Data Lake: что это, как работает и зачем бизнесу
В современном мире данные стали новой нефтью — и эта метафора становится все более актуальной с каждым днем. Согласно исследованиям IDG, мировой объем данных будет расти в среднем на 23% в год в течение следующих нескольких лет. Компании сталкиваются с настоящим потопом информации: логи веб-серверов, данные IoT-устройств, социальные сети, видеозаписи с камер наблюдения, результаты опросов клиентов. И здесь возникает закономерный вопрос: как все это хранить, не разорившись на инфраструктуре?

Традиционные базы данных и хранилища оказываются неспособными справиться с такими объемами неструктурированной информации. Именно поэтому в арсенале современных компаний появляется концепция Data Lake — «озера данных». Эта статья предназначена для аналитиков, менеджеров и IT-специалистов, которые хотят понять, может ли эта технология решить их проблемы с растущими объемами информации и стоит ли инвестировать в ее внедрение.
Что такое Data Lake простыми словами
Представим, что информация в вашей компании — это вода из разных источников: горные ручьи (CRM-системы), дождевые потоки (логи серверов), подземные воды (архивные документы). Традиционные базы данных работают как водопроводная система — они требуют, чтобы вся вода была предварительно очищена, структурирована и подана по определенным трубам. Data Lake, напротив, представляет собой именно озеро — огромный резервуар, куда можно сливать воду из любых источников в первозданном виде.
Дата Лейк — это архитектурный подход к хранению информации, которая позволяет сохранять ее в исходном формате без предварительной обработки. В отличие от традиционных решений, здесь не нужно заранее определять схему данных или их структуру. Можете загрузить туда CSV-файлы, JSON-документы, изображения, видео, аудиозаписи — озеро примет все.
Ключевая особенность заключается в принципе «схема при чтении» (schema-on-read) вместо «схема при записи» (schema-on-write). Это означает, что структура информации определяется не в момент сохранения, а тогда, когда вы решаете ее использовать. Такой подход радикально снижает барьеры для сохранения информации и позволяет экспериментировать с данными, не зная заранее, как именно они будут применяться.
Чем отличается от других систем хранения
| Параметр | Data Lake | Data Warehouse | Database |
|---|---|---|---|
| Формат | Любой | Структурированный | Структурированный |
| Предобработка | Не нужна | Обязательна | Обязательна |
| Стоимость хранения | Низкая | Выше | Средняя |
| Использование | Big Data, ML | BI, отчёты | Транзакции |
| Время до первого использования | Минимальное | Значительное | Среднее |
| Гибкость структуры | Максимальная | Ограниченная | Ограниченная |
Как видим, каждое решение имеет свою нишу, и “озеро данных” не является универсальной заменой для всех типов хранилищ.
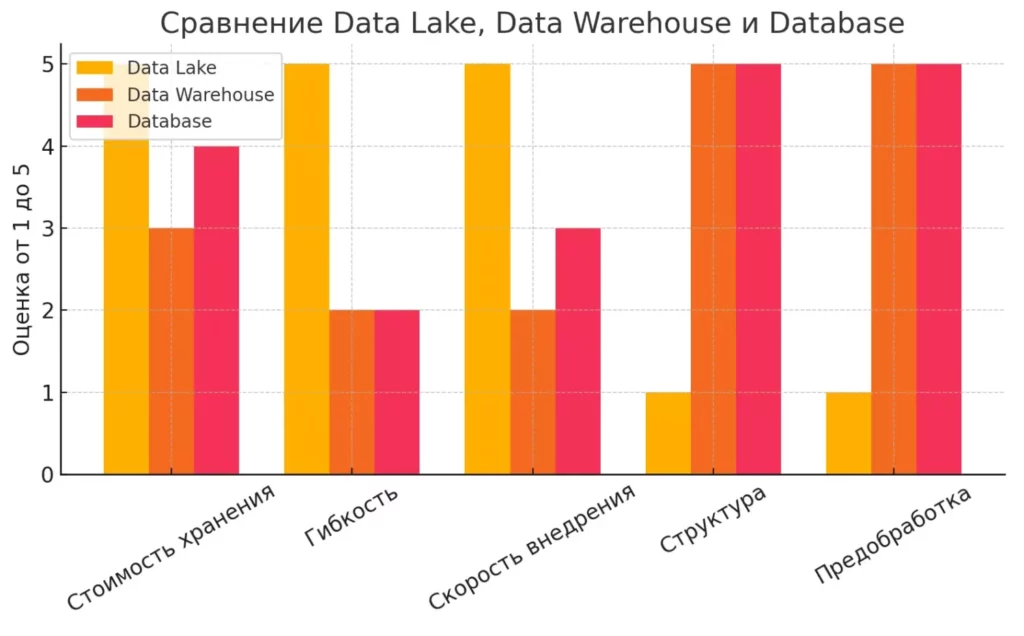
Визуальное сравнение ключевых характеристик трёх типов систем хранения. Помогает понять преимущества и ограничения Data Lake по сравнению с другими решениями.
