Что такое HashMap в Java и как она работает
В мире Java-разработки эффективное управление данными — ключевой фактор успеха приложения. Среди множества инструментов для хранения информации особое место занимает HashMap — универсальная структура данных, позволяющая организовать пары «ключ-значение» с молниеносным доступом к необходимой информации. В этом курсе мы рассмотрим, как устроен HashMap, каковы его преимущества и ограничения, а также как использовать эту структуру данных наиболее эффективно.

Представьте себе словарь, где вместо перелистывания страниц в поисках нужного слова вы мгновенно открываете нужную страницу. Именно такое преимущество дает хеш-таблица разработчикам, значительно ускоряя процессы поиска, хранения и обработки данных в приложении.
- Что такое HashMap?
- Как работает HashMap?
- Основные методы
- Производительность и оптимизация
- HashMap vs. другие коллекции в Java
- Частые ошибки и подводные камни
- Заключение
- Рекомендуем посмотреть курсы по Java
Что такое HashMap?
HashMap — это одна из ключевых структур данных в Java, которая реализует интерфейс Map и представляет собой хеш-таблицу. По своей сути, хеш-таблица — это ассоциативный массив, хранящий элементы в формате «ключ-значение», где каждому уникальному ключу соответствует определенное значение. Эта концепция напоминает обычный толковый словарь, в котором для каждого слова (ключа) существует определение (значение).
Этот скриншот демонстрирует исходное определение HashMap в официальной документации Oracle. Он подтверждает, что HashMap реализует интерфейс Map, поддерживает null-значения, но не гарантирует порядок элементов. Также подчеркиваются параметры, влияющие на производительность: начальная емкость и коэффициент загрузки. Визуализация помогает читателю увидеть, как структура описана на уровне JDK и предоставляет базовое представление об официальной реализации.
Если провести аналогию с реальным миром, то хеш-таблицу можно сравнить с библиотечной картотекой. У каждой книги есть уникальный идентификатор (ключ), по которому библиотекарь может моментально найти её местоположение на полке (значение). Не нужно просматривать все книги по порядку — достаточно знать ключ, чтобы получить мгновенный доступ к нужной информации.
Главное преимущество HashMap заключается в скорости доступа к данным. В отличие от массивов или списков, где для поиска элемента может потребоваться перебор всей структуры, HashMap обеспечивает доступ к значению по ключу за константное время O(1) в среднем случае. Именно эта особенность делает хеш-таблицу незаменимым инструментом для разработчиков, работающих с большими объемами данных.
Где используется?
Спектр применения хеш-таблицы в реальной разработке чрезвычайно широк. Рассмотрим несколько распространенных сценариев:
- Кэширование данных: HashMap часто используется для реализации простых кэшей, где ключом может выступать идентификатор запроса, а значением — результат вычислительно сложной операции.
- Подсчет частотности: Например, для анализа текста, где ключами выступают слова, а значениями — количество их появлений в тексте.
- Хранение конфигураций: Удобное хранение настроек приложения в формате «параметр-значение».
- Индексирование данных: Для быстрого поиска объектов по определенным атрибутам.
- Создание ассоциативных структур: Например, для хранения соответствия между ID пользователя и его данными.
В корпоративной разработке хеш-таблица становится незаменимым компонентом при работе с большими потоками информации, особенно когда требуется быстрый поиск и обновление данных по уникальным идентификаторам.
Как работает HashMap?
Структура данных
Под капотом хеш-таблица представляет собой нечто более сложное, чем просто набор пар ключ-значение. Его внутренняя реализация — это массив так называемых «корзин» (buckets), каждая из которых может содержать один или несколько элементов.
По умолчанию, когда мы создаем новый HashMap, Java выделяет место для 16 таких корзин. Это исходный размер, который будет автоматически увеличиваться по мере заполнения структуры данными. Каждая корзина содержит связанный список элементов — узлов (Node), которые хранят ключ, значение и ссылку на следующий узел в списке.
Интересно отметить, что начиная с Java 8 произошло важное изменение в структуре хеш-таблицы. Теперь, когда количество элементов в одной корзине превышает определенный порог (обычно 8), связанный список трансформируется в красно-черное дерево. Это значительно улучшает производительность в случаях высокой загруженности отдельных корзин.
