Коллекции в Java: что выбрать и зачем это знать
Коллекции в Java — это не просто набор структур данных, а настоящий фундамент для любого серьезного приложения. Представьте, что вы пытаетесь поддерживать порядок в своей цифровой жизни без папок, списков и таблиц — примерно то же самое означает программирование на Java без collection. В этом курсе рассмотрим, что такое коллекции в Джава, как их выбрать и что учитывать при выборе.

Java Collections Framework (JCF) — это тот инструментарий, который позволяет элегантно хранить, обрабатывать и передавать данные, не изобретая велосипед заново для каждого проекта. Коллекции решают фундаментальную проблему: как эффективно работать с группами объектов, когда заранее не известно их точное количество?
Не случайно вопросы о collection — любимая тема технических интервью для Java-разработчиков всех уровней. Рекрутеры знают: если кандидат уверенно ориентируется в хитросплетениях JCF, он способен создавать производительный и поддерживаемый код. Так что, понимаете вы разницу между HashMap и TreeMap или нет — вопрос не академический, а вполне себе карьерный.
- Что такое Java Collections Framework (JCF)
- Основные интерфейсы и их особенности
- List
- Set
- Queue / Deque
- Map
- Как выбрать нужную коллекцию
- Что учитывать при выборе
- Таблица выбора коллекции
- Коллекции и производительность
- Таблица Big-O сложностей для основных операций
- Коллекции на собеседовании
- Частые вопросы и темы
- Как готовиться
- Заключение
- Рекомендуем посмотреть курсы по Java
Что такое Java Collections Framework (JCF)
Думаю, пришло время разложить этот фреймворк по полочкам. Java Collections Framework — это не какая-то внешняя библиотека, которую нужно устанавливать отдельно (как, возможно, многие новички могли бы подумать). Это встроенная часть JDK, которая предоставляет архитектуру для представления и обработки групп объектов — или, говоря простым языком, набор классов и интерфейсов для работы с коллекциями данных.
Появился этот фреймворк не просто так, а для решения вполне конкретных проблем. До JDK 1.2 разработчикам приходилось либо создавать собственные коллекции (что очевидно неэффективно — примерно как изобретать лопату каждый раз, когда нужно что-то выкопать), либо использовать ограниченный набор имеющихся классов вроде Vector и Hashtable. JCF принёс в мир Java порядок, согласованность и предсказуемость.
Если посмотреть на иерархию JCF, она напоминает родословное древо благородной семьи — где каждый потомок унаследовал определённые черты, но обзавёлся и собственными особенностями. На вершине этой иерархии находится интерфейс Iterable, от которого наследуется Collection. А далее начинается самое интересное: интерфейс Collection разветвляется на три основных вида — List, Set и Queue.
При этом отдельно, словно дальний, но важный родственник, стоит интерфейс Map, который не наследуется от Collection (хотя и входит в JCF). Вместо этого он идёт собственным путём, храня данные в виде пар «ключ-значение».
Каждый из этих интерфейсов имеет свои конкретные реализации — те самые классы, объекты которых мы создаём в нашем коде: ArrayList, HashSet, HashMap и т.д. Они отличаются друг от друга принципами работы, скоростью операций и особенностями хранения данных — примерно как разные типы транспорта: кто-то быстрее, кто-то вместительнее, а кто-то экономичнее.
| Интерфейс | Особенности | Основные реализации |
|---|---|---|
| List | Упорядоченная collection с дубликатами | ArrayList, LinkedList |
| Set | Коллекция уникальных элементов | HashSet, TreeSet |
| Queue | Очередь с принципом FIFO | LinkedList, PriorityQueue |
| Map | Пары «ключ-значение» | HashMap, TreeMap |
Знание этой иерархии — не просто теоретическая база. Это практический инструмент, который позволяет выбирать оптимальную структуру данных для каждой конкретной задачи, что напрямую влияет на производительность приложения и качество кода.
Основные интерфейсы и их особенности
List
Давайте начнем с, пожалуй, самого популярного ребенка в семействе collection — интерфейса List. Если вы когда-нибудь составляли список покупок или задач, то интуитивно уже понимаете его суть: это упорядоченная collection элементов, в которой важен порядок, а одинаковые element могут повторяться. Ну, знаете, как в той песне — «всё по порядку и ничего не менять».
Практически, это означает, что каждый element в List имеет свой индекс (начиная с нуля, конечно же — мы ведь программисты, а не обычные люди). И да, если вам хочется добавить в список покупок «молоко» три раза, потому что вы патологически забывчивы — пожалуйста, List вас за это не осудит.