Архитектура и принципы работы
Давайте разберемся, как устроено озеро изнутри. На первый взгляд может показаться, что это просто большой файловый сервер, но в действительности архитектура Data Lake гораздо сложнее и продуманнее.
Основные компоненты архитектуры
В основе озера лежит распределенная файловая система — чаще всего это Apache Hadoop Distributed File System (HDFS) или облачные решения вроде Amazon S3. Информация физически размещаются на множестве серверов, что обеспечивает горизонтальную масштабируемость. Когда объем информации увеличивается, мы просто добавляем новые узлы в кластер.
Критически важным элементом является система управления метаданными. Без нее озеро быстро превращается в то, что эксперты ядовито называют «болотом данных». Метаданные содержат информацию о происхождении файлов, времени загрузки, формате, схеме и связях между различными наборами информации.
Процесс работы с данными
Рабочий процесс выглядит следующим образом: информация поступает из различных источников через ETL-пайплайны (Extract, Transform, Load), но в отличие от традиционных подходов, здесь реализуется концепция ELT — сначала данные загружаются в исходном виде, а трансформация происходит позднее, при необходимости.
Для извлечения и анализа используются специализированные инструменты. Это может быть Apache Spark для распределенной обработки, Apache Kafka для стриминга данных в реальном времени, или современные ML-платформы вроде Apache Airflow для оркестрации сложных аналитических процессов.
Зонирование и организация информации
Несмотря на кажущуюся хаотичность, в грамотно спроектированном озере существует четкое зонирование. Обычно выделяют несколько слоев: сырые данные (raw zone), данные в процессе обработки (staging zone), очищенные данные (curated zone) и песочница для экспериментов (sandbox). Такая организация позволяет аналитикам и data scientists эффективно работать с информацией, не мешая друг другу.
Возникает закономерный вопрос: не создает ли такая гибкость больше проблем, чем решает? Практика показывает, что успех озера критически зависит от качества управления информацией и культуры ее использования в организации.
Преимущества и недостатки
Как и любая технология, Дата Лейк имеет свои светлые и темные стороны. Давайте рассмотрим их объективно, без маркетинговых прикрас.
Ключевые преимущества
- Главное преимущество озера — это скорость и экономичность загрузки. Вместо того чтобы тратить недели на проектирование схемы базы данных и настройку ETL-процессов, мы можем начать собирать информацию практически мгновенно. Это особенно ценно в эпоху быстро меняющихся требований бизнеса.
- Стоимость хранения — еще один весомый аргумент. Современные облачные решения позволяют хранить петабайты информации за относительно небольшие деньги. По нашим наблюдениям, стоимость хранения в Data Lake может быть в 5-10 раз ниже, чем в традиционных корпоративных хранилищах данных.
- Гибкость использования открывает новые возможности для аналитики. Data scientists могут экспериментировать с различными подходами к анализу, не ограничиваясь заранее определенными моделями данных. Это особенно важно для задач машинного обучения, где структура информации может многократно изменяться в процессе итераций.
