Вопросы и задачи на собеседовании по Java в 2026 году: полный гид
Собеседование по Java в 2026 году — это уже не просто проверка знания синтаксиса и умения написать цикл. Рынок вырос, стек усложнился, а ожидания интервьюеров сдвинулись в сторону реальной инженерной зрелости: понимания JVM, многопоточности, архитектурных компромиссов и современных возможностей языка.

Этот гид написан для тех, кто готовится пройти техническое интервью на позицию junior, middle или senior Java-разработчика. Мы разберём не только список популярных вопросов, но и логику ответов — что именно хочет услышать интервьюер, какие формулировки работают, а какие выдают поверхностное знание темы.
Внутри — практические разборы по Java Core, многопоточности и JMM, устройству JVM и GC, современным возможностям Java 17/21 и экосистеме Spring Boot 3+. Отдельное внимание уделено форматам интервью и плану подготовки: что учить в первую очередь, если до собеседования неделя, две или месяц.
- Какие вопросы и задачи по Java спрашивают на собеседовании в 2026 году и как устроен процесс?
- Какие вопросы по Java Core встречаются чаще всего (и как отвечать без воды)?
- Какие вопросы по многопоточности и JMM задают в 2026 году?
- CompletableFuture и пулы потоков: какие задачи дают и как рассуждать?
- Какие вопросы по JVM, GC и производительности задают middle/senior?
- Какие возможности современной Java (17/21+) реально спрашивают на собеседованиях в 2026?
- Какие вопросы по Spring Boot 3+ и архитектуре бэкенда чаще всего задают?
- Как закрепить результат: репетиция интервью, портфолио и «карта пробелов»
- Рекомендуем посмотреть курсы по Java
Какие вопросы и задачи по Java спрашивают на собеседовании в 2026 году и как устроен процесс?
Прежде чем разбирать конкретные темы, полезно понять саму механику: из каких этапов состоит современное Java-интервью, что проверяют на каждом и чем отличаются ожидания от разных уровней. Это не абстрактная теория — неправильное понимание формата приводит к типичным провалам даже у сильных кандидатов.
Какие форматы интервью бывают: отбор с HR, технический созвон, live coding, проектирование систем, разбор кода?
Типичная воронка выглядит так:
- Отбор с HR — 20–30 минут. Проверяют мотивацию, опыт по резюме, ожидания по зарплате и базовую адекватность. Технических вопросов почти нет, но уже здесь важно говорить конкретно: не «работал с микросервисами», а «разрабатывал сервис уведомлений на Spring Boot, разворачивали в Kubernetes».
- Технический созвон — 45–60 минут. Здесь начинается реальная проверка. Могут спросить вопросы по Java Core, многопоточности, базам данных, архитектуре. Формат — диалог, а не допрос: интервьюер ожидает, что кандидат будет рассуждать вслух, уточнять условия и признавать границы своих знаний.
- Live coding — решение задачи в реальном времени (CoderPad, IDE с демонстрацией экрана). Оценивают не только результат, но и процесс: как кандидат декомпозирует задачу, называет переменные, обрабатывает граничные случаи. Молчать — худшее, что можно делать.
- Тестовое задание — встречается реже, обычно на middle/senior. Дают 3–7 дней на небольшой проект. Здесь смотрят на качество кода, тесты, структуру, README.
- Проектирование систем — обсуждение архитектуры системы (чат, очередь задач, сокращатель ссылок). Актуально для middle+ и senior. Ожидают не «правильный ответ», а структурированное мышление: требования → ограничения → компромиссы → решение.
- Разбор чужого кода — кандидату показывают чужой код и просят найти проблемы. Хороший формат для проверки практического опыта: видно, замечает ли человек состояние гонки, утечку ресурсов или нарушение контракта equals/hashCode.
Типовой провал на live coding: кандидат молчит, пока думает, и начинает писать только когда «всё понял». Интервьюер в это время не понимает, что происходит, и делает вывод о слабых коммуникативных навыках.
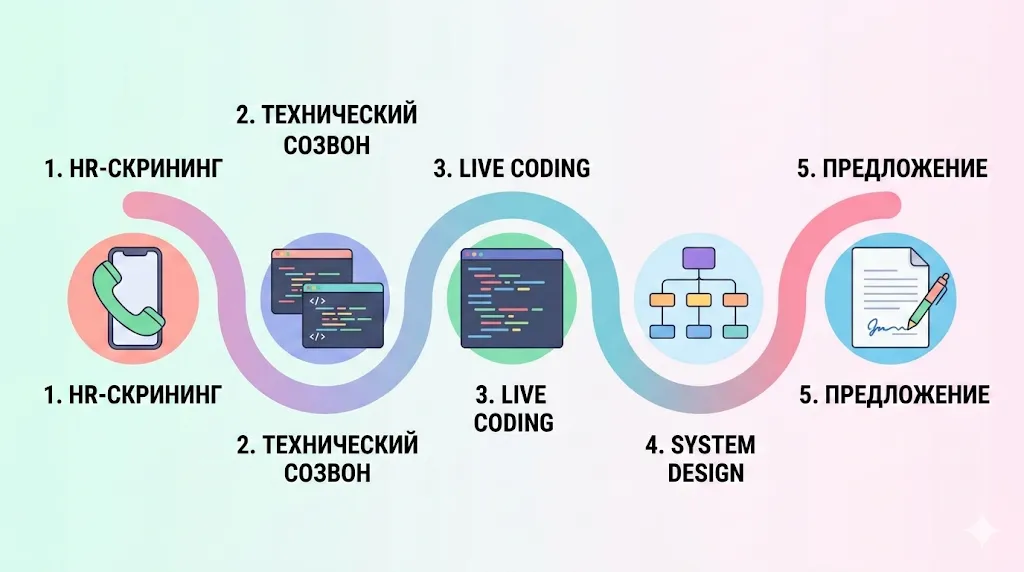
Эта иллюстрация визуализирует типичную воронку собеседования, от первого контакта с HR до получения финального предложения. Она помогает читателю мгновенно оценить структуру процесса и распределение времени между этапами.
