Модели машинного обучения: понятное объяснение для всех
В эпоху цифровой трансформации мы ежедневно взаимодействуем с результатами работы искусственного интеллекта, часто даже не подозревая об этом. Рекомендации музыки в Spotify, персонализированная лента в социальных сетях, голосовые помощники в смартфонах — все это работает благодаря моделям машинного обучения. Но что представляют собой эти загадочные «модели» и как они влияют на нашу жизнь?

Мы подготовили курс, который поможет разобраться в основах машинного обучения — от базовых концепций до практических применений. Независимо от вашего технического бэкграунда, эта статья даст вам необходимые знания для понимания одной из ключевых технологий современности. Давайте погрузимся в мир алгоритмов, которые учатся думать.
- Что такое модель машинного обучения?
- Как работает машинное обучение?
- Какие бывают типы обучения?
- Основные алгоритмы и модели машинного обучения
- Как выбрать подходящую модель?
- Где применяют модели машинного обучения?
- Профессии в области ML: кто работает с моделями?
- Частые ошибки и советы новичкам
- Заключение
- Рекомендуем посмотреть курсы по системной аналитике
Что такое модель машинного обучения?
В мире современных технологий мы постоянно сталкиваемся с результатами работы искусственного интеллекта — от рекомендаций фильмов на Netflix до голосовых помощников в наших смартфонах. Но что именно стоит за этими «умными» решениями?
Модель машинного обучения — это, по сути, компьютерная программа, которая учится находить закономерности в данных и на их основе делать прогнозы или принимать решения. Представьте себе очень внимательного ученика, который изучает тысячи примеров и постепенно понимает, как связаны между собой различные факторы.
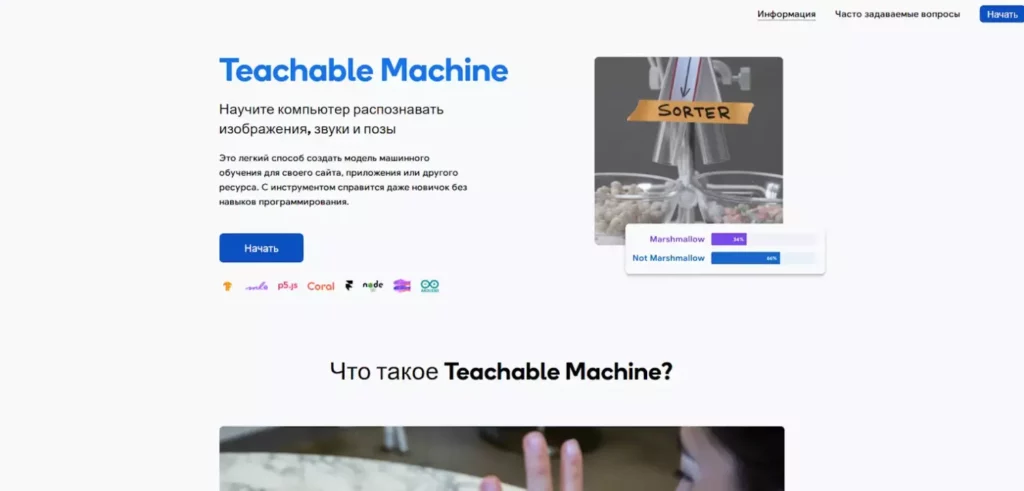
Скриншот сайта https://teachablemachine.withgoogle.com/. Показывает, как «обучается» модель на примерах в визуальной среде. Это помогает интуитивно понять концепцию обучения модели, особенно без технического фона.
Важно понимать иерархию современных технологий: искусственный интеллект (AI) — это широкая область, включающая все попытки создать «думающие» машины. Машинное обучение (ML) — это подраздел AI, где программы учатся самостоятельно, а глубокое обучение (Deep Learning) — это продвинутый метод машинного обучения, основанный на нейронных сетях.
Почему это важно? Машинное обучение позволяет автоматизировать сложные процессы принятия решений: от диагностики заболеваний до оптимизации логистических маршрутов. В бизнесе ML-модели помогают предсказывать спрос, выявлять мошенничество и персонализировать предложения для клиентов.
Краткая история машинного обучения: от шахмат к ChatGPT
Идея обучающихся машин не нова. В 1950-х годах Алан Тьюринг задал фундаментальный вопрос: могут ли машины думать? В те годы появились первые попытки запрограммировать компьютеры на распознавание шаблонов. В 1957 году ученый Фрэнк Розенблатт представил концепцию перцептрона — первой математической модели нейронной сети, а уже в 1958 году продемонстрировал машину Mark I, способную обучаться распознаванию простых изображений.
