Кэширование в Laravel: полное руководство и стратегии применения
Кэширование в Laravel — это не просто очередная фича, которую можно игнорировать до момента, когда сервер начнёт задыхаться под нагрузкой. Это фундаментальный инструмент для создания быстрых и масштабируемых веб-приложений, который может превратить медленно ползущий сайт в молниеносную платформу.

В этой статье мы разберём не только базовые приёмы работы с кэшем (с конкретными примерами кода), но и стратегический подход к кэшированию — от простой мемоизации до сложных многоуровневых систем.
- Что такое кэширование и зачем оно нужно
- Основные подходы и уровни кэширования
- Как работает Cache::remember
- Управление жизненным циклом кэша
- Лучшие практики кэширования в Laravel
- Заключение
- Рекомендуем посмотреть курсы по веб разработке
Что такое кэширование и зачем оно нужно
Кэширование — это, по сути, способ сказать компьютеру: «Слушай, дружок, ты уже вычислял это значение пять минут назад, зачем тебе делать это снова?» Технически это механизм хранения часто запрашиваемых данных во временном хранилище, чтобы при следующем обращении не тратить время и ресурсы на повторные вычисления или запросы к базе данных.
Представьте библиотекаря, который каждый раз, когда кто-то спрашивает про «Войну и мир», бежит в архив и полчаса ищет книгу среди миллионов томов. А теперь представьте, что он просто держит популярные книги на рабочем столе. Вот это и есть кэширование — только вместо книг у нас данные, а вместо библиотекаря — ваше Laravel-приложение.
Зачем же нам это нужно? Три кита, на которых стоит вся философия кэширования:
Повышение производительности — самая очевидная выгода. Когда пользователь запрашивает список статей блога, зачем каждый раз дёргать базу данных, если этот список не менялся последние полчаса? Кэшированный ответ возвращается за миллисекунды вместо сотен миллисекунд на выполнение SQL-запроса. Пользователи счастливы, сервер не перегружен — все довольны.
Масштабируемость — когда ваше приложение начинает обслуживать не десяток, а тысячи пользователей одновременно, каждый сэкономленный запрос к базе данных становится золотом. Эффективное кэширование позволяет выдерживать пиковые нагрузки без необходимости немедленно покупать дополнительные серверы (хотя рано или поздно всё равно придётся, но это уже другая история).
Экономия ресурсов — меньше нагрузки на базу данных означает меньше потребления CPU и памяти на сервере. А если вы используете облачные сервисы с почасовой оплатой за ресурсы, то правильно настроенный кэш может серьёзно сократить ваши счета. Особенно это заметно, когда речь идёт о сложных аналитических запросах, которые могут выполняться секундами, а результат при этом актуален часами.
Кэширование — это как страховка для вашего приложения. В обычное время вы его почти не замечаете, но когда наступает час пик или происходит неожиданный наплыв пользователей, именно кэш спасает ваш сайт от превращения в медленную, неотзывчивую развалину.
Основные подходы и уровни кэширования
Кэширование в современных веб-приложениях — это не один инструмент, а целый оркестр различных технологий, где каждый музыкант играет свою партию. И как в любом оркестре, важно понимать, когда какой инструмент использовать, чтобы не получить какофонию вместо симфонии. Давайте разберём основные уровни кэширования от самых «внешних» до самых «внутренних».
