GPU-сервер — что это такое, зачем нужен и как выбрать подходящую конфигурацию
GPU-серверы обеспечивают кратный прирост производительности, позволяют ускорять обучение моделей, выполнять глубокие нейросетевые вычисления, поддерживать сложные pipeline-процессы и обрабатывать petabyte-масштаб объёмов данных.

В этом материале мы подробно разберём, что такое GPU-сервер, в чём его преимущества перед классическими CPU-платформами, какие задачи он решает и как выбрать оптимальную конфигурацию для ML-проектов, дата-центров, исследовательских лабораторий и бизнеса.
- Что такое GPU-сервер и чем он отличается от обычного компьютера / CPU-сервера
- Где используются GPU-серверы: ключевые сценарии и задачи
- Архитектура и ключевые компоненты GPU-сервера
- Виды GPU-серверов: от бюджетных до топовых решений
- Как выбрать GPU-сервер под конкретные задачи
- Преимущества GPU-серверов и когда они действительно нужны
- Недостатки GPU-серверов и ситуации, когда их использование неоправданно
- Примеры современных GPU и серверных конфигураций
- Заключение
- Рекомендуем посмотреть курсы по машинному обучению
Что такое GPU-сервер и чем он отличается от обычного компьютера / CPU-сервера
GPU-сервер — это специализированная вычислительная система, в которой основную роль выполняют графические процессоры (Graphics Processing Unit, GPU), изначально созданные для обработки графики, но сегодня активно применяемые для широкого спектра высокопроизводительных вычислений. В отличие от традиционных серверов, где центральный процессор (CPU) последовательно обрабатывает все операции, он использует архитектуру массивно-параллельных вычислений, позволяющую одновременно выполнять тысячи однотипных операций.

Реалистичное изображение современного GPU, используемого в серверных системах. Хорошо видны вентилятор охлаждения, металлические радиаторы и контактная PCIe-шина. Такая визуализация помогает читателю понять, как физически выглядит ключевой элемент GPU-сервера.
Ключевое отличие от обычного компьютера или CPU-сервера заключается в способе обработки данных и целевом назначении. Обычный ПК ориентирован на последовательное выполнение разнородных задач — от текстовых редакторов до браузеров, где важна универсальность. Традиционный CPU, хотя и обладает большей вычислительной мощностью, также работает по принципу последовательной обработки, что делает его эффективным для баз данных, веб-серверов и бизнес-приложений. GPU же спроектирован для решения узкоспециализированных, но крайне ресурсоёмких задач, требующих обработки больших массивов данных с множеством параллельных операций.
Основные отличия:
- Архитектура вычислений: тысячи простых ядер GPU против десятков сложных ядер CPU.
- Производительность: в 8–100 раз выше при параллельных вычислениях.
- Специализация: оптимизация под конкретные типы нагрузок (ML, рендеринг, Big Data).
- Масштабируемость: возможность установки нескольких GPU (до 8–10 на один сервер).
- Энергопотребление и охлаждение: значительно более высокие требования к инфраструктуре.
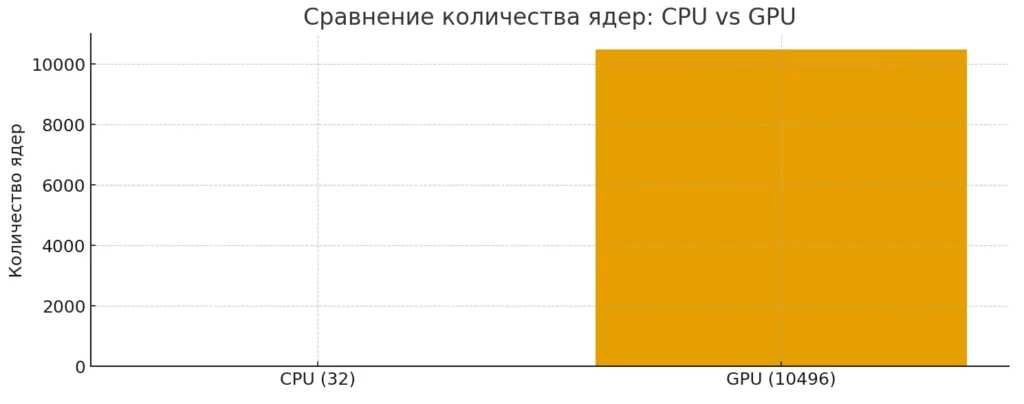
Диаграмма показывает разницу в количестве вычислительных ядер CPU и GPU. У CPU — десятки ядер, тогда как у GPU их тысячи, что определяет кардинально разные модели вычислений. Иллюстрация помогает визуально понять прирост параллелизма.
Принцип работы GPU-сервера
GPU использует принципиально иную архитектуру. Графический процессор содержит тысячи относительно простых вычислительных ядер, объединённых в блоки и способных выполнять операции параллельно — то есть одновременно в множестве независимых потоков.
Критически важное преимущество GPU-архитектуры — устойчивость к ошибкам в отдельных потоках. Если в одном из параллельных вычислений возникает проблема, это не приводит к краху всей системы, как это могло бы произойти в последовательной обработке CPU. Программа продолжает работу, обрабатывая остальные данные. Благодаря этому GPU-серверы обеспечивают производительность вычислений, в 8–10 раз превосходящую традиционные CPU-решения при работе с задачами, допускающими параллелизацию.

Схема показывает концептуальную разницу между архитектурами: несколько широких потоков CPU против множества маленьких параллельных потоков GPU. Она помогает интуитивно объяснить принцип массивно-параллельных вычислений. Такой визуальный контраст усиливает понимание сути GPU-ускорения.