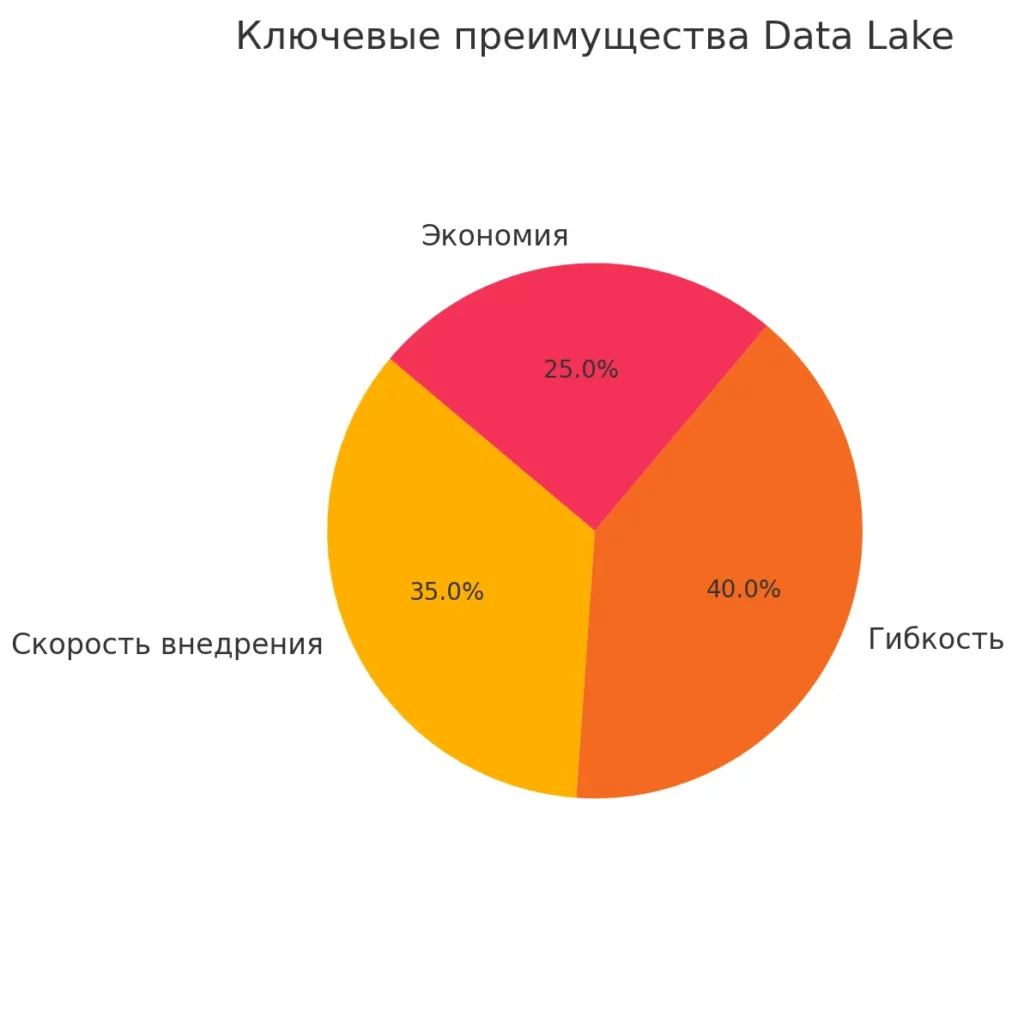
Быстрый обзор основных выгод: гибкость архитектуры, экономия на хранении и ускорение процессов внедрения.
Существенные недостатки
- Однако за все приходится платить. Главная проблема озера — это сложность извлечения и анализа данных. Если в традиционной базе данных вы можете написать SQL-запрос и получить результат, то здесь потребуется целая команда специалистов для подготовки информации к использованию.
- Риск превращения в «болото данных» — это не просто теоретическая угроза. Согласно исследованиям, до 60% проектов DL терпят неудачу именно из-за отсутствия должного управления информацией. Накапливается огромное количество дублей, устаревшей информации и просто мусора.
- Техническая сложность также не должна недооцениваться. Построение и поддержка “озера данных” требует высококвалифицированных инженеров, знакомых с распределенными системами, что в российских реалиях может стать серьезной проблемой.