Хеширование и поиск элементов
Когда мы добавляем пару ключ-значение в HashMap, происходит следующее:
- Для ключа вызывается метод hashCode(), который возвращает целочисленный хеш-код
- Этот хеш-код преобразуется в индекс корзины с помощью операции hash & (n-1), где n — текущий размер массива корзин
- Значение помещается в соответствующую корзину
При поиске значения по ключу процесс аналогичен: сначала вычисляется хеш ключа, затем определяется нужная корзина, и, наконец, в корзине ищется элемент с таким же ключом (для сравнения используется метод equals()).
Именно поэтому методы hashCode() и equals() критически важны для правильной работы хеш-таблицы. Если два объекта равны с точки зрения equals(), то их хеш-коды также должны быть равны.
Коллизии и их обработка
Коллизия происходит, когда два разных ключа имеют одинаковый хеш-код или когда разные хеш-коды приводят к одинаковому индексу корзины. Это неизбежное явление в хеш-таблицах.
До Java 8 коллизии разрешались исключительно с помощью связанных списков: если два элемента попадали в одну корзину, они формировали цепочку. Когда такая цепочка становилась длинной, производительность поиска существенно снижалась.
В Java 8+ была внедрена двухуровневая система: при небольшом количестве коллизий используются связанные списки, но когда количество элементов в корзине превышает порог, происходит преобразование в красно-черное дерево, что позволяет сократить время поиска с O(n) до O(log n).
Внутренний механизм расширения (resize)
Когда количество элементов в хеш-таблице достигает определенного порога, происходит расширение (resize) — создается новый массив корзин вдвое большего размера, и все существующие элементы перехешируются и распределяются по новому массиву.
Порог заполнения определяется произведением размера массива на коэффициент загрузки (load factor). По умолчанию коэффициент загрузки равен 0.75, то есть расширение происходит, когда HashMap заполнен на 75%.
Процесс расширения требует значительных вычислительных ресурсов, поэтому для оптимизации производительности рекомендуется заранее задавать приблизительный размер хеш-таблицы, если известно ожидаемое количество элементов.
Основные методы
HashMap обладает богатым набором методов, которые позволяют эффективно манипулировать данными. Рассмотрим ключевые методы, которые встречаются в повседневной практике Java-разработчика.
| Метод | Описание | Пример использования |
|---|---|---|
| put(K key, V value) | Добавляет новую пару ключ-значение или обновляет значение для существующего ключа | map.put(«user123», new User(«John»)); |
| get(K key) | Возвращает значение по указанному ключу или null, если ключ отсутствует | User user = map.get(«user123»); |
| remove(K key) | Удаляет элемент с указанным ключом и возвращает его значение | User removedUser = map.remove(«user123»); |
| containsKey(K key) | Проверяет наличие ключа в HashMap | if(map.containsKey(«user123»)) { … } |
| containsValue(V value) | Проверяет наличие значения в HashMap | boolean hasUser = map.containsValue(userObject); |
| size() | Возвращает количество пар ключ-значение | int userCount = userMap.size(); |
| isEmpty() | Проверяет, пуста ли HashMap | if(map.isEmpty()) { loadInitialData(); } |
| clear() | Удаляет все элементы из HashMap | userCache.clear(); |
| keySet() | Возвращает Set всех ключей | for(String userId : userMap.keySet()) { … } |
| values() | Возвращает Collection всех значений | for(User user : userMap.values()) { … } |
| entrySet() | Возвращает Set всех пар ключ-значение | for(Map.Entry<String, User> entry : map.entrySet()) { … } |
| putAll(Map m) | Добавляет все элементы из указанной Map | newUserMap.putAll(existingUserMap); |
| getOrDefault(Object key, V defaultValue) | Возвращает значение по ключу или defaultValue, если ключ отсутствует | int count = map.getOrDefault(«key», 0); |
| putIfAbsent(K key, V value) | Добавляет пару ключ-значение, только если ключ отсутствует | map.putIfAbsent(«user123», newUser); |
Важно отметить, что с Java 8 в HashMap появились новые функциональные методы, которые позволяют более элегантно решать распространенные задачи:
// Обновление значения с использованием лямбда-выражения
map.compute("visits", (key, value) -> (value == null) ? 1 : value + 1);
// Обновление только существующего значения
map.computeIfPresent("user123", (key, user) -> user.updateLastLogin());
// Добавление значения только при отсутствии ключа
map.computeIfAbsent("stats", key -> new Statistics());
// Объединение значений
map.merge("totalCount", newCount, (oldValue, newValue) -> oldValue + newValue);
Эти функциональные методы особенно полезны в многопоточных приложениях и при работе со сложной логикой обновления значений, так как позволяют атомарно проверять условия и модифицировать данные.
