Генераторы в Python: полный гайд для начинающих и не только
В мире разработки на Python существует инструмент, который часто остается недооцененным начинающими программистами, но активно используется профессионалами — генераторы. Представьте, что вам нужно обработать файл размером в несколько гигабайт или создать практически бесконечную последовательность данных. Как сделать это эффективно, не перегружая оперативную память компьютера? Именно здесь на помощь приходят генераторы — элегантный и мощный механизм Python для работы с большими объемами данных.
В этой статье мы подробно разберем, что это такое, как они работают «под капотом», и в каких случаях их применение не просто удобно, а необходимо для создания эффективного кода.
- Что такое генераторы в Python
- Как работают
- Как создать генератор в Python
- Генераторы vs списки и итераторы
- Где и как применять на практике
- Как обрабатывать ошибки при работе с генераторами
- Преимущества и ограничения
- Заключение
- Рекомендуем посмотреть курсы по Python
Что такое генераторы в Python
Генераторы — это специальный тип итераторов, который позволяет создавать последовательности значений «на лету», не загружая их целиком в память. Ключевая особенность заключается в том, что они используют принцип «ленивых вычислений» (lazy evaluation): элементы последовательности вычисляются только в момент обращения к ним, а не заранее.
В отличие от обычных функций, которые выполняются от начала до конца и возвращают результат через return, генераторные функции используют ключевое слово yield, которое приостанавливает выполнение функции, возвращает значение и запоминает состояние. При следующем обращении к генератору выполнение продолжается с того места, где оно было приостановлено.
Они принципиально отличаются от других конструкций Python:
- Отличие от обычных функций: функции выполняются полностью и возвращают один результат, генераторы могут «выдавать» значения постепенно и приостанавливать свою работу.
- Отличие от итераторов: хотя генераторы являются итераторами, их проще создавать — не нужно реализовывать методы __iter__() и __next__().
- Отличие от коллекций (списков, кортежей): коллекции хранят все данные в памяти одновременно, генераторы этого не делают, что критично при работе с большими объемами данных.
Главное преимущество — минимальное использование памяти, поскольку в ней хранится только текущее состояние итератора, а не вся последовательность значений. Это делает их незаменимыми при обработке больших файлов, потоков данных или создании бесконечных последовательностей.
Как работают
Понимание внутреннего механизма работы итераторов позволяет наиболее эффективно использовать их возможности. В отличие от обычных функций, генераторы обладают уникальной способностью: они могут «запоминать» своё состояние между вызовами и продолжать выполнение с того места, где остановились.
Поведение при выполнении
Жизненный цикл итератора можно представить как последовательность из нескольких ключевых этапов:
- Создание объекта-генератора — при вызове итерационной функции её тело не выполняется немедленно, вместо этого возвращается объект-генератор.
- Выполнение до первого yield — когда вызывается метод next(), код функции выполняется до тех пор, пока не встретит инструкцию yield.
- Приостановка и возврат значения — встретив yield, генератор возвращает значение и «замораживает» своё состояние.
- Продолжение с сохранённой позиции — при следующем вызове next() итератор возобновляет работу с точки после yield.
- Завершение — когда генератор завершается (либо встречается return, либо заканчивается тело функции), выбрасывается исключение StopIteration.
Рассмотрим простой пример:
def simple_generator():
print("Первый шаг")
yield 1
print("Второй шаг")
yield 2
print("Третий шаг")
yield 3
print("Завершение")
# Создаём объект-генератор
gen = simple_generator()
# Первый вызов next() - выполнение до первого yield
value1 = next(gen) # Выводит: "Первый шаг", возвращает: 1
# Второй вызов next() - продолжение с позиции после первого yield
value2 = next(gen) # Выводит: "Второй шаг", возвращает: 2
# Третий вызов next() - продолжение с позиции после второго yield
value3 = next(gen) # Выводит: "Третий шаг", возвращает: 3
# Четвёртый вызов next() - завершение генератора
next(gen) # Выводит: "Завершение", выбрасывает StopIteration
Ключевой момент здесь в том, что генератор сохраняет все локальные переменные и позицию в коде между вызовами, что позволяет ему «помнить» о своём состоянии.