Ключевые отличия от обычного ПК
Несмотря на то, что и обычный персональный компьютер, и GPU-сервер могут содержать графические процессоры, между этими системами существуют принципиальные различия, выходящие далеко за рамки простого количественного сравнения компонентов. Давайте детально рассмотрим, в чём заключаются эти отличия и почему GPU-сервер представляет собой качественно иную категорию вычислительного оборудования.
| Компонент | Обычный ПК | GPU-сервер |
|---|---|---|
| Процессор (CPU) | Intel Core i5/i7/i9, AMD Ryzen — до 16 ядер, ориентация на производительность одного потока | Intel Xeon, AMD EPYC, Threadripper — до 64+ ядер, поддержка ECC-памяти, расширенные возможности многопоточности |
| Графические карты (GPU) | 1–2 потребительские видеокарты (GeForce RTX), 8–24 ГБ VRAM | 4–10 профессиональных GPU (NVIDIA A-серия, H-серия), 40–80 ГБ VRAM на карту, поддержка NVLink |
| Оперативная память | 16–64 ГБ DDR4/DDR5, 2–4 канала | 128 ГБ – 2 ТБ с поддержкой ECC, 4–8 каналов, повышенная отказоустойчивость |
| Хранилище данных | 1–2 SSD/HDD, до 4 ТБ | Множественные NVMe SSD в RAID-массивах, 10–100+ ТБ, высокоскоростные интерфейсы |
| Система охлаждения | Воздушное охлаждение, 2–4 вентилятора | Промышленное охлаждение: мощные вентиляторы, жидкостное охлаждение, специализированные радиаторы |
| Блок питания | 500–850 Вт | 1500–3000+ Вт, резервирование, высокий КПД (80+ Titanium) |
| Форм-фактор | Desktop/Tower корпус | Rack-серверы (1U–4U), оптимизация для дата-центров |
Эти различия не случайны — каждый компонент GPU-сервера спроектирован с учётом специфических требований: непрерывной работы под максимальной нагрузкой (24/7/365), возможности масштабирования, отказоустойчивости и эффективного управления теплоотводом. Обычный ПК, даже мощный игровой или рабочий, просто не рассчитан на подобные условия эксплуатации и не обладает необходимой инфраструктурой для поддержания стабильной работы при многомесячных непрерывных вычислениях.
Где используются GPU-серверы: ключевые сценарии и задачи
Универсальность GPU-серверов в сочетании с их исключительной производительностью открыла возможности для применения этой технологии в самых разных отраслях — от киноиндустрии до фундаментальной науки. Изначально графические процессоры создавались исключительно для обработки визуальной информации, однако их архитектура оказалась настолько эффективной для параллельных вычислений, что сегодня GPU-серверы стали критически важным инструментом во множестве областей, где требуется обработка больших объёмов данных с использованием математических алгоритмов, схожих с рендерингом.
Основные сферы применения:
- Искусственный интеллект и машинное обучение — обучение и инференс нейронных сетей, глубокое обучение, компьютерное зрение.
- 3D-графика и визуализация — рендеринг анимации, архитектурная визуализация, спецэффекты для кино.
- Обработка больших данных — анализ массивов информации, статистические расчёты, прогностическое моделирование.
- Медиапроизводство — кодирование и декодирование видеопотоков, обработка изображений в реальном времени.
- Научные исследования — молекулярное моделирование, климатические симуляции, физические расчёты.
- Криптография — майнинг криптовалют, криптографический анализ, обработка блокчейн-данных.
- Финансовая аналитика — высокочастотный трейдинг, риск-моделирование, анализ рыночных данных.
Возникает закономерный вопрос: что объединяет столь разнородные задачи? Ответ кроется в природе вычислений — все эти сценарии требуют выполнения множества однотипных операций над большими массивами данных, где последовательная обработка CPU оказывается неэффективной. Давайте подробнее рассмотрим наиболее распространённые области применения.
Машинное обучение, нейросети, ИИ. Современные языковые модели, такие как GPT или Claude, системы компьютерного зрения, распознающие объекты на изображениях, генеративные нейросети вроде Stable Diffusion — все они обучались на мощных GPU-кластерах, содержащих десятки и сотни графических процессоров. При этом GPU необходимы не только на этапе обучения, но и при инференсе — применении уже обученной модели к новым данным. Когда пользователь генерирует изображение с помощью нейросети или получает ответ от чат-бота, за кулисами работают GPU-серверы, обрабатывающие запрос в реальном времени.
Критически важным фактором здесь становится объём видеопамяти (VRAM). Современные модели могут требовать десятки гигабайт памяти только для загрузки весов нейросети, не говоря уже о батчах данных для обучения. Именно поэтому профессиональные GPU-карты серий NVIDIA A и H с 40–80 ГБ памяти становятся стандартом де-факто для серьёзных ML-проектов. Возникает ситуация, когда без GPU-сервера полноценная работа с современным машинным обучением попросту невозможна — CPU-решения оказываются в сотни раз медленнее и экономически нецелесообразны.
Рендеринг, 3D-визуализация, VFX. Индустрия компьютерной графики — это та сфера, для которой GPU изначально и создавались, и где их преимущества проявляются наиболее очевидно. Рендеринг фотореалистичных 3D-сцен, создание визуальных эффектов для кинофильмов, архитектурная визуализация — все эти задачи требуют обработки миллионов полигонов, расчёта освещения, теней, отражений и текстур. То, что на CPU могло бы занимать дни или даже недели, GPU-сервер способен выполнить за часы.
Большие данные и аналитика (Big Data). GPU-серверы радикально меняют подход к работе с Big Data благодаря способности выполнять массивно-параллельные операции. Фреймворки для обработки данных, такие как Apache Spark с GPU-ускорением, RAPIDS от NVIDIA или различные библиотеки для параллельных вычислений, позволяют распределить обработку огромных датасетов между тысячами ядер графических процессоров. Операции фильтрации, агрегации, группировки данных, построения статистических моделей — всё это выполняется в десятки раз быстрее по сравнению с CPU-решениями.
