Что такое SQL-подзапросы и как с ними работать
Представьте ситуацию: вам нужно найти всех сотрудников с зарплатой выше средней по компании. Казалось бы, простая задача, но одним обычным запросом её не решить — сначала нужно вычислить среднее значение, а затем использовать его для фильтрации. Именно здесь на помощь приходят SQL-подзапросы — мощный инструмент, который позволяет вкладывать один запрос в другой.
В этом курсе мы разберём, что такое подзапросы, где их применять и как избежать типичных ошибок. Вы узнаете о различных типах вложенных запросов, познакомитесь с их ограничениями и научитесь оптимизировать производительность. Готовы погрузиться в мир сложных SQL-конструкций?
- Что такое подзапрос в SQL
- Зачем использовать подзапросы
- Где можно применять подзапросы
- Коррелированные подзапросы
- Ограничения и подводные камни
- Подзапрос или JOIN/CTE — что выбрать?
- Как улучшить производительность при работе с подзапросами
- Заключение
- Рекомендуем посмотреть курсы по SQL
Что такое подзапрос в SQL
Подзапрос (или вложенный запрос) — это SELECT-запрос, помещённый внутри другого SQL-оператора. Внешний запрос использует результат выполнения внутреннего запроса для своей работы. Подзапрос всегда заключается в круглые скобки и выполняется в первую очередь.
SELECT employee_name, salary FROM employees WHERE salary > ( SELECT AVG(salary) FROM employees );
Основные характеристики подзапросов:
- Всегда используют SELECT — подзапрос не может быть UPDATE, INSERT или DELETE.
- Могут размещаться в различных частях запроса — WHERE, HAVING, FROM, SELECT.
- Всегда заключаются в скобки — это обязательное синтаксическое требование.
- Выполняются до основного запроса — результат становится частью внешнего оператора.
В отличие от обычного запроса, подзапрос не возвращает данные напрямую пользователю, а передаёт их для дальнейшей обработки во внешний запрос.
Типы возвращаемых результатов подзапросов
Понимание того, какой тип результата возвращает подзапрос, критически важно для правильного использования операторов SQL. Каждый тип подзапроса совместим только с определёнными операторами сравнения и логическими конструкциями.
Скалярный подзапрос
Скалярный подзапрос возвращает одно значение (одна строка, один столбец). Это самый распространённый тип, который можно использовать с операторами сравнения =, >, <, >=, <=, <>.
-- Сотрудники с зарплатой выше средней SELECT employee_name, salary FROM employees WHERE salary > ( SELECT AVG(salary) FROM employees ); -- Добавляем вычисляемую колонку с общим количеством заказов SELECT customer_name, (SELECT COUNT(*) FROM orders WHERE customer_id = customers.id) as total_orders FROM customers; ULL в зарплатах
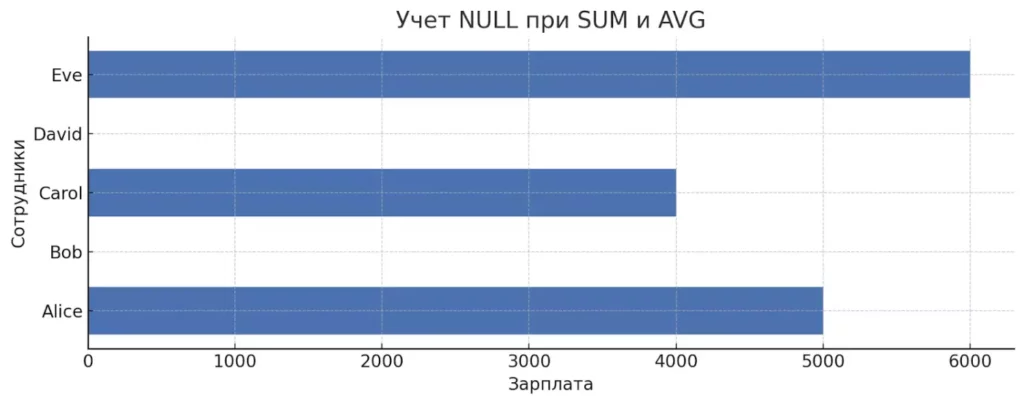
Горизонтальная диаграмма показывает сотрудников с известной и неизвестной зарплатой. NULL-значения визуализированы серым цветом и не участвуют в расчёте среднего. Это важно учитывать при написании подзапросов, использующих агрегатные функции.