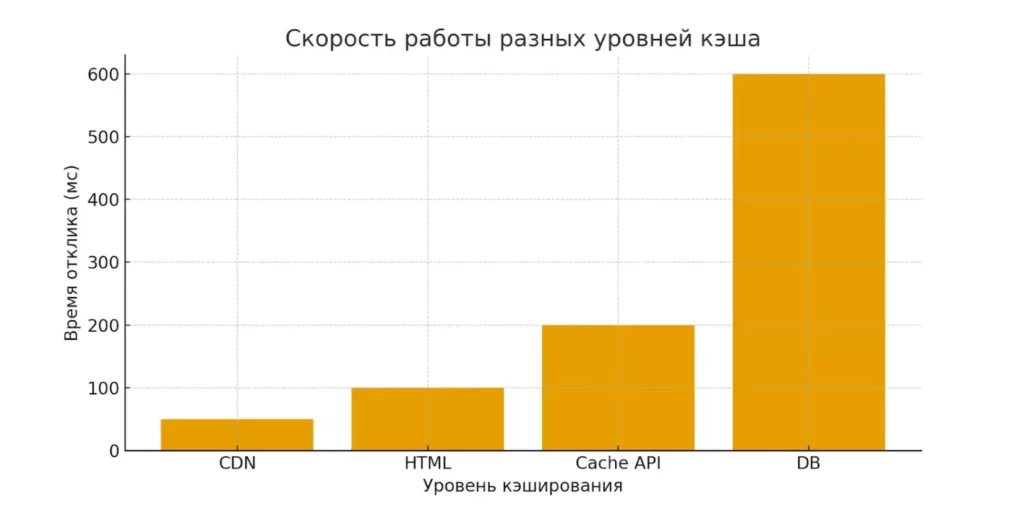
Диаграмма сравнивает скорость работы разных уровней кэширования. Чем ближе уровень к пользователю, тем быстрее отклик.
Кэширование на уровне DNS и CDN
Это самый «дальний» от вашего приложения уровень кэширования, но при этом потенциально самый эффективный. Представьте, что ваш сервер находится в Москве, а пользователь сидит во Владивостоке и запрашивает главную страницу сайта. Без CDN его запрос пролетит через всю страну, ваш сервер обработает его, вернёт HTML, и этот HTML снова полетит через всю страну обратно.
Сервисы вроде Cloudflare и Amazon CloudFront перехватывают эти запросы и отвечают из ближайшей к пользователю точки присутствия. Пользователь во Владивостоке получает ответ из хабинского дата-центра за несколько миллисекунд вместо сотен.
Скриншот главной страницы Cloudflare. Помогает визуально понять, что такое CDN-сервис, и как он выглядит на практике.
Идеально подходит для статического контента или страниц, которые редко меняются — лендинги, блоги, каталоги товаров. Но есть подводные камни: такой кэш нельзя очистить из вашего Laravel-приложения простым Cache::forget(), придётся интегрироваться с API CDN. Плюс, этот уровень не дружит с персонализированным контентом и сессиями пользователей.
HTML-кэширование в Laravel
Следующий уровень — кэширование готовых HTML-страниц прямо в вашем приложении. Пакеты вроде ResponseCache от Spatie или Page Cache от Joseph Silber позволяют сохранять полностью сгенерированные страницы и отдавать их при повторных запросах без выполнения контроллеров и представлений.
Это даёт больше контроля по сравнению с CDN — вы можете кэшировать страницы на основе данных сессии, GET-параметров или даже создавать персонализированные кэши для каждого пользователя. Правда, каждый запрос всё равно доходит до вашего сервера (если только не настроить Nginx для прямой отдачи кэшированных файлов), но обработка происходит значительно быстрее.
Скриншот официальной документации Laravel Cache.
Встроенные механизмы Laravel
Laravel из коробки предоставляет несколько механизмов кэширования, которые работают на уровне самого фреймворка:
- Configuration Caching (php artisan config:cache) — кэширует все конфигурационные файлы в один скомпилированный файл.
- Route Caching (php artisan route:cache) — ускоряет регистрацию маршрутов.
- View Caching — кэширует скомпилированные Blade-шаблоны.
Эти инструменты работают «из коробки» и дают заметный прирост производительности практически без усилий с вашей стороны.
Конфигурация кэша в Laravel
Прежде чем использовать кэширование на практике, важно понимать, как оно настраивается. Все параметры задаются в файле config/cache.php.
Основные моменты:
- default — драйвер кэша, который используется по умолчанию.
- stores — список доступных драйверов и их конфигурация.
- prefix — префикс для всех ключей кэша (полезно при работе с несколькими приложениями, использующими один Redis или Memcached).
Пример (фрагмент config/cache.php):
return [
'default' => env('CACHE_DRIVER', 'file'),
'stores' => [
'file' => [
'driver' => 'file',
'path' => storage_path('framework/cache/data'),
],
'redis' => [
'driver' => 'redis',
'connection' => 'cache',
],
],
'prefix' => env('CACHE_PREFIX', 'laravel_cache'),
];
Менять драйвер кэша удобно через переменную окружения .env:
CACHE_DRIVER=redis
Таким образом можно быстро переключать окружения (локально использовать file, а в продакшне — redis или memcached).