Особенно ярко преимущества GPU проявляются в задачах, требующих не только обработки, но и анализа данных с применением сложных математических моделей. Прогностическая аналитика, кластеризация, поиск аномалий, построение рекомендательных систем — все эти задачи критически зависят от скорости вычислений. Компании, работающие с большими данными, всё чаще переходят на гибридные архитектуры, где CPU координирует процессы, а GPU выполняет тяжёлые вычисления, обеспечивая баланс между универсальностью и производительностью.
Медиапроцессинг: стриминг, кодирование, мультимедиа. Взрывной рост потокового видео, развитие платформ вроде YouTube, Twitch, Netflix и появление контента в разрешениях 4K и 8K создали колоссальный спрос на эффективную обработку мультимедиа. Кодирование и декодирование видеопотоков, транскодирование между форматами, применение фильтров и эффектов в реальном времени — все эти операции требуют огромных вычислительных ресурсов, и GPU-серверы здесь оказываются незаменимыми.
Современные графические процессоры содержат специализированные аппаратные блоки — энкодеры и декодеры (NVENC/NVDEC у NVIDIA), способные обрабатывать несколько видеопотоков одновременно с минимальной нагрузкой на основные вычислительные ядра. Это позволяет стриминговым сервисам обрабатывать тысячи одновременных трансляций, конвертируя их в различные битрейты и разрешения для адаптивной доставки контента пользователям с разной пропускной способностью канала.
Помимо стриминга, GPU-серверы активно применяются в обработке изображений и видео для профессиональных задач: цветокоррекция, стабилизация, удаление шумов, апскейлинг с использованием нейросетей. Технологии вроде NVIDIA DLSS или AI-based upscaling демонстрируют, как GPU может не просто ускорять традиционные алгоритмы, но и обеспечивать качественно новый уровень обработки медиаконтента.
Научные и инженерные вычисления, моделирование. Фундаментальная наука и инженерия всегда были областями, требующими экстремальных вычислительных мощностей. Моделирование климатических изменений, симуляции молекулярной динамики, расчёты в области квантовой физики, аэродинамическое моделирование — все эти задачи оперируют сложными математическими моделями и огромными объёмами данных. До появления GPU-ускорения подобные вычисления были доступны лишь суперкомпьютерным центрам, но сегодня ситуация меняется.
GPU-серверы демократизировали доступ к высокопроизводительным вычислениям (HPC), позволяя исследовательским лабораториям и инженерным компаниям решать задачи, ранее требовавшие месяцев расчётов на кластерах CPU. Численное моделирование методом конечных элементов, вычислительная гидродинамика (CFD), молекулярное моделирование в биохимии — во всех этих областях применение GPU сокращает время расчётов на порядки величин.
Особенно впечатляющие результаты GPU показывают в задачах, где требуется многократный перебор вариантов или итерационные расчёты. Например, в фармацевтике GPU-серверы используются для виртуального скрининга тысяч химических соединений при поиске новых лекарств, а в материаловедении — для моделирования свойств новых материалов на атомарном уровне. Научное сообщество всё активнее интегрирует GPU-ускорение в специализированное ПО, превращая эту технологию в стандартный инструмент современных исследований.
Архитектура и ключевые компоненты GPU-сервера
Понимание архитектуры GPU-сервера критически важно для грамотного выбора конфигурации под конкретные задачи.
Процессор (CPU). В GPU-серверах используются не потребительские процессоры вроде Intel Core или AMD Ryzen, а специализированные серверные CPU — Intel Xeon, AMD EPYC или AMD Threadripper Pro. Эти процессоры обладают рядом критически важных характеристик: значительно большим количеством ядер (до 64 и более), поддержкой ECC-памяти (Error-Correcting Code) для обеспечения целостности данных при длительных вычислениях, расширенным количеством линий PCIe для подключения множественных GPU без потери пропускной способности.
Особое значение имеет именно количество линий PCIe. Каждая современная профессиональная видеокарта требует 16 линий PCIe 4.0 или 5.0 для обеспечения максимальной производительности обмена данными с CPU и памятью. Если в системе планируется установка 4–8 GPU, процессор должен обеспечивать 64–128 линий PCIe — возможность, доступная только серверным платформам. Без этого возникает ситуация, когда мощные графические процессоры простаивают в ожидании данных, что полностью обесценивает инвестиции в дорогостоящее оборудование.
Графические ускорители (GPU). Профессиональные GPU отличаются увеличенным объёмом видеопамяти — от 40 до 80 ГБ против 8–24 ГБ у игровых карт. Это критично для работы с большими нейросетями и обработки массивных датасетов, когда данные должны целиком помещаться в память GPU для эффективных вычислений. Кроме того, профессиональные карты поддерживают технологии межкартового взаимодействия вроде NVIDIA NVLink, позволяющего объединить память нескольких GPU в единый пул и обеспечить высокоскоростной обмен данными между картами — пропускная способность достигает 600 ГБ/с против 16–32 ГБ/с через шину PCIe.
Не менее важным фактором становится наличие тензорных ядер (Tensor Cores) — специализированных вычислительных блоков, оптимизированных для операций с матрицами, которые составляют основу алгоритмов машинного обучения. Эти ядра обеспечивают многократное ускорение при обучении и инференсе нейросетей. Профессиональные карты также отличаются улучшенным охлаждением, рассчитанным на круглосуточную работу под максимальной нагрузкой, поддержкой виртуализации GPU (vGPU) и расширенными гарантийными обязательствами производителя. Возникает вопрос: оправдывает ли разница в цене (профессиональная карта может стоить в 3–5 раз дороже игровой) эти преимущества? Для серьёзных проектов ответ однозначен — экономия на GPU оборачивается потерей производительности и надёжности всей системы.
