Как улучшить производительность SQL-запросов: советы и ловушки
Если вы устали смотреть на «вечный» статус выполнения SQL-запроса, а план выполнения вызывает ступор — эта статья для вас.

Мы собрали реальные советы и примеры, как ускорить выборки, наладить кэш, правильно использовать индексы и не наступать на типовые грабли. Подходит как для новичков, так и для тех, кто уже не первый год дружит с SQL, но всё ещё иногда воюет с производительностью.
- Что такое производительность SQL-запросов?
- Основные инструменты для анализа SQL-запросов
- Как анализировать план выполнения SQL-запросов
- Практические рекомендации по оптимизации SQL-запросов
- Оптимизация индексов для повышения производительности
- Кэширование данных как способ оптимизации
- Типичные ошибки и проблемы в SQL-запросах
- Частые ошибки и их исправление
- Советы по поддержанию высокой производительности баз данных
- Заключение
- Рекомендуем посмотреть курсы по SQL
Что такое производительность SQL-запросов?
Представьте, что ваша база данных — это библиотека, а SQL-запрос — библиотекарь, которого вы отправили на поиски нужной книги. Производительность запроса — это то, насколько быстро и эффективно этот «библиотекарь» справляется со своей задачей. И поверьте моему опыту, разница между хорошим и плохим «библиотекарем» может быть как между Гермионой Грейнджер и троллем из подземелья (и я сейчас не о том тролле, который правит код по пятницам).
Ключевые метрики производительности
| Метрика | Что это и почему важно | На что влияет |
| Время выполнения | Время от отправки запроса до получения результата (тот самый промежуток между «запустил» и «пойду пока кофе попью») | Отзывчивость приложения и терпение пользователей |
| Использование CPU | Насколько сильно ваш запрос заставляет процессор «потеть» | Общая производительность сервера и количество одновременно обрабатываемых запросов |
| Потребление памяти | Объем оперативной памяти, который «съедает» ваш запрос (иногда с аппетитом, достойным студента в столовой) | Стабильность работы сервера и возможность обработки других запросов |
| I/O операции | Количество обращений к диску (чем больше, тем печальнее для производительности) | Скорость выполнения запроса и нагрузка на дисковую подсистему |
| Количество обработанных строк | Сколько записей пришлось «перелопатить» для получения результата | Время выполнения и нагрузка на все компоненты системы |
Горизонтальная диаграмма показывает пять ключевых метрик, влияющих на производительность SQL-запросов: время выполнения, использование CPU, потребление памяти, I/O-операции и количество обработанных строк. Метрики упорядочены по степени их влияния — от наиболее критичной (время выполнения) до менее значимой.
Факторы, влияющие на производительность
А теперь о том, что может превратить ваш запрос из гоночного болида в старую телегу (и наоборот):
- Структура запроса — да-да, тот самый момент, когда «работает — не трогай» может стоить вам нервных клеток и серверных ресурсов.
- Индексы — волшебные структуры данных, которые могут как ускорить поиск в тысячи раз, так и замедлить вставку данных до «давайте-ка-я-пока-посплю».
- Статистика данных — то, насколько актуальная у оптимизатора информация о ваших данных (представьте библиотекаря с устаревшим каталогом — весело, правда?).
- Параметризация — использование параметров вместо хардкода, что может как спасти ситуацию, так и создать новые проблемы (привет, parameter sniffing!).
- Фрагментация — состояние ваших индексов и данных (порядок vs хаос, только в мире баз данных).
Понимание этих метрик и факторов — первый шаг к оптимизации. И поверьте, иногда достаточно небольших изменений, чтобы превратить запрос-тормоз в запрос-молнию. Хотя чаще всего придется попотеть — но об этом в следующих разделах.
Основные инструменты для анализа SQL-запросов
Знаете, что общего между детективом и оптимизатором SQL-запросов? Оба нуждаются в правильных инструментах для расследования. И если Шерлоку Холмсу хватало лупы и трубки, то нам придется вооружиться чем-то посерьезнее.
Встроенные инструменты: ваш базовый арсенал
План выполнения запросов
Это как рентгеновский снимок вашего запроса — показывает всё, что происходит внутри (и иногда заставляет вздрогнуть от увиденного). В SQL Server Management Studio это та самая кнопка с иконкой плана выполнения, которую вы, возможно, случайно нажимали, думая, что это кнопка запуска.