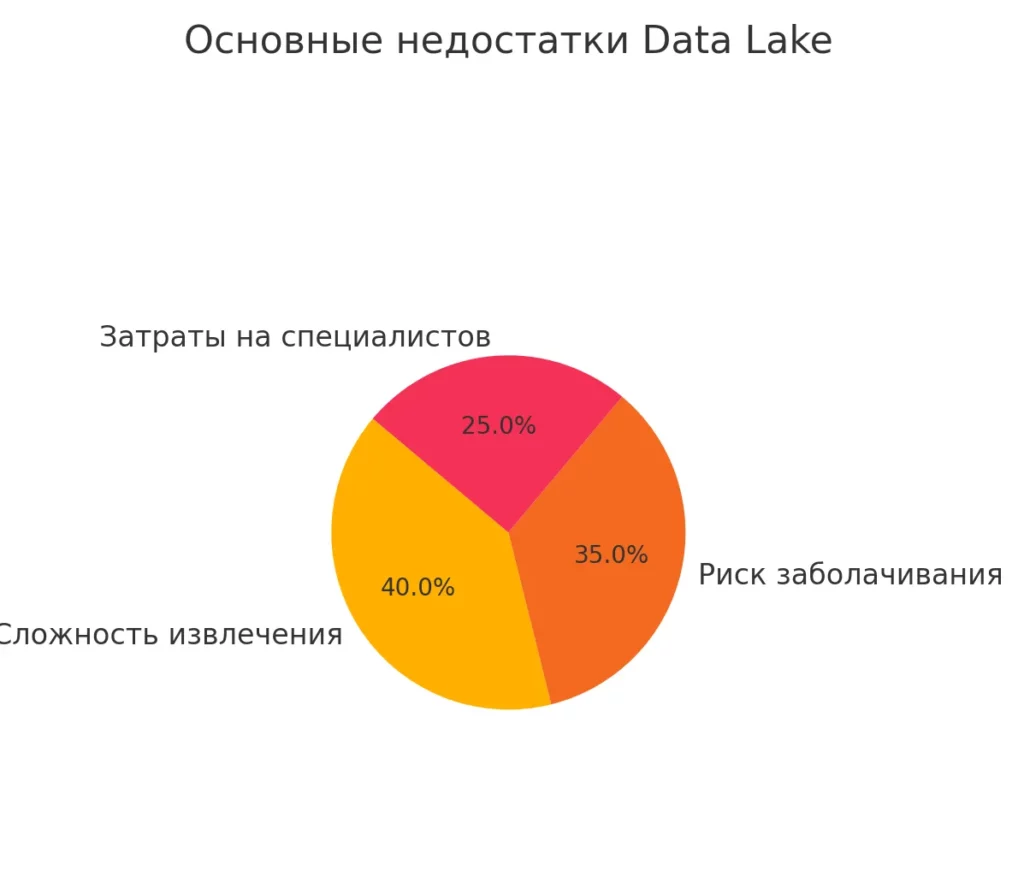
Иллюстрирует риски и скрытые издержки при неправильной реализации или эксплуатации Data Lake.
Скрытые расходы
Многие компании недооценивают расходы на этапе извлечения информации. Низкая стоимость хранения компенсируется высокими затратами на специалистов, инструменты анализа и вычислительные ресурсы. Парадокс заключается в том, что экономия на входе может обернуться значительными тратами на выходе.
Вопрос безопасности также стоит особняком. Когда информация хранится без четкой структуры, сложнее контролировать доступ к конфиденциальной информации и обеспечивать соответствие требованиям регуляторов.
Кому и когда нужен Data Lake
Теперь перейдем к практической стороне вопроса: стоит ли вашей компании инвестировать в “озеро данных”, или это просто дань технологической моде?
Идеальные кандидаты для внедрения
Data Lake — это не универсальное решение, а инструмент для решения вполне конкретных задач. В первую очередь он подходит компаниям, которые работают с большими объемами неструктурированных данных. Речь идет о ретейле с его многоканальной аналитикой, телекоммуникационных компаниях, обрабатывающих петабайты трафика, или финансовых организациях, анализирующих поведение клиентов в реальном времени.
Особенно эффективным “озера” становится для компаний, активно использующих машинное обучение и искусственный интеллект. Современные нейросети требуют огромных объемов разнообразных информации для обучения — от текстов и изображений до временных рядов и графовых структур. Попытка втиснуть все это в реляционную базу данных превратится в настоящий кошмар.
Сценарии использования
Рассмотрим конкретные сценарии, где Data Lake показывает свою эффективность. В e-commerce это может быть анализ поведения пользователей с объединением информации из веб-аналитики, CRM-системы, социальных сетей и отзывов клиентов. В промышленности — предиктивная аналитика на основе данных с IoT-датчиков, логов оборудования и данных о техническом обслуживании.
Интересный пример — персонализация контента в медиа-компаниях. Платформы вроде Netflix или YouTube используют DL для анализа предпочтений пользователей, объединяя данные о просмотрах, поисковых запросах, времени просмотра и даже данные о том, в какой момент пользователь поставил видео на паузу.
