Управление выполнением в Python: break, continue, await и многопоточность простыми словами
Управление потоком выполнения программы — это фундаментальный навык, который отличает начинающего разработчика от уверенного практика. Python предоставляет нам два уровня контроля: первый работает внутри одного потока исполнения (операторы break, continue и await), второй позволяет организовать параллельную работу через многопоточность и механизмы синхронизации.

Зачем это нужно? Представьте, что вы обрабатываете список из миллиона элементов в поисках одного конкретного значения. Без оператора break ваша программа будет упорно перебирать все элементы, даже когда нужный уже найден. Или взять ситуацию, когда несколько частей программы должны одновременно обращаться к одной БД — без правильной синхронизации потоков вы рискуете получить испорченные данные или «гонку условий» (race condition).
Мы рассмотрим весь спектр инструментов — от простых операторов управления циклами до механизмов асинхронного программирования и многопоточности. Наша задача — показать, когда применять каждый из них, какие подводные камни существуют и как избежать типичных ошибок. Независимо от того, пишете ли вы простой скрипт для автоматизации задач или разрабатываете высоконагруженный веб-сервис, понимание этих концепций критически важно для создания эффективного и надежного кода.
- Базовые инструменты управления выполнением в Python
- Оператор break: полное завершение цикла
- Оператор continue: пропуск итерации
- Асинхронность и оператор await: управление событиями без блокировок
- Что такое потоки в Python и как они работают
- Модуль threading: создание и запуск потоков
- Механизмы синхронизации потоков
- Очереди для потокобезопасного обмена данными
- Старый модуль thread: почему лучше не использовать
- Как выбрать: break/continue, await или потоки?
- Практические мини-задачи для закрепления
- Заключение
- Рекомендуем посмотреть курсы по Python
Базовые инструменты управления выполнением в Python
Прежде чем погружаться в детали, давайте определим базовую классификацию инструментов управления выполнением. Операторы break и continue работают исключительно внутри циклов (for и while) и управляют итерациями — первый полностью прерывает цикл, второй пропускает текущую итерацию и переходит к следующей. Оператор await, напротив, работает только внутри асинхронных функций (async def) и позволяет приостановить выполнение корутины до завершения асинхронной операции.
Ключевое различие между этими подходами заключается в области применения и уровне абстракции. Break и continue — это синхронные операторы для управления циклами в рамках одного потока выполнения. Await — инструмент асинхронного программирования, который работает на уровне event loop и позволяет эффективно управлять операциями ввода-вывода без блокировки основного потока.
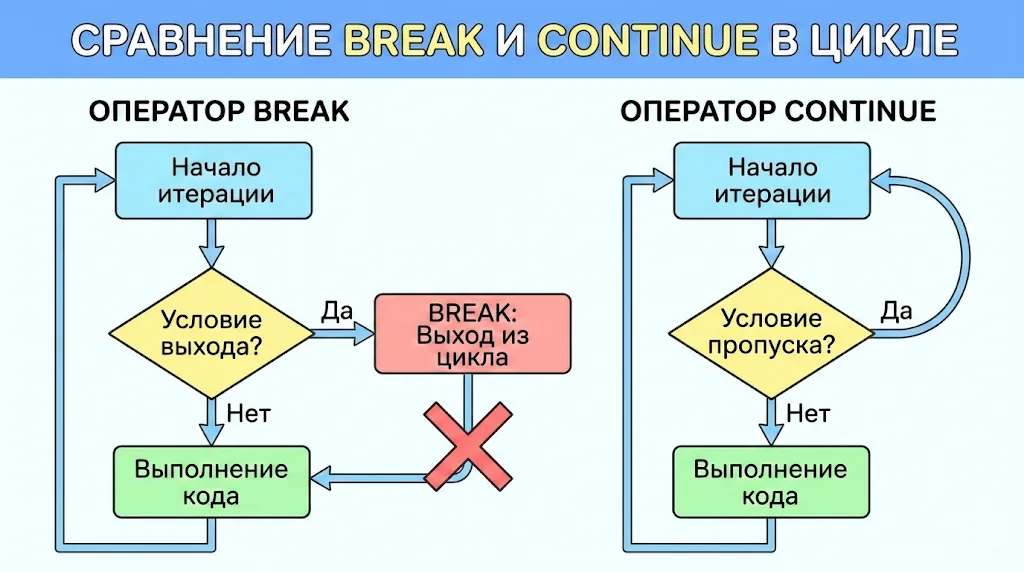
Наглядное сравнение двух операторов. Слева видно, как break полностью прерывает цикл и выходит из него при выполнении условия. Справа показано, как continue пропускает только текущую итерацию, немедленно возвращаясь к началу цикла для следующей проверки условия.
Таблица: Когда что использовать
| Оператор | Область применения | Что делает | Типичные ошибки |
|---|---|---|---|
| break | Циклы for/while | Немедленно завершает выполнение цикла | Использование вне цикла; безусловный break в начале цикла |
| continue | Циклы for/while | Пропускает оставшийся код итерации и переходит к следующей | Путаница с break; лишние continue, усложняющие логику |
| await | Асинхронные функции (async def) | Приостанавливает выполнение корутины до завершения awaitable-объекта | Использование вне async; await синхронной функции; блокировка в корутине |
Оператор break: полное завершение цикла
Оператор break — это своеобразный «аварийный выход» из цикла. Когда Python встречает break внутри for или while, выполнение цикла немедленно прекращается, и управление передается первой инструкции после него. Важно понимать, что break завершает только тот цикл, в котором он непосредственно находится — если у вас вложенные циклы, внешний продолжит работу.
