Как устроена память в Python: что происходит с объектами и кто их удаляет
Когда мы говорим о Python как об языке программирования, который «берёт на себя» управление памятью, возникает закономерный вопрос: а что именно происходит под капотом этой абстракции? Для большинства программистов работа с памятью остаётся чем-то вроде чёрного ящика — мы создаём переменные, объекты, коллекции, а язык сам решает, где их хранить и когда удалять. Такой подход, безусловно, экономит время и позволяет сосредоточиться на бизнес-логике, однако отсутствие понимания внутренних механизмов нередко оборачивается проблемами: утечками памяти, неожиданными просадками производительности или даже зависанием приложений в продакшене.

Python использует три ключевых механизма для управления памятью, каждый из которых решает свою специфическую задачу. Первый — это подсчёт ссылок (reference counting), фундаментальный принцип, определяющий жизненный цикл каждой сущности в памяти. Второй — сборщик мусора (garbage collector), который выявляет и устраняет циклические ссылки, с которыми не справляется простой подсчёт. Третий — внутренний менеджер памяти CPython, организующий работу с низкоуровневыми структурами: аренами, пулами и блоками. Вместе эти три компонента образуют сложную, но элегантную систему, обеспечивающую баланс между удобством разработки и эффективностью использования ресурсов.
Зачем же рядовому разработчику погружаться в эти технические детали? Во-первых, понимание механизмов работы с данными даёт возможность писать более производительный код — особенно это актуально для высоконагруженных систем, где каждая миллисекунда имеет значение. Во-вторых, знание о том, как Python работает с памятью, помогает избежать типичных ошибок при проектировании архитектуры приложений, будь то веб-сервисы или ML-модели. Наконец, в процессе отладки — когда приложение неожиданно «съедает» гигабайты оперативной памяти — без понимания устройства этих процессов разобраться в проблеме становится практически невозможно. В этой статье мы последовательно рассмотрим все три механизма: от базовых принципов до нюансов, которые влияют на многопоточность и производительность ваших программ.
- Как устроена память программы: базовые принципы
- Что такое CPython и как он управляет объектами
- Структура объектов в CPython: PyObject и счётчик ссылок
- Подсчёт ссылок: главный механизм очистки памяти Python
- Проблема циклических ссылок и зачем нужен GC
- Как работает сборщик мусора Python (GC)
- Внутреннее управление памятью CPython: arenas → pools → blocks
- Как память Python влияет на производительность и многопоточность
- Заключение
- Рекомендуем посмотреть курсы по Python
Как устроена память программы: базовые принципы
Прежде чем погружаться в специфику Python, стоит разобраться с тем, как вообще работает память на уровне операционной системы. Представим компьютерную память как обширную библиотеку с пустыми страницами, где каждая запущенная программа получает свой набор страниц для записи данных. Когда мы запускаем Python-скрипт, операционная система создаёт для него отдельный процесс — изолированную среду выполнения со своими ресурсами, включая выделенный сегмент оперативной памяти.
- Память процесса не представляет собой единый монолитный блок — она организована в виде нескольких областей с разным назначением: сегмент кода (где хранится исполняемый байткод), стек (для локальных переменных и вызовов функций), куча (heap) для динамически создаваемых элементов. Именно куча интересует нас в первую очередь, поскольку именно здесь размещаются все те списки, словари и пользовательские сущности, с которыми мы работаем в коде.
- Операционная система выполняет роль распорядителя памяти: она решает, какие физические адреса RAM соответствуют виртуальным адресам процесса, следит за тем, чтобы один процесс не мог случайно (или намеренно) обратиться к ресурсам другого. Однако прямое обращение к системным вызовам для каждой создаваемой сущности было бы крайне неэффективным — представьте, что каждый раз при создании небольшой переменной программа обращалась бы к ОС за новым фрагментом памяти. Именно здесь на сцену выходят менеджеры памяти.
- Менеджер памяти — это промежуточный слой между программой и операционной системой, своего рода буфер, который запрашивает у ОС крупные блоки, а затем самостоятельно распределяет их между мелкими элементами. CPython использует собственный менеджер (pymalloc), который оптимизирован специально для работы с типичными для Python структурами — небольшими, часто создаваемыми и быстро удаляемыми. Благодаря этому Python скрывает от разработчика всю сложность низкоуровневых операций: мы не думаем о том, где физически разместится наш словарь или список, не заботимся о выравнивании данных.
Но понимание того, что за этой абстракцией стоит целая иерархия механизмов — от системных вызовов до внутренних структур интерпретатора — помогает лучше осознать, почему Python ведёт себя именно так, а не иначе в различных сценариях работы с данными.
