Scikit-learn — что это, зачем нужен и как начать работать
В мире машинного обучения существует множество инструментов, но лишь немногие из них могут похвастаться такой популярностью и универсальностью, как Scikit-learn. Эта Python-библиотека стала де-факто стандартом для решения классических задач машинного обучения — от простой классификации до сложных алгоритмов кластеризации.
Мы рассмотрим, что представляет собой Scikit-learn, почему она завоевала доверие разработчиков по всему миру и как начать работу с этим мощным инструментом. Независимо от того, делаете ли вы первые шаги в data science или ищете надежное решение для продакшн-проектов, понимание возможностей Scikit-learn открывает двери в увлекательный мир практического машинного обучения.
- Что такое scikit-learn и где применяется
- Преимущества и особенности scikit-learn
- Установка и подключение библиотеки
- Ключевые задачи, которые решает scikit-learn
- Работа с данными: предобработка и разбиение
- Примеры использования scikit-learn
- Как оценивать модели и подбирать параметры
- Где читать и учиться дальше
- Заключение
- Рекомендуем посмотреть курсы по Python
Что такое scikit-learn и где применяется
Scikit-learn представляет собой комплексную Python-библиотеку для машинного обучения с открытым исходным кодом, которая была создана в 2007 году в рамках программы Google Summer of Code. На сегодняшний день это один из наиболее зрелых и стабильных инструментов в экосистеме Python для решения задач машинного обучения.
Библиотека специализируется на классических алгоритмах машинного обучения и предоставляет единообразный API для работы с различными типами моделей. В отличие от фреймворков глубокого обучения, таких как TensorFlow или PyTorch, Scikit-learn сосредоточена на традиционных методах ML, которые остаются актуальными и эффективными для множества практических задач.
Сферы применения Scikit-learn охватывают практически все области, где требуется анализ данных:
- Финансовые технологии — скоринг клиентов, детекция мошенничества, алгоритмическая торговля.
- Электронная коммерция — рекомендательные системы, сегментация клиентов, прогнозирование спроса.
- Медицина и биоинформатика — диагностика заболеваний, анализ геномных данных.
- Маркетинг и аналитика — A/B тестирование, анализ настроений, персонализация контента.
- Промышленность — предиктивное обслуживание, контроль качества, оптимизация процессов.
Преимущества и особенности scikit-learn
Популярность Scikit-learn среди ML-разработчиков не случайна — библиотека обладает рядом ключевых преимуществ, которые делают её предпочтительным выбором для множества проектов.
Главная сила Scikit-learn заключается в её продуманной архитектуре и консистентном API. Все алгоритмы в библиотеке следуют единому паттерну: метод fit() для обучения модели и predict() для получения прогнозов. Такая унификация позволяет легко экспериментировать с различными алгоритмами, не изучая каждый раз новый интерфейс.
Особого внимания заслуживает бесшовная интеграция с экосистемой научных вычислений Python. Библиотека изначально проектировалась для работы с NumPy массивами, что обеспечивает высокую производительность, а совместимость с Pandas DataFrame упрощает предобработку данных. Интеграция с Matplotlib позволяет быстро визуализировать результаты, что критически важно для анализа и отладки моделей.
| Преимущество | Что это даёт |
|---|---|
| Единообразный API | Быстрое переключение между алгоритмами без изучения новых интерфейсов |
| Comprehensive toolkit | Полный цикл ML: от предобработки до оценки качества моделей |
| Производительность | Оптимизированные алгоритмы на C/Cythonдля критически важных операций |
| Подробная документация | Снижение порога входа и ускорение разработки |
| Активное сообщество | Регулярные обновления, исправления багов, новые возможности |
| Open source | Прозрачность кода и возможность использования в коммерческих проектах |
Важно отметить, что Scikit-learn придерживается принципа «batteries included» — в одной библиотеке вы найдёте инструменты для всего жизненного цикла машинного обучения: от загрузки и предобработки данных до обучения моделей и оценки их качества. Это избавляет от необходимости собирать инструментарий из разрозненных библиотек и обеспечивает совместимость компонентов.