Теперь давайте познакомимся с основными реализациями этого интерфейса — они все, как родственники на семейном ужине: вроде похожи, но у каждого свой характер.
- ArrayList — самый популярный парень в классе. Внутри он использует обычный массив, который автоматически расширяется при добавлении новых элементов. Доступ к произвольному element по индексу выполняется за O(1) — то есть моментально, независимо от размера списка. Это как найти нужную страницу в книге, когда знаешь её номер. Но есть и недостатки: вставка или удаление element в середине требует сдвига всех последующих элементов, что для больших списков может быть затратно.
- LinkedList — более гибкий, но и более требовательный к памяти родственник. Представьте цепочку людей, держащихся за руки, где каждый знает только своих ближайших соседей. Вставка и удаление в середине происходят быстро (O(1)), но только если вы уже знаете позицию — иначе придется пройти по цепочке до нужного места (O(n)). Доступ к произвольному element тоже требует прохода по списку — не самый эффективный вариант, если вам нужно часто обращаться к случайным элементам.
- Vector — старший брат ArrayList, который родился в эпоху, когда о многопоточности только начинали задумываться. Все его методы синхронизированы, что делает его потокобезопасным, но и более медленным. Сегодня его использование не рекомендуется, если только у вас нет особых причин для этого — как ношение галстука-бабочки в повседневной жизни.
- Stack — специализированная реализация на основе Vector, работающая по принципу LIFO (последним пришел — первым ушел). Представьте стопку тарелок: добавляете сверху, берете тоже сверху. Сегодня вместо Stack обычно рекомендуется использовать ArrayDeque, который выполняет те же операции, но более эффективно.
| Реализация | Преимущества | Недостатки | Когда использовать |
|---|---|---|---|
| ArrayList | Быстрый доступ к element по индексу. Компактное хранение. | Медленная вставка/удаление в середине для больших списков. | Когда чаще читаете, чем модифицируете. Произвольный доступ по индексу. |
| LinkedList | Быстрая вставка/удаление в любом месте (если известна позиция). Реализует также Queue и Deque. | Больше памяти для хранения ссылок. Медленный произвольный доступ. | Когда часто вставляете/удаляете в начале/конце или в известных позициях. |
| Vector | Потокобезопасность. | Медленнее из-за синхронизации. Устаревший API. | Практически никогда в новом коде. |
| Stack | Удобен для работы со стеком. | Основан на Vector, медленнее современных альтернатив. | Лучше использовать ArrayDeque для функциональности стека. |
Выбор между ними — это всегда компромисс между скоростью доступа, эффективностью модификации и использованием памяти. И да, это как раз те вопросы, которые любят задавать на собеседовании: «В чем разница между ArrayList и LinkedList?» или «Когда бы вы предпочли LinkedList вместо ArrayList?». Так что, если хотите блеснуть на интервью — запомните эту таблицу. Ну, или хотя бы её общий смысл.
Set
Переходим к следующему интерфейсу коллекций — Set, или множеству, как его назвали бы математики. Если List — это записная книжка, где можно писать что угодно и в любом количестве, то Set — это элитный клуб с правилом «только уникальные личности». Дубликаты? Извините, охрана у входа вежливо попросит вашу копию удалиться.
Главная особенность множества в том, что оно гарантирует уникальность element. И это не просто каприз — такая структура идеально подходит для ситуаций, когда вам нужно исключить повторения: список уникальных посетителей сайта, набор различных категорий товаров или, если угодно, перечень причин, почему вы опять не написали тесты к своему коду (и «не было времени» может присутствовать только один раз, как бы вы ни старались).
Давайте рассмотрим основные реализации интерфейса Set:
- HashSet — самая быстрая и распространенная реализация. Использует хеш-таблицу для хранения элементов, благодаря чему операции добавления, удаления и проверки наличия элемента выполняются за постоянное время O(1). Это как моментальная телепортация к нужному element, вместо утомительного перебора всего списка. Но за эту скорость приходится платить: элементы в HashSet не упорядочены, так что если вы ожидаете какой-то порядок — будете разочарованы. Это как искать книги в библиотеке, где они расставлены не по алфавиту или тематике, а по какому-то загадочному принципу, известному только библиотекарю.
- LinkedHashSet — это HashSet с памятью. Он помнит порядок, в котором вы добавляли элементы, и при итерации возвращает их именно в этом порядке. Достигается это за счет дополнительных связей между element (отсюда и «Linked» в названии). Расплата — несколько большее использование памяти и чуть меньшая производительность, чем у простого HashSet. Но если вам важен порядок добавления — это ваш выбор.