Чек-лист live coding: до / во время / после
- До: убедитесь, что среда настроена, шрифт читаем, микрофон работает.
- Во время: проговорите условие своими словами → уточните ограничения → набросайте структуру → пишите с комментариями → называйте, что делаете.
- После: предложите улучшения сами, не ждите наводящих вопросов.
Что спрашивают на junior vs middle vs senior: чем отличаются ожидания?
Ключевое различие — не в наборе тем, а в глубине и контексте. Junior должен знать «как», middle — «почему», senior — «при каких условиях и какой ценой».
| Уровень | Java Core | Concurrency | JVM | Spring | Архитектура | Что демонстрировать |
| Junior | Синтаксис, коллекции, ООП-базис | Thread, synchronized — понятие | Heap/stack — базово | DI, аннотации, REST | Не требуется | Желание разобраться, чистый код |
| Middle | Generics, Stream API, контракты | JMM, locks, CompletableFuture | GC-алгоритмы, утечки | Транзакции, AOP, Boot 3 | REST-практики, кэш, очереди | Самостоятельность, мышление в категориях компромиссов |
| Senior | Байткод, производительность, паттерны | Неблокирующие структуры, диагностика | Профилирование, настройка | Миграции, наблюдаемость | Распределённые системы, масштаб | Архитектурные решения, наставничество |
Как подготовиться за 7 / 14 / 30 дней: план и приоритеты тем?
Универсальный принцип: сначала закрываем «стыдные пробелы» (базовые темы, которые спрашивают на 90% интервью), потом углубляемся в специфику уровня.
Чек-лист подготовки:
7 дней — минимальный спринт:
- Повторить Java Core: коллекции, equals/hashCode, исключения.
- Разобрать volatile, synchronized, happens-before.
- Решить 5–7 задач на LeetCode (лёгкие/средние) с объяснением вслух.
- Прочитать про Spring DI и @Transactional.
14 дней — нормальная подготовка:
- Добавить: Generics, Stream API, CompletableFuture.
- JVM: heap/metaspace/GC на уровне объяснения принципов.
- Spring Boot 3: Jakarta, транзакции, AOP.
- Провести 1–2 пробных интервью.
30 дней — глубокое погружение:
- Современный Java: records, sealed, virtual threads.
- Проектирование систем: разобрать 3–4 типовых сценария.
- Наблюдаемость, тесты, Testcontainers.
- Подготовить 3–5 историй из своего опыта по схеме STAR.
Ошибка при подготовке — читать «всё подряд» без практики. Знание, которое не проговорено вслух и не применено в задаче, на интервью рассыпается под первым уточняющим вопросом.
Николай Алименков, Java Champion, эксперт по архитектуре: «Собеседование сегодня — это проверка того, понимает ли человек цену каждой строки кода. Знание того, как работает Garbage Collector под нагрузкой, важнее, чем умение перечислить методы интерфейса List. Мы ищем инженеров, которые думают категориями ресурсов (CPU, RAM, Latency)».
Какие вопросы по Java Core встречаются чаще всего (и как отвечать без воды)?
Java Core — фундамент любого технического интервью, независимо от уровня. Разница лишь в том, что junior’у достаточно знать «как работает», а middle и senior должны объяснять «почему именно так» и «что сломается, если сделать иначе». Разберём три блока, которые встречаются практически на каждом собеседовании.
ООП и базовые контракты: equals/hashCode, неизменяемость, исключения — что спрашивают?
Коротко: здесь проверяют не знание определений, а понимание последствий. Интервьюер не хочет услышать «equals сравнивает объекты» — он хочет услышать, что произойдёт с объектом в HashSet, если нарушить контракт.
- equals/hashCode. Контракт прост: если equals возвращает true, hashCode у обоих объектов должен совпадать. Нарушение этого правила не вызывает ошибку компиляции — и в этом ловушка. Объект с переопределённым equals без переопределения hashCode будет вести себя непредсказуемо в любой хэш-структуре: HashMap, HashSet, Hashtable. Типовой вопрос: «Что случится, если положить объект в HashSet, потом изменить поле, по которому считается hashCode?» Правильный ответ: объект «потеряется» — найти его по equals уже не получится, а удалить — тоже.
- Неизменяемость. Неизменяемый объект — тот, чьё состояние не меняется после создания. Классический пример — String. Чтобы сделать класс действительно неизменяемым, недостаточно объявить поля final: если поле хранит ссылку на изменяемый объект (например, List), нужно делать защитные копии при получении и при инициализации. Неизменяемость упрощает работу с многопоточностью — неизменяемый объект не требует синхронизации, его можно безопасно публиковать.
- Исключения. Проверяемые исключения вынуждают вызывающий код явно обработать ситуацию — это хорошо для восстанавливаемых ошибок (файл не найден, сеть недоступна). Непроверяемые (RuntimeException) уместны для ошибок программирования: null там, где его быть не должно, некорректный аргумент. Типовой антипаттерн — ловить Exception или Throwable в бизнес-логике и проглатывать ошибку без логирования. Второй антипаттерн — использовать исключения как управляющий поток (throw вместо if).
Типовая ловушка: кандидат объясняет equals/hashCode правильно, но не может ответить на вопрос «почему нарушение контракта не вызывает ошибку?» — а ответ прост: Java не может проверить это статически.
Коллекции: HashMap изнутри, сложность операций, когда что выбирать?
Коротко: нужно знать не только «что выбрать», но и «почему» — с точки зрения структуры данных и поведения под нагрузкой.