Когда Дата Лейк не нужен
Существуют ситуации, когда внедрение Data Lake будет пустой тратой денег. Если ваша компания работает преимущественно со структурированными данными небольшого объема, традиционные решения окажутся более эффективными. Небольшому бизнесу с простыми аналитическими потребностями озеро данных может показаться излишне сложным.
Также стоит воздержаться от внедрения, если в компании нет команды data scientists или аналитиков, способных работать с неструктурированными данными. “Озеро” без квалифицированных пользователей превращается в дорогостоящий склад цифрового мусора.
Оценка готовности организации
Перед принятием решения о внедрении стоит честно оценить готовность организации. Есть ли у вас стратегия работы с данными? Понимает ли руководство, что Data Lake — это не просто технология, а изменение подхода к работе с информацией? Готовы ли вы инвестировать в обучение сотрудников и найм специалистов?
Согласно нашим наблюдениям, успешные проекты Data Lake характеризуются не только технической грамотностью, но и сильной поддержкой со стороны бизнеса. Без понимания ценности данных на уровне топ-менеджмента даже самое технически совершенное решение может оказаться невостребованным.
Практические шаги по внедрению
Допустим, вы приняли решение о внедрении Data Lake. Теперь возникает вопрос: с чего начать и как избежать типичных ошибок?
Этап планирования и стратегии
Первый шаг — это не выбор технологий, а определение бизнес-целей. Какие задачи должно решать озеро данных? Повышение качества рекомендательных систем? Оптимизация логистических процессов? Предиктивная аналитика для снижения оттока клиентов? Четкое понимание целей поможет избежать создания «озера ради озера».
Критически важно провести аудит существующих данных. Где они хранятся сейчас? В каком формате? Кто и как их использует? Какова их ценность для бизнеса? Этот анализ поможет определить приоритеты загрузки и выбрать подходящую архитектуру.
Выбор технологической платформы
Современный рынок предлагает множество решений для построения Data Lake. Облачные провайдеры — Amazon AWS, Microsoft Azure, Google Cloud Platform — предоставляют готовые сервисы, которые можно быстро запустить. Для компаний с особыми требованиями к безопасности или локализации данных подойдут on-premise решения на базе Hadoop или более современных платформ вроде Apache Iceberg.
При выборе стоит учитывать не только текущие потребности, но и планы развития. Сможет ли выбранная платформа масштабироваться? Поддерживает ли она современные форматы данных? Интегрируется ли с существующими системами? Есть ли готовые коннекторы для ваших источников данных?
Организация процессов и команды
Успех проекта во многом зависит от правильной организации команды. Понадобятся data engineers для настройки пайплайнов, data scientists для анализа, администраторы для поддержки инфраструктуры. Не менее важна роль data steward — человека, отвечающего за качество данных и их соответствие бизнес-требованиям.
Особое внимание стоит уделить процессам управления данными. Кто может загружать данные в озеро? Как обеспечивается их качество? Какие существуют правила именования и каталогизации? Как контролируется доступ к конфиденциальной информации?
Поэтапное внедрение
Мы рекомендуем начинать с пилотного проекта — выбрать одну конкретную задачу и довести ее до успешного завершения. Это может быть анализ логов веб-сервера для выявления аномалий или объединение данных из нескольких источников для создания единого представления о клиенте.
Пилотный проект позволит команде накопить опыт работы с технологией, выявить слабые места в процессах и продемонстрировать бизнес-ценность решения. Только после успешного завершения пилота стоит переходить к масштабированию.
Мониторинг и оптимизация
Data Lake — это живая система, которая требует постоянного внимания. Необходимо отслеживать объемы данных, производительность запросов, качество информации. Особенно важно следить за «заболачиванием» — накоплением неиспользуемых данных, которые только увеличивают расходы.
Регулярные ревизии содержимого озера помогут поддерживать его в рабочем состоянии. Какие данные действительно используются? Что можно архивировать или удалить? Нужны ли дополнительные источники данных для решения бизнес-задач?
Тренды и будущее
Технологический ландшафт развивается стремительно, и “озеро данных” не остается в стороне от этих изменений. Давайте рассмотрим, как эволюционирует эта концепция и что ждет нас в ближайшие годы.
