Структуры данных: что это, виды и примеры применения
В современном программировании эффективная организация информации становится краеугольным камнем успешной разработки.

Структуры данных — это не просто академическая концепция, а практический инструмент, который определяет производительность приложений и качество кода.
- Что такое структура данных
- Зачем нужны структуры данных в программировании
- Классификация структур данных
- Основные структуры данных и их особенности
- Как выбрать подходящую структуру данных
- Заключение
- Рекомендуем посмотреть курсы по программированию на PHP
Что такое структура данных
Структура данных в программировании представляет собой специализированный контейнер, который организует и хранит информацию по определенным правилам. Можно представить это как систему папок на компьютере — каждая имеет свою логику организации файлов, что упрощает поиск и работу с данными.
По своей сути структуры данных решают фундаментальную задачу: как эффективно разместить информацию в памяти компьютера и обеспечить быстрый доступ к ней. Вместо того чтобы создавать отдельную переменную для каждого элемента данных (что привело бы к хаосу в коде), мы используем структуры для группировки связанной информации.
Связь с алгоритмами здесь неразрывна — каждая структура данных поддерживает определенный набор операций: добавление элементов, поиск, удаление, сортировку. Выбор конкретной структуры напрямую влияет на производительность этих операций и, следовательно, на работу всего приложения.
Зачем нужны структуры данных в программировании
В практике разработки структуры данных играют роль архитектурного фундамента любого приложения. Представим ситуацию: нам нужно создать систему управления библиотекой. Без структур данных мы бы создавали отдельные переменные для каждой книги, что превратило бы код в неуправляемый хаос уже при сотне экземпляров.
Основная ценность структур данных заключается в оптимизации трех ключевых аспектов разработки. Во-первых, они обеспечивают упорядоченное хранение информации — данные организуются логически понятным способом, что упрощает понимание и поддержку кода.
Во-вторых, структуры данных критически важны для производительности. Выбор подходящей структуры может означать разницу между поиском элемента за миллисекунду или за несколько секунд. Например, поиск в хэш-таблице выполняется практически мгновенно, в то время как линейный поиск по неупорядоченному списку может занимать значительное время.
Третий аспект — это экономия памяти. Грамотно подобранная структура данных позволяет избежать дублирования информации и минимизировать расход ресурсов. В эпоху больших данных и мобильных устройств это становится особенно актуальным.
Реальные примеры применения включают кэширование веб-страниц (используются hash-map), обработку очередей задач в многопоточных приложениях, организацию файловых систем и даже алгоритмы рекомендаций в социальных сетях.
Классификация структур данных
Понимание различных типов структур данных требует систематического подхода к их классификации. В программировании мы используем несколько критериев для группировки структур, что помогает выбрать оптимальное решение для конкретной задачи.
Диаграмма показывает распределение структур данных по категориям: линейные, нелинейные, статические и динамические. Такой формат помогает быстро увидеть, какие группы чаще встречаются в практике.
По представлению данных в памяти
Первый критерий разделения касается того, как структуры данных взаимодействуют с памятью компьютера. Физические структуры отражают реальное расположение данных в оперативной памяти — здесь важны конкретные адреса и способы размещения информации. Массивы являются типичным примером: элементы располагаются в памяти последовательно, что обеспечивает быстрый доступ по индексу.
Логические структуры, напротив, определяют концептуальные связи между элементами данных, не привязываясь к физическому расположению. Связанные списки демонстрируют этот принцип: элементы могут быть разбросаны по памяти, но логически связаны через указатели.
По составу
Разделение по составу помогает понять внутреннюю архитектуру структур данных. Простые структуры представляют собой неделимые единицы — например, целые числа или символы. Их размер и способ хранения четко определены на уровне языка программирования.
Сложные структуры формируются из комбинации других структур, создавая иерархические системы данных. Например, массив структур, где каждая структура содержит несколько полей различных типов.
По связи между элементами
Этот критерий определяет способ организации отношений между данными. Несвязные структуры, такие как массивы и стеки, не содержат явных указателей между элементами — их связь обеспечивается порядком расположения или правилами доступа.
Связные структуры используют явные ссылки для создания отношений между элементами. Связанные списки и деревья являются классическими примерами таких структур.