EXPLAIN/EXPLAIN ANALYZE
Представьте, что это ваш личный консультант, который подробно рассказывает, почему запрос работает именно так, а не иначе. Правда, иногда его объяснения напоминают инструкцию к сборке шкафа из IKEA — вроде все понятно, но что-то не сходится.
Профессиональные инструменты анализа
| Инструмент | Функционал | Поддерживаемые СУБД | Особенности |
| SQL Server Management Studio | План выполнения, статистика, профилировщик | SQL Server | Бесплатный, но только для Windows (как неожиданно!) |
| Azure Data Studio | Мониторинг, планы выполнения, интеграция с облаком | SQL Server, PostgreSQL | Кроссплатформенный, современный интерфейс |
| DBeaver | Универсальный анализ, визуализация планов | Практически все | Швейцарский нож мира БД |
| DataGrip | Умный редактор, профилирование | Все популярные СУБД | Платный, но стоит каждого потраченного рубля |
Специализированные решения для мониторинга
- New Relic: Следит за вашими запросами как ревнивая жена за перепиской мужа. Знает всё о времени выполнения, использовании ресурсов и даже может предупредить, когда что-то идет не так.
- Datadog: Как фитнес-трекер для ваших баз данных. Собирает метрики, строит красивые графики и иногда заставляет задуматься о «диете» для ваших запросов.
- SolarWinds Database Performance Analyzer: Для тех случаев, когда нужно копнуть действительно глубоко. Анализирует все аспекты производительности и выдаёт рекомендации (правда, иногда настолько очевидные, что становится неловко).
Бесплатные, но полезные утилиты
- sp_whoisactive: Покажет, кто сейчас «мучает» вашу базу данных
- SQL Server First Responder Kit: Набор скриптов для диагностики (как аптечка первой помощи, только для баз данных)
- Extended Events: Встроенный механизм для отслеживания всего и вся (если вы готовы потратить время на его настройку)
Помните: самый лучший инструмент — тот, которым вы умеете пользоваться. И да, наличие дорогого инструмента не гарантирует, что ваши запросы внезапно станут быстрее — примерно как покупка профессиональной беговой обуви не сделает из вас Усэйна Болта.
Как анализировать план выполнения SQL-запросов
Знаете, план выполнения SQL-запроса похож на детективный роман — с той разницей, что здесь преступником часто оказывается наш собственный код. И как хороший детектив, мы должны уметь читать улики. Давайте разберем основные элементы этого триллера под названием «План выполнения запроса».
Ключевые операции в плане выполнения
- Index Scan (Сканирование индекса) — когда база данных читает весь индекс, как студент, который листает учебник в поисках нужной темы перед экзаменом. Часто признак того, что что-то пошло не так.
- Index Seek (Поиск по индексу) — прямое обращение к нужным данным. Как GPS-навигатор, который сразу ведет вас к цели. Обычно это то, что мы хотим видеть в плане.
- Table Scan (Полное сканирование таблицы) — когда база читает всю таблицу целиком. Примерно как искать иголку в стоге сена, методично перебирая каждую соломинку. Спойлер: обычно это плохой знак.
Предупреждения, которые нельзя игнорировать
| Предупреждение | Что это значит | Почему вам должно быть не всё равно |
| High Memory Grant | База просит слишком много памяти | Ваш запрос — настоящий обжора ресурсов |
| Missing Index | Отсутствует полезный индекс | Как ездить на машине без навигатора |
| Implicit Conversion | Неявное преобразование типов | SQL выполняет лишнюю работу из-за несовместимости типов |
| Parameter Sniffing | Проблемы с параметризацией | План выполнения оптимизирован под одни данные, а используется для других |
Как обнаружить узкие места
- Операции с высокой стоимостью
- Ищите операции, которые «съедают» больше 20% стоимости запроса
- Обращайте внимание на неожиданно дорогие простые операции
- Предупреждающие значки
- Желтый восклицательный знак — предупреждение
- Красный крест — серьезная проблема
- Зеленые значки с подсказками — рекомендации по оптимизации (да, иногда SQL Server бывает добрым)
- Анализ потока данных
- Толстые стрелки между операциями — признак большого объема обрабатываемых данных
- Несоответствие ожидаемого и фактического числа строк — намек на устаревшую статистику
Типичные «больные места» и их лечение
- Sort (Сортировка): Если занимает более 30% стоимости запроса, пора задуматься об индексе
- Hash Match: Может указывать на неоптимальное соединение таблиц
- Nested Loops с большим количеством итераций: Возможно, стоит пересмотреть структуру запроса
Помните: анализ плана выполнения — это искусство, а не наука. Иногда приходится экспериментировать, чтобы найти оптимальное решение. И да, бывает, что план выполнения выглядит как карта сокровищ, нарисованная пьяным пиратом — но это нормально, мы все через это проходим.