Laravel Cache API
А вот здесь начинается самое интересное — программный Cache API Laravel’а. Это универсальный швейцарский нож для кэширования любых данных:
// Сохранить значение на час
Cache::put('user-stats-' . $userId, $statistics, 3600);
// Получить значение или null
$stats = Cache::get('user-stats-' . $userId);
// Получить или выполнить функцию и сохранить результат
$posts = Cache::remember('recent-posts', 600, function () {
return Post::where('published', true)
->orderBy('created_at', 'desc')
->limit(10)
->get();
});
// Использование тегов для группового управления
Cache::tags(['users', 'posts'])->put('user-posts-' . $userId, $posts, 1800);
Cache::tags(['posts'])->flush(); // Очистить весь кэш с тегом 'posts'
Этот уровень идеален для кэширования результатов сложных вычислений, API-запросов к внешним сервисам или тяжёлых запросов к базе данных.
Драйверы кэша в Laravel
Laravel поддерживает несколько различных хранилищ для кэша. Каждый драйвер имеет свои особенности, которые важно учитывать:
- File — по умолчанию, хранение кэша в файловой системе (storage/framework/cache/data). Подходит для небольших проектов или локальной разработки.
- Database — хранение кэша в таблице БД. Удобно для проектов без внешних сервисов, но накладывает нагрузку на базу.
- Redis — быстрый in-memory хранилище. Хорош для высоконагруженных приложений, поддерживает теги и сложные сценарии.
- Memcached — аналог Redis, но с упрощённым функционалом, часто используется для распределённого кэширования.
- Array — временное хранение в памяти PHP-процесса. Полезно для тестов, но данные сбрасываются при завершении запроса.
- DynamoDB (через AWS) — распределённое облачное хранилище для продакшн-проектов в инфраструктуре Amazon.
Пример переключения драйвера в .env:
CACHE_DRIVER=memcached
А при необходимости можно подключать несколько драйверов одновременно (например, быстрый Redis для сессий и file для бэкапов).
Мемоизация (внутри одного запроса)
Мемоизация — это кэширование «на один раз», которое живёт только в рамках текущего HTTP-запроса. Простейший пример:
class UserService
{
protected $cachedStats;
public function getUserStats($userId)
{
if ($this->cachedStats !== null) {
return $this->cachedStats;
}
$this->cachedStats = $this->calculateComplexStats($userId);
return $this->cachedStats;
}
}
Или с использованием элегантного пакета Spatie Once:
$stats = once(function() use ($userId) {
return $this->calculateComplexStats($userId);
});
Мемоизация — отличная точка входа в мир кэширования, потому что она практически безрисковая (данные не могут устареть между запросами) и очень простая в реализации.
Кэширование запросов к базе данных
И наконец, самый распространённый случай — кэширование результатов запросов к базе данных:
$activeUsers = Cache::remember('active-users-count', 1800, function () {
return User::where('last_activity', '>', now()->subDays(7))->count();
});
Некоторые сервисы, такие как PlanetScale Boost, предлагают кэширование запросов на уровне самой базы данных, что может быть ещё эффективнее для определённых сценариев.
Каждый из этих уровней решает свои задачи, и в идеальном мире (который, как мы знаем, существует только в презентациях менеджеров) они работают вместе, создавая многоуровневую систему кэширования, где каждый запрос проходит через несколько фильтров оптимизации.
Как работает Cache::remember
Метод Cache::remember — это, пожалуй, самый элегантный и часто используемый инструмент кэширования в Laravel. Он работает по принципу «если есть — отдай, если нет — вычисли и сохрани», что делает его идеальным для большинства сценариев кэширования.
