможность основывать стратегию на фактических данных. Это особенно важно в условиях быстро меняющихся рынков, где цена ошибки постоянно растет.
Democratization of data — демократизация данных — становится реальностью, когда различные подразделения получают доступ к единой аналитической платформе. Маркетинговые команды могут самостоятельно анализировать эффективность кампаний, операционные подразделения — оптимизировать процессы, а топ-менеджмент — получать актуальную информацию для стратегического планирования.
Real-time insights меняют скорость реакции бизнеса на изменения. Системы на базе Hadoop могут обнаруживать аномалии в поведении клиентов, изменения рыночной конъюнктуры, технические проблемы в режиме реального времени, позволяя принимать оперативные корректирующие меры.
Внедрение Хадуп представляет собой не только технологический проект, но и организационную трансформацию. Компании, которые успешно интегрируют большие данные в свои бизнес-процессы, получают устойчивое конкурентное преимущество в цифровой экономике. При этом важно понимать, что технология сама по себе не решает бизнес-задачи — ключевым фактором успеха остается способность организации извлекать практическую ценность из доступных данных.
Сравнение Hadoop и современных альтернатив (Spark и др.)
Технологический ландшафт больших данных постоянно эволюционирует, и сегодня Hadoop сосуществует с рядом альтернативных решений, каждое из которых имеет свои сильные стороны. Понимание различий между этими платформами критически важно для выбора оптимальной архитектуры в конкретных проектах.
Apache Spark vs MapReduce: революция in-memory вычислений
Наиболее значимой альтернативой классическому MapReduce стал Apache Spark, который предлагает принципиально иной подход к обработке данных. Ключевое преимущество Spark заключается в возможности выполнения вычислений в оперативной памяти, что обеспечивает кратное увеличение производительности для итеративных алгоритмов.
MapReduce после каждой операции записывает промежуточные результаты на диск, что создает значительные накладные расходы на операции ввода-вывода. Spark, напротив, может сохранять данные в памяти между операциями, что особенно эффективно для алгоритмов машинного обучения, требующих многократного прохода по одному набору данных.
Программные интерфейсы также существенно различаются. MapReduce требует написания low-level кода на Java с явным определением Map и Reduce функций. Spark предоставляет высокоуровневые API на языках Java, Scala, Python и R, которые значительно упрощают разработку и делают платформу доступной для более широкого круга специалистов.
Spark поддерживает потоковую обработку данных через Spark Streaming, что позволяет создавать unified архитектуры для batch и real-time обработки. MapReduce, будучи изначально спроектированным для пакетной обработки, требует дополнительных инструментов для работы с потоками данных.
Специализированные решения для конкретных задач
Apache Kafka завоевал позицию стандарта де-факто для потоковой обработки данных в реальном времени. В отличие от Hadoop, который оптимизирован для пакетной обработки больших объемов, Kafka обеспечивает low-latency обработку потоков событий с пропускной способностью миллионы сообщений в секунду.
Apache Flink представляет собой еще одну альтернативу для stream processing с нативной поддержкой event time и exactly-once семантики. Flink особенно эффективен для сложных статeful вычислений над потоками данных, где требуется гарантированная консистентность.
Облачные платформы, такие как Amazon EMR, Google Cloud Dataflow, Azure HDInsight, предоставляют managed варианты Хадуп и сопутствующих технологий. Это снижает операционные затраты и позволяет организациям сосредоточиться на бизнес-логике вместо управления инфраструктурой.
Гибридные архитектуры: лучшее из разных миров
Современные enterprise архитектуры редко полагаются на единственную технологию. Вместо этого используются гибридные подходы, где каждый компонент выполняет задачи, для которых он наиболее оптимизирован.
Типичная modern data platform может включать HDFS для долгосрочного хранения данных, Apache Kafka для real-time ingestion, Spark для batch и stream processing, Elasticsearch для поиска и анализа логов, различные NoSQL базы данных для operational workloads.