Глубокое понимание методов и умение выбирать наиболее подходящий из них для конкретной задачи — важный навык, который отличает опытного Java-разработчика и позволяет писать более эффективный и элегантный код.
Производительность и оптимизация
Время выполнения операций
Одной из главных причин популярности HashMap является производительность основных операций. В среднем случае операции put(), get() и remove() выполняются за константное время O(1). Это означает, что время выполнения не зависит от количества элементов в коллекции — будь то 10 записей или 10 миллионов, теоретически доступ к данным происходит одинаково быстро.
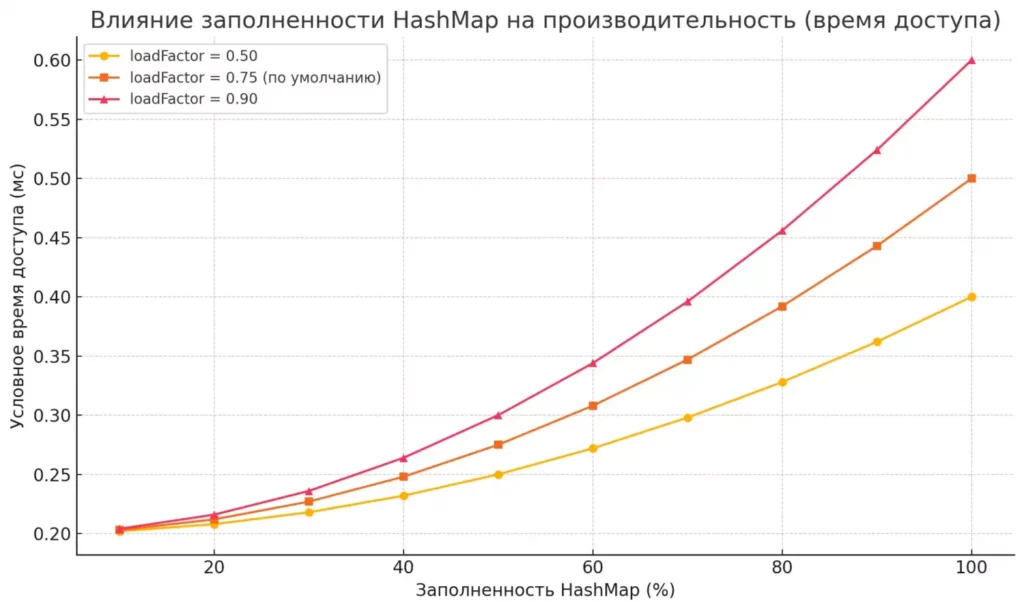
Скриншот иллюстрирует, как производительность HashMap ухудшается при увеличении степени заполненности, особенно при высоком loadFactor. При плотном заполнении коллекции увеличивается вероятность коллизий, что замедляет доступ к элементам. График наглядно демонстрирует, почему разумный выбор loadFactor помогает избежать перерасхода памяти без критического ухудшения производительности.
Однако необходимо понимать, что это справедливо только для «среднего случая». В худшем сценарии, когда много ключей хешируются в одну корзину, производительность может деградировать до O(n) для хеш-таблицы до Java 8, и до O(log n) для более новых версий. Именно поэтому качество хеш-функции играет решающую роль в сохранении высокой производительности.
// Плохая имплементация hashCode() может привести к деградации производительности
@Override
public int hashCode() {
return 1; // Всегда возвращает одинаковый хеш, все элементы попадут в одну корзину!
}
Как выбрать правильный размер?
При создании можно указать два важных параметра: начальную емкость (initialCapacity) и коэффициент загрузки (loadFactor):
// Создание HashMap с начальной емкостью 100 и стандартным коэффициентом загрузки 0.75 HashMap<String, User> userMap = new HashMap<>(100); // Создание HashMap с указанием обоих параметров HashMap<String, Product> inventory = new HashMap<>(10000, 0.8f);
Начальная емкость определяет количество корзин при создании. Если вы приблизительно знаете, сколько элементов будет храниться в HashMap, рекомендуется устанавливать начальную емкость как ожидаемое_количество_элементов / коэффициент_загрузки. Это поможет избежать ненужных операций resize.