HashMap хранит пары ключ-значение в массиве корзин (buckets). Ключ хэшируется, результат определяет индекс корзины. При коллизии элементы попадают в одну корзину — до Java 8 это был связный список (O(n) в худшем случае), с Java 8 при превышении порога корзина превращается в красно-чёрное дерево (O(log n)). При заполнении таблицы выше load factor (по умолчанию 0.75) происходит перехэширование — создаётся новый массив, все элементы перекладываются. Это дорогостоящая операция, и если известен примерный размер коллекции, лучше задать initialCapacity заранее.
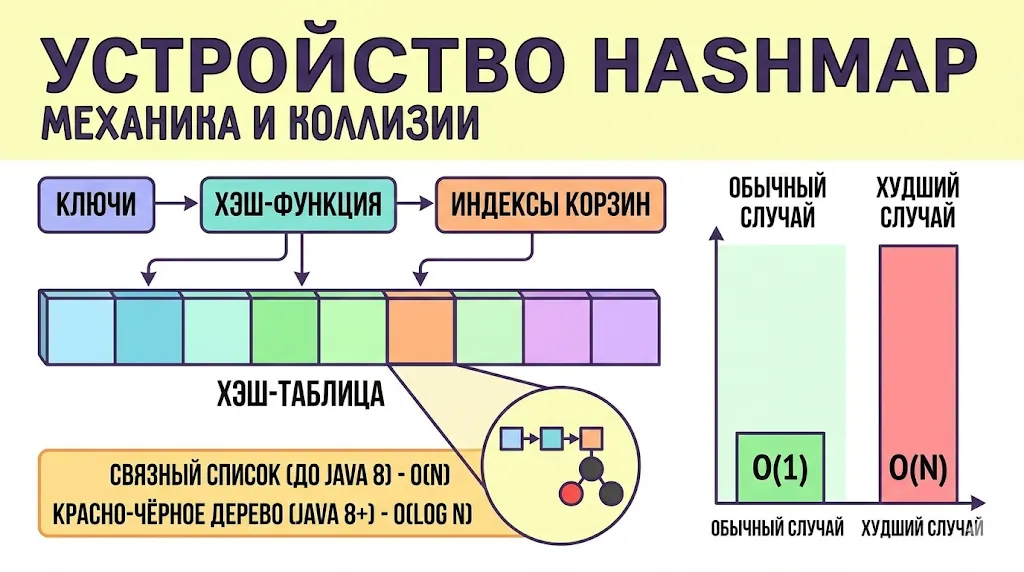
Упрощённая инфографика, показывающая внутреннее устройство HashMap. Изображение демонстрирует, как ключи хэшируются в индексы массива, и как возникают коллизии в «корзинах». Сравнение O(1) и O(n) наглядно показывает важность правильного hashCode.
Мини-задача: «Почему пропадает элемент из HashSet после изменения поля?» Ответ: HashSet использует hashCode для поиска корзины. Если поле, участвующее в hashCode, изменилось, объект лежит в «старой» корзине, а поиск идёт в «новой». Элемент физически есть в коллекции, но найти его невозможно — классическая потеря объекта.
| Структура | Когда выбирать | Плюсы | Минусы | Типовой вопрос |
| ArrayList | Частое чтение по индексу, редкая вставка в середину | O(1) get, компактная память | O(n) вставка в середину, расширение | Чем отличается от LinkedList? |
| LinkedList | Частые вставки/удаления в начало/конец | O(1) add/remove на краях | Нет произвольного доступа, больше памяти | Когда реально быстрее ArrayList? |
| HashMap | Быстрый поиск по ключу | O(1) амортизированно | Нет порядка, не потокобезопасен | Что происходит при коллизии? |
| TreeMap | Нужен отсортированный порядок ключей | O(log n), навигация | Медленнее HashMap | Когда использовать вместо HashMap? |
| ConcurrentHashMap | Многопоточный доступ | Потокобезопасен, нет блокировки всей карты | Чуть сложнее API | Чем отличается от Collections.synchronizedMap? |
| Проверяемое исключение | Восстанавливаемые ошибки | Явный контракт | Загромождает сигнатуры | Когда использовать вместо непроверяемого? |
| Непроверяемое исключение | Ошибки программирования | Не требует обработки | Легко потерять | Почему NPE — непроверяемое? |
«Почему на практике бывает иначе»: O(1) у HashMap — амортизированная сложность. При плохом hashCode (все объекты в одну корзину) реальная сложность деградирует до O(n). Расширение ArrayList тоже не бесплатно: при каждом увеличении копируется весь массив.
Generics и типизация: wildcard, стирание типов — типовые вопросы и ошибки?
Коротко: generics в Java реализованы через стирание типов — и это объясняет большинство неочевидных ограничений, на которых ловят кандидатов.
Стирание типов означает, что информация о параметрах типа существует только на этапе компиляции. В рантайме List<String> и List<Integer> — одно и то же: просто List. Именно поэтому нельзя написать new T[], нельзя использовать instanceof с параметром типа, и нельзя перегрузить методы, отличающиеся только параметром generics.
Wildcard. ? extends T (верхняя граница) — читать можно, писать нельзя (производитель). ? super T (нижняя граница) — писать можно, читать сложнее (потребитель). Мнемоника PECS (Producer Extends, Consumer Super) помогает запомнить, но важнее понимать причину: компилятор не может гарантировать безопасность записи в List<? extends Number>, потому что не знает, List<Integer> это или List<Double>.
Инвариантность. List<Dog> не является подтипом List<Animal>, даже если Dog extends Animal. Это инвариантность. Массивы в Java ковариантны (Dog[] — подтип Animal[]), и именно поэтому с массивами возможен ArrayStoreException в рантайме — проблема, которую generics решают на этапе компиляции.
Мини-задача: «Почему компилятор ругается на этот код?»
List ints = new ArrayList<>(); List nums = ints; // ошибка компиляции
Ответ: List<Integer> не является List<Number> из-за инвариантности. Если бы присвоение было разрешено, можно было бы добавить Double в список целых чисел через ссылку nums — нарушение типобезопасности. Правильное решение: List<? extends Number> nums = ints;.