Как передавать значения в генератор с помощью .send()
Генераторы в Python не только возвращают значения с помощью yield, но и могут принимать данные извне с помощью метода .send(). Это открывает дополнительные возможности: например, генератор может динамически реагировать на внешние сигналы или изменять своё поведение в зависимости от переданных значений.
Как это работает
При первом запуске генератора нужно использовать next() — это активирует выполнение до первой инструкции yield. После этого вместо next() можно вызывать generator.send(value) — это передаст значение обратно внутрь генератора, которое будет подставлено в выражение x = yield.
Пример использования .send():
def echo():
received = yield "Готов к приёму"
while True:
received = yield f"Получено: {received}"
g = echo()
print(next(g)) # Готов к приёму
print(g.send("Привет")) # Получено: Привет
print(g.send("ещё")) # Получено: ещё
Важно: первый запуск должен быть next(g), а не g.send(…), иначе произойдёт TypeError, так как генератор ещё не «пришёл» к первому yield.
Этот механизм полезен, например, в ситуациях, когда генератор управляется извне — например, при пошаговой обработке данных, диалоговых системах, парсерах или конечных автоматах.
Исключение StopIteration
Исключение StopIteration — это стандартный механизм Python для сигнализации о завершении итерации. Когда генератор исчерпывает все значения (достигает конца функции или встречает return), автоматически возникает это исключение.
Важно понимать, что это не ошибка в традиционном смысле — это способ сообщить, что последовательность завершена. Циклы for в Python автоматически обрабатывают это исключение, что делает работу интуитивно понятной.
Если генераторная функция содержит return value, то возвращаемое значение сохраняется в атрибуте value исключения StopIteration:
def gen_with_return(): yield 1 yield 2 return "Завершено" g = gen_with_return() next(g) # 1 next(g) # 2 try: next(g) except StopIteration as e: print(e.value) # Выведет: "Завершено"
Понимание механизма работы итераторов «под капотом» позволяет использовать их более эффективно и избегать типичных ошибок, таких как попытка повторного использования исчерпанного генератора или неожиданного исчерпания в середине процесса.
Как создать генератор в Python
В арсенале Python существует два основных способа создания: с помощью генераторных функций с использованием ключевого слова yield и через генераторные выражения. Каждый из этих подходов имеет свои преимущества и области применения.
С помощью функции (yield)
Генераторная функция внешне похожа на обычную функцию Python, но вместо оператора return использует yield. Это принципиальное отличие полностью меняет поведение функции — она возвращает не единичное значение, а создаёт объект-итератор.
Синтаксис генераторной функции прост:
def имя_функции(параметры): # Код функции yield значение1 # Возможно, ещё код yield значение2 # И так далее
Рассмотрим классический пример — генератор чисел Фибоначчи:
def fibonacci(limit): a, b = 0, 1 count = 0 while count < limit: yield a a, b = b, a + b count += 1 # Использование генератора для получения первых 10 чисел Фибоначчи for number in fibonacci(10): print(number)
Особенность этих функций в том, что они могут содержать обычный код Python, включая циклы, условные операторы и обработку исключений, но при этом сохраняют своё состояние между вызовами благодаря yield.
Через выражения
Генераторные выражения предлагают компактный синтаксис для создания итераторов в одну строку. Они напоминают списковые включения (list comprehensions), но используют круглые скобки вместо квадратных:
генератор = (выражение for переменная in итерируемый_объект if условие)
Пример итеративного выражения для получения квадратов чисел:
# Списковое включение (создаёт весь список сразу) squares_list = [x*x for x in range(1000000)] # Занимает много памяти # Генераторное выражение (вычисляет значения по запросу) squares_gen = (x*x for x in range(1000000)) # Минимальное использование памяти # Использование: print(next(squares_gen)) # 0 print(next(squares_gen)) # 1
В таблице ниже сравним два подхода к созданию:
| Характеристика | Генераторные функции | Генераторные выражения |
|---|---|---|
| Сложность | Могут содержать сложную логику | Подходят для простых преобразований |
| Читаемость | Более понятны для сложных алгоритмов | Компактны, но могут быть менее очевидны |
| Гибкость | Позволяют использовать любой код Python | Ограничены одной операцией над последовательностью |
| Применение | Сложные последовательности, требующие состояния | Простые преобразования существующих последовательностей |
Выражения становятся предпочтительным выбором, когда:
- Требуется простая трансформация существующей последовательности.