Что такое CPython и как он управляет объектами
Когда мы говорим о Python, важно различать сам язык как спецификацию и его конкретные реализации. Python — это набор синтаксических правил, стандартная библиотека и философия языка, зафиксированные в документации. Однако для того, чтобы код на Python действительно выполнялся на компьютере, нужна реализация интерпретатора, которая преобразует написанный нами код в машинные инструкции. Существует несколько таких реализаций: PyPy, Jython, IronPython, но эталонной и наиболее распространённой остаётся CPython — интерпретатор, написанный на языке C.
CPython выполняет двухэтапную работу: сначала он компилирует исходный код Python в промежуточный байткод (набор низкоуровневых инструкций), а затем виртуальная машина интерпретатора построчно выполняет этот байткод. Именно на этом этапе происходит взаимодействие с памятью: создаются объекты, изменяются их значения, устанавливаются связи между ними. И здесь мы подходим к ключевой особенности CPython: абсолютно всё в Python является объектом. Число, строка, функция, модуль — каждая сущность представлена в памяти как структура определённого формата.
В основе любой такой сущности лежит структура PyObject — базовый «шаблон», от которого наследуются все остальные типы данных. Эта структура содержит минимальный набор полей, необходимых для управления: счётчик ссылок (reference count), указатель на тип и служебную информацию. Счётчик ссылок отслеживает, сколько переменных или других элементов в данный момент ссылаются на эту сущность — именно этот механизм определяет, когда её можно безопасно удалить из памяти. Указатель на тип позволяет интерпретатору понять, с чем именно он имеет дело: это целое число, строка или пользовательский класс?
Связь между байткодом, памятью и объектами работает следующим образом: когда интерпретатор встречает инструкцию создания (например, x = [1, 2, 3]), он обращается к менеджеру памяти за свободным блоком нужного размера, инициализирует там структуру PyObject с соответствующими полями, заполняет данные списка и присваивает переменной x ссылку на него. При каждом обращении к переменной интерпретатор идёт по этой ссылке и работает через соответствующую структуру. Понимание этой архитектуры критически важно для осознания того, почему в Python «всё передаётся по ссылке» и почему изменение элемента в одной функции может повлиять на его состояние в другой части программы.
Структура объектов в CPython: PyObject и счётчик ссылок
Давайте детальнее разберём, что именно содержит базовая структура PyObject и как она определяет жизненный цикл каждой сущности в памяти. В упрощённом виде PyObject включает следующие поля:
- ob_refcnt — счётчик ссылок, целое число, показывающее, сколько активных ссылок указывает на данный элемент;
- ob_type — указатель на объект типа, который описывает, к какому классу принадлежит данная сущность (int, str, list и так далее);
- дополнительные поля — в зависимости от конкретного типа могут присутствовать данные о размере, хеше, внутренних буферах.
Счётчик ссылок — это сердце системы управления памятью в CPython. Каждый раз, когда мы присваиваем элемент новой переменной, передаём его в функцию или добавляем в коллекцию, счётчик увеличивается на единицу. Когда переменная выходит из области видимости, удаляется из коллекции или перезаписывается другим значением — счётчик уменьшается. Как только он достигает нуля, интерпретатор понимает, что сущность больше никому не нужна, и освобождает занимаемую ею память.
Типичные операции, увеличивающие счётчик ссылок:
- Присваивание переменной: y = x.
- Добавление в список или словарь: my_list.append(x).
- Передача как аргумента функции: some_function(x).
- Создание замыкания, захватывающего переменную.
Операции, уменьшающие счётчик:
- Выход переменной из области видимости (конец функции, блока).
- Удаление переменной: del x.
- Удаление из коллекции: my_list.remove(x).
- Перезапись переменной: x = something_else.
Для исследования поведения счётчика Python предоставляет встроенный инструмент — функцию sys.getrefcount(), которая возвращает текущее значение для переданной сущности. Правда, следует учитывать, что сам вызов этой функции временно увеличивает счётчик на единицу, поскольку элемент передаётся как аргумент. Такая прозрачность механизма делает отладку проблем с памятью в Python значительно проще по сравнению с языками, где управление полностью ручное.
Подсчёт ссылок: главный механизм очистки памяти Python
Подсчёт ссылок представляет собой элегантный и предсказуемый способ автоматического управления памятью. Суть механизма проста: каждая сущность «знает», сколько других элементов на неё ссылаются, и как только это число обнуляется — она немедленно уничтожается. Такой подход радикально отличается от сборщиков мусора, используемых в Java или C#, где удаление неиспользуемых элементов происходит периодически и непредсказуемо.