Типовая ошибка на интервью: кандидат объясняет wildcard правильно, но не может связать стирание типов с конкретным ограничением. Лучший способ показать понимание — объяснить, почему instanceof List<String> не компилируется, и что за этим стоит.
Какие вопросы по многопоточности и JMM задают в 2026 году?
Многопоточность — традиционно одна из самых «страшных» тем на Java-собеседовании. На практике интервьюер редко ждёт энциклопедических знаний о всех примитивах синхронизации. Главное, что проверяют: понимает ли кандидат модель памяти, умеет ли рассуждать о видимости и упорядоченности, и не применяет ли многопоточные инструменты там, где они не нужны — или наоборот, обходится без них там, где они критичны.
volatile / synchronized / happens-before: как объяснять простыми словами?
Коротко: три ключевых понятия JMM — видимость, атомарность и упорядоченность. Большинство ошибок в многопоточном коде связаны с непониманием хотя бы одного из них.
- volatile гарантирует видимость: запись в volatile-переменную одним потоком будет видна всем остальным потокам немедленно, без кэширования в регистрах процессора. Однако volatile не гарантирует атомарность составных операций. Классический пример: counter++ — это три операции (чтение, увеличение, запись), и volatile здесь не спасёт от состояния гонки. Типовой вопрос: «Когда достаточно volatile, а когда нужен synchronized?» Ответ: volatile достаточно, когда один поток пишет, остальные только читают, и нет составных операций.
- synchronized обеспечивает и видимость, и атомарность в пределах критической секции. Работает через монитор объекта: только один поток может держать монитор одновременно. Важная деталь — synchronized в Java реентерабелен: поток, уже держащий монитор, может войти в другой synchronized-блок на том же объекте без взаимоблокировки.
- happens-before — отношение между операциями, которое гарантирует: если операция A happens-before операции B, то все изменения, сделанные в A, видны в B. Бытовой пример: представьте флаг готовности данных. Поток-производитель записывает данные, затем устанавливает volatile boolean ready = true. Поток-потребитель читает ready и, увидев true, гарантированно видит и все данные, записанные до установки флага — именно потому что запись в volatile happens-before чтения из него.
Типовая ловушка: кандидат знает volatile и synchronized по отдельности, но не может объяснить, какие именно гарантии даёт JMM при публикации объекта через volatile-ссылку. Правильный ответ: все записи, сделанные до публикации ссылки, видны любому потоку, который прочитает эту ссылку.
Locks / Atomics / Concurrent Collections: что сравнивают и на чём ловят?
Коротко: выбор инструмента синхронизации — это всегда компромисс между простотой, гибкостью и производительностью. Интервьюер ожидает, что кандидат понимает этот компромисс, а не просто перечисляет классы.
| Инструмент | Гарантии | Когда уместен | Частые ошибки |
| synchronized | Видимость + атомарность, реентерабельность | Простая критическая секция, не нужна гибкость | Синхронизация на this в публичном классе — опасно |
| ReentrantLock | То же + tryLock, таймауты, справедливость | Нужна попытка захвата, прерывание ожидания | Забыть unlock в блоке finally — взаимоблокировка гарантирована |
| AtomicInteger и др. | Атомарность одной переменной (CAS) | Счётчики, флаги, одиночные переменные | Атомарность одной операции ≠ атомарность последовательности |
| ConcurrentHashMap | Потокобезопасные операции над картой | Многопоточный read/write без полной блокировки | Составные операции (проверка-затем-действие) всё равно небезопасны |
ConcurrentHashMap vs HashMap — один из самых частых вопросов. HashMap не потокобезопасен: параллельная запись может привести к бесконечному циклу при перехэшировании (в старых JDK) или потере данных. Collections.synchronizedMap решает проблему грубо — блокирует всю карту целиком. ConcurrentHashMap использует сегментированную блокировку (в Java 8+ — CAS и синхронизацию на уровне корзины), что даёт значительно лучшую пропускную способность при параллельном доступе.
Мини-кейс: двойная проверка блокировки без volatile.
if (instance == null) {
synchronized (MyClass.class) {
if (instance == null) {
instance = new MyClass(); // опасно без volatile
}
}
}
Проблема: создание объекта — не атомарная операция. JVM может опубликовать ссылку на instance до того, как конструктор завершится (переупорядочивание инструкций). Второй поток увидит ненулевую ссылку и начнёт работать с частично инициализированным объектом. Решение: объявить instance как volatile — это запрещает переупорядочивание записи ссылки относительно инициализации объекта.
CompletableFuture и пулы потоков: какие задачи дают и как рассуждать?
Коротко: CompletableFuture — основной инструмент асинхронного программирования в современном Java. На собеседовании проверяют понимание цепочки вызовов, а не знание всех методов API наизусть.
thenApply vs thenCompose — самый частый вопрос по CF:
| Метод | Что делает | Когда использовать | Ошибка новичка |
| thenApply | Применяет функцию к результату, возвращает CF<U> | Синхронное преобразование результата | Использовать для вызова другого асинхронного метода — получится CF<CF<U>> |
| thenCompose | Принимает функцию, возвращающую CF<U>, «разворачивает» вложенность | Цепочка асинхронных вызовов | Путать с thenApply и получать вложенные Future |
| thenCombine | Объединяет результаты двух независимых CF | Параллельные независимые запросы | Использовать thenCompose там, где задачи независимы |
| exceptionally | Обрабатывает исключение, возвращает запасное значение | Обработка ошибок в цепочке | Не ставить в конце цепочки — исключения «выше» не перехватятся |
Пулы потоков. По умолчанию CF использует ForkJoinPool.commonPool(). Блокирующие вызовы в commonPool — антипаттерн: можно заблокировать весь пул и получить голодание потоков для всего приложения. Правило: для задач с ожиданием ввода-вывода передавайте явный Executor.