- Логика генерации умещается в одну строку.
- Необходимо временно создать итерируемый объект (например, для передачи в функцию).
С другой стороны, функции лучше использовать, когда:
- Логика генерации значений сложна и включает несколько шагов.
- Необходимо сохранять сложное состояние между итерациями.
- Требуется обработка исключений внутри генератора.
Выбор между этими двумя подходами зависит от конкретной задачи, но понимание возможностей каждого из них позволяет писать более эффективный и элегантный код.
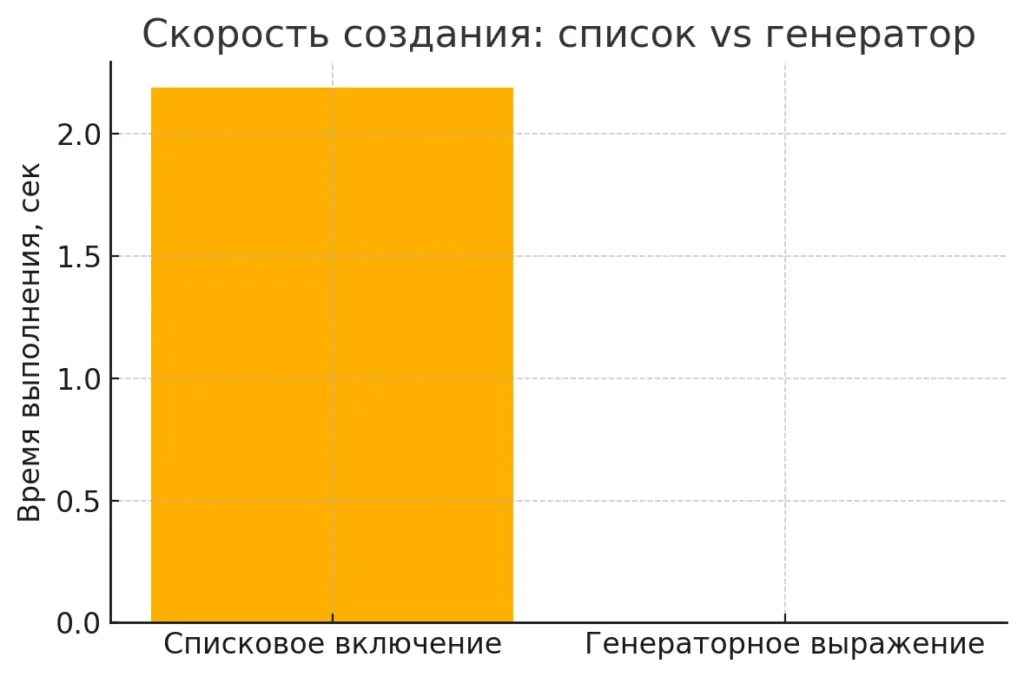
Скорость создания: список vs генератор — генератор создаётся мгновенно, в отличие от спискового включения.
Генераторы vs списки и итераторы
При разработке на Python перед программистами часто встает вопрос выбора между различными структурами данных и подходами к обработке последовательностей. Генераторы, списки и итераторы имеют схожие применения, но существенно различаются по характеристикам производительности и удобству использования.
