Лучшие библиотеки Python для работы с Excel: полный обзор, сравнение и примеры кода
Excel остаётся одним из самых распространённых инструментов для работы с данными в корпоративной среде. Миллионы специалистов ежедневно используют электронные таблицы для учёта, анализа показателей, построения отчётов и визуализации информации. Однако по мере роста объёмов и усложнения бизнес-процессов становятся очевидными ограничения этого инструмента: ручная обработка занимает слишком много времени, VBA-макросы работают медленно и требуют специфических знаний, а масштабирование решений на основе Эксель превращается в настоящую проблему.

Python предлагает элегантное решение этих задач. В отличие от Excel, где автоматизация ограничена возможностями встроенных макросов, Python открывает доступ к мощной экосистеме библиотек, которые позволяют не просто читать и записывать данные, но и интегрировать их с внешними API, БД, системами машинного обучения.
Преимущества Python для задач:
- Автоматизация рутинных операций — от массового обновления отчётов до консолидации информации из десятков файлов одной командой.
- Обработка больших объёмов данных — Python справляется с миллионами строк там, где Эксель начинает «тормозить».
- Интеграция с внешними системами — возможность подключения к API, базам данных, облачным хранилищам и ETL-процессам.
- Расширенная аналитика — использование библиотек для статистического анализа, машинного обучения и визуализации.
- Воспроизводимость результатов — код можно версионировать, тестировать и повторно использовать, в отличие от ручных операций в Excel.
- Кросс-платформенность — решения на Python работают на любой операционной системе без привязки к Microsoft Office.
В этой статье мы подробно рассмотрим библиотеки Python, которые превращают работу с Эксель из рутинной обязанности в автоматизированный и масштабируемый процесс.
- Как выбрать библиотеку Python для работы с Excel
- Обзор библиотек Python для Excel (полный список)
- Сравнительная таблица
- Краткие рекомендации по выбору
- Примеры кода (конкуренты дают мало — можно сделать лучше)
- Когда Excel-библиотек недостаточно и что использовать вместо них
- Заключение
- Рекомендуем посмотреть курсы по обучению Excel
Как выбрать библиотеку Python для работы с Excel
Выбор подходящей библиотеки для работы с Excel — это не вопрос личных предпочтений, а скорее инженерная задача, нуждающаяся в анализе конкретных требований проекта. На практике правильный выбор инструмента может сократить время разработки в несколько раз и избавить от необходимости переписывать код в будущем.
Основные критерии выбора:
- Формат файлов — необходимо определить, с какими типами придётся работать. Современные проекты чаще используют .xlsx и .xlsm, однако в корпоративной среде до сих пор встречаются устаревшие .xls файлы, требующие специализированных библиотек.
- Режим работы с данными — одни специализируются на чтении существующих файлов, другие — на создании новых, третьи умеют и то, и другое. Если задача заключается только в извлечении информации для анализа, нет смысла использовать тяжеловесные решения с поддержкой форматирования.
- Объём обрабатываемых данных — для небольших отчётов подойдут универсальные библиотеки, но когда речь идёт о сотнях тысяч строк, критичной становится производительность. Некоторые оптимизированы специально для работы с большими массивами.
- Требования к форматированию — если нужен простой экспорт информации в таблицу, достаточно минималистичных решений. Но для создания презентабельных отчётов с условным форматированием, объединёнными ячейками и диаграммами потребуются библиотеки с расширенными возможностями стилизации.
- Работа с формулами — некоторые задачи требуют не только записи формул в ячейки, но и их интерпретации на стороне Python. Это особенно актуально для серверных приложений, где нет доступа к установленному Эксель.
- Производительность — скорость работы становится критичной при автоматизации процессов, которые должны выполняться регулярно или обрабатывать большие объёмы файлов.
Общие рекомендации по типам задач:
- Для анализа данных → Pandas — де-факто стандарт для работы с табличными данными, мощные возможности трансформации и агрегации.
- Для создания форматированных отчётов → OpenPyXL или XlsxWriter — полный контроль над стилями, шрифтами, диаграммами.
- Для работы со старыми файлами → xlrd/xlwt — поддержка формата .xls, актуально для легаси-систем.
- Для унификации работы с разными форматами → pyexcel — единый API для CSV, XLS, XLSX и других форматов.
- Для автоматизации Excel как замена VBA → xlwings, PyXLL или IronXL — интерактивная работа с запущенным Эксель, вызов Python-функций из ячеек.
Возникает вопрос: существует ли универсальное решение, которое закроет все потребности? На практике такого инструмента нет — каждая библиотека оптимизирована под определённый класс задач. Более того, в сложных проектах часто приходится комбинировать несколько: например, использовать Pandas для обработки данных и OpenPyXL для создания финального отчёта с нужным форматированием. Понимание сильных и слабых сторон каждого инструмента позволяет построить эффективный и поддерживаемый код.
Обзор библиотек Python для Excel (полный список)
Рассмотрим подробно каждую, её возможности и оптимальные сценарии использования. Этот расширенный обзор объединяет весь спектр инструментов — от популярных решений для анализа данных до специализированных инструментов для enterprise-интеграций.

Эта иллюстрация показывает взаимодействие людей вокруг Excel и Python, подчёркивая, что инструменты дополняют друг друга. Визуальный образ помогает проще воспринимать идею о совместном использовании технологий для повышения эффективности работы с данными.
Pandas
Pandas — это основа современного анализа информации в Python, и работа с Excel-файлами составляет лишь небольшую часть её возможностей. Библиотека предоставляет мощный инструментарий для чтения, трансформации и записи табличных данных в различных форматах, включая CSV, XLS и XLSX.
Ключевые функции для работы с Эксель — read_excel() и to_excel() — позволяют быстро загружать информацию в DataFrame (основную структуру Pandas) и экспортировать результаты обработки обратно. Отлично справляется с задачами фильтрации, группировки, агрегации, объединения таблиц и временных рядов. Именно поэтому Pandas остаётся незаменимым инструментом для специалистов по данным и аналитиков.
Однако есть существенное ограничение: Pandas не предназначен для создания визуально сложных отчётов. Библиотека может записать информацию в Excel, но контроль над форматированием минимален. Если задача требует презентабельного оформления — придётся комбинировать Pandas с OpenPyXL или XlsxWriter. Тем не менее, для ETL-процессов, предварительной обработки информации и аналитики Pandas остаётся оптимальным выбором за счёт производительности и удобства работы с большими наборами данных.