Типичные сценарии применения break включают поиск элемента в коллекции (когда найден нужный, дальнейший перебор не имеет смысла), обработку данных до достижения определенного условия или реализацию бесконечных циклов с условием выхода. В контексте оптимизации производительности break позволяет избежать ненужных итераций — согласно нашим наблюдениям, в задачах поиска это может сократить время выполнения в десятки раз.
Примеры использования break в циклах while и for
Рассмотрим практические примеры. Поиск числа в списке:
numbers = [5, 12, 8, 130, 44, 9]
target = 130
for num in numbers:
if num == target:
print(f"Найдено: {num}")
break
print(f"Проверяем: {num}")
Вывод:
Проверяем: 5
Проверяем: 12
Проверяем: 8
Найдено: 130
Использование break в цикле while для ограничения попыток:
attempt = 0
max_attempts = 3
while True:
attempt += 1
password = input("Введите пароль: ")
if password == "secret123":
print("Доступ разрешен")
break
if attempt >= max_attempts:
print("Превышено количество попыток")
break
print(f"Неверный пароль. Осталось попыток: {max_attempts - attempt}")
Типичные ошибки и рекомендации
Самая распространенная ошибка — использование break вне цикла. Python выдаст синтаксическую ошибку SyntaxError: ‘break’ outside loop. Вторая частая проблема — безусловный break в начале цикла, что делает его бессмысленным. Наконец, при работе с вложенными циклами новички часто ожидают, что break завершит все циклы сразу, хотя он влияет только на ближайший внешний. Для выхода из нескольких уровней вложенности рекомендуется использовать флаговые переменные или переосмыслить логику программы.
Оператор continue: пропуск итерации
Оператор continue работает противоположным образом по сравнению с break — вместо полного завершения цикла он пропускает оставшуюся часть текущей итерации и немедленно переходит к следующей. Когда Python встречает continue, все инструкции после него до конца тела цикла игнорируются, и начинается новая итерация (в случае for) или повторная проверка условия (в случае while).
Это особенно полезно, когда нужно обработать коллекцию данных, отфильтровав определенные элементы, но продолжив работу с остальными. В отличие от break, который говорит «остановись и выйди», continue означает «пропусти это и продолжай дальше». Такой подход позволяет избежать глубокой вложенности условных конструкций и делает код более читаемым.
Примеры continue в фильтрации данных
Пропуск четных чисел при обработке списка:
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
for num in numbers:
if num % 2 == 0:
continue
print(f"Обрабатываем нечетное число: {num}")
Вывод:
Обрабатываем нечетное число: 1
Обрабатываем нечетное число: 3
Обрабатываем нечетное число: 5
Обрабатываем нечетное число: 7
Обрабатываем нечетное число: 9
Пропуск некорректных значений при обработке данных:
user_inputs = ["25", "abc", "30", "", "45", "xyz"]
for value in user_inputs:
if not value.isdigit():
print(f"Пропускаем некорректное значение: '{value}'")
continue
number = int(value)
print(f"Обрабатываем число: {number}")
Вывод:
Обрабатываем число: 25
Пропускаем некорректное значение: 'abc'
Обрабатываем число: 30
Пропускаем некорректное значение: ''
Обрабатываем число: 45
Пропускаем некорректное значение: 'xyz'
Когда continue лучше, чем break
Ключевое различие между continue и break заключается в намерении: continue используется, когда нужно пропустить отдельные элементы, но продолжить обработку остальных, тогда как break применяется для полного прекращения цикла при достижении определенного условия. Если вы фильтруете данные, валидируете элементы списка или обрабатываете пользовательский ввод с возможными ошибками — continue ваш выбор. Если же вы ищете конкретный элемент или достигли критического состояния, требующего остановки — используйте break. Возникает вопрос: можно ли всегда заменить continue на вложенный if? Технически да, но это приведет к менее читаемому коду с большей глубиной вложенности.
Асинхронность и оператор await: управление событиями без блокировок
Асинхронное программирование в Python — это парадигма, позволяющая эффективно работать с операциями ввода-вывода без блокировки основного потока выполнения. В центре этой концепции находятся корутины — специальные функции, объявленные с ключевым словом async def, которые могут приостанавливать свое выполнение и передавать управление другим корутинам.
Оператор await работает только внутри асинхронных функций и указывает точки, в которых выполнение корутины может быть приостановлено. Когда Python встречает await, он не блокирует программу в ожидании результата — вместо этого управление передается event loop (циклу событий), который может переключиться на выполнение других корутин. Это принципиально отличается от работы с потоками: те реально параллельны (с оговоркой на GIL), тогда как корутины исполняются кооперативно в одном потоке, переключаясь в явно обозначенных точках.
Event loop можно представить как диспетчера, который управляет выполнением множества корутин. Когда одна ожидает завершения I/O-операции (чтение файла, сетевой запрос), event loop переключается на другую готовую к выполнению корутину. Это делает асинхронный код особенно эффективным для задач, связанных с сетевыми запросами, работой с базами данных или файловой системой.
