Многомерная база данных — что это такое, как устроена и где используется
В эпоху больших данных и повсеместной цифровизации традиционные подходы к хранению и анализу информации часто оказываются недостаточными. Представьте ситуацию: компания накопила терабайты данных о продажах, клиентах и операциях, но каждый раз для получения простого отчета аналитикам приходится писать сложные SQL-запросы и ждать результатов по несколько часов.

Звучит знакомо?
Именно здесь на помощь приходят многомерные базы данных — технология, которая кардинально меняет подход к структурированию и анализу данных. В отличие от классических реляционных СУБД, где информация хранится в плоских таблицах, многомерные системы организуют данные в виде кубов, позволяя мгновенно получать агрегированные показатели по множественным измерениям.
В этом курсе мы детально разберем, что представляют собой многомерные базы данных, как они устроены изнутри и где находят применение в современном мире технологий.
- Что такое многомерная база данных
- Где применяются многомерные базы данных
- Зачем нужны многомерные базы данных
- Основные элементы многомерной базы данных
- Языки запросов для многомерных БД
- Преимущества многомерных баз данных
- Ограничения и недостатки
- Заключение
- Рекомендуем посмотреть курсы по backend разработке
Что такое многомерная база данных
Многомерная база данных (МСУБД) — это специализированная система управления базами данных (СУБД), разработанная специально для оперативной аналитической обработки (OLAP). В отличие от традиционных реляционных СУБД, где информация хранится в плоских таблицах, многомерные системы организуют данные в виде многомерных кубов, оптимизированных для хранения предварительно агрегированных показателей и обеспечения мгновенного аналитического доступа.
Схематическое изображение многомерного куба с тремя измерениями: время, продукт, регион. Каждая ячейка куба хранит агрегированные данные, что иллюстрирует базовый принцип МСУБД.
Ключевое отличие от реляционных баз данных заключается в принципиально ином подходе к организации информации. Если в SQL-базах мы имеем дело с плоскими таблицами, связанными через внешние ключи, то многомерные БД представляют данные в виде многомерных кубов. Каждая ось такого куба представляет отдельное измерение (время, география, продукты), а точки пересечения содержат агрегированные значения — меры.
Представим простой пример: в реляционной базе для анализа продаж нам потребуется несколько связанных таблиц (товары, клиенты, заказы, регионы), и каждый аналитический запрос будет включать множественные JOIN-операции. В многомерной БД та же информация организована в виде куба «Продажи», где измерениями выступают «Время», «Продукт» и «Регион», а мерой — «Сумма продаж».
Такая архитектура обеспечивает фундаментальное преимущество — возможность мгновенного преобразования данных между различными форматами. Например, JSON-структуры легко трансформируются в XML, документные данные — в графовые связи, а реляционные таблицы — в многомерные представления. Эта гибкость делает многомерные БД особенно ценными в современных гетерогенных IT-средах, где данные поступают из множества источников в различных форматах.
Где применяются многомерные базы данных
Финансовый анализ и бюджетирование
В финансовой сфере многомерные БД стали стандартом де-факто для корпоративного планирования и анализа. Финансовые кубы позволяют организовать данные по измерениям «Счета», «Подразделения», «Периоды» и «Сценарии», обеспечивая мгновенный доступ к показателям рентабельности, ликвидности и капитализации.
Практический кейс: крупная ритейлерская сеть использует МСУБД для консолидации финансовой отчетности 200+ магазинов. Система позволяет в режиме реального времени отслеживать выполнение бюджетов, анализировать отклонения и строить rolling-прогнозы на основе актуальных трендов. Время подготовки месячной управленческой отчетности сократилось с двух недель до одного дня.
Прогнозирование и предиктивная аналитика
Многомерные структуры идеально подходят для временного анализа и прогнозирования благодаря встроенным функциям работы с временными рядами. МСУБД позволяют легко применять статистические модели к многомерным данным, учитывая сезонность, тренды и циклические паттерны.