Оптимальные сценарии: анализ, консолидация множества Excel-файлов, подготовка данных для дальнейшей визуализации, работа с временными рядами.
OpenPyXL
OpenPyXL — это библиотека, которая предоставляет полный контроль над современными Эксель-файлами формата .xlsx и .xlsm (Excel 2010 и новее). В отличие от Pandas, где акцент сделан на обработке информации, OpenPyXL позволяет создавать профессионально оформленные отчёты с любой степенью визуальной сложности.
Пример работы с Эксель с помощью OpenPyXL. Источник: Rutube, Клондайк Аналитика.
Поддерживает чтение и запись файлов, работу с несколькими листами, управление метаданными книги. Но её главное преимущество — это возможности форматирования: вы можете настраивать шрифты, цвета заливки, границы ячеек, выравнивание, условное форматирование, объединение. OpenPyXL умеет работать с формулами (записывать их в ячейки, хотя не вычисляет на стороне Python), создавать и настраивать диаграммы различных типов, добавлять изображения в документы.
Стоит отметить, что за гибкость приходится платить более сложным кодом по сравнению с Pandas. Работа с OpenPyXL требует явного указания стилей, форматов ячеек и их координат. Однако для задач, где визуальное представление критично — например, при автоматизации создания регулярных отчётов для менеджмента — эта библиотека незаменима.
Оптимальные сценарии: создание кастомных отчётов с форматированием, автоматизация формирования презентабельных документов, работа с шаблонами Excel, добавление диаграмм и визуализаций.
XlsxWriter
XlsxWriter — это библиотека, специализирующаяся исключительно на создании Эксель-файлов формата .xlsx с нуля. В отличие от OpenPyXL, которая умеет и читать, и записывать файлы, XlsxWriter сфокусирована только на генерации новых документов, и именно эта специализация делает её особенно мощной в своей нише.

Пример работы в эксель через XlsxWriter. Источник: Rutube, Питоновое Воображение
Она предоставляет впечатляющий набор возможностей для форматирования: поддержка всех типов диаграмм Excel (от простых линейных до сложных комбинированных), условное форматирование, защита листов и ячеек, создание выпадающих списков, настройка параметров печати, добавление изображений и фигур. XlsxWriter отличается высокой производительностью при работе с большими файлами и генерирует оптимизированные по размеру документы.
Особенность — богатый API для работы с диаграммами. Если задача требует создания сложных визуализаций информации непосредственно в Эксель (а не экспорта готовых изображений), XlsxWriter предоставляет детальный контроль над всеми параметрами графиков: осями, легендами, подписями данных, цветовыми схемами. Это делает библиотеку идеальной для автоматизации создания аналитических дашбордов.
Главное ограничение очевидно из названия — не умеет читать существующие файлы. Это означает, что XlsxWriter не подходит для задач, где нужно модифицировать уже созданные документы или извлекать из них информацию. Однако для сценариев, где требуется регулярно генерировать отчёты с нуля по заданному шаблону, XlsxWriter часто оказывается более удобным и быстрым решением, чем OpenPyXL.
Оптимальные сценарии: генерация отчётов с нуля, создание файлов с большим количеством диаграмм, автоматизация создания аналитических дашбордов, экспорт данных с богатым форматированием.
Pyexcel
Pyexcel предлагает принципиально иной подход к работе с табличными данными — вместо специализации на конкретном формате библиотека предоставляет унифицированный API для работы с CSV, ODS, XLS, XLSX и множеством других форматов. Это решение особенно ценно в проектах, где приходится обрабатывать данные из разнородных источников.
Архитектура построена на системе плагинов: базовая функциональность дополняется модулями для поддержки конкретных форматов. Это позволяет устанавливать только необходимые зависимости, сохраняя проект лёгким. Pyexcel упрощает типичные операции: импорт из файлов в массивы Python или словари, трансформацию структуры информации в памяти, экспорт результатов обратно в нужный формат.
Библиотека демонстрирует свою силу в задачах конвертации информации между форматами. Например, массовое преобразование CSV-файлов в XLSX или миграция данных из устаревших XLS в современные форматы выполняется буквально несколькими строками кода. Pyexcel также предоставляет удобные абстракции для работы с книгами, содержащими несколько листов, позволяя обращаться к данным через интуитивно понятный интерфейс.
Однако универсальность имеет свою цену: Pyexcel не предлагает расширенных возможностей форматирования или работы с формулами. Библиотека фокусируется на данных, а не на их визуальном представлении. Для проектов, где критична скорость обработки больших объёмов или требуется сложное форматирование, стоит рассмотреть специализированные решения. Но для задач ETL, миграции информации и унификации работы с различными источниками Pyexcel остаётся элегантным выбором.
Оптимальные сценарии: конвертация информации между форматами, унификация работы с разнородными источниками, простая обработка табличных данных, быстрое прототипирование.
xlrd / xlwt
Библиотеки xlrd и xlwt представляют собой связку инструментов для работы со старым форматом Эксель — .xls, который использовался до появления Office 2007. Несмотря на то, что этот формат можно считать устаревшим, он до сих пор активно встречается в корпоративных средах, особенно в организациях с легаси-системами или строгими требованиями к обратной совместимости.
xlrd специализируется на чтении .xls файлов: извлечение информации из ячеек, получение ее о форматировании, работа с несколькими листами книги. xlwt, соответственно, отвечает за создание новых файлов в этом формате. Важно отметить, что начиная с версии 2.0, xlrd прекратила поддержку .xlsx файлов — разработчики сознательно ограничили область применения библиотеки только форматом .xls, рекомендуя для современных файлов использовать другие решения.
Возможности довольно ограничены по сравнению с современными инструментами. Базовое форматирование поддерживается, но о сложных диаграммах, условном форматировании или продвинутых стилях речи не идёт. Тем не менее, в определённых контекстах xlrd/xlwt остаются незаменимыми: когда нужно интегрироваться с устаревшими системами учёта, обрабатывать архивные данные или поддерживать совместимость с программным обеспечением, которое генерирует только .xls файлы.