Правильное использование await: примеры
Базовый пример с asyncio.sleep():
import asyncio
async def fetch_data(source_id):
print(f"Начинаем загрузку из источника {source_id}")
await asyncio.sleep(2) # Имитация сетевого запроса
print(f"Данные из источника {source_id} получены")
return f"data_{source_id}"
async def main():
result = await fetch_data(1)
print(f"Результат: {result}")
asyncio.run(main())
Вызов нескольких корутин параллельно:
import asyncio
async def download_file(file_id):
print(f"Загружаем файл {file_id}...")
await asyncio.sleep(1)
return f"file_{file_id}.txt"
async def main():
# Запуск трех корутин одновременно
results = await asyncio.gather(
download_file(1),
download_file(2),
download_file(3)
)
print(f"Загружены файлы: {results}")
asyncio.run(main())
Ошибки при использовании await
Самая частая ошибка — попытка использовать await вне асинхронной функции. Python выдаст SyntaxError: ‘await’ outside async function. Вторая распространенная проблема — непонимание порядка выполнения: новички часто ожидают, что несколько последовательных await будут работать параллельно, хотя на самом деле они выполняются последовательно. Для параллельного нужно использовать asyncio.gather() или asyncio.create_task().
Третья ошибка — блокирующие операции внутри корутин. Если вы вызовете time.sleep() вместо asyncio.sleep(), это заблокирует весь event loop, и преимущества асинхронности исчезнут. Наконец, попытка использовать await с обычной (не асинхронной) функцией приведет к ошибке — await работает только с awaitable-объектами (корутинами, задачами, futures).
Как работает event loop:
[Корутина A] --await--> Event Loop ---> [Корутина B] ↑ | | await | ↓ └------------ Event Loop <----- [Корутина C]
Что такое потоки в Python и как они работают
Поток (thread) — это независимая последовательность выполнения инструкций внутри одного процесса. Когда вы запускаете Python-программу, создается основной поток (main thread), который последовательно выполняет код. Однако Python позволяет создавать дополнительные потоки, которые могут работать параллельно с основным, выполняя разные задачи одновременно.
Важно понимать различие между потоком и процессом. Процесс — это самостоятельная программа со своим пространством памяти, собственными переменными и ресурсами. Потоки же существуют внутри одного процесса и разделяют общую память и ресурсы. Это делает потоки более легковесными и быстрыми в создании, но одновременно требует особой осторожности при работе с общими данными.
Здесь мы подходим к концепции GIL (Global Interpreter Lock) — механизму, который является одновременно особенностью и ограничением CPython. GIL гарантирует, что в каждый момент времени только один поток может выполнять байт-код Python, даже на многоядерных процессорах. Это означает, что многопоточность в Python эффективна для задач с интенсивным вводом-выводом (сетевые запросы, работа с файлами), но не дает преимуществ для CPU-интенсивных вычислений. Для последних лучше использовать модуль multiprocessing.
Зачем же нужны потоки, если GIL ограничивает истинную параллельность? Ответ прост: когда поток ожидает завершения I/O-операции (чтение файла, получение данных из сети), GIL освобождается, и другие потоки могут работать. Это позволяет значительно ускорить программы, которые проводят большую часть времени в ожидании внешних ресурсов. Представьте веб-скрейпер, загружающий сотни страниц — вместо последовательной загрузки каждой страницы, потоки позволяют отправить множество запросов одновременно и обрабатывать ответы по мере их поступления.
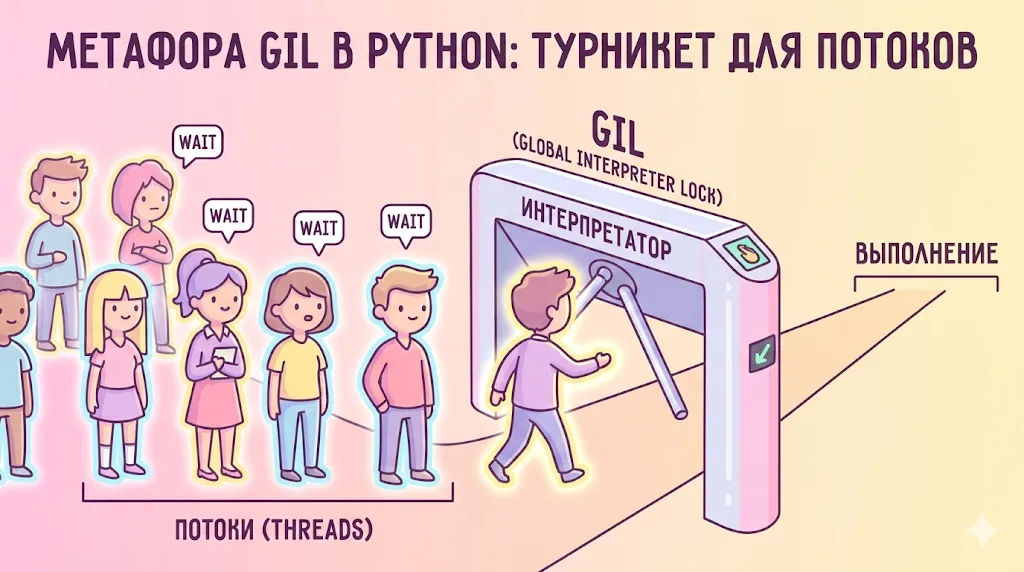
Визуальная метафора, объясняющая Global Interpreter Lock (GIL). Потоки изображены в виде людей в очереди перед турникетом (интерпретатором), который пропускает только одного за раз. Это интуитивно объясняет, почему многопоточность в Python не дает прироста производительности на CPU-задачах.
