Что такое тестирование на отказоустойчивость и зачем оно нужно
В современном мире программных решений пользователи ожидают бесперебойной работы систем — от банковских приложений до платформ электронной коммерции. Однако что происходит, когда неизбежное случается: сервер отключается, база данных дает сбой или сетевое соединение прерывается?

Тестирование на отказоустойчивость (Fault Tolerance Testing) представляет собой процесс проверки способности системы продолжать функционировать или корректно восстанавливаться после возникновения различных типов сбоев. Этот вид тестирования позволяет нам оценить, насколько стабильно ведет себя программное обеспечение в экстремальных условиях и может ли оно обеспечить непрерывность бизнес-процессов даже при критических отказах инфраструктуры.
- Зачем проводить тестирование отказоустойчивости
- Какие сбои проверяются при тестировании
- Основные этапы тестирования
- Методы и подходы к тестированию отказоустойчивости
- Примеры сценариев отказоустойчивости
- Распространённые ошибки при тестировании
- Как часто нужно проводить тестирование отказоустойчивости
- Метрики, которые стоит отслеживать
- Инструменты для тестирования отказоустойчивости
- Заключение
- Рекомендуем посмотреть курсы по QA-тестированию
Зачем проводить тестирование отказоустойчивости
В эпоху цифровой трансформации, когда простой сервиса может стоить компании миллионы рублей, тестирование отказоустойчивости становится не роскошью, а необходимостью. Давайте разберемся, почему современный бизнес не может позволить себе игнорировать этот аспект качества ПО.
Ключевые преимущества для бизнеса:
- Защита репутации — предотвращение потери доверия клиентов из-за неожиданных сбоев.
- Минимизация финансовых потерь — снижение убытков от простоя критически важных систем.
- Соответствие SLA — гарантия выполнения обязательств по доступности сервиса.
- Конкурентное преимущество — повышение надежности как фактор выбора клиентами.
- Предотвращение каскадных отказов — защита от ситуаций, когда сбой одного компонента приводит к отказу всей системы.
Какие сбои проверяются при тестировании
При тестировании отказоустойчивости мы имитируем широкий спектр потенциальных проблем, с которыми может столкнуться система в реальных условиях эксплуатации. Рассмотрим основные категории сбоев, которые должны быть покрыты комплексным тестированием.
Отказ оборудования
Аппаратные сбои остаются одной из наиболее критичных угроз для стабильности системы. Мы тестируем отказы жестких дисков, блоков питания, серверов и сетевого оборудования. Особое внимание уделяется проверке механизмов автоматического переключения на резервные компоненты и процедур восстановления данных.
Сетевые сбои
Нестабильность сетевых соединений может проявляться в различных формах: от полного обрыва связи до высокой латентности или потери пакетов. Тестирование включает симуляцию разрыва соединений между микросервисами, проблем с DNS-резолюцией и сбоев в работе балансировщиков нагрузки.
Ошибки программного обеспечения
Программные сбои могут возникать на любом уровне стека: от операционной системы до прикладного ПО. Мы проверяем поведение системы при критических исключениях, утечках памяти, зависаниях процессов и некорректной обработке входных данных.
Проблемы с базами данных
База данных часто становится единой точкой отказа в архитектуре приложения. Тестируется отказ основной БД, проблемы с репликацией, блокировки транзакций и сценарии восстановления из резервных копий.
Повышенная нагрузка и сбои при масштабировании
Системы должны корректно обрабатывать ситуации, когда нагрузка превышает плановые показатели. Проверяется работа механизмов автомасштабирования, деградации функциональности и поведение при исчерпании ресурсов.
| Тип отказа | Примеры | Ожидаемая реакция системы |
|---|---|---|
| Отказ диска | Повреждение HDD/SSD | Переключение на RAID, уведомление администратора |
| Сетевой сбой | Обрыв соединения | Использование резервных каналов, retry-механизмы |
| Сбой ПО | Критическое исключение | Restart сервиса, логирование ошибки |
| Отказ БД | Недоступность master-сервера | Переключение на replica, режим только чтения |
| Перегрузка | Превышение лимитов CPU/RAM | Throttling, горизонтальное масштабирование |
Основные этапы тестирования
Эффективное тестирование отказоустойчивости требует системного подхода и четкого планирования. Давайте рассмотрим ключевые этапы, которые обеспечивают комплексную проверку устойчивости системы к различным типам сбоев.