На практике использование их сегодня — это скорее вынужденная необходимость, чем осознанный выбор. Если у вас есть возможность работать с современными форматами, стоит отдать предпочтение более функциональным решениям. Однако знание xlrd/xlwt может оказаться критичным при миграции информации из старых систем или поддержке существующих интеграций.
Оптимальные сценарии: работа с легаси-системами, обработка архивных данных в формате .xls, интеграция с устаревшим ПО, миграция информации из старых форматов.
PyExcelerate
PyExcelerate — это узкоспециализированная библиотека, созданная с одной чёткой целью: максимально быстрая запись больших объёмов данных в формат .xlsx. Если перед вами стоит задача сгенерировать файл с сотнями тысяч или миллионами строк, PyExcelerate демонстрирует впечатляющую производительность, значительно опережая универсальные решения.
Оптимизация достигнута за счёт минималистичного подхода: библиотека поддерживает только создание новых файлов (не чтение), фокусируется на эффективной записи информации и предоставляет базовые возможности стилизации — установку шрифтов, цветов, границ ячеек. Это осознанный компромисс: отказ от сложной функциональности в пользу скорости выполнения.
Интересная особенность PyExcelerate — поддержка добавления стилей, что выгодно отличает её от многих других «скоростных» библиотек. Вы можете не только быстро записать данные, но и применить к ним форматирование, что делает итоговый файл более презентабельным. Однако не стоит ожидать возможностей уровня OpenPyXL — речь идёт именно о базовой стилизации.
На практике PyExcelerate находит применение в системах отчётности, где регулярно генерируются большие выгрузки информации: экспорт транзакций из баз, формирование детализированных логов, создание массивных справочников. В таких сценариях разница в производительности становится критичной — задача, которая занимает минуты с другими библиотеками, может выполниться за секунды с PyExcelerate.
Ограничение очевидно: если вам нужна богатая функциональность (диаграммы, формулы, сложное форматирование) или необходимо читать существующие файлы, придётся выбрать другой инструмент. Но для своей узкой ниши PyExcelerate остаётся непревзойдённым решением.
Оптимальные сценарии: массовый экспорт данных из баз, генерация больших отчётов, создание файлов с миллионами строк, задачи, где критична скорость записи.
xlwings
xlwings занимает особую нишу среди библиотек для работы — это решение для автоматизации самого приложения Microsoft Excel или Google Sheets, а не просто для манипуляций с файлами. По сути, xlwings позволяет управлять Эксель так же, как это делают VBA-макросы, но с использованием всей мощи экосистемы Python.
Пример работы в Эксель с xlwings. Источник: Rutube, Учитель Python
Работает по принципу взаимодействия с запущенным экземпляром Excel: вы можете открывать книги, изменять информацию в реальном времени, запускать макросы, обновлять диаграммы — и всё это видно непосредственно в интерфейсе программы. Это делает xlwings незаменимым инструментом для сценариев, где требуется интерактивная работа с таблицами или интеграция Python-кода в существующие бизнес-процессы, построенные вокруг Excel.
Ключевое преимущество xlwings перед чтением/записью файлов через OpenPyXL или Pandas — способность использовать вычислительные возможности самого Excel. Вы можете вызывать встроенные функции, работать с формулами, которые Эксель пересчитывает автоматически, использовать сводные таблицы.
Типичный сценарий: специалист по данным обрабатывает информацию в Python (используя pandas, numpy, scikit-learn), а затем через xlwings передаёт результаты в Excel-шаблон, который используют бизнес-пользователи. Это позволяет автоматизировать аналитические процессы, сохраняя привычный интерфейс для конечных пользователей.
Оптимальные сценарии: автоматизация офисных процессов, замена VBA-макросов, интеграция Python-аналитики с Excel-отчётами, работа с существующими сложными книгами, интерактивная обработка информации.
PyXLL
PyXLL представляет собой коммерческое решение, которое превращает Python в полноценный язык для написания пользовательских функций (UDF — User Defined Functions). Если xlwings позволяет управлять Эксель извне, то PyXLL интегрирует Python непосредственно внутрь, делая Python-код доступным прямо из ячеек электронных таблиц.
Основная идея PyXLL — вы пишете функции на Python, помечаете их специальными декораторами, и они становятся доступны в Эксель точно так же, как встроенные функции типа SUM или VLOOKUP. Пользователь может вызвать вашу Python-функцию прямо из формулы в ячейке, передать ей параметры и получить результат. Это открывает возможность использовать всю мощь Python — от научных вычислений до машинного обучения — непосредственно в привычной среде Excel.
PyXLL поддерживает не только простые функции, но и более сложные сценарии: создание пользовательских элементов меню, настраиваемые панели инструментов, интеграцию с внешними API и базами данных. Библиотека позволяет использовать любые Python-пакеты — pandas, numpy, scikit-learn, requests.
Коммерческая модель PyXLL означает, что библиотека платная, но это также гарантирует профессиональную поддержку и регулярные обновления. Для enterprise-среды, где критична стабильность и возможность получить техническую помощь, это может быть решающим фактором.
Оптимальные сценарии: создание пользовательских функций Excel на Python, интеграция аналитических моделей в Эксель-интерфейс, enterprise-решения, финансовое моделирование, предоставление Python-функциональности бизнес-пользователям.
IronXL for Python
IronXL — это Python-обёртка над .NET-библиотекой IronXL, которая изначально разрабатывалась для платформы .NET и C#. Это решение нацелено на enterprise-сегмент и предоставляет коммерческий инструментарий для работы с Excel-файлами в корпоративных приложениях.
Библиотека поддерживает широкий спектр операций: чтение и запись файлов форматов XLS, XLSX и CSV, создание диаграмм различных типов, применение стилей и форматирования, работу с формулами Эксель. IronXL также предоставляет возможности конвертации между форматами — например, преобразование CSV в XLSX или экспорт информации в JSON. Особенность библиотеки — кросс-платформенная поддержка: код работает на Windows, Linux и macOS.
За счёт .NET-основы IronXL демонстрирует высокую производительность при работе с большими файлами и обеспечивает точную совместимость с форматами Microsoft Excel. Библиотека также предлагает дополнительные возможности, редкие среди Python-решений: работу с защищёнными паролем файлами, детальную настройку параметров печати, управление комментариями и проверкой данных.