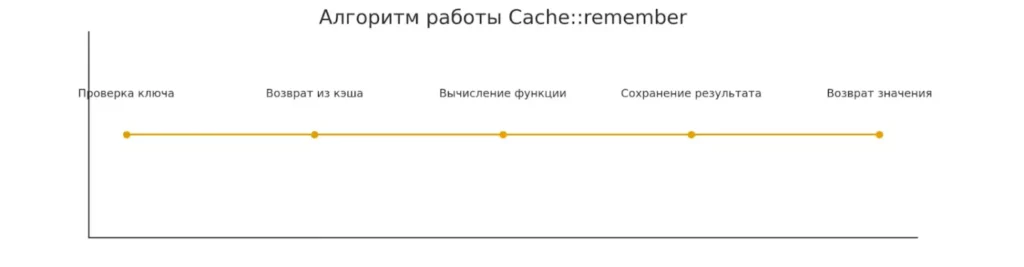
Схема пошагово показывает, как работает метод Cache::remember. Процесс включает проверку ключа, возврат из кэша или выполнение функции с последующим сохранением результата.
Алгоритм работы выглядит предельно просто:
- Проверка существования — Laravel проверяет, есть ли в кэше данные по указанному ключу.
- Возврат из кэша — если данные найдены и не истекли, они немедленно возвращаются.
- Выполнение функции — если данных нет, выполняется переданная функция (closure).
- Сохранение результата — результат функции сохраняется в кэше с указанным временем жизни.
- Возврат результата — вычисленное значение возвращается вызывающему коду.
Базовый пример кэширования списка статей блога:
$blogs = Cache::remember('all-blogs', 600, function () {
return DB::table('blogs')
->where('published', true)
->orderBy('created_at', 'desc')
->get();
});
Здесь ‘all-blogs’ — уникальный ключ кэша, 600 — время жизни в секундах (10 минут), а замыкание содержит логику получения данных из базы. При первом обращении выполнится запрос к БД, при последующих (в течение 10 минут) данные будут браться из кэша.
Но что делать, когда нужно кэшировать персонализированные данные? Тут приходится быть чуть более изобретательным с ключами кэша:
$userId = Auth::id();
$cacheKey = 'user-blogs-' . $userId;
$userBlogs = Cache::remember($cacheKey, 600, function () use ($userId) {
return DB::table('blogs')
->where('user_id', $userId)
->where('published', true)
->orderBy('created_at', 'desc')
->get();
});
Включение идентификатора пользователя в ключ кэша гарантирует, что каждый пользователь получит свой персонализированный набор данных. Иначе говоря, Петя не увидит блоги Васи, даже если они оба запросят «свои» статьи одновременно.
Ещё более продвинутый пример — кэширование с учётом дополнительных параметров:
$category = request('category', 'all');
$page = request('page', 1);
$cacheKey = "blogs-{$category}-page-{$page}";
$blogs = Cache::remember($cacheKey, 300, function () use ($category, $page) {
$query = DB::table('blogs')->where('published', true);
if ($category !== 'all') {
$query->where('category', $category);
}
return $query->orderBy('created_at', 'desc')
->skip(($page - 1) * 15)
->take(15)
->get();
});
Красота Cache::remember в том, что он делает кэширование практически прозрачным — ваш код читается так, как будто кэширования вообще нет, но при этом получает все его преимущества. Это классический пример хорошего API: мощный функционал скрыт за простым интерфейсом.
Правда, стоит помнить об одной важной детали: функция внутри Cache::remember должна быть детерминированной — то есть при одинаковых входных данных всегда возвращать одинаковый результат. Если внутри функции используются rand(), now() или другие изменяющиеся значения, кэширование может преподнести неприятные сюрпризы.
Управление жизненным циклом кэша
Кэширование — это как содержание домашнего питомца: мало его завести, нужно ещё и правильно за ним ухаживать. Иначе вместо милого котика, который радует глаз, получится злобное чудовище, которое портит жизнь всем вокруг. В случае с кэшем «злобное чудовище» — это устаревшие данные, которые могут довести до инфаркта и вас, и ваших пользователей.
График иллюстрирует принцип работы TTL (времени жизни кэша). Данные доступны до момента истечения времени и автоматически сбрасываются после.
Проблема устаревших данных
Представьте ситуацию: пользователь покупает товар в вашем интернет-магазине, деньги списываются с карты, но страница всё ещё показывает, что товар в корзине — потому что список товаров закэширован. Пользователь в панике пытается купить ещё раз, деньги списываются повторно, и вот уже звонит в поддержку с претензиями. А в это время ваш коллега пытается понять, почему в базе данных одна информация, а на сайте — совсем другая.