В 1980-х нейросети стали сложнее, но вычислительных мощностей было недостаточно. Прорыв произошёл в начале 2010-х — благодаря графическим процессорам и большим данным. Тогда появились алгоритмы глубокого обучения, способные распознавать лица, тексты и речь.
Сегодня ML используется везде — от медицины до маркетинга. А такие системы, как ChatGPT или AlphaFold, стали символами новой технологической эпохи. Понимание этой эволюции помогает осознать, почему машинное обучение стало одной из ключевых технологий XXI века.
Как работает машинное обучение?
Процесс машинного обучения можно сравнить с тем, как ребенок учится различать яблоки и груши. Сначала родители показывают ему множество фруктов, называя каждый: «Это яблоко, это груша». Постепенно ребенок запоминает признаки — форму, цвет, размер — и начинает самостоятельно определять новые фрукты.
Машинное обучение работает по схожему принципу, но в более структурированном виде:
- Первый этап — сбор данных. Мы собираем большое количество примеров того, что хотим научиться предсказывать. Это могут быть фотографии, тексты, числовые показатели — любая информация, связанная с нашей задачей.
- Второй этап — выбор модели. Определяем, какой алгоритм лучше всего подходит для нашей задачи. Это как выбор правильного инструмента: для забивания гвоздей нужен молоток, а не отвертка.
- Третий этап — обучение. Модель анализирует предоставленные данные, ищет закономерности и «запоминает» их. В процессе обучения программа многократно корректирует свои внутренние параметры, стремясь максимально точно воспроизводить известные результаты.
- Четвертый этап — тестирование. Проверяем, насколько хорошо обученная модель работает с новыми, ранее не виденными данными. Это критически важный этап — ведь модель должна быть полезной в реальных условиях, а не только на тренировочных примерах.
Когда мы говорим, что «модель обучается», мы имеем в виду математический процесс оптимизации, при котором алгоритм постепенно улучшает свою способность находить правильные ответы.
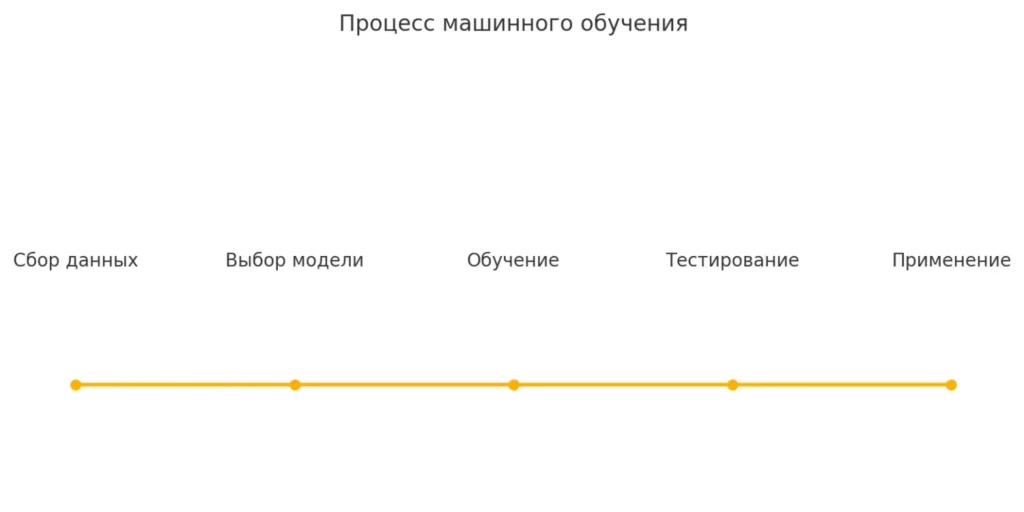
Основные этапы машинного обучения — от сбора данных до внедрения модели.
Как обучение отличается от программирования
Главное отличие машинного обучения от традиционного программирования — в способе получения логики.
В классическом программировании человек сам описывает каждое правило: «если X — сделай Y». Например, чтобы различать яблоко и грушу, программист должен задать список признаков и написать условия.
В машинном обучении таких жёстких правил нет. Вместо этого алгоритм сам находит закономерности, обучаясь на примерах. Мы не говорим, что красное — это яблоко. Мы просто показываем много красных и жёлтых фруктов, и модель сама определяет, что к чему.