Коэффициент загрузки определяет, насколько плотно может быть заполнен HashMap перед расширением. Значение по умолчанию 0.75 является хорошим компромиссом между использованием памяти и производительностью. Меньшие значения уменьшают вероятность коллизий, но увеличивают расход памяти, а более высокие значения экономят память, но могут снизить производительность из-за увеличения количества коллизий.
Как избежать коллизий?
Коллизии — главный враг производительности. Вот несколько рекомендаций по их минимизации:
- Правильно реализуйте методы hashCode() и equals(). Хеш-код должен равномерно распределять объекты по всему диапазону значений int и использовать все значимые поля объекта:
@Override
public int hashCode() {
return Objects.hash(id, name, email); // Использование всех важных полей
}
- Используйте неизменяемые (immutable) объекты в качестве ключей. Это гарантирует, что хеш-код не изменится после добавления объекта в HashMap.
- Избегайте использования сложных объектов в качестве ключей, если нет необходимости. Примитивные типы, обернутые в соответствующие классы (Integer, String), обычно имеют хорошо оптимизированные хеш-функции.
- При большом количестве однотипных данных рассмотрите возможность использования специализированных реализаций, например EnumMap для ключей-перечислений или IdentityHashMap, если вам нужно сравнение по ссылкам, а не по equals().
- Настраивайте начальную емкость, если вы приблизительно знаете ожидаемый размер коллекции, чтобы минимизировать операции resize и перераспределения элементов.
Вдумчивый подход к выбору и настройке HashMap может значительно повысить производительность вашего приложения, особенно в случаях, когда происходит интенсивная работа с данными или обработка больших объемов информации.
HashMap vs. другие коллекции в Java
При разработке приложений выбор правильной структуры данных может существенно повлиять на производительность и удобство работы с кодом. Давайте сравним хеш-таблицу с другими популярными коллекциями в Java, чтобы понять, в каких случаях какую структуру лучше использовать.
| Структура | Преимущества | Недостатки | Когда использовать |
|---|---|---|---|
| HashMap | • Быстрый доступ по ключу O(1)
• Высокая производительность операций • Гибкость типов ключей |
• Нет гарантированного порядка элементов
• Не синхронизирован • Потребляет больше памяти чем массивы |
• Когда нужен быстрый поиск по ключу
• Для создания кэшей • Для подсчета частотности |
| TreeMap | • Элементы автоматически отсортированы по ключу
• Гарантированная производительность O(log n) • Поддерживает диапазонные запросы |
• Медленнее чем HashMap
• Ключи должны быть сравнимыми |
• Когда нужны упорядоченные данные
• Для диапазонного поиска • Когда важна стабильность производительности |
| LinkedHashMap | • Сохраняет порядок вставки элементов
• Почти такая же скорость доступа, как у HashMap |
• Занимает больше памяти, чем HashMap
• Немного медленнее HashMap |
• Когда важен порядок вставки
• Для реализации LRU-кэшей • Для предсказуемой итерации |
| Hashtable | • Синхронизирована (потокобезопасна)
• Не позволяет null-ключи и null-значения |
• Медленнее из-за синхронизации
• Устаревший API |
• Когда нужна простая потокобезопасность
• Для совместимости с устаревшим кодом |
| ConcurrentHashMap | • Потокобезопасная без полной блокировки
• Высокая производительность при конкурентном доступе |
• Немного медленнее обычного HashMap в однопоточной среде | • В многопоточных приложениях
• Когда нужна масштабируемая производительность |
| EnumMap | • Высокоэффективная реализация для ключей-перечислений
• Использует меньше памяти |
• Работает только с enum-ключами | • Когда ключи являются enum-константами |
| ArrayList | • Эффективное хранение последовательности элементов
• Быстрый доступ по индексу |
• Медленный поиск элементов O(n)
• Медленная вставка/удаление в середину |
• Для хранения упорядоченных коллекций
• Когда нужен доступ по индексу |
| HashSet | • Быстрая проверка наличия элементов
• Гарантирует уникальность элементов |
• Нет доступа по индексу
• Хранит только ключи, не значения |
• Для хранения уникальных элементов
• Когда нужна только проверка вхождения |
Выбор между HashMap и другими коллекциями зависит от специфических требований вашего приложения:
- Если вам нужен быстрый доступ по ключу и порядок элементов не важен — HashMap
- Если нужен доступ по ключу и сортировка — TreeMap
- Если важен порядок вставки элементов — LinkedHashMap
- Для многопоточных приложений — ConcurrentHashMap
- Когда ключи являются enum-константами — EnumMap
Понимание сильных и слабых сторон различных коллекций позволяет делать обоснованный выбор и писать более эффективный код. Нередко в одном приложении используются несколько типов коллекций для решения разных задач.
