Scikit-learn и машинное обучение: как Python делает магию реальностью
Если вы когда-нибудь задумывались, как ваш почтовый ящик магическим образом фильтрует спам, или почему Netflix так точно угадывает ваши киновкусы, то позвольте представить главного виновника — машинное обучение. А для тех, кто хочет не только восхищаться этими технологиями, но и создавать их собственными руками, существует Scikit-learn — мощная библиотека, которая превращает сложные алгоритмы машинного обучения в относительно понятный Python-код.

В этом руководстве мы разберём, что такое Scikit-learn, как с ним работать и почему эта библиотека стала стандартом де-факто в мире ML-разработки. Всё это без лишней академической зауми, но с должным уважением к математике, которая за всем этим стоит.
- Что такое Scikit-learn и зачем он нужен?
- Обзор возможностей
- Почему Scikit-learn так популярен?
- Установка и настройка
- Основные возможности
- Создаём первый ML-проект
- Обзор ключевых алгоритмов
- Ограничения Scikit-learn
- Рекомендуем посмотреть курсы по Python
Что такое Scikit-learn и зачем он нужен?
Scikit-learn (или просто sklearn — для тех, кто не хочет тратить драгоценные миллисекунды на печатание полного названия) — это библиотека машинного обучения для Python, которая появилась в 2007 году как мелкий проект Google Summer of Code, а затем выросла в гигантскую экосистему, без которой современный Data Science немыслим. По сути, это такая швейцарская армейская бритва для машинного обучения — компактная, но невероятно функциональная.
Эта библиотека построена на фундаменте других научных инструментов Python: NumPy (для работы с многомерными массивами и математики), SciPy (для более сложных вычислений), Matplotlib (для визуализации данных) и Pandas (для манипуляций с данными). Такой симбиоз делает её чрезвычайно мощной — как Вольтрон, собранный из нескольких отдельных роботов, который почему-то оказывается гораздо сильнее, чем сумма его частей (вот она, магия коллаборации в мире открытого кода!).
Где применяется эта библиотека? Ох, проще перечислить, где она НЕ применяется. Рекомендательные системы (вроде тех, что предлагают вам товары, которые вы и так собирались купить), спам-фильтры, системы распознавания текста и изображений, финансовые прогнозы, медицинская диагностика — везде, где нужно анализировать данные и делать на их основе прогнозы, sklearn чувствует себя как рыба в воде. И даже если вы работаете в какой-то экзотической области, где еще никто не применял машинное обучение, — что маловероятно в 2025 году — шансы, что вы начнете именно со Scikit-learn, стремятся к единице.
Обзор возможностей
Начнем с того, что sklearn — это настоящий комбайн алгоритмов. Здесь есть практически всё для классических задач машинного обучения:
- Классификация — когда нужно отнести объект к одному из нескольких классов (например, определить, спам это или нет).
- Регрессия — предсказание числовых значений (например, цен на жилье).
- Кластеризация — группировка похожих объектов (например, сегментация клиентов).
- Уменьшение размерности — когда у вас слишком много признаков, а нужно меньше (особенно полезно для визуализации многомерных данных).
- Предварительная обработка данных — нормализация, стандартизация, кодирование категориальных переменных и прочие необходимые манипуляции.
- Выбор модели — инструменты для настройки параметров алгоритмов и оценки их качества.
И всё это упаковано в удивительно последовательный и интуитивно понятный интерфейс. Три строчки кода — и ваша модель уже учится распознавать кошек на фотографиях (ну, почти).
Области применения
Я уже упоминал несколько областей, но давайте посмотрим на конкретные примеры:
- Рекомендательные системы — Spotify, Netflix, Amazon и даже ваш любимый Яндекс.Маркет используют ML-алгоритмы для рекомендаций.
- Финансы — прогнозирование рыночных тенденций, оценка кредитных рисков, обнаружение мошенничества.
- Медицина — диагностика заболеваний, анализ медицинских изображений, прогнозирование эффективности лечения.
- Маркетинг — сегментация клиентов, прогнозирование оттока, оптимизация рекламных кампаний.
- Обработка естественного языка — от простой классификации текстов до более сложных задач анализа тональности.
- Компьютерное зрение — хотя для сложных задач обычно используют специализированные библиотеки, для простых задач sklearn вполне подойдет.
Фактически, где есть данные и желание извлечь из них пользу (а где их сейчас нет?), там потенциально может использоваться Scikit-learn. И именно поэтому знание этой библиотеки — это билет в мир Data Science и один из обязательных навыков в портфолио современного аналитика данных или разработчика ML-моделей.
Почему Scikit-learn так популярен?
Популярность объясняется не только его функциональностью, но и рядом других факторов, которые в совокупности создают то, что маркетологи назвали бы «идеальным пользовательским опытом» (а я бы назвал «библиотекой, которая не заставляет вас швырять ноутбук в стену из-за непонятных ошибок»).
Во-первых, sklearn имеет удивительно последовательный и интуитивно понятный API. Все алгоритмы следуют одной и той же простой схеме: создаём объект модели, вызываем метод fit() для обучения, затем predict() для прогнозирования. Никаких сюрпризов, никаких неожиданных исключений (ну, почти). Просто, как кубики LEGO — сначала учимся, потом предсказываем. Эта последовательность действий настолько логична, что я иногда ловлю себя на мысли, что пытаюсь применить этот паттерн к другим аспектам жизни. Увы, к моим отношениям с налоговой это не применимо…
Во-вторых, sklearn — это не просто библиотека алгоритмов, а целая экосистема с исчерпывающей документацией. И под «исчерпывающей» я имею в виду действительно ИСЧЕРПЫВАЮЩУЮ — с описанием каждого параметра, примерами кода, математическими выкладками и даже ссылками на научные статьи, если вам вдруг захочется погрузиться в теорию. Для сравнения: это как если бы инструкция к вашей микроволновке включала объяснение квантовой физики, лежащей в основе её работы.