- TreeSet — стройная и упорядоченная реализация, которая хранит элементы в виде красно-черного дерева. Главное преимущество — element всегда отсортированы, либо по естественному порядку (если объекты реализуют Comparable), либо с помощью специального компаратора. Это как книжные полки, где томики аккуратно расставлены по алфавиту — всегда можно быстро найти нужный. Цена этого порядка — операции добавления, удаления и поиска выполняются за O(log n), что медленнее, чем у HashSet, но все равно очень эффективно для большинства задач.
Когда же использовать Set вместо List? Ответ прост: когда уникальность элементов важнее их порядка или возможности доступа по индексу. Например:
- Хранение списка уникальных пользователей системы
- Удаление дубликатов из collection
- Быстрая проверка наличия element (особенно для HashSet)
- Хранение element в отсортированном виде (для TreeSet)
И да, на собеседовании вас вполне могут спросить: «Что будет, если добавить в HashSet объект, а потом изменить его состояние так, что изменится его хеш-код?». Ответ: ничего хорошего — объект окажется «потерянным» в множестве, потому что его будут искать по новому хеш-коду, а хранится он по старому. Это как переклеить номер на почтовом ящике, не сказав об этом почтальону — ваши письма будут доставляться по старому адресу.
Так что, если вы храните в Set изменяемые объекты — будьте особенно осторожны. Лучше всего использовать неизменяемые объекты или хотя бы не менять те их поля, которые влияют на результат hashCode() и equals().
Queue / Deque
Теперь давайте перейдем к очередям — структурам данных, которые следуют принципу «первым пришел — первым обслужен». Если вы когда-нибудь стояли в очереди в банке или супермаркете (а кто из нас не стоял?), то интуитивно понимаете концепцию Queue в Java.
Очередь в программировании работает точно так же, как и в реальной жизни: новые элементы добавляются в конец, а извлекаются из начала. Этот принцип называется FIFO (First In, First Out) — первым пришел, первым ушел. И если в реальной жизни всегда найдется кто-то, кто попытается влезть без очереди, то в программировании такой беспорядок, к счастью, невозможен.
Интерфейс Deque (произносится «дек», а не «дэкью», как многие ошибочно полагают) — это двунаправленная очередь, которая позволяет добавлять и удалять element с обоих концов. Это как очередь в фастфуде с двумя окошками: можно встать как в начало, так и в конец, в зависимости от ваших привилегий.
Основные реализации этих интерфейсов:
- PriorityQueue — это особый вид очереди, где элементы выстраиваются не по времени поступления, а по приоритету. Представьте очередь в аэропорту, где сначала пропускают пассажиров бизнес-класса, а потом уже всех остальных. В PriorityQueue элементы автоматически сортируются либо по естественному порядку (если они реализуют интерфейс Comparable), либо с помощью компаратора, переданного в конструктор. Это невероятно удобно для задач, где нужно постоянно получать минимальный или максимальный элемент из collection — например, при обработке задач по их приоритету.
- ArrayDeque — эффективная реализация Deque, использующая динамический массив. Она быстрее LinkedList для большинства операций и не имеет ограничений на емкость (кроме доступной памяти). ArrayDeque может использоваться как классическая очередь (FIFO), так и как стек (LIFO — Last In, First Out), и даже как двусторонняя очередь, когда элементы добавляются и удаляются с обоих концов.
Когда же использовать очереди? Вот несколько типичных сценариев:
- Обработка задач в порядке их поступления (классическая очередь)
- Реализация алгоритма обхода в ширину для графов и деревьев
- Управление заданиями по приоритету (PriorityQueue)
- Реализация алгоритма обхода в глубину (стек, через ArrayDeque)
- Реализация буфера сообщений или команд
Интересный факт: LinkedList не только реализует интерфейс List, но и интерфейс Deque. Это делает его универсальным инструментом, который может использоваться и как список, и как двусторонняя очередь. Впрочем, есть правило, которое я называю «законом мастера на все руки» — тот, кто умеет делать всё, редко бывает лучшим в чем-то конкретном. Так и с LinkedList — для операций с очередями ArrayDeque обычно эффективнее.
Так что, если вам нужно реализовать принцип «первым пришел — первым обслужен» или «последним пришел — первым обслужен», или вообще создать какой-то гибридный порядок обработки элементов — очереди и стеки (через Deque) будут вашими верными помощниками.
