Stable Diffusion: нейросеть для генерации изображений и анимаций
Stable Diffusion — тот редкий случай, когда технологический прорыв внезапно стал доступен не только избранным корпорациям с миллиардными бюджетами, но и обычным смертным вроде нас с вами.

Представьте: ещё вчера для создания приличной иллюстрации требовались годы обучения и тысячи часов практики, а сегодня достаточно ввести текстовое описание и получить результат за пару минут. Magical, isn’t it? Эта нейросеть с открытым исходным кодом перевернула представление о генерации изображений, позволяя не только создавать картинки «из ничего», но и дорисовывать детали, изменять стиль, расширять холст и даже анимировать статичные изображения. В этом руководстве я расскажу, как установить и использовать Stable Diffusion, даже если ваши познания в программировании ограничиваются умением включать компьютер (и то не с первого раза).
- Что такое Stable Diffusion и как она работает?
- Варианты использования
- Как пользоваться без установки
- Как установить на компьютер
- Как работать в Stable Diffusion: интерфейс и настройки
- Как составить качественный запрос (prompt) для генерации
- Расширенные возможности
- Этические и юридические вопросы
- Заключение
- Рекомендуем посмотреть курсы по веб-дизайну
Что такое Stable Diffusion и как она работает?
Это нейросеть, которая превращает текстовые описания в image, причём делает это с таким мастерством, что впору задуматься о переквалификации всех графических дизайнеров в «промпт-инженеров» (а что, звучит современно и загадочно).
Разработана эта чудо-машина компанией Stability AI в 2022 году, и главное её отличие от прочих подобных нейросетей — открытый исходный код. Это как если бы Ferrari вдруг опубликовала чертежи своих автомобилей и разрешила всем желающим собирать их в гараже — фантастика, но реальность.
Открытость кода дала невиданную ранее свободу: теперь любой программист, вооружившись достаточно мощным компьютером, может не только использовать нейросеть, но и модифицировать её под свои нужды, обучать на собственных данных или даже создавать новые версии. Представьте, что вы можете «натренировать» AI рисовать именно в том стиле, который вам нравится — от пиксель-арта до гиперреализма. Неудивительно, что с момента выхода нейросети появилось бесчисленное множество её модификаций и улучшений.
И если DALL-E от OpenAI и Midjourney остаются преимущественно закрытыми сервисами (с ограниченным доступом и, главное, без возможности запуска на собственном оборудовании), то Stable Diffusion можно установить на свой компьютер и пользоваться без ограничений. Это как разница между походом в ресторан, где вы едите то, что вам предлагают, и возможностью готовить дома с полным доступом к кухне, ингредиентам и рецептам — очевидно, что второй вариант даёт гораздо больше возможностей для экспериментов и кастомизации.
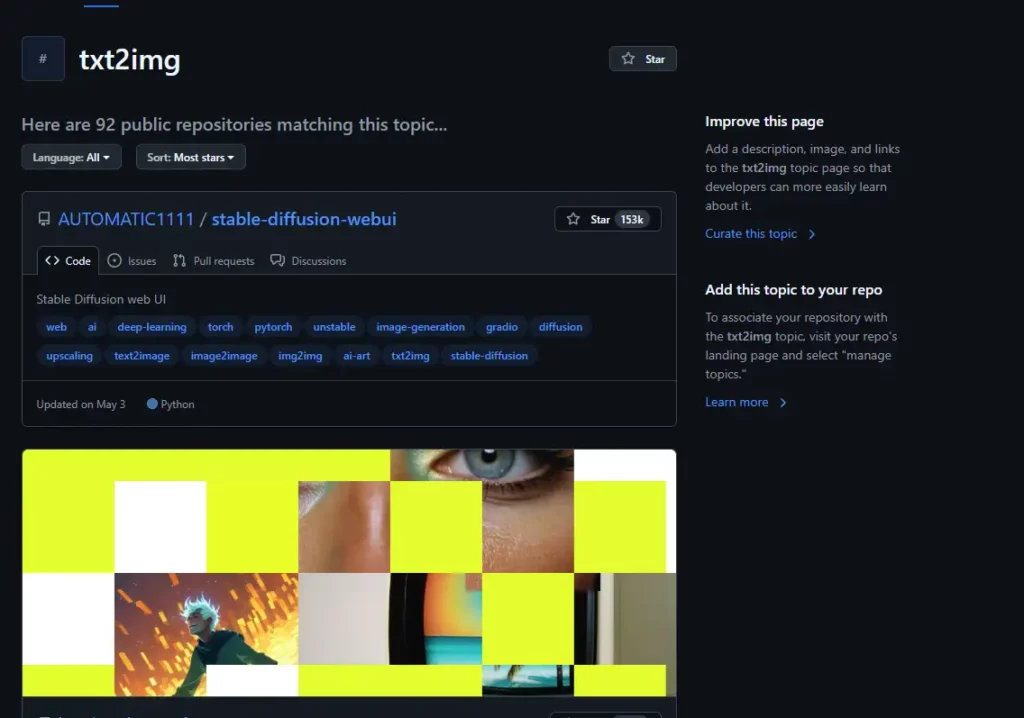
Но будем честны: вся эта техническая свобода имеет и обратную сторону — сложность в настройке и использовании. К счастью, сообщество вокруг нейросети настолько активно, что разработало множество упрощённых интерфейсов и готовых решений, сделав технологию доступной даже для тех, кто термин «командная строка» считает названием какой-то экзотической игры.На изображении представлен скриншот страницы GitHub по теме txt2img, где на первом месте в списке репозиториев отображается проект AUTOMATIC1111/stable-diffusion-webui — самый популярный пользовательский интерфейс для работы с нейросетью Stable Diffusion. В карточке репозитория указаны теги, описывающие его тематику: image-generation, text2image, upscaling, diffusion, а также видна статистика — более 150 тысяч звёзд (Stars). Ниже отображаются миниатюры сгенерированных изображений, демонстрирующих примеры работы нейросети.
Принципы работы
Если вы представляете работу Stable Diffusion как волшебную шкатулку, в которую кидаешь текст и получаешь картинку — поздравляю, вы недалеки от истины. Но, как техноэнтузиаст со здоровой долей цинизма, я просто обязан объяснить, что происходит внутри этой «шкатулки».
В основе лежит техника латентной диффузии — впечатляющее название для процесса, в котором алгоритм сначала превращает image в шум, а затем последовательно удаляет этот шум, восстанавливая исходную картинку. Представьте, что вы берёте фотографию, постепенно заливаете её краской, а затем (о, чудо!) умеете вернуть её к исходному состоянию. Именно этому нейросеть и обучается: как из шума воссоздать конкретное изображение.