Мини-задача: «Объединить 3 асинхронных запроса, обработать таймаут.»
CompletableFuture fa = fetchA(); CompletableFuture fb = fetchB(); CompletableFuture fc = fetchC(); CompletableFuture.allOf(fa, fb, fc) .orTimeout(3, TimeUnit.SECONDS) .thenApply(v -> combine(fa.join(), fb.join(), fc.join())) .exceptionally(ex -> fallback());
Ключевые моменты: allOf ждёт все три, orTimeout добавлен в Java 9 и отменяет future по таймауту с TimeoutException, exceptionally даёт запасной вариант. join() внутри thenApply безопасен, потому что вызывается только после завершения всех трёх future.
Типовой вопрос про пулы: «Чем фиксированный пул потоков отличается от кэшируемого?» Фиксированный ограничивает количество потоков — задачи встают в очередь. Кэшируемый создаёт потоки по требованию и переиспользует простаивающие — при резком всплеске нагрузки может создать тысячи потоков и исчерпать ресурсы JVM.
Какие вопросы по JVM, GC и производительности задают middle/senior?
Тема JVM и производительности — водораздел между middle и senior. Junior может не знать деталей GC, но middle уже должен понимать, почему приложение начало тормозить после недели работы, а senior — уметь выстроить гипотезу и проверить её инструментами. Главный принцип, который ценят интервьюеры: говорить не магическими флагами JVM, а принципами диагностики и осознанными компромиссами.
Heap / stack / metaspace: что важно знать для реальных инцидентов?
Коротко: три области памяти JVM решают разные задачи, и понимание их границ помогает быстро локализовать проблему на продакшене.
- Heap — основная область для объектов. Делится на молодое поколение (Eden + пространства Survivor) и старое поколение. Большинство объектов живут недолго и умирают при малой сборке мусора (minor GC) — это нормально и быстро. Проблемы начинаются, когда объекты «протекают» в старое поколение и не освобождаются: растёт давление на полную сборку мусора (Full GC), паузы увеличиваются.
- Stack — память для каждого потока: кадры вызовов, локальные переменные, ссылки. Stack не участвует в GC. Типичная проблема — StackOverflowError при глубокой рекурсии или бесконечном вызове. Важная деталь: объекты, не «убегающие» за пределы метода, могут быть размещены JVM прямо на стеке (анализ ускользания) — это снижает давление на heap и GC.
- Metaspace (заменил PermGen в Java 8) хранит метаданные классов: байткод, константные пулы, методы. Metaspace растёт динамически и ограничена только системной памятью, если не задать -XX:MaxMetaspaceSize. Типичный инцидент: приложение с динамической генерацией классов (CGLIB-прокси в Spring, скрипты на Groovy) постепенно заполняет Metaspace — и получает OutOfMemoryError: Metaspace.
- Давление аллокаций — ситуация, когда приложение создаёт объекты быстрее, чем GC успевает их собирать. Симптомы: частые minor GC, высокая нагрузка на процессор от GC-потоков, деградация задержки. Решение — не всегда «настроить GC», а сначала найти источник аллокаций: профилировщик покажет, какие методы аллоцируют больше всего.
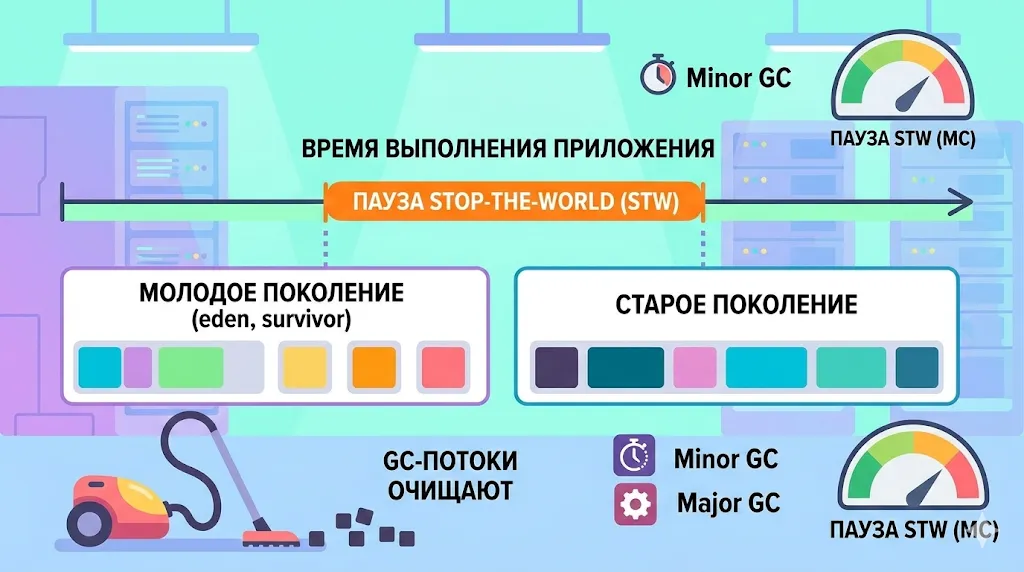
Иллюстрация процесса сборка мусора и паузы Stop-the-World (STW). Она показывает, как GC очищает поколения памяти, временно останавливая выполнение приложения, что критично для задержки.
Типовая ловушка: кандидат путает Metaspace с heap и не может объяснить, почему OutOfMemoryError: Metaspace возникает при нулевом росте heap. Понимание этого разграничения — маркер реального опыта с инцидентами на продакшене.
GC (G1 / ZGC / и др.): как отвечать корректно и не уйти в «магические настройки»?
Коротко: интервьюер не ждёт набора флагов — он ждёт понимания компромиссов. Главные оси: пропускная способность против задержки, и как разные GC балансируют между ними.