В такой архитектуре Hadoop выступает не как монолитная платформа, а как набор специализированных компонентов. HDFS остается популярным выбором для cost-effective хранения больших объемов данных, YARN используется как resource manager для различных вычислительных фреймворков, а экосистема инструментов предоставляет проверенные решения для специфических задач.
| Аспект | MapReduce | Spark | Kafka | Flink |
| Модель обработки | Batch | Batch + Streaming | Streaming | Streaming |
| Скорость | Низкая (диск I/O) | Высокая (in-memory) | Очень высокая | Высокая |
| Latency | Минуты | Секунды-минуты | Миллисекунды | Миллисекунды |
| API | Java (low-level) | Java, Scala, Python, R | Java, Scala | Java, Scala |
| Use case | ETL, batch analytics | ML, iterative algorithms | Event streaming | Complex event processing |
| Learning curve | Высокая | Средняя | Средняя | Высокая |
Факторы выбора технологии
При выборе между Хадуп и альтернативными решениями следует учитывать несколько ключевых факторов:
Объем данных и паттерны доступа. Hadoop остается оптимальным выбором для очень больших объемов данных (петабайты), где требуется sequential scan всего dataset. Для меньших объемов или random access паттернов могут быть более эффективными specialized решения.
Требования к latency. Если критически важна низкая задержка обработки, стоит рассмотреть streaming платформы. Для batch analytics, где допустимы задержки в часы, классический Хадуп может быть cost-effective решением.
Экспертиза команды и существующая инфраструктура. Организации с большими инвестициями в Hadoop экосистему могут эволюционно мигрировать к hybrid архитектурам, постепенно заменяя отдельные компоненты более современными альтернативами.
Бюджетные ограничения. Open-source природа Hadoop делает его привлекательным для cost-sensitive проектов, особенно в сравнении с enterprise cloud решениями, стоимость которых может быстро масштабироваться с ростом объемов данных.
Выбор оптимальной технологии должен основываться на специфических требованиях проекта, а не на следовании модным трендам. Хадуп продолжает оставаться жизнеспособным решением для многих сценариев, особенно в комбинации с современными инструментами из его экосистемы.
Примеры реальных кейсов
Теоретические преимущества Hadoop становятся по-настоящему понятными при рассмотрении конкретных случаев его применения в крупных организациях. Эти кейсы демонстрируют не только техническую состоятельность платформы, но и ее способность решать критические бизнес-задачи с измеримым экономическим эффектом.
Yahoo: пионер промышленного внедрения
Yahoo сыграла ключевую роль в развитии Хадуп, и их опыт остается одним из наиболее показательных примеров масштабного внедрения. К 2012 году компания эксплуатировала кластер из более чем 40 000 узлов, обрабатывающий свыше 500 петабайт данных.
Основной задачей было создание персонализированного поискового опыта и рекламных рекомендаций для сотен миллионов пользователей. Hadoop позволил консолидировать данные о поисковых запросах, кликах по ссылкам, демографической информации и поведенческих паттернах в единую аналитическую платформу. Результатом стало повышение релевантности поисковой выдачи на 30% и увеличение кликабельности рекламных блоков на 25%.
Экономический эффект проявился в снижении затрат на инфраструктуру более чем в 10 раз по сравнению с альтернативными решениями того времени. При этом время обработки ежедневных аналитических задач сократилось с 26 часов до 2,5 часов.
Facebook*: социальные данные в петабайтном масштабе
Facebook столкнулась с уникальной задачей: обработка социального графа, включающего миллиарды связей между пользователями, их контентом и взаимодействиями. К 2014 году data warehouse компании на базе Hadoop хранил более 300 петабайт информации и обрабатывал свыше 600 терабайт новых данных ежедневно.
Ключевым применением стала оптимизация новостной ленты (News Feed) — алгоритма, который определяет, какой контент видит каждый пользователь. Hadoop позволил анализировать факторы релевантности постов в режиме, близком к реальному времени: отношения между пользователями, историю взаимодействий, тип контента, время публикации, географическое расположение.