Или ещё веселее: система отправки email-уведомлений кэширует список получателей, но кто-то изменил адрес в профиле. В итоге важное письмо улетает не туда, клиент не получает информацию о заказе, и снова звонки в поддержку. Такие баги особенно коварны, потому что они нестабильны — иногда всё работает, иногда нет, и понять закономерность очень сложно.
Invalidation — очистка устаревшего кэша
Золотое правило кэширования: каждый раз, когда вы добавляете кэш, сразу же продумывайте, когда и как этот кэш будет очищаться. Это не опциональная задача «на потом», это обязательная часть реализации.
Трёхшаговый процесс правильного внедрения кэширования:
- Добавить кэширование — написать код, который сохраняет и извлекает данные.
- Документировать слой кэширования — описать, что кэшируется, как долго живёт, как настраивается в разных окружениях.
- Реализовать invalidation — добавить логику очистки кэша и обязательно протестировать её.
Простейший пример с блогом:
// Кэшируем список статей
$posts = Cache::remember('blog-posts', 1800, function () {
return Post::published()->latest()->get();
});
// При создании новой статьи очищаем кэш
class PostController extends Controller
{
public function store(Request $request)
{
$post = Post::create($request->validated());
// Очищаем кэш списка статей
Cache::forget('blog-posts');
return redirect()->route('posts.show', $post);
}
}
Для более сложных сценариев можно использовать события модели:
class Post extends Model
{
protected static function booted()
{
// Очищаем кэш при любых изменениях постов
static::saved(function () {
Cache::forget('blog-posts');
Cache::tags(['posts'])->flush();
});
static::deleted(function () {
Cache::forget('blog-posts');
Cache::tags(['posts'])->flush();
});
}
}
Eviction-стратегии
Иногда ручная очистка кэша становится слишком сложной — особенно когда у вас десятки различных ключей, зависящих друг от друга. Тут на помощь приходят стратегии автоматического «вытеснения» (eviction).
TTL (Time To Live) — самый простой подход. Данные автоматически удаляются через определённое время:
// Данные живут максимум час, независимо от изменений
Cache::put('user-stats-' . $userId, $stats, 3600);
Вытеснение на уровне драйвера — Redis и Memcached умеют автоматически удалять старые данные, когда заканчивается память. Настраивается в конфигурации самого драйвера.
Умные ключи с временными метками — изящный трюк для автоматической инвалидации:
// Включаем время последнего изменения пользователя в ключ
$cacheKey = "user-stats-{$user->id}-{$user->updated_at->timestamp}";
$stats = Cache::remember($cacheKey, 3600, function () use ($user) {
return $this->calculateUserStats($user);
});
// При изменении пользователя делаем touch()
$user->update(['name' => $newName]);
$user->touch(); // updated_at изменится, старый кэш станет недостижимым
Такой подход работает с настройками вытеснения — старые ключи просто «забываются» драйвером кэша, когда заканчивается место.
Планировщик для очистки — если не хочется настраивать eviction на уровне драйвера:
// В app/Console/Kernel.php
protected function schedule(Schedule $schedule)
{
// Очищаем определённые теги каждые 6 часов
$schedule->call(function () {
Cache::tags(['temporary', 'stats'])->flush();
})->everySixHours();
}
Постоянные vs изменяемые данные
Не все данные одинаково полезны — некоторые стоит кэшировать «навсегда», другие требуют регулярного обновления. Классический пример: API для получения GPS-координат по адресу.
Адрес «Красная площадь, 1, Москва» вряд ли поменяет свои координаты в ближайшие годы — такие данные можно кэшировать очень долго или даже сохранять в отдельную таблицу базы данных. А вот список «проблемных адресов, которые не удалось геокодировать» может меняться, когда улучшается API внешнего сервиса.
// Постоянные данные -- в отдельный драйвер или БД
Cache::store('permanent')->put("coordinates-{$addressHash}", $coordinates);
// Временные данные -- в обычный кэш с TTL
Cache::put("failed-geocoding-{$addressHash}", true, 86400); // сутки
Разделение типов данных по разным хранилищам позволяет применять разные стратегии очистки: временные данные можно смело сносить командой cache:clear, а постоянные останутся нетронутыми.