Давайте сравним эти подходы по ключевым параметрам:
| Характеристика | Списки | Генераторы | Итераторы |
|---|---|---|---|
| Потребление памяти | Хранят все элементы сразу | Хранят только текущее состояние | Хранят только текущее состояние |
| Скорость создания | Медленнее для больших наборов данных | Мгновенное создание | Зависит от реализации |
| Доступ к элементам | Произвольный доступ (O(1)) | Только последовательный | Только последовательный |
| Повторное использование | Можно использовать многократно | Одноразовое использование | Одноразовое использование |
| Методы работы | Множество встроенных методов | Минимальный набор методов | Минимальный набор методов |
| Вычисление элементов | Все сразу при создании | По требованию (lazy) | По требованию (lazy) |
| Удобство создания | Весьма удобно | Очень удобно | Требует реализации протокола итератора |
Эффективность генераторов особенно очевидна при работе с большими объемами данных. Рассмотрим пример, демонстрирующий разницу в потреблении памяти:
import sys
# Список занимает память пропорционально количеству элементов
big_list = [x for x in range(1000000)]
print(f"Размер списка: {sys.getsizeof(big_list)} байт")
# Генератор занимает фиксированное количество памяти
big_gen = (x for x in range(1000000))
print(f"Размер генератора: {sys.getsizeof(big_gen)} байт")
Разница может быть колоссальной: список может занимать десятки мегабайт, тогда как генератор — всего несколько сотен байт.
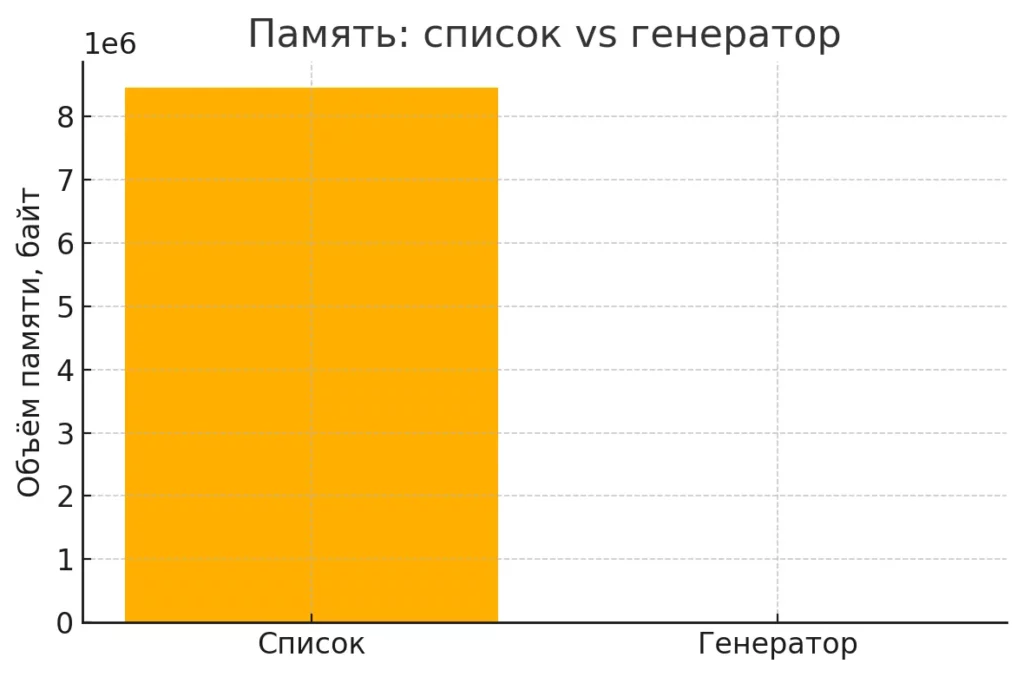
Память: список vs генератор — список занимает десятки мегабайт, тогда как генератор — всего сотни байт.
Когда использовать генераторы:
- При обработке больших объемов данных, которые не помещаются в память.
- Когда данные нужно обрабатывать последовательно, элемент за элементом.
- При работе с потенциально бесконечными последовательностями.
- Когда важна производительность и экономия ресурсов.
- В случаях, когда последовательность используется только один раз.
Когда использовать списки:
- Когда требуется многократный доступ к элементам.
- При необходимости произвольного доступа по индексу.
- Если последовательность небольшая и легко помещается в память.
- Когда нужны операции, специфичные для списков (сортировка, обращение и т.д.).
- В случаях, когда требуется знать длину последовательности заранее.
Когда использовать кастомные итераторы:
- При создании специализированных объектов с собственной логикой итерации.
- Когда требуется полный контроль над процессом итерации.
- В случаях, когда обычные генераторы не обеспечивают необходимого функционала.