На практике IronXL находит применение в бизнес-приложениях, где Python используется как часть более широкой технологической экосистемы, включающей .NET-компоненты. Библиотека также подходит для проектов, где критична совместимость с корпоративными стандартами Microsoft и требуется коммерческая поддержка.
Оптимальные сценарии: enterprise-приложения, интеграция Python с .NET-системами, проекты, требующие коммерческой поддержки, обработка защищённых файлов, кросс-платформенные корпоративные решения.
Pycel
Pycel предлагает нестандартный подход к работе с Эксель — вместо простого чтения или записи информации библиотека компилирует книги в вычислительные графы Python. Это означает, что Pycel анализирует структуру электронной таблицы, выявляет зависимости между ячейками и формулами, а затем создаёт граф, который можно выполнять независимо от самого Excel.
Получившийся граф содержит узлы для каждой ячейки книги и описывает их взаимосвязи. Когда изменяется значение одной ячейки, Pycel использует эти зависимости для динамического пересчёта всех затронутых ячеек — точно так же, как это делает сам Эксель, но скачивать его не нужно.
Эта функциональность открывает интересные возможности для серверных приложений. Представьте ситуацию: у вас есть сложная финансовая модель в Excel с множеством взаимосвязанных расчётов. Вместо того чтобы переписывать всю логику на Python (что чревато ошибками и требует времени), вы можете использовать Pycel для выполнения этих вычислений на сервере Linux, где Эксель физически недоступен.
Pycel особенно полезен в сценариях, где бизнес-логика заключена в Excel-файлах, созданных аналитиками, и эту логику нужно масштабировать или автоматизировать. Например, модель ценообразования, которую финансовый аналитик поддерживает в Excel, может быть развернута через Pycel как веб-сервис, отвечающий на запросы в реальном времени.
Оптимальные сценарии: серверное выполнение вычислений, миграция бизнес-логики из Эксель в Python, автоматизация сложных расчётов без переписывания формул, создание API на основе Excel-моделей.
formulas
formulas — это ещё один интерпретатор формул для Python, но с несколько иным фокусом по сравнению с Pycel. Это пакет с открытым исходным кодом, который позволяет читать книги Эксель, анализировать содержащиеся в них формулы и компилировать их в Python-код для последующего выполнения.
Библиотека решает конкретную проблему: как выполнять вычисления без самого приложения Excel? В корпоративной среде часто возникают ситуации, когда бизнес-логика закодирована в формулах, но эти вычисления нужно производить на серверах, где установка Microsoft Office невозможна или нецелесообразна. formulas позволяет извлечь эту логику и выполнить её в чистом Python-окружении.
После компиляции формул библиотека может выполнять их значительно быстрее, чем сам Эксель, особенно при массовой обработке информации. Это связано с тем, что компилированный Python-код оптимизирован и не требует накладных расходов на поддержку графического интерфейса и других функций Excel. Кроме того, такой подход делает вычисления платформонезависимыми — код одинаково работает на Windows, Linux и macOS.
Возникает вопрос: в чём разница между formulas и Pycel? Обе библиотеки решают схожие задачи, но formulas делает акцент на точности интерпретации формул и производительности вычислений, тогда как Pycel больше фокусируется на представлении книги как вычислительного графа. Выбор между ними зависит от конкретных требований проекта и личных предпочтений разработчика.
Оптимальные сценарии: интерпретация формул в Python, серверные вычисления без Excel, оптимизация производительности расчётов, миграция бизнес-логики из электронных таблиц.
Сравнительная таблица
Чтобы облегчить выбор, мы подготовили сравнительную таблицу, которая объединяет ключевые характеристики всех рассмотренных инструментов. Эта таблица позволяет быстро оценить возможности каждого решения и сопоставить их с требованиями конкретного проекта.
| Библиотека | Форматы | Чтение | Запись | Формулы | Форматирование | Скорость | Лучшие сценарии |
|---|---|---|---|---|---|---|---|
| Pandas | CSV, XLS, XLSX | ✓ | ✓ | Нет | Минимальное | Высокая | Анализ данных, ETL, консолидация файлов |
| OpenPyXL | XLSX, XLSM | ✓ | ✓ | Запись | Полное | Средняя | Кастомные отчёты, работа с шаблонами |
| XlsxWriter | XLSX | – | ✓ | Запись | Полное | Высокая | Генерация отчётов, диаграммы, дашборды |
| Pyexcel | CSV, XLS, XLSX, ODS | ✓ | ✓ | Нет | Минимальное | Средняя | Конвертация форматов, унификация |
| xlrd/xlwt | XLS | ✓/– | –/✓ | Нет | Базовое | Средняя | Легаси-системы, старые файлы |
| PyExcelerate | XLSX | – | ✓ | Нет | Базовое | Очень высокая | Массовый экспорт больших данных |
| xlwings | XLS, XLSX | ✓ | ✓ | Интерпретация | Через Excel | Средняя | Автоматизация Excel, замена VBA |
| PyXLL | XLS, XLSX | ✓ | ✓ | Интерпретация | Через Excel | Средняя | UDF на Python, интеграция в Excel |
| IronXL | XLS, XLSX, CSV | ✓ | ✓ | Запись | Полное | Высокая | Enterprise-решения, .NET-интеграция |
| Pycel | XLSX | ✓ | – | Интерпретация | Нет | Высокая | Серверное выполнение формул |
| formulas | XLSX | ✓ | – | Интерпретация | Нет | Высокая | Компиляция формул в Python |
Ключевые различия и преимущества:
- Pandas доминирует в аналитике данных благодаря мощному API для трансформаций, но практически бесполезна для создания визуально сложных отчётов. Её главное преимущество — скорость обработки больших наборов информации и интеграция с научной экосистемой Python (NumPy, SciPy, Matplotlib).
- OpenPyXL и XlsxWriter конкурируют в нише создания форматированных отчётов. Первая предлагает универсальность (чтение + запись), вторая — специализацию на создании файлов с акцентом на производительность и диаграммы. На практике OpenPyXL чаще выбирают для модификации существующих файлов, XlsxWriter — для генерации отчётов с нуля.