Анализ требований и рисков
На начальном этапе мы определяем критически важные компоненты системы и потенциальные точки отказа. Проводится анализ архитектуры приложения, выявляются зависимости между сервисами и оценивается влияние возможных сбоев на бизнес-процессы. Особое внимание уделяется изучению SLA и требований к доступности системы.
Проектирование сценариев отказа
На основе результатов анализа рисков разрабатываются детальные тестовые сценарии. Каждый сценарий описывает конкретный тип сбоя, условия его возникновения, ожидаемое поведение системы и критерии успешного прохождения теста. Важно учесть как изолированные отказы, так и комбинированные сценарии.
Настройка среды и инфраструктуры
Подготавливается тестовая среда, максимально приближенная к продуктивной. Настраиваются инструменты для мониторинга, логирования и симуляции отказов. Особое внимание уделяется обеспечению безопасности тестирования — недопустимо, чтобы тесты повлияли на работу реальных пользователей.
Выполнение тестов
Проводится последовательное выполнение разработанных сценариев с детальным документированием всех наблюдаемых эффектов. Фиксируется время восстановления системы, корректность работы механизмов резервирования и качество пользовательского опыта в условиях деградации функциональности.
Сбор и анализ результатов
После завершения тестирования проводится комплексный анализ полученных данных. Выявляются узкие места в архитектуре, оценивается эффективность механизмов восстановления и формулируются рекомендации по улучшению отказоустойчивости системы.
Повторное тестирование после исправлений
После внесения изменений в код или инфраструктуру проводится повторная проверка для подтверждения устранения выявленных проблем. Этот итеративный процесс продолжается до достижения требуемого уровня отказоустойчивости.
Последовательность этапов:
- Анализ архитектуры и выявление рисков.
- Разработка матрицы тестовых сценариев.
- Подготовка изолированной тестовой среды.
- Выполнение сценариев отказов с мониторингом.
- Анализ метрик и формирование отчета.
- Проверка исправлений и регрессионное тестирование.
Методы и подходы к тестированию отказоустойчивости
Современное тестирование отказоустойчивости использует разнообразные методы — от классического ручного моделирования до автоматизированных платформ хаос-инжиниринга. Выбор подходящего метода зависит от архитектуры системы, доступных ресурсов и требований к глубине тестирования.
Ручное моделирование
Традиционный подход предполагает преднамеренное воздействие на систему для симуляции отказов. Это может включать физическое отключение серверов, прерывание сетевых соединений или завершение критически важных процессов. Несмотря на кажущуюся простоту, ручное тестирование требует высокой квалификации инженеров и тщательного планирования для предотвращения непредвиденных последствий.
Автоматизация через специализированные инструменты
Автоматизированные решения, такие как Chaos Monkey от Netflix или Gremlin, позволяют проводить контролируемые эксперименты в продуктивной среде. Эти инструменты могут случайным образом завершать процессы, создавать искусственную латентность или имитировать отказы целых зон доступности, при этом обеспечивая безопасность экспериментов.
Интеграция с нагрузочным и стресс-тестированием
Наиболее реалистичные результаты достигаются при комбинировании тестирования отказоустойчивости с нагрузочным тестированием. Использование инструментов вроде JMeter или Gatling в сочетании с симуляцией сбоев позволяет оценить поведение системы в условиях, максимально приближенных к реальным пиковым нагрузкам.
| Метод | Когда применяется | Преимущества |
|---|---|---|
| Ручное моделирование | Начальные этапы, критичные компоненты | Полный контроль, детальный анализ |
| Chaos Engineering | Продуктивная среда, микросервисы | Реалистичность, минимум вмешательства |
| Комбинированное тестирование | Перед релизами, при изменении архитектуры | Максимальное покрытие сценариев |
| Автоматизированные платформы | Регулярное тестирование, CI/CD | Повторяемость, интеграция в процессы |
Современные подходы все чаще склоняются к философии «chaos engineering» — дисциплине проведения экспериментов в распределенных системах для построения уверенности в способности системы противостоять турбулентным условиям в продуктивной среде.
Примеры сценариев отказоустойчивости
Практическое тестирование отказоустойчивости строится вокруг конкретных сценариев, которые моделируют реальные проблемы, с которыми может столкнуться система. Рассмотрим наиболее распространенные и критически важные тестовые случаи, применяемые в современной практике QA-инжиниринга.