Процесс генерации разбит на несколько этапов, и за каждый отвечает отдельный компонент:
- Сначала текстовый кодировщик (CLIPText) превращает ваш запрос типа «рыжий кот в космическом скафандре» в набор векторов — числовую абракадабру, понятную компьютеру.
- Затем UNet (назван так не в честь подводной лодки, а от «U-shaped neural network») вместе с планировщиком начинает работу с шумом, постепенно преобразуя его в соответствии с вашим запросом.
- Наконец, декодер превращает получившийся результат в image, которое вы можете увидеть собственными глазами.
Всё это происходит в так называемом «латентном пространстве» — абстрактном измерении, где изображения представлены не как пиксели, а как математические векторы. Звучит как научная фантастика, но это позволяет обрабатывать данные значительно быстрее и эффективнее, чем если бы нейросеть работала напрямую с пикселями.
Обучена вся эта махина была на примерно 5 миллиардах image из интернета — да, именно так, ваши посты в Instagram могли послужить материалом для тренировки. Пугает? Немного. Впечатляет? Безусловно.
Отличие от других нейросетей (DALL-E, MidJourney)
Давайте разберемся, чем же Stable Diffusion отличается от других популярных нейросетей для генерации image — кроме того очевидного факта, что её название звучит как название новой модели стиральной машины (что, впрочем, весьма символично, учитывая её способность к «отмыванию» шума из изображений).
| Параметр | Stable Diffusion | DALL-E | MidJourney |
|---|---|---|---|
| Доступность | Полностью открытый код, можно запустить на своем компьютере | Закрытая система, доступ через API или веб-интерфейс | Закрытая система, доступ через Discord |
| Стоимость | Бесплатно (если не считать электричество и седые волосы при установке) | Ограниченно бесплатно, далее платная подписка | Платная подписка |
| Гибкость | Максимальная: можно модифицировать код, дообучать модель, изменять параметры | Ограниченная: только доступный интерфейс и API | Ограниченная: команды в Discord |
| Качество | Варьируется в зависимости от модели и настроек (от «моя трёхлетняя племянница рисует лучше» до «вау, это действительно нарисовал компьютер?») | Стабильно высокое | Стабильно высокое, с уникальным художественным стилем |
| Скорость | Зависит от железа (от «пойду сделаю кофе» до «моргнуть не успеешь») | Быстрая | Средняя |
| Права | Вы владеете сгенерированными изображениями (в теории… юристы всё ещё спорят) | Ограниченные права на использование | Ограниченные права на использование |
| Ограничения контента | Минимальные (если вы запускаете локально) | Строгие фильтры безопасности | Строгие фильтры безопасности |
| Локальная работа | Да, без доступа к интернету | Нет | Нет |
| Требования к «железу» | Высокие (в идеале видеокарта, на которой можно жарить яичницу) | Нет (облачный сервис) | Нет (облачный сервис) |
Основное отличие Stable Diffusion, которое я не устану подчеркивать, как преподаватель, объясняющий разницу между «который» и «котрый» — это её открытость. Это как если бы у вас был выбор: арендовать автомобиль с ограничениями по пробегу и маршруту или купить собственный и ездить куда вздумается, модифицировать его и даже собрать новый на основе купленного.
Однако за эту свободу приходится платить — и речь не только о мощном компьютере, но и о необходимости разбираться в настройках и тонкостях работы. Если DALL-E и MidJourney — это «наведи и снимай» камеры, то Stable Diffusion больше похожа на профессиональную зеркалку со множеством настроек, в которых легко запутаться, но которые дают несравнимо больше возможностей при должном мастерстве.
И да, DALL-E может генерировать вполне приличные картинки практически из коробки, а над результатами Stable Diffusion иногда хочется посмеяться, а иногда — заплакать, особенно когда дело касается image человеческих рук (почему-то нейросети особенно «любят» рисовать людей с шестью пальцами — возможно, это какой-то тайный план по подготовке к глобальной генетической мутации, о которой нам пока не сообщили).
Варианты использования
Когда я впервые столкнулся с инструментом, мне казалось, что это просто очередная технологическая игрушка для гиков вроде меня, которые готовы часами настраивать параметры, чтобы получить картинку котика в идеальном ракурсе. Однако реальность оказалась куда интереснее и многограннее — эта нейросеть уже сейчас трансформирует целые индустрии, от дизайна до кинопроизводства.
Вот где нейросеть уже активно применяется (и нет, это не просто генерация мемов для корпоративных чатов, хотя и это тоже):
- В рекламе и маркетинге — для быстрого создания концепт-артов, визуализации идей и даже готовых рекламных материалов. Представьте, что вместо недельной работы над баннером дизайнер может генерировать десятки вариантов за час — это не просто экономия времени, это революция в рабочих процессах.
- В геймдеве — для прототипирования персонажей, локаций и предметов. Разработчики игр используют нейросеть на ранних этапах разработки, чтобы быстро визуализировать идеи и определиться с художественным стилем.
- В архитектуре и дизайне интерьеров — для создания концептуальных визуализаций пространств. «А что если эту стену сделать голубой, а диван переставить к окну?» — спрашивает клиент, и через минуту вы показываете ему готовую визуализацию.
- В производстве контента — блогеры, YouTube-каналы и онлайн-издания используют нейросеть для создания иллюстраций к статьям и видео, что значительно снижает затраты на визуальный контент.
Даже в кинопроизводстве — для создания концепт-артов, раскадровок и даже спецэффектов. И тут уже становится не до шуток, когда понимаешь, что технология, которую ты запускаешь на своем домашнем компьютере, используется Голливудом для создания фильмов с бюджетом в сотни миллионов долларов.
При этом важно понимать, что возможности не ограничиваются просто генерацией image по текстовому запросу — это лишь верхушка айсберга. Давайте рассмотрим основные функции более подробно.
Генерация изображений по текстовому описанию
Базовая и самая очевидная функция — вы вводите текст, нейросеть выдаёт картинку. Звучит просто, но дьявол, как всегда, кроется в деталях промпта (или, проще говоря, в том, как именно вы сформулируете свой запрос).
Простой промпт типа «кот» даст вам, ну… кота. Иногда с шестью лапами, иногда в неестественной позе, но определённо кота. А вот детальный промпт вроде «оранжевый полосатый кот, сидящий на подоконнике викторианского особняка и смотрящий на дождливую улицу, мягкое вечернее освещение, фотореалистичный стиль, высокая детализация» вполне может породить что-то, что не стыдно повесить на стену.