Map
Ну а теперь, дамы и господа, представляю вам интерфейс Map — своеобразного отщепенца в семействе JCF, который технически даже не является коллекцией (не наследуется от интерфейса Collection), но при этом является, пожалуй, одной из самых полезных структур данных в Java.
Map — это структура «ключ-значение», или, говоря более приземленно, своего рода словарь или телефонная книга: вы ищете человека по имени (ключу) и получаете его номер телефона (значение). В реальном программировании это может быть поиск пользователя по ID, товара по артикулу, настройки по её названию — да практически что угодно, где есть пара из идентификатора и связанных с ним данных.
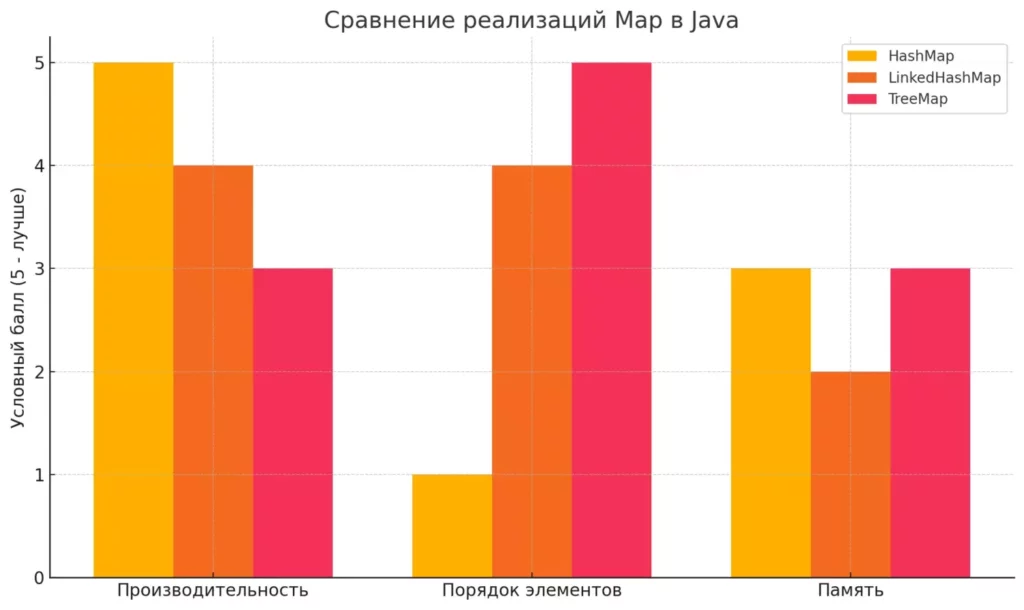
На диаграмме сравниваются три популярные реализации интерфейса Map в Java по нескольким критериям
Особенность Map в том, что ключи должны быть уникальными (как и в телефонной книге — у вас может быть только один номер для «Мама»), а вот значения могут повторяться (у нескольких людей может быть одинаковый номер телефона — например, у рабочих телефонов компании).
Давайте рассмотрим основные реализации этого «особенного» интерфейса:
- HashMap — вероятно, самая используемая реализация Map. Работает на основе хеш-таблицы, что обеспечивает операциям добавления, удаления и поиска сложность O(1) в среднем случае. Это как моментальный телепорт к нужному ящику с информацией. Однако, порядок элементов в HashMap не определен — итерация может возвращать элементы в любом порядке. Кроме того, HashMap не является потокобезопасным, так что в многопоточной среде без дополнительной синхронизации его использовать опасно — как доверить одну телефонную книгу десяти людям, которые одновременно пытаются в ней что-то исправить.
- LinkedHashMap — это HashMap с чувством порядка. Он сохраняет порядок вставки элементов (или порядок доступа, если указан соответствующий параметр в конструкторе), что делает итерацию предсказуемой. За это приходится платить небольшим дополнительным расходом памяти и времени выполнения операций. Используйте, когда важен порядок элементов, например, при кэшировании с вытеснением по принципу «давно не использовался».
- TreeMap — упорядоченная реализация на основе красно-черного дерева. Элементы всегда отсортированы по ключам (либо естественным образом, либо с помощью компаратора). Это как библиотека, где книги всегда расставлены по алфавиту. Цена этой упорядоченности — логарифмическая сложность O(log n) для основных операций, что медленнее, чем у HashMap, но все еще весьма эффективно. Используйте, когда нужен быстрый доступ к отсортированным данным или диапазону ключей.