Диаграмма: основной поток → дополнительные потоки
Основной поток (Main Thread) | ├─→ Поток 1 (Thread-1) → выполняет задачу A | ├─→ Поток 2 (Thread-2) → выполняет задачу B | └─→ Поток 3 (Thread-3) → выполняет задачу C
Все потоки разделяют общую память процесса
Модуль threading: создание и запуск потоков
Модуль threading предоставляет высокоуровневый интерфейс для работы с потоками в Python. Основной класс — threading.Thread, который принимает несколько ключевых параметров: target (функция, которую будет выполнять поток), args (кортеж аргументов для функции), kwargs (словарь именованных аргументов) и name (имя потока для идентификации).
Рассмотрим базовый пример создания двух потоков с разными аргументами:
import threading
import time
def worker(worker_id, duration):
print(f"Поток {worker_id} начал работу")
time.sleep(duration)
print(f"Поток {worker_id} завершил работу за {duration} секунд")
# Создание потоков
thread1 = threading.Thread(target=worker, args=(1, 2), name="Worker-1")
thread2 = threading.Thread(target=worker, args=(2, 3), name="Worker-2")
# Запуск потоков
thread1.start()
thread2.start()
print("Основной поток продолжает работу...")
# Ожидание завершения потоков
thread1.join()
thread2.join()
print("Все потоки завершены")
Метод start() запускает выполнение — он создает системный поток и вызывает функцию target. Важно понимать, что start() не блокирует выполнение — основной поток продолжает работу немедленно. Метод join(), напротив, блокирует вызывающий поток до завершения указанного. Это критически важно, когда основной поток должен дождаться результатов работы дочерних перед продолжением.
Метод is_alive() позволяет проверить, выполняется ли поток в данный момент:
import threading
import time
def long_task():
time.sleep(3)
thread = threading.Thread(target=long_task)
thread.start()
print(f"Поток активен: {thread.is_alive()}") # True
thread.join()
print(f"Поток активен: {thread.is_alive()}") # False
Демон-потоки: когда нужны и как работают
Демон-поток (daemon thread) — это тот, который автоматически завершается при завершении основной программы. Обычные потоки блокируют завершение программы до своего завершения, демон этого не делает. Установить поток как демон можно через параметр daemon=True при создании или через атрибут daemon.
Демоны используются для фоновых задач, которые должны работать на протяжении жизни программы, но не критичны для ее корректного завершения. Типичные примеры: мониторинг системных ресурсов, периодическая очистка кэша, фоновая синхронизация данных.
Пример неправильного использования (поток не завершит работу):
import threading
import time
def background_task():
for i in range(10):
print(f"Фоновая задача: {i}")
time.sleep(1)
# Обычный поток - программа будет ждать его завершения
thread = threading.Thread(target=background_task)
thread.start()
print("Основная программа завершена")
# Программа ждет 10 секунд
Правильное использование с daemon=True:
import threading
import time
def background_task():
for i in range(10):
print(f"Фоновая задача: {i}")
time.sleep(1)
# Демон-поток - завершится вместе с программой
thread = threading.Thread(target=background_task, daemon=True)
thread.start()
print("Основная программа завершена")
# Программа завершается сразу, не дожидаясь фоновой задачи
Таймеры в threading: отложенный запуск
Класс threading.Timer позволяет запустить функцию с заданной задержкой. Это специализированный подкласс Thread, который ожидает указанное время перед вызовом целевой функции.
import threading
def delayed_message(message):
print(f"Сообщение: {message}")
# Создание таймера с задержкой 3 секунды
timer = threading.Timer(3.0, delayed_message, args=("Прошло 3 секунды!",))
timer.start()
print("Таймер запущен, ожидание...")
timer.join()
print("Таймер завершен")
Timer также поддерживает метод cancel(), который позволяет отменить выполнение до истечения времени задержки. Это полезно для реализации таймаутов или отмены отложенных операций при изменении условий.
Механизмы синхронизации потоков
Lock (замок) — это базовый примитив синхронизации, который гарантирует, что только один поток может выполнять критическую секцию кода в конкретный момент времени. Когда один поток захватывает замок методом acquire(), все остальные потоки, пытающиеся захватить тот же замок, блокируются до тех пор, пока первый поток не освободит его методом release().
Критическая секция — это участок кода, который обращается к общим ресурсам (переменным, файлам, сетевым соединениям) и должен выполняться атомарно, без вмешательства других потоков. Без синхронизации возникает состояние гонки (race condition), когда результат зависит от порядка выполнения потоков.
Пример с критической секцией:
import threading
counter = 0
lock = threading.Lock()
def increment():
global counter
for _ in range(100000):
lock.acquire()
try:
counter += 1
finally:
lock.release()
# Создаем два потока
thread1 = threading.Thread(target=increment)
thread2 = threading.Thread(target=increment)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print(f"Итоговое значение счетчика: {counter}") # Будет 200000
Без использования lock значение counter могло бы быть меньше 200000 из-за состояния гонки. Более элегантный способ использования lock — контекстный менеджер with, который автоматически вызывает release() даже при возникновении исключений:
def increment_safe(): global counter for _ in range(100000): with lock: counter += 1
Lock обязательно нужно использовать при модификации разделяемых данных, работе с файлами из нескольких потоков, обновлении счетчиков, изменении структур данных (списков, словарей) и любых операциях, которые не являются атомарными.