Иллюстрация демонстрирует разницу между простым и детализированным текстовым описанием. Первый промпт приводит к базовому мультяшному изображению, второй — к реалистичной, хорошо освещённой сцене с проработанными деталями. Это наглядно подчеркивает важность точной формулировки запроса в работе с нейросетью.
Дорисовка и редактирование изображений
А вот это уже интереснее — функции inpainting (дорисовка внутри) и outpainting (расширение холста) позволяют модифицировать существующие картинки. Допустим, у вас есть фотография, но на ней не хватает какого-то элемента или вы хотите что-то заменить — Stable Diffusion справится с этим за пару кликов (ну, может, за дюжину, если вы, как я, вечно путаетесь в интерфейсе).
Я лично использовал эту функцию, чтобы «расширить» старую семейную фотографию, где часть родственников была обрезана — нейросеть дорисовала недостающие элементы так, что не отличишь от оригинала. Правда, один из дядюшек внезапно обзавёлся третьей рукой, но это уже детали… К тому же, возможно, это бесценное историческое свидетельство тех генетических экспериментов, о которых история умалчивает.
Создание анимаций
Это уже продвинутый уровень использования, но да, нейросеть может и в анимацию. С помощью дополнительных инструментов и расширений (например, AnimateDiff или ControlNet) можно создавать короткие анимированные сцены — от простых движений камеры до полноценных трансформаций.
Представьте, что ваша статичная картинка с котом внезапно оживает — кот моргает, двигает ушами, поворачивает голову. Или городской пейзаж, где начинает идти дождь, загораются окна, проезжают автомобили. Эти возможности открывают совершенно новые горизонты для творчества и коммуникации.
И хотя на текущем этапе создание сложных анимаций всё ещё требует существенных навыков и дополнительных инструментов, скорость развития технологии наводит на мысль, что вскоре мы сможем генерировать полноценные видеоролики просто введя текстовое описание. Страшно? Пожалуй. Восхитительно? Безусловно.
Как пользоваться без установки
Допустим, вы не готовы превращать свой компьютер в маленький термоядерный реактор, запуская локальную версию Stable Diffusion (или просто не хотите объяснять своей второй половине, почему семейный бюджет внезапно уменьшился на стоимость видеокарты, «которая абсолютно необходима для… э-э-э… рабочих задач»). В таком случае онлайн-версии — ваш спасительный круг в море генеративных технологий.
Веб-сервисы и приложения значительно упрощают процесс работы с нейросетью, избавляя вас от головной боли с установкой, настройкой и обновлением. Это как разница между сборкой автомобиля в гараже и заказом такси — второй вариант не даёт полного контроля, зато экономит время, нервы и, как правило, деньги.
Основные преимущества онлайн-версий:
- Не нужен мощный компьютер — все вычисления происходят на удалённых серверах.
- Доступны с любого устройства с интернетом — хоть с телефона, хоть с холодильника (если он, конечно, к интернету подключен, а если нет — то зачем вам такой холодильник в 2024 году?).
- Не требуют установки и настройки — работают из коробки.
- Постоянно обновляются разработчиками.
Но есть и недостатки:
- Ограниченная функциональность по сравнению с локальной версией.
- Часто имеют лимиты на количество image или требуют платной подписки.
- Могут содержать водяные знаки на итоговых изображениях.
- Ваши запросы видны сервису (и вообще, кто знает, не используют ли они ваши гениальные промпты для обучения своих моделей?).
- Зависимость от стабильности интернет-соединения.
Лучшие веб-сервисы для работы
| Сервис | Особенности | Лимиты | Цена |
|---|---|---|---|
| DreamStudio | Официальный сервис от Stability AI, высокое качество, новейшие модели | Кредитная система, стартовый бонус при регистрации | От $10 за ~500 изображений |
| Mage.space | Простой интерфейс, хорошее качество, быстрая генерация | 25 бесплатных изображений в день | Бесплатно / $10 в месяц |
| Playground AI | Удобный интерфейс, множество моделей, включая DALL-E 3 | 1000 изображений в месяц | Бесплатно / $15 в месяц |
| Leonardo.ai | Ориентирован на геймдизайн, поддерживает стили игр | 150 изображений в день | Бесплатно / от $10 в месяц |
| NightCafe | Много моделей и стилей, система кредитов и достижений | Ограниченное число бесплатных кредитов ежедневно | Бесплатно / от $5.99 в месяц |
| getimg.ai | Интуитивный интерфейс, множество инструментов | 100 генераций в месяц | Бесплатно / от $9 в месяц |
Что поражает, так это количество этих сервисов — кажется, что они размножаются быстрее, чем я успеваю о них узнавать. Это как с кофейнями в центре города — каждый раз, проходя по знакомой улице, обнаруживаешь новую.
Как использовать Telegram-бот нейросети
Для тех, кто предпочитает не покидать уютный чат Telegram даже ради создания шедевров изобразительного искусства, существуют специальные боты. Эти маленькие кудесники хотя и не обладают всей мощью настольной версии нейросети, но справляются с базовыми задачами на удивление хорошо.
Вот пошаговая инструкция по использованию одного из таких ботов:
- Найдите в Telegram бота @stable_diffusion_bot (или любого другого с похожим функционалом).
- Нажмите кнопку «Старт» или отправьте команду /start.
- Следуйте инструкциям бота по настройке — обычно это просто пара кликов.
- Для генерации image введите команду /txt, а затем ваш промпт. Например:
/txt рыжий кот в космическом скафандре на фоне марсианского пейзажа, детализированный, в стиле цифровой живописи.
- Дождитесь результата — обычно это занимает от 10 секунд до минуты, в зависимости от загрузки сервера.
- Для дополнительных опций используйте другие команды бота, например, /help для получения списка всех доступных функций.
Преимущество ботов в Telegram — их мобильность и интеграция в привычную экосистему общения. Вы можете генерировать картинки на ходу и сразу делиться ими с друзьями, не переключаясь между приложениями. Это как иметь маленькую художественную студию прямо в кармане — удобно, практично, и совершенно очаровательно, когда работает как надо.
Как установить на компьютер
Настало время погрузиться в настоящую технологическую алхимию — установку Stable Diffusion на собственный компьютер. Предупреждаю сразу: этот процесс местами напоминает средневековый ритуал вызова демонов, только вместо пентаграмм у нас командная строка, а вместо свечей — светящиеся индикаторы на корпусе вашего ПК.