Появление Data Lakehouse
Одним из главных трендов последних лет стало появление концепции Data Lakehouse — гибридного решения, которое объединяет преимущества озера данных и традиционных хранилищ. Эта архитектура позволяет хранить данные в открытых форматах (Apache Parquet, Delta Lake), обеспечивая при этом ACID-транзакции и возможность выполнения SQL-запросов.
Практическое значение Data Lakehouse заключается в том, что аналитики больше не должны ждать, пока data engineers подготовят данные для анализа. Они могут работать с информацией напрямую, используя знакомые инструменты бизнес-аналитики. Компании вроде Databricks и Snowflake уже предлагают готовые решения в этой области.
Влияние искусственного интеллекта
Развитие нейросетей и машинного обучения кардинально меняет требования к DL. Современные языковые модели вроде GPT требуют не просто больших объемов данных, а качественно подготовленных датасетов с богатой разметкой. Это приводит к появлению специализированных инструментов для работы с неструктурированными данными — от автоматического тегирования изображений до извлечения сущностей из текстов.
Интересная тенденция — использование самих нейросетей для управления данными в озере. AI-системы могут автоматически классифицировать поступающую информацию, выявлять дубликаты, предсказывать полезность данных для конкретных задач. Это помогает решить проблему «заболачивания», о которой мы говорили ранее.
Федеративные и мультиоблачные архитектуры
Еще одна важная тенденция — движение к федеративным архитектурам данных. Вместо централизованного озера компании создают распределенные системы, где различные подразделения управляют своими доменами данных, но при этом обеспечивается единый доступ и совместимость.
Мультиоблачные решения также набирают популярность. Компании не хотят зависеть от одного провайдера и стремятся использовать лучшие сервисы от разных поставщиков. Это создает новые вызовы в области интеграции и управления данными, но и открывает возможности для оптимизации затрат.
Усиление требований к приватности и безопасности
Ужесточение требований к защите персональных данных влияет на архитектуру Data Lake. Концепция «приватности по дизайну» (privacy by design) становится обязательной, особенно для компаний, работающих с европейскими или российскими клиентами. Это требует внедрения технологий шифрования, дифференциальной приватности и продвинутого контроля доступа.
Перспективы развития
Заглядывая в будущее, можно предположить, что DL станет еще более автоматизированным и интеллектуальным. Мы увидим системы, которые самостоятельно определяют ценность данных, оптимизируют их размещение и предлагают insights без участия человека.
Возможно, концепция централизованного озера данных уступит место более гибким, адаптивным архитектурам. Данные будут храниться там, где они создаются, но при этом оставаться доступными для анализа через единые интерфейсы.
Остается открытым вопрос: сможет ли технология Data Lake адаптироваться к быстро меняющимся требованиям бизнеса и не станет ли она жертвой собственной сложности? Ответ на этот вопрос мы получим в ближайшие годы.
Нужно ли внедрять в свой бизнес
Подводя итоги нашего рассмотрения технологии Data Lake, стоит задаться финальным вопросом: является ли эта концепция действительно революционным решением для работы с данными или это просто очередная модная технология, которая через несколько лет будет забыта?
Реальная ценность для бизнеса
Наш анализ показывает, что Data Lake может приносить реальную пользу, но только при соблюдении определенных условий. Компании, которые смогли правильно внедрить эту технологию, действительно получают конкурентные преимущества. Исследование Aberdeen Group показало, что организации с Data Lake демонстрируют рост выручки на 9% по сравнению с конкурентами — и это далеко не случайность.
Однако ключевое слово здесь — «правильно». Data Lake не является магическим решением, которое само по себе превратит ваши данные в золото. Это инструмент, эффективность которого критически зависит от стратегии его использования, квалификации команды и зрелости процессов управления данными в организации.
Критерии для принятия решения
Прежде чем принимать решение о внедрении, честно ответьте на несколько вопросов. Работает ли ваша компания с действительно большими объемами разнородных данных? Есть ли у вас команда специалистов, способных извлечь ценность из неструктурированной информации? Понимает ли руководство, что ROI от Data Lake может проявиться не сразу, а через месяцы или даже годы?
Если ответы положительные, то Data Lake может стать мощным инструментом для развития вашего бизнеса. Если же вы надеетесь решить с его помощью проблемы, которые лучше решаются традиционными средствами, то лучше воздержаться от инвестиций.