Установка и подключение библиотеки
Процесс установки Scikit-learn достаточно прост, однако существует несколько способов, каждый из которых имеет свои особенности. Мы рассмотрим наиболее распространённые подходы для различных сценариев разработки.
Стандартная установка через pip является самым быстрым способом получить актуальную версию библиотеки:
pip install scikit-learn
Для тех, кто предпочитает conda (особенно при работе с Anaconda или Miniconda), альтернативный способ:
conda install scikit-learn
При установке через conda автоматически разрешаются зависимости от оптимизированных математических библиотек, что может обеспечить лучшую производительность на некоторых системах.
Scikit-learn имеет несколько обязательных зависимостей, которые обычно устанавливаются автоматически: NumPy (≥1.17.3), SciPy (≥1.3.2) и joblib (≥0.11). Для полноценной работы рекомендуется также установить Pandas для удобной работы с данными и Matplotlib для визуализации:
pip install pandas matplotlib
После установки подключение библиотеки в проект выглядит стандартно:
import sklearn from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.ensemble import RandomForestClassifier
Стоит отметить, что Scikit-learn поддерживает Python версий 3.8 и выше. Команда разработчиков следует политике поддержки версий Python в соответствии с официальным графиком жизненного цикла языка, что гарантирует актуальность и безопасность используемых возможностей.
Для разработчиков, работающих в облачных средах типа Google Colab или Jupyter Hub, библиотека обычно предустановлена, что позволяет сразу приступить к экспериментам без дополнительной настройки окружения.
Ключевые задачи, которые решает scikit-learn
Scikit-learn покрывает практически весь спектр задач классического машинного обучения, предоставляя разработчикам мощный и универсальный инструментарий. Мы можем разделить эти задачи на несколько основных категорий, каждая из которых требует своего подхода и методов решения.
Библиотека традиционно делит алгоритмы машинного обучения на две большие группы: обучение с учителем (supervised learning) и обучение без учителя (unsupervised learning). Первая категория работает с размеченными данными, где для каждого примера известен правильный ответ, вторая — ищет скрытые закономерности в данных без предварительной разметки.
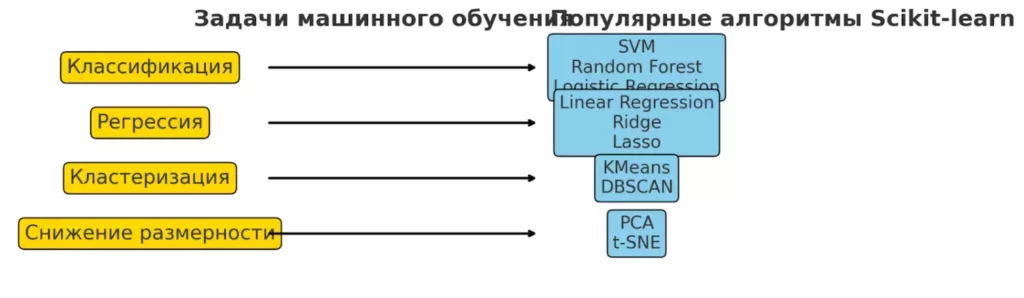
Схема показывает основные задачи машинного обучения и наиболее популярные алгоритмы Scikit-learn для каждой из них. Это поможет быстро сориентироваться, какой подход использовать под конкретную задачу.
Классификация
Задачи классификации направлены на предсказание категории или класса для новых объектов. Scikit-learn предлагает широкий выбор алгоритмов: от простой логистической регрессии до сложных ансамблевых методов.
Support Vector Machines (SVM) отлично справляется с задачами высокой размерности и нелинейными границами классов. Логистическая регрессия остаётся популярным выбором благодаря интерпретируемости результатов. Случайный лес (Random Forest) демонстрирует высокую точность на разнообразных датасетах и устойчивость к переобучению.