Прежде чем мы начнем, давайте убедимся, что ваш компьютер не превратится в дорогостоящий обогреватель. Минимальные требования для комфортной работы:
- Видеокарта NVIDIA с 4+ ГБ VRAM (GeForce GTX 1650 или выше)
- 16 ГБ оперативной памяти (и да, 8 ГБ формально достаточно, но вы будете страдать)
- 10+ ГБ свободного места на диске (а лучше 20-30 ГБ)
- Процессор, который выпущен в этом тысячелетии (хотя для генерации image основная нагрузка идет на видеокарту)
Если у вас Mac с чипом M1/M2, то вы тоже в игре — специальные версии Stable Diffusion работают и на них, хотя и с некоторыми ограничениями. А вот владельцам более старых Mac или компьютеров с интегрированной графикой я рекомендую вернуться к предыдущему разделу о веб-сервисах — ваша техника скажет вам «спасибо».
Выбор способа установки (готовые сборки или через терминал)
У вас есть два пути: простой и сложный. Это как выбор между поездкой в IKEA за готовой мебелью или покупкой пиломатериалов и самостоятельным строительством. Результат может быть похожим, но процесс и уровень кастомизации радикально отличаются.
Простой путь: готовые сборки
- Преимущества: быстрая установка, минимум настроек, работает «из коробки»
- Недостатки: ограниченная гибкость, не все функции доступны, сложнее обновлять
Сложный путь: установка через Git и Python
- Преимущества: полный контроль, доступ ко всем функциям, легко обновлять и модифицировать
- Недостатки: требует базовых навыков работы с командной строкой, больше шагов, выше шанс ошибки
Будучи техническим мазохистом, я, конечно, рекомендую второй путь — но только если фраза «git clone» не вызывает у вас нервный тик и желание спрятаться под одеялом. В противном случае — готовые сборки определенно ваш выбор.
Системные требования
Давайте более детально рассмотрим, что вам понадобится для комфортной работы с нейросетью:
| Параметр | Минимальные | Рекомендуемые | Оптимальные |
|---|---|---|---|
| Видеокарта | NVIDIA GTX 1650 (4 ГБ VRAM) | NVIDIA RTX 3060 (8 ГБ VRAM) | NVIDIA RTX 4080/4090 (16+ ГБ VRAM) |
| Процессор | Intel Core i5 / AMD Ryzen 5 | Intel Core i7 / AMD Ryzen 7 | Intel Core i9 / AMD Ryzen 9 |
| ОЗУ | 8 ГБ | 16 ГБ | 32+ ГБ |
| Хранилище | 10 ГБ (SSD) | 50 ГБ (SSD) | 100+ ГБ (NVMe SSD) |
| ОС | Windows 10/11, macOS, Linux | Windows 10/11, macOS, Linux | Windows 10/11, Linux |
Чем больше VRAM (видеопамяти) у вашей видеокарты, тем более крупные и качественные image вы сможете генерировать. С 4 ГБ VRAM вы ограничены примерно размером 512×512 пикселей, с 8 ГБ — можете замахнуться на 1024×1024, а с 12+ ГБ открывается простор для экспериментов с большими и детализированными изображениями.
Впрочем, если ваш компьютер не дотягивает до минимальных требований, не спешите расстраиваться — существуют специальные оптимизированные версии (например, Stable Diffusion с поддержкой CPU или с пониженным потреблением памяти), которые работают медленнее, но требуют меньше ресурсов.
Установка через Automatic1111 WebUI (рекомендуемый вариант)
AUTOMATIC1111 WebUI — это самый популярный и функциональный интерфейс для Stable Diffusion. Он как швейцарский нож в мире нейросетей — включает множество инструментов, расширений и настроек.
Для установки на Windows:
- Установите Python 3.10.x (важно: именно эту версию, не новее) с официального сайта. При установке обязательно отметьте пункт «Add Python to PATH».
- Установите Git для Windows с git-scm.com.
- Скачайте AUTOMATIC1111 WebUI через Git. Откройте командную строку или PowerShell и введите:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
- Перейдите в скачанную папку:
cd stable-diffusion-webui
- Запустите установку и первый запуск:
webui-user.bat
- Дождитесь, пока скрипт скачает все необходимые компоненты и модели. Это может занять от 10 минут до часа, в зависимости от скорости вашего интернета.
- После завершения установки в браузере автоматически откроется веб-интерфейс по адресу http://localhost:7860.
Если вы используете Mac или Linux, процесс аналогичен, только вместо .bat файла вы запускаете .sh скрипт.
Важно: при первом запуске AUTOMATIC1111 автоматически скачает базовую модель Stable Diffusion, но это лишь одна из множества доступных моделей. Позже вы сможете добавить другие, специализированные под конкретные стили или задачи.
Альтернативные способы установки
Если вы предпочитаете более простые решения или имеете специфические требования, вот несколько альтернатив:
NMKD Stable Diffusion GUI (только для Windows)
- Простая установка через исполняемый файл
- Минималистичный интерфейс, подходит для новичков
- Меньше функций, чем у AUTOMATIC1111
DiffusionBee (только для macOS, особенно для чипов M1/M2)
- Полностью нативное приложение для Mac
- Установка как обычное приложение через .dmg файл
- Оптимизировано для Apple Silicon
Google Colab (работает в браузере, нужен аккаунт Google)
- Не требует мощного компьютера — все вычисления в облаке Google
- Бесплатно (с ограничениями) или за небольшую плату
- Отличный вариант для тестирования перед установкой локальной версии
Easy Diffusion (Windows, macOS, Linux)
- Графический установщик, минимум ручной работы
- Простой и понятный интерфейс
- Подходит для быстрого старта
Лично я перепробовал почти все эти варианты и остановился на AUTOMATIC1111 — несмотря на более сложную установку, его гибкость и функциональность с лихвой компенсируют первоначальные трудности. Это как с кофемашиной: автоматическая сделает напиток одним нажатием кнопки, но профессиональная рычажная даст вам возможность экспериментировать и получать именно тот результат, который вы хотите.
Как работать в Stable Diffusion: интерфейс и настройки
Итак, вы успешно установили, и перед вами открылся интерфейс, напоминающий приборную панель космического корабля из научно-фантастического фильма категории B. Не паникуйте — несмотря на обилие кнопок, ползунков и непонятных аббревиатур, разобраться во всём этом вполне реально (хотя, признаюсь, первые пару часов я чувствовал себя обезьяной перед ядерной панелью управления).