В итоге правильное управление жизненным циклом кэша — это баланс между производительностью и актуальностью данных. Слишком агрессивная очистка сводит на нет пользу от кэширования, а слишком консервативная может привести к показу устаревшей информации. Ключ к успеху — понимание бизнес-логики вашего приложения и тщательное тестирование сценариев инвалидации.
Лучшие практики кэширования в Laravel
После того как мы разобрались с техническими аспектами кэширования, пора поговорить о том, как использовать все эти знания правильно. Кэширование — это как острый нож: в умелых руках творит чудеса, в неумелых — может серьёзно поранить. Вот набор проверенных практик, которые помогут вам избежать большинства граблей.
Не кэшируйте всё подряд — самая частая ошибка начинающих. Увидев, как Cache::remember ускоряет один запрос, появляется соблазн обернуть в кэш каждую строчку кода. Но кэширование имеет смысл только для операций, которые действительно требуют значительных ресурсов. Простой запрос User::find($id) с правильно настроенными индексами выполняется за единицы миллисекунд — кэшировать его бессмысленно. А вот сложная аналитика с JOIN’ами по нескольким таблицам и агрегацией — отличный кандидат.
Всегда продумывайте стратегию очистки — это не просто рекомендация, это жизненная необходимость. Каждый раз, когда добавляете Cache::remember, сразу же спрашивайте себя: «При каких условиях эти данные станут неактуальными?» Если не можете ответить — не кэшируйте. Лучше медленный, но правильный сайт, чем быстрый, но показывающий устаревшую информацию.
Документируйте слои кэша — через полгода вы забудете, что означает ключ usr_stats_v2_final_new, а ваши коллеги будут проклинать день, когда вы это написали. Создайте простой документ или комментарии в коде, где описано:
- Что кэшируется и зачем.
- Сколько живёт кэш.
- При каких условиях очищается.
- Как настроить в разных окружениях (local, staging, production).
Используйте осмысленные ключи кэша — Cache::remember(‘data’, …) это плохо. Cache::remember(‘user-monthly-stats-‘ . $userId . ‘-‘ . $month, …) — намного лучше. Хорошие ключи должны быть уникальными, описательными и включать все параметры, от которых зависит результат.
Тестируйте и мониторьте — добавьте тесты, которые проверяют не только работу кэша, но и его очистку. Настройте мониторинг hit rate (процент попаданий в кэш) — если он резко упал, возможно, что-то сломалось в логике инвалидации.
Чек-лист для внедрения кэширования:
✅ Операция действительно ресурсоёмкая (> 100ms или дорогие API-вызовы).
✅ Понятно, когда данные становятся неактуальными.
✅ Реализована логика очистки кэша.
✅ Добавлены тесты для проверки инвалидации.
✅ Ключи кэша уникальны и описательны.
✅ Время жизни кэша соответствует бизнес-требованиям.
✅ Есть документация или комментарии в коде.
✅ Настроен мониторинг (опционально, но желательно).
Выбирайте правильный TTL — время жизни кэша должно соответствовать природе данных. Курсы валют можно кэшировать на несколько часов, список товаров в категории — на десятки минут, а результаты поиска — на единицы минут. Слишком длинный TTL увеличивает риск показа устаревших данных, слишком короткий снижает эффективность кэширования.
Используйте теги для группового управления — если в вашем приложении много взаимосвязанных данных, теги кэша позволяют очищать группы связанных записей одной командой:
Cache::tags(['users', 'posts'])->put($key, $value, $ttl); Cache::tags(['posts'])->flush(); // Очистит все кэши с тегом 'posts'
Будьте осторожны с кэшированием в тестах — если ваши тесты используют кэш, убедитесь, что между тестами он очищается. Иначе тесты могут влиять друг на друга и давать ложные результаты.
Планируйте fallback-стратегии — что произойдёт, если драйвер кэша недоступен? Laravel умеет graceful degradation, но лучше явно протестировать поведение приложения при отключенном кэше.