Телекоммуникационные компании используют многомерную аналитику для прогнозирования оттока клиентов (churn prediction), анализируя поведенческие паттерны по измерениям: тип услуги, география, демографические характеристики, история платежей. Такой подход позволяет выявлять группы риска и принимать превентивные меры по удержанию клиентов.
Сегментация клиентов и маркетинг
В маркетинговой аналитике многомерные БД обеспечивают глубокое понимание клиентского поведения через анализ покупательских паттернов в разрезе множественных измерений: демография, география, каналы взаимодействия, продуктовые предпочтения.
E-commerce платформы строят кубы клиентской аналитики для персонализации предложений. Система анализирует транзакционную историю в контексте сезонности, категорий товаров, ценовых сегментов и поведенческих метрик, формируя персонализированные рекомендации в реальном времени.
Логистика и управление запасами
В сфере supply chain management многомерные БД помогают оптимизировать складские запасы и логистические процессы. Кубы строятся по измерениям: склады, продукты, поставщики, временные периоды, что позволяет анализировать оборачиваемость, прогнозировать потребности и оптимизировать маршруты доставки.
Производственные компании используют МСУБД для анализа эффективности цепей поставок, отслеживая KPI по измерениям: заводы, линии производства, сырьевые материалы, качественные показатели. Это обеспечивает быструю идентификацию узких мест и возможность оперативной корректировки производственных планов.
Зачем нужны многомерные базы данных
Основная ценность многомерных баз данных раскрывается в сфере аналитики и работы с большими объемами данных. В отличие от традиционного SQL-подхода, где каждый аналитический запрос требует сложной обработки отдельных строк таблиц, многомерные системы предлагают принципиально иной механизм — предварительно агрегированные данные, организованные по измерениям.
Главная задача, которую решают МСУБД, — это ускорение аналитических процессов. Представьте, что вместо выполнения сложного JOIN-запроса по нескольким таблицам для получения отчета о продажах по регионам за квартал, вы просто обращаетесь к соответствующему сечению куба данных. Результат получается мгновенно, поскольку агрегирование уже выполнено на этапе загрузки данных в систему.
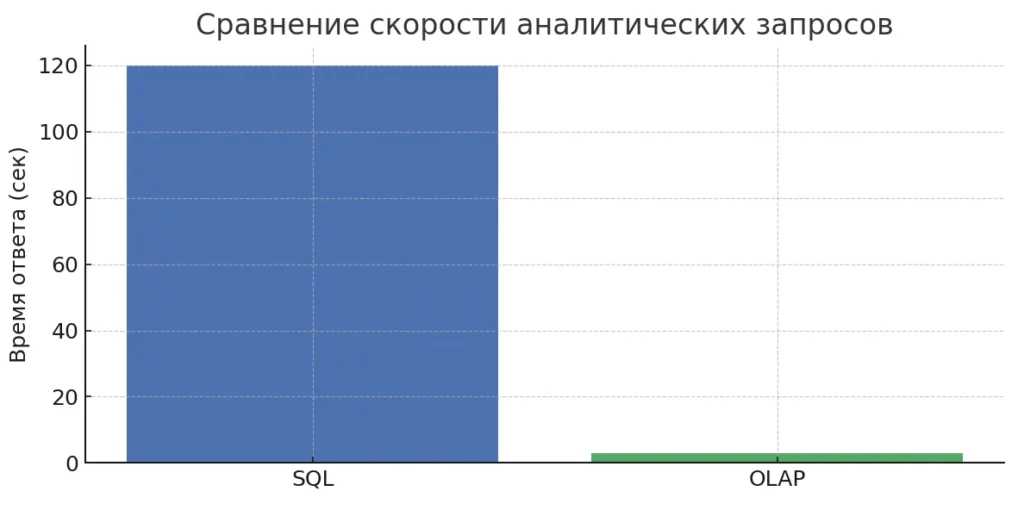
Диаграмма показывает разницу во времени выполнения аналитических запросов в традиционных SQL-БД и многомерных OLAP-системах. Разница на порядок иллюстрирует ключевое преимущество МСУБД — мгновенные ответы.