Интерфейс AUTOMATIC1111 организован в виде вкладок, каждая из которых отвечает за определённый функционал. Основные разделы, с которыми вы будете взаимодействовать:
- txt2img — генерация image из текста (здесь вы проведёте большую часть времени)
- img2img — модификация существующих изображений
- Extras — улучшение качества, увеличение разрешения и другие операции с готовыми картинками
- PNG Info — извлечение параметров из сгенерированных image
- Settings — настройки интерфейса и параметров генерации
- Extensions — управление дополнительными модулями и расширениями
На первый взгляд это может показаться избыточным (зачем столько всего, когда я просто хочу нарисовать кота в шляпе?), но со временем вы оцените глубину и гибкость этой системы.
Основные элементы интерфейса
| Элемент | Описание | Зачем нужен |
|---|---|---|
| Prompt | Текстовое поле для ввода описания того, что вы хотите получить | Основной инструмент коммуникации с нейросетью |
| Negative Prompt | Текстовое поле для указания того, чего НЕ должно быть на картинке | Помогает избегать артефактов и нежелательных элементов |
| Sampling Method | Алгоритм, используемый для генерации | Влияет на качество и скорость создания картинки |
| Sampling Steps | Количество шагов деноизинга (очистки от шума) | Более высокие значения дают более детализированный результат |
| Width/Height | Размеры в пикселях | Определяют разрешение конечной картинки |
| Batch Count/Size | Количество сеансов генерации и изображений в каждом | Позволяет создавать множество вариаций за один запуск |
| CFG Scale | Насколько строго нейросеть следует вашему промпту | Баланс между следованием тексту и креативностью ИИ |
| Seed | Стартовое значение для генератора случайных чисел | Позволяет воспроизводить результаты или создавать вариации |
| Generate | Кнопка для запуска процесса создания | Главная кнопка, на которую вы будете нажимать чаще всего |
Казалось бы, все просто: вводишь текст, нажимаешь кнопку, получаешь результат. Но на практике это скорее похоже на настройку музыкального инструмента — недостаточно просто дернуть за струны, нужно точно знать, какую ноту вы хотите извлечь.
Основные параметры генерации
CFG Scale (Classifier Free Guidance) — параметр, который определяет, насколько строго нейросеть следует вашему промпту. Значения обычно варьируются от 1 до 30:
- Низкие значения (1-4): больше креативности, но меньше соответствия промпту
- Средние значения (5-10): хороший баланс для большинства случаев
- Высокие значения (11+): очень буквальное следование тексту, иногда в ущерб эстетике
Я обычно устанавливаю значение 7-8 для большинства генераций — это как золотая середина между «ИИ делает что хочет» и «ИИ слишком буквально воспринимает каждое слово».
Steps (шаги) — количество итераций, которые нейросеть выполняет для очистки изображения от шума. Больше шагов обычно даёт более качественный результат, но увеличивает время генерации:
- 20-30 шагов: хороший баланс между качеством и скоростью
- 40-50 шагов: для image высокого качества
- 60+ шагов: обычно не дают заметного улучшения, но съедают больше времени
Seed (сид) — начальное значение для генератора случайных чисел. Это как координаты в огромном море возможных изображений:
- -1: случайный сид каждый раз (используется по умолчанию)
- Конкретное число: позволяет воспроизвести точно такое же image или создать его вариации, меняя другие параметры
Sampling Methods (методы сэмплирования) — алгоритмы, определяющие как именно происходит очистка шума. Различаются по скорости, качеству и особенностям результата:
- DPM++ 2M Karras: обычно дает высокое качество при среднем количестве шагов
- Euler a: быстрый и достаточно качественный для многих задач
- DDIM: стабильные результаты, хорошо работает с небольшим количеством шагов
Если вся эта информация кажется вам избыточной — не волнуйтесь. Большинство параметров имеют разумные значения по умолчанию, и вы можете начать с простой генерации, постепенно экспериментируя с настройками.
Использование негативных промптов
Негативный промпт — это, пожалуй, самое недооцененное секретное оружие в арсенале пользователя Stable Diffusion. Это как список того, что вы категорически НЕ хотите видеть на картинке.
По умолчанию Stable Diffusion, особенно без дополнительной тренировки, имеет некоторые… странности. Например, нейросеть обожает рисовать людей с лишними пальцами, асимметричными лицами или странными пропорциями. Также она часто добавляет размытый текст, непонятные артефакты и другие нежелательные элементы.
Для борьбы с этими причудами существует целая культура негативных промптов. Вот пример базового негативного промпта, который я использую почти всегда:
ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, extra limbs, disfigured, deformed, body out of frame, bad anatomy, watermark, signature, cut off, low contrast, underexposed, overexposed, bad art, beginner, amateur
Это примерно можно перевести как «пожалуйста, не рисуй это так, как будто ты пьяный художник с палкой вместо руки». И, что удивительно, это действительно работает — качество изображений с правильным негативным промптом заметно повышается.
Для разных типов image можно использовать специализированные негативные промпты. Например, для портретов часто добавляют «asymmetrical eyes, cross-eyed», а для пейзажей — «blurry, hazy». Это как маленькая шпаргалка для нейросети, напоминание о том, чего делать не стоит.
Как составить качественный запрос (prompt) для генерации
Составление качественного промпта — это тот навык, который превращает случайного пользователя Stable Diffusion в настоящего «промпт-инженера» (да, такое словосочетание действительно существует, и некоторые люди даже вносят его в резюме, что вызывает у меня смешанные чувства, колеблющиеся между восхищением и лёгким недоумением).
Промпт для нейросети — это как рецепт для шеф-повара: чем точнее и детальнее инструкции, тем ближе результат к вашим ожиданиям. Однако, в отличие от настоящего шеф-повара, нейросеть не может переспросить, если чего-то не поняла, и не обладает интуицией, чтобы восполнить недостающие детали.
После сотен (если не тысяч) экспериментов я пришёл к выводу, что хороший промпт обычно содержит несколько ключевых элементов, расположенных в определённом порядке. И да, порядок действительно имеет значение — Stable Diffusion придаёт больший вес словам в начале промпта.
Структура эффективного промпта
Идеальный промпт обычно состоит из следующих компонентов:
- Основной объект или сцена — что именно вы хотите увидеть на картинке. Начинайте с самого важного. Например: «портрет молодой женщины» или «средневековый замок на скалистом утёсе».