Табличный подзапрос
Табличный подзапрос возвращает несколько строк и столбцов, фактически представляя собой временную таблицу. Используется в операторах FROM и требует обязательного псевдонима.
-- Анализ средней зарплаты по отделам SELECT dept_name, avg_salary, employee_count FROM ( SELECT department_id, AVG(salary) as avg_salary, COUNT(*) as employee_count FROM employees GROUP BY department_id ) AS dept_stats JOIN departments d ON dept_stats.department_id = d.id;
Подзапрос с множественным результатом
Возвращает несколько значений в одном столбце (несколько строк, один столбец). Совместим с операторами IN, ANY, ALL, EXISTS и их отрицаниями.
-- Товары из категорий с высокими продажами SELECT product_name, price FROM products WHERE category_id IN ( SELECT category_id FROM sales GROUP BY category_id HAVING SUM(amount) > 100000 ); -- Сотрудники из отделов с зарплатой выше любой в IT SELECT employee_name, salary FROM employees WHERE salary > ANY ( SELECT salary FROM employees WHERE department = 'IT' );
Совместимость операторов с типами результатов
| Тип результата | Совместимые операторы | Пример использования |
| Скалярный | =, >, <, >=, <=, <> | WHERE price > (SELECT AVG(price)…) |
| Множественный | IN, ANY, ALL, EXISTS | WHERE id IN (SELECT customer_id…) |
| Табличный | FROM (с псевдонимом) | FROM (SELECT * FROM…) AS temp |
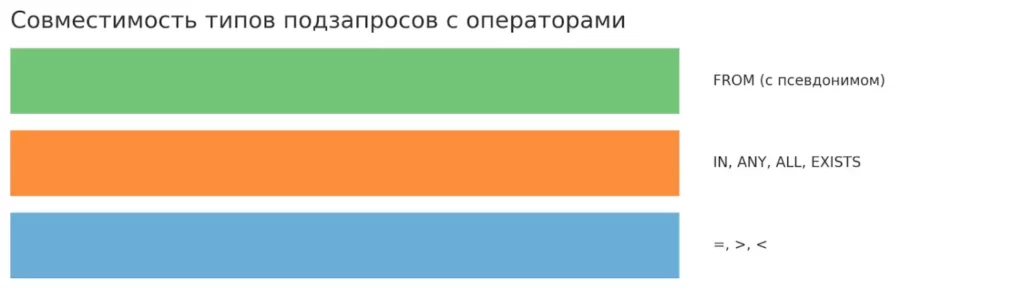
Диаграмма показывает, какие операторы можно использовать с каждым типом подзапроса. Скалярные подзапросы совместимы с операторами сравнения, множественные — с IN, ANY, ALL, EXISTS, а табличные — только в FROM. Это наглядно помогает избежать синтаксических ошибок.
Типичные ошибки совместимости
-- ОШИБКА: множественный результат с оператором = SELECT name FROM products WHERE price = (SELECT price FROM sales); -- может вернуть несколько значений -- ПРАВИЛЬНО: используем агрегацию для получения скалярного результата SELECT name FROM products WHERE price = (SELECT MAX(price) FROM sales); -- ОШИБКА: табличный подзапрос без псевдонима SELECT * FROM (SELECT id, name FROM customers); -- ПРАВИЛЬНО: с псевдонимом SELECT * FROM (SELECT id, name FROM customers) AS c;
Правильное определение типа результата подзапроса поможет избежать синтаксических ошибок и выбрать оптимальный оператор для решения задачи.
