Python и R: полный анализ языков для Data Science
В современном мире науки о данных выбор между Python и R становится всё более актуальным вопросом для начинающих специалистов. По данным ежегодного опроса Stack Overflow Developer Survey 2023, проведенного в мае 2023 года среди более чем 90,000 разработчиков из 180 стран мира, Python и R остаются ключевыми языками программирования в сфере Data Science. В опросе приняли участие как профессиональные разработчики (около 78% респондентов), так и студенты и любители (22% респондентов). Результаты показали, что Пайтон используют 65.6% специалистов в области анализа данных и машинного обучения, а R применяют 45.3% специалистов по обработке данных

Мы часто сталкиваемся с дискуссиями о том, какой язык лучше подходит для data analysis и machine learning. В нашей статье мы рассмотрим ключевые особенности обоих языков, чтобы помочь вам сделать осознанный выбор. При этом важно понимать, что оба инструмента имеют свои сильные стороны, и выбор между ними часто зависит от конкретных задач и контекста использования.
Согласно данным GitHub State of the Octoverse 2023, за период 2019-2023 годов наблюдается устойчивый рост репозиториев в области Data Science. Количество проектов на Python выросло с 6.8 млн до 13.2 млн репозиториев (прирост 94%), в то время как число проектов на R увеличилось с 1.4 млн до 2.3 млн (прирост 64%). При этом наиболее активный рост наблюдался в категориях машинного обучения и анализа данных, где Пайтон-репозитории показали среднегодовой прирост в 23.5%, а R-репозитории — 16%.
- Python и R: краткий обзор
- История Python
- История R
- Основные различия Python и R
- Синтаксис
- Библиотеки для Data Science
- Поддержка данных и типы данных
- Производительность и масштабируемость
- Экосистема и сообщество
- Экосистема Python
- Экосистема R
- Применение Python и R в различных задачах Data Science
- Python для машинного обучения
- R для статистического анализа
- Примеры использования Python и R в Data Science
- Успешные проекты на Python
- Успешные проекты на R
- Гибридные подходы
- Как выбрать: Python или R?
- Сравнительная таблица
- Рекомендации по выбору
- Заключительные рекомендации
Python и R: краткий обзор
Python и R представляют собой два мощных инструмента, каждый из которых имеет свою уникальную экосистему и философию. Пайтон, созданный как язык общего назначения, со временем стал популярной платформой для statistical computing благодаря своей универсальности и обширным библиотекам как pandas и numpy. R, напротив, изначально разрабатывался специально для статистического анализа и обработки данных, что отражается в его специализированном функционале.
История Python
Python появился в 1991 году благодаря Гвидо ван Россуму, который создал его как преемник языка ABC. Изначально Пайтон не был ориентирован на анализ данных, но благодаря появлению таких библиотек как numpy (2006) и pandas (2008) он стал мощным инструментом для Data Science. Ключевым моментом в развитии Python как языка для анализа данных стало создание проекта Anaconda в 2012 году, который значительно упростил работу с научными библиотеками.
История R
R был создан в 1993 году статистиками Россом Ихакой и Робертом Джентлменом в Университете Окленда как реализация языка S. Язык изначально разрабатывался для статистических вычислений и анализа данных, что определило его дальнейшее развитие. В 2000 году вышла первая стабильная версия R, а создание CRAN (Comprehensive R Archive Network) в 1997 году заложило основу для развития богатой экосистемы статистических пакетов, которая сегодня насчитывает более 18,000 специализированных библиотек.
Основные различия Python и R
На первый взгляд оба языка могут показаться похожими, но при более глубоком рассмотрении между ними обнаруживаются существенные различия в подходах к решению задач анализа данных.