- Детали и атрибуты объекта — конкретные характеристики, которые делают изображение уникальным. Например: «с длинными рыжими волосами, в зелёном платье» или «с высокими башнями и каменными стенами».
- Обстановка и контекст — окружение, освещение, время суток, погода. Например: «в солнечный день, мягкое освещение» или «во время грозы, с молнией на заднем плане».
- Стиль — художественный стиль, техника, источник вдохновения. Например: «в стиле акварельной живописи» или «в стиле концепт-арта для видеоигры».
- Технические параметры — качество, разрешение, ракурс. Например: «детализированное, 8k, фотореалистичное» или «широкоугольный снимок».
Соединяя эти элементы вместе, мы получаем полноценный промпт:
Портрет молодой женщины с длинными рыжими волосами, в зелёном платье, в солнечный день, мягкое освещение, в стиле акварельной живописи, детализированное, 8k
Важно не перегружать промпт лишними деталями — нейросеть не всегда успешно справляется с противоречивыми или слишком сложными инструкциями. Лучше сосредоточиться на самых важных аспектах image.
Инструменты для улучшения промптов
К счастью, вам не нужно изобретать велосипед каждый раз, когда хочется создать новое изображение. Существует множество инструментов и ресурсов, которые помогут составить эффективный промпт:
- Lexica.art — это настоящая сокровищница промптов и image. Вы можете найти здесь практически любой стиль или тематику, изучить, какие слова и конструкции используются для получения определённых результатов. Это как Google Images, только для промптов Stable Diffusion.
- Promptomania — специализированный инструмент для создания промптов с визуальным конструктором. Вы выбираете категории и параметры из предложенных вариантов, а система формирует готовый текст. Идеально для новичков, которые ещё не освоили «промпт-фу».
- ChatGPT или другие языковые модели — могут помочь сформулировать детальное описание для вашей идеи. Просто попросите ИИ составить промпт для Stable Diffusion на основе вашей концепции — и вы получите структурированный текст, который можно использовать или доработать.
- PromptGenerator.ai — специализированный ИИ для создания эффективных промптов под конкретные нейросети, включая Stable Diffusion. Особенно полезен, когда у вас есть только общая идея, но сложно сформулировать детали.
- Midjourney Discord Community — несмотря на то, что это сообщество другой нейросети, многие приёмы работы с промптами универсальны, и там вы найдёте множество подсказок и примеров.
Я часто использую комбинацию этих инструментов: начинаю с базовой идеи, ищу похожие imageна Lexica.art, анализирую их промпты, а затем дорабатываю под свои нужды, иногда с помощью ChatGPT для более точных формулировок.
Примеры удачных промптов
| Тип | Промпт | Результат |
|---|---|---|
| Портрет | «studio portrait of a beautiful young woman with short blonde hair and blue eyes, wearing a red blazer, professional photography, soft lighting, detailed face, photorealistic, 85mm lens, f/1.8, Fujifilm XT4» | Высококачественный фотореалистичный портрет с конкретными характеристиками фотографии |
| Пейзаж | «breathtaking landscape of mountain valley at sunset, warm golden hour lighting, lush forest, small river, dramatic clouds, photorealistic, detailed, 8k, wide angle, landscape photography» | Детализированный пейзаж с эффектным освещением и атмосферой |
| Фэнтезийная сцена | «ancient wizard’s tower on a floating island, surrounded by clouds, mystical aura, magical crystals glowing with blue light, digital art, detailed illustration, fantasy concept art, trending on ArtStation» | Стилизованная фэнтезийная иллюстрация в популярном стиле |
| Арт в конкретном стиле | «portrait of a samurai warrior in ukiyo-e style, traditional Japanese woodblock print, vibrant colors, detailed armor, dramatic pose, artistic» | Изображение, имитирующее конкретный исторический художественный стиль |
Обратите внимание, как каждый промпт содержит не только описание объекта, но и технические детали, стиль, качество image. Именно эти дополнительные параметры часто превращают «сносное» изображение в «вау-эффект».
И ещё один лайфхак: не стесняйтесь использовать англоязычные промпты, даже если английский не ваш родной язык. Большинство моделей Stable Diffusion обучались преимущественно на англоязычных данных и работают с ними существенно лучше, чем с другими языками. Простой перевод промпта может заметно улучшить результат (а Google Translate всегда под рукой).
Расширенные возможности
Если вы освоили базовые функции Stable Diffusion и вам уже не так интересно генерировать однотипные картинки, самое время погрузиться в расширенные возможности. Это как переход от вождения автомобиля в режиме «просто добраться из пункта А в пункт Б» к участию в гоночных соревнованиях — те же основные принципы, но совершенно новый уровень мастерства и возможностей.
Самое прекрасное в экосистеме вокруг Stable Diffusion — её постоянное развитие. Практически каждый день появляются новые расширения, модели и инструменты, расширяющие границы возможного. И хотя я физически не могу охватить всё в рамках одной статьи (для этого потребовалась бы целая книга, причём постоянно обновляемая), я расскажу о наиболее полезных и впечатляющих функциях.
Обучение модели на собственных данных
Пожалуй, самая захватывающая возможность — это адаптация (или «файнтюнинг») нейросети под ваши конкретные задачи. Представьте, что вы можете обучить Stable Diffusion генерировать изображения в стиле ваших собственных работ, рисовать конкретного персонажа или даже создавать портреты, похожие на вас или ваших близких.
Существует несколько основных подходов к обучению:
- Textual Inversion — относительно простой метод, требующий всего 3-5 image в одном стиле. В результате вы получаете специальное «эмбеддинг» — файл, который содержит закодированное представление этого стиля. Затем вы можете использовать специальный токен в ваших промптах (например, <моя_кошка>), и нейросеть будет генерировать изображения, включающие этот элемент.
- Процесс обучения занимает от 30 минут до нескольких часов, в зависимости от вашего оборудования и желаемого качества результата. Этот метод хорошо подходит для объектов с характерными визуальными признаками — например, чашки с уникальным рисунком или конкретного здания.
- DreamBooth — более продвинутый метод, требующий больше вычислительных ресурсов, но дающий более впечатляющие результаты. Для обучения нужно 10-20 image объекта с разных ракурсов и в разных условиях. На выходе вы получаете полноценную модель, которая может генерировать вариации этого объекта в различных ситуациях.