Зачем использовать подзапросы
Подзапросы решают задачи, которые невозможно выполнить одним простым запросом. Давайте рассмотрим основные преимущества их использования:
- Экономия кода и упрощение логики — вместо написания нескольких отдельных запросов мы объединяем их в один, что делает код более компактным и логически связанным.
- Повышение читаемости — подзапросы формируют блоки с понятной структурой, где каждый уровень вложенности решает конкретную подзадачу.
- Динамическая фильтрация — возможность использовать результаты вычислений (например, среднее значение) для фильтрации данных в реальном времени.
- Переиспользование кода — один внешний запрос можно использовать с разными подзапросами в зависимости от задачи.
- Аналитические возможности — подзапросы незаменимы для сложных аналитических задач, где нужно сравнивать значения с агрегированными данными.
Без подзапросов многие аналитические задачи потребовали бы создания временных таблиц или выполнения множественных запросов с ручной обработкой промежуточных результатов.
Где можно применять подзапросы
Подзапросы можно размещать в различных частях SQL-запроса, каждое местоположение имеет свои особенности и области применения.
Примеры подзапросов в WHERE
Наиболее частое применение — фильтрация данных на основе результата подзапроса:
SELECT product_name, price FROM products WHERE price > ( SELECT AVG(price) FROM products );
Примеры подзапросов в FROM
Подзапрос выступает как временная таблица, требует обязательного псевдонима:
SELECT dept_name, avg_salary FROM ( SELECT department_id, AVG(salary) as avg_salary FROM employees GROUP BY department_id ) AS dept_stats JOIN departments ON dept_stats.department_id = departments.id;
Примеры подзапросов в SELECT
Подзапрос становится дополнительной колонкой в результате:
SELECT customer_name, (SELECT COUNT(*) FROM orders WHERE customer_id = customers.id) as order_count FROM customers;
Примеры подзапросов в HAVING
Фильтрация агрегированных данных:
SELECT department_id, AVG(salary) FROM employees GROUP BY department_id HAVING AVG(salary) > ( SELECT AVG(salary) FROM employees );
| Место | Когда удобно | Особенности |
|---|---|---|
| WHERE | Фильтрация по скалярным значениям | Может возвращать одно значение или список |
| FROM | Работа с агрегированными данными | Требует псевдоним, возвращает таблицу |
| SELECT | Добавление вычисляемых колонок | Должен возвращать одно значение |
| HAVING | Фильтрация групп | Работает с агрегатными функциями |
Коррелированные подзапросы
Коррелированный подзапрос — это особый тип вложенного запроса, который ссылается на данные из внешнего запроса. В отличие от обычных подзапросов, которые выполняются один раз, коррелированные выполняются для каждой строки внешнего запроса.
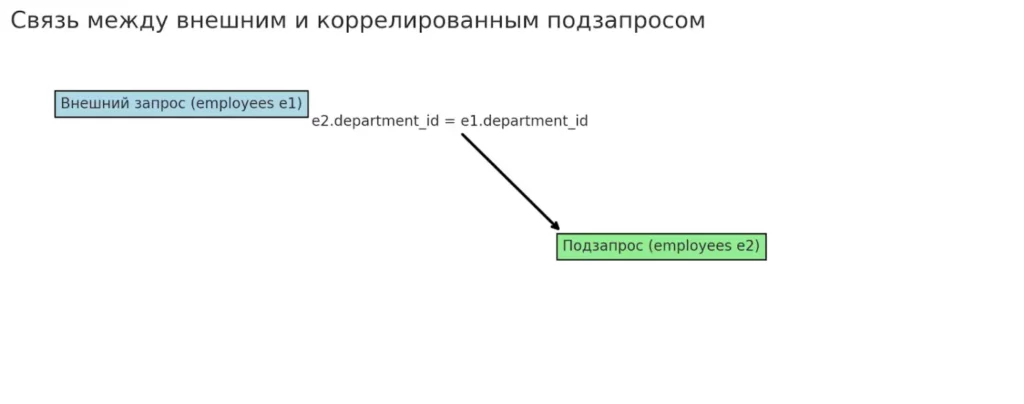
Схема иллюстрирует, как подзапрос внутри SQL-запроса (employees e2) ссылается на данные из внешнего уровня (employees e1). Такая связь делает запрос зависимым от каждой строки внешнего результата, что влияет на производительность.