Взгляд в будущее
Технология Data Lake продолжает эволюционировать, и мы видим появление более совершенных решений вроде Data Lakehouse, которые устраняют многие недостатки первого поколения. Развитие искусственного интеллекта и машинного обучения создает новые возможности для автоматизации процессов управления данными.
Вместе с тем, растущие требования к приватности и безопасности данных заставляют пересматривать архитектурные подходы. Возможно, будущее за более распределенными и федеративными системами, где данные остаются под контролем их владельцев, но при этом доступны для анализа.
Практические рекомендации
Если вы решили двигаться в направлении Data Lake, начните с малого. Выберите одну конкретную задачу, соберите небольшую команду экспертов, проведите пилотный проект. Не пытайтесь сразу построить корпоративное озеро данных — сначала убедитесь, что понимаете технологию и можете извлечь из нее пользу.
Заключение
Инвестируйте в обучение команды и создание процессов управления данными. Помните: технология — это только инструмент, а реальную ценность создают люди, которые умеют ее использовать. В конечном счете, успех Data Lake зависит не от выбора конкретной технологической платформы, а от того, насколько хорошо эта технология интегрируется в общую стратегию работы с данными в вашей организации. Подведем итоги:
- Data Lake — это способ хранения разнородных данных. Он позволяет загружать информацию без предварительной структуры.
- Архитектура озера опирается на распределённые файловые системы. Это обеспечивает масштабируемость и гибкость при росте объёмов.
- Преимущества Data Lake — низкая стоимость, гибкость и поддержка ML. Но для эффективности нужна продуманная организация.
- Основные риски — заболачивание, сложность извлечения и слабая безопасность. Они возникают при отсутствии стратегии и контроля.
- Внедрение требует команды, стратегии и пилотных проектов. Без этого озеро данных превращается в неуправляемое хранилище.
- Будущее за гибридными архитектурами и автоматизацией. Data Lakehouse, AI и федеративные подходы уже формируют новый стандарт.
Если вы только начинаете осваивать новую профессию, рекомендуем обратить внимание на подборку курсов по системной аналитике. В них собраны как теоретические основы, так и практические кейсы по построению, оптимизации и защите озёр данных.
Рекомендуем посмотреть курсы по системной аналитике
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Аналитик данных
|
Eduson Academy
100 отзывов
|
Цена
Ещё -5% по промокоду
105 900 ₽
|
От
8 825 ₽/мес
Беспроцентная. На 1 год.
|
Длительность
6 месяцев
|
Старт
3 февраля
|
Подробнее |
|
Системный и бизнес-анализ в разработке ПО. Интенсив
|
Level UP
36 отзывов
|
Цена
75 000 ₽
|
От
18 750 ₽/мес
|
Длительность
1 месяц
|
Старт
6 февраля
|
Подробнее |
|
Системный аналитик PRO
|
Нетология
46 отзывов
|
Цена
с промокодом kursy-online
79 800 ₽
140 000 ₽
|
От
3 500 ₽/мес
Рассрочка на 2 года.
|
Длительность
10 месяцев
|
Старт
13 февраля
|
Подробнее |
|
Системный аналитик с нуля
|
Stepik
33 отзыва
|
Цена
4 500 ₽
|
|
Длительность
1 неделя
|
Старт
в любое время
|
Подробнее |
|
Системный аналитик с нуля до PRO
|
Eduson Academy
100 отзывов
|
Цена
Ещё -10% по промокоду
125 900 ₽
257 760 ₽
|
От
10 492 ₽/мес
10 740 ₽/мес
|
Длительность
6 месяцев
|
Старт
в любое время
|
Подробнее |

Лучшие книги по тестированию программного обеспечения в 2025 году
Не знаете, с каких книг начать путь в тестировании? Подобрали лучшие издания: от базовых руководств до продвинутых книг по TDD, SQL и управлению QA.

Растровая и векторная графика: что это, отличия и где применять
Задумывались, почему при увеличении фото появляются пиксели, а логотипы остаются четкими? В этой статье разберём, чем отличается векторная графика от растровой и как понять, когда использовать каждый тип.

Объектное хранилище S3: что это, как работает и как использовать
S3 хранилище это не просто сервис для файлов — это целая экосистема для бизнеса и разработчиков. В статье разберем архитектуру, преимущества и реальные сценарии использования.