- Этот метод отлично работает для обучения на лицах (создание цифровых двойников), персонажей, уникальных объектов и даже стилей. Однако, будьте готовы к тому, что обучение может занять от нескольких часов до суток, и вам понадобится видеокарта с хорошим объёмом памяти (минимум 12 ГБ VRAM, а лучше 24 ГБ).
- LoRA (Low-Rank Adaptation) — золотая середина между Textual Inversion и DreamBooth. Этот метод позволяет создавать компактные модули-адаптеры, которые можно применять к базовой модели Stable Diffusion. LoRA обычно занимает всего 100-300 МБ (по сравнению с 2-4 ГБ для полной модели) и может быть обучена за 1-3 часа на 8 ГБ VRAM.
- Преимущество LoRA — возможность комбинировать несколько адаптеров одновременно. Например, вы можете применить LoRA для стиля аниме, LoRA для конкретного персонажа и LoRA для определённого типа одежды — и получить аниме-версию этого персонажа в этой одежде.
Процесс обучения для всех этих методов доступен прямо из интерфейса AUTOMATIC1111 с помощью соответствующих расширений. Вам не нужно быть программистом или дата-сайентистом — достаточно подготовить набор изображений, указать несколько параметров и запустить процесс.
Улучшение качества изображений с помощью AI-апскейлеров
Еще одна мощная возможность — это улучшение качества и увеличение разрешения изображений с помощью AI-апскейлеров. Это особенно полезно, если вы хотите использовать созданные image для печати или на больших экранах.
По умолчанию многие модели Stable Diffusion генерируют изображения разрешением 512×512 или 768×768 пикселей. Это нормально для просмотра на экране смартфона, но явно недостаточно для крупноформатной печати или дисплеев высокого разрешения.
В AUTOMATIC1111 встроено несколько апскейлеров:
- ESRGAN — классический апскейлер, который хорошо справляется с увеличением разрешения в 2-4 раза без потери деталей. Особенно хорош для фотореалистичных image.
- LDSR (Latent Diffusion Super Resolution) — использует технологию, аналогичную самой Stable Diffusion, но специализированную для увеличения разрешения. Работает медленнее, но часто даёт лучшие результаты, особенно для сложных текстур.
- SD Upscale — умный гибрид, который сначала увеличивает изображение с помощью базового алгоритма, а затем использует Stable Diffusion для восстановления и добавления деталей. Этот метод позволяет не только увеличить разрешение, но и улучшить качество изображения, исправив артефакты и нечёткие области.
Для максимального контроля вы можете использовать сочетание различных апскейлеров, применяя их последовательно или к разным частям изображения. Например, сначала увеличить всё image с помощью ESRGAN, а затем применить SD Upscale только к лицам персонажей для улучшения деталей.
Кроме того, существуют специализированные модели для улучшения конкретных аспектов изображения:
- GFPGAN и CodeFormer — для улучшения лиц, исправления непропорциональных черт и добавления реалистичных деталей.
- SwinIR — для общего улучшения качества с минимальными искажениями оригинала.
Комбинируя эти инструменты, вы можете превратить изначально скромное image 512×512 в высококачественную картинку разрешением 2048×2048 или даже больше, пригодную для печати и профессионального использования.
И самое приятное — все эти инструменты интегрированы в интерфейс AUTOMATIC1111 и доступны буквально в несколько кликов. Никакого дополнительного программного обеспечения или сложных настроек не требуется.
Этические и юридические вопросы
Ах, мы подошли к той части, где даже самые опытные юристы начинают нервно теребить галстуки и бормотать что-то вроде «ну, это зависит от контекста» и «законодательство в этой области все еще формируется». Приготовьтесь к увлекательному путешествию в мир правовой неопределенности!
Вопрос о правах на image, созданные с помощью нейросетей, напоминает мне ситуацию с первыми автомобилями, когда законы предписывали, чтобы перед каждой машиной шел человек с красным флагом, предупреждая о ее приближении. Технологии развиваются гораздо быстрее, чем законодательство успевает за ними угнаться.
Авторские права и лицензирование
Кому принадлежат права на изображение, созданное Stable Diffusion? Ответ на этот вопрос настолько однозначен, насколько однозначна инструкция по сборке мебели из IKEA. То есть, совсем неоднозначен.
В большинстве юрисдикций (включая США и Европу) авторское право на произведение принадлежит человеку, который его создал. Это фундаментальный принцип, заложенный в законы об авторском праве задолго до появления искусственного интеллекта. Проблема в том, что нейросеть не является человеком (по крайней мере, пока Скайнет не захватил мир).
Текущая юридическая практика склоняется к тому, что права на image, сгенерированные нейросетью, принадлежат:
- Пользователю, который создал промпт и настроил параметры генерации
- И/или компании Stability AI, которая создала саму нейросеть
- И/или (частично) авторам, чьи работы использовались для обучения модели
При этом многие юристы сходятся во мнении, что человек, который ввел промпт, имеет по крайней мере некоторые права на результат — примерно как фотограф имеет права на фотографии, даже если он не изобрел фотоаппарат.
Stability AI занимает относительно либеральную позицию. В своей лицензии для версии 1.x они указывают, что пользователи могут свободно использовать сгенерированные изображения, включая коммерческое использование. Однако, с выходом новых версий и моделей условия могут меняться, поэтому всегда стоит проверять актуальную лицензию.
А теперь самое интересное: в некоторых странах (например, США) работы, созданные исключительно ИИ, вообще не могут быть защищены авторским правом! Бюро авторских прав США недавно постановило, что только работы с «человеческим авторством» подлежат защите. Это создает удивительную ситуацию, когда image, созданные Stable Diffusion, могут фактически оказаться в общественном достоянии в одних странах, но защищены авторским правом в других.
Моя личная рекомендация (не являющаяся юридической консультацией, ибо я не юрист, а просто технарь с излишне развитым чувством сарказма):
- Для личного использования можно не беспокоиться
- Для коммерческого использования лучше получить консультацию юриста, специализирующегося на интеллектуальной собственности
- Избегайте использования явных имитаций стиля конкретных художников без их разрешения
- Обязательно проверьте актуальную лицензию модели, которую вы используете
Этические аспекты использования
Помимо юридических вопросов существует целый клубок этических проблем, связанных с генеративными нейросетями. И хотя многие из этих проблем не имеют простых решений, осознание их существования — уже половина дела.
Использование чужих работ для обучения модели
Stable Diffusion и подобные ей нейросети обучаются на миллионах изображений, собранных из интернета, зачастую без явного согласия авторов. Это вызывает законные вопросы: справедливо ли использовать чужие работы для создания системы, которая потенциально может заменить самих авторов?