Принцип работы подсчёта ссылок можно описать следующим образом: при создании сущности её счётчик устанавливается в значение 1 (на неё ссылается как минимум одна переменная). Каждая новая ссылка инкрементирует счётчик, каждое удаление — декрементирует. Когда он достигает нуля, CPython вызывает деструктор (метод del, если он определён) и освобождает занимаемую память. Этот процесс происходит детерминированно — мы можем точно предсказать, в какой момент произойдёт удаление.
У подсчёта ссылок есть несомненные преимущества. Во-первых, это скорость: освобождение происходит мгновенно, без задержек на сканирование всей кучи элементов. Во-вторых, предсказуемость: если мы знаем, что переменная была последней ссылкой, то после её удаления память гарантированно освободится. Это особенно важно при работе с внешними ресурсами — файлами, сетевыми соединениями, блокировками — когда своевременное освобождение критично.
Однако у механизма есть фундаментальное ограничение: он не способен справиться с циклическими ссылками. Представим ситуацию, когда элемент A ссылается на B, а B обратно на A. Даже если никакие внешние переменные больше не ссылаются ни на A, ни на B, их счётчики останутся равными единице из-за взаимных связей. Такие «островки» элементов, ссылающихся друг на друга, но недостижимых из основной программы, приводят к утечкам памяти.
Примеры ситуаций, увеличивающих счётчик ссылок:
- Множественное присваивание: когда одной сущности присваиваются несколько имён.
- Хранение в коллекциях: размещение в списке, кортеже, словаре или множестве.
- Атрибуты: присваивание одного элемента как атрибута другого.
- Захват в замыканиях: когда внутренняя функция ссылается на переменные внешней.
- Аргументы функций: увеличение счётчика на время выполнения.
Рассмотрим простой пример:
import sys
# Создаём объект -- список
data = [1, 2, 3]
print(sys.getrefcount(data)) # Выведет 2 (переменная data + аргумент функции)
# Создаём ещё одну ссылку
another_ref = data
print(sys.getrefcount(data)) # Выведет 3
# Добавляем в словарь
my_dict = {'key': data}
print(sys.getrefcount(data)) # Выведет 4
# Удаляем одну ссылку
del another_ref
print(sys.getrefcount(data)) # Выведет 3
# Удаляем из словаря
del my_dict
print(sys.getrefcount(data)) # Выведет 2
Этот механизм работает настолько прозрачно, что большинство разработчиков даже не задумываются о его существовании. Однако понимание подсчёта ссылок становится критически важным в сценариях, где требуется точный контроль над жизненным циклом элементов — например, при работе с большими объёмами данных в машинном обучении или при оптимизации высоконагруженных систем.
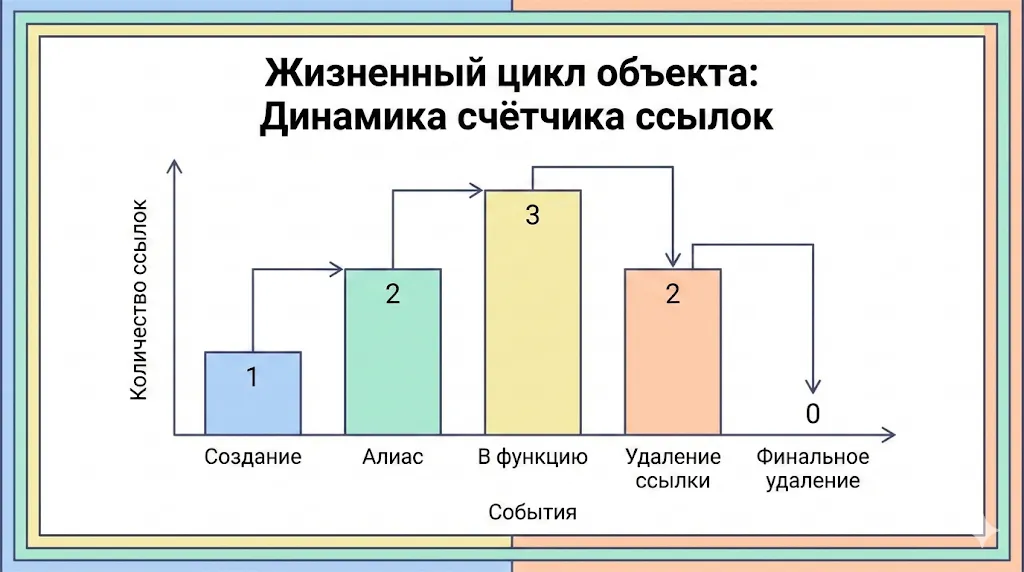
Эта диаграмма иллюстрирует, как меняется значение счётчика ссылок объекта на протяжении его жизни. Счётчик увеличивается при создании новых ссылок (алиасов, передаче в функцию) и уменьшается при их удалении. Когда значение достигает нуля, объект уничтожается.