Deadlock: что это и как возникает
Deadlock (взаимная блокировка) — это ситуация, когда два или более потока бесконечно ждут друг друга, каждый удерживая ресурс, необходимый другому. Это классическая проблема параллельного программирования, которая может полностью заблокировать приложение.
Пример возникновения deadlock:
import threading
import time
lock1 = threading.Lock()
lock2 = threading.Lock()
def task1():
with lock1:
print("Поток 1 захватил lock1")
time.sleep(0.1)
print("Поток 1 ждет lock2...")
with lock2:
print("Поток 1 захватил lock2")
def task2():
with lock2:
print("Поток 2 захватил lock2")
time.sleep(0.1)
print("Поток 2 ждет lock1...")
with lock1:
print("Поток 2 захватил lock1")
thread1 = threading.Thread(target=task1)
thread2 = threading.Thread(target=task2)
thread1.start()
thread2.start()
# Программа зависнет!
В этом примере поток 1 захватывает lock1 и ждет lock2, в то время как поток 2 удерживает lock2 и ждет lock1. Ни один из потоков не может продолжить выполнение.
Почему deadlock опасен? Он приводит к полному зависанию программы без явных ошибок или исключений. В production-среде это может означать недоступность сервиса, потерю данных или необходимость принудительного перезапуска приложения.
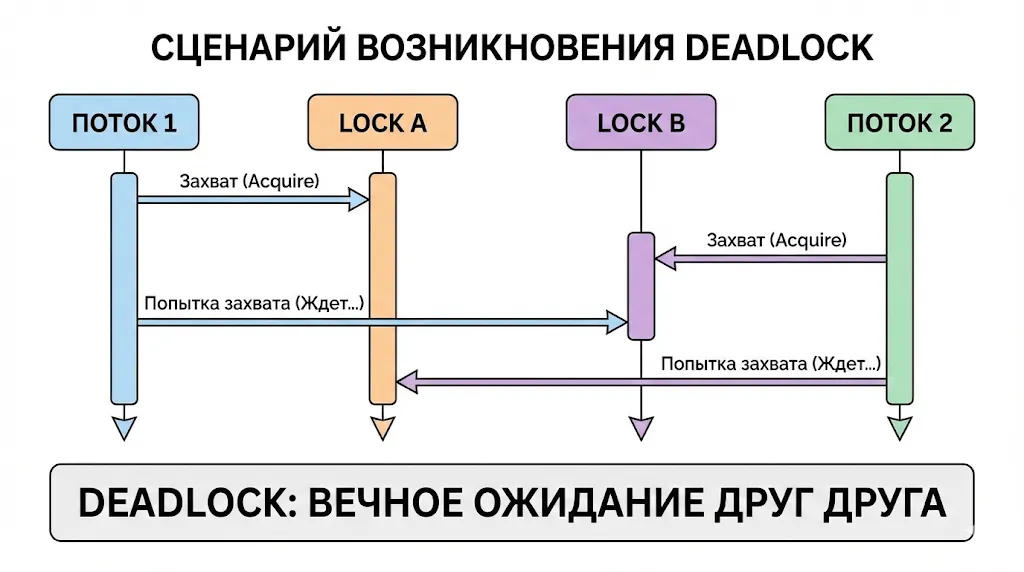
Диаграмма последовательности, которая хронологически показывает, как два потока попадают в ситуацию взаимной блокировки. Каждый поток захватывает один ресурс и пытается получить доступ ко второму, который уже занят другим потоком, что приводит к бесконечному ожиданию.
Способы предотвращения deadlock:
- Упорядочение захвата замков — всегда захватывайте замки в одном и том же порядке во всех потоках.
- Использование таймаутов — метод acquire(timeout=…) позволяет ограничить время ожидания.
- Минимизация критических секций — удерживайте замки минимально возможное время.
- Использование высокоуровневых примитивов — RLock, Semaphore, Condition могут упростить логику.
Правильная версия предыдущего примера:
def task1():
with lock1:
print("Поток 1 захватил lock1")
with lock2:
print("Поток 1 захватил lock2")
def task2():
# Тот же порядок захвата!
with lock1:
print("Поток 2 захватил lock1")
with lock2:
print("Поток 2 захватил lock2")
Semaphore: ограничение количества потоков
Semaphore (семафор) — это счетчик, который ограничивает количество потоков, одновременно имеющих доступ к ресурсу. В отличие от Lock, который допускает только один поток, Semaphore позволяет указать максимальное число одновременных доступов.
Когда это нужно? Представьте пул подключений к базе данных: у вас может быть максимум 5 одновременных соединений, и вы хотите ограничить количество потоков, пытающихся подключиться.
import threading
import time
# Разрешаем максимум 3 одновременных доступа
semaphore = threading.Semaphore(3)
def access_resource(thread_id):
print(f"Поток {thread_id} ожидает доступа...")
with semaphore:
print(f"Поток {thread_id} получил доступ к ресурсу")
time.sleep(2) # Имитация работы с ресурсом
print(f"Поток {thread_id} освободил ресурс")
threads = []
for i in range(6):
t = threading.Thread(target=access_resource, args=(i,))
threads.append(t)
t.start()
for t in threads:
t.join()
Сравнение Lock vs Semaphore:
- Lock: бинарный семафор (0 или 1), только один поток может захватить.
- Semaphore: счетный семафор (0 до N), несколько потоков могут захватить одновременно.