SELECT employee_name, salary FROM employees e1 WHERE salary > ( SELECT AVG(salary) FROM employees e2 WHERE e2.department_id = e1.department_id );
Этот запрос находит сотрудников с зарплатой выше средней по их отделу.
SELECT customer_name FROM customers c WHERE EXISTS ( SELECT 1 FROM orders o WHERE o.customer_id = c.id AND o.order_date > '2024-01-01' );
Плюсы и минусы коррелированных подзапросов:
Плюсы:
- Позволяют выполнять сложные сравнения на уровне строк.
- Незаменимы для операций EXISTS/NOT EXISTS.
- Логически понятная структура запроса.
Минусы:
- Низкая производительность из-за многократного выполнения.
- Сложность оптимизации для СУБД.
- Потенциальные проблемы с индексацией.
Когда нельзя заменить на JOIN: при использовании EXISTS для проверки существования связанных записей без их извлечения.
Когда лучше заменить: при необходимости объединения данных для дальнейшей обработки.
Ограничения и подводные камни
При работе с подзапросами важно учитывать ряд ограничений, которые могут привести к ошибкам или неожиданному поведению запросов.
| Ограничение | Причина | Как обойти |
|---|---|---|
| Один столбец для операторов сравнения | = , > , < принимают только скалярные значения | Использовать IN, EXISTS или агрегатные функции |
| GROUP BY без возврата одного значения | Нарушает правило скалярности | Добавить агрегатную функцию или убрать GROUP BY |
| ORDER BY только с TOP | Сортировка подзапроса не влияет на результат | Перенести ORDER BY во внешний запрос |
| Несовместимые типы данных | Сравнение текста с числами | Использовать CAST или CONVERT |
| DISTINCT + GROUP BY | Может привести к неопределенному поведению | Использовать только одну из операций |
-- НЕПРАВИЛЬНО: возвращает несколько столбцов SELECT name FROM employees WHERE salary = (SELECT salary, bonus FROM payments); -- ПРАВИЛЬНО: возвращает одно значение SELECT name FROM employees WHERE salary = (SELECT MAX(salary) FROM payments);
Частые ошибки:
-- НЕПРАВИЛЬНО: GROUP BY без агрегации SELECT * FROM products WHERE price > (SELECT price FROM sales GROUP BY product_id); -- ПРАВИЛЬНО: с агрегатной функцией SELECT * FROM products WHERE price > (SELECT AVG(price) FROM sales GROUP BY product_id);
Особое внимание стоит уделить работе с NULL в операторе NOT IN — если подзапрос возвращает NULL, весь результат будет пустым.
Подзапрос или JOIN/CTE — что выбрать?
Часто одну и ту же задачу можно решить несколькими способами. Выбор между подзапросом, JOIN или CTE (Common Table Expression) зависит от конкретной ситуации и требований к производительности.