Для бизнеса это означает качественно новые возможности в области принятия решений. Аналитики получают способность проводить интерактивные исследования данных — менять фильтры, детализировать показатели, строить сравнения в режиме реального времени. Такой подход особенно ценен при работе с большими данными, где традиционные методы анализа становятся неэффективными.
Многомерные БД также превосходно справляются с задачами визуализации сложных зависимостей. Возможность исследовать данные с разных углов зрения — переключаться между уровнями иерархий, применять различные фильтры, строить динамические сводные таблицы — превращает анализ данных из рутинной процедуры в интуитивно понятный процесс поиска инсайтов.
Не менее важным преимуществом является централизация разнородных источников данных. Вместо поддержания множества специализированных систем для документов, графов, временных рядов и реляционных данных, организация может использовать единую платформу, что существенно снижает сложность администрирования и повышает качество данных.
Основные элементы многомерной базы данных
Кубы данных
Куб данных представляет собой центральную структуру многомерной базы, которая организует информацию в виде многомерного массива. В отличие от двумерных таблиц реляционных БД, куб может иметь произвольное количество измерений — от простого трехмерного представления до сложных многомерных структур с десятками осей.
Принцип организации куба основан на разделении данных по категориям — измерениям. Каждое измерение представляет определенный аспект анализа: время, география, продуктовая линейка, каналы продаж. Пересечение значений разных измерений образует ячейку куба, содержащую агрегированные показатели — меры.
Рассмотрим классический пример куба продаж: ось X представляет временные периоды (месяцы), ось Y — продуктовые категории, ось Z — регионы. Каждая точка пересечения содержит сумму продаж конкретной категории товаров в определенном регионе за конкретный месяц.
Измерения и иерархии
Измерения в многомерных БД — это атрибуты, определяющие контекст анализа данных. Каждое измерение может содержать иерархическую структуру, позволяющую анализировать данные на различных уровнях детализации.
Временное измерение обычно включает иерархию: Год → Квартал → Месяц → Неделя → День. Географическое измерение может быть организовано как: Континент → Страна → Регион → Город → Район. Продуктовое измерение: Категория → Подкатегория → Бренд → Модель.
Иерархии обеспечивают навигационные возможности — пользователь может начать анализ на высоком уровне (например, годовые показатели) и затем детализировать до более конкретных периодов, используя операции drill-down и roll-up.
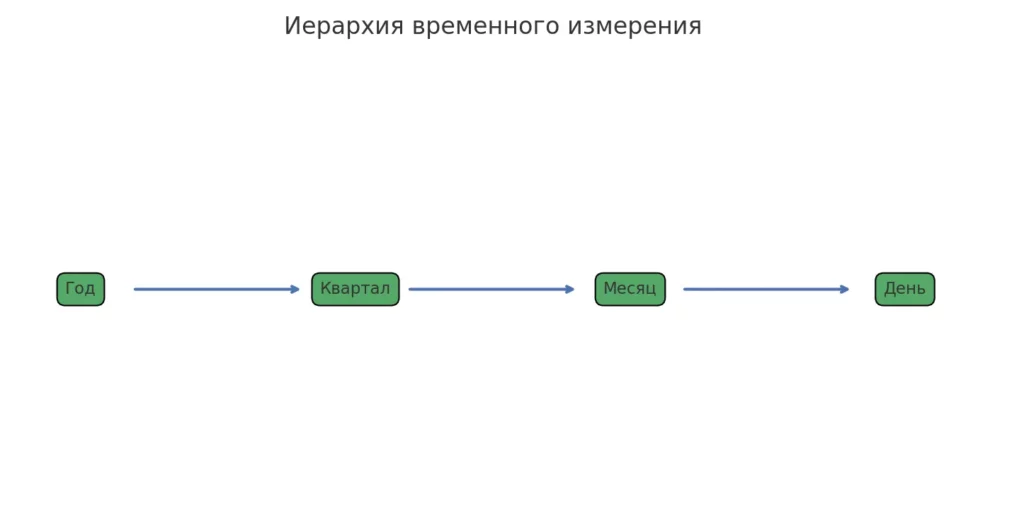
Простая схема показывает структуру временного измерения — от года к дню. Такая иерархия позволяет выполнять drill-down и roll-up операции при анализе данных.