- Lock: используется для защиты критических секций.
- Semaphore: используется для ограничения доступа к ресурсам с ограниченной пропускной способностью.
Event: сигнализация между потоками
Event (событие) — это примитив синхронизации для передачи сигналов между потоками. Event имеет внутренний флаг, который может быть установлен (set()) или сброшен (clear()). Потоки могут ждать установки флага методом wait().
import threading
import time
event = threading.Event()
def waiter(name):
print(f"{name} ожидает сигнала...")
event.wait() # Блокируется до установки события
print(f"{name} получил сигнал и начал работу!")
def setter():
print("Setter готовится отправить сигнал...")
time.sleep(3)
print("Setter отправляет сигнал!")
event.set() # Все ждущие потоки разблокируются
# Создаем несколько ждущих потоков
for i in range(3):
t = threading.Thread(target=waiter, args=(f"Waiter-{i}",))
t.start()
setter_thread = threading.Thread(target=setter)
setter_thread.start()
Типичный пример использования — ожидание инициализации ресурса:
import threading
ready_event = threading.Event()
data = None
def initialize_data():
global data
# Длительная инициализация
data = {"status": "initialized"}
ready_event.set() # Сигнализируем о готовности
def process_data():
ready_event.wait() # Ждем готовности данных
print(f"Обработка данных: {data}")
init_thread = threading.Thread(target=initialize_data)
process_thread = threading.Thread(target=process_data)
process_thread.start()
init_thread.start()
init_thread.join()
process_thread.join()
Condition: ожидание условий
Condition (условная переменная) — более сложный примитив, который комбинирует Lock и механизм ожидания. Он позволяет потокам ждать выполнения определенного условия и получать уведомления, когда условие изменяется.
import threading
import time
condition = threading.Condition()
items = []
def producer():
global items
for i in range(5):
time.sleep(1)
with condition:
items.append(i)
print(f"Произведен элемент {i}")
condition.notify() # Уведомляем один ждущий поток
def consumer():
global items
while True:
with condition:
while not items:
print("Потребитель ждет...")
condition.wait() # Ждем уведомления
item = items.pop(0)
print(f"Потреблен элемент {item}")
if item == 4: # Последний элемент
break
prod_thread = threading.Thread(target=producer)
cons_thread = threading.Thread(target=consumer)
cons_thread.start()
prod_thread.start()
prod_thread.join()
cons_thread.join()
Отличие от события (Event): Event — это простой флаг (установлен/не установлен), Condition позволяет ждать более сложных условий и предоставляет методы notify() и notify_all() для гибкого управления уведомлениями. Condition автоматически управляет блокировкой, что упрощает реализацию паттернов producer-consumer.
Блок-схема: когда использовать какой механизм
Нужна защита общих данных? → Lock Ограничение одновременных доступов? → Semaphore Простая сигнализация между потоками? → Event Сложное условие + producer-consumer? → Condition Предотвращение deadlock? → Упорядочение Lock + таймауты
Очереди для потокобезопасного обмена данными
Модуль queue предоставляет потокобезопасные структуры данных для обмена информацией между потоками. Класс Queue — это FIFO-очередь (First In, First Out), которая автоматически управляет блокировками, избавляя разработчика от необходимости явно использовать Lock.
Основные методы Queue: put() для добавления элемента в очередь, get() для его извлечения (блокируется, если очередь пуста), task_done() для сигнализации о завершении обработки и join() для ожидания обработки всех элементов.
Классический паттерн producer-consumer с использованием Queue:
import threading
import queue
import time
task_queue = queue.Queue()
def producer(name, num_items):
for i in range(num_items):
item = f"{name}-item-{i}"
task_queue.put(item)
print(f"Producer {name} добавил: {item}")
time.sleep(0.5)
print(f"Producer {name} завершил работу")
def consumer(name):
while True:
try:
item = task_queue.get(timeout=3)
print(f"Consumer {name} обрабатывает: {item}")
time.sleep(1) # Имитация обработки
task_queue.task_done()
except queue.Empty:
print(f"Consumer {name} завершил работу (очередь пуста)")
break
# Создаем производителей и потребителей
prod1 = threading.Thread(target=producer, args=("P1", 5))
prod2 = threading.Thread(target=producer, args=("P2", 5))
cons1 = threading.Thread(target=consumer, args=("C1",))
cons2 = threading.Thread(target=consumer, args=("C2",))
# Сначала запускаем потребителей
cons1.start()
cons2.start()
# Затем производителей
prod1.start()
prod2.start()
# Ждем завершения производителей
prod1.join()
prod2.join()
# Ждем обработки всех задач
task_queue.join()
print("Все задачи обработаны")
Преимущества Queue перед ручным управлением Lock: автоматическая синхронизация, встроенные методы блокировки и ожидания, поддержка приоритетов (через PriorityQueue), ограничение размера очереди для предотвращения переполнения памяти. Возникает вопрос: почему бы не использовать обычный список с Lock? Queue инкапсулирует сложную логику управления состоянием, обработки исключений и взаимодействия потоков, что делает код более надежным и читаемым.
Старый модуль thread: почему лучше не использовать
Модуль thread (в Python 3 переименован в _thread) — это низкоуровневый интерфейс для работы с потоками, который существует в основном для обратной совместимости. В отличие от threading, который предоставляет объектно-ориентированный API с удобными абстракциями, _thread работает на более примитивном уровне с минимальными гарантиями безопасности.