Оперативная память (RAM). Оперативная память в GPU-сервере выполняет роль критически важного буфера между процессором, графическими ускорителями и системой хранения данных. В отличие от обычных ПК, где 16–32 ГБ RAM считается достаточным объёмом, GPU-серверы оперируют совершенно иными масштабами — типичные конфигурации начинаются от 128 ГБ и могут достигать 1–2 терабайт оперативной памяти. Такие объёмы обусловлены спецификой работы с большими данными и машинным обучением.
Перед тем как данные попадут на обработку в GPU, они должны быть загружены в оперативную память, предобработаны CPU и только затем переданы на графические процессоры. При обучении нейросетей на больших датасетах или обработке массивных массивов данных недостаток RAM приводит к постоянным обращениям к дисковой подсистеме, что катастрофически замедляет вычисления — разница в скорости между RAM и даже самыми быстрыми SSD составляет десятки раз. Серверная память принципиально отличается от потребительской наличием поддержки ECC (Error-Correcting Code) — технологии автоматического обнаружения и исправления ошибок в данных.
При многочасовых и многодневных вычислениях даже единичная ошибка в памяти может привести к искажению результатов или краху всего процесса. ECC-память обеспечивает целостность данных и стабильность работы системы. Кроме того, серверные платформы поддерживают многоканальные режимы работы памяти (4, 6 или 8 каналов), что обеспечивает пропускную способность до 200–300 ГБ/с — критически важный параметр для эффективной работы множественных GPU.
Хранение данных (Storage). GPU-серверы комплектуются множественными высокоскоростными NVMe SSD, объединёнными в RAID-массивы различных уровней. RAID 0 обеспечивает максимальную скорость чтения и записи за счёт распределения данных между дисками, достигая пропускной способности в несколько гигабайт в секунду — это критично при загрузке больших батчей данных для обучения нейросетей. RAID 1 или RAID 10 жертвуют частью скорости ради надёжности, создавая зеркальные копии данных на нескольких накопителях, что защищает от потери информации при выходе из строя одного из дисков.
Типичная конфигурация GPU-сервера включает 4–8 NVMe SSD объёмом от 2 до 8 ТБ каждый, что даёт суммарную ёмкость 10–50 ТБ и выше. Для долгосрочного хранения результатов и архивных датасетов дополнительно используются HDD большого объёма или подключение к сетевым хранилищам (NAS/SAN). Возникает вопрос баланса между скоростью, объёмом и стоимостью — и здесь универсального решения не существует, выбор зависит от специфики задач и требований к производительности дисковой подсистемы.
Охлаждение и питание. Тепловыделение и энергопотребление GPU-сервера — это параметры, которые выходят далеко за рамки простых технических характеристик и напрямую влияют на возможность эксплуатации системы. Современная профессиональная видеокарта под полной нагрузкой потребляет 300–400 Вт и выделяет соответствующее количество тепла. Если в сервере установлено 4–8 таких карт, суммарное тепловыделение достигает 2000–3000 Вт — это сопоставимо с мощностью промышленного обогревателя.
Обычное воздушное охлаждение, применяемое в персональных компьютерах, в GPU-серверах достигает своих пределов. Серверные системы используют промышленные решения: мощные высокооборотные вентиляторы с производительностью в сотни кубометров воздуха в час, специализированные радиаторы с увеличенной площадью теплоотвода, продуманную организацию воздушных потоков внутри корпуса. Для топовых конфигураций применяются системы жидкостного охлаждения, где теплоноситель циркулирует через специальные блоки на GPU и CPU, отводя тепло к внешним радиаторам.
Блок питания GPU-сервера — это отдельная инженерная задача. Суммарное энергопотребление системы с несколькими GPU легко достигает 2000–3000 Вт, что требует применения промышленных БП с высоким КПД (сертификация 80+ Titanium, эффективность 94–96%) и часто предусматривает резервирование — установку двух блоков питания для обеспечения отказоустойчивости. Важно понимать, что GPU-сервер предъявляет серьёзные требования к электрической инфраструктуре помещения — стандартная домашняя розетка на 16А (3,5 кВт) может оказаться недостаточной для питания такой системы. Дата-центры решают эту проблему за счёт промышленных систем электроснабжения и охлаждения, что делает размещение мощных GPU-серверов в коммерческих ЦОДах предпочтительным вариантом для большинства компаний.
Виды GPU-серверов: от бюджетных до топовых решений
Классификация GPU-серверов базируется на нескольких ключевых параметрах: количестве установленных графических процессоров, классе используемых GPU (потребительские, профессиональные, вычислительные), объёме памяти и системы хранения, возможностях масштабирования. Давайте рассмотрим основные категории и поймём, для каких задач каждая из них оптимальна.
Серверы начального уровня
GPU-серверы начального уровня — это решения, ориентированные на малый и средний бизнес, стартапы, исследовательские группы и специалистов, делающих первые шаги в области GPU-вычислений. Типичная конфигурация такого сервера включает 1–2 графических процессора, серверный CPU среднего класса (Intel Xeon E или AMD EPYC начальной серии), 64–128 ГБ оперативной памяти и несколько терабайт SSD-хранилища.
В качестве GPU здесь могут использоваться как профессиональные карты начального уровня (NVIDIA RTX A4000, A4500), так и топовые потребительские решения (RTX 4090, RTX 4080), которые при значительно меньшей стоимости обеспечивают впечатляющую производительность для многих задач. Подобная конфигурация подходит для обучения небольших и средних нейросетей, рендеринга проектов умеренной сложности, разработки и тестирования ML-алгоритмов, обработки данных в объёмах до нескольких терабайт.