Проблема циклических ссылок и зачем нужен GC
Механизм подсчёта ссылок, при всей своей элегантности, обладает одним существенным изъяном: он беспомощен перед циклическими структурами данных. Циклическая ссылка возникает, когда два или более элемента ссылаются друг на друга, образуя замкнутый круг. Классический пример — список, содержащий словарь, который в свою очередь ссылается обратно на этот список. Даже если из основного кода программы больше нет ни одной ссылки на эту конструкцию, счётчики обоих элементов останутся ненулевыми из-за взаимных связей.
Представим такой сценарий:
# Создаём список и словарь
my_list = [1, 2, 3]
my_dict = {'key': 'value'}
# Создаём циклическую ссылку
my_list.append(my_dict)
my_dict['ref'] = my_list
# Удаляем внешние ссылки
del my_list
del my_dict
После выполнения этого кода список и словарь всё ещё существуют в памяти, несмотря на то что программа больше не может к ним обратиться. Счётчик списка не равен нулю (на него ссылается словарь), счётчик словаря тоже ненулевой (на него ссылается список). Подсчёт не видит, что весь этот «остров» изолирован от остальной программы и фактически является мусором.
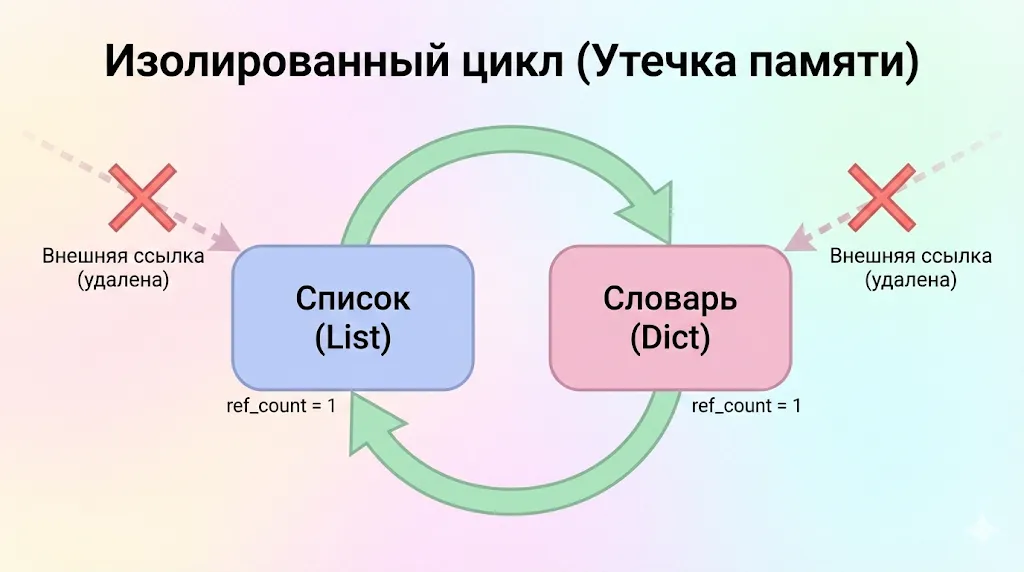
Пример взаимной зависимости двух объектов (списка и словаря), образующих изолированный «остров» в памяти. Внешние ссылки на них удалены, но внутренние счётчики ссылок остаются равными единице, что предотвращает их автоматическое удаление механизмом подсчёта ссылок.
Именно для решения этой проблемы в Python существует модуль gc (garbage collector) — сборщик мусора, который периодически сканирует память в поисках таких недостижимых циклов и освобождает их. В отличие от подсчёта ссылок, который работает непрерывно и мгновенно, сборщик запускается эпизодически, когда накапливается определённое количество элементов или по явному вызову gc.collect().
Ещё одна проблема, которую решает GC, связана с деструкторами — методами del. Если элементы с пользовательскими деструкторами участвуют в циклических ссылках, Python не может определить безопасный порядок их удаления. Какой элемент уничтожать первым, если они взаимозависимы? В версиях Python ниже 3.4 такие структуры вообще не удалялись автоматически, что приводило к гарантированным утечкам. Современные версии научились разрывать такие циклы, но делают это осторожно, иногда пропуская вызов деструкторов для предотвращения ошибок.
| Характеристика | Одиночные объекты | Циклические структуры |
| Обработка подсчётом ссылок | ✓ Удаляются мгновенно | ✗ Остаются в памяти |
| Требуется GC | Нет | Да |
| Предсказуемость удаления | Высокая | Зависит от запуска GC |
| Работа с del | Безопасна | Может быть проблематична |
| Типичные примеры | Строки, числа, простые списки | Графы, деревья с обратными ссылками, кеши с взаимными зависимостями |
Таким образом, сборщик мусора в Python — это не основной, а вспомогательный механизм, «страховочная сетка», которая ловит то, что ускользает от подсчёта ссылок. В большинстве программ циклические ссылки встречаются не так часто, поэтому GC не оказывает существенного влияния на производительность. Однако в специфических сценариях — например, при работе со сложными графовыми структурами или при активном использовании рекурсивных связей — понимание работы сборщика становится необходимым для предотвращения проблем.