- WeakHashMap — специализированная версия HashMap, где ключи хранятся как слабые ссылки. Это означает, что если на ключ больше нет «сильных» ссылок в программе, он может быть удален сборщиком мусора вместе с соответствующим значением. Это полезно для реализации кэшей, где данные хранятся, пока на них есть ссылки, а потом автоматически удаляются — как записки, которые исчезают, когда о них забывают.
- EnumMap — специализированная реализация для ключей-перечислений (enum). Очень эффективно использует память и обеспечивает отличную производительность, так как знает, что число возможных ключей фиксировано и известно заранее. Это как ограниченный набор ячеек, где каждая соответствует конкретному значению перечисления.
| Реализация | Порядок элементов | Производительность | Особенности |
|---|---|---|---|
| HashMap | Не определен | O(1) для основных операций | Наиболее универсальная и часто используемая |
| LinkedHashMap | По порядку вставки или доступа | Немного медленнее HashMap | Удобна для предсказуемой итерации |
| TreeMap | Отсортирован по ключам | O(log n) для основных операций | Хороша для получения отсортированных данных |
| WeakHashMap | Как у HashMap | Как у HashMap, плюс возможная очистка | Автоматическая очистка «забытых» ключей |
| EnumMap | По порядку констант enum | Очень быстрая | Только для ключей-перечислений |
Важно понимать, что для корректной работы с HashMap и другими картами, использующими хеширование, классы ключей должны правильно реализовывать методы hashCode() и equals(). Если вы используете собственные классы в качестве ключей и не переопределите эти методы, можете столкнуться с неожиданным поведением — объекты, которые вы считаете равными, система будет считать разными, и наоборот.
Кстати, если вам интересно, как на самом деле работает хеширование в HashMap — это отдельная увлекательная тема, которую обожают поднимать на собеседованиях. На удивление много разработчиков не понимают, что происходит, когда два разных объекта имеют одинаковый хеш-код (это называется коллизией), и как HashMap справляется с этой ситуацией (через цепочки связанных объектов в одном «бакете» или, начиная с Java 8, через красно-черное дерево при достаточном количестве коллизий).
Как выбрать нужную коллекцию
Что учитывать при выборе
Выбор правильной коллекции — это как выбор подходящего инструмента для конкретной работы. Молотком можно забить гвоздь, но им же можно и часы разбить — технически возможно, но явно не оптимально. Так же и с коллекциями — почти любая задача может быть решена с использованием ArrayList, но правильно подобранная структура данных сделает ваш код более элегантным, понятным и производительным.
Итак, на что следует обратить внимание при выборе collection?
- Порядок элементов — нужно ли сохранять порядок вставки или поддерживать элементы в отсортированном состоянии? Если да, то ArrayList, LinkedList, LinkedHashSet, LinkedHashMap, или TreeSet/TreeMap будут хорошими кандидатами. Если порядок не важен, HashSet или HashMap обычно более эффективны.
- Уникальность элементов — нужны ли дубликаты? Если нет, и вам важно исключить повторения — выбирайте реализации Set. Если дубликаты допустимы — List будет лучшим выбором.
- Доступ к элементам — как будут извлекаться элементы? По индексу? По ключу? В порядке добавления или удаления? Для произвольного доступа по индексу ArrayList работает лучше всего. Для доступа по ключу — очевидно, Map. Для обработки элементов в порядке FIFO или LIFO — Queue или Deque.
- Частота модификаций — насколько часто будут добавляться или удаляться элементы? Если операции вставки/удаления в середину списка происходят часто, LinkedList может быть эффективнее, чем ArrayList. Но для большинства сценариев преимущества ArrayList перевешивают его недостатки.
- Многопоточность — будет ли коллекция использоваться в многопоточной среде? Стандартные реализации collection не являются потокобезопасными (за исключением устаревших Vector и Hashtable). Для многопоточного доступа рассмотрите классы из пакета java.util.concurrent, такие как ConcurrentHashMap или CopyOnWriteArrayList, или используйте обертки из класса Collections (synchronizedList, synchronizedMap и т.д.).
- Потребление памяти — ограничены ли вы в ресурсах? Некоторые коллекции требуют больше памяти, чем другие. Например, LinkedList хранит ссылки на предыдущий и следующий элементы для каждого узла, что увеличивает накладные расходы по сравнению с ArrayList.