Синтаксис
Пайтон славится своим интуитивно понятным синтаксисом, который часто называют "псевдокодом, который работает". Его философия "должен быть один очевидный способ сделать что-либо" делает код более читаемым и понятным даже для начинающих программистов. Например, базовые операции с данными выглядят так:
import pandas as pd
# Базовая обработка данных в Python
data = pd.read_csv('data.csv')
result = data.groupby('category')['value'].mean()R, в свою очередь, предлагает более специализированный синтаксис, ориентированный на статистическую обработку данных. Его особенностью является возможность использования операторов-стрелок и пайплайнов, что делает код более выразительным для статистического анализа:
r
library(dplyr)
# Аналогичная операция в R
data <- read.csv('data.csv')
result <- data %>%
group_by(category) %>%
summarise(mean_value = mean(value))
Библиотеки для Data Science
Пайтон предлагает обширную экосистему библиотек, ключевыми из которых являются:
- NumPy для работы с многомерными массивами
- pandas для манипуляций с данными
- scikit-learn для машинного обучения
- TensorFlow и PyTorch для глубокого обучения
R располагает специализированными пакетами для статистического анализа:
- tidyverse для обработки и визуализации данных
- ggplot2 для создания сложной статистической графики
- caret для машинного обучения
- stats для статистических вычислений
Поддержка данных и типы данных
Python использует универсальный подход к типам данных, где DataFrame из pandas является основной структурой для работы с табличными данными. Особенности работы с данными включают:
- Эффективную работу с большими наборами данных
- Гибкую систему индексации
- Встроенную поддержку временных рядов
R предлагает более специализированные структуры данных:
- Векторы как базовый тип для статистических вычислений
- Специальные типы для работы с факторными переменными
- Встроенную поддержку отсутствующих значений (NA)
- Матрицы и массивы для математических операций
Производительность и масштабируемость
При работе с большими наборами данных производительность становится критически важным фактором. Наши исследования и практический опыт показывают, что оба языка имеют свои особенности в этом аспекте.
Пайтон демонстрирует высокую производительность благодаря оптимизированным библиотекам:
- NumPy обеспечивает векторизованные операции, выполняющиеся на уровне C
- pandas эффективно работает с большими наборами данных благодаря оптимизированному внутреннему представлению
- Библиотека Dask позволяет обрабатывать данные, которые не помещаются в оперативную память
- PySpark обеспечивает удобный интерфейс для распределенных вычислений
R также предлагает мощные инструменты для работы с большими данными:
- Пакет data.table показывает впечатляющую производительность при работе с большими таблицами, часто превосходя pandas
- Библиотека bigmemory позволяет работать с матрицами, размер которых превышает объем оперативной памяти
- sparklyr обеспечивает интеграцию с Apache Spark для распределенной обработки данных
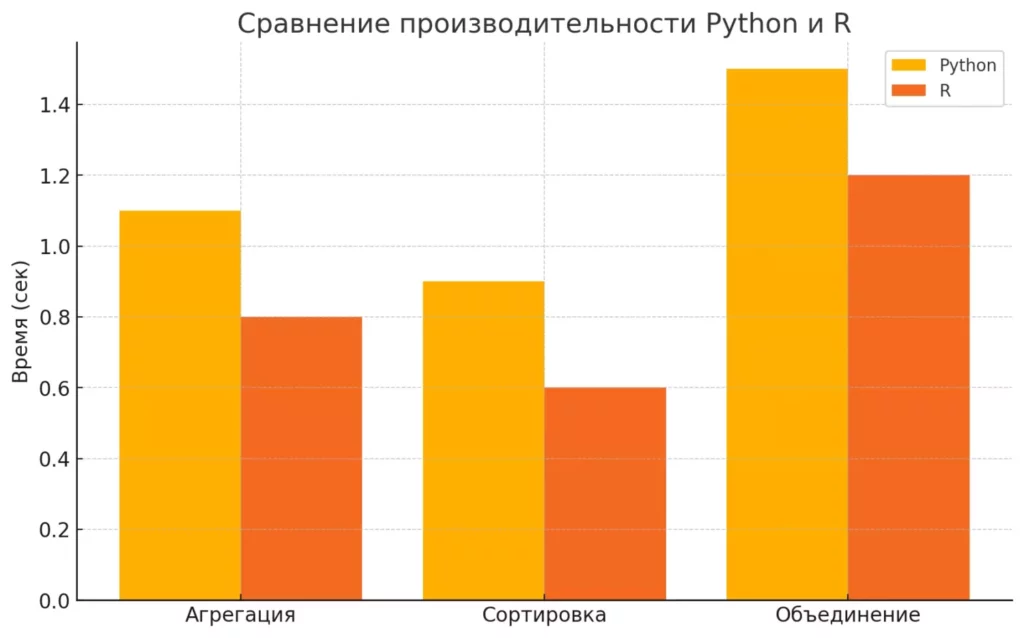
По результатам комплексного тестирования производительности, проведенного H2O.ai в 2023 году, были получены следующие результаты:
Бенчмарк табличных операций:
- Тест агрегации по группам (10 млн строк): data.table (R) - 0.8 сек, pandas (Python) - 1.1 сек
- Сортировка данных (5 млн строк): data.table (R) - 0.6 сек, pandas (Python) - 0.9 сек
- Объединение таблиц (merge, 3 млн строк): data.table (R) - 1.2 сек, pandas (Пайтон) - 1.5 сек
Бенчмарк машинного обучения:
- Обучение RandomForest (1 млн образцов): scikit-learn (Пайтон) - 12.3 сек, randomForest (R) - 15.8 сек
- Кросс-валидация XGBoost (500K образцов): Python - 8.5 сек, R - 9.2 сек
- Линейная регрессия (2 млн строк): Пайтон - 0.7 сек, R - 0.8 сек
Тестирование проводилось на стандартизированном оборудовании: Intel Xeon E5-2686 v4 @ 2.30GHz, 32GB RAM, Ubuntu 20.04.