Основные сценарии тестирования:
- Внезапное отключение основного сервера приложений — проверка автоматического переключения трафика на резервные инстансы и сохранения пользовательских сессий.
- Сбой в работе базы данных — тестирование переключения на slave-реплику, поведения приложения в режиме только чтения и процедур восстановления.
- Разрыв сетевого соединения между микросервисами — оценка работы circuit breaker‘ов, retry-механизмов и fallback-стратегий.
- Исчерпание дискового пространства — проверка алертов, процедур очистки логов и деградации функциональности.
- Превышение лимитов памяти и CPU — тестирование механизмов throttling, автомасштабирования и приоритизации запросов.
- Отказ внешних API и интеграций — проверка таймаутов, кэширования и альтернативных источников данных.
- Сбой в системе мониторинга — тестирование работы резервных каналов оповещения и процедур эскалации.
- Повреждение конфигурационных файлов — проверка валидации настроек и возврата к безопасным значениям по умолчанию.
- Атака типа DDoS — тестирование rate limiting, фильтрации трафика и работы CDN.
- Сбой в DNS-серверах — проверка кэширования DNS-записей и использования альтернативных резолверов.
- Отказ системы логирования — тестирование буферизации логов и альтернативных каналов записи.
- Сбой в процессе развертывания — проверка механизмов rollback и blue-green deployment.
Ожидаемое поведение системы:
При каждом сценарии система должна демонстрировать предсказуемое поведение: автоматическое обнаружение проблемы, активацию резервных механизмов, уведомление администраторов и, при необходимости, корректную деградацию функциональности без полной потери работоспособности. Критически важно, чтобы пользователи получали понятные сообщения об ошибках, а не сталкивались с неинформативными техническими исключениями.
Распространённые ошибки при тестировании
Даже опытные команды разработки могут допускать критические просчеты при планировании и проведении тестирования отказоустойчивости. Понимание этих типичных ошибок поможет избежать ложного чувства безопасности и обеспечить действительно качественную проверку системы.
Основные ошибки и их последствия:
- Отсутствие изоляции тестовой среды — проведение экспериментов с отказами в среде, связанной с продуктивными системами, что может привести к непредвиденным сбоям в работе реальных пользователей.
- Неполное покрытие сценариев — фокусировка только на очевидных отказах (например, падение сервера) при игнорировании более тонких проблем, таких как медленные запросы к базе данных или частичная деградация сети.
- Игнорирование логирования и мониторинга — недостаточное внимание к качеству логов во время тестирования, что затрудняет последующий анализ инцидентов и понимание причинно-следственных связей.
- Тестирование только в идеальных условиях — проведение проверок при минимальной нагрузке, что не отражает реальное поведение системы в пиковые периоды.
- Отсутствие тестирования каскадных отказов — проверка изолированных сбоев без учета того, как один отказ может спровоцировать цепочку проблем в связанных компонентах.
- Недооценка человеческого фактора — игнорирование того, как операционная команда будет реагировать на алерты и проводить восстановительные процедуры в стрессовых условиях.
- Отсутствие временных ограничений — проведение тестов без четких временных рамок, что не позволяет оценить скорость восстановления системы.
- Пренебрежение документированием — недостаточно детальная фиксация результатов тестирования, что усложняет воспроизведение проблем и отслеживание прогресса в устранении выявленных недостатков.
Наш опыт показывает, что наиболее критичные проблемы часто возникают именно на стыке этих ошибок — когда неполное покрытие сценариев сочетается с недостаточным мониторингом в условиях реальной нагрузки.
Как часто нужно проводить тестирование отказоустойчивости
Вопрос периодичности тестирования отказоустойчивости не имеет универсального ответа — он зависит от критичности системы, динамики изменений в архитектуре и требований бизнеса к доступности. Однако существуют общепринятые практики, которые помогают определить оптимальную стратегию тестирования.