Таблица выбора коллекции
| Задача | Рекомендуемая коллекция | Альтернатива |
|---|---|---|
| Быстрый доступ по индексу | ArrayList | Vector (если нужна потокобезопасность) |
| Частое добавление/удаление в начале/конце | LinkedList | ArrayDeque (если не нужен доступ по индексу) |
| Быстрый доступ по ключу | HashMap | ConcurrentHashMap (для многопоточности) |
| Хранение уникальных элементов | HashSet | LinkedHashSet (если важен порядок вставки) |
| Хранение отсортированных элементов | TreeSet / TreeMap | — |
| Обработка в порядке приоритета | PriorityQueue | — |
| Кэширование с учетом порядка доступа | LinkedHashMap (с параметром accessOrder=true) | — |
| Работа со стеком (LIFO) | ArrayDeque | Stack (устаревший) |
| Работа с очередью (FIFO) | ArrayDeque | LinkedList |
Помните, что иногда оптимальное решение может заключаться в комбинировании нескольких collection или даже в создании собственной реализации для специфических требований. Но в большинстве случаев стандартных реализаций из JCF более чем достаточно для решения типичных задач программирования.
Коллекции и производительность
Производительность — та самая тема, которая превращает выбор коллекции из теоретического упражнения в практическое искусство. Разные реализации имеют различные временные характеристики для разных операций, и понимание этих нюансов может серьезно повлиять на эффективность вашего приложения, особенно при работе с большими объемами данных.
Давайте рассмотрим сравнительную производительность основных реализаций collection для типичных операций:
ArrayList vs LinkedList — классическое противостояние в мире списков:
- Доступ по индексу:
ArrayList — O(1), LinkedList — O(n). Здесь ArrayList явный победитель: доступ к элементу по индексу происходит моментально, в то время как LinkedList вынужден последовательно перебирать элементы от начала или конца списка. Это как найти страницу в книге по номеру или перелистывать журнал в поисках нужной статьи.
- Вставка/удаление в начале:
ArrayList — O(n), LinkedList — O(1). Здесь LinkedList берет реванш: добавление или удаление элемента в начале требует лишь изменения нескольких ссылок, в то время как ArrayList вынужден сдвигать все элементы, чтобы освободить или заполнить место.
- Вставка/удаление в конце:
ArrayList — O(1)* (амортизированно, иногда O(n) при расширении), LinkedList — O(1). Для LinkedList это так же просто, как и в начале. Для ArrayList операция обычно быстрая, но иногда может требовать расширения внутреннего массива, что приводит к копированию всех элементов.
- Вставка/удаление в середине:
ArrayList — O(n), LinkedList — O(n). Тут ничья по сложности, но с нюансами: для LinkedList нужно сначала найти позицию (что занимает O(n)), а затем выполнить саму операцию (O(1)). Для ArrayList поиск позиции мгновенный (O(1)), но затем нужно сдвинуть все последующие элементы (O(n)).
HashMap vs TreeMap — баланс между скоростью и порядком:
- Вставка/получение/удаление:
HashMap — O(1) в среднем случае, TreeMap — O(log n). HashMap работает как телепорт — практически мгновенный доступ, независимо от размера. TreeMap гарантирует упорядоченность, но платит за это логарифмическим временем операций.
- Проход по отсортированным ключам:
HashMap — O(n log n) (нужно сначала отсортировать), TreeMap — O(n) (уже отсортированы). Если вам нужны ключи в порядке сортировки, TreeMap сэкономит время на сортировке.
HashSet vs TreeSet — аналогично HashMap и TreeMap, с теми же временными характеристиками, но для работы с уникальными элементами без значений.
Таблица Big-O сложностей для основных операций
| Коллекция | Доступ | Поиск | Вставка | Удаление |
|---|---|---|---|---|
| ArrayList | O(1) | O(n) | O(1)* / O(n)** | O(1)* / O(n)** |
| LinkedList | O(n) | O(n) | O(1)*** | O(1)*** |
| HashMap | O(1) | O(1) | O(1) | O(1) |
| TreeMap | O(log n) | O(log n) | O(log n) | O(log n) |
| HashSet | — | O(1) | O(1) | O(1) |
| TreeSet | — | O(log n) | O(log n) | O(log n) |
| PriorityQueue | O(1)**** | O(n) | O(log n) | O(log n) |
* — в конце списка
** — в начале или середине списка
*** — если позиция известна; если нет, то O(n) для поиска + O(1) для операции
**** — только для доступа к головному элементу
Но не стоит слепо полагаться только на теоретическую сложность. В реальном мире многое зависит от конкретных сценариев использования, размера данных и особенностей JVM:
- Константы имеют значение:
О-нотация скрывает константные множители, которые могут быть значительными для малых размеров данных. Например, для небольших списков разница между ArrayList и LinkedList может быть несущественной или даже противоположной теоретическим ожиданиям из-за лучшей локальности кэша у ArrayList.