В-третьих, активное и большое сообщество разработчиков. Это означает, что если вы столкнулись с проблемой, то с вероятностью 99.9% кто-то уже сталкивался с ней раньше и разместил решение на Stack Overflow. А если нет — то на GitHub есть тысячи разработчиков, готовых помочь (или хотя бы посочувствовать).
Ну и, конечно, открытый исходный код под лицензией BSD, что позволяет использовать библиотеку бесплатно даже в коммерческих проектах. Капитализм капитализмом, но хорошие инструменты должны быть доступны всем — таков дух мира Python.
Сравнение с другими библиотеками машинного обучения
Давайте посмотрим, как Scikit-learn соотносится с другими популярными ML-библиотеками:
| Критерий | Scikit-learn | TensorFlow | PyTorch |
|---|---|---|---|
| Специализация | Классические алгоритмы ML | Глубокое обучение, нейросети | Глубокое обучение, исследования |
| Кривая обучения | Пологая (легко начать) | Крутая (много концепций) | Средняя (интуитивнее TF) |
| Скорость разработки | Высокая для простых моделей | Средняя | Высокая для исследований |
| Производительность | Хорошая для CPU | Отличная для GPU | Отличная для GPU |
| Применение | Табличные данные, классические задачи ML | Производственные системы, сложные нейросети | Исследования, прототипирование |
| Экосистема | Сильная для классического ML | Обширная, много инструментов | Растущая, сильное академическое сообщество |
Как видите, sklearn не пытается быть всем для всех — это не швейцарский армейский нож для абсолютно любой задачи машинного обучения. Если вам нужно строить сложные многослойные нейронные сети, которые будут распознавать кошек на фотографиях с точностью до породы и настроения, то лучше обратить внимание на PyTorch или TensorFlow. Но для 80% задач машинного обучения, с которыми вы столкнетесь в реальной жизни (особенно если работаете с табличными данными), Scikit-learn будет не просто достаточен, а оптимален.
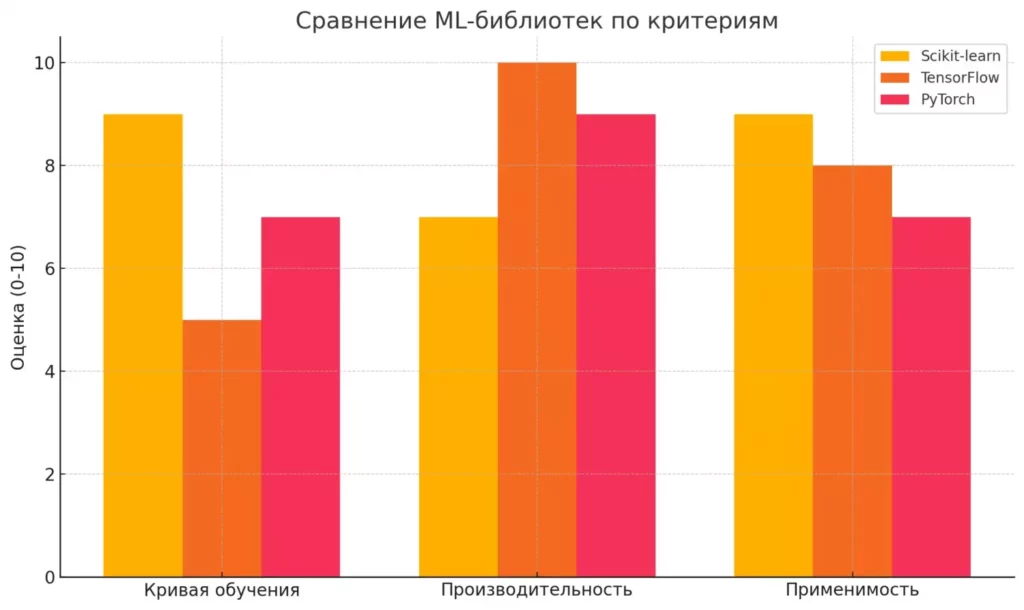
Эта диаграмма наглядно демонстрирует сильные и слабые стороны популярных ML-библиотек. Видно, что Scikit-learn особенно удобна для быстрого старта (лёгкая кривая обучения) и отлично подходит для задач на табличных данных, в то время как TensorFlow лидирует по производительности, особенно на GPU.
Установка и настройка
Установка — процесс примерно такой же сложный, как приготовление растворимого кофе. Правда, в отличие от кофе, результат всегда получается предсказуемо хорошим (если, конечно, вы не используете какую-нибудь экзотическую версию Python, скомпилированную на Raspberry Pi под управлением самописной ОС — в этом случае, друг мой, вы уже за гранью того, чем может помочь эта статья).
Для установки библиотеки вам потребуется Python (желательно версии 3.6 или выше — хотя, серьезно, если вы все еще используете Python 2.7 в 2025 году, пора задуматься о своих жизненных выборах). Scikit-learn зависит от NumPy, SciPy и joblib, но не беспокойтесь — если их нет, они установятся автоматически вместе с основной библиотекой.