Регрессия
Регрессионные алгоритмы предсказывают непрерывные числовые значения. Линейная регрессия служит базовым методом для понимания зависимостей между переменными. Ridge регрессия добавляет регуляризацию для борьбы с переобучением, а Lasso дополнительно выполняет отбор признаков, обнуляя коэффициенты менее значимых переменных.
Кластеризация
Методы кластеризации группируют похожие объекты без использования меток классов. K-Means эффективно разделяет данные на заранее заданное количество кластеров сферической формы. DBSCAN способен находить кластеры произвольной формы и автоматически определять выбросы в данных.
Снижение размерности
Алгоритмы снижения размерности помогают визуализировать многомерные данные и устранить избыточность признаков. Principal Component Analysis (PCA) находит главные компоненты, объясняющие максимальную дисперсию в данных. t-SNE специализируется на создании двумерных представлений для визуализации сложных структур данных.
График демонстрирует, как метод главных компонент (PCA) переводит многомерные данные в двумерное пространство для визуализации и дальнейшего анализа. Это облегчает выявление скрытых закономерностей и структур в данных.
Подбор гиперпараметров
GridSearchCV выполняет исчерпывающий поиск оптимальных параметров в заданной сетке значений. RandomizedSearchCV предлагает более эффективную альтернативу для больших пространств параметров, случайно сэмплируя комбинации для тестирования.
Работа с данными: предобработка и разбиение
Качественная предобработка данных зачастую определяет успех всего проекта машинного обучения. Scikit-learn предоставляет комплексный набор инструментов для подготовки данных, который охватывает большинство типичных задач, с которыми сталкиваются практики.
Большинство алгоритмов машинного обучения чувствительны к масштабу признаков — переменные с большими значениями могут доминировать над переменными с меньшими значениями, искажая результаты обучения. Scikit-learn решает эту проблему несколькими способами масштабирования.
Категориальные переменные требуют специального подхода, поскольку алгоритмы машинного обучения работают исключительно с числовыми данными. Правильное кодирование таких признаков критически важно для сохранения заложенной в них информации.
| Метод | Назначение |
|---|---|
| StandardScaler | Приводит признаки к стандартному нормальному распределению (μ=0, σ=1) |
| MinMaxScaler | Масштабирует значения в диапазон [0, 1] или заданный интервал |
| OneHotEncoder | Преобразует категориальные переменные в бинарные признаки |
| LabelEncoder | Кодирует категории целыми числами (для целевой переменной) |
| train_test_split | Разделяет данные на обучающую и тестовую выборки |
Процесс масштабирования выглядит следующим образом:
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_scaled = scaler.fit_transform(X_train) X_test_scaled = scaler.transform(X_test)
Важно помнить, что параметры масштабирования должны вычисляться только на обучающей выборке, а затем применяться к тестовым данным — это предотвращает утечку информации из тестового набора.
Для работы с категориальными признаками используется One-Hot кодирование:
from sklearn.preprocessing import OneHotEncoder encoder = OneHotEncoder(sparse=False, drop='first') X_categorical_encoded = encoder.fit_transform(X_categorical)
Разделение данных на обучающую и тестовую выборки — базовая практика для честной оценки модели:
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42, stratify=y )
Параметр stratify обеспечивает пропорциональное представление классов в обеих выборках, что особенно важно для несбалансированных датасетов.
Примеры использования scikit-learn
Теоретические знания обретают смысл только при практическом применении. Мы рассмотрим три классических примера, которые демонстрируют возможности Scikit-learn для решения различных типов задач машинного обучения.
Классификация: определение вида ириса
Датасет ирисов Фишера считается «Hello World» машинного обучения. Эта задача классификации позволяет определить вид цветка на основе морфологических характеристик.