Основные проблемы _thread: отсутствие метода join() для ожидания завершения потоков, сложность отслеживания состояния потоков, минимальная обработка исключений (ошибка в потоке может молча завершить его без уведомления основной программы), отсутствие высокоуровневых примитивов синхронизации. Согласно официальной документации Python, модуль _thread считается устаревшим, и его использование не рекомендуется для новых проектов.
Рекомендация однозначна: всегда используйте модуль threading для работы с потоками. Он построен поверх _thread, предоставляя безопасный и удобный интерфейс с полным набором инструментов синхронизации. Если вам нужна истинная параллельность для CPU-интенсивных задач, рассмотрите модуль multiprocessing вместо попыток оптимизировать потоки на низком уровне. В современном Python использование _thread оправдано только в очень специфических случаях внутренней реализации библиотек, где требуется максимальный контроль над поведением потоков.
Как выбрать: break/continue, await или потоки?
Выбор правильного инструмента зависит от характера решаемой задачи. Break и continue работают на уровне управления циклами в синхронном коде, await управляет асинхронными операциями внутри одного потока, а потоки позволяют выполнять действительно параллельные операции (с оговоркой на GIL).
Ключевое правило: используйте самый простой инструмент, который решает вашу задачу. Не стоит создавать потоки для простого прерывания цикла или использовать асинхронность там, где достаточно последовательного выполнения.
Сравнительная таблица:
| Задача | Использовать break/continue | Использовать await | Использовать потоки |
|---|---|---|---|
| Поиск элемента в списке | ✅ break при нахождении | ❌ Излишне сложно | ❌ Излишне сложно |
| Фильтрация данных в цикле | ✅ continue для пропуска | ❌ Не подходит | ❌ Не подходит |
| Множественные HTTP-запросы | ❌ Будет медленно | ✅ Идеально с aiohttp | ✅ Подходит, но сложнее |
| Обработка файлов I/O | ❌ Синхронно медленно | ✅ С aiofiles эффективно | ✅ Для больших файлов |
| CPU-интенсивные вычисления | ❌ Не параллелит | ❌ Не даст ускорения | ❌ GIL ограничивает, нужен multiprocessing |
| Веб-скрейпинг 100+ страниц | ❌ Слишком медленно | ✅ Оптимально | ✅ Приемлемо |
| Обработка событий UI | ❌ Заблокирует интерфейс | ✅ Не блокирует | ✅ Можно, но async проще |
| Работа с базой данных | ❌ Последовательно | ✅ С asyncpg/motor | ✅ С пулом соединений |
Практический совет: для I/O-операций (сеть, файлы, база данных) выбирайте между async/await и потоками. Async/await дает лучшую производительность при меньшем потреблении ресурсов, но требует асинхронных библиотек. Потоки работают с любыми библиотеками, но потребляют больше памяти. Для CPU-задач используйте multiprocessing. Для простого управления циклами — break/continue.
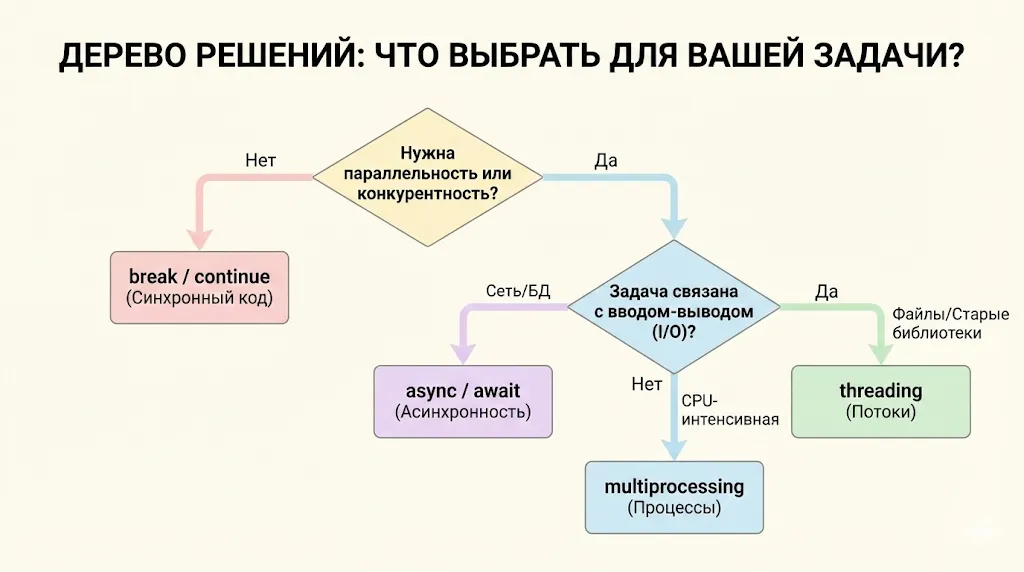
Эта шпаргалка в виде дерева решений поможет читателю быстро определить, какой инструмент (break/continue, async/await, threading или multiprocessing) лучше всего подходит для его конкретной задачи, основываясь на ключевых вопросах о параллельности и типе нагрузки (I/O или CPU).
Практические мини-задачи для закрепления
Теория без практики остается абстракцией. Мы предлагаем три задачи разного уровня сложности для закрепления изученного материала.