Такая наглядная демонстрация особенно важна для новичков — она показывает, что установка Scikit-learn действительно проста и не требует сложной настройки. Скриншот терминала с прогресс-баром и сообщением об успешной установке снижает тревожность и повышает уверенность в собственных силах.
Самый простой способ установки — через менеджер пакетов pip. Откройте свой любимый терминал (да, я знаю, что для многих это словосочетание звучит как оксюморон) и выполните:
pip install -U scikit-learn
Флаг -U означает обновление до последней версии, если библиотека уже установлена. Иногда это спасает от странных багов, которые вы могли бы потратить часы на отладку, только чтобы в конце концов выяснить, что проблема была в устаревшей версии.
Если вы предпочитаете использовать Anaconda (а многие дата-сайентисты именно так и делают — это как Rolls-Royce среди дистрибутивов Python для анализа данных), то установка еще проще:
conda install scikit-learn
Готово. Не нужно компилировать из исходников, не нужно возиться с зависимостями. Просто работает — как в идеальном мире, который существует только в рекламе Apple.
Установка через pip
Для тех, кто хочет больше деталей об установке через pip:
- Убедитесь, что у вас установлен Python 3.6+ (проверьте командой python —version)
- Если у вас несколько версий Python, уточните, что используете нужную: python3 -m pip install -U scikit-learn
- На Windows может потребоваться запустить командную строку от имени администратора
- На Linux/Mac может потребоваться использовать sudo pip install -U scikit-learn если устанавливаете глобально
Если у вас возникают проблемы с установкой (что бывает реже, чем задержки рейсов в Шереметьево, но все же случается), стоит проверить совместимость версий Python и Scikit-learn в официальной документации.
Работа в Google Colab
А теперь для тех, кто хочет избежать всей этой суеты с установкой (или просто ленится настраивать локальное окружение — я вас не осуждаю): Google Colab — ваш лучший друг. Это бесплатный облачный сервис, который позволяет писать и выполнять Python-код прямо в браузере, и — о чудо! — Scikit-learn там уже предустановлен.
Просто откройте Google Colab, создайте новый блокнот и вперед — никакой установки, никаких зависимостей, даже компьютер мощный не нужен (все вычисления происходят на серверах Google). Единственный минус — если ваши данные конфиденциальны, возможно, стоит дважды подумать перед тем, как загружать их на сервера Google (хотя, давайте будем честными, они, вероятно, уже знают о вас больше, чем вы сами).
Совместимость с другими библиотеками
Scikit-learn дружит с основными библиотеками экосистемы Python для анализа данных:
- NumPy — фундамент для всех числовых вычислений в Python. Scikit-learn использует NumPy массивы как основной формат данных.
- Pandas — если данные хранятся в DataFrame, то легко конвертировать их в формат, понятный sklearn (обычно простым .values или .to_numpy()).
- Matplotlib и Seaborn — для визуализации результатов вашего машинного обучения (потому что иногда график стоит тысячи строк логов).
- SciPy — для более сложных математических операций, которые могут потребоваться в процессе.
Эта совместимость не случайна — она результат продуманной архитектуры и общих соглашений между библиотеками. Это как если бы разные производители мебели договорились использовать одинаковые крепления, чтобы вы могли собрать идеальный гарнитур из компонентов разных брендов.
Основные возможности
Это огромный супермаркет алгоритмов, где каждый может найти что-то на свой вкус. От классических методов вроде линейной регрессии, которые были популярны еще до того, как компьютеры стали умнее калькуляторов, до сложных ансамблевых методов, которые могли бы заставить нервничать даже опытных статистиков. Но что действительно выделяет эту библиотеку — так это её последовательный интерфейс, где каждый алгоритм следует одному и тому же шаблону использования.
Представьте, что вы учите иностранный язык, и вдруг обнаруживаете, что все глаголы спрягаются по одинаковому правилу, без исключений. Именно так работает Scikit-learn — создал объект модели, вызвал fit() для обучения, потом predict() для предсказаний. И неважно, используете ли вы линейную регрессию для предсказания цен на жилье или случайный лес для классификации грибов на съедобные и ядовитые (важное уточнение: я бы не рекомендовал полагаться исключительно на ML-модель при сборе грибов — все-таки последствия ошибки немного серьезнее, чем неточный прогноз котировок акций).
Помимо обучения и предсказания, sklearn предлагает множество инструментов для обработки данных, выбора и оценки моделей, а также визуализации результатов. Это как если бы вы пришли покупать молоток, а вам предложили целый набор инструментов вместе с инструкцией, как построить дом.
Давайте рассмотрим основные компоненты этой библиотеки, которые вы, скорее всего, будете использовать чаще всего (если, конечно, вы не какой-нибудь странный дата-сайентист, который предпочитает писать все алгоритмы с нуля — в таком случае, примите мои соболезнования по поводу ваших выходных).
Готовые датасеты в Scikit-learn
Одна из приятных особенностей — это наличие встроенных датасетов для тестирования и обучения. Это как если бы кулинарная книга не только давала рецепты, но и прилагала к ним все необходимые ингредиенты.
Библиотека предлагает несколько классических датасетов:
- Iris dataset (load_iris) — классический набор данных о цветах ириса с их параметрами. Идеален для задач классификации, поскольку содержит 3 вида ирисов, которые нужно различать по 4 признакам. Это как «Hello, World!» в мире машинного обучения.