Практические рекомендации по оптимизации SQL-запросов
Знаете, что общего между оптимизацией SQL-запросов и кулинарией? В обоих случаях результат зависит не только от ингредиентов, но и от того, как вы их смешиваете. Давайте разберем основные рецепты оптимизации для разных типов запросов — и да, некоторые из них настолько очевидны, что вы удивитесь, почему не использовали их раньше.
SELECT-запросы: искусство точности
Основные правила
-- Плохо (как стрелять из пушки по воробьям) SELECT * FROM users; -- Хорошо (как использовать снайперскую винтовку) SELECT id, name, email FROM users WHERE active = 1;
- **Забудьте о SELECT ***:
- Это как заказать «всё меню» в ресторане — звучит круто, пока не придет счет (в нашем случае — счет ресурсов)
- Выбирайте только нужные столбцы — ваша память скажет спасибо
- WHERE-условия:
- Используйте максимально конкретные условия
- Помните: каждое условие — это фильтр, который может сократить объем обрабатываемых данных
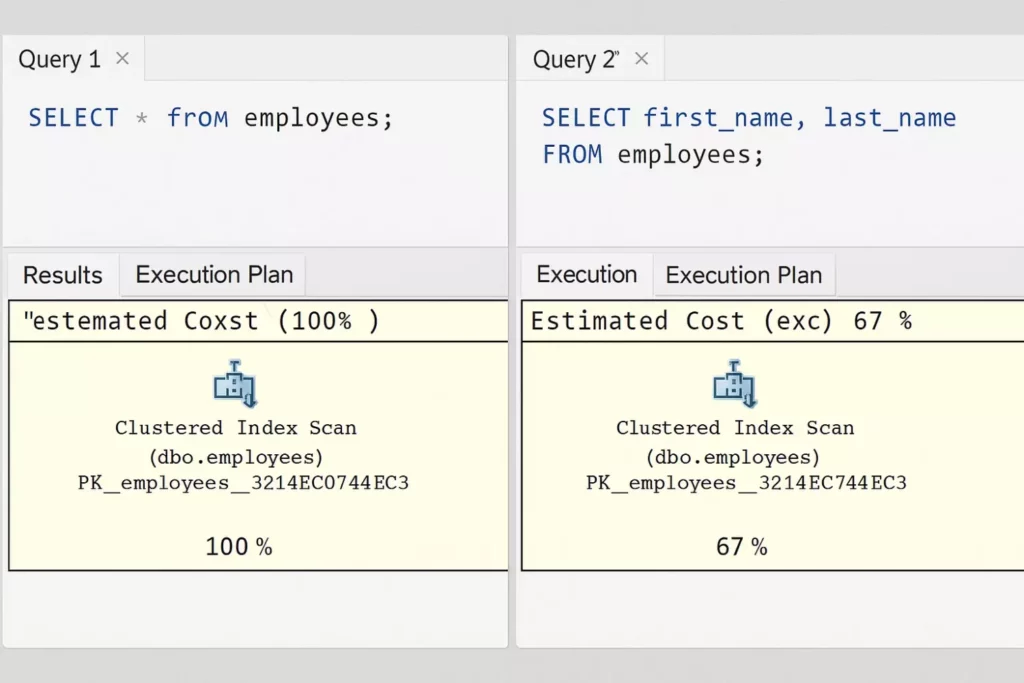
На изображении представлен интерфейс SQL Server Management Studio (SSMS), разделённый на две части. Слева — запрос SELECT * FROM employees;, под которым отображён план выполнения с полной стоимостью (100%). Справа — оптимизированный запрос SELECT first_name, last_name FROM employees; с планом выполнения, где стоимость снижается до 67%. В обоих случаях используется кластерное сканирование индекса, однако визуализация подчёркивает, как выбор конкретных столбцов снижает затраты на выполнение, что критично при работе с большими объёмами данных.