Задача 1: Поиск простого числа с break
Напишите функцию, которая находит первое простое число больше заданного значения. Используйте break для оптимизации — как только число найдено, прекратите поиск.
def find_next_prime(start): num = start + 1 while True: is_prime = True for i in range(2, int(num ** 0.5) + 1): if num % i == 0: is_prime = False break # Не простое, прерываем проверку делителей if is_prime: return num # Нашли, выходим из while num += 1
Задача 2: Фильтрация невалидных данных с continue
Дан список строк с email-адресами, некоторые из которых некорректны. Обработайте только валидные адреса, пропуская остальные с помощью continue.
emails = ["user@example.com", "invalid-email", "admin@site.org", "", "test@"]
for email in emails:
if "@" not in email or len(email) < 5:
print(f"Пропускаем невалидный email: '{email}'")
continue
# Обработка валидного email
print(f"Обрабатываем: {email}")
# Здесь может быть отправка письма, сохранение в БД и т.д.
Задача 3: Синхронизация потоков через Event
Создайте два потока: первый генерирует данные, второй их обрабатывает. Используйте Event для сигнализации о готовности данных.
import threading
import time
data_ready = threading.Event()
shared_data = []
def data_generator():
print("Генератор: подготовка данных...")
time.sleep(2)
shared_data.extend([1, 2, 3, 4, 5])
print("Генератор: данные готовы")
data_ready.set() # Сигнализируем о готовности
def data_processor():
print("Процессор: ожидание данных...")
data_ready.wait() # Ждем сигнала
print(f"Процессор: обработка {len(shared_data)} элементов")
total = sum(shared_data)
print(f"Процессор: сумма = {total}")
gen_thread = threading.Thread(target=data_generator)
proc_thread = threading.Thread(target=data_processor)
proc_thread.start()
gen_thread.start()
gen_thread.join()
proc_thread.join()
Эти задачи демонстрируют реальные сценарии применения изученных инструментов. Попробуйте модифицировать их: добавьте обработку исключений, расширьте функциональность или комбинируйте несколько подходов.
Заключение
Мы рассмотрели полный спектр инструментов управления выполнением в Python — от простых операторов break и continue до сложных механизмов многопоточности и асинхронного программирования.. Подведем итоги:
- Операторы break и continue управляют поведением циклов. Они помогают прерывать выполнение или пропускать итерации без усложнения кода.
- Оператор await используется внутри асинхронных функций. Он позволяет приостанавливать корутину без блокировки основного потока выполнения.
- Асинхронное программирование эффективно при работе с вводом-выводом. Оно позволяет обрабатывать несколько задач без простоя в ожидании ответа.
- Потоки в Python подходят для параллельных I/O-операций. Однако из-за GIL они не ускоряют вычислительно сложные задачи.
- Примитивы синхронизации защищают общие данные от ошибок. Lock, Semaphore, Event и Condition координируют работу потоков и предотвращают гонки.
- Очереди из модуля queue упрощают обмен данными между потоками. Они обеспечивают потокобезопасность без ручного управления блокировками.
- Выбор инструмента управления выполнением зависит от типа задачи. Для циклов подходят break и continue, для I/O — async/await или потоки.
Если вы только начинаете осваивать профессию python-разработчика и хотите глубже разобраться в теме асинхронности, потоков и управления выполнением кода, рекомендуем обратить внимание на подборку курсов по python-разработке. В программах обычно есть теоретическая и практическая часть, что помогает не просто понять синтаксис, а научиться применять инструменты в реальных задачах.
Рекомендуем посмотреть курсы по Python
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Профессия Python-разработчик
|
Eduson Academy
114 отзывов
|
Цена
116 400 ₽
|
От
9 700 ₽/мес
|
Длительность
6 месяцев
|
Старт
21 марта
|
Подробнее |
|
Fullstack-разработчик на Python
|
Нетология
46 отзывов
|
Цена
161 200 ₽
325 635 ₽
с промокодом kursy-online
|
От
4 975 ₽/мес
|
Длительность
18 месяцев
|
Старт
26 марта
|
Подробнее |
|
Python-разработчик
|
Академия Синергия
38 отзывов
|
Цена
89 800 ₽
224 500 ₽
с промокодом KURSHUB
|
От
3 742 ₽/мес
0% на 24 месяца
|
Длительность
6 месяцев
|
Старт
31 марта
|
Подробнее |
|
Профессия Python-разработчик
|
Skillbox
232 отзыва
|
Цена
157 107 ₽
285 648 ₽
Ещё -27% по промокоду
|
От
4 621 ₽/мес
9 715 ₽/мес
|
Длительность
12 месяцев
|
Старт
23 марта
|
Подробнее |
|
Python-разработчик
|
Яндекс Практикум
102 отзыва
|
Цена
159 000 ₽
|
От
18 500 ₽/мес
|
Длительность
9 месяцев
Можно взять академический отпуск
|
Старт
26 марта
|
Подробнее |

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.

OTUS vs GeekBrains для backend: где строже к качеству кода и полезнее ревью
OTUS или GeekBrains — где обучение backend-разработке даёт более строгий подход к качеству кода? Разбираем, как устроено code review, какие инженерные практики используют школы и как проверить уровень ревью до оплаты курса.

Яндекс Практикум vs Contented: Figma/UI — где быстрее собрать 3 кейса и получить внятные правки
Выбираете между курсами UX/UI дизайна в Яндекс Практикуме и Contented? Разбираем, где быстрее собрать три сильных кейса в портфолио, как устроены ревью проектов и на что обратить внимание при выборе обучения.