По изменяемости
Статические структуры имеют фиксированный размер, определяемый на этапе создания. Классические массивы демонстрируют этот подход — после объявления массива из 100 элементов мы не можем изменить его размер.
Динамические структуры адаптируются к изменяющимся требованиям программы, позволяя добавлять или удалять элементы во время выполнения. Полустатические структуры занимают промежуточное положение, предоставляя ограниченные возможности изменения.
По упорядоченности
Линейные структуры организуют данные в последовательность, где каждый элемент имеет четко определенных предшественника и преемника. Массивы, списки, стеки и очереди относятся к этой категории.
Нелинейные структуры создают более сложные отношения между элементами, позволяя ветвления и циклические связи. Деревья и графы являются наиболее распространенными примерами нелинейных структур данных.
Основные структуры данных и их особенности
В практике программирования мы чаще всего сталкиваемся с ограниченным набором структур данных, которые покрывают большинство потребностей разработки. Рассмотрим каждую из них с точки зрения практического применения.
Массивы (Array)
Массивы представляют собой самую фундаментальную структуру данных — последовательность элементов одного типа, размещенных в памяти непрерывно. Каждый элемент имеет уникальный индекс, начинающийся с нуля в большинстве языков программирования. Главное преимущество массивов — мгновенный доступ к любому элементу по индексу, что обеспечивает константную временную сложностьO(1).

Массив хранит элементы последовательно в памяти и обеспечивает быстрый доступ по индексу. Визуализация помогает увидеть логику нумерации и хранения.
Применяются массивы для хранения небольших коллекций данных, когда известен максимальный размер и требуется быстрый доступ к элементам. Примеры включают координаты точек в графических приложениях, хранение пикселей изображения или результатов измерений в научных вычислениях.
Динамические массивы
Динамические массивы решают основное ограничение обычных массивов — фиксированный размер. Они автоматически расширяются при добавлении новых элементов, обычно увеличивая внутренний размер в два раза при достижении лимита.
Используются в ситуациях с непредсказуемым объемом данных: списки пользователей в приложении, история действий, результаты поискового запроса. В современных языках программирования это ArrayList в Java или vector в C++.
Связные списки (Linked List)
Связные списки состоят из узлов, каждый из которых содержит данные и ссылку на следующий элемент. Это позволяет эффективно вставлять и удалять элементы в любой позиции без перемещения остальных элементов, в отличие от массивов.

Связный список состоит из узлов, соединённых ссылками. Такая структура упрощает добавление и удаление элементов.
Применение находят в реализации файловых систем (список свободных блоков), создании хэш-таблиц с разрешением коллизий методом цепочек, а также в системах управления памятью. Двусвязные списки дополнительно содержат ссылки на предыдущий элемент, что позволяет перемещаться в обоих направлениях.
Стек (Stack)
Стек реализует принцип LIFO (Last In, First Out) — последний добавленный элемент будет первым извлеченным. Представить стек можно как стопку тарелок: мы можем добавить тарелку только наверх и взять тоже только верхнюю.
Критически важен для реализации рекурсивных алгоритмов, где каждый вызов функции добавляется в стек вызовов. Также применяется для отмены операций (Undo) в редакторах, вычисления математических выражений и синтаксического анализа в компиляторах.
Очередь и двусторонняя очередь (Queue, Deque)
Очередь следует принципу FIFO (First In, First Out) — элементы обрабатываются в порядке их добавления. Двусторонняя очередь (deque) позволяет добавлять и извлекать элементы с обеих сторон, комбинируя возможности стека и очереди.
Очереди незаменимы в многопоточных приложениях для организации задач, буферизации данных между быстрыми и медленными процессами, а также в алгоритмах обхода графов в ширину (BFS).
Множество (Set)
Множества хранят уникальные элементы без определенного порядка, поддерживая математические операции: объединение, пересечение, разность. Дублирование элементов автоматически предотвращается.
Применяются для хранения уникальных идентификаторов пользователей, токенов сессий, а также в алгоритмах, где важна уникальность данных — например, при подсчете уникальных посетителей сайта.
Словарь / Map
Словари хранят пары «ключ-значение», где каждый ключ уникален. Это обеспечивает быстрый поиск значения по известному ключу, обычно с временной сложностью O(1) в среднем случае.
Широко используются для кэширования данных, конфигурационных файлов, индексирования в базах данных. В веб-разработке словари применяются для передачи параметров между клиентом и сервером.