Это делает ML более гибким и мощным, но и менее предсказуемым — модель может найти связи, которые человек не заметит, но и допустить неожиданные ошибки.
Какие бывают типы обучения?
Машинное обучение классифицируется по способу, которым модель получает знания. Каждый тип решает определенный класс задач и требует разного подхода к данным.
Обучение с учителем (Supervised Learning) — самый распространенный тип. Здесь у нас есть «правильные ответы» для всех примеров в обучающей выборке. Модель изучает связь между входными данными и известными результатами, а затем применяет эти знания к новым случаям. Классические примеры: определение, является ли email спамом (есть размеченная база писем), или прогноз стоимости недвижимости на основе характеристик квартиры.
Обучение без учителя (Unsupervised Learning) работает с неразмеченными данными — мы не знаем «правильных ответов». Модель самостоятельно ищет скрытые закономерности и структуры. Типичный пример — сегментация клиентов магазина: алгоритм анализирует покупательское поведение и автоматически выделяет группы с похожими предпочтениями.
Полуобучение (Semi-Supervised Learning) объединяет два предыдущих подхода. У нас есть небольшое количество размеченных данных и много неразмеченных. Это особенно полезно, когда разметка данных требует экспертных знаний и больших затрат — например, при анализе медицинских снимков.
Обучение с подкреплением (Reinforcement Learning) основано на системе поощрений и наказаний. Модель учится через взаимодействие со средой, получая обратную связь о качестве своих действий. Именно так работают системы, играющие в шахматы или управляющие беспилотными автомобилями.
Четыре типа машинного обучения — в образах: учитель, исследователь, комбинированный подход и игрок.
Выбор типа обучения зависит от характера имеющихся данных и конкретной задачи, которую необходимо решить.
Основные алгоритмы и модели машинного обучения
Разнообразие алгоритмов машинного обучения может показаться пугающим, но каждый из них создан для решения определенного типа задач. Давайте разберем основные модели, которые формируют костяк современного ML.
Алгоритмы для обучения с учителем
Линейная регрессия — это фундамент машинного обучения, своего рода «Hello, World!» для data science. Алгоритм ищет прямую линию, которая наилучшим образом описывает зависимость между переменными. Представьте график, где по оси X отложена площадь квартиры, а по Y — её цена. Линейная регрессия найдет прямую линию, которая покажет, как цена растет с увеличением площади. Используется везде, где нужно предсказать числовое значение: от прогноза продаж до оценки влияния рекламных кампаний.
Логистическая регрессия решает задачи классификации, несмотря на название «регрессия». Вместо прямой линии она строит S-образную кривую, которая позволяет предсказывать вероятности. Банки активно используют этот алгоритм для кредитного скоринга: модель анализирует доходы, кредитную историю, возраст заемщика и выдает вероятность того, что кредит будет возвращен вовремя.
K-ближайших соседей (KNN) работает по принципу «скажи мне, кто твои соседи, и я скажу, кто ты». Когда нужно классифицировать новый объект, алгоритм ищет K самых похожих примеров в обучающих данных и принимает решение на основе «голосования большинства». Рекомендательные системы часто используют KNN: если ваши музыкальные предпочтения похожи на предпочтения других пользователей, система порекомендует вам треки, которые понравились этим «соседям».
Метод опорных векторов (SVM) создает границы между классами данных, стремясь максимизировать расстояние до ближайших точек каждого класса. Это особенно эффективно при работе с текстами — например, для автоматической классификации документов или анализа тональности отзывов. SVM хорошо работает даже с небольшими объемами данных и высокой размерностью признаков.
Дерево решений имитирует человеческий процесс принятия решений через серию вопросов типа «да/нет». Каждый узел дерева — это вопрос о конкретном признаке данных, а листья — финальные решения. Классический пример: определение кредитоспособности клиента через вопросы «Возраст больше 25 лет?», «Доход выше 50,000?», «Есть ли просрочки?». Главное преимущество — высокая интерпретируемость результатов.
Случайный лес (Random Forest) объединяет множество деревьев решений, каждое из которых обучается на случайной подвыборке данных. Финальное решение принимается голосованием всех деревьев. Это решает главную проблему одиночных деревьев — склонность к переобучению. Random Forest широко применяется в медицине для диагностики заболеваний и в финансах для оценки рисков.