Меры
Меры представляют собой числовые показатели, которые агрегируются внутри куба. Это могут быть как простые метрики (сумма продаж, количество заказов, средний чек), так и сложные вычисляемые показатели (рентабельность, темпы роста, индексы).
Важная особенность мер заключается в их аддитивности — способности корректно суммироваться по различным измерениям. Например, сумма продаж является аддитивной по всем измерениям, в то время как средняя цена требует специальной обработки при агрегировании.
Агрегирование
Агрегирование — это процесс предварительного вычисления и сохранения сводных данных на различных уровнях детализации. МСУБД автоматически выполняют операции SUM (суммирование), AVG (усреднение), COUNT (подсчет), MAX/MIN для всех возможных комбинаций измерений.
Предварительное агрегирование кардинально ускоряет выполнение аналитических запросов — вместо обработки миллионов строк исходных данных система обращается к уже вычисленным агрегатам. Это особенно критично для интерактивной аналитики, где время отклика должно составлять секунды, а не минуты.
Языки запросов для многомерных БД
MDX (Multidimensional Expressions)
MDX представляет собой специализированный язык запросов, разработанный Microsoft специально для работы с многомерными структурами данных. В отличие от SQL, который оперирует двумерными таблицами, MDX создан для навигации по кубам и извлечения данных из многомерного пространства.
Основные возможности MDX включают сложную фильтрацию данных по множественным критериям, создание вычисляемых полей на основе существующих мер, выполнение агрегирующих операций и пространственную навигацию по иерархиям измерений. Язык поддерживает операции drill-down, roll-up, slice и dice, которые являются фундаментальными для OLAP-анализа.
Рассмотрим практический пример MDX-запроса для анализа продаж:
SELECT [Measures].[Sales Amount] ON COLUMNS, [Product].[Category].[Category].Members ON ROWS FROM [Sales Cube] WHERE [Date].[Year].&[2024]
Этот запрос извлекает сумму продаж по категориям продуктов за 2024 год. Обратите внимание на синтаксис — MDX использует концепцию осей (COLUMNS, ROWS) и специальную нотацию для обращения к элементам измерений.
DAX (Data Analysis Expressions)
DAX получил широкое распространение с развитием экосистемы Microsoft — Power BI, Analysis Services, Excel Power Pivot. Этот язык сочетает функциональное программирование с табличной моделью данных, предоставляя мощные возможности для создания сложных вычислений.
Ключевые функции DAX включают CALCULATE для модификации контекста фильтрации, RANKX для ранжирования, FILTER для создания динамических фильтров, и множество временных функций для анализа трендов. DAX особенно эффективен при работе с большими объемами данных благодаря оптимизированному движку VertiPaq.
Пример создания сегментации клиентов с использованием DAX:
Customer Segment = SWITCH( TRUE(), [Customer Lifetime Value] > 10000, "Premium", [Customer Lifetime Value] > 5000, "Standard", [Customer Lifetime Value] > 1000, "Basic", "Inactive" )
Еще один практический пример — вычисление динамического показателя роста:
Sales Growth = DIVIDE( [Current Period Sales] - [Previous Period Sales], [Previous Period Sales] ) * 100
Оба языка требуют понимания концепций контекста фильтрации и особенностей многомерного мышления, что делает их изучение достаточно сложным для специалистов, привыкших к традиционному SQL-подходу.
Преимущества многомерных баз данных
Многомерные базы данных предоставляют ряд ключевых преимуществ, которые делают их незаменимыми в современной аналитической экосистеме:
- Высокая производительность — пожалуй, самое значимое преимущество МСУБД. Благодаря предварительному агрегированию данных и специальным алгоритмам сжатия, аналитические запросы выполняются в разы быстрее по сравнению с традиционными реляционными системами. Мы говорим о сокращении времени выполнения с часов до секунд, что критично для интерактивной аналитики.