- xlwings и PyXLL работают с живым Эксель, но по-разному: xlwings управляет приложением извне (автоматизация процессов), PyXLL интегрирует Python внутрь программы (пользовательские функции). Выбор зависит от того, кто будет конечным пользователем — Python-разработчик или специалист, работающий в Эксель.
- Pycel и formulas решают задачу интерпретации формул, но с разными акцентами: Pycel строит граф зависимостей для динамических вычислений, formulas компилирует формулы для максимальной производительности. Обе библиотеки критичны для миграции Excel-логики на серверы.
- PyExcelerate не имеет конкурентов по скорости записи больших объёмов данных, но платит за это ограниченной функциональностью. IronXL предлагает коммерческое решение с гарантиями поддержки для enterprise. Pyexcel выигрывает в универсальности работы с форматами.
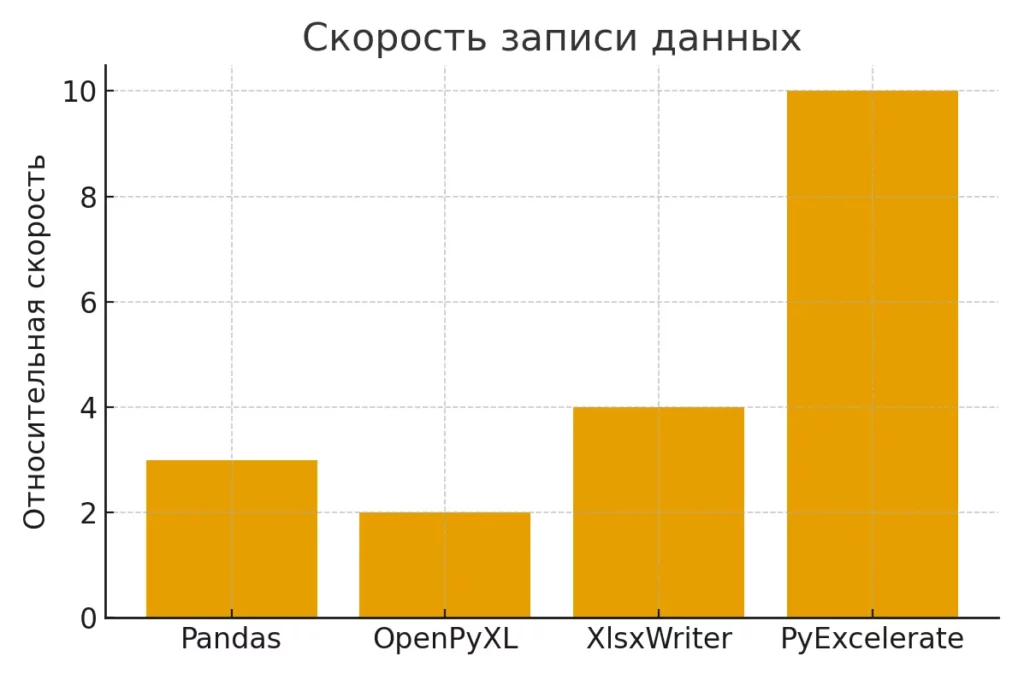
Диаграмма сравнивает относительную скорость записи Excel-файлов разными Python-библиотеками. Хорошо показывает, почему PyExcelerate выбирают для больших выгрузок.
Важно понимать, что «лучшей» библиотеки в абсолютном смысле не существует — каждая оптимизирована под определённые сценарии. Более того, в реальных проектах часто используется комбинация библиотек: Pandas для обработки информации + OpenPyXL для финального отчёта, или xlwings для автоматизации + formulas для вычислений на сервере.
Краткие рекомендации по выбору
После детального обзора всех библиотек давайте сформулируем практические рекомендации, которые помогут быстро определиться с выбором инструмента в зависимости от конкретной задачи.
- Для анализа и ETL-процессов → Pandas. Если ваша основная цель — обработка, трансформация и анализ табличных данных, Pandas остаётся безальтернативным выбором. Библиотека идеально подходит для консолидации множества файлов, фильтрации информации, группировки, агрегации и подготовки для дальнейшей визуализации или машинного обучения.
- Для создания форматированных отчётов → XlsxWriter / OpenPyXL Когда требуется сгенерировать презентабельный отчёт с диаграммами, условным форматированием и профессиональным оформлением, выбирайте XlsxWriter для создания файлов с нуля или OpenPyXL, если нужно модифицировать существующие шаблоны. OpenPyXL также предпочтительнее, когда требуется читать данные из файлов перед их обработкой.
- Для автоматизации работы с Excel → xlwings, PyXLL, IronXL Если задача — автоматизировать действия в самом приложении Эксель (открытие файлов, обновление информации, запуск макросов), используйте xlwings. Для создания пользовательских функций, доступных прямо из ячеек Excel, выбирайте PyXLL. IronXL подойдёт для enterprise-проектов, где критична коммерческая поддержка и интеграция с .NET-экосистемой.
- Для работы со старыми файлами → xlrd/xlwt. В случаях, когда необходимо обрабатывать устаревшие файлы формата .xls из легаси-систем, xlrd и xlwt остаются единственным надёжным выбором. Для современных форматов эти библиотеки использовать не рекомендуется.
- Для обработки больших объёмов → PyExcelerate. Когда на первый план выходит скорость записи миллионов строк в Эксель-файл, PyExcelerate демонстрирует непревзойдённую производительность. Библиотека оптимальна для массовых экспортов информации из баз или генерации объёмных выгрузок.
- Для универсальности и конвертации форматов → pyexcel. Если проект требует работы с разнородными форматами (CSV, XLS, XLSX, ODS) через единый API, или необходимо конвертировать данные между форматами, Pyexcel предоставляет элегантное решение с минимальным количеством кода.
- Для серверного выполнения Excel-логики → Pycel, formulas. В ситуациях, когда бизнес-логика заключена в формулах, но вычисления должны выполняться на сервере без установленной программы, используйте Pycel или formulas для интерпретации и выполнения формул в Python-окружении.