Ансамблевые методы (XGBoost, CatBoost) представляют собой эволюцию идеи случайного леса. Они последовательно строят модели, где каждая следующая исправляет ошибки предыдущих. XGBoost завоевал популярность в соревнованиях по машинному обучению благодаря высокой точности, а CatBoost особенно хорош при работе с категориальными данными. Крупные компании используют эти алгоритмы для прогнозирования спроса, оптимизации цен и персонализации рекламы.
Алгоритмы машинного обучения и тип задач, для которых они применяются: регрессия, классификация или кластеризация.
Алгоритмы для обучения без учителя
K-Means кластеризация автоматически разбивает данные на заданное количество групп (кластеров) так, чтобы объекты внутри каждой группы были максимально похожи, а между группами — максимально различны. Ритейлеры используют K-Means для сегментации клиентов: алгоритм может выделить группы «экономных покупателей», «любителей премиум-товаров» и «импульсивных покупателей» на основе истории покупок.
DBSCAN кластеризация более гибкий алгоритм, который сам определяет количество кластеров и может находить группы любой формы. Он также выявляет аномалии — точки, которые не относятся ни к одному кластеру. Это делает DBSCAN полезным для обнаружения мошенничества в финансовых операциях или выявления неисправностей в промышленном оборудовании.
Нейронные сети
Нейронные сети заслуживают особого внимания как наиболее мощный и универсальный инструмент современного машинного обучения. Они моделируют работу человеческого мозга через сеть взаимосвязанных узлов (нейронов), организованных в слои.
Базовая архитектура включает входной слой (получает данные), один или несколько скрытых слоев (обрабатывают информацию) и выходной слой (производит результат). Каждое соединение между нейронами имеет вес, который корректируется в процессе обучения.
Нейросети revolutionized множество областей: компьютерное зрение (распознавание объектов на фотографиях), обработка естественного языка (переводчики, ChatGPT), распознавание речи (голосовые помощники). Автопилоты Tesla, рекомендации YouTube, фильтры Instagram — все это работает на нейронных сетях.
Главное отличие от классических алгоритмов — способность автоматически выявлять сложные нелинейные зависимости и работать с неструктурированными данными типа изображений, текстов и звука.
Как выбрать подходящую модель?
Выбор правильной модели машинного обучения — это искусство, которое приходит с опытом, но существуют четкие принципы, которые помогают принять обоснованное решение.
- Тип задачи определяет класс алгоритмов. Если нужно предсказать числовое значение (цену, температуру, количество продаж), используйте регрессионные модели. Для задач классификации (спам или не спам, болен или здоров) подойдут логистическая регрессия, SVM или деревья решений. Когда цель — найти скрытые группы в данных, обращайтесь к алгоритмам кластеризации.
- Объем и качество данных кардинально влияют на выбор. Для небольших датасетов (до нескольких тысяч примеров) хорошо работают простые модели: линейная регрессия, KNN, наивный байесовский классификатор. Большие объемы данных позволяют использовать сложные алгоритмы — случайный лес, градиентный бустинг, нейронные сети.
- Интерпретируемость результатов часто важнее точности. В медицине или финансах, где решения ML-модели влияют на жизни людей, предпочтение отдается понятным алгоритмам: деревьям решений или линейной регрессии. Нейронные сети могут быть точнее, но объяснить их решения крайне сложно.
- Практическое правило для новичков. Начинайте с простых моделей и постепенно усложняйте. Сначала попробуйте линейную регрессию или логистическую регрессию, затем переходите к Random Forest, и только потом экспериментируйте с нейросетями. Часто простые модели работают удивительно хорошо.
- Всегда тестируйте несколько подходов. Даже опытные специалисты не могут заранее знать, какая модель окажется лучшей для конкретной задачи. Современные инструменты позволяют быстро сравнить десятки алгоритмов и выбрать оптимальный.
Помните: идеальной модели не существует. Каждая имеет свои сильные и слабые стороны, и выбор всегда зависит от контекста конкретной задачи.
Где применяют модели машинного обучения?
Машинное обучение давно перестало быть академической дисциплиной и прочно вошло в нашу повседневную жизнь. Сегодня ML-модели работают в самых разных отраслях, часто оставаясь незаметными для конечных пользователей.
Финансовые технологии стали одними из первых массово внедрять машинное обучение. Кредитный скоринг теперь анализирует не только традиционные показатели вроде дохода и кредитной истории, но и цифровой след клиента: активность в социальных сетях, паттерны покупок, даже скорость заполнения онлайн-форм. Алгоритмы выявления мошенничества отслеживают подозрительные транзакции в реальном времени, блокируя карты при малейших признаках компрометации.