Stop-the-world (STW) — пауза, во время которой все потоки приложения останавливаются для работы GC. Чем меньше и предсказуемее паузы, тем лучше задержка. Чем больше GC успевает собрать за один проход — тем выше пропускная способность, но паузы могут быть длиннее.
| Цель | Симптомы проблемы | Ключевые метрики | Типичные шаги диагностики |
| Низкая задержка | Редкие, но длинные паузы; p99 скачет | Время паузы GC, длительность STW | Логи GC → найти долгие паузы → проверить размер старого поколения |
| Высокая пропускная способность | Процессор на GC > 5–10%; приложение «ступает» | Накладные расходы GC, скорость аллокаций | Профилировщик аллокаций → найти источник мусора |
| Утечка памяти | Heap растёт монотонно, Full GC не помогает | Размер живого набора, heap после Full GC | Дамп heap → анализ в MAT/VisualVM → найти корень удержания |
| OOM в Metaspace | OOM: Metaspace, классы не выгружаются | Использование/выделение Metaspace | Найти источник динамической генерации классов |
G1GC — сборщик мусора по умолчанию с Java 9. Делит heap на регионы равного размера, старается укладываться в целевое время паузы (-XX:MaxGCPauseMillis). Хорош как сбалансированный выбор для большинства приложений.
ZGC и Shenandoah — сборщики с очень низкими паузами (единицы миллисекунд даже на больших heap). ZGC стал пригодным для продакшена в Java 15, Shenandoah доступен в OpenJDK. Подходят для сервисов, критичных к задержке. Платят за это несколько большим расходом процессора и памяти.
Как отвечать корректно: не говорите «ZGC лучше G1». Говорите: «ZGC оптимизирован для минимальных пауз, но требует больше ресурсов. Для большинства серверных сервисов G1 с настроенным MaxGCPauseMillis — разумный выбор. Выбор GC должен опираться на измерения, а не на интуицию».
Профилирование и диагностика: дампы процессора / heap / потоков — что должен уметь кандидат?
Коротко: диагностика проблем производительности — это последовательное сужение гипотез, а не перебор настроек. Кандидат должен уметь описать шаги расследования, даже если никогда не использовал конкретный инструмент.
Схема расследования инцидента: рост памяти / рост задержки
Метрики (Prometheus/Grafana) └── Что растёт? Heap? CPU? Задержка? Число потоков? │ Логи GC └── Частота и длительность пауз → есть ли Full GC? │ Дамп потоков (jstack / /actuator/threaddump) └── Есть ли потоки в состоянии BLOCKED/WAITING? Взаимоблокировка? Горячие объекты-мониторы? │ Дамп heap (jmap / -XX:+HeapDumpOnOutOfMemoryError) └── Что занимает память? Крупные коллекции? Утечка через статические поля / слушатели / кэши? │ Профиль CPU (async-profiler / JFR) └── Какие методы потребляют процессор? Неожиданная сериализация? Регулярные выражения? Рефлексия? │ Гипотеза → воспроизведение → исправление → измерение
- Дамп потоков — снимок состояния всех потоков в момент времени. Признаки взаимоблокировки: два потока в состоянии BLOCKED, каждый ждёт монитор, который держит другой. Признаки голодания потоков: все потоки пула в WAITING, очередь задач растёт.
- Дамп heap — полный слепок heap. Анализируется в Eclipse MAT или VisualVM. Ключевые сценарии: найти объект с наибольшим удерживаемым heap, проследить цепочку корней GC до подозреваемого. Типичные источники утечек — статические коллекции, незакрытые слушатели, кэши без политики вытеснения.
- Профиль CPU — показывает, где реально тратится время. Часто оказывается, что узкое место не там, где ожидали: например, компиляция регулярного выражения внутри горячего метода или избыточная сериализация в логгере.
Что ценит интервьюер: не знание конкретных флагов, а способность рассуждать последовательно. «Я бы начал с метрик, затем посмотрел логи GC, потом взял дамп потоков» — это уже хороший ответ. Добавьте один реальный кейс из своего опыта — и ответ станет отличным.
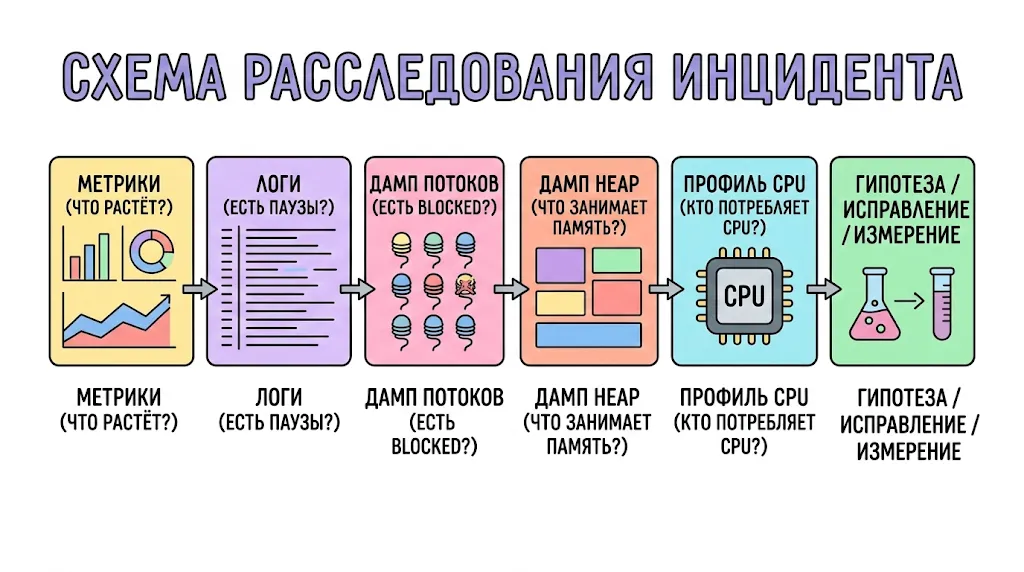
Визуализированная схема расследования инцидента производительности. Она предлагает структурированный подход: от анализа метрик и логов до снятия дампов и тестирования исправлений.