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
# Загрузка данных
iris = load_iris()
X, y = iris.data, iris.target
# Разделение на обучающую и тестовую выборки
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
# Обучение модели
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Прогнозирование и оценка
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Точность модели: {accuracy:.3f}")
В этом примере мы достигаем точности более 95%, что демонстрирует эффективность случайного леса для задач с хорошо разделимыми классами.
Регрессия: прогноз цены жилья
Задача регрессии позволяет предсказывать непрерывные значения. Мы используем классический датасет Boston Housing для прогнозирования стоимости недвижимости.
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split # <-- Этот импорт был пропущен
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.preprocessing import StandardScaler
# 1. Загружаем новый датасет
housing = fetch_california_housing()
# 2. Используем переменную housing вместо boston
X, y = housing.data, housing.target
# Разделение и масштабирование
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Обучение модели
model = LinearRegression()
model.fit(X_train_scaled, y_train)
# Оценка качества
y_pred = model.predict(X_test_scaled)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Среднеквадратичная ошибка: {mse:.2f}")
print(f"Коэффициент детерминации R²: {r2:.3f}")
Линейная регрессия показывает R² около 0.6-0.7, что указывает на умеренную предсказательную способность модели.
Кластеризация: K-Means на синтетических данных
Кластеризация помогает обнаруживать скрытые группы в данных без использования меток классов.
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
# Генерация синтетических данных
X, y_true = make_blobs(n_samples=300, centers=4, cluster_std=0.60,
random_state=0)
# Применение K-Means
kmeans = KMeans(n_clusters=4, random_state=42, n_init=10)
y_pred = kmeans.fit_predict(X)
# Визуализация результатов
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.scatter(X[:, 0], X[:, 1], c=y_true, cmap='viridis')
plt.title('Истинные кластеры')
plt.subplot(1, 2, 2)
plt.scatter(X[:, 0], X[:, 1], c=y_pred, cmap='viridis')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1],
marker='x', s=300, linewidths=3, color='red')
plt.title('K-Means кластеризация')
plt.show()
Алгоритм K-Means успешно идентифицирует структуру данных, находя центроиды кластеров и группируя похожие точки.
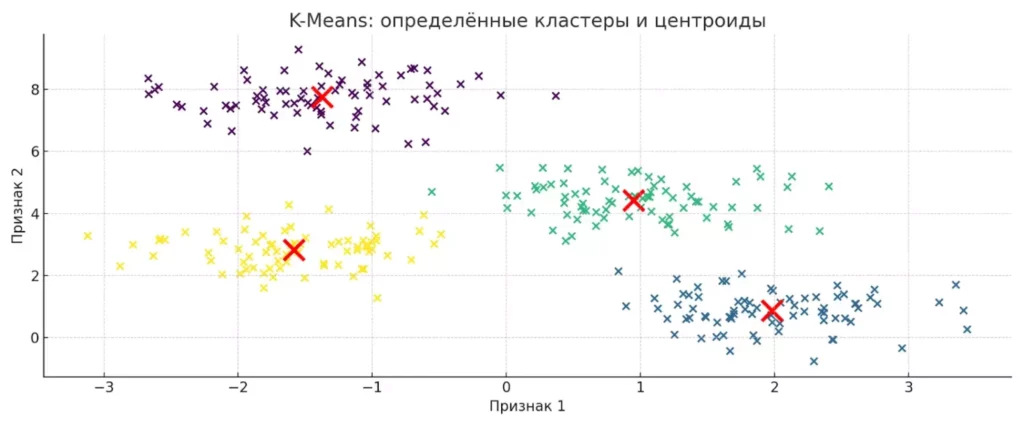
Диаграмма показывает, как алгоритм K-Means разделяет данные на четыре кластера и находит их центры (выделены красными крестами). Визуализация помогает наглядно оценить качество кластеризации и понять принципы работы алгоритма.
Как оценивать модели и подбирать параметры
Создание модели машинного обучения — это лишь первый шаг. Критически важно правильно оценить её качество и оптимизировать параметры для достижения наилучших результатов. Scikit-learn предоставляет комплексный набор инструментов для решения этих задач.