JOIN-запросы: танцы с таблицами
Оптимизация соединений
-- Неоптимально (как пригласить на вечеринку всех, кого знаешь) SELECT o.*, c.* FROM orders o LEFT JOIN customers c ON o.customer_id = c.id;-- Оптимально (как пригласить только тех, кто действительно придет) SELECT o.order_id, o.total, c.name FROM orders o INNER JOIN customers c ON o.customer_id = c.id WHERE o.status = 'active';
Правила хорошего тона:
- Порядок соединения таблиц:
- Начинайте с таблицы, которая вернет меньше строк
- Используйте правильный тип JOIN (INNER вместо LEFT, где возможно)
- Индексы для JOIN:
- Создавайте индексы на столбцах соединения
- Следите за порядком столбцов в составных индексах
INSERT, UPDATE и DELETE: операции с осторожностью
Пакетная обработка
-- Медленно (как отправлять письма по одному)
INSERT INTO logs (message) VALUES ('log1');
INSERT INTO logs (message) VALUES ('log2');-- Быстро (как использовать массовую рассылку)
INSERT INTO logs (message) VALUES
('log1'),
('log2'),
('log3');
Таблица рекомендаций
| Тип запроса | Основные советы | Подводные камни |
| SELECT | Конкретные столбцы, эффективные WHERE | Избегайте функций в WHERE |
| JOIN | Правильный порядок и тип соединений | Следите за кардинальностью |
| INSERT | Используйте пакетную вставку | Учитывайте размер транзакции |
| UPDATE | Обновляйте только нужные столбцы | Проверяйте индексы |
| DELETE | Используйте пакетное удаление | Следите за блокировками |
Бонусные советы (которые почему-то часто забывают):
- Используйте транзакции с умом:
Слишком маленькие — накладные расходы
Слишком большие — блокировки и проблемы с откатом
- SET NOCOUNT ON:
Уменьшает сетевой трафик
Особенно полезно в хранимых процедурах
- Избегайте курсоров:
Используйте SET-based подход
Если без курсора никак, оптимизируйте его настройки
Помните: оптимизация — это не одноразовая акция, а постоянный процесс. Как говорил мой первый руководитель: «Запрос работает быстро не потому, что он быстрый, а потому, что его правильно написали». Мудрый был человек, хотя его запросы иногда тоже приходилось оптимизировать.
Оптимизация индексов для повышения производительности
Давайте поговорим об индексах — этих невоспетых героях мира баз данных. Знаете, что общего между индексами в базе данных и оглавлением в книге? Оба помогают быстро найти нужную информацию, но если их слишком много — книга становится толще, чем полезнее.
Типы индексов: выбираем оружие
B-Tree индексы
- Классика жанра, как джинсы и белая футболка — подходит почти для всего
- Отлично работают для поиска по диапазонам и точным значениям
- Поддерживают сортировку (в отличие от вашего рабочего стола)
Hash индексы
- Супербыстрые для точного поиска
- Бесполезны для поиска по диапазону (как GPS, который знает только конечную точку)
- Занимают меньше места, чем B-Tree
Full-text индексы
- Для поиска в текстовых полях
- Позволяют искать «как в Google» (ну, почти)
- Съедают много места, но оно того стоит
Когда создавать индексы
-- Когда запрос выглядит так - пора задуматься об индексе SELECT * FROM products WHERE category_id = 5 AND price > 1000 ORDER BY name;-- Создаем индекс (и молимся, чтобы не было побочных эффектов) CREATE INDEX idx_products_cat_price ON products(category_id, price, name);
Признаки того, что индекс нужен:
- Частые запросы по определенным столбцам
- Много операций WHERE и JOIN
- Сортировка больших наборов данных
- План выполнения намекает (а иногда и прямо кричит)
Подводные камни индексов
| Ситуация | Почему это проблема | Решение |
| Слишком много индексов | Замедляют INSERT/UPDATE/DELETE | Удалить неиспользуемые |
| Фрагментация | Снижает эффективность | Регулярная дефрагментация |
| Неправильный порядок столбцов | Индекс не используется | Пересмотреть структуру |
| Избыточные индексы | Впустую тратят ресурсы | Объединить похожие индексы |
Преимущества правильных индексов:
- Ускорение поиска в разы (иногда в сотни раз)
- Снижение нагрузки на сервер
- Счастливые пользователи и еще более счастливый DBA
Когда НЕ стоит создавать индексы:
- На маленьких таблицах (это как ставить навигатор для поездки в соседний дом)
- На часто обновляемых столбцах
- Когда выборка возвращает >20% данных таблицы
- На столбцах с низкой селективностью
Бонусный совет:
Помните об автоматическом обслуживании индексов. Это как регулярное ТО для машины — никто не любит этим заниматься, но без этого всё рано или поздно развалится.