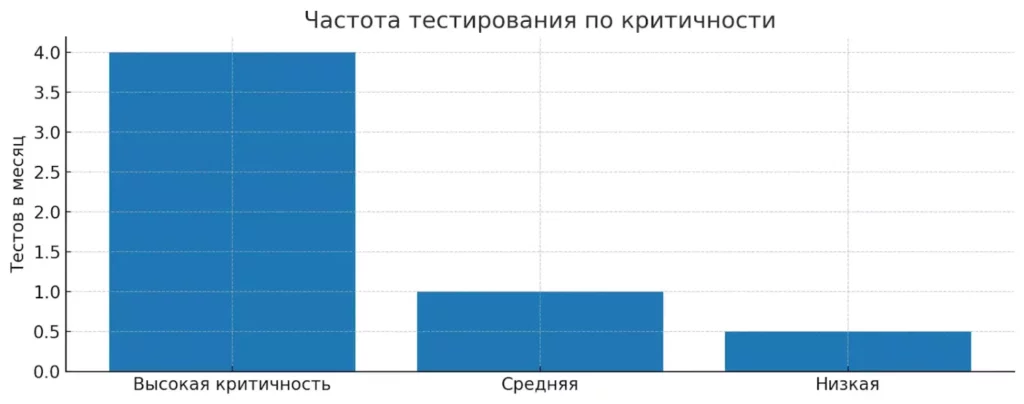
Диаграмма иллюстрирует, как частота тестов зависит от критичности системы. Чем важнее сервис, тем чаще должны проводиться проверки на отказоустойчивость.
Обязательные случаи для проведения тестирования:
- Перед каждым мажорным релизом — любые значительные изменения в архитектуре или критически важных компонентах требуют проверки отказоустойчивости.
- После изменений в инфраструктуре — миграция на новые серверы, изменение конфигурации сети или обновление системного ПО.
- При внедрении новых интеграций — добавление зависимостей от внешних сервисов создает новые точки потенциальных отказов.
- После инцидентов в продуктивной среде — каждый реальный сбой должен стать основой для нового тестового сценария.
- При масштабировании системы — увеличение нагрузки или расширение географии развертывания требует переоценки устойчивости.
Рекомендации по регулярности:
Для критически важных систем (финансовые сервисы, медицинские платформы) мы рекомендуем еженедельное проведение автоматизированных тестов основных сценариев отказов с ежемесячными комплексными проверками. Системы среднего уровня критичности могут ограничиться ежемесячным базовым тестированием с квартальными углубленными проверками.
Важно помнить, что тестирование отказоустойчивости в продуктивной среде (практика chaos engineering) требует особой осторожности и должно проводиться только в системах с высоким уровнем зрелости процессов мониторинга и восстановления. Начинать следует с наименее критичных компонентов в периоды минимальной нагрузки.
Современные DevOps-практики все больше склоняются к интеграции базовых проверок отказоустойчивости в CI/CD пайплайны, что обеспечивает непрерывную валидацию устойчивости системы при каждом изменении кода.
Метрики, которые стоит отслеживать
Эффективное тестирование отказоустойчивости невозможно без четкого понимания того, какие показатели следует измерять и анализировать. Правильно выбранные метрики позволяют не только оценить текущее состояние системы, но и прогнозировать потенциальные проблемы до их возникновения.MTTR и RTO
График демонстрирует снижение времени восстановления (MTTR) и допустимого простоя (RTO) в процессе регулярного тестирования. Это показывает эффективность внедрённых процедур по повышению отказоустойчивости.
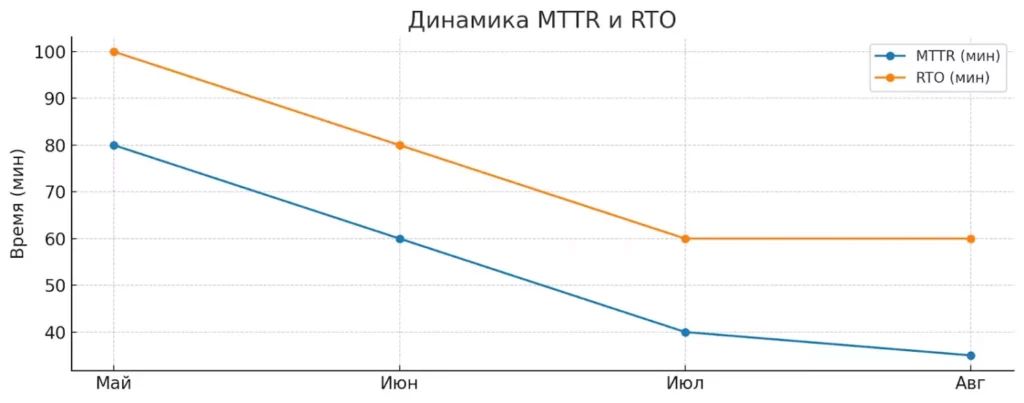
График демонстрирует снижение времени восстановления (MTTR) и допустимого простоя (RTO) в процессе регулярного тестирования. Это показывает эффективность внедрённых процедур по повышению отказоустойчивости.