Как работает сборщик мусора Python (GC)
Сборщик мусора в Python использует поколенческий алгоритм (generational garbage collection), основанный на гипотезе о том, что большинство элементов живут очень недолго. Смысл прост: если сущность существует достаточно долго, вероятность её скорого удаления снижается. Исходя из этого наблюдения, GC разделяет все отслеживаемые элементы на три поколения.
- Поколение 0 — самое молодое. Сюда попадают все только что созданные структуры, которые могут участвовать в циклических ссылках (списки, словари, экземпляры классов, множества). Это поколение проверяется чаще всего, поскольку именно здесь находится основная масса краткоживущих элементов. Когда их количество превышает пороговое значение (по умолчанию 700), запускается сборка мусора для этого поколения.
- Поколение 1 — среднее. Элементы, пережившие сборку в поколении 0, продвигаются сюда. Проверки происходят реже — примерно раз на 10 сборок нулевого поколения. Порог для запуска сборки первого поколения по умолчанию составляет 10 накопленных проверок.
- Поколение 2 — самое старое. Сюда перемещаются структуры, пережившие сборку в первом. Проверка второго — самая редкая и затратная операция, происходящая примерно раз на 10 сборок первого поколения (порог по умолчанию также 10).
Важно понимать, что не все элементы попадают под контроль GC. Простые неизменяемые типы — числа, строки, кортежи из неизменяемых элементов — не могут образовывать циклические ссылки сами по себе, поэтому сборщик их игнорирует. Отслеживаются только контейнерные типы, способные содержать ссылки на другие структуры.
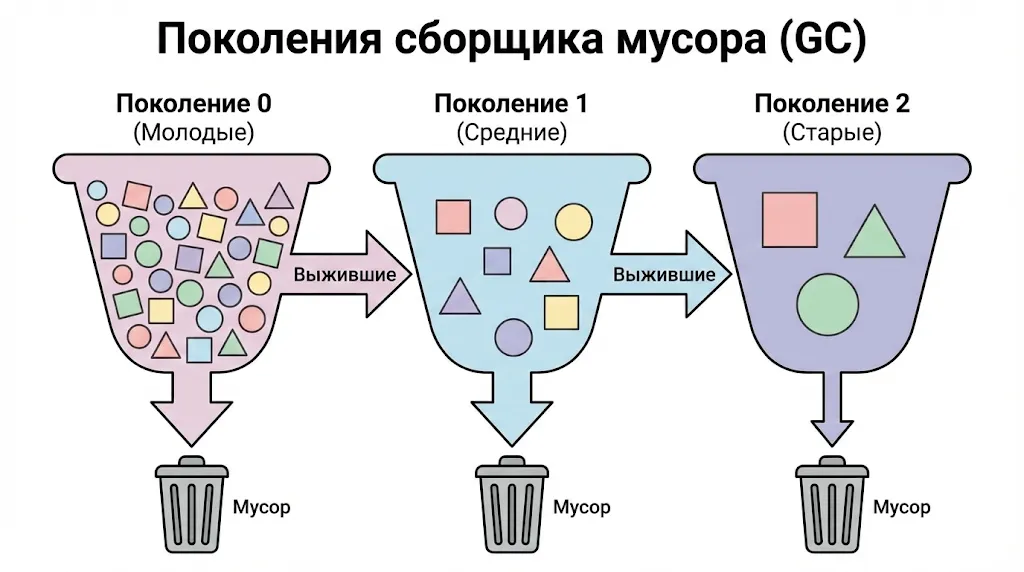
Схема работы поколенческого сборщика мусора. Новые объекты попадают в «Поколение 0», а выжившие после сборки «перетекают» в более старшие поколения, которые проверяются реже. Это позволяет оптимизировать процесс очистки памяти.
Когда GC запускается, происходит событие stop-the-world: все работающие потоки программы приостанавливаются на время поиска и удаления циклических структур. Python «замораживает» выполнение кода, сканирует элементы текущего поколения (и всех младших), выявляет недостижимые циклы и освобождает их. После завершения работы программа продолжает выполнение. Для коротких сборок нулевого поколения эта пауза почти незаметна, но полная сборка всех трёх поколений может занять заметное время, особенно если в памяти находятся миллионы структур.
Критерии перемещения между поколениями:
- Элемент выживает после сборки → перемещается в следующее поколение.