И помните главное правило: кэширование должно быть невидимым для пользователей. Если пользователь может заметить, что данные кэшированы (кроме увеличения скорости), значит, что-то идёт не так. Хороший кэш — как хорошая магия: впечатляющий результат при полном отсутствии понимания, как это работает.
Заключение
Кэширование в Laravel — это не просто инструмент для ускорения приложений, это фундаментальная технология, которая определяет разницу между «работающим» и «масштабируемым» проектом. Мы прошли путь от простейших примеров с Cache::remember до сложных многоуровневых стратегий с invalidation и eviction — и это лишь верхушка айсберга возможностей современного кэширования. Подведем итоги:
- Кэширование ускоряет работу приложений. Оно снижает нагрузку на сервер и обеспечивает быстрый отклик.
- Laravel предлагает несколько уровней кэширования. От встроенных инструментов до интеграции с CDN и базами данных.
- Cache::remember упрощает работу с данными. Он позволяет автоматически сохранять и возвращать результаты вычислений.
- Управление жизненным циклом кэша критически важно. Неправильная настройка может привести к устаревшим данным и ошибкам.
- Правильные практики кэширования повышают масштабируемость. Они делают приложение стабильным и экономят ресурсы.
Если вы только начинаете осваивать профессию веб-разработчика, рекомендуем обратить внимание на подборку курсов по веб-разработке. В них есть и теоретическая база, и практические примеры, которые помогут глубже понять кэширование и внедрить его в реальные проекты.
Рекомендуем посмотреть курсы по веб разработке
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Веб-разработчик
|
Eduson Academy
82 отзыва
|
Цена
Ещё -5% по промокоду
119 000 ₽
|
От
9 917 ₽/мес
|
Длительность
12 месяцев
|
Старт
6 февраля
|
Ссылка на курс |
|
Веб-разработчик с нуля до PRO
|
Skillbox
203 отзыва
|
Цена
Ещё -20% по промокоду
294 783 ₽
589 565 ₽
|
От
8 670 ₽/мес
Без переплат на 1 год.
|
Длительность
10 месяцев
|
Старт
21 декабря
|
Ссылка на курс |
|
Веб-разработчик с нуля
|
Нетология
44 отзыва
|
Цена
с промокодом kursy-online
141 800 ₽
286 430 ₽
|
От
4 376 ₽/мес
Без переплат на 2 года.
7 222 ₽/мес
|
Длительность
17 месяцев
|
Старт
5 января
|
Ссылка на курс |
|
Fullstack-разработчик на python (с нуля)
|
Eduson Academy
82 отзыва
|
Цена
Ещё -5% по промокоду
95 000 ₽
|
От
7 917 ₽/мес
20 642 ₽/мес
|
Длительность
7 месяцев
|
Старт
30 декабря
|
Ссылка на курс |
|
Профессия Веб-разработчик
|
Skillbox
203 отзыва
|
Цена
Ещё -20% по промокоду
152 538 ₽
305 075 ₽
|
От
4 486 ₽/мес
Без переплат на 34 месяца с отсрочкой платежа 3 месяца.
|
Длительность
24 месяца
|
Старт
21 декабря
|
Ссылка на курс |

Лучшие планировщики задач — ТОП-13 приложений для эффективного тайм-менеджмента
Хотите выбрать идеальное приложение для продуктивной работы и планирования задач? Мы собрали лучшие приложения для тайм-менеджмента, их возможности и советы по подбору подходящего инструмента.

Что такое C# и как он работает: история появления, особенности и области применения
Си шарп — это язык, который используют в играх, веб-сервисах и корпоративных системах. Как он работает, в чём его сильные и слабые стороны и стоит ли начинать с него обучение? В статье разбираем всё по шагам и простым языком.

Грамотная миграция баз данных: секреты успеха
Узнайте, как грамотно спланировать миграцию базы данных и избежать потери данных. Практические советы, примеры и инструменты для успешного перехода

Зарплата верстальщиков HTML/CSS — сколько зарабатывают в 2025 году
Интересует, сколько зарабатывают верстальщики? В этой статье рассказываем, от чего зависит их доход, какие навыки повышают зарплату и где искать лучшие вакансии.