Некоторые художники активно выступают против такого использования их работ, и несколько громких судебных процессов уже инициированы. Результаты этих разбирательств могут серьезно повлиять на будущее всей индустрии ИИ.
Имитация стилей известных художников
С помощью Stable Diffusion можно создавать изображения «в стиле» конкретных художников, как живых, так и умерших. Это создает этическую дилемму: с одной стороны, художники всегда вдохновлялись работами друг друга; с другой — автоматизированная имитация стиля без согласия автора или его наследников выглядит как минимум сомнительно.
Представьте, что кто-то создает тысячи «новых работ» в вашем узнаваемом стиле и продает их, не выплачивая вам ни копейки. Справедливо ли это? Для многих ответ очевиден: нет. Но граница между «вдохновением» и «имитацией» остается размытой.
Deepfakes и дезинформация
С развитием генеративных технологий становится все сложнее отличить реальные фотографии от сгенерированных. Это открывает дорогу для создания deepfakes — поддельных изображений или видео, которые могут быть использованы для дезинформации, манипуляций или даже шантажа.
Соблазн использовать Stable Diffusion для создания фейковых «компрометирующих» изображений с известными личностями или просто с вашими знакомыми может быть велик, но этические последствия таких действий могут быть серьезными.
Усиление предубеждений и стереотипов
Нейросети, обучаемые на данных из интернета, неизбежно впитывают существующие в обществе предубеждения и стереотипы. Это может приводить к тому, что Stable Diffusion будет генерировать образы, закрепляющие эти стереотипы — например, показывая определенные профессии преимущественно связанными с одним полом или расой.
Разработчики активно работают над снижением этих эффектов, но полностью избавиться от них практически невозможно — ведь модель отражает общество, с его достоинствами и недостатками.
В конечном счете, каждый пользователь Stable Diffusion сам решает, как этично использовать эту технологию. Я лишь призываю к осознанности и уважению к правам и чувствам других людей. Технология сама по себе нейтральна — все зависит от того, как мы ее применяем.
Заключение
Мы с вами прошли увлекательный путь от понимания основ Stable Diffusion до изучения её продвинутых возможностей, и если ваша голова пока не взорвалась от количества информации — примите мои искренние поздравления. Вы, похоже, из той же породы технооптимистов, что и я.
Stable Diffusion — это не просто очередная технологическая игрушка, а настоящий переворот в том, как мы создаём и взаимодействуем с визуальным контентом. Представьте: ещё пять лет назад идея о том, что обычный человек сможет генерировать фотореалистичные изображения на своём компьютере, описывая их текстом, казалась бы научной фантастикой. Сегодня это реальность, доступная каждому (ну, почти каждому — при условии наличия более-менее приличного компьютера и толики терпения для борьбы с установкой).
Особенно впечатляет открытость этой технологии. В мире, где крупные технологические компании всё чаще закрывают свои разработки за стенами патентов и подписок, нейросеть демонстрирует, что открытый код и сообщество энтузиастов могут создавать инструменты, не уступающие (а порой и превосходящие) коммерческие аналоги.
Конечно, как и любая мощная технология, Stable Diffusion вызывает множество вопросов — этических, юридических, экономических. Что происходит с профессией художника-иллюстратора в мире, где компьютер может создать тысячи вариаций иллюстраций за время, которое человеку потребовалось бы на создание одной? Кому принадлежат права на сгенерированные изображения? Как отличить реальную фотографию от созданной ИИ?
На многие из этих вопросов у нас пока нет однозначных ответов. Законодательство едва поспевает за технологическим прогрессом, а общество только начинает осознавать масштабы предстоящих изменений.
Но одно можно сказать наверняка: Stable Diffusion и подобные ей технологии ИИ уже меняют мир прямо сейчас. И независимо от того, видите ли вы в этом угрозу или возможность, лучше быть готовым к этим изменениям. Надеюсь, эта статья помогла вам сделать первый шаг к пониманию и освоению нового инструмента, который может существенно расширить границы вашего творчества.
Если вы хотите не только использовать Stable Diffusion, но и углубиться в визуальное оформление, обратите внимание на подборку лучших курсов по веб-дизайну. Там вы найдете программы, которые помогут развить вкус, прокачать навыки дизайна и лучше понимать визуальные тренды.
Рекомендуем посмотреть курсы по веб-дизайну
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Профессия Веб-дизайнер
|
Eduson Academy
114 отзывов
|
Цена
60 171 ₽
101 484 ₽
Ещё -8% по промокоду
|
От
5 014 ₽/мес
Беспроцентная. На 1 год.
8 457 ₽/мес
|
Длительность
2 месяца
|
Старт
22 марта
|
Подробнее |
|
Веб-дизайн 3.0
|
Skillbox
232 отзыва
|
Цена
120 984 ₽
201 648 ₽
Ещё -33% по промокоду
|
От
5 041 ₽/мес
На 24 месяца
8 402 ₽/мес
|
Длительность
9 месяцев
|
Старт
25 марта
|
Подробнее |
|
Веб-дизайнер
|
Нетология
46 отзывов
|
Цена
83 460 ₽
139 100 ₽
с промокодом kursy-online
|
От
3 477 ₽/мес
Без переплат на 2 года.
|
Длительность
6 месяцев
|
Старт
6 апреля
|
Подробнее |
|
Интенсив Визуальное исследование
|
Bang Bang Education
75 отзывов
|
Цена
7 700 ₽
|
|
Длительность
21 день
|
Старт
идет донабор
|
Подробнее |
|
Веб-дизайнер
|
Академия Синергия
38 отзывов
|
Цена
93 156 ₽
|
От
3 882 ₽/мес
0% на 24 месяца
|
Длительность
6 месяцев
|
Старт
31 марта
|
Подробнее |

OTUS vs SkillFactory: автотесты — где больше «пишем код», а где больше «разбираем подходы»
Если вы ищете курс по автоматизации тестирования, который сочетает теорию и практику, вы попали по адресу. В этой статье мы сравниваем два популярных курса: OTUS и SkillFactory, чтобы помочь вам определиться с выбором. Какой из них поможет вам быстрее освоить важнейшие навыки тестирования? Читайте и узнайте все подробности!

OTUS vs ProductStar: куда идти технарю, чтобы стать продактом — честное сравнение подходов
OTUS или ProductStar — что выбрать, если вы хотите перейти в продакт-менеджмент? Разбираем разницу в обучении, практике и результате, чтобы вы не потратили время зря.

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.