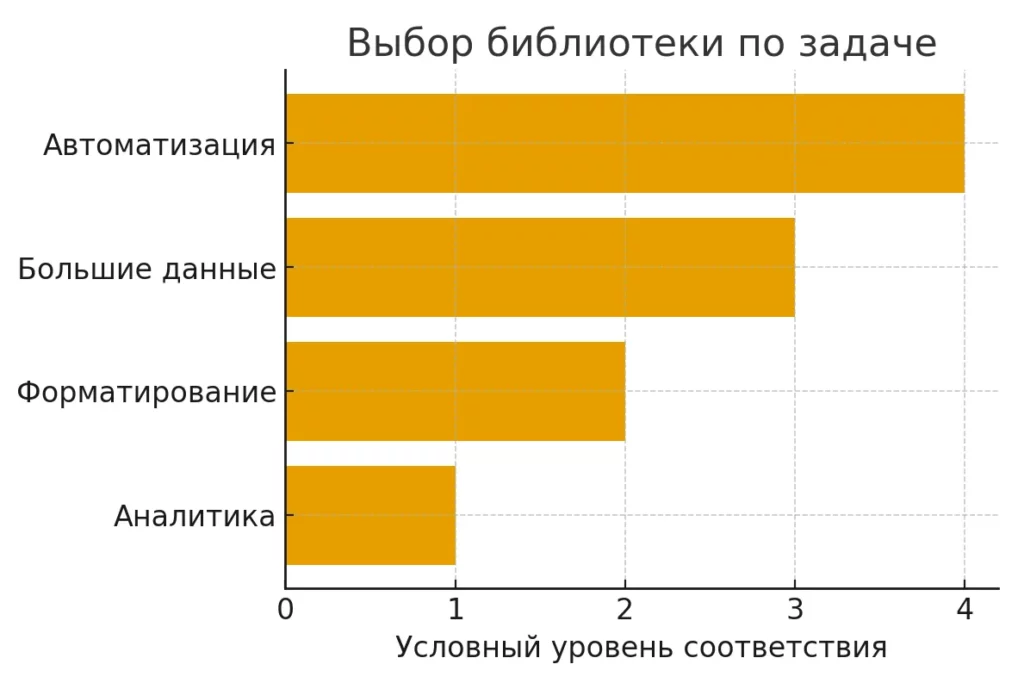
Горизонтальная диаграмма помогает быстро определить оптимальный инструмент в зависимости от задачи: от аналитики до автоматизации.
Примеры кода (конкуренты дают мало — можно сделать лучше)
Теория без практики остаётся абстракцией. Давайте рассмотрим конкретные примеры кода, которые демонстрируют типичные сценарии работы с Эксель через Python. Эти примеры можно использовать как отправную точку для ваших собственных проектов.
Пример чтения Excel (Pandas)
Pandas предоставляет наиболее простой способ загрузить данные из Excel для последующего анализа. Вот базовый пример чтения файла и выполнения типичных операций:
import pandas as pd
# Чтение Excel-файла
df = pd.read_excel('sales_data.xlsx', sheet_name='Q1_2024')
# Просмотр первых строк
print(df.head())
# Фильтрация данных
high_sales = df[df['revenue'] > 100000]
# Группировка и агрегация
regional_summary = df.groupby('region').agg({
'revenue': 'sum',
'orders': 'count',
'customer_id': 'nunique'
})
# Запись результата в новый файл
regional_summary.to_excel('regional_report.xlsx', sheet_name='Summary')
Этот пример демонстрирует типичный workflow аналитика: загрузка информации, фильтрация, агрегация и экспорт результатов. Pandas автоматически определяет типы данных и предоставляет мощный API для их обработки.
Пример записи Excel (OpenPyXL)
OpenPyXL позволяет создавать файлы с полным контролем над форматированием. Рассмотрим создание отчёта с заголовками, информацией стилизацией:
from openpyxl import Workbook
from openpyxl.styles import Font, PatternFill, Alignment, Border, Side
# Создание новой книги
wb = Workbook()
ws = wb.active
ws.title = "Monthly Report"
# Заголовок отчёта
ws['A1'] = 'Отчёт о продажах за октябрь 2024'
ws['A1'].font = Font(size=14, bold=True)
ws['A1'].alignment = Alignment(horizontal='center')
ws.merge_cells('A1:D1')
# Заголовки колонок
headers = ['Продукт', 'Количество', 'Цена', 'Сумма']
ws.append(headers)
# Стилизация заголовков
header_fill = PatternFill(start_color='366092', end_color='366092', fill_type='solid')
header_font = Font(color='FFFFFF', bold=True)
for cell in ws[2]:
cell.fill = header_fill
cell.font = header_font
cell.alignment = Alignment(horizontal='center')
# Добавление данных
data = [
['Ноутбук', 45, 75000, '=B3*C3'],
['Монитор', 120, 15000, '=B4*C4'],
['Клавиатура', 200, 3500, '=B5*C5']
]
for row in data:
ws.append(row)
# Форматирование границ
thin_border = Border(
left=Side(style='thin'),
right=Side(style='thin'),
top=Side(style='thin'),
bottom=Side(style='thin')
)
for row in ws['A2':f'D{ws.max_row}']:
for cell in row:
cell.border = thin_border
# Автоширина колонок
for column in ws.columns:
max_length = max(len(str(cell.value)) for cell in column)
ws.column_dimensions[column[0].column_letter].width = max_length + 2
wb.save('formatted_report.xlsx')
Этот пример показывает возможности OpenPyXL по созданию профессионально оформленных отчётов: объединение ячеек, цветовая заливка, работа с формулами и границами.