- Достигает поколения 2 → остаётся там до удаления.
- Все младшие поколения всегда проверяются вместе со старшим.
Python позволяет настраивать поведение GC через модуль gc. Можно изменить пороговые значения для каждого поколения с помощью gc.set_threshold(), вручную запустить сборку через gc.collect() или даже полностью отключить автоматическую работу сборщика функцией gc.disable(). Последнее иногда используется в высокопроизводительных системах, где разработчики готовы взять управление в свои руки ради предсказуемой латентности. Однако в большинстве случаев настройки по умолчанию работают достаточно эффективно, и вмешательство в работу GC требуется редко.
Внутреннее управление памятью CPython: arenas → pools → blocks
Теперь погрузимся в самый технический аспект работы с памятью в Python — внутреннюю архитектуру менеджера CPython, известного как pymalloc. Эта система представляет собой трёхуровневую иерархию структур данных, каждая из которых решает свою задачу: арены (arenas) управляют крупными сегментами, пулы (pools) группируют элементы одного размера, блоки (blocks) представляют минимальные единицы выделения.
- Арены — это самый верхний уровень иерархии, крупные фрагменты фиксированного размера в 256 КБ (или 4 МБ на некоторых платформах), которые pymalloc запрашивает у операционной системы. Когда Python нужно разместить новый элемент, он не обращается к ОС за каждым маленьким кусочком — вместо этого он берёт свободное место из уже выделенной арены. Арены организованы в двусвязный список usable_arenas, отсортированный по количеству доступных свободных пулов. Чем меньше на арене свободных пулов — тем ближе она к началу списка. Такой подход гарантирует, что новые структуры размещаются на наиболее заполненных аренах, что минимизирует фрагментацию.
- Пулы — это средний уровень, представляющий собой фрагменты арены размером 4 КБ. Каждый пул специализирован на хранении блоков строго определённого размера: один может содержать только блоки по 8 байт, другой — только по 16 байт, третий — по 24 байта и так далее, вплоть до 512 байт. Эта специализация обусловлена тем, что pymalloc работает исключительно со структурами размером до 512 байт — всё, что больше, передаётся напрямую системному аллокатору malloc. Пулы могут находиться в трёх состояниях: used (частично заполнен, есть и занятые, и свободные блоки), full (все блоки заняты) и empty (все блоки свободны). Для каждого класса размеров CPython поддерживает отдельный список пулов в состоянии used — именно из них в первую очередь выделяется место под новые элементы.
- Блоки — это минимальная единица выделения, непосредственные ячейки, в которых хранятся данные Python-структур. Размер блока кратен 8 байтам и определяется при создании пула. Внутри пула все блоки одинакового размера, что позволяет избежать внешней фрагментации. Блоки существуют в одном из трёх состояний:
- untouched — часть пула, которая ещё никогда не выделялась; это «нетронутая» область, находящаяся в конце пула; free — блок, который ранее использовался, но был освобождён и теперь доступен для повторного размещения данных; такие блоки организованы в односвязный список через указатель freeblock; allocated — блок, содержащий актуальные данные.
Когда приложению требуется место под новый элемент, pymalloc выполняет следующую последовательность действий. Сначала определяется класс размера (округление до ближайшего кратного 8 байтам). Затем проверяется, есть ли пул подходящего размера в состоянии used. Если да — из него берётся первый доступный блок из списка freeblock. Если свободных блоков нет, но остались в состоянии untouched — выделяется один из них. Если и пул, и его untouched-область исчерпаны, пул переходит в состояние full и больше не используется до освобождения хотя бы одного блока. Если подходящих пулов вообще нет, Python ищет свободную арену и инициализирует в ней новый пул нужного размера.
Освобождение происходит поэтапно. Когда элемент удаляется, его блок помечается как free и добавляется в список freeblock соответствующего пула. Если весь пул становится пустым (все блоки free или untouched), пул помечается как empty, но память арены не освобождается. Арена возвращает память операционной системе только тогда, когда абсолютно все её пулы становятся пустыми. Такой подход позволяет избежать частых обращений к ОС, но одновременно создаёт ситуацию, когда Python может удерживать больше ресурсов, чем фактически использует — один-единственный живой элемент на арене не даст освободить все 256 КБ.
Эта многоуровневая архитектура объясняет, почему Python иногда не возвращает память операционной системе даже после удаления большого количества структур: если на каждой арене остался хотя бы один занятый пул, вся её память останется зарезервированной за процессом Python. Именно поэтому в долгоживущих приложениях с пиковыми нагрузками можно наблюдать ситуацию, когда использование остаётся высоким даже после того, как активность снизилась.
pymalloc: быстрый аллокатор Python для маленьких объектов
Pymalloc — это специализированный аллокатор, встроенный в CPython и оптимизированный под типичные паттерны работы Python-программ. Ключевая особенность заключается в том, что он обрабатывает только элементы размером до 512 байт — именно такие составляют подавляющее большинство в типичном Python-коде. Всё, что превышает этот порог, передаётся напрямую системному аллокатору malloc, который является универсальным, но менее оптимизированным для специфики Python.