-- Проверка фрагментации (когда становится интересно, почему всё так медленно)
SELECT a.index_id, name, avg_fragmentation_in_percent
FROM sys.dm_db_index_physical_stats
(DB_ID(), OBJECT_ID('YourTable'), NULL, NULL, NULL) AS a
JOIN sys.indexes AS b
ON a.object_id = b.object_id AND a.index_id = b.index_id;
Кэширование данных как способ оптимизации
Знаете, что общего между кэшированием и заначкой в холодильнике? Оба способа позволяют быстро получить то, что нам нужно, без лишних телодвижений. Давайте разберемся, как правильно организовать такую «заначку» для наших данных.
Виды кэширования в мире SQL
Кэширование на уровне БД
-- Просмотр состояния кэша в SQL Server
SELECT * FROM sys.dm_os_buffer_descriptors
WHERE database_id = DB_ID('YourDatabase');-- Очистка кэша (когда всё совсем плохо)
DBCC DROPCLEANBUFFERS;
Кэширование на уровне приложения
// Redis пример (потому что кто же сейчас не использует Redis?)
const Redis = require('redis');
const client = Redis.createClient();async function getCachedData(key) {
const cached = await client.get(key);
if (cached) {
return JSON.parse(cached); // Ура, данные в кэше!
}const data = await executeExpensiveQuery();
await client.set(key, JSON.stringify(data), 'EX', 3600); // Кэшируем на час
return data;
}
Стратегии кэширования
| Стратегия | Когда использовать | Подводные камни |
| Write-through | Данные редко меняются | Медленная запись |
| Write-behind | Высокая нагрузка на запись | Риск потери данных |
| Cache-aside | Чтение важнее записи | Проблемы согласованности |
Популярные решения для кэширования
- Redis
- Быстрый как Флэш из комиксов
- Поддерживает сложные структуры данных
- Может работать как очередь сообщений (бонус!)
# Python пример с Redis
import redis
r = redis.Redis()def get_user_data(user_id):
cache_key = f"user:{user_id}"# Пытаемся найти в кэше
if r.exists(cache_key):
return r.hgetall(cache_key)# Если нет в кэше, идем в БД
user = db.query("SELECT * FROM users WHERE id = %s", user_id)
r.hmset(cache_key, user)
r.expire(cache_key, 3600) # Час живет, потом умирает
return user
- Memcached
- Проще, чем Redis (как велосипед против мотоцикла)
- Отлично масштабируется
- Только строки и числа (никаких излишеств!)
- Кэш запросов SQL Server
- Встроенный и бесплатный (редкое сочетание в мире Microsoft)
- Автоматически управляется сервером
- Иногда слишком умный для своего же блага
Советы по реализации кэширования
- Определите TTL (Time To Live)
- Слишком короткий — частые обращения к БД
- Слишком длинный — риск устаревших данных
- Золотая середина — зависит от бизнес-требований
- Мониторинг кэша
-- Проверка hit ratio в SQL Server SELECT (a.cntr_value * 1.0 / b.cntr_value) * 100.0 as cache_hit_ratio FROM sys.dm_os_performance_counters a JOIN sys.dm_os_performance_counters b ON a.object_name = b.object_name WHERE a.counter_name = 'Buffer cache hit ratio' AND b.counter_name = 'Buffer cache hit ratio base'
- Инвалидация кэша
- Определите стратегию очистки
- Используйте паттерны типа «Cache-aside»
- Не забывайте о версионировании кэша
Помните: кэширование — это не серебряная пуля. Иногда оно может создать больше проблем, чем решить. Как говорил один мудрый DBA: «Есть только две сложные вещи в Computer Science: инвалидация кэша и названия переменных». И он был чертовски прав!