- Boston Housing dataset (load_boston) — данные о ценах на жилье в Бостоне. Отлично подходит для регрессии, когда вы хотите предсказать непрерывную величину (хотя цены на недвижимость с тех пор немного изменились).
- Digits dataset (load_digits) — изображения рукописных цифр. Упрощенная версия знаменитого MNIST, если вы не готовы погружаться в глубокое обучение.
- Wine dataset (load_wine) — данные о химическом составе вин из разных регионов. Подходит для классификации, когда у вас есть много признаков.
Загрузить любой из этих датасетов проще простого:
from sklearn import datasets iris = datasets.load_iris() X = iris.data # признаки y = iris.target # метки классов
И вот у вас уже есть данные, готовые для эксперимента. Никаких CSV-файлов, никаких проблем с форматами — просто чистые, структурированные данные, как будто по волшебству.
Предварительная обработка данных (preprocessing)
Реальные данные редко бывают настолько аккуратными, как в учебниках. Обычно они грязные, неструктурированные и полны пропусков — как комната подростка в воскресенье утром. И здесь на помощь приходит модуль preprocessing из sklearn.
Вот некоторые из его возможностей:
- Стандартизация и нормализация — приведение признаков к одному масштабу, чтобы алгоритм не считал, что признак «годовой доход» важнее, чем «возраст», просто потому что его значения больше.
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_scaled = scaler.fit_transform(X)
- Кодирование категориальных переменных — преобразование текстовых категорий в числа, потому что алгоритмы машинного обучения не очень хорошо понимают слова (у них математическое образование, а не филологическое).
from sklearn.preprocessing import OneHotEncoder encoder = OneHotEncoder() X_encoded = encoder.fit_transform(X[:, [categorical_column_index]])
- Обработка пропущенных значений — потому что в реальной жизни данные имеют свойство таинственно исчезать.
from sklearn.impute import SimpleImputer imputer = SimpleImputer(strategy='mean') X_imputed = imputer.fit_transform(X)
Эти инструменты могут не выглядеть захватывающе на первый взгляд, но поверьте, они спасут вам жизнь (или как минимум несколько часов работы), когда дело дойдет до реальных проектов.
Уменьшение размерности данных
Иногда данных слишком много — не в смысле количества наблюдений, а в смысле количества признаков. Представьте, что вы пытаетесь предсказать цену автомобиля, имея 500 различных параметров для каждой машины. Это не только избыточно, но и может привести к переобучению модели (когда модель запоминает данные вместо того, чтобы учиться на них).
Scikit-learn предлагает несколько методов для сокращения размерности:
- PCA (Principal Component Analysis) — волшебный метод, который находит главные компоненты в ваших данных, позволяя сократить количество признаков с минимальной потерей информации.
from sklearn.decomposition import PCA pca = PCA(n_components=2) # Сокращаем до 2 измерений X_reduced = pca.fit_transform(X)
- t-SNE — нелинейный метод уменьшения размерности, особенно полезный для визуализации данных высокой размерности.
from sklearn.manifold import TSNE tsne = TSNE(n_components=2) X_tsne = tsne.fit_transform(X)
Эти методы особенно полезны, когда вы хотите визуализировать данные или ускорить работу алгоритмов, которые плохо справляются с большим количеством признаков.
Методы выбора модели
Выбор оптимальных параметров для модели — это часто процесс проб и ошибок. Но вместо того, чтобы наугад подбирать значения (и, возможно, проклинать свою жизнь), sklearn предлагает автоматизированные методы:
- GridSearchCV — перебирает все возможные комбинации параметров, чтобы найти лучшую. Это как если бы вы перепробовали все возможные настройки своей кофемашины, чтобы найти идеальный рецепт.
from sklearn.model_selection import GridSearchCV
param_grid = {'C': [0.1, 1, 10], 'kernel': ['linear', 'rbf']}
grid_search = GridSearchCV(SVC(), param_grid, cv=5)
grid_search.fit(X_train, y_train)
best_params = grid_search.best_params_
- Cross-validation — метод оценки обобщающей способности модели путем обучения и тестирования на разных подмножествах данных.
from sklearn.model_selection import cross_val_score
scores = cross_val_score(model, X, y, cv=5)
print(f"Cross-validation scores: {scores}")
print(f"Average score: {scores.mean()}")
Эти методы помогают не только найти оптимальные параметры, но и оценить, насколько хорошо модель будет работать на новых данных — то есть решают классическую проблему переобучения, когда модель отлично работает на тренировочных данных, но разваливается на новых (как студент, который заучил ответы на конкретные вопросы, но не понял материал).
В следующих разделах мы поговорим о том, как применить все эти инструменты на практике, создав полноценный ML-проект от начала до конца. А пока — подготовьте ваши данные и настройте компьютер, мы готовимся к практике!