Ритейл и электронная коммерция используют ML для прогнозирования спроса и оптимизации запасов. Amazon может предсказать, какие товары будут популярны в конкретном регионе за несколько дней до пикового спроса. Рекомендательные системы стали ключевым бизнес-инструментом. Например, по данным исследования McKinsey, еще несколько лет назад они генерировали до 35% выручки Amazon, анализируя поведение миллионов покупателей
Медицина переживает революцию благодаря компьютерному зрению и анализу медицинских изображений. Нейросети уже превосходят врачей в диагностике некоторых видов рака по рентгеновским снимкам и МРТ. Системы поддержки принятия врачебных решений анализируют симптомы, историю болезни и результаты анализов, предлагая возможные диагнозы и планы лечения.
Безопасность и видеонаблюдение полагаются на алгоритмы распознавания лиц и поведенческой аналитики. Системы в аэропортах автоматически выявляют подозрительное поведение, а умные камеры могут отследить движение конкретного человека через весь город, что поднимает важные вопросы о балансе между безопасностью и приватностью.
Мы наблюдаем лишь начало эры повсеместного применения машинного обучения — технологии становятся доступнее, а области применения расширяются с каждым днем.
Профессии в области ML: кто работает с моделями?
Экосистема машинного обучения включает специалистов разного профиля, каждый из которых играет свою роль в создании и внедрении ML-решений. Понимание этих ролей поможет определиться с карьерным путем в данной области.
Data Scientist — универсальный солдат мира данных. Эти специалисты формулируют бизнес-задачи в терминах машинного обучения, исследуют данные, выбирают и настраивают модели, интерпретируют результаты. Требуются знания статистики, программирования на Python или R, понимание бизнес-процессов. Data Scientist должен уметь объяснить сложные концепции простыми словами — часто именно от этого зависит внедрение ML-решения в компании.
ML-инженер фокусируется на технической стороне: разворачивает модели в production, обеспечивает их масштабируемость и надежность, настраивает мониторинг. Это гибрид разработчика и data scientist-а, который знает Docker, Kubernetes, облачные платформы и может интегрировать ML-модель в существующую IT-инфраструктуру. Спрос на таких специалистов растет быстрее всего.
Разработчики библиотек и фреймворков создают инструменты, которыми пользуются остальные. Команды TensorFlow, PyTorch, scikit-learn состоят именно из таких специалистов. Им нужны глубокие знания математики, алгоритмов и системного программирования. Это высший пилотаж в ML-разработке.
Исследователи ML работают в академических институтах и R&D-подразделениях крупных компаний, изобретая новые алгоритмы и методы. Обычно требуется PhD в области computer science, математики или смежных дисциплин.
Для новичков рекомендуется начать с изучения Python, математической статистики и основ машинного обучения. Онлайн-курсы, pet-проекты на GitHub и участие в соревнованиях на Kaggle — проверенный путь входа в профессию. Главное — практика и постоянное обучение в быстро развивающейся области.
Частые ошибки и советы новичкам
Путь в машинное обучение полон подводных камней, и знание типичных ошибок поможет избежать разочарований на начальном этапе.
- Переобучение (overfitting) — главный враг начинающих data scientist-ов. Модель отлично работает на тренировочных данных, но проваливается на новых примерах. Это происходит, когда алгоритм «зазубривает» обучающую выборку вместо поиска общих закономерностей. Решение: обязательно разделяйте данные на тренировочную, валидационную и тестовую части, используйте кросс-валидацию.
- Недостаток качественных данных убивает даже самые совершенные алгоритмы. Помните правило: «мусор на входе — мусор на выходе». Потратьте время на исследование и очистку данных — это 80% успеха проекта. Проверяйте на дубли, пропуски, выбросы и несоответствия.
- Неправильный выбор метрик приводит к оптимизации не тех показателей. Высокая точность не всегда означает хорошую модель — особенно при несбалансированных классах. Для медицинской диагностики важнее не пропустить болезнь (высокая полнота), чем избежать ложных тревог.
- Игнорирование доменной экспертизы — типичная ошибка технических специалистов. Модель может быть математически корректной, но бессмысленной с точки зрения предметной области. Всегда консультируйтесь с экспертами в той сфере, для которой создаете решение.
- Стремление к сложности с самого начала. Новички часто хотят сразу использовать нейросети для простых задач. Начинайте с базовых алгоритмов — они часто работают не хуже сложных моделей и помогают лучше понять данные.