Ключевое преимущество серверов начального уровня — относительно доступная стоимость при сохранении основных возможностей GPU-вычислений. Это позволяет компаниям протестировать технологию, оценить реальную потребность в вычислительных ресурсах и понять, какие задачи эффективно решаются с помощью GPU, прежде чем инвестировать в более дорогостоящие конфигурации. Для многих проектов такой сервер остаётся оптимальным решением на протяжении длительного времени, особенно если задачи не требуют обработки экстремально больших датасетов или обучения массивных моделей.
Профессиональные серверы для ML/рендеринга
Профессиональные GPU-серверы представляют собой следующую ступень по производительности и возможностям — это рабочие лошадки для компаний, серьёзно занимающихся машинным обучением, компьютерной графикой, научными вычислениями и обработкой больших данных. Типичная конфигурация включает 4–8 профессиональных графических процессоров (NVIDIA RTX A5000, A6000, H100), топовые серверные CPU (Intel Xeon Platinum, AMD EPYC высших серий), 256–512 ГБ оперативной памяти с поддержкой ECC и высокоскоростную систему хранения на базе NVMe SSD в RAID-массивах объёмом 10–50 ТБ.
Именно на этом уровне раскрываются возможности технологий вроде NVLink, позволяющей объединить память нескольких GPU и обеспечить высокоскоростной обмен данными между картами. Это критично при обучении крупных языковых моделей, обработке высокоразрешенных изображений и видео, выполнении сложных научных симуляций. Производительность таких систем в задачах машинного обучения может в десятки раз превосходить серверы начального уровня, что напрямую влияет на скорость разработки и возможность работы с передовыми алгоритмами.
Профессиональные серверы также отличаются повышенной надёжностью и отказоустойчивостью: резервируемые блоки питания, промышленные системы охлаждения, поддержка удалённого управления через IPMI, возможность горячей замены компонентов. Стоимость таких систем исчисляется десятками тысяч долларов, однако для компаний, где GPU-вычисления составляют основу бизнес-процессов — студий VFX, AI-стартапов, исследовательских лабораторий — эти инвестиции окупаются за счёт резкого ускорения работы и возможности решать задачи, недоступные на менее мощном оборудовании.
Enterprise-серверы и масштабируемые кластеры
На вершине пирамиды GPU-серверов находятся enterprise-решения и масштабируемые кластеры — системы, предназначенные для крупных корпораций, исследовательских центров и облачных провайдеров, работающих с задачами экстремальной сложности. Здесь речь идёт не об отдельных серверах, а о целых инфраструктурах, объединяющих десятки и сотни GPU-серверов в единый вычислительный комплекс.
Ключевая особенность enterprise-уровня — высокоскоростные сетевые технологии, обеспечивающие эффективное взаимодействие между узлами кластера. Применяются специализированные решения вроде RDMA (Remote Direct Memory Access), позволяющие серверам обмениваться данными напрямую, минуя операционную систему, или InfiniBand — сетевая технология с пропускной способностью до 400 Гбит/с и задержками менее микросекунды. Это превращает распределённый кластер в единую вычислительную систему, способную обучать гигантские нейросети с миллиардами параметров или проводить сложнейшие научные симуляции.
Масштабируемость становится критическим фактором на этом уровне. Архитектура должна позволять наращивать мощности по мере роста задач — добавлять новые серверные стойки, интегрировать их в существующую инфраструктуру без простоя и переконфигурации всей системы. Управление такими кластерами требует специализированного ПО для оркестрации вычислений, мониторинга состояния тысяч компонентов и оптимального распределения нагрузки. Стоимость enterprise-решений измеряется сотнями тысяч и миллионами долларов, но именно они обеспечивают вычислительную мощь для прорывных исследований в области ИИ, разработки передовых технологий и решения задач, определяющих будущее целых индустрий.
Как выбрать GPU-сервер под конкретные задачи
Выбор оптимальной конфигурации GPU-сервера — это процесс, требующий глубокого понимания специфики ваших задач, реалистичной оценки текущих и будущих потребностей, а также чёткого представления о бюджетных ограничениях. Ошибки на этом этапе могут обойтись дорого: недостаточная производительность приведёт к необходимости скорого апгрейда или замены оборудования, а избыточные инвестиции в неоправданно мощную конфигурацию заморозят средства, которые могли бы быть направлены на развитие других аспектов проекта.
Определяем тип нагрузки
Первый и наиболее критичный шаг в выборе GPU-сервера — это детальный анализ типа задач, которые предстоит решать. Различные области применения предъявляют принципиально разные требования к конфигурации оборудования, и универсального решения, одинаково эффективного для всех сценариев, попросту не существует.
Машинное обучение и нейросети требуют прежде всего большого объёма видеопамяти и высокой производительности тензорных ядер. Если вы планируете обучать крупные языковые модели или работать с компьютерным зрением, критичным становится наличие 40–80 ГБ VRAM на карту и поддержка технологий вроде NVLink для объединения памяти нескольких GPU. Big Data и аналитика акцентируют внимание на пропускной способности обмена данными между GPU и системной памятью, что требует мощного CPU с большим количеством линий PCIe и значительных объёмов оперативной памяти — 256 ГБ и более.
Рендеринг и 3D-визуализация менее требовательны к объёму VRAM (достаточно 24–48 ГБ), но критичны к количеству CUDA-ядер и общей вычислительной мощности GPU. Медиапроцессинг предполагает использование аппаратных энкодеров/декодеров, поэтому здесь важнее количество GPU, способных одновременно обрабатывать множественные потоки, чем их индивидуальная мощность. Научные вычисления требуют баланса между GPU и CPU, поскольку многие задачи HPC предполагают тесное взаимодействие между графическими и центральными процессорами. Чёткое понимание приоритетов вашей нагрузки позволяет сфокусироваться на действительно важных характеристиках и избежать переплаты за избыточные возможности.