Выбор метрик оценки зависит от типа задачи и бизнес-требований. Для задач классификации мы используем различные показатели, каждый из которых освещает определённые аспекты работы модели. Для регрессионных задач применяются метрики, измеряющие отклонение предсказанных значений от истинных.
| Метрика | Тип задачи | Интерпретация |
|---|---|---|
| Accuracy | Классификация | Доля правильных предсказаний |
| Precision | Классификация | Точность положительных предсказаний |
| Recall | Классификация | Полнота — доля найденных положительных случаев |
| F1-score | Классификация | Гармоническое среднее precision и recall |
| MSE | Регрессия | Среднеквадратичная ошибка |
| MAE | Регрессия | Средняя абсолютная ошибка |
| R² | Регрессия | Коэффициент детерминации |
Кросс-валидация помогает получить более надёжную оценку качества модели, тестируя её на различных подмножествах данных:
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(random_state=42)
scores = cross_val_score(model, X, y, cv=5, scoring='accuracy')
print(f"Точность кросс-валидации: {scores.mean():.3f} (+/- {scores.std() * 2:.3f})")
Автоматический подбор гиперпараметров существенно упрощает процесс оптимизации модели. GridSearchCV выполняет исчерпывающий поиск в заданном пространстве параметров:
from sklearn.model_selection import GridSearchCV
# Определение сетки параметров
param_grid = {
'n_estimators': [50, 100, 200],
'max_depth': [3, 5, 7, None],
'min_samples_split': [2, 5, 10]
}
# Создание объекта поиска
grid_search = GridSearchCV(
RandomForestClassifier(random_state=42),
param_grid,
cv=5,
scoring='accuracy',
n_jobs=-1 # Использование всех доступных ядер
)
# Выполнение поиска
grid_search.fit(X_train, y_train)
print(f"Лучшие параметры: {grid_search.best_params_}")
print(f"Лучший результат: {grid_search.best_score_:.3f}")
Для больших пространств параметров более эффективным может оказаться RandomizedSearchCV, который случайно сэмплирует комбинации параметров:
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint
# Определение распределений параметров
param_distributions = {
'n_estimators': randint(50, 300),
'max_depth': [3, 5, 7, 10, None],
'min_samples_split': randint(2, 20)
}
random_search = RandomizedSearchCV(
RandomForestClassifier(random_state=42),
param_distributions,
n_iter=100, # Количество случайных комбинаций
cv=5,
scoring='accuracy',
random_state=42,
n_jobs=-1
)
random_search.fit(X_train, y_train)
Такой подход особенно полезен при работе с большим количеством гиперпараметров, где полный перебор может занять неприемлемо много времени.
Где читать и учиться дальше
Освоение Scikit-learn — это непрерывный процесс, особенно учитывая постоянное развитие библиотеки и появление новых методов машинного обучения. Мы составили список ресурсов, которые помогут углубить знания и оставаться в курсе последних тенденций.
Официальная документация остаётся золотым стандартом для изучения любой технологии. Документация Scikit-learn выделяется качественными примерами кода, подробными объяснениями алгоритмов и практическими руководствами:
- scikit-learn.org — основная документация с user guide и API reference.
- Примеры и туториалы — более 200 готовых примеров кода.
GitHub репозиторий предоставляет доступ к исходному коду и позволяет отслеживать развитие проекта:
github.com/scikit-learn/scikit-learn — исходный код, issue tracker, roadmap разработки
Книги для глубокого изучения предлагают структурированный подход к машинному обучению:
- «Hands-On Machine Learning» Aurélien Géron — практическое руководство с акцентом на Scikit-learn и TensorFlow.
- «Python Machine Learning» Sebastian Raschka — теоретические основы и их реализация на Python.
- «Introduction to Statistical Learning» James, Witten, Hastie, Tibshirani — фундаментальные концепции статистического обучения.