Частые ошибки и подводные камни
При работе с HashMap разработчики часто сталкиваются с определенными проблемами, которые могут привести к некорректной работе программы или снижению производительности. Рассмотрим наиболее типичные ошибки и способы их предотвращения.
Ошибки при переопределении hashCode() и equals()
Одна из самых распространенных ошибок связана с неправильной реализацией методов hashCode() и equals() для классов, используемых в качестве ключей:
public class User {
private int id;
private String name;
// Неправильная реализация: учитывается только id
@Override
public boolean equals(Object obj) {
if (this == obj) return true;
if (!(obj instanceof User)) return false;
User other = (User) obj;
return id == other.id;
}
// Ошибка: hashCode() использует все поля, а equals() -- только id
@Override
public int hashCode() {
return Objects.hash(id, name);
}
}
В приведенном примере нарушается фундаментальный контракт: если два объекта равны согласно equals(), их хеш-коды также должны быть равными. Здесь два объекта с одинаковыми id, но разными именами будут равны согласно equals(), но могут иметь разные хеш-коды, что приведет к непредсказуемому поведению HashMap.
Правильный подход:
@Override
public boolean equals(Object obj) {
if (this == obj) return true;
if (!(obj instanceof User)) return false;
User other = (User) obj;
return id == other.id && Objects.equals(name, other.name);
}
@Override
public int hashCode() {
return Objects.hash(id, name);
}
Изменение ключа после вставки
Еще одна коварная ошибка — изменение состояния объекта, используемого в качестве ключа, после его добавления в HashMap:
Map<User, String> userRoles = new HashMap<>();
User user = new User(1, "admin");
userRoles.put(user, "ADMIN");
// Меняем состояние ключа
user.setName("superadmin");
// Теперь этот объект может оказаться в другой корзине и станет недоступным
String role = userRoles.get(user); // Может вернуть null!
После изменения состояния объекта его хеш-код может измениться, и HashMap будет искать его в неправильной корзине. Это может привести к утечкам памяти, так как объект остается в HashMap, но становится недоступным.
Решение: Всегда используйте неизменяемые (immutable) объекты в качестве ключей или, по крайней мере, гарантируйте, что поля, используемые в hashCode() и equals(), не будут изменяться после добавления объекта в HashMap.
Высокая нагрузка на память при использовании больших HashMap
При работе с большими объемами данных HashMap может потреблять значительное количество памяти:
// Создаем HashMap для миллиона пользователей без указания начальной емкости
Map<Integer, User> userById = new HashMap<>();
for (int i = 0; i < 1_000_000; i++) {
userById.put(i, new User(i, "User " + i));
}
В этом примере HashMap будет многократно выполнять операцию resize, что приведет к лишним затратам памяти и процессорного времени.
Оптимизированный вариант:
// Указываем начальную емкость с учетом ожидаемого количества элементов
Map<Integer, User> userById = new HashMap<>(1_333_333); // ~1M / 0.75
for (int i = 0; i < 1_000_000; i++) {
userById.put(i, new User(i, "User " + i));
}
Проблемы многопоточного доступа
Стандартная реализация хеш-таблицы не является потокобезопасной. Попытка модификации HashMap из нескольких потоков может привести к непредсказуемым результатам:
// Опасно в многопоточной среде!
Map<String, Integer> counters = new HashMap<>();
// В разных потоках
counters.put("visits", counters.getOrDefault("visits", 0) + 1);
Такой код может привести к потере данных, порче структуры HashMap или даже к бесконечному циклу в некоторых версиях Java.
Безопасные альтернативы:
// Вариант 1: Синхронизированная обертка
Map<String, Integer> counters = Collections.synchronizedMap(new HashMap<>());
// Вариант 2: ConcurrentHashMap (предпочтительно для высоконагруженных систем)
Map<String, Integer> counters = new ConcurrentHashMap<>();
// Вариант 3: Использование атомарных операций в ConcurrentHashMap
ConcurrentHashMap<String, AtomicInteger> counters = new ConcurrentHashMap<>();
// В разных потоках
counters.computeIfAbsent("visits", k -> new AtomicInteger()).incrementAndGet();
Осведомленность об этих распространенных проблемах и понимание механизмов их решения помогут вам избежать трудно отлаживаемых ошибок и создавать более надежные приложения на Java.