Типичные ошибки и проблемы в SQL-запросах
Знаете, что общего между SQL-запросами и отношениями? В обоих случаях маленькие ошибки могут привести к большим проблемам. Давайте разберем самые «популярные» грабли, на которые наступают даже опытные разработчики (да-да, я тоже на них наступал).
Самые «любимые» антипаттерны
- Неявные преобразования типов
-- Плохо (заставляем SQL Server гадать) WHERE phone_number = 12345 -- phone_number это varchar-- Хорошо (явно указываем, что имеем в виду) WHERE phone_number = '12345'
Когда вы заставляете SQL Server преобразовывать типы данных, это как просить переводчика работать в режиме реального времени — вроде работает, но медленно и с потенциальными ошибками.
- Избыточные подзапросы
-- Плохо (запрос в стиле "матрёшка") SELECT * FROM orders WHERE customer_id IN ( SELECT customer_id FROM customers WHERE region_id IN ( SELECT id FROM regions WHERE country = 'USA' ) )-- Хорошо (JOIN как цивилизованные люди) SELECT DISTINCT o.* FROM orders o JOIN customers c ON o.customer_id = c.customer_id JOIN regions r ON c.region_id = r.id WHERE r.country = 'USA'
- Оператор IN с большим списком
-- Очень плохо (когда IN превращается в "ОЧЕНЬ-ОЧЕНЬ IN") WHERE product_id IN (1,2,3,4,5,...,1000)-- Лучше (используем временную таблицу) CREATE TABLE #temp_products (product_id int) INSERT INTO #temp_products VALUES (1),(2),(3),... ... WHERE product_id IN (SELECT product_id FROM #temp_products)
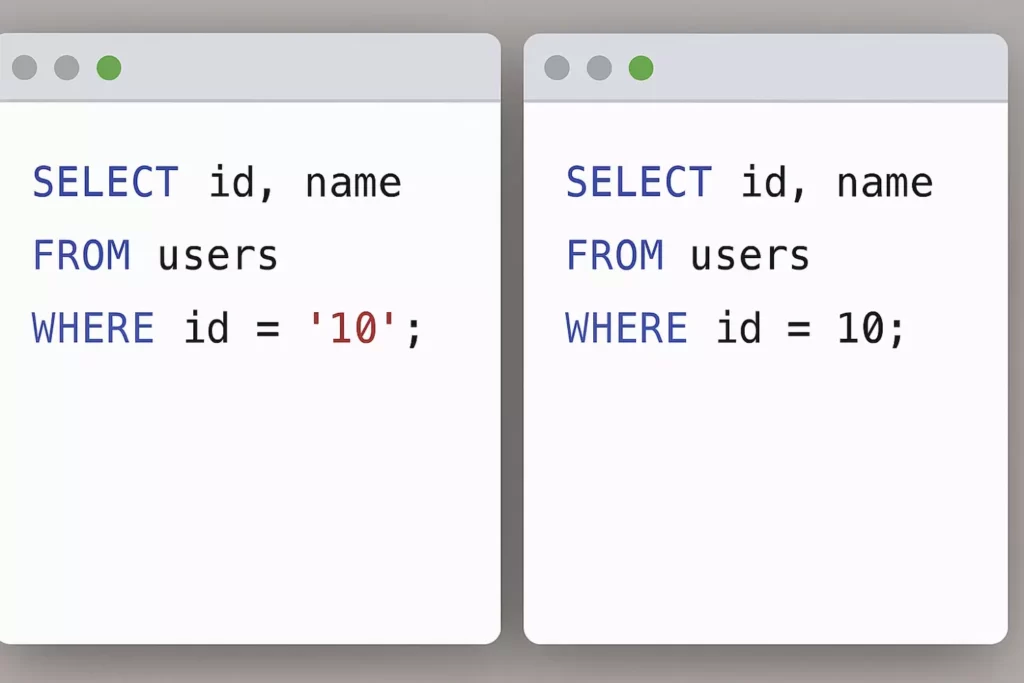
На изображении показаны два SQL-запроса, размещённые бок о бок в интерфейсе СУБД. Слева — пример с ошибкой: в условии WHERE id = ’10’ значение сравнивается как строка (varchar), что приводит к неявному преобразованию типа и снижению производительности. Справа — корректный вариант запроса: WHERE id = 10, где тип данных int используется явно.