| Метод | Преимущества | Недостатки | Когда применять |
|---|---|---|---|
| Подзапрос | Логическая понятность, компактность | Может быть медленным, ограничения синтаксиса | Простые фильтрации, проверка существования |
| JOIN | Высокая производительность, гибкость | Сложность при множественных условиях | Объединение данных, работа с большими таблицами |
| CTE | Читаемость, переиспользование, рекурсия | Не всегда поддерживается старыми СУБД | Сложные многоэтапные запросы, иерархические данные |
Пример трансформации подзапроса в JOIN:
-- Подзапрос SELECT e.name, e.salary FROM employees e WHERE e.department_id IN ( SELECT d.id FROM departments d WHERE d.location = 'Moscow' ); -- JOIN (обычно быстрее) SELECT e.name, e.salary FROM employees e JOIN departments d ON e.department_id = d.id WHERE d.location = 'Moscow'; -- CTE (наиболее читаемо) WITH moscow_depts AS ( SELECT id FROM departments WHERE location = 'Moscow' ) SELECT e.name, e.salary FROM employees e JOIN moscow_depts md ON e.department_id = md.id;
Общее правило: используйте подзапросы для логических проверок (EXISTS, NOT EXISTS), JOIN для объединения данных, CTE для сложной многоступенчатой логики.
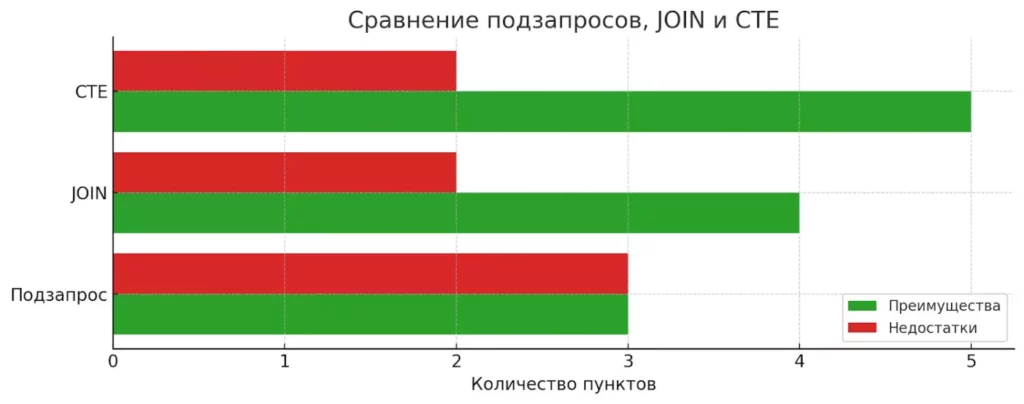
На диаграмме показано, сколько преимуществ и недостатков у каждого подхода. CTE лидирует по числу плюсов (читаемость, переиспользуемость), JOIN — самый сбалансированный, а подзапросы — просты, но могут тормозить выполнение. Визуализация помогает выбрать метод под задачу.
Как улучшить производительность при работе с подзапросами
Подзапросы могут значительно замедлить выполнение запросов, особенно при работе с большими объёмами данных. Рассмотрим основные способы оптимизации.
5 советов по оптимизации подзапросов:
- Избегайте коррелированных подзапросов в циклах — замените их на JOIN или используйте EXISTS вместо IN для проверки существования.
- Применяйте предварительную агрегацию — если подзапрос вычисляет одно и то же значение многократно, вынесите расчёт в отдельную переменную или CTE.
- Создавайте индексы на столбцы в условиях WHERE — особенно важно для столбцов, используемых в коррелированных подзапросах.
- Ограничивайте объём данных в подзапросах — используйте WHERE в подзапросе для фильтрации ненужных строк на раннем этапе.
- Анализируйте план выполнения — используйте EXPLAIN PLAN для понимания того, как СУБД обрабатывает ваш запрос.
-- Неоптимально: коррелированный подзапрос SELECT name FROM customers c WHERE (SELECT COUNT(*) FROM orders o WHERE o.customer_id = c.id) > 5; -- Оптимально: JOIN с агрегацией SELECT DISTINCT c.name FROM customers c JOIN ( SELECT customer_id FROM orders GROUP BY customer_id HAVING COUNT(*) > 5 ) o ON c.id = o.customer_id;
Помните: современные СУБД умеют автоматически оптимизировать многие подзапросы, но знание принципов оптимизации поможет вам писать изначально эффективный код.