Какие возможности современной Java (17/21+) реально спрашивают на собеседованиях в 2026?
Важный контекст: большинство корпоративных команд работают на LTS-версиях — Java 17 или Java 21. Знание новых возможностей ценится, но интервьюер хочет убедиться не в том, что кандидат читал примечания к релизу, а в том, что понимает, зачем возможность появилась и где её применение оправдано. Разберём три блока, которые реально встречаются на собеседованиях.
| Возможность | Зачем | 1 вопрос на интервью | 1 практический кейс |
| Records | Убрать шаблонный код для классов-данных | Какие ограничения у records? | DTO для REST-ответа |
| Sealed classes | Ограничить иерархию наследования | Чем sealed лучше enum в моделировании? | Моделирование результата операции (Success/Failure) |
| Сопоставление с образцом (instanceof) | Убрать явное приведение типов | Как изменился switch с Java 21? | Обработка разных типов событий в диспетчере |
| Virtual threads | Дешёвые потоки для задач с ожиданием ввода-вывода | Чем отличаются от обычных потоков? | HTTP-сервер с тысячами одновременных соединений |
| Sequenced Collections | Единый API для упорядоченных коллекций | Что добавляет SequencedCollection? | Работа с первым/последним элементом без ухищрений |
| Предварительные возможности | Обкатка до стабилизации | Почему не стоит использовать в продакшене? | String Templates — пример осторожного упоминания |
Records, sealed, сопоставление с образцом: какие вопросы и практические кейсы?
Коротко: все три возможности решают одну проблему — многословность Java при моделировании данных и ветвлении логики. На собеседовании важно показать не только синтаксис, но и понимание ограничений.
Records появились в Java 16 как стабильная возможность. Record — это неизменяемый класс-данных: компилятор автоматически генерирует конструктор, геттеры, equals, hashCode и toString.
record Point(int x, int y) {}
Типовые вопросы и ограничения: record не может расширять другой класс (только реализовывать интерфейсы), все поля неявно final, нельзя добавить изменяемое состояние. Практический кейс — DTO для REST-ответа: меньше кода, неизменяемость «из коробки», хорошо работает с Jackson.
Sealed classes (Java 17) позволяют явно ограничить список подклассов:
sealed interface Shape permits Circle, Rectangle, Triangle {}
Ключевое преимущество перед enum: подтипы могут иметь разные поля и поведение. Компилятор знает полный список наследников, поэтому switch по sealed-иерархии может быть исчерпывающим — не нужен default. Практический кейс: моделирование результата операции (Success с данными, Failure с ошибкой) — аналог sealed class Result из Kotlin.
Сопоставление с образцом развивается от Java 16 (instanceof с переменной) до полноценного switch с образцами в Java 21:
switch (shape) {
case Circle c -> Math.PI * c.radius() * c.radius();
case Rectangle r -> r.width() * r.height();
case Triangle t -> triangleArea(t);
}
Компилятор проверяет исчерпывающность switch для sealed-иерархии. Типовой вопрос: «Что нового в switch с Java 21?» — охранные образцы (case Circle c when c.radius() > 0), обработка null в switch, исчерпывающность для sealed.
Типовая ловушка: кандидат говорит «records — это просто Lombok без аннотаций». Это поверхностное сравнение. Важнее подчеркнуть: records — языковая конструкция с семантическими гарантиями неизменяемости и полноценной поддержкой в компиляторе, IDE и механизме рефлексии.
Virtual threads: когда использовать и какие есть ограничения?
Коротко: virtual threads (Java 21, Project Loom) — не замена всем потокам, а решение конкретной проблемы: высокой стоимости обычных потоков при задачах с ожиданием ввода-вывода.
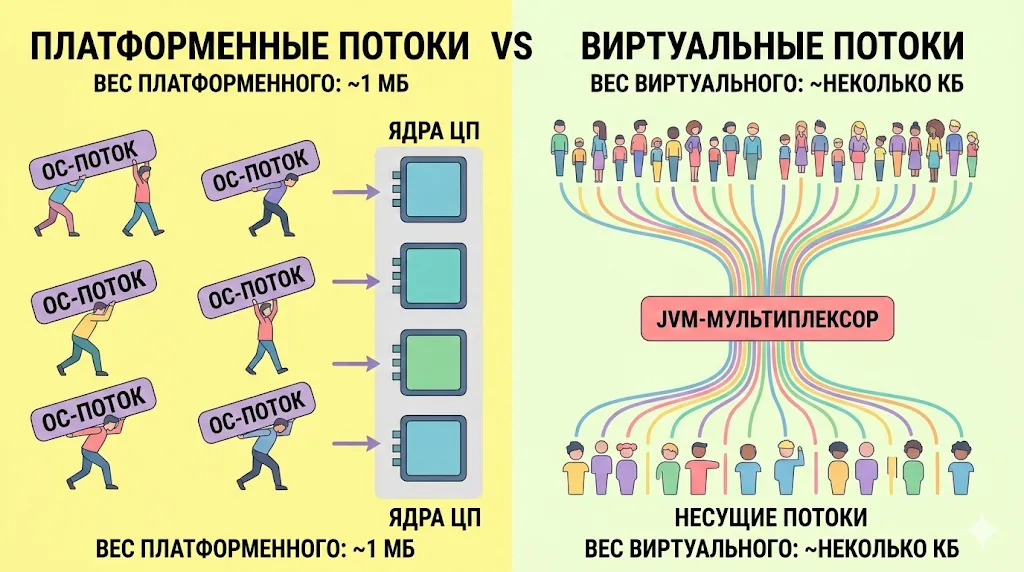
Инфографика, сравнивающая традиционные платформенные потоки (тяжеловесные и ограниченные по количеству) с новыми виртуальными потоками в Java 21+. Иллюстрация наглядно показывает, как легковесность виртуальных потоков позволяет достичь высокой пропускной способности.