- Гибкость анализа проявляется в возможности мгновенно менять перспективу рассмотрения данных. Аналитик может начать с обзора годовых показателей по всем регионам, затем детализировать конкретный квартал, переключиться на анализ по продуктовым линейкам и вернуться к временным трендам — и все это без написания новых запросов.
- Масштабируемость и эффективное сжатие данных обеспечиваются за счет специальных техник хранения. Многомерные БД используют алгоритмы сжатия, оптимизированные для аналитических нагрузок, что позволяет работать с терабайтами данных на стандартном оборудовании. Кроме того, архитектура МСУБД естественным образом поддерживает горизонтальное масштабирование.
- Возможности создания сложных отчетов и дашбордов превращают многомерные БД в идеальную платформу для бизнес-интеллекта. Системы легко интегрируются с инструментами визуализации, позволяя создавать интерактивные дашборды с drill-down функциональностью, динамические сводные таблицы и многомерные диаграммы.
- Унификация разнородных данных — особенно важное преимущество в эпоху мультиформатных данных. МСУБД могут одновременно работать с документами, графами, временными рядами и реляционными структурами, предоставляя единый интерфейс доступа и анализа.
- Готовые аналитические конструкции избавляют от необходимости каждый раз создавать сложные SQL-запросы. Концепции измерений, иерархий и мер становятся естественным языком для описания бизнес-логики, что существенно снижает барьер входа для бизнес-аналитиков без глубоких технических знаний.
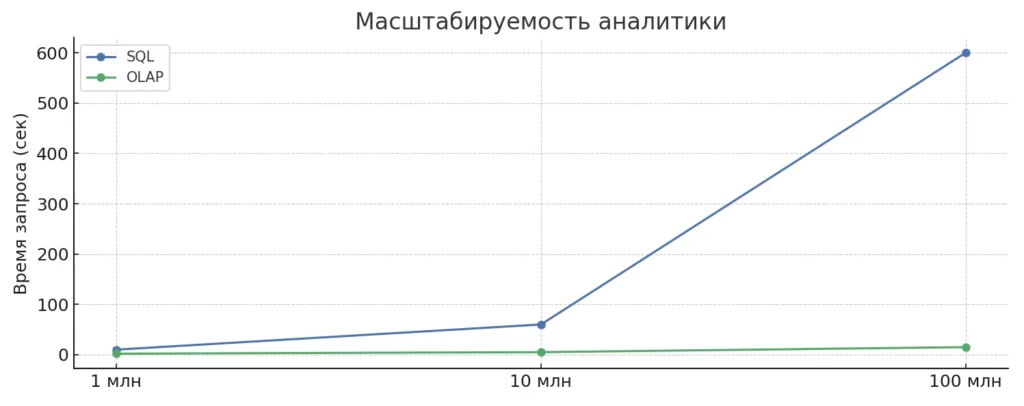
График демонстрирует, как многомерные БД сохраняют высокую производительность при росте объема данных. OLAP-системы обрабатывают сотни миллионов строк быстрее, чем SQL — это критично для real-time аналитики.
Ограничения и недостатки
Несмотря на впечатляющие возможности, многомерные базы данных имеют ряд существенных ограничений, которые необходимо учитывать при принятии решения об их внедрении.
- Сложность настройки и администрирования представляет собой главный барьер для многих организаций. Проектирование многомерных структур требует глубокого понимания предметной области и специфики аналитических потребностей. Неправильно спроектированные измерения или иерархии могут привести к неэффективной работе системы и искажению результатов анализа. Администрирование МСУБД также значительно сложнее традиционных реляционных систем — требуется понимание концепций кубов, партиционирования, агрегирования и оптимизации запросов.
- Высокие требования к ресурсам становятся особенно заметными при работе с большими объемами данных. Хотя многомерные БД эффективно сжимают данные, процесс построения и обновления кубов может требовать значительных вычислительных мощностей и времени. Операции полного пересчета агрегатов в крупных системах могут занимать часы, что создает окна недоступности для аналитиков.