Анти-паттерны: когда подзапросы вредят
Несмотря на мощь подзапросов, их неправильное использование может привести к снижению производительности, ухудшению читаемости кода и усложнению поддержки. Рассмотрим типичные анти-паттерны и способы их избежать.
Избыточное усложнение простых задач
Анти-паттерн: Использование подзапросов для задач, которые решаются простым JOIN.
-- ПЛОХО: подзапрос для простого объединения SELECT customer_name FROM customers WHERE id IN ( SELECT customer_id FROM orders WHERE order_date > '2024-01-01' ); -- ХОРОШО: простой JOIN SELECT DISTINCT c.customer_name FROM customers c JOIN orders o ON c.id = o.customer_id WHERE o.order_date > '2024-01-01';
Множественные коррелированные подзапросы
Анти-паттерн: Использование нескольких коррелированных подзапросов в одном запросе, каждый из которых сканирует одну и ту же таблицу.
-- ПЛОХО: множественные коррелированные подзапросы SELECT customer_name, (SELECT COUNT(*) FROM orders o WHERE o.customer_id = c.id) as order_count, (SELECT SUM(total) FROM orders o WHERE o.customer_id = c.id) as total_spent, (SELECT MAX(order_date) FROM orders o WHERE o.customer_id = c.id) as last_order FROM customers c;
-- ХОРОШО: одно объединение с агрегацией SELECT c.customer_name, COALESCE(o.order_count, 0) as order_count, COALESCE(o.total_spent, 0) as total_spent, o.last_order FROM customers c LEFT JOIN ( SELECT customer_id, COUNT(*) as order_count, SUM(total) as total_spent, MAX(order_date) as last_order FROM orders GROUP BY customer_id ) o ON c.id = o.customer_id;
Подзапросы вместо EXISTS для проверки существования
Анти-паттерн: Использование COUNT(*) в подзапросе для проверки существования записей.
-- ПЛОХО: COUNT(*) для проверки существования SELECT customer_name FROM customers c WHERE (SELECT COUNT(*) FROM orders WHERE customer_id = c.id) > 0;
-- ХОРОШО: EXISTS останавливается на первом найденном результате SELECT customer_name FROM customers c WHERE EXISTS (SELECT 1 FROM orders WHERE customer_id = c.id);
Дублирование логики в подзапросах
Анти-паттерн: Повторение одинаковых подзапросов в разных частях кода.
-- ПЛОХО: дублирование подзапроса SELECT product_name, price, CASE WHEN price > (SELECT AVG(price) FROM products) THEN 'Expensive' ELSE 'Affordable' END as price_category FROM products WHERE price > (SELECT AVG(price) FROM products);
-- ХОРОШО: CTE для переиспользования WITH avg_price AS ( SELECT AVG(price) as avg_val FROM products ) SELECT product_name, price, CASE WHEN price > avg_val THEN 'Expensive' ELSE 'Affordable' END as price_category FROM products, avg_price WHERE price > avg_val;
Глубокая вложенность подзапросов
Анти-паттерн: Создание «пирамиды» из множественных уровней вложенности.
—
- ПЛОХО: глубокая вложенность SELECT customer_name FROM customers WHERE id IN ( SELECT customer_id FROM orders WHERE product_id IN ( SELECT id FROM products WHERE category_id IN ( SELECT id FROM categories WHERE name = 'Electronics' ) ) );
-- ХОРОШО: поэтапное решение через CTE WITH electronics_categories AS ( SELECT id FROM categories WHERE name = 'Electronics' ), electronics_products AS ( SELECT id FROM products WHERE category_id IN (SELECT id FROM electronics_categories) ), electronics_orders AS ( SELECT customer_id FROM orders WHERE product_id IN (SELECT id FROM electronics_products) ) SELECT customer_name FROM customers WHERE id IN (SELECT customer_id FROM electronics_orders);
Когда подзапросы оправданы
Подзапросы стоит использовать в следующих случаях:
| Ситуация | Обоснование | Пример |
| Проверка EXISTS/NOT EXISTS | Логически понятнее JOIN | WHERE EXISTS (SELECT 1 FROM…) |
| Скалярные вычисления | Добавление одного значения | SELECT name, (SELECT COUNT(*) FROM…) |
| Сложная бизнес-логика | Когда JOIN усложняет понимание | Многоуровневые условия фильтрации |
Признаки проблемных подзапросов
Красные флаги, указывающие на необходимость рефакторинга:
- Время выполнения запроса значительно увеличилось.