Результатом стало увеличение времени, проводимого пользователями в социальной сети, на 40%, что напрямую отразилось на рекламной выручке. Система также обеспечила обнаружение спама и фейковых аккаунтов с точностью свыше 95%, значительно улучшив качество платформы.
*принадлежит компании Meta, деятельность которой признана экстремистской в РФ
The New York Times: цифровая трансформация медиа
The New York Times использовала Хадуп для решения задачи, которая казалась практически невыполнимой традиционными методами: оцифровка и индексация архива статей за 150 лет существования издания. Проект включал обработку 11 миллионов статей в различных форматах.
Используя Amazon EC2 и Hadoop, команда из 100 виртуальных машин обработала 4 терабайта TIFF-изображений за 24 часа, создав PDF-файлы с возможностью поиска. Стоимость проекта составила менее $240, что в тысячи раз меньше альтернативных вариантов обработки.
Успех этого проекта открыл новые возможности для монетизации архивных материалов и создания premium подписок с доступом к историческому контенту.
JPMorgan Chase: управление финансовыми рисками
Один из крупнейших американских банков внедрил Hadoop для трансформации систем управления рисками после финансового кризиса 2008 года. Основной задачей было создание unified view всех рисковых позиций банка в режиме реального времени.
Хадуп консолидировал данные из более чем 3000 различных систем: торговых платформ, кредитных систем, регуляторной отчетности, рыночных data feeds. Ежедневно обрабатывалось свыше 50 терабайт транзакционных данных для расчета Value-at-Risk, stress testing и регуляторной отчетности.
Критическим достижением стало сокращение времени подготовки ежедневных рисковых отчетов с 8 часов до 30 минут. Это позволило трейдерам получать актуальную информацию о рисках портфеля в начале торгового дня, что существенно улучшило качество принимаемых решений.
Walmart: оптимизация retail операций
Walmart, крупнейший ритейлер в мире, использует Hadoop для анализа данных от 20 000 магазинов, обслуживающих 200 миллионов клиентов еженедельно. Система обрабатывает 2,5 петабайта данных, включая транзакции, движение товаров, данные о ценах конкурентов, погодную информацию.
Одним из ключевых применений стала оптимизация ассортимента в зависимости от локальных предпочтений и сезонных факторов. Алгоритмы машинного обучения анализируют корреляции между погодными условиями и продажами определенных категорий товаров, позволяя автоматически корректировать заказы для каждого магазина.
Результатом стало сокращение излишков товарных запасов на 10% при одновременном снижении случаев out-of-stock на 15%. Экономический эффект составил свыше $2 миллиардов ежегодно только от оптимизации supply chain.
Ключевые факторы успеха
Анализ successful implementations выявляет несколько критических факторов:
Четкое определение бизнес-целей предшествует техническому внедрению. Организации, которые начинают с конкретных измеримых задач, достигают лучших результатов, чем те, кто внедряет технологию ради самой технологии.
Поэтапный подход позволяет минимизировать риски и накапливать экспертизу. Начало с pilot проектов и постепенное масштабирование оказывается более эффективным, чем попытки революционных изменений.
Инвестиции в персонал часто оказываются более критическими, чем инвестиции в инфраструктуру. Успешные организации создают dedicated команды data engineers и data scientists, а также обеспечивают training существующих специалистов.
Эти реальные кейсы демонстрируют, что Hadoop — не просто технологическое решение, а инструмент бизнес-трансформации, способный создавать устойчивые конкурентные преимущества при правильном применении.
Заключение
Наше исследование экосистемы Apache Hadoop охватило широкий спектр аспектов — от фундаментальных архитектурных принципов до практических применений в различных отраслях. Мы рассмотрели, как платформа эволюционировала от экспериментального проекта до основы современных аналитических систем крупнейших корпораций, изучили ее компоненты и смежные технологии, проанализировали реальные кейсы внедрения и сравнили с современными альтернативами. Подведем итоги:
- Apache Hadoop — экосистема больших данных. Она решает задачи хранения и распределённой обработки на обычных серверах.