Частые ошибки и их исправление
| Ошибка | Почему это плохо | Как исправить |
| SELECT * | Лишний трафик и нагрузка | Выбирать конкретные столбцы |
| LIKE ‘%text%’ | Не использует индексы | Искать альтернативные решения (full-text search) |
| SELECT DISTINCT | Часто признак плохого дизайна | Пересмотреть структуру запроса |
| Scalar functions в WHERE | Убивают производительность | Переписать на set-based логику |
Особый случай: параметры в хранимых процедурах
-- Опасно (parameter sniffing nightmare) CREATE PROCEDURE GetOrders @status varchar(20) AS SELECT * FROM orders WHERE status = @status-- Безопаснее CREATE PROCEDURE GetOrders @status varchar(20) AS DECLARE @local_status varchar(20) = @status SELECT * FROM orders WHERE status = @local_status
Бонусные советы:
- Используйте инструменты анализа
- План выполнения — ваш лучший друг
- Профилировщик — когда друг не помогает
- DMVs — когда всё совсем плохо
- Тестируйте на реальных данных
- Запрос, который летает на 100 строках, может умереть на 1 000 000
- Документируйте сложные запросы
- Ваше будущее «я» скажет вам спасибо
- Коллеги тоже будут благодарны (возможно)
Помните: оптимизация — это итеративный процесс. Иногда приходится выбирать между «работает медленно» и «работает неправильно». Выбирайте мудро!
Советы по поддержанию высокой производительности баз данных
Знаете, что общего между базой данных и автомобилем? Обоим требуется регулярное техническое обслуживание, чтобы избежать внезапных проблем в самый неподходящий момент. И если вы думаете, что сможете просто настроить всё один раз и забыть — позвольте мне разрушить эту прекрасную иллюзию.
Основные правила профилактики
- Регулярный мониторинг
-- Проверка самых "тяжелых" запросов (топ-10 любимчиков) SELECT TOP 10 qs.total_elapsed_time / qs.execution_count as avg_elapsed_time, qs.execution_count, SUBSTRING(qt.text,qs.statement_start_offset/2, (CASE WHEN qs.statement_end_offset = -1 THEN LEN(CONVERT(nvarchar(max), qt.text)) * 2 ELSE qs.statement_end_offset END - qs.statement_start_offset)/2) as query_text FROM sys.dm_exec_query_stats qs CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) qt ORDER BY avg_elapsed_time DESC;
- Логирование медленных запросов
- Настройте Extended Events или SQL Server Profiler
- Установите разумные пороги для «медленных» запросов
- Регулярно анализируйте логи (а не складывайте их в папочку «разберу потом»)
- Автоматизация обслуживания
-- Пример задачи обслуживания индексов
CREATE PROCEDURE MaintenanceTask
AS
BEGIN
-- Обновление статистики
EXEC sp_updatestats;-- Реорганизация фрагментированных индексов
-- (потому что фрагментация -- это не только про жесткий диск)
DECLARE @tableName nvarchar(255)
DECLARE tableCursor CURSOR FOR
SELECT OBJECT_NAME(object_id)
FROM sys.indexes
WHERE index_id > 0OPEN tableCursor
FETCH NEXT FROM tableCursor INTO @tableNameWHILE @@FETCH_STATUS = 0
BEGIN
EXEC('ALTER INDEX ALL ON ' + @tableName + ' REORGANIZE')
FETCH NEXT FROM tableCursor INTO @tableName
ENDCLOSE tableCursor
DEALLOCATE tableCursor
END
Чек-лист регулярных проверок
- Мониторинг использования ресурсов
- Анализ планов выполнения популярных запросов
- Проверка фрагментации индексов
- Обновление статистики
- Очистка устаревших данных
- Проверка настроек автоматического роста файлов
Помните: профилактика всегда дешевле лечения. Особенно когда речь идет о боевых системах, где простой может стоить… ну, вы понимаете.