Этические риски и границы машинного обучения
С ростом применения ML всё чаще поднимаются вопросы этики. Вот несколько ключевых проблем:
- Смещение и дискриминация. Если модель обучена на искажённых данных, она может усиливать социальные стереотипы — например, необоснованно отказывать в кредите определённым группам людей.
- Непрозрачность. Алгоритмы, особенно нейросети, часто действуют как «чёрный ящик». Это затрудняет объяснение, почему система приняла то или иное решение.
- Конфиденциальность. Сбор и анализ пользовательских данных порождает риск нарушения приватности.
- Автоматизация и рабочие места. Автоматизированные системы заменяют людей в некоторых профессиях, что требует переосмысления ролей и подготовки кадров.
Компании, использующие ML, должны учитывать эти аспекты и внедрять подходы explainable AI, а также привлекать экспертов по этике и юристов на этапе проектирования систем.
Заключение
Машинное обучение перестало быть уделом узкого круга исследователей и стало неотъемлемой частью современного технологического ландшафта. От рекомендаций в социальных сетях до автономных автомобилей — ML-модели формируют мир вокруг нас. Подведем итоги:
- Модель машинного обучения — это алгоритм, который учится на данных. Она анализирует примеры и делает прогнозы на новых входных данных.
- Существуют разные типы обучения: с учителем, без учителя, с подкреплением и полуобучение. Каждый применяется для решения своих задач.
- Ключевые алгоритмы включают линейную регрессию, деревья решений, KNN, SVM, нейросети и ансамбли. У каждого — свои плюсы и ограничения.
- Модели применяются в медицине, финансах, ритейле, безопасности и повседневной жизни. Мы сталкиваемся с ними ежедневно — даже не замечая.
- Войти в профессию можно через Python, курсы, pet-проекты и соревнования. Главное — практика и понимание основ.
Если вы только начинаете осваивать профессию в сфере машинного обучения, рекомендуем обратить внимание на подборку курсов по системной аналитике. В них есть как теоретическая база, так и практические задания — от простых моделей до работы с реальными данными.
Рекомендуем посмотреть курсы по системной аналитике
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Аналитик данных
|
Академия Эдюсон
122 отзыва
|
Цена
109 900 ₽
|
От
9 158 ₽/мес
Беспроцентная. На 1 год.
|
Длительность
6 месяцев
|
Старт
9 июня
|
|
|
Системный аналитик PRO
|
Нетология
47 отзывов
|
Цена
79 800 ₽
140 000 ₽
с промокодом kursy-online
|
От
3 500 ₽/мес
Рассрочка на 2 года.
|
Длительность
10 месяцев
|
Старт
13 июня
|
|
|
Системный аналитик с нуля
|
Stepik
33 отзыва
|
Цена
4 500 ₽
|
|
Длительность
1 неделя
|
Старт
в любое время
|
Подробнее |
|
Системный аналитик с нуля до PRO
|
Академия Эдюсон
122 отзыва
|
Цена
129 900 ₽
257 760 ₽
Ещё -10% по промокоду
|
От
5 412 ₽/мес
10 740 ₽/мес
|
Длительность
6 месяцев
|
Старт
в любое время
|

Product Analyst с нуля: почему SQL и метрики могут быть выгоднее «общего курса аналитика»
Product Analyst с нуля — это не только про SQL и красивые графики. Разбираемся, какие навыки действительно нужны на старте, чем продуктовая аналитика отличается от общего анализа данных и как выбрать обучение без лишних модулей.

Customer Success Manager после курсов: кому подойдет переход из продаж, поддержки или аккаунтинга
Курсы Customer Success Manager помогают перейти в CSM осознанно: понять SaaS-логику, разобраться в onboarding, retention и health score, а затем упаковать прошлый опыт для работодателя. Как понять, подходит ли вам эта роль и какие навыки нужно добрать в первую очередь?
FinOps-специалист: новая роль для тех, кто умеет экономить деньги на облаках и IT-инфраструктуре
FinOps-специалист помогает компаниям разобраться, куда уходят деньги на облака, Kubernetes, SaaS и IT-инфраструктуру. Как устроена эта роль, какие навыки нужны и с чего начать путь в профессию — разбираем простым языком.

Самообучение или курс с наставником: какой формат реально доводит до результата
Самообучение или курс с наставником — что выбрать, если хочется не просто смотреть уроки, а дойти до результата? Разберём, как цель, дисциплина, практика и обратная связь влияют на обучение.