Почему Python не обращается к malloc для каждого мелкого элемента? Дело в том, что системный аллокатор спроектирован для работы с произвольными запросами любого размера, от единиц байт до гигабайт. Такая универсальность требует сложных внутренних структур и метаданных, что создаёт накладные расходы. Для каждого выделенного блока malloc хранит служебную информацию о его размере, состоянии, связях с соседними блоками. Когда программа создаёт тысячи небольших структур — как это постоянно происходит в Python, — эти накладные расходы становятся значительными как по объёму, так и по времени выполнения.
Pymalloc решает эту проблему через резервирование блоков. Вместо того чтобы для каждого элемента обращаться к ОС, pymalloc заранее запрашивает крупные фрагменты (арены), делит их на пулы по классам размеров, а затем быстро раздаёт уже готовые блоки нужного размера. Поскольку размеры стандартизированы и кратны 8 байтам, не требуется сложная бухгалтерия — достаточно односвязного списка свободных блоков. Выделение сводится к простому взятию первого элемента из списка, что выполняется за константное время O(1).
Рассмотрим практический пример выгоды. Предположим, программа создаёт миллион небольших словарей для обработки JSON-данных. С системным malloc каждый запрос потребовал бы обращения к сложной внутренней логике аллокатора, синхронизации в многопоточной среде и управления метаданными. С pymalloc же эти миллион выделений превращаются в несколько десятков обращений к ОС за аренами плюс быстрые операции взятия блоков из предварительно подготовленных пулов.
Преимущества pymalloc:
- Скорость выделения — операции выполняются за константное время благодаря простым спискам свободных блоков.
- Минимизация фрагментации — группировка структур одного размера в отдельные пулы предотвращает внешнюю фрагментацию.
- Снижение накладных расходов — отсутствие служебной информации для каждого блока экономит ресурсы.
- Кеширование — повторное использование освобождённых блоков без возврата их в ОС ускоряет аллокацию.
- Локальность данных — размещение связанных элементов близко друг к другу улучшает производительность кеша процессора.
Pymalloc — это яркий пример того, как специализированное решение, заточенное под конкретные задачи, может значительно превзойти универсальный инструмент. Именно благодаря этому аллокатору Python способен эффективно работать с огромным количеством мелких структур, не превращая каждую операцию создания переменной в узкое место производительности.
Как память Python влияет на производительность и многопоточность
Управление памятью в Python имеет одно критическое следствие, которое напрямую влияет на возможности многопоточного программирования: необходимость защиты счётчика ссылок от одновременного доступа из разных потоков. Представим ситуацию, когда два потока одновременно пытаются изменить одну и ту же структуру — один увеличивает счётчик (добавляя элемент в список), другой уменьшает (удаляя ссылку). Без синхронизации эти операции могут переплестись на уровне машинных инструкций, что приведёт к повреждению счётчика и непредсказуемым последствиям: преждевременному удалению или, наоборот, утечке.
Для обеспечения потокобезопасности счётчика требуется какой-то механизм синхронизации. Можно было бы использовать отдельную блокировку для каждой сущности, но это породило бы колоссальные накладные расходы — как по объёму (дополнительный мьютекс на каждый элемент), так и по производительности (постоянные операции захвата и освобождения блокировок). Разработчики CPython выбрали более радикальное решение: Global Interpreter Lock, или GIL — глобальная блокировка интерпретатора, которая разрешает выполнение байткода Python только одному потоку в каждый момент времени.
GIL решает проблему потокобезопасности «в лоб»: если в любой момент работает только один поток, то гонки за ресурсами просто не возникает. Счётчик ссылок, внутренние структуры интерпретатора, состояние элементов — всё это защищено автоматически, без необходимости в тонкой синхронизации на каждом шаге. Более того, GIL упрощает интеграцию с C-библиотеками, которые часто не являются потокобезопасными: достаточно освободить GIL перед входом в C-код, и проблема решена.
Однако у этой элегантной защиты есть обратная сторона: GIL превращает многопоточность в Python в иллюзию. Даже если вы создадите десять потоков для выполнения вычислительно интенсивных задач, они не будут выполняться параллельно — в каждый момент будет работать только один, остальные будут ожидать освобождения GIL. Это делает многопоточность бесполезной для CPU-bound задач (тех, где узким местом является процессор), хотя для I/O-bound операций (работа с сетью, дисками, базами данных) потоки остаются эффективными, поскольку во время ожидания ввода-вывода GIL освобождается и другие потоки получают возможность работать.