Выбор между генераторами, списками и итераторами — это компромисс между удобством, производительностью и функциональностью. В современной разработке на Python генераторы становятся всё более популярными благодаря их эффективности и элегантности, особенно в эпоху обработки больших данных и распределённых вычислений.
Где и как применять на практике
Теоретическое понимание генераторов — это только первый шаг. Настоящая их ценность раскрывается в практических сценариях, где они не просто удобны, а зачастую незаменимы. Рассмотрим несколько реальных кейсов, где они демонстрируют свои преимущества наиболее ярко.
Обработка больших файлов
Одно из классических применений генераторов — обработка больших файлов без загрузки их целиком в память. Представьте лог-файл размером в несколько гигабайт, из которого нужно извлечь только определённые строки:
def process_large_file(file_path, pattern):
with open(file_path, 'r') as file:
for line in file: # файл итерируется построчно, не загружается целиком
if pattern in line:
yield line.strip()
# Использование:
error_logs = process_large_file('massive_log.txt', 'ERROR')
for error in error_logs:
# обработка каждой строки с ошибкой
print(f"Обнаружена ошибка: {error}")
Этот подход эффективен, поскольку:
- В памяти находится только одна строка файла в каждый момент времени.
- Обработка начинается немедленно, без ожидания чтения всего файла.
- Если файл неожиданно огромен, программа не приведёт к исчерпанию памяти.
Создание бесконечных последовательностей
Генераторы идеально подходят для создания теоретически бесконечных последовательностей, например, для математических расчётов:
def fibonacci(): a, b = 0, 1 while True: # бесконечный цикл yield a a, b = b, a + b def prime_numbers(): """Генератор простых чисел.""" primes = [] n = 2 while True: if all(n % p != 0 for p in primes): primes.append(n) yield n n += 1 # Использование: fib_gen = fibonacci() for _ in range(10): print(next(fib_gen)) # Вывод первых 10 чисел Фибоначчи
Очевидно, что создать «бесконечный список» невозможно, а с генераторами мы можем работать с такими последовательностями, забирая столько элементов, сколько нам нужно.
Генерация потоков данных
В веб-разработке и системах обработки данных они незаменимы для создания потоков данных (data streams):
def stream_data_from_api(api_endpoint, page_size=100):
page = 1
while True:
response = requests.get(
f"{api_endpoint}?page={page}&size={page_size}"
)
data = response.json()
if not data['results']:
break # данных больше нет
for item in data['results']:
yield item
page += 1
# Применение в ETL-процессе:
def process_api_data():
data_stream = stream_data_from_api('https://api.example.com/data')
for item in data_stream:
# очистка данных
cleaned_item = clean_data(item)
# трансформация
transformed_item = transform_data(cleaned_item)
# загрузка в базу данных
save_to_database(transformed_item)
Этот подход позволяет создать эффективный конвейер обработки данных, где:
- Данные запрашиваются постепенно, а не всё сразу.
- Обработка происходит параллельно с получением новых данных.
- Система может работать с практически неограниченным объёмом данных.
Композиция для сложных обработок
Генераторы можно комбинировать, создавая сложные конвейеры обработки данных:
def read_csv(file_path):
with open(file_path, 'r') as f:
for line in f:
yield line.strip().split(',')
def filter_data(rows, column_index, value):
for row in rows:
if row[column_index] == value:
yield row
def calculate_average(rows, column_index):
total = 0
count = 0
for row in rows:
total += float(row[column_index])
count += 1
return total / count if count > 0 else 0
# Использование:
data = read_csv('sales.csv')
filtered_data = filter_data(data, 3, 'Electronics')
avg_price = calculate_average(filtered_data, 2)
print(f"Средняя цена электроники: {avg_price}")
Такая комбинация особенно эффективна в сценариях ETL (Extract-Transform-Load) и обработке больших данных, где традиционный подход с загрузкой всех данных в память может оказаться неприменимым.
Практические применения не ограничиваются перечисленными примерами — они находят своё место в самых разных областях, от анализа данных и машинного обучения до игровых движков и систем реального времени, везде, где требуется эффективная обработка потоков данных без избыточного расхода памяти.