- Амортизация:
Некоторые операции, такие как добавление в ArrayList, имеют амортизированную сложность O(1), но отдельные операции могут требовать O(n) времени при расширении внутреннего массива.
- Алгоритмические улучшения:
Начиная с Java 8, HashMap использует древовидную структуру для бакетов с большим количеством коллизий, что улучшает производительность в худшем случае с O(n) до O(log n).
Выбор коллекции с учетом производительности — это баланс между различными операциями, который зависит от конкретного сценария использования. Нет универсально «лучшей» коллекции — есть лишь коллекция, наиболее подходящая для вашей конкретной задачи.
Коллекции на собеседовании
Частые вопросы и темы
Почему рекрутеры так одержимы вопросами о коллекциях? Да потому, что ответы на них мгновенно выдают уровень понимания кандидатом ключевых структур данных, алгоритмической сложности и дизайна Java в целом. Это как лакмусовая бумажка для отделения тех, кто просто запомнил синтаксис, от тех, кто действительно понимает, что происходит «под капотом».
Вот типичные вопросы, которые вы можете услышать на собеседовании:
Базовые вопросы — для начинающих разработчиков:
- «В чём разница между ArrayList и LinkedList?» — классика жанра, если не можете внятно ответить на этот вопрос, дальнейшая беседа может быть весьма короткой.
- «Что произойдёт при итерации по коллекции и одновременном её изменении?» — вопрос-ловушка о ConcurrentModificationException, который часто ставит в тупик новичков.
- «Почему нельзя использовать примитивные типы в коллекциях?» — вопрос на понимание основ обобщённого программирования и автоупаковки/автораспаковки.
Средний уровень — для разработчиков с опытом:
- «Как внутренне устроен HashMap? Что такое collision и как они разрешаются?» — здесь ожидается понимание хеш-таблиц, стратегий разрешения коллизий и изменений в реализации начиная с Java 8.
- «Чем TreeMap отличается от HashMap? Когда бы вы предпочли один другому?» — проверка на понимание компромиссов между производительностью и функциональностью.
- «Какие коллекции потокобезопасны? Какие альтернативы есть в java.util.concurrent?» — вопрос на стыке коллекций и многопоточности.
Продвинутый уровень — для старших разработчиков:
- «Как бы вы реализовали кэш с ограничением размера и политикой вытеснения LRU (Least Recently Used)?» — проверка способности применять знания о коллекциях для решения реальных задач.
- «Какие проблемы производительности могут возникнуть при использовании CopyOnWriteArrayList?» — вопрос на глубокое понимание конкурентных коллекций и их ограничений.
- «Почему ConcurrentHashMap не реализует полную потокобезопасность для составных операций?» — проверка на понимание тонкостей многопоточного программирования.
Интересно, что вопросы часто формулируются по-разному, но имеют одинаковую суть. Например, вместо прямого «В чём разница между ArrayList и LinkedList?», вас могут спросить: «Какую коллекцию вы бы выбрали для хранения миллиона элементов, если нужен быстрый доступ по индексу?» или «Какую структуру данных вы бы использовали для реализации стека?».
Как готовиться
Подготовка к вопросам о коллекциях на собеседовании — это не просто зубрёжка теории, а понимание принципов работы и применения этих структур данных. Вот несколько рекомендаций:
- Повторите теорию — особенно иерархию интерфейсов, основные реализации и их характеристики. Не просто запоминайте факты, а стремитесь понять, почему одна структура эффективнее другой для конкретных операций.
- Изучите исходный код — да, серьёзно. Java — это открытый проект, и вы можете посмотреть, как реализованы основные коллекции. Это не только углубит ваше понимание, но и впечатлит интервьюера, если вы сможете рассказать о некоторых внутренних механизмах.
- Практикуйтесь в коде — напишите простые программы, которые сравнивают производительность разных коллекций для типичных операций. Ничто не заменит практического опыта.
- Изучите частые вопросы и ответы — подготовьте шпаргалки по типичным вопросам и темам, которые часто всплывают на собеседованиях. Но не просто механически запоминайте ответы — важно уметь объяснить, почему ответ именно такой.
- Будьте готовы писать код на доске — иногда вас могут попросить не просто ответить на вопрос, но и написать небольшой пример кода, демонстрирующий использование коллекций для решения конкретной задачи.