Деревья (Trees)
Деревья организуют данные в иерархическую структуру с корневым узлом и ветвящимися потомками. Бинарное дерево поиска поддерживает порядок элементов: левые потомки меньше родителя, правые — больше или равны.
Идеально подходят для хранения иерархических данных: файловая система, организационная структура компании, синтаксические деревья в компиляторах. Обеспечивают эффективный поиск, вставку и удаление с логарифмической сложностью.
Графы (Graphs)
Графы состоят из вершин (узлов) и ребер (связей между ними). Могут быть ориентированными (с направленными связями) или неориентированными, взвешенными (с весами ребер) или невзвешенными.
Применяются для моделирования социальных сетей (связи между пользователями), транспортных систем (маршрутизация), интернета (связи между сайтами), а также в алгоритмах машинного обучения для представления знаний.
| Структура | Доступ | Поиск | Вставка | Удаление | Применение |
| Массив | O(1) | O(n) | O(n) | O(n) | Индексированные данные |
| Связный список | O(n) | O(n) | O(1) | O(1) | Частые вставки/удаления |
| Стек | O(1) | — | O(1) | O(1) | Рекурсия, отмена операций |
| Очередь | O(1) | — | O(1) | O(1) | Буферизация, планирование |
| Хэш-таблица | O(1) | O(1) | O(1) | O(1) | Быстрый поиск по ключу |
| Дерево поиска | O(log n) | O(log n) | O(log n) | O(log n) | Упорядоченные данные |
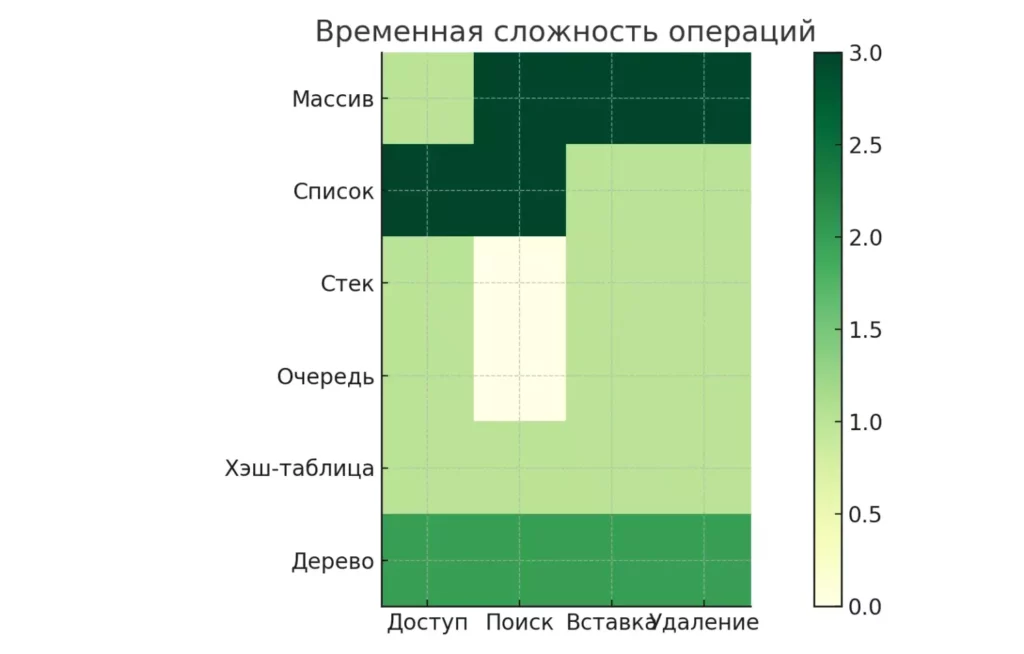
Тепловая карта демонстрирует сравнительные затраты времени на основные операции для разных структур данных. Чем светлее ячейка, тем эффективнее выполняется операция.
Как выбрать подходящую структуру данных
Выбор оптимальной структуры данных напоминает подбор инструмента для конкретной задачи — универсального решения не существует, но есть четкие критерии для принятия решения.