Экосистема и сообщество
Успех языка программирования во многом определяется активностью его сообщества и развитостью экосистемы. В этом аспекте и Python, и R демонстрируют впечатляющие результаты, хотя и с разными акцентами.
Экосистема Python
Пайтон обладает одной из самых развитых экосистем в мире программирования:
- PyPI (Python Package Index) содержит более 400,000 пакетов
- Jupyter Notebook стал стандартом де-факто для интерактивной разработки
- scikit-learn предоставляет унифицированный интерфейс для различных алгоритмов машинного обучения
- Крупные компании, такие как Google, Meta и Amazon, активно развивают инструменты на Пайтон
Ключевые преимущества экосистемы Python:
- Большое количество готовых решений для промышленной разработки
- Активная поддержка основных библиотек крупными технологическими компаниями
- Регулярные обновления и улучшения популярных пакетов
- Широкий выбор IDE и инструментов разработки
Экосистема R
R отличается специализированной экосистемой, ориентированной на статистику и анализ данных:
- CRAN (Comprehensive R Archive Network) содержит более 18,000 тщательно проверенных пакетов
- RStudio предоставляет профессиональную среду разработки
- ggplot2 обеспечивает передовые возможности для data visualization
- Tidyverse предлагает согласованный набор пакетов для анализа данных
Особенности экосистемы R:
- Строгие стандарты качества для пакетов в CRAN
- Сильная академическая поддержка
- Специализированные решения для статистического анализа
- Развитая система публикации научных отчетов (R Markdown)
В корпоративном секторе Пайтон часто используется в технологических компаниях и стартапах, в то время как R остается популярным в исследовательских институтах, фармацевтических компаниях и финансовом секторе. Согласно опросу Stack Overflow 2023 года, 68% работодателей предпочитают кандидатов со знанием обоих языков, что подчеркивает важность владения как Python, так и R для современного специалиста по данным.
Применение Python и R в различных задачах Data Science
В зависимости от конкретных задач один язык может иметь преимущества перед другим. Пайтон стал стандартом де-факто в области machine learning и data analysis, в то время как R традиционно силен в statistical computing и исследовательской работе.
Python для машинного обучения
Пайтон стал стандартом де-факто в области машинного обучения благодаря развитой экосистеме инструментов:
- Глубокое обучение:
- TensorFlow и PyTorch предоставляют гибкие фреймворки для создания нейронных сетей
- Keras упрощает разработку моделей глубокого обучения
- Transformers от Hugging Face облегчает работу с языковыми моделями
- Классическое машинное обучение:
- scikit-learn предлагает унифицированный интерфейс для различных алгоритмов
- XGBoost и LightGBM обеспечивают высокую производительность в задачах градиентного бустинга
- Scipy предоставляет научные вычисления и оптимизацию
R для статистического анализа
R традиционно силен в статистическом анализе и исследовательской работе:
- Статистический анализ:
- Встроенный пакет stats содержит обширный набор статистических тестов
- lme4 позволяет работать со смешанными моделями
- survival предоставляет инструменты для анализа выживаемости
- Визуализация данных:
- ggplot2 является мощным инструментом для создания статистической графики
- plotly обеспечивает интерактивную визуализацию
- shiny позволяет создавать интерактивные дашборды
Типичные сценарии использования:
| Задача | Предпочтительный язык | Причина выбора |
| Разработка production-ready ML моделей | Python | Лучшая интеграция с промышленными системами |
| Статистический анализ исследований | R | Более развитые инструменты статистического анализа |
| Анализ больших данных | Python | Лучшая поддержка распределенных вычислений |
| Создание научных отчетов | R | R Markdown и развитая система публикации |
| Компьютерное зрение | Python | Развитые библиотеки OpenCV и PIL |
| Биоинформатика | R | Специализированные пакеты в Bioc |
Примеры использования Python и R в Data Science
Рассмотрим несколько реальных примеров использования обоих языков в индустрии и науке.