- Кривая обучения для специалистов представляет серьезную проблему. Переход от привычного SQL к MDX или DAX требует переосмысления подходов к работе с данными. Многомерное мышление, понимание контекстов фильтрации, специфика навигации по иерархиям — все это требует значительных инвестиций в обучение персонала. На практике это часто приводит к ситуации, когда мощные возможности МСУБД используются лишь частично.
- Ограниченная гибкость схемы данных также может стать проблемой в динамично развивающихся проектах. Изменение структуры куба — добавление новых измерений или модификация иерархий — часто требует полного пересчета агрегатов и может привести к временной недоступности системы. Это делает многомерные БД менее подходящими для agile-проектов с часто меняющимися требованиями к аналитике.
Заключение
Многомерные базы данных представляют собой специализированную технологию для организации и анализа больших объемов структурированных данных, которая принципиально отличается от традиционных реляционных СУБД архитектурой хранения в виде многомерных кубов и предварительно агрегированными показателями. Подведем итоги:
- Многомерные базы данных ускоряют аналитику. Предварительные агрегаты сокращают время отклика с часов до секунд.
- Кубовая модель делает анализ гибким. Измерения и иерархии позволяют быстро выполнять drill-down и roll-up.
- МСУБД хорошо масштабируются. Сжатие и партиционирование поддерживают стабильную производительность на терабайтах.
- BI-инструменты интегрируются естественно. Дашборды и отчёты строятся на готовых мерах без ручного SQL.
- MDX и DAX расширяют выразительность запросов. Вычисляемые показатели и контексты фильтрации упрощают сложные расчёты.
- Области применения широки. Финансы, прогнозирование, маркетинг и логистика получают быстрые инсайты.
- Внедрение требует компетенций. Проектирование кубов и администрирование сложнее классических СУБД.
Если вы только начинаете осваивать профессию разработчика, рекомендуем обратить внимание на подборку курсов по backend-разработке. Материалы включают теорию и практику, чтобы отработать навыки на реальных задачах и уверенно применять OLAP-подход.
Рекомендуем посмотреть курсы по backend разработке
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
IT-специалист с нуля
|
Eduson Academy
114 отзывов
|
Цена
122 500 ₽
|
От
10 208 ₽/мес
0% на 24 месяца
11 239 ₽/мес
|
Длительность
12 месяцев
|
Старт
24 марта
|
Подробнее |
|
Бэкенд-разработчик
|
HTML Academy
34 отзыва
|
Цена
30 600 ₽
46 000 ₽
|
От
1 700 ₽/мес
На 18 месяцев
2 453 ₽/мес
|
Длительность
11 месяцев
|
Старт
в любое время
|
Подробнее |
|
Веб-разработчик с нуля
|
Нетология
46 отзывов
|
Цена
163 300 ₽
302 470 ₽
с промокодом kursy-online
|
От
5 041 ₽/мес
Без переплат на 2 года.
7 222 ₽/мес
|
Длительность
17 месяцев
|
Старт
5 апреля
|
Подробнее |
|
FastAPI — погружение в backend разработку на Python
|
Stepik
33 отзыва
|
Цена
250 000 ₽
|
|
Длительность
4 месяца
|
Старт
в любое время
|
Подробнее |
|
Профессия Fullstack-разработчик на Python
|
Skillbox
232 отзыва
|
Цена
146 073 ₽
292 147 ₽
Ещё -20% по промокоду
|
От
4 296 ₽/мес
|
Длительность
12 месяцев
|
Старт
23 марта
|
Подробнее |

OTUS vs ProductStar: куда идти технарю, чтобы стать продактом — честное сравнение подходов
OTUS или ProductStar — что выбрать, если вы хотите перейти в продакт-менеджмент? Разбираем разницу в обучении, практике и результате, чтобы вы не потратили время зря.

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.

OTUS vs GeekBrains для backend: где строже к качеству кода и полезнее ревью
OTUS или GeekBrains — где обучение backend-разработке даёт более строгий подход к качеству кода? Разбираем, как устроено code review, какие инженерные практики используют школы и как проверить уровень ревью до оплаты курса.