Сimport numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LogisticRegression from sklearn import metrics
Загрузка датасета ирисов
iris = datasets.load_iris() X = iris.data[:, (2, 3)] # Берем только длину и ширину лепестка y = iris.target
Преобразуем данные в DataFrame для наглядности
df = pd.DataFrame(iris.data, columns=iris.feature_names) df['target'] = iris.target
Добавим названия видов для удобства
species_names = {0: 'setosa', 1: 'versicolor', 2: 'virginica'} df['species'] = df['target'].map(species_names)
Визуализация данных
plt.figure(figsize=(10, 6)) for species in [0, 1, 2]: plt.scatter(df[df['target'] == species]['petal length (cm)'], df[df['target'] == species]['petal width (cm)'], label=species_names[species]) plt.xlabel('Длина лепестка (см)') plt.ylabel('Ширина лепестка (см)') plt.title('Распределение видов ирисов по размерам лепестков') plt.legend()
Разделение данных на обучающую и тестовую выборки
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
Стандартизация данных
scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train) X_test_scaled = scaler.transform(X_test)
Создание и обучение модели логистической регрессии
log_reg = LogisticRegression(max_iter=1000) log_reg.fit(X_train_scaled, y_train)
Предсказания на тестовой выборке
y_pred = log_reg.predict(X_test_scaled)
Оценка модели
accuracy = metrics.accuracy_score(y_test, y_pred) conf_matrix = metrics.confusion_matrix(y_test, y_pred) classification_report = metrics.classification_report(y_test, y_pred)
print(f"Точность модели: {accuracy:.2f}") print("\nМатрица ошибок:") print(conf_matrix) print("\nОтчет о классификации:") print(classification_report)
Визуализация границ решения
def plot_decision_boundary(X, y, model, scaler): h = .02 # шаг в сетке x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1 y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1 xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# Масштабируем и предсказываем на всей сетке
Z = model.predict(scaler.transform(np.c_[xx.ravel(), yy.ravel()]))
Z = Z.reshape(xx.shape)
plt.figure(figsize=(10, 6))
plt.contourf(xx, yy, Z, alpha=0.3)
# Отображаем точки данных
for species in [0, 1, 2]:
plt.scatter(X[y == species, 0], X[y == species, 1],
label=species_names[species])
plt.xlabel('Длина лепестка (см)')
plt.ylabel('Ширина лепестка (см)')
plt.title('Границы решения логистической регрессии')
plt.legend()
plot_decision_boundary(X, y, log_reg, scaler)
Создаём первый ML-проект
Теория — это прекрасно, но, как говорил мой преподаватель по программированию, «теория без практики — всё равно что автомобиль без колёс: выглядит внушительно, но никуда не едет». Поэтому давайте создадим наш первый полноценный ML-проект с использованием sklearn — от загрузки данных до оценки качества модели и визуализации результатов.
Наша задача будет классической для начинающих в машинном обучении — классификация ирисов. Эта задача настолько популярна в мире ML, что стала своеобразным «Hello, World!» для дата-сайентистов. И не без причины — датасет компактный, хорошо структурированный и идеально подходит для демонстрации основных концепций.
Постановка задачи
Мы будем решать задачу классификации: по размерам лепестков и чашелистиков цветка определить, к какому из трёх видов ирисов он относится (setosa, versicolor или virginica). У нас есть 150 примеров ирисов с 4 числовыми признаками:
- Длина чашелистика
- Ширина чашелистика
- Длина лепестка
- Ширина лепестка
Для простоты визуализации мы сосредоточимся только на длине и ширине лепестка, но в реальной задаче использовали бы все доступные признаки.
Подготовка данных
Первый шаг любого ML-проекта — загрузка и подготовка данных. Для ирисов это тривиально, благодаря встроенному датасету:
from sklearn import datasets iris = datasets.load_iris() X = iris.data[:, (2, 3)] # Берем только длину и ширину лепестка y = iris.target
Всегда полезно визуализировать данные, чтобы лучше понять, с чем мы имеем дело:
import matplotlib.pyplot as plt plt.figure(figsize=(10, 6)) for species in [0, 1, 2]: plt.scatter(X[y == species, 0], X[y == species, 1])
Из визуализации становится очевидно, что виды ирисов довольно хорошо разделяются по размерам лепестков — что делает задачу классификации вполне решаемой.
Следующий шаг — разделение данных на обучающую и тестовую выборки. Это критически важно: мы обучаем модель на одной части данных, а тестируем на другой, чтобы оценить, насколько хорошо она обобщает новые случаи
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
И наконец, стандартизация данных — приведение их к одному масштабу:
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train) X_test_scaled = scaler.transform(X_test)
Обучение модели
Для нашей задачи классификации выберем логистическую регрессию — это простой, но мощный алгоритм, который хорошо работает для многих задач:
from sklearn.linear_model import LogisticRegression log_reg = LogisticRegression(max_iter=1000) log_reg.fit(X_train_scaled, y_train)
Заметьте, насколько лаконичен этот код — всего пара строк, а мы уже обучили модель машинного обучения! Scikit-learn делает весь сложный математический аппарат незаметным для пользователя, позволяя сосредоточиться на сути задачи.
Оценка качества модели
После обучения модели важно оценить, насколько хорошо она работает. Для этого используем нашу тестовую выборку:
y_pred = log_reg.predict(X_test_scaled)
Теперь мы можем сравнить предсказания модели с реальными значениями и вычислить различные метрики:
from sklearn import metrics accuracy = metrics.accuracy_score(y_test, y_pred) conf_matrix = metrics.confusion_matrix(y_test, y_pred) classification_report = metrics.classification_report(y_test, y_pred)
Эти метрики дадут нам полное представление о том, насколько хорошо модель справляется с задачей. Обычно для задачи классификации интересны следующие показатели:
- Точность (precision) — какая доля объектов, названных моделью положительными, действительно являются положительными
- Полнота (recall) — какая доля положительных объектов была выявлена моделью
- F1-мера — среднее гармоническое между точностью и полнотой
Делание предсказаний
Теперь, когда мы убедились, что наша модель работает достаточно хорошо, мы можем использовать её для предсказания на новых данных:
# Предположим, у нас есть новый ирис с длиной лепестка 5 см и шириной 1.7 см
new_iris = np.array([[5.0, 1.7]])
new_iris_scaled = scaler.transform(new_iris)
predicted_species = log_reg.predict(new_iris_scaled)
print(f"Предсказанный вид: {iris.target_names[predicted_species[0]]}")
Это и есть конечная цель машинного обучения — создать модель, которая может делать предсказания на новых, невиданных ранее данных.