Ключевые показатели надежности:
MTTR (Mean Time to Recovery) — среднее время восстановления системы после сбоя. Этот показатель критически важен для оценки эффективности процедур восстановления и готовности операционной команды к реагированию на инциденты.
MTBF (Mean Time Between Failures) — среднее время между отказами, которое характеризует общую надежность системы. Увеличение этого показателя указывает на улучшение стабильности архитектуры.
Диаграмма Венна демонстрирует, как соотносятся два ключевых показателя: время между сбоями (MTBF) и время на восстановление (MTTR). Их понимание помогает формировать целостную картину надёжности системы.
RTO (Recovery Time Objective) — максимально допустимое время простоя системы, определяемое бизнес-требованиями. Превышение RTO может привести к серьезным финансовым и репутационным потерям.
RPO (Recovery Point Objective) — максимально допустимый объем потери данных при сбое, измеряемый во времени. Этот показатель особенно критичен для систем, обрабатывающих финансовые транзакции.
| Метрика | Что измеряет | Почему важно |
|---|---|---|
| MTTR | Скорость восстановления | Влияет на общее время простоя и пользовательский опыт |
| MTBF | Частота отказов | Показывает стабильность и качество архитектуры |
| SLA Compliance | Соблюдение уровня сервиса | Определяет выполнение обязательств перед клиентами |
| RTO | Целевое время восстановления | Устанавливает рамки для планирования процедур recovery |
| RPO | Допустимая потеря данных | Определяет требования к частоте резервного копирования |
| Error Rate | Частота ошибок в системе | Индикатор качества работы в нормальных условиях |
Важно отметить, что метрики должны отслеживаться не только во время тестирования, но и в продуктивной среде. Только сопоставление показателей тестовой и реальной эксплуатации позволяет адекватно оценить эффективность проводимых проверок отказоустойчивости.
Инструменты для тестирования отказоустойчивости
Современный рынок предлагает широкий спектр инструментов для проведения тестирования отказоустойчивости — от простых утилит командной строки до комплексных платформ управления хаос-экспериментами. Выбор подходящего решения зависит от архитектуры системы, бюджета и уровня экспертизы команды.
Chaos Monkey — пионер в области chaos engineering, разработанный Netflix. Этот инструмент случайным образом завершает работу виртуальных машин в продуктивной среде, заставляя инженеров создавать более устойчивые системы. Особенно эффективен для облачных архитектур на AWS.
Gremlin — коммерческая платформа, предоставляющая контролируемую среду для проведения экспериментов с отказами. Поддерживает широкий спектр типов атак: от ресурсных (CPU, память, диск) до сетевых (латентность, потеря пакетов).
Chaos Toolkit — открытый инструмент с декларативным подходом к описанию экспериментов. Позволяет создавать воспроизводимые сценарии тестирования и интегрироваться с различными облачными провайдерами и системами оркестрации.
Litmus — cloud-native платформа для Kubernetes, специализирующаяся на тестировании отказоустойчивости контейнеризованных приложений. Предоставляет богатую библиотеку готовых экспериментов для различных сценариев отказов.
Pumba — легковесный инструмент для Docker-контейнеров, позволяющий симулировать сетевые задержки, потери пакетов и сбои контейнеров. Идеально подходит для локальной разработки и тестирования.
| Инструмент | Платформа | Особенности |
|---|---|---|
| Chaos Monkey | AWS, облачные среды | Простота использования, фокус на инфраструктуре |
| Gremlin | Multi-cloud, on-premise | Комплексная платформа, детальная аналитика |
| Chaos Toolkit | Универсальная | Открытый код, декларативный подход |
| Litmus | Kubernetes | Native интеграция с k8s, богатая библиотека |
| Pumba | Docker | Легковесность, подходит для разработки |
| Simian Army | AWS | Расширенный набор «обезьян» от Netflix |
При выборе инструмента важно учитывать не только технические возможности, но и зрелость команды в области chaos engineering. Начинать рекомендуется с простых решений вроде Pumba для локального тестирования, постепенно переходя к более сложным платформам по мере накопления опыта.
Заключение
Тестирование отказоустойчивости давно перестало быть экзотической практикой крупных технологических гигантов — сегодня это неотъемлемая часть культуры качества в любой серьезной разработке. В мире, где цифровые сервисы становятся критически важной инфраструктурой для бизнеса и общества, способность системы элегантно справляться с непредвиденными ситуациями определяет не просто техническое совершенство, но и конкурентное преимущество.