Расчёт требуемой мощности GPU и CPU
После определения типа нагрузки необходимо перейти к конкретным расчётам вычислительной мощности. Этот этап требует не только понимания текущих задач, но и прогнозирования их эволюции — модели машинного обучения будут расти, датасеты увеличиваться, сложность проектов возрастать. Планирование с запасом в 30–50% от текущих потребностей — разумная стратегия, позволяющая отсрочить необходимость апгрейда.
Количество GPU определяется масштабом задач и требованиями к скорости их решения. Для экспериментальных проектов и разработки достаточно 1–2 карт, для production-систем машинного обучения оптимальны 4–8 GPU, а крупномасштабные задачи могут требовать кластерных решений. Важно учитывать, что не все алгоритмы эффективно масштабируются на множественные GPU — прирост производительности может быть нелинейным. Объём VRAM рассчитывается исходя из размера моделей и батчей данных: для работы с небольшими нейросетями достаточно 16–24 ГБ, средние модели требуют 40–48 ГБ, а для крупных языковых моделей необходимо 80 ГБ и более на карту.

График показывает, как растёт производительность при увеличении числа GPU. Идеальная линейная кривая сравнивается с реальным приростом, который становится менее эффективным при большом числе карт. Это помогает читателю понимать, почему 8 GPU не дают восьмикратного ускорения.
Линии PCIe — критичный параметр, который часто упускают из виду. Каждый GPU требует 16 линий PCIe для полноценной работы без троттлинга. Если планируется установка 4 GPU, процессор должен обеспечивать минимум 64 линии, для 8 карт — 128 линий. Серверные CPU Intel Xeon Scalable или AMD EPYC предлагают 64–128 линий, что позволяет реализовать конфигурации с множественными GPU. Недооценка этого параметра приводит к ситуации, когда дорогостоящие графические процессоры работают лишь на часть своих возможностей из-за недостаточной пропускной способности шины данных.
Оценка бюджета и стоимости владения
Финальный этап выбора GPU-сервера требует трезвой оценки не только первоначальных инвестиций в оборудование, но и совокупной стоимости владения (Total Cost of Ownership, TCO) на протяжении всего жизненного цикла системы. GPU-серверы — это не просто дорогостоящее приобретение, это инфраструктура с существенными эксплуатационными расходами.
Капитальные затраты формируются из стоимости основных компонентов: профессиональные GPU составляют 50–70% бюджета (от $5000 за RTX A4000 до $30000+ за H100), серверный CPU добавляет $2000–8000, система памяти и хранения — ещё $3000–10000, корпус, охлаждение и питание — $2000–5000. Итоговая стоимость сервера с 4–8 GPU легко достигает $50000–150000, а enterprise-решения исчисляются сотнями тысяч долларов.
Эксплуатационные расходы включают электроэнергию (сервер с 8 GPU потребляет 2,5–3 кВт круглосуточно, что даёт $200–400 ежемесячно при средних тарифах), охлаждение дата-центра (удвоение энергозатрат), обслуживание и администрирование. При размещении в коммерческом ЦОД добавляется аренда стоечного пространства ($300–1000 в месяц). За 3–5 лет эксплуатации эти расходы могут сравняться с первоначальной стоимостью оборудования.
Альтернативой покупке становится аренда GPU-серверов у облачных провайдеров или специализированных хостеров. Это позволяет избежать капитальных затрат, получить гибкость масштабирования и переложить заботы об инфраструктуре на провайдера. Для проектов с непостоянной нагрузкой или ограниченным сроком жизни аренда часто оказывается экономически целесообразнее покупки. Однако при долгосрочной интенсивной эксплуатации собственное оборудование окупается за 12–24 месяца.
| Тип задачи | Основные требования к GPU | Требования к CPU | Требования к RAM | Требования к хранилищу | Особенности и рекомендации |
| Машинное обучение / нейросети (ML/AI) | 40–80 ГБ VRAM на карту, Tensor Cores, NVLink для объединения памяти, 1–8 GPU | Много линий PCIe (64–128), 16–64 ядер | 256–1024 ГБ ECC | NVMe SSD 4–16 ТБ, RAID 0/10 | Критичен объём VRAM; важна пропускная способность между GPU; оптимален кластерный масштаб при больших моделях |
| Компьютерная графика, рендеринг, VFX | 24–48 ГБ VRAM, высокая CUDA-производительность, 1–8 GPU | 16–38 ядер, высокая частота | 128–256 ГБ | NVMe SSD + HDD для проектов | Основная нагрузка — на GPU; важна стабильность охлаждения и поддержка нескольких GPU |
| Big Data / аналитика | 16–24 ГБ VRAM, 1–4 GPU | 32–96 ядер, высокая многопоточность | 512–2048 ГБ ECC | NVMe SSD 10–50 ТБ, RAID 10 | Ключевой параметр — большая RAM; GPU ускоряет обработку, CPU координирует процессы |
| Медиапроцессинг / кодирование видео | 12–24 ГБ VRAM, поддержка NVENC/NVDEC, 1–4 GPU | 12–32 ядер | 64–128 ГБ | NVMe SSD + быстрый кеш | Важнее количество потоков NVENC, чем VRAM; подходит для стримингов и видеохостингов |
| Научные вычисления (HPC) | 40–80 ГБ VRAM, Tensor Cores, NVLink, 2–8 GPU | 32–64 ядер | 256–1024 ГБ ECC | NVMe SSD + высокоскоростной доступ к NAS/SAN | Часто требуется работа в кластере и поддержка InfiniBand |
| Криптография / майнинг | Средняя VRAM, энергоэффективность, 6–10 GPU | Низкие требования | 32–64 ГБ | Простой SSD | Максимальная рентабельность по ваттам; охлаждение критично |
Преимущества GPU-серверов и когда они действительно нужны
Несмотря на впечатляющие возможности GPU-серверов, важно понимать, что это не универсальное решение для любых вычислительных задач. Графические процессоры демонстрируют выдающуюся эффективность в строго определённых сценариях, и попытка применить их там, где они не нужны, приведёт лишь к неоправданным расходам без реального прироста производительности.