Временная сложность операций становится ключевым фактором при работе с большими объемами данных. Если приложению необходимо выполнять миллионы поисковых запросов, разница между O(1) хэш-таблицы и O(n) линейного поиска в массиве может составлять часы работы процессора. Аналогично, для задач с частыми вставками и удалениями связанные списки предпочтительнее массивов.
Пространственная сложность требует баланса между скоростью и расходом памяти. Хэш-таблицы обеспечивают быстрый доступ, но могут использовать в несколько раз больше памяти, чем массивы. В условиях ограниченных ресурсов — например, в embedded-системах или мобильных приложениях — этот фактор становится критическим.
Характер операций с данными также определяет выбор. Для последовательной обработки элементов оптимальны массивы или списки. Когда важен порядок обработки по приоритету, используют кучи (heap). Для задач с отменой операций незаменим стек.
Практический подход заключается в анализе конкретных требований: какие операции выполняются чаще, каков ожидаемый объем данных, есть ли ограничения по памяти. В современной разработке часто применяют концепцию абстрактных типов данных (ADT), которые позволяют менять внутреннюю реализацию без изменения интерфейса, что упрощает оптимизацию производительности на более поздних этапах разработки.
Заключение
Структуры данных представляют собой фундаментальный инструментарий современного программирования, определяющий эффективность и качество разрабатываемых решений. Понимание их принципов работы позволяет создавать производительные приложения и избегать критических узких мест в архитектуре системы. Подведем итоги:
- Структуры данных — фундамент программирования. Они определяют, как информация хранится и обрабатывается в приложениях.
- Выбор правильной структуры влияет на производительность. Правильное решение позволяет ускорить поиск и снизить нагрузку на память.
- Основные структуры применяются в реальных проектах. От массивов до графов — каждая из них решает конкретные задачи.
- Понимание классификации помогает ориентироваться. Деление на линейные, нелинейные, статические и динамические структуры облегчает выбор.
- Знание временной сложности — ключ к оптимизации. Сравнение операций показывает, какая структура эффективнее в конкретном случае.
Если вы только начинаете осваивать профессию разработчика, рекомендуем обратить внимание на подборку курсов по PHP-разработке. В них есть как теоретическая база, так и практические задания для закрепления знаний. Это поможет быстрее перейти от понимания основ к решению реальных задач.
Рекомендуем посмотреть курсы по программированию на PHP
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Frontend-разработчик
|
Eduson Academy
114 отзывов
|
Цена
116 400 ₽
|
От
9 700 ₽/мес
|
Длительность
12 месяцев
|
Старт
6 апреля
|
Подробнее |
|
Frontend-разработчик
|
Нетология
46 отзывов
|
Цена
120 700 ₽
268 288 ₽
с промокодом kursy-online
|
От
3 726 ₽/мес
На 2 года
|
Длительность
13 месяцев
|
Старт
5 апреля
|
Подробнее |
|
PHP-разработчик. Базовый уровень
|
Skillbox
232 отзыва
|
Цена
80 990 ₽
161 979 ₽
Ещё -20% по промокоду
|
От
6 749 ₽/мес
Без переплат на 1 год.
|
Длительность
3 месяца
|
Старт
23 марта
|
Подробнее |
|
Web-разработчик
|
ProductStar
52 отзыва
|
Цена
100 224 ₽
250 560 ₽
Ещё -5% по промокоду
|
От
2 784 ₽/мес
Рассрочка на 2 года.
|
Длительность
10 месяцев
|
Старт
22 марта
|
Подробнее |
|
Веб-разработчик с нуля
|
Нетология
46 отзывов
|
Цена
163 300 ₽
302 470 ₽
с промокодом kursy-online
|
От
5 041 ₽/мес
Без переплат на 2 года.
7 222 ₽/мес
|
Длительность
17 месяцев
|
Старт
5 апреля
|
Подробнее |

OTUS vs ProductStar: куда идти технарю, чтобы стать продактом — честное сравнение подходов
OTUS или ProductStar — что выбрать, если вы хотите перейти в продакт-менеджмент? Разбираем разницу в обучении, практике и результате, чтобы вы не потратили время зря.

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.

OTUS vs GeekBrains для backend: где строже к качеству кода и полезнее ревью
OTUS или GeekBrains — где обучение backend-разработке даёт более строгий подход к качеству кода? Разбираем, как устроено code review, какие инженерные практики используют школы и как проверить уровень ревью до оплаты курса.