Как обрабатывать ошибки при работе с генераторами
При работе с итераторами обработка ошибок имеет свои особенности. Поскольку генераторы выполняются пошагово, исключения могут возникать как при создании итератора, так и в процессе получения значений. Рассмотрим основные подходы к обеспечению надёжной работы с ними.
Обработка исключений в генераторных функциях
Внутри функции можно использовать стандартные конструкции try/except/finally:
def safe_generator(iterable):
iterator = iter(iterable)
while True:
try:
item = next(iterator)
yield item
except StopIteration:
break
except Exception as e:
print(f"Ошибка при обработке элемента: {e}")
# Можно решить: пропустить элемент, yield default, или что-то ещё
continue
Особенно важен блок finally, который будет выполнен даже если генератор не исчерпал все значения:
def file_reader(filename): f = open(filename, 'r') try: for line in f: yield line finally: f.close() # Гарантированно закрываем файл
Как сделать генератор «безопасным»
Чтобы предотвратить типичные проблемы при работе, можно использовать несколько паттернов:
- Проверка предусловий — валидация аргументов перед созданием генератора:
def positive_numbers(max_value):
if not isinstance(max_value, int) or max_value <= 0:
raise ValueError("max_value должно быть положительным целым числом")
for i in range(1, max_value + 1):
yield i
- Корректная обработка StopIteration — в некоторых контекстах это исключение нужно перехватывать:
def get_next_or_default(generator, default=None): try: return next(generator) except StopIteration: return default
Защита от повторного использования — так как генераторы одноразовые:
class ReusableGenerator: def __init__(self, generator_function, *args, **kwargs): self.generator_function = generator_function self.args = args self.kwargs = kwargs def __iter__(self): return self.generator_function(*self.args, **self.kwargs)
Типичные ошибки при работе с генераторами
- Попытка использовать исчерпанный генератор
gen = (x for x in range(3)) list(gen) # [0, 1, 2] list(gen) # [] - генератор уже исчерпан!
- Неконтролируемое исчерпание генератора
def process_data(data_gen): # Проверка первого элемента исчерпает генератор на один элемент! first = next(data_gen, None) if first is None: return "Нет данных" # Здесь генератор начнётся со ВТОРОГО элемента! for item in data_gen: process(item)
- Забытое закрытие ресурсов
def read_lines(filename): f = open(filename) for line in f: yield line # Если генератор не будет полностью исчерпан, # файл может остаться открытым!
- Неперехваченные исключения в генераторе
def parse_numbers(lines): for line in lines: yield int(line) # Выбросит ValueError для нечисловых строк
Корректное обращение с ошибками не только делает код более надёжным, но и часто помогает избежать сложно диагностируемых проблем, особенно в длинных цепочках обработки данных.
Преимущества и ограничения
При выборе инструментов для решения задач обработки данных необходимо трезво оценивать как сильные стороны, так и ограничения каждого подхода. Генераторы не исключение — они обладают рядом уникальных преимуществ, но имеют и определённые недостатки, которые нужно учитывать.
Преимущества
| Преимущество | Описание |
|---|---|
| Ленивые вычисления | Генераторы вычисляют элементы только по запросу, что позволяет работать с теоретически бесконечными последовательностями и откладывать тяжёлые вычисления до момента, когда они действительно необходимы. |
| Экономия памяти | В памяти хранится только текущее состояние генератора, а не вся последовательность целиком, что критически важно при обработке больших объёмов данных. |
| Производительность | Мгновенное создание (не нужно вычислять все элементы сразу) и отсутствие накладных расходов на хранение всей коллекции. |
| Композиция | Легко комбинируются в конвейеры обработки данных, что делает код модульным и выразительным. |
| Чистота кода | Использование часто приводит к более чистому и понятному коду, особенно для потоковой обработки данных. |
Ограничения
| Ограничение | Описание |
|---|---|
| Одноразовость | Генератор может быть использован только один раз — после исчерпания его нельзя «перемотать» назад. |
| Последовательный доступ | Отсутствие произвольного доступа к элементам (нельзя обратиться к n-му элементу, не пройдя через все предыдущие). |
| Нет информации о размере | В общем случае невозможно узнать, сколько элементов содержит генератор, не исчерпав его. |
| Сложность отладки | Отложенное вычисление может затруднить отладку, так как ошибки проявляются только при фактическом обращении к элементу. |
| Потенциальные утечки ресурсов | Если генератор не исчерпан полностью, ресурсы (например, открытые файлы) могут не освобождаться. |
| Сложность для новичков | Концепция ленивых вычислений и управления состоянием может быть непривычной для начинающих программистов. |
Понимание этих характеристик позволяет сделать осознанный выбор при проектировании системы. Например, если вам нужно многократно обращаться к элементам последовательности, генератор может оказаться неподходящим решением. С другой стороны, при обработке потоков данных, где каждый элемент просматривается только один раз, этот итератор становится идеальным выбором.