- Базовые компоненты — HDFS, YARN, MapReduce, Common. Их связка даёт отказоустойчивость, масштабирование и единые настройки.
- HDFS — распределённая ФС с репликацией. Она оптимизирована под последовательное чтение крупных файлов и устойчивость к сбоям.
- YARN — менеджер ресурсов кластера. Он изолирует вычисления в контейнерах и поддерживает разные планировщики.
- MapReduce — модель batch-обработки. Она делит вычисления на этапы Map/Shuffle/Reduce и масштабируется горизонтально.
- Экосистема дополняется Hive, Pig, HBase, Spark. Эти инструменты расширяют SQL-анализ, ETL, NoSQL и in-memory вычисления.
- Data Lake на Hadoop — «schema-on-read». Он объединяет batch и stream, поддерживая гибридные архитектуры (Lambda).
- Бизнес-ценность — снижаются затраты и растёт скорость аналитики. Решаются задачи персонализации, скоринга, IoT и мониторинга.
- Выбор технологии зависит от целей и задержек. Hadoop сочетают со Spark, Kafka, Flink в современных платформах данных.
Если вы только начинаете осваивать аналитику данных, рекомендуем обратить внимание на подборку курсов по системной аналитике. В них есть теоретическая и практическая часть, чтобы быстро перейти от базовой архитектуры к реальным кейсам. Такая программа поможет уверенно работать с HDFS, YARN и Spark.
Рекомендуем посмотреть курсы по системной аналитике
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Аналитик данных
|
Eduson Academy
114 отзывов
|
Цена
109 900 ₽
|
От
9 158 ₽/мес
Беспроцентная. На 1 год.
|
Длительность
6 месяцев
|
Старт
17 марта
|
Подробнее |
|
Системный аналитик PRO
|
Нетология
46 отзывов
|
Цена
79 800 ₽
140 000 ₽
с промокодом kursy-online
|
От
3 500 ₽/мес
Рассрочка на 2 года.
|
Длительность
10 месяцев
|
Старт
13 апреля
|
Подробнее |
|
Системный аналитик с нуля
|
Stepik
33 отзыва
|
Цена
4 500 ₽
|
|
Длительность
1 неделя
|
Старт
в любое время
|
Подробнее |
|
Системный аналитик с нуля до PRO
|
Eduson Academy
114 отзывов
|
Цена
109 900 ₽
257 760 ₽
Ещё -12% по промокоду
|
От
4 579 ₽/мес
10 740 ₽/мес
|
Длительность
6 месяцев
|
Старт
в любое время
|
Подробнее |

Яндекс Практикум vs GeekBrains: фронтенд — где лучше база и где быстрее выход на первые проекты
Ищете лучший курс по фронтенду, но не знаете, какой выбрать? В нашей статье вы найдете подробное сравнение программ Яндекс Практикума и GeekBrains — прочитайте и выберите подходящий курс для своего старта!

Яндекс Практикум vs Нетология: аналитик — где больше практики по требованиям и моделям
Выбираете между Яндекс Практикумом и Нетологией для обучения системному анализу? В статье разбираем курсы системного аналитика: сколько практики дают школы, какие проекты входят в программу и где лучше изучать требования, BPMN и UML.

Яндекс Практикум vs OTUS: DevOps — где больше лабораторных и настоящих задач
DevOps-обучение в Яндекс Практикуме и OTUS часто сравнивают, но где студент действительно работает с инфраструктурой и CI/CD? Разбираем задания, проекты и формат обучения, чтобы понять, какие навыки дают курсы.

Яндекс Практикум vs Skillfactory: какой курс по Data Science выбрать
Skillfactory и Яндекс Практикум предлагают похожие курсы Data Science, но обучение на них устроено по-разному. Где больше практики, где сильнее менторская поддержка и на какой платформе проще собрать портфолио проектов? Разбираем реальные различия курсов, формат занятий и нагрузку.