Ключевые преимущества GPU-серверов:
- Массивно-параллельная обработка данных — способность одновременно выполнять тысячи однотипных операций обеспечивает производительность, в 10–100 раз превосходящую CPU-решения для подходящих задач.
- Ускорение работы с большими массивами данных — эффективная обработка петабайтов информации в задачах Big Data, где традиционные серверы достигают своих пределов.
- Высокая скорость обучения нейросетей — тензорные ядра современных GPU сокращают время обучения моделей с недель до часов, делая возможными итеративные эксперименты и быструю разработку.
- Экономическая эффективность для специализированных нагрузок — при решении задач, оптимизированных под GPU, стоимость вычислений на единицу производительности оказывается существенно ниже по сравнению с CPU-кластерами.
- Гибкость конфигураций — возможность масштабирования от 1–2 GPU до сотен карт в кластере позволяет адаптировать систему под растущие потребности.
Недостатки GPU-серверов и ситуации, когда их использование неоправданно
Несмотря на яркие преимущества, GPU-серверы имеют ряд существенных недостатков, которые важно учитывать при выборе решений для вычислительных задач. Их использование оправдано не во всех случаях, а неподходящее применение может привести к значительным затратам без существенного прироста эффективности.
Основные недостатки GPU-серверов:
- Высокая стоимость начальных вложений и обслуживания — покупка и настройка мощных GPU-серверов требуют значительных финансовых ресурсов, а их эксплуатация связана с высокими затратами на электроснабжение, охлаждение и техническое обслуживание.
- Ограниченная универсальность — GPU хорошо показывают себя в задачах, требующих массивной параллельной обработки, таких как обучение нейросетей, обработка больших данных или моделирование. Однако для задач, не связанных с такой структурой вычислений, они зачастую оказываются менее эффективными по сравнению с CPU.
- Сложность программирования и оптимизации — разработка программных решений, максимально использующих потенциал GPU, требует специальных знаний и навыков параллельного программирования (например, CUDA или OpenCL). Без этого невозможно добиться заявленной производительности.
- Энергопотребление и тепловыделение — GPU-серверы потребляют много энергии, что увеличивает операционные расходы. Для серверов с сотнями GPU решается вопрос охлаждения, что требует дополнительных инвестиций и инфраструктуры.
- Меньшая универсальность и гибкость — если в инфраструктуре установлены GPU, оптимизированные под узкие сценарии, использование их для задач без параллельных вычислений или с иной структурой данных оказывается неэффективным и экономически нерентабельным.
Когда действительно нужны GPU-серверы:
-
Для задач, связанных с глубоким обучением и тренингом нейросетей, где параллельная обработка существенно ускоряет процессы.
-
Для анализа и обработки огромных массивов данных (Big Data), превышающих возможности CPU.
-
В областях, требующих моделирования и симуляции, где скорости выполнения критичны и параллельность обеспечивает выгоду.
Общие выводы — GPU-серверы не являются универсальным решением, подходящим для любой вычислительной задачи. Их применение оправдано только в сценариях, где массивная параллельность и высокая скорость обработки приносят заметный эффект, а остальные случаи требуют тщательного анализа стоимости и эффективности.
Примеры современных GPU и серверных конфигураций
Давайте рассмотрим актуальные модели GPU и проанализируем, как они комбинируются в готовых серверных конфигурациях для решения типичных задач в области машинного обучения, рендеринга и обработки больших данных.
Топовые современные GPU
Профессиональный сегмент графических процессоров сегодня представлен несколькими линейками, каждая из которых оптимизирована под определённый класс задач. NVIDIA RTX A-серия (A4000, A5000, A6000) — это универсальные рабочие станции для профессиональной графики и вычислений среднего масштаба. RTX A6000 с 48 ГБ VRAM и архитектурой Ampere обеспечивает баланс между производительностью рендеринга и возможностями машинного обучения, делая эту карту популярным выбором для студий визуализации и небольших ML-проектов.
NVIDIA H-серия (H100, H200) представляет собой вершину вычислительных возможностей, специально спроектированную для крупномасштабного машинного обучения и HPC-задач. H100 с 80 ГБ HBM3-памяти и производительностью до 2000 TFLOPS в тензорных вычислениях стала стандартом для обучения больших языковых моделей. Поддержка технологии Transformer Engine обеспечивает многократное ускорение при работе с архитектурами трансформеров, лежащими в основе современных LLM. H200 развивает эту концепцию, предлагая 141 ГБ памяти — критичный параметр для работы с моделями на сотни миллиардов параметров.
Альтернативой экосистеме NVIDIA выступает AMD Instinct (MI250, MI300) — серия, активно развивающаяся и предлагающая конкурентоспособную производительность в научных вычислениях и некоторых ML-задачах, часто по более привлекательной цене. MI300X с 192 ГБ HBM3 демонстрирует впечатляющие возможности для работы с крупными моделями. Однако экосистема ПО и фреймворков для AMD пока уступает зрелости CUDA-платформы NVIDIA, что остаётся фактором при выборе оборудования.
Типичные конфигурации серверов под разные задачи
Понимание того, как конкретные GPU комбинируются с другими компонентами в готовых конфигурациях, помогает составить реалистичное представление о требованиях и возможностях различных систем.
ML-сервер для обучения нейросетей: 4× NVIDIA H100 (80 ГБ каждый) с поддержкой NVLink, 2× AMD EPYC 9554 (64 ядра), 1 ТБ ECC RAM, 8× NVMe SSD 4 ТБ в RAID 0, блок питания 3000 Вт. Такая конфигурация обеспечивает 320 ГБ объединённой видеопамяти через NVLink и способна обучать модели масштаба GPT-3 или работать с мультимодальными архитектурами. Стоимость системы — $150000–200000, но производительность позволяет сократить время обучения крупных моделей с месяцев до недель.