Для полноты картины мы можем визуализировать границы решения, чтобы понять, как модель классифицирует пространство признаков:
def plot_decision_boundary(X, y, model, scaler): # Создаем сетку точек h = .02 x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1 y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1 xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) # Предсказываем для всех точек сетки Z = model.predict(scaler.transform(np.c_[xx.ravel(), yy.ravel()])) Z = Z.reshape(xx.shape) # Рисуем границы и точки plt.contourf(xx, yy, Z, alpha=0.3) for species in [0, 1, 2]: plt.scatter(X[y == species, 0], X[y == species, 1])
Весь этот пример показывает, насколько просто создать полноценную ML-модель с помощью sklearn. Конечно, в реальных проектах задачи будут сложнее, данных будет больше, и потребуется больше предварительной обработки — но базовый процесс останется тем же.
Если вы хотите попробовать этот код, я создал полный пример в артефакте выше. В следующем разделе мы рассмотрим различные алгоритмы, доступные в sklearn, и когда их лучше использовать.
Обзор ключевых алгоритмов
Если представить машинное обучение как гигантскую кухню, то алгоритмы — это рецепты, а Scikit-learn — это ваша кулинарная книга с подробными инструкциями. И как любой уважающий себя шеф-повар знает разницу между тушением и пассерованием, так и хороший дата-сайентист должен понимать, какой алгоритм подходит для конкретной задачи.
В арсенале Scikit-learn буквально десятки алгоритмов — от простых линейных моделей до сложных ансамблевых методов, от классических статистических подходов до новейших достижений в области машинного обучения (ну, новейших по состоянию на момент создания библиотеки — ML развивается с такой скоростью, что «новейшее» обычно устаревает ещё до того, как вы закончите читать научную статью о нём).
Давайте разберём наиболее популярные и полезные алгоритмы, сгруппированные по типам задач.
Методы классификации
Классификация — это задача отнесения объекта к одному из предопределённых классов на основе его признаков. Это как если бы вы учили компьютер отличать собак от кошек, спам от обычной почты или приемлемые заявки на кредит от рискованных.
- Логистическая регрессия
Несмотря на слово «регрессия» в названии, это метод классификации. Он особенно хорош для бинарной классификации (когда классов всего два) и когда необходимо получать не только класс, но и вероятность принадлежности к нему.
from sklearn.linear_model import LogisticRegression log_reg = LogisticRegression(C=1.0, solver='lbfgs', max_iter=100) log_reg.fit(X_train, y_train)
Параметр C контролирует регуляризацию — меньшие значения означают более сильную регуляризацию, что помогает бороться с переобучением. Это как регулятор отопления — поверни в одну сторону, станет жарче (модель сложнее), поверни в другую — прохладнее (модель проще).
- Метод опорных векторов (SVM)
SVM — мощный метод для линейной и нелинейной классификации. Он работает, находя гиперплоскость, которая наилучшим образом разделяет классы.
from sklearn.svm import SVC svm_clf = SVC(kernel='rbf', C=5, gamma='scale') svm_clf.fit(X_train, y_train)
Параметр kernel определяет тип ядра — для линейно разделимых данных подойдёт ‘linear’, а для более сложных случаев можно использовать ‘rbf’ (радиальная базисная функция). Это как выбирать между прямой линией и кривой для разделения точек на графике.
- K-ближайших соседей (KNN)
KNN — интуитивно понятный алгоритм: новый объект относится к тому классу, к которому принадлежит большинство из K его ближайших соседей.
from sklearn.neighbors import KNeighborsClassifier knn_clf = KNeighborsClassifier(n_neighbors=5, weights='uniform') knn_clf.fit(X_train, y_train)
Параметр n_neighbors определяет количество соседей, которых нужно учитывать. Выбор оптимального K — это искусство, которое приходит с опытом (или с перебором параметров через GridSearchCV, что чаще).
- Случайный лес (Random Forest)
Random Forest — один из самых популярных алгоритмов в Data Science. Он строит множество деревьев решений и объединяет их предсказания.
from sklearn.ensemble import RandomForestClassifier rf_clf = RandomForestClassifier(n_estimators=100, max_depth=None, random_state=42) rf_clf.fit(X_train, y_train)
Параметр n_estimators определяет количество деревьев — больше деревьев обычно дают лучшую точность, но требуют больше вычислительных ресурсов. Это как если бы вы спрашивали мнение не у одного эксперта, а у целой группы, а затем выбирали наиболее популярный ответ.
Методы регрессии
Регрессия отличается от классификации тем, что предсказывает непрерывные значения, а не категории. Например, цены на дома, выручку компании или рост человека.
- Линейная регрессия
Самый простой и интерпретируемый метод регрессии, который ищет линейную зависимость между признаками и целевой переменной.
from sklearn.linear_model import LinearRegression lin_reg = LinearRegression() lin_reg.fit(X_train, y_train)
Несмотря на свою простоту, линейная регрессия часто даёт хорошие результаты, особенно когда данные имеют линейную структуру или после соответствующей трансформации признаков.