Заключение
Знаете, что общего между оптимизацией SQL-запросов и боевыми искусствами? В обоих случаях нет предела совершенству, но каждое улучшение делает вас сильнее. После всего, что мы обсудили, давайте подведем итоги и посмотрим, как применить эти знания на практике.
Ключевые выводы
- Производительность — это не случайность
- Хорошие запросы не появляются сами собой
- Каждая оптимизация — это осознанное решение
- Иногда «достаточно хорошо» лучше, чем «идеально»
- Инструменты — ваши друзья
- План выполнения запроса — ваш главный советчик
- Мониторинг — ваша система раннего предупреждения
- Индексы — ваше секретное оружие (если использовать с умом)
- Профилактика лучше лечения
- Регулярное обслуживание базы данных
- Мониторинг производительности
- Своевременная оптимизация запросов
И помните: нет универсальных решений. Каждая база данных уникальна, как отпечаток пальца, и что работает в одном случае, может быть катастрофой в другом.
Знаете, что общего между изучением SQL и путешествием в горы? Чем выше поднимаешься, тем больше открывается новых вершин для покорения! Если вы прочитали эту статью и почувствовали вкус к оптимизации, возможно, вам захочется углубить свои знания. На KursHub собрана отличная подборка курсов по SQL для разных уровней подготовки — от новичков до продвинутых разработчиков. Там вы найдете структурированные программы обучения, которые помогут не только освоить основы, но и стать настоящим мастером SQL-оптимизации. А теперь, вооружившись новыми знаниями (и, возможно, желанием учиться дальше), давайте подведем итоги нашего путешествия в мир производительных запросов.
Рекомендуем посмотреть курсы по SQL
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
SQL с нуля для анализа данных
|
Eduson Academy
112 отзывов
|
Цена
49 900 ₽
|
От
4 158 ₽/мес
Беспроцентная. На 1 год.
|
Длительность
1 месяц
|
Старт
14 марта
|
Подробнее |
|
Продвинутый SQL
|
Нетология
46 отзывов
|
Цена
41 600 ₽
77 018 ₽
с промокодом kursy-online
|
От
2 567 ₽/мес
Рассрочка на 1 год.
|
Длительность
1 месяц
|
Старт
26 марта
2 раза в неделю по будням
|
Подробнее |
|
SQL-разработчик
|
Eduson Academy
112 отзывов
|
Цена
89 900 ₽
|
От
7 492 ₽/мес
0% на 12 месяцев
|
Длительность
6 месяцев
|
Старт
16 марта
|
Подробнее |

Яндекс Практикум vs Skillfactory: какой курс по Data Science выбрать
Skillfactory и Яндекс Практикум предлагают похожие курсы Data Science, но обучение на них устроено по-разному. Где больше практики, где сильнее менторская поддержка и на какой платформе проще собрать портфолио проектов? Разбираем реальные различия курсов, формат занятий и нагрузку.

Skillbox vs ProductStar: где продакт-трек более прикладной (кейсы, метрики, решения)
Skillbox или ProductStar — где на самом деле больше практики для продакт-менеджера? Разбираем формат кейсов, работу с метриками, стажировки и портфолио, чтобы понять, какой курс действительно готовит к работе product manager.

Skypro vs ProductStar: куда идти аналитику, чтобы стать продактом — траектория и кейсы
Если вы аналитик и хотите перейти в продакт-менеджмент, но не знаете, с чего начать, эта статья для вас. Мы расскажем, какие шаги и курсы помогут вам освоить нужные навыки, чтобы успешно перейти в продуктовую роль. Задайтесь вопросом: готовы ли вы на решение проблем, а не просто на анализ данных?

Собеседование Devops Junior и Middle: актуальные вопросы и темы 2026 года
Вопросы на собеседовании DevOps могут сильно различаться в зависимости от уровня кандидата. Какие навыки и знания проверяют у Junior и Middle в 2026 году? Мы расскажем, как подготовиться к собеседованию и что важно знать для успешного прохождения интервью.