- Тестирование отказоустойчивости проверяет поведение системы при сбоях. Это позволяет выявить уязвимости до того, как они повлияют на пользователей.
- Проверяются разные типы отказов: от сетевых и аппаратных до сбоев в ПО и перегрузок. Такой охват обеспечивает комплексную оценку устойчивости.
- Эффективное тестирование включает анализ архитектуры, разработку сценариев, симуляции отказов и повторную проверку после доработок. Это создаёт замкнутый цикл повышения надёжности.
- Используются как ручные методы, так и автоматизированные инструменты — например, Chaos Monkey или Gremlin. Это даёт гибкость в подходах и уровнях глубины.
- Регулярность тестирования зависит от критичности системы. Чем выше риск последствий отказа, тем чаще должны проводиться проверки.
- Частые ошибки — игнорирование мониторинга, плохая изоляция среды и недостаточная документация. Избежание этих ошибок повышает эффективность тестов.
- Внедрение тестирования отказоустойчивости — это инвестиция в стабильность и доверие. Это особенно важно для систем с высокой нагрузкой и ответственностью.
Если вы только начинаете осваивать профессию тестировщика, рекомендуем обратить внимание на подборку курсов по QA-тестированию. В них есть как теоретические основы, так и практические задания с реальными сценариями, что поможет вам уверенно применить знания на практике.
Рекомендуем посмотреть курсы по QA-тестированию
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Автоматизированное тестирование на Python
|
Eduson Academy
114 отзывов
|
Цена
88 800 ₽
|
От
7 400 ₽/мес
0% на 24 месяца
|
Длительность
6 месяцев
|
Старт
в любое время
|
Подробнее |
|
Тестировщик ПО
|
Нетология
46 отзывов
|
Цена
105 000 ₽
184 200 ₽
с промокодом kursy-online
|
От
3 070 ₽/мес
Без переплат на 2 года.
4 805 ₽/мес
|
Длительность
6 месяцев
|
Старт
20 марта
|
Подробнее |
|
Тестировщик мобильных игр
|
XYZ School
21 отзыв
|
Цена
90 300 ₽
129 000 ₽
Ещё -14% по промокоду
|
От
6 000 ₽/мес
|
Длительность
4 месяца
|
Старт
19 марта
|
Подробнее |
|
Тестировщик ПО
|
Eduson Academy
114 отзывов
|
Цена
110 200 ₽
|
От
4 591 ₽/мес
Беспроцентная. На 1 год.
|
Длительность
4 месяца
|
Старт
6 апреля
|
Подробнее |
|
Профессия Инженер по автоматизации тестирования
|
Skillbox
232 отзыва
|
Цена
138 372 ₽
276 744 ₽
Ещё -20% по промокоду
|
От
5 766 ₽/мес
Без переплат на 2 года.
|
Длительность
4 месяца
|
Старт
19 марта
|
Подробнее |

Яндекс Практикум vs Karpov.Courses: A/B — где понятнее, а где глубже и строже
Выбор между курсами по A/B тестированию от Яндекс Практикум и Karpov может быть непростым. Узнайте, какой из них лучше соответствует вашим целям и ожиданиям. В статье мы детально разберем их особенности, включая теоретическую и практическую части курсов, чтобы помочь вам сделать правильный выбор!

Яндекс Практикум vs GeekBrains: фронтенд — где лучше база и где быстрее выход на первые проекты
Ищете лучший курс по фронтенду, но не знаете, какой выбрать? В нашей статье вы найдете подробное сравнение программ Яндекс Практикума и GeekBrains — прочитайте и выберите подходящий курс для своего старта!

Яндекс Практикум vs Нетология: аналитик — где больше практики по требованиям и моделям
Выбираете между Яндекс Практикумом и Нетологией для обучения системному анализу? В статье разбираем курсы системного аналитика: сколько практики дают школы, какие проекты входят в программу и где лучше изучать требования, BPMN и UML.

Яндекс Практикум vs OTUS: DevOps — где больше лабораторных и настоящих задач
DevOps-обучение в Яндекс Практикуме и OTUS часто сравнивают, но где студент действительно работает с инфраструктурой и CI/CD? Разбираем задания, проекты и формат обучения, чтобы понять, какие навыки дают курсы.