- В одном запросе более 3 уровней вложенности.
- Один и тот же подзапрос повторяется несколько раз.
- Коррелированный подзапрос обращается к таблице с миллионами записей.
- План выполнения показывает полное сканирование таблиц.
Помните: подзапросы — это инструмент, а не цель. Выбирайте подход, который обеспечивает лучший баланс между читаемостью кода и производительностью для вашей конкретной задачи.
Заключение
Подзапросы — это мощный инструмент SQL, который открывает возможности для решения сложных аналитических задач. В этой статье мы рассмотрели основные принципы их работы, области применения и способы оптимизации. Подведем итоги:
- Подзапрос — это вложенный SELECT, работающий внутри основного запроса. Позволяет объединить несколько операций в один блок.
- Существует несколько мест для подзапросов. WHERE, SELECT, FROM и HAVING решают разные задачи.
- Коррелированные подзапросы используют данные из внешнего запроса. Они мощные, но могут замедлить выполнение.
- У подзапросов есть ограничения. Скобки, один столбец в условии, обработка NULL — всё это важно учитывать.
- JOIN и CTE иногда лучше. Используйте их, если запрос становится слишком громоздким.
- Оптимизация — ключ к эффективности. Используйте индексы, агрегации и анализируйте план выполнения.
Только начинаете осваивать профессию аналитика данных? Рекомендуем обратить внимание на курсы по SQL, где подзапросы изучаются и в теории, и на практике. Это поможет быстрее перейти от простых выборок к сложной аналитике.
Рекомендуем посмотреть курсы по SQL
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
SQL с нуля для анализа данных
|
Eduson Academy
110 отзывов
|
Цена
49 900 ₽
|
От
4 158 ₽/мес
Беспроцентная. На 1 год.
|
Длительность
1 месяц
|
Старт
27 февраля
|
Подробнее |
|
Продвинутый SQL
|
Нетология
46 отзывов
|
Цена
41 600 ₽
77 018 ₽
с промокодом kursy-online
|
От
2 567 ₽/мес
Рассрочка на 1 год.
|
Длительность
1 месяц
|
Старт
26 февраля
2 раза в неделю по будням
|
Подробнее |
|
SQL-разработчик
|
Eduson Academy
110 отзывов
|
Цена
79 900 ₽
|
От
6 658 ₽/мес
0% на 12 месяцев
|
Длительность
6 месяцев
|
Старт
2 марта
|
Подробнее |

Этапы разработки мобильного приложения: путь к успешному запуску
Как создать успешное мобильное приложение? В этой статье вы узнаете, как пройти путь от идеи до запуска, избегая распространенных ошибок и ориентируясь на потребности рынка.

Яндекс Практикум против Хекслета: где на самом деле учат кодить, а не просто смотреть видео
Яндекс Практикум против Хекслета — какой формат обучения действительно помогает научиться программировать, а не просто проходить уроки? Разберём практику, код-ревью, темп обучения и реальные результаты студентов — чтобы вы могли выбрать платформу осознанно.

Что такое Axure RP и кому он нужен
Думаете, что Axure это обычная программа для рисования? Ошибаетесь! Узнайте, почему с её помощью прототипировать становится проще и веселее.

Что выбрать: ITSM или ITIL? Ответ для бизнеса
ITSM и ITIL часто упоминаются вместе, но что это такое на самом деле? Узнайте, как эти концепции помогают улучшить IT-услуги и оптимизировать процессы