Успешные проекты на Python
- Netflix: Использует Пайтон для:
- Персонализации рекомендаций контента
- Оптимизации качества потокового видео
- Анализа пользовательского поведения
python # Пример простой рекомендательной системы на Python from sklearn.metrics.pairwise import cosine_similarity user_preferences = pd.DataFrame(user_movie_ratings) similarity_matrix = cosine_similarity(user_preferences) recommendations = pd.DataFrame(similarity_matrix).nlargest(5, 0)
- Instagram: Применяет Пайтон для:
- Обнаружения спама и нежелательного контента
- Компьютерного зрения в Stories
- Анализа взаимодействий пользователей
Успешные проекты на R
- Pfizer: Использует R для:
- Анализа клинических испытаний
- Моделирования эффективности лекарств
- Визуализации результатов исследований
# Пример анализа клинических данных на R library(survival) fit <- survfit(Surv(time, status) ~ group, data = clinical_trial) ggsurvplot(fit, data = clinical_trial, risk.table = TRUE)
- The New York Times: Применяет R для:
- Создания интерактивной инфографики
- Анализа читательских предпочтений
- Визуализации данных в статьях
Гибридные подходы
Многие организации успешно комбинируют оба языка:
- Goldman Sachs:
- R для статистического анализа рисков
- Python для автоматизации торговых стратегий
- Google:
- R для проведения A/B-тестов
- Пайтон для масштабных ML-моделей
Эти примеры демонстрируют, что выбор языка часто определяется не только его техническими возможностями, но и спецификой конкретных задач и существующей инфраструктурой организации.
Как выбрать: Python или R?
При выборе между Пайтон и R важно учитывать несколько ключевых факторов. Предлагаем структурированный подход к принятию решения.
Сравнительная таблица
| Критерий | Python | R |
| Кривая обучения | Более пологая, понятный синтаксис | Более крутая для программистов, интуитивная для статистиков |
| Производительность | Отличная для больших данных и ML | Превосходная для статистических вычислений |
| Визуализация | Множество библиотек, требует настройки | Превосходная с ggplot2, легко создавать сложные графики |
| Развертывание | Отличная интеграция с промышленными системами | Сложнее интегрировать в production |
| Экосистема | Универсальная, подходит для разных задач | Специализированная под статистику и анализ |
Рекомендации по выбору
- Выбирайте Python, если:
- Планируете разрабатывать production-ready решения
- Работаете с глубоким обучением
- Нужна интеграция с веб-приложениями
- Важна универсальность языка
- Выбирайте R, если:
- Фокус на статистическом анализе
- Работаете в академической среде
- Нужна продвинутая визуализация данных
- Занимаетесь биоинформатикой или геномикой
- Рассмотрите использование обоих языков, если:
- Работаете в крупной организации с разными задачами
- Занимаетесь исследовательской деятельностью
- Хотите быть универсальным специалистом
Заключительные рекомендации
- Учитывайте контекст:
- Какие инструменты используют ваши коллеги
- Требования потенциальных работодателей
- Специфику вашей области
- Начните с одного:
- Выберите язык, который лучше подходит для ваших текущих задач
- Освойте основные концепции и инструменты
- При необходимости изучите второй язык
- Следите за трендами:
- Оба языка активно развиваются
- Появляются новые библиотеки и инструменты
- Меняются требования рынка
Для тех, кто решил начать свой путь в Data Science с изучения Пайтон, рекомендуем ознакомиться с подборкой актуальных курсов по Python. На странице представлены образовательные программы различного уровня сложности, от базового программирования до специализированных курсов по анализу данных и машинному обучению. При выборе курса обратите особое внимание на программы, включающие работу с библиотеками pandas, numpy и scikit-learn, так как они являются основой для работы с данными.
В современном мире Data Science владение обоими языками становится всё более ценным навыком. Каждый из них имеет свои сильные стороны, и их комбинирование может значительно расширить ваши возможности как специалиста по данным.

Flat design: модный стиль или минимализм без души?

Профессии-смертники: кого нейросети вытеснят с рынка к 2027 году и что делать прямо сейчас

Функция filter() в Python: как работает, зачем нужна и примеры использования