Пример создания отчёта с форматированием (XlsxWriter)
XlsxWriter особенно силён в создании отчётов с диаграммами. Вот пример генерации файла с данными и графиком:
import xlsxwriter
# Создание книги и листа
workbook = xlsxwriter.Workbook('sales_chart.xlsx')
worksheet = workbook.add_worksheet('Sales Data')
# Форматы
header_format = workbook.add_format({
'bold': True,
'bg_color': '#4472C4',
'font_color': 'white',
'align': 'center',
'border': 1
})
currency_format = workbook.add_format({'num_format': '#,##0.00₽'})
# Заголовки
headers = ['Месяц', 'Продажи', 'Расходы', 'Прибыль']
worksheet.write_row('A1', headers, header_format)
# Данные
data = [
['Январь', 125000, 45000, 80000],
['Февраль', 142000, 48000, 94000],
['Март', 138000, 52000, 86000],
['Апрель', 165000, 55000, 110000],
['Май', 178000, 58000, 120000],
['Июнь', 195000, 62000, 133000]
]
row = 1
for month, sales, expenses, profit in data:
worksheet.write(row, 0, month)
worksheet.write(row, 1, sales, currency_format)
worksheet.write(row, 2, expenses, currency_format)
worksheet.write(row, 3, profit, currency_format)
row += 1
# Создание графика
chart = workbook.add_chart({'type': 'column'})
chart.add_series({
'name': '=Sales Data!$B$1',
'categories': '=Sales Data!$A$2:$A$7',
'values': '=Sales Data!$B$2:$B$7',
'fill': {'color': '#4472C4'}
})
chart.add_series({
'name': '=Sales Data!$C$1',
'categories': '=Sales Data!$A$2:$A$7',
'values': '=Sales Data!$C$2:$C$7',
'fill': {'color': '#ED7D31'}
})
chart.set_title({'name': 'Динамика продаж и расходов'})
chart.set_x_axis({'name': 'Месяц'})
chart.set_y_axis({'name': 'Сумма, ₽'})
chart.set_style(11)
worksheet.insert_chart('F2', chart, {'x_scale': 1.5, 'y_scale': 1.5})
# Автоподбор ширины колонок
worksheet.set_column('A:A', 12)
worksheet.set_column('B:D', 15)
workbook.close()
XlsxWriter демонстрирует удобный API для создания диаграмм с полным контролем над их внешним видом. Обратите внимание на использование форматов для валют и стилизацию графика.
Пример автоматизации Excel (xlwings)
xlwings позволяет управлять запущенным Excel и взаимодействовать с ним в реальном времени:
import xlwings as xw
import pandas as pd
# Открытие существующего файла (или создание нового)
wb = xw.Book('financial_model.xlsx')
ws = wb.sheets['Dashboard']
# Чтение данных из Excel
input_data = ws.range('B2:B5').value
# Обработка данных в Python
df = pd.DataFrame({
'Выручка': [input_data[0]],
'Себестоимость': [input_data[1]],
'Маржа': [input_data[0] - input_data[1]],
'Рентабельность': [(input_data[0] - input_data[1]) / input_data[0] * 100]
})
# Запись результатов обратно в Excel
ws.range('D2').value = df.values
# Обновление графика (Excel пересчитает формулы автоматически)
ws.range('A1').value = 'Обновлено: ' + pd.Timestamp.now().strftime('%Y-%m-%d %H:%M')
# Вызов Excel-макроса из Python (если есть)
# wb.macro('RefreshPivotTables')()
# Сохранение
wb.save()
# wb.close() # Опционально закрыть файл
xlwings особенно полезен, когда нужно интегрировать Python-аналитику в существующие Excel-файлы, используемые бизнес-пользователями. Excel остаётся интерфейсом, а Python выполняет сложные вычисления в фоне.
Когда Excel-библиотек недостаточно и что использовать вместо них
Несмотря на мощь и универсальность библиотек Python для работы с Excel, существуют сценарии, где электронные таблицы перестают быть оптимальным решением. Понимание этих ограничений помогает принять своевременное решение о миграции на более подходящие технологии.
- Ограничения по объёму данных. Excel имеет жёсткий лимит в 1 048 576 строк на лист. Даже если технически удаётся работать с таким объёмом через Python-библиотеки, производительность становится неприемлемой. Файлы размером более 100 МБ открываются медленно, операции поиска и фильтрации занимают секунды или минуты. Когда информации становится больше миллиона записей, пора рассматривать переход на реляционные БД — PostgreSQL, MySQL или даже SQLite для локальных задач.
- Проблемы с многопользовательским доступом. Excel-файлы не предназначены для одновременной работы множества пользователей. Даже с использованием облачных решений вроде Google Sheets или SharePoint возникают конфликты версий, потеря информации и проблемы синхронизации. Для приложений, где критична совместная работа с данными в реальном времени, необходима архитектура «клиент-сервер» с централизованной БД и API.
- Требования к целостности данных. Excel не обеспечивает транзакционность и не гарантирует целостность при сбоях. В таблице легко случайно удалить формулу, перезаписать важную информацию или нарушить связи между листами. Когда данные становятся критичными для бизнеса — финансовая отчётность, учёт складских операций, клиентская база — необходимы СУБД с поддержкой транзакций, ограничений целостности и механизмов восстановления.
- Сложные аналитические запросы. По мере усложнения аналитики Excel-формулы превращаются в нечитаемые конструкции, а производительность падает. Задачи вроде многомерного анализа, работы с временными рядами, сложных JOIN-операций между таблицами эффективнее решаются средствами SQL или специализированными аналитическими платформами.
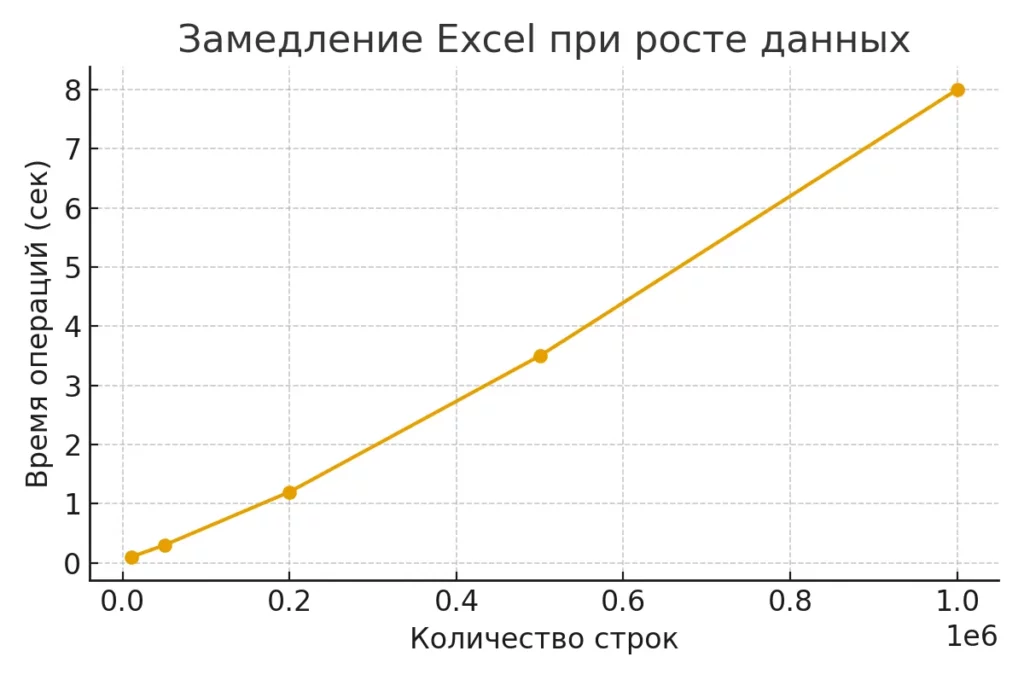
График демонстрирует, как резко ухудшается производительность Excel при увеличении числа строк. Визуально обосновывает переход к БД.