И помните — понимание коллекций действительно важно не только для прохождения собеседования, но и для эффективной работы в реальных проектах. Большинство программ так или иначе манипулируют наборами данных, и умение выбрать правильную структуру данных часто определяет производительность и удобство сопровождения вашего кода.
Заключение
Итак, мы с вами совершили увлекательное путешествие по миру Java Collections Framework — от простых списков до сложных карт и очередей с приоритетами. Надеюсь, теперь вы понимаете, что выбор правильной коллекции — это не просто академический вопрос, а реальный фактор, влияющий на производительность, читаемость и поддерживаемость вашего кода.
Но наше путешествие не обязательно заканчивается здесь. Java Collections Framework — это лишь верхушка айсберга, и если вы действительно хотите углубить свои знания, стоит обратить внимание на следующие темы:
- Generics (Обобщения) — механизм, который делает коллекции типобезопасными и более удобными в использовании. Понимание ограничений типов, стирания типов и ковариантности/контравариантности обобщенных типов открывает новые горизонты для работы с коллекциями.
- Concurrent Collections — специализированные реализации коллекций для многопоточных сред из пакета java.util.concurrent, такие как ConcurrentHashMap, BlockingQueue и CopyOnWriteArrayList. Эти структуры данных обеспечивают потокобезопасность с минимальными затратами на синхронизацию.
- Stream API — мощный инструмент для функционального стиля обработки коллекций, который появился в Java 8. С помощью стримов можно элегантно выполнять операции фильтрации, отображения, сортировки и агрегации над элементами коллекций.
Коллекции в Java — это не просто набор классов и интерфейсов, а целая философия работы с данными. Овладев этой философией, вы не только сможете уверенно проходить собеседования, но и писать более эффективный, элегантный и поддерживаемый код.
Так что экспериментируйте, практикуйтесь и не бойтесь копаться в исходниках. Именно так и рождается настоящее понимание.
Рекомендуем посмотреть курсы по Java
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Java-разработчик
|
Eduson Academy
100 отзывов
|
Цена
Ещё -5% по промокоду
115 000 ₽
|
От
9 583 ₽/мес
0% на 24 месяца
15 476 ₽/мес
|
Длительность
8 месяцев
|
Старт
скоро
Пн,Ср, 19:00-22:00
|
Подробнее |
|
Профессия Java-разработчик
|
Skillbox
217 отзывов
|
Цена
Ещё -20% по промокоду
190 971 ₽
381 943 ₽
|
От
5 617 ₽/мес
Это минимальный ежемесячный платеж. От Skillbox без %.
8 692 ₽/мес
|
Длительность
9 месяцев
Эта длительность обучения очень примерная, т.к. все занятия в записи (но преподаватели ежедневно проверяют ДЗ). Так что можно заниматься более интенсивно и быстрее пройти курс или наоборот.
|
Старт
26 января
|
Подробнее |
|
Java-разработчик с нуля
|
Нетология
46 отзывов
|
Цена
с промокодом kursy-online
143 700 ₽
266 020 ₽
|
От
4 433 ₽/мес
Без переплат на 2 года.
|
Длительность
14 месяцев
|
Старт
2 февраля
|
Подробнее |
|
Java-разработчик
|
Академия Синергия
35 отзывов
|
Цена
с промокодом KURSHUB
103 236 ₽
258 090 ₽
|
От
3 585 ₽/мес
10 240 ₽/мес
|
Длительность
6 месяцев
|
Старт
3 февраля
|
Подробнее |
|
Java-разработка
|
Moscow Digital Academy
66 отзывов
|
Цена
132 720 ₽
165 792 ₽
|
От
5 530 ₽/мес
на 12 месяца.
6 908 ₽/мес
|
Длительность
12 месяцев
|
Старт
в любое время
|
Подробнее |

Почему тестировщики ошибаются: анализ причин и решений
Ошибки в тестировании — это нормально, но их можно минимизировать. В статье разберем основные причины, примеры и практические советы, которые помогут сделать процесс тестирования эффективнее.

Продажи на Ozon: как начать и не упустить шанс на успех
Не знаете, с чего начать на Ozon? Эта статья – ваш гид в мир e-commerce. Пошаговые советы, примеры и лайфхаки для быстрого старта.

Что такое уникальность текста и почему она влияет на выдачу в поиске
Уникальность текста — это давно не только антиплагиат и цифры. Хотите понять, какие тексты ранжируются выше и почему? Эта статья даст вам реальные ответы и примеры.