Сервер для рендеринга и VFX: 8× NVIDIA RTX A6000 (48 ГБ каждый), Intel Xeon W-3375 (38 ядер), 512 ГБ RAM, 4× NVMe SSD 2 ТБ + 16 ТБ HDD-массив для проектов, жидкостное охлаждение. Конфигурация оптимизирована для максимального количества GPU при сохранении достаточной производительности CPU для композитинга и постобработки. Общий объём VRAM в 384 ГБ позволяет одновременно держать в памяти сложные сцены с высоким разрешением текстур. Стоимость — $80000–100000.
Скриншот спецификаций профессиональной GPU NVIDIA A6000.
Сервер для Big Data аналитики: 4× NVIDIA RTX A5000 (24 ГБ каждый), 2× AMD EPYC 9654 (96 ядер суммарно), 2 ТБ ECC RAM, 12× NVMe SSD 8 ТБ в RAID 10. Здесь акцент смещён на баланс между GPU для параллельных вычислений, мощным многоядерным CPU для координации и огромным объёмом оперативной памяти для работы с датасетами в оперативке. Высокоскоростное хранилище с избыточностью обеспечивает быстрый доступ к данным и защиту от потерь. Стоимость — $60000–80000.
Заключение
Мы прошли путь от базовых концепций GPU-вычислений до детального разбора конфигураций и сценариев применения, и теперь можем сформулировать практические рекомендации по выбору оптимального решения. Ключевой вывод, который следует из нашего анализа: GPU-сервер — это не просто мощное оборудование, это инвестиция, которая должна быть тщательно обоснована спецификой ваших задач и реалистичной оценкой потребностей. Подведем итоги:
- GPU-сервер обеспечивает массивно-параллельную обработку данных. Это значительно ускоряет вычисления и обучение моделей.
- Производительность GPU превосходит CPU в задачах, требующих работы с большими массивами данных. Это делает такие серверы ключевым инструментом в ML, рендеринге и аналитике.
- Архитектура GPU-серверов требует продуманного выбора компонентов. От объёма VRAM, линий PCIe и охлаждения напрямую зависит итоговая эффективность.
- Разные типы нагрузок требуют разных конфигураций. Это помогает избежать переплаты и подобрать оптимальный сервер под конкретный сценарий.
- Стоимость владения включает не только покупку оборудования. Энергопотребление, охлаждение и ЦОД также формируют итоговый бюджет проекта.
Если вы только начинаете осваивать машинное обучение и хотите лучше разбираться в работе GPU-систем на практике, рекомендуем обратить внимание на подборку курсов по ML. В них есть как теоретическая база, так и практические задания, которые помогут глубже понять устройство вычислительных систем и ускорить развитие навыков.
Рекомендуем посмотреть курсы по машинному обучению
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Специалист Data Scientist с нуля
|
Eduson Academy
112 отзывов
|
Цена
109 900 ₽
|
От
9 158 ₽/мес
|
Длительность
9 месяцев
|
Старт
10 марта
|
Подробнее |
|
Онлайн-курс по машинному обучению для начинающих
|
Karpov.Courses
75 отзывов
|
Цена
129 000 ₽
181 100 ₽
|
От
7 546 ₽/мес
|
Длительность
7 месяцев
|
Старт
8 апреля
|
Подробнее |
|
Машинное обучение
|
Нетология
46 отзывов
|
Цена
53 600 ₽
99 268 ₽
с промокодом kursy-online
|
От
2 481 ₽/мес
Без переплат на 18 месяцев.
|
Длительность
10 месяцев
|
Старт
10 марта
|
Подробнее |
|
Профессия Machine Learning Engineer
|
Skillbox
226 отзывов
|
Цена
182 297 ₽
364 594 ₽
Ещё -20% по промокоду
|
От
5 881 ₽/мес
Это минимальный ежемесячный платеж за курс.
|
Длительность
13 месяцев
|
Старт
11 марта
|
Подробнее |
|
Профессия Machine Learning Engineer
|
GeekBrains
68 отзывов
|
Цена
124 560 ₽
249 084 ₽
с промокодом kursy-online15
|
От
3 460 ₽/мес
6 919 ₽/мес
|
Длительность
6 месяцев
|
Старт
19 марта
|
Подробнее |

Платное обучение в вузах подорожает: кого это ударит сильнее всего
Минобрнауки предложило запретить вузам устанавливать стоимость платного обучения ниже затрат на бюджетного студента. Реформа затронет региональные и частные университеты, где цена иногда опускалась до 30 000 рублей в год. Параллельно планируется сократить 45 000 платных мест — 13% от общего числа.

Skypro vs Bang Bang Education: где дизайнера лучше прокачивают «думать руками»
Выбираете курсы дизайна и пытаетесь понять, где действительно учат работать с реальными задачами? В этом материале разбираем, как сравнивать программы обучения, на что смотреть в практике, ревью и портфолио, и какие критерии помогут выбрать курс осознанно.

Собеседование PHP-разработчика: вопросы, задачи и подготовка
Если вы только начинаете осваивать профессию PHP-разработчика или хотите увереннее чувствовать себя на интервью, рекомендуем обратить внимание на подборку курсов по PHP-разработке. В таких программах обычно есть теоретическая и практическая часть: изучение языка, фреймворков, баз данных и решение реальных задач.

Вопросы и задачи на собеседовании по Java в 2026 году: полный гид
Собеседование на позицию java разработчик собеседование сегодня включает не только вопросы по синтаксису языка. Какие темы проверяют, какие задачи дают и как подготовиться к интервью по Java — разбираем ключевые блоки, типовые вопросы и практические советы.