Что использовать вместо Excel:
- Для хранения и управления структурированной информацией переходите на реляционные СУБД — PostgreSQL или MySQL для серверных приложений, SQLite для локальных решений или встроенных систем. Python предоставляет отличные библиотеки для работы с базами: SQLAlchemy для ORM-подхода, psycopg2 для прямой работы с PostgreSQL, встроенный модуль sqlite3.
- Для больших данных и распределённых вычислений рассматривайте Apache Spark с библиотекой PySpark, которая позволяет обрабатывать терабайты информации на кластерах. Для аналитики временных рядов и финансовых данных существуют специализированные решения вроде InfluxDB или TimescaleDB.
- Для задач бизнес-аналитики и визуализации, где Excel традиционно использовался для создания дашбордов, переходите на современные BI-платформы — Tableau, Power BI, Apache Superset (open-source альтернатива). Эти инструменты напрямую подключаются к БД и обеспечивают интерактивную визуализацию без ограничений Excel.
Python помогает в миграции информации из Excel в эти системы: Pandas читает Excel-файлы, трансформирует данные и загружает их в базы через методы to_sql() или специализированные библиотеки вроде pandas-gbq для Google BigQuery. Это делает переход безболезненным и автоматизируемым.
Возникает вопрос: всегда ли нужно мигрировать от Excel? Нет, электронные таблицы остаются отличным инструментом для небольших наборов данных, прототипирования, ad-hoc анализа и обмена информацией с бизнес-пользователями. Ключ в том, чтобы вовремя распознать момент, когда ограничения Excel начинают тормозить развитие проекта, и иметь план миграции на масштабируемую архитектуру.
Заключение
Выбор библиотеки Python для работы с Excel — это инженерное решение, которое зависит от конкретных требований проекта: объёма данных, необходимости форматирования, производительности и сценариев использования. Как мы увидели, универсального инструмента не существует — каждая библиотека оптимизирована под определённый класс задач. Подведем итоги:
- Python предоставляет широкий выбор инструментов для работы с Excel. Это помогает автоматизировать отчёты, ускорить обработку данных и сделать процессы масштабируемыми.
- Каждая библиотека решает свой круг задач. Поэтому важно оценивать форматы, производительность, требования к форматированию и сценарии использования.
- Pandas, OpenPyXL и XlsxWriter закрывают основные рабочие процессы. В то время как PyExcelerate, Pycel, xlwings и другие решения подходят для узких и продвинутых задач.
- Excel остаётся удобным инструментом для небольших задач. Но при росте объёмов данных и требований к надёжности стоит рассматривать базы данных и BI-системы.
- Комбинация Python и Excel создаёт гибкую среду. Она позволяет строить воспроизводимые, стабильные и быстрые аналитические процессы.
Если вы только начинаете осваивать работу с автоматизацией Excel и хотите глубже понять возможности Python, рекомендуем обратить внимание на подборку курсов по Excel. В них есть теоретическая часть для формирования базы и практические задания, которые помогут закрепить инструменты на реальных задачах. Такие материалы особенно полезны, когда вы только начинаете осваивать аналитику данных и автоматизацию отчётов.
Рекомендуем посмотреть курсы по обучению Excel
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Excel и Google-таблицы: от новичка до эксперта
|
Eduson Academy
114 отзывов
|
Цена
16 800 ₽
33 600 ₽
Ещё -10% по промокоду
|
От
1 400 ₽/мес
Беспроцентная. На 1 год.
2 800 ₽/мес
|
Длительность
2 недели
|
Старт
6 апреля
|
Подробнее |
|
Excel Pro. Убойные таблицы
|
Bonnie&Slide
43 отзыва
|
Цена
27 200 ₽
38 800 ₽
|
От
2 266 ₽/мес
на 12 месяцев
|
Длительность
3 недели
|
Старт
в любое время
|
Подробнее |
|
Excel для анализа данных
|
Нетология
46 отзывов
|
Цена
30 300 ₽
56 062 ₽
с промокодом kursy-online
|
От
2 803 ₽/мес
Это минимальный ежемесячный платеж за курс.
2 491 ₽/мес
|
Длительность
2 месяца
|
Старт
6 апреля
|
Подробнее |
|
Excel для рабочих и личных задач
|
Skillbox
232 отзыва
|
Цена
27 864 ₽
55 728 ₽
Ещё -20% по промокоду
|
От
2 322 ₽/мес
На 10 месяцев
4 644 ₽/мес
|
Длительность
2 месяца
|
Старт
21 марта
|
Подробнее |
|
Excel для эффективной работы
|
Академия Синергия
38 отзывов
|
Цена
21 900 ₽
43 800 ₽
с промокодом KURSHUB
|
От
1 460 ₽/мес
0% на 12 месяцев
|
Длительность
2 месяца
|
Старт
в любое время
|
Подробнее |

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.

OTUS vs GeekBrains для backend: где строже к качеству кода и полезнее ревью
OTUS или GeekBrains — где обучение backend-разработке даёт более строгий подход к качеству кода? Разбираем, как устроено code review, какие инженерные практики используют школы и как проверить уровень ревью до оплаты курса.

Яндекс Практикум vs Contented: Figma/UI — где быстрее собрать 3 кейса и получить внятные правки
Выбираете между курсами UX/UI дизайна в Яндекс Практикуме и Contented? Разбираем, где быстрее собрать три сильных кейса в портфолио, как устроены ревью проектов и на что обратить внимание при выборе обучения.