- Регрессия Ridge и Lasso
Эти методы добавляют регуляризацию к линейной регрессии, что помогает справиться с мультиколлинеарностью и уменьшить переобучение.
from sklearn.linear_model import Ridge, Lasso ridge_reg = Ridge(alpha=1.0) lasso_reg = Lasso(alpha=0.1) ridge_reg.fit(X_train, y_train) lasso_reg.fit(X_train, y_train)
Параметр alpha контролирует силу регуляризации. Ridge и Lasso отличаются типом регуляризации: Ridge использует L2-регуляризацию (квадрат значений коэффициентов), а Lasso — L1-регуляризацию (абсолютные значения), которая может приводить к разреженным моделям (некоторые коэффициенты становятся точно равными нулю).
- Случайный лес для регрессии
Да, тот же Random Forest, но теперь для предсказания непрерывных значений.
from sklearn.ensemble import RandomForestRegressor rf_reg = RandomForestRegressor(n_estimators=100, max_depth=None, random_state=42) rf_reg.fit(X_train, y_train)
Вместо голосования, которое используется в классификации, в регрессии Random Forest берёт среднее значение предсказаний всех деревьев.
- Градиентный бустинг
Один из самых мощных алгоритмов для регрессии (и классификации), который последовательно строит деревья решений, исправляя ошибки предыдущих моделей.
from sklearn.ensemble import GradientBoostingRegressor gb_reg = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42) gb_reg.fit(X_train, y_train)
Параметр learning_rate контролирует, насколько сильно каждое дерево будет исправлять ошибки предыдущих. Это как настройка скорости обучения — слишком высокая может привести к переобучению, слишком низкая потребует большего количества деревьев.
Методы кластеризации
Кластеризация — это задача разбиения множества объектов на группы (кластеры) так, чтобы объекты внутри одной группы были более похожи друг на друга, чем на объекты из других групп. Это обучение без учителя, поскольку правильные ответы (метки классов) не предоставляются.
- K-средних (K-means)
Самый популярный и простой алгоритм кластеризации, который разбивает данные на K кластеров, минимизируя расстояние от точек до центров их кластеров.
from sklearn.cluster import KMeans kmeans = KMeans(n_clusters=3, random_state=42) kmeans.fit(X)
Параметр n_clusters определяет количество кластеров, которое нужно найти. Определение оптимального K — это отдельная задача, для которой существуют специальные методы (например, метод локтя или силуэтный анализ).
- DBSCAN
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) — алгоритм, основанный на плотности, который может обнаруживать кластеры произвольной формы и автоматически определять количество кластеров.
from sklearn.cluster import DBSCAN dbscan = DBSCAN(eps=0.5, min_samples=5) dbscan.fit(X)
Параметр eps определяет максимальное расстояние между точками, чтобы считать их соседями, а min_samples — минимальное количество точек, необходимое для формирования «плотной области».
- Агломеративная кластеризация
Иерархический метод кластеризации, который начинает с того, что каждая точка является отдельным кластером, а затем постепенно объединяет их.
from sklearn.cluster import AgglomerativeClustering agg_clustering = AgglomerativeClustering(n_clusters=3) agg_clustering.fit(X)
Этот метод особенно полезен, когда требуется построить дендрограмму — древовидную диаграмму, показывающую иерархию кластеров.
Важно помнить, что ни один алгоритм не является идеальным для всех задач. Выбор алгоритма зависит от многих факторов: типа и объёма данных, требуемой интерпретируемости, вычислительных ресурсов и так далее. Часто лучшей стратегией является попробовать несколько разных алгоритмов и выбрать тот, который даёт наилучшие результаты на вашем конкретном наборе данных.
А теперь, когда мы вооружены знаниями о различных алгоритмах, давайте рассмотрим, чего Scikit-learn НЕ умеет — потому что знание ограничений инструмента порой важнее, чем знание его возможностей.
Ограничения Scikit-learn
Несмотря на всю свою мощь и универсальность, Scikit-learn — не серебряная пуля, способная решить любую задачу машинного обучения. У этой библиотеки есть чёткие границы применимости, и важно их понимать, чтобы не тратить время на попытки заставить квадратный колышек влезть в круглое отверстие (хотя, если бить достаточно сильно, это иногда получается, но результат редко бывает элегантным).
Вот основные области, где sklearn показывает свои слабости:
- Глубокое обучение и нейронные сети
Если вы хотите построить многослойный перцептрон с миллионами параметров для распознавания кошек на видео или генерации текста в стиле Достоевского, Scikit-learn вежливо предложит вам обратиться к специализированным библиотекам, таким как TensorFlow, PyTorch или Keras. Хотя в sklearn есть простейшие нейронные сети (MLPClassifier и MLPRegressor), они скорее демонстрационные, чем практически применимые для серьёзных задач глубокого обучения.
# Это максимум, на что способен Scikit-learn в плане нейронных сетей from sklearn.neural_network import MLPClassifier mlp = MLPClassifier(hidden_layer_sizes=(100, 50), max_iter=1000)
Это как пытаться участвовать в Формуле-1 на семейном седане — технически это автомобиль, но шансы на победу стремятся к нулю.