Заключение
HashMap в Java — это мощный и гибкий инструмент, который заслуженно занимает место одной из наиболее часто используемых структур данных в арсенале разработчиков. Мы рассмотрели, как устроен HashMap изнутри, его производительность, методы работы и типичные сценарии применения.
Ключевые выводы:
- HashMap обеспечивает доступ к данным в формате ключ-значение со средней сложностью O(1), что делает его идеальным выбором для задач, требующих быстрого поиска.
- Правильная реализация методов hashCode() и equals() критически важна для надежной работы. Всегда помните о контракте этих методов при создании кастомных классов-ключей.
- Учитывайте специфику задачи при выборе между хеш-таблицей и ее альтернативами (TreeMap, LinkedHashMap, ConcurrentHashMap) — каждая из них имеет свои преимущества в определенных сценариях.
- Оптимизируйте использование HashMap: задавайте оптимальный начальный размер, используйте неизменяемые ключи и обращайте внимание на потокобезопасность в многопоточных приложениях.
Грамотное применение хеш-таблицы и понимание его внутренних механизмов позволят вам создавать более производительные, понятные и масштабируемые приложения на Java. Как и с любым инструментом, мастерство приходит с практикой — экспериментируйте с разными подходами и не забывайте анализировать производительность ваших решений в реальных условиях.
Остается лишь задать вопрос: какую структуру данных вы выберете в следующий раз, когда вам понадобится хранить ассоциативные пары данных в вашем Java-приложении? Теперь у вас есть все необходимые знания для принятия обоснованного решения.
Если вы только начинаете работать с Java или хотите углубить знания в работе с коллекциями, обратите внимание на подборку лучших курсов по Java-программированию. Здесь вы найдете актуальные программы обучения, включая практику по работе с HashMap и другими структурами данных, что поможет быстрее освоить профессиональные инструменты.
Рекомендуем посмотреть курсы по Java
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Java-разработчик
|
Eduson Academy
114 отзывов
|
Цена
133 900 ₽
|
От
11 158 ₽/мес
0% на 24 месяца
15 476 ₽/мес
|
Длительность
8 месяцев
|
Старт
скоро
Пн,Ср, 19:00-22:00
|
Подробнее |
|
Профессия Java-разработчик
|
Skillbox
232 отзыва
|
Цена
190 971 ₽
381 943 ₽
Ещё -20% по промокоду
|
От
5 617 ₽/мес
Это минимальный ежемесячный платеж. От Skillbox без %.
8 692 ₽/мес
|
Длительность
9 месяцев
Эта длительность обучения очень примерная, т.к. все занятия в записи (но преподаватели ежедневно проверяют ДЗ). Так что можно заниматься более интенсивно и быстрее пройти курс или наоборот.
|
Старт
23 марта
|
Подробнее |
|
Java-разработчик с нуля
|
Нетология
46 отзывов
|
Цена
143 700 ₽
266 020 ₽
с промокодом kursy-online
|
От
4 433 ₽/мес
Без переплат на 2 года.
|
Длительность
14 месяцев
|
Старт
30 марта
|
Подробнее |
|
Java-разработчик
|
Академия Синергия
38 отзывов
|
Цена
103 236 ₽
|
От
4 302 ₽/мес
0% на 24 месяца
|
Длительность
6 месяцев
|
Старт
31 марта
|
Подробнее |
|
Java-разработка
|
Moscow Digital Academy
66 отзывов
|
Цена
132 720 ₽
165 792 ₽
|
От
5 530 ₽/мес
на 12 месяца.
6 908 ₽/мес
|
Длительность
12 месяцев
|
Старт
в любое время
|
Подробнее |

OTUS vs SkillFactory: автотесты — где больше «пишем код», а где больше «разбираем подходы»
Если вы ищете курс по автоматизации тестирования, который сочетает теорию и практику, вы попали по адресу. В этой статье мы сравниваем два популярных курса: OTUS и SkillFactory, чтобы помочь вам определиться с выбором. Какой из них поможет вам быстрее освоить важнейшие навыки тестирования? Читайте и узнайте все подробности!

OTUS vs ProductStar: куда идти технарю, чтобы стать продактом — честное сравнение подходов
OTUS или ProductStar — что выбрать, если вы хотите перейти в продакт-менеджмент? Разбираем разницу в обучении, практике и результате, чтобы вы не потратили время зря.

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.