Онлайн-курсы и образовательные платформы предлагают интерактивное обучение:
- Coursera «Machine Learning» Andrew Ng — классический курс по основам ML.
- edX «Introduction to Data Science» MIT — комплексное введение в data science.
- Kaggle Learn — бесплатные микрокурсы по практическому машинному обучению.
Специализированные ресурсы для практики:
- Kaggle — соревнования, датасеты, сообщество практиков.
- Papers With Code — новейшие исследования с готовой реализацией.
- Towards Data Science — статьи и кейсы от практикующих специалистов.
Регулярное изучение этих ресурсов поможет не только освоить технические аспекты Scikit-learn, но и развить понимание того, как эффективно применять машинное обучение для решения реальных задач.
Заключение
Scikit-learn представляет собой идеальный инструмент для входа в мир машинного обучения и одновременно мощное решение для продакшн-систем. Библиотека успешно сочетает простоту использования с профессиональными возможностями, предоставляя разработчикам всех уровней единообразный интерфейс для решения широкого спектра задач — от базовой классификации до сложных алгоритмов кластеризации и снижения размерности.
- Scikit-learn — стандартная библиотека для машинного обучения. Она позволяет строить, обучать и тестировать модели в несколько строк кода.
- Библиотека поддерживает основные алгоритмы классификации, регрессии, кластеризации. Вы можете выбрать подходящий инструмент под любую задачу.
- Удобная работа с данными. Интеграция с Pandas, поддержка Pipelines и автоматизация обработки.
- Большое сообщество, подробная документация и масса примеров. Это снижает порог входа и ускоряет освоение data science.
- Scikit-learn подходит для обучения, экспериментов и продакшн-решений. Удобен для новичков, и для опытных специалистов.
Если только начинаете осваивать машинное обучение и хотите закрепить теорию на практике, рекомендуем обратить внимание на подборку курсов по Python. В них есть и теоретические блоки, и практические проекты — для быстрого старта и погружения в реальные задачи.
Рекомендуем посмотреть курсы по Python
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Профессия Python-разработчик
|
Eduson Academy
114 отзывов
|
Цена
116 400 ₽
|
От
9 700 ₽/мес
|
Длительность
6 месяцев
|
Старт
25 марта
|
Подробнее |
|
Fullstack-разработчик на Python
|
Нетология
46 отзывов
|
Цена
161 200 ₽
325 635 ₽
с промокодом kursy-online
|
От
4 975 ₽/мес
|
Длительность
18 месяцев
|
Старт
26 марта
|
Подробнее |
|
Python-разработчик
|
Академия Синергия
38 отзывов
|
Цена
89 800 ₽
224 500 ₽
с промокодом KURSHUB
|
От
3 742 ₽/мес
0% на 24 месяца
|
Длительность
6 месяцев
|
Старт
31 марта
|
Подробнее |
|
Профессия Python-разработчик
|
Skillbox
232 отзыва
|
Цена
157 107 ₽
285 648 ₽
Ещё -27% по промокоду
|
От
4 621 ₽/мес
9 715 ₽/мес
|
Длительность
12 месяцев
|
Старт
23 марта
|
Подробнее |
|
Python-разработчик
|
Яндекс Практикум
102 отзыва
|
Цена
159 000 ₽
|
От
18 500 ₽/мес
|
Длительность
9 месяцев
Можно взять академический отпуск
|
Старт
26 марта
|
Подробнее |

OTUS vs ProductStar: куда идти технарю, чтобы стать продактом — честное сравнение подходов
OTUS или ProductStar — что выбрать, если вы хотите перейти в продакт-менеджмент? Разбираем разницу в обучении, практике и результате, чтобы вы не потратили время зря.

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.

OTUS vs GeekBrains для backend: где строже к качеству кода и полезнее ревью
OTUS или GeekBrains — где обучение backend-разработке даёт более строгий подход к качеству кода? Разбираем, как устроено code review, какие инженерные практики используют школы и как проверить уровень ревью до оплаты курса.