В чём польза генераторов? Иллюстрация наглядно показывает, почему они становятся всё более популярными среди Python-разработчиков.
Заключение
Генераторы в Python представляют собой мощный инструмент, который значительно расширяет возможности разработчика при решении широкого спектра задач. Их способность экономить память, обрабатывать потенциально бесконечные последовательности и создавать элегантные конвейеры обработки данных делает их незаменимыми в современном программировании.
- Генераторы = ленивые итераторы: они создают элементы по запросу, а не заранее, что экономит память.
- yield вместо return: генераторные функции приостанавливаются и продолжаются с места остановки.
- Идеальны для больших и бесконечных данных: например, при чтении гигабайтных файлов или генерации последовательностей.
- Удобнее, чем итераторы вручную: не нужно реализовывать __iter__ и __next__.
- Генераторные выражения — компактная альтернатива для простых случаев.
- Важны нюансы управления: используйте .send(), .throw() и .close() для продвинутого контроля.
- Обрабатывайте исключения корректно: генераторы могут скрывать ошибки, если их не ловить.
- Не забывайте об ограничениях: они одноразовые, не поддерживают случайный доступ и не сообщают длину.
Хотите углубиться в ленивые вычисления и потоковую обработку данных? Посмотрите подборку курсов по Python — будет полезно!
Рекомендуем посмотреть курсы по Python
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Профессия Python-разработчик
|
Eduson Academy
114 отзывов
|
Цена
116 400 ₽
|
От
9 700 ₽/мес
|
Длительность
6 месяцев
|
Старт
25 марта
|
Подробнее |
|
Fullstack-разработчик на Python
|
Нетология
46 отзывов
|
Цена
161 200 ₽
325 635 ₽
с промокодом kursy-online
|
От
4 975 ₽/мес
|
Длительность
18 месяцев
|
Старт
26 марта
|
Подробнее |
|
Python-разработчик
|
Академия Синергия
38 отзывов
|
Цена
89 800 ₽
224 500 ₽
с промокодом KURSHUB
|
От
3 742 ₽/мес
0% на 24 месяца
|
Длительность
6 месяцев
|
Старт
31 марта
|
Подробнее |
|
Профессия Python-разработчик
|
Skillbox
232 отзыва
|
Цена
157 107 ₽
285 648 ₽
Ещё -27% по промокоду
|
От
4 621 ₽/мес
9 715 ₽/мес
|
Длительность
12 месяцев
|
Старт
23 марта
|
Подробнее |
|
Python-разработчик
|
Яндекс Практикум
102 отзыва
|
Цена
159 000 ₽
|
От
18 500 ₽/мес
|
Длительность
9 месяцев
Можно взять академический отпуск
|
Старт
26 марта
|
Подробнее |

OTUS vs SkillFactory: автотесты — где больше «пишем код», а где больше «разбираем подходы»
Если вы ищете курс по автоматизации тестирования, который сочетает теорию и практику, вы попали по адресу. В этой статье мы сравниваем два популярных курса: OTUS и SkillFactory, чтобы помочь вам определиться с выбором. Какой из них поможет вам быстрее освоить важнейшие навыки тестирования? Читайте и узнайте все подробности!

OTUS vs ProductStar: куда идти технарю, чтобы стать продактом — честное сравнение подходов
OTUS или ProductStar — что выбрать, если вы хотите перейти в продакт-менеджмент? Разбираем разницу в обучении, практике и результате, чтобы вы не потратили время зря.

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.