Сборщик мусора также не остаётся в стороне от проблемы многопоточности. Когда GC запускает сборку, он приостанавливает все потоки (stop-the-world), сканирует память и освобождает циклические структуры. В однопоточной программе эта пауза практически незаметна, но в многопоточном приложении с интенсивным созданием элементов сборки могут происходить чаще, создавая заметные задержки. Именно поэтому в высокопроизводительных системах, где критична предсказуемая латентность, разработчики иногда отключают автоматическую сборку и запускают её вручную в контролируемые моменты времени.
Таким образом, архитектура управления памятью CPython определяет фундаментальные ограничения языка в области параллельных вычислений. Это не недостаток дизайна, а сознательный компромисс: простота, безопасность и удобство разработки в обмен на ограничения в многопоточной производительности.
Заключение
Понимание устройства памяти в Python — это не академическое знание, а практический инструмент, позволяющий писать более эффективный код и избегать типичных ловушек. Давайте сформулируем ключевые принципы, которые стоит держать в голове при разработке на Python:
- Управление памятью в python строится на сочетании подсчёта ссылок, сборщика мусора и внутреннего аллокатора. Вместе эти механизмы обеспечивают автоматическое и достаточно эффективное освобождение ресурсов.
- Подсчёт ссылок отвечает за мгновенное удаление объектов, когда на них больше не остаётся ссылок. Однако этот механизм не способен самостоятельно справляться с циклическими структурами.
- Сборщик мусора в python находит и удаляет циклические ссылки. Он работает поколениями и запускается периодически, что может влиять на производительность.
- Внутренний аллокатор pymalloc ускоряет работу с мелкими объектами. Он использует арены, пулы и блоки, что снижает накладные расходы на выделение памяти.
- Python не всегда возвращает память операционной системе сразу. Это связано с архитектурой менеджера памяти и не всегда означает утечку.
- Глобальная блокировка интерпретатора связана с управлением памятью. Она упрощает работу со счётчиком ссылок, но ограничивает многопоточность для вычислительных задач.
- Оптимизировать использование памяти стоит только после профилирования. Инструменты анализа помогают найти реальные проблемы, а не тратить время на преждевременную оптимизацию.
Если вы только начинаете осваивать профессию python-разработчика или хотите глубже разобраться во внутреннем устройстве языка, рекомендуем обратить внимание на подборку курсов по Python. В программах есть теоретическая и практическая часть, что помогает не только понять принципы работы памяти, но и закрепить знания на реальных задачах.
Рекомендуем посмотреть курсы по Python
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Профессия Python-разработчик
|
Eduson Academy
114 отзывов
|
Цена
116 400 ₽
|
От
9 700 ₽/мес
|
Длительность
6 месяцев
|
Старт
21 марта
|
Подробнее |
|
Fullstack-разработчик на Python
|
Нетология
46 отзывов
|
Цена
161 200 ₽
325 635 ₽
с промокодом kursy-online
|
От
4 975 ₽/мес
|
Длительность
18 месяцев
|
Старт
26 марта
|
Подробнее |
|
Python-разработчик
|
Академия Синергия
38 отзывов
|
Цена
89 800 ₽
224 500 ₽
с промокодом KURSHUB
|
От
3 742 ₽/мес
0% на 24 месяца
|
Длительность
6 месяцев
|
Старт
31 марта
|
Подробнее |
|
Профессия Python-разработчик
|
Skillbox
232 отзыва
|
Цена
157 107 ₽
285 648 ₽
Ещё -27% по промокоду
|
От
4 621 ₽/мес
9 715 ₽/мес
|
Длительность
12 месяцев
|
Старт
23 марта
|
Подробнее |
|
Python-разработчик
|
Яндекс Практикум
102 отзыва
|
Цена
159 000 ₽
|
От
18 500 ₽/мес
|
Длительность
9 месяцев
Можно взять академический отпуск
|
Старт
26 марта
|
Подробнее |

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.

OTUS vs GeekBrains для backend: где строже к качеству кода и полезнее ревью
OTUS или GeekBrains — где обучение backend-разработке даёт более строгий подход к качеству кода? Разбираем, как устроено code review, какие инженерные практики используют школы и как проверить уровень ревью до оплаты курса.

Яндекс Практикум vs Contented: Figma/UI — где быстрее собрать 3 кейса и получить внятные правки
Выбираете между курсами UX/UI дизайна в Яндекс Практикуме и Contented? Разбираем, где быстрее собрать три сильных кейса в портфолио, как устроены ревью проектов и на что обратить внимание при выборе обучения.