- Обработка неструктурированных данных
Scikit-learn создан для работы с аккуратными, структурированными, числовыми данными. Если ваши данные — это изображения, аудио, видео или сырой текст, вам придётся сначала преобразовать их в числовые признаки, прежде чем скармливать sklearn. И хотя в библиотеке есть некоторые инструменты для простой обработки текста (например, TF-IDF векторизация), они весьма ограничены по сравнению со специализированными библиотеками для обработки естественного языка, такими как NLTK, SpaCy или Gensim.
- Масштабируемость
Scikit-learn прекрасно работает с датасетами, которые помещаются в оперативную память вашего компьютера. Но как только речь заходит о больших данных, которые измеряются в гигабайтах или терабайтах, sklearn начинает задыхаться. Для таких масштабов лучше обратиться к распределённым вычислениям с помощью Spark MLlib, Dask или специальных решений для больших данных.
- Онлайн-обучение и потоковые данные
Большинство моделей sklearn предполагают, что все данные доступны сразу. Если вы работаете с потоковыми данными, которые постоянно обновляются, и хотите, чтобы модель обучалась «на лету», Scikit-learn может оказаться не лучшим выбором. Есть некоторые модели с поддержкой инкрементного обучения (например, SGDClassifier), но для серьёзной работы с потоковыми данными лучше рассмотреть специализированные решения.
- Автоматизированное машинное обучение (AutoML)
Хотя Scikit-learn предлагает инструменты для автоматизации некоторых аспектов создания моделей (например, GridSearchCV для подбора гиперпараметров), он не предоставляет полноценного AutoML решения, которое автоматически выбирало бы лучшие алгоритмы, признаки и параметры. Для этого существуют специальные библиотеки, такие как Auto-Sklearn, TPOT или H2O AutoML.
- Выживаемость и временные ряды
Задачи анализа выживаемости или прогнозирования временных рядов имеют свою специфику, которая не всегда хорошо представлена в Scikit-learn. Для таких задач могут больше подойти специализированные библиотеки, такие как Lifelines (для анализа выживаемости) или Prophet, StatsModels или Sktime (для временных рядов).
- Интерпретируемость моделей
Многие алгоритмы в sklearn работают как «чёрные ящики» — они дают предсказания, но не объясняют, как именно они к ним пришли. В современном мире, где всё больше внимания уделяется объяснимому ИИ, это может быть проблемой. Хотя есть возможность извлечь важность признаков из некоторых моделей (например, из случайного леса), для более глубокого анализа интерпретируемости моделей лучше обратиться к специализированным библиотекам, таким как SHAP, LIME или ELI5.
Понимание этих ограничений поможет вам сделать осознанный выбор: использовать sklearn для задач, где он силён, и обращаться к другим инструментам там, где требуются специализированные решения. В конце концов, у хорошего мастера должен быть не один инструмент, а целый набор, и знание, когда какой применять, отличает профессионала от любителя.
В конце концов, Scikit-learn — это не просто библиотека, а дверь в захватывающий мир машинного обучения. И кто знает, может быть, именно ваша модель однажды изменит мир (или по крайней мере поможет вам получить повышение на работе, что, согласитесь, тоже неплохо).
Если вы только начинаете осваивать Python или хотите систематизировать знания, загляните в подборку курсов по программированию на Python. Там собраны обучающие программы от ведущих онлайн-школ — от базовых до продвинутых, включая направления, связанные с машинным обучением и использованием Scikit-learn.
Рекомендуем посмотреть курсы по Python
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Профессия Python-разработчик
|
Eduson Academy
114 отзывов
|
Цена
116 400 ₽
|
От
9 700 ₽/мес
|
Длительность
6 месяцев
|
Старт
25 марта
|
Подробнее |
|
Fullstack-разработчик на Python
|
Нетология
46 отзывов
|
Цена
161 200 ₽
325 635 ₽
с промокодом kursy-online
|
От
4 975 ₽/мес
|
Длительность
18 месяцев
|
Старт
26 марта
|
Подробнее |
|
Python-разработчик
|
Академия Синергия
38 отзывов
|
Цена
89 800 ₽
224 500 ₽
с промокодом KURSHUB
|
От
3 742 ₽/мес
0% на 24 месяца
|
Длительность
6 месяцев
|
Старт
31 марта
|
Подробнее |
|
Профессия Python-разработчик
|
Skillbox
232 отзыва
|
Цена
157 107 ₽
285 648 ₽
Ещё -27% по промокоду
|
От
4 621 ₽/мес
9 715 ₽/мес
|
Длительность
12 месяцев
|
Старт
23 марта
|
Подробнее |
|
Python-разработчик
|
Яндекс Практикум
102 отзыва
|
Цена
159 000 ₽
|
От
18 500 ₽/мес
|
Длительность
9 месяцев
Можно взять академический отпуск
|
Старт
26 марта
|
Подробнее |

OTUS vs SkillFactory: автотесты — где больше «пишем код», а где больше «разбираем подходы»
Если вы ищете курс по автоматизации тестирования, который сочетает теорию и практику, вы попали по адресу. В этой статье мы сравниваем два популярных курса: OTUS и SkillFactory, чтобы помочь вам определиться с выбором. Какой из них поможет вам быстрее освоить важнейшие навыки тестирования? Читайте и узнайте все подробности!

OTUS vs ProductStar: куда идти технарю, чтобы стать продактом — честное сравнение подходов
OTUS или ProductStar — что выбрать, если вы хотите перейти в продакт-менеджмент? Разбираем разницу в обучении, практике и результате, чтобы вы не потратили время зря.

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.