Как работают. Обычный поток — обёртка над потоком операционной системы, их дорого создавать и их количество ограничено. Виртуальный поток — легковесная сущность, которую JVM мультиплексирует на пул несущих потоков. Блокирующий вызов в виртуальном потоке не блокирует поток ОС — JVM «паркует» виртуальный поток и освобождает несущий для другой задачи.
Когда хороши: серверы с большим количеством одновременных соединений с ожиданием ввода-вывода (HTTP, JDBC, файловые операции). Позволяют писать простой синхронный код без реактивного стека и получать сопоставимую пропускную способность.
Когда не решают: задачи, ограниченные вычислительными ресурсами — здесь узкое место не в ожидании, а в вычислениях. Увеличение числа виртуальных потоков не поможет. Также важно: synchronized-блоки и некоторые нативные вызовы могут «закреплять» виртуальный поток за несущим, снижая выгоду.
Типовые вопросы на интервью:
- «Чем виртуальный поток отличается от обычного?» — стоимостью создания и отсутствием прямой привязки к потоку ОС.
- «Можно ли использовать виртуальные потоки с блокирующими вызовами JDBC?» — да, и это одно из ключевых преимуществ; но драйвер не должен использовать synchronized внутри (большинство современных драйверов это учитывают).
- «Заменяют ли виртуальные потоки реактивное программирование?» — частично: для сервисов с ожиданием ввода-вывода да, но реактивный подход даёт дополнительный контроль над противодавлением и потоками данных.
Что ценит интервьюер: понимание того, что виртуальные потоки — не «серебряная пуля». Хороший ответ включает сценарий применения, ограничение и осознанный вывод: «для нашего HTTP-сервера с нагрузкой, ограниченной вводом-выводом, это имеет смысл, для пакетной обработки данных — нет».
Предварительные возможности (например, String Templates): как о них говорить безопасно?
Коротко: предварительные возможности — это языковые конструкции, включённые в JDK для обратной связи от сообщества, но ещё не стабилизированные. Они могут измениться или быть отозваны в следующем релизе.
Что важно понимать: использование предварительных возможностей требует явного флага компилятора (—enable-preview) и той же версии JDK в рантайме. Это означает, что код, написанный с предварительной возможностью, может перестать компилироваться или изменить поведение при обновлении JDK — серьёзный риск для продакшена.
String Templates — показательный случай. Возможность появилась как предварительная в Java 21, затем была пересмотрена и отозвана в Java 23: разработчики решили переработать дизайн. Именно поэтому она — идеальный пример для обсуждения на интервью: демонстрирует, что «предварительное» — это не «почти стабильно», а «может кардинально измениться».
Как говорить о предварительных возможностях на собеседовании:
- Не стоит: «String Templates — отличная возможность, я активно использую её в проекте».
- Стоит: «Я слежу за String Templates как за интересным направлением, но в продакшене использование предварительных возможностей несёт риск: API может измениться. String Templates уже были отозваны в Java 23 — хороший пример того, почему осторожность оправдана».
Такой ответ демонстрирует не просто знание возможности, но и зрелость инженерного мышления — именно это отличает уверенного middle от junior, который прочитал статью накануне.
Общий принцип для раздела «Современный Java»: знание новых возможностей — плюс. Понимание их ограничений и уместности — то, что реально отличает кандидата. На интервью выигрывает не тот, кто перечислил больше возможностей, а тот, кто объяснил, почему выбрал именно эту и при каких условиях она оправдана.
Какие вопросы по Spring Boot 3+ и архитектуре бэкенда чаще всего задают?
Spring Boot остаётся де-факто стандартом для Java-бэкенда в корпоративной разработке. Это означает, что на большинстве собеседований блок по Spring — не опциональный, а обязательный. В 2026 году фокус сместился: недостаточно знать аннотации, интервьюер хочет понять, понимает ли кандидат, что происходит «под капотом» — как работают прокси, почему транзакция не применяется, что изменилось при переходе на Boot 3. Разберём три ключевых блока.
Джош Лонг, Spring Developer Advocate: «Spring Boot 3 и GraalVM Native Image изменили правила игры. Теперь мы спрашиваем кандидатов не только про Dependency Injection, но и про то, как их код будет вести себя в условиях ограниченных ресурсов (Serverless/Containerized environment)».
Spring DI / AOP / транзакции: базовый минимум для большинства вакансий?
Коротко: DI, AOP и транзакции — три столпа Spring, которые спрашивают на 90% технических интервью. Поверхностного знания аннотаций недостаточно: важно понимать механику.
Внедрение зависимостей и жизненный цикл бина. Spring управляет объектами (бинами) через ApplicationContext. Жизненный цикл: создание → внедрение зависимостей → @PostConstruct → работа → @PreDestroy → уничтожение. Области видимости: singleton (один экземпляр на контекст, по умолчанию), prototype (новый при каждом запросе), request/session (для веб-слоя). Типовой вопрос: «Что произойдёт, если внедрить prototype-бин в singleton?» Ответ: prototype создастся один раз при инициализации singleton и не будет пересоздаваться — нарушение ожидаемой семантики. Решение — ObjectProvider или ApplicationContext.getBean().
AOP и прокси. Spring AOP реализован через прокси: динамический прокси JDK (для интерфейсов) или CGLIB (для классов). Аспекты (@Around, @Before, @After) применяются только при вызове через прокси-объект. Это объясняет главную ловушку — вызов изнутри: если метод класса вызывает другой метод того же класса напрямую (через this), прокси не задействован, и аспект не сработает. Типичные сценарии применения AOP: логирование, аудит, измерение времени выполнения, повторные попытки.
Транзакции. @Transactional работает через тот же механизм прокси. Ключевые параметры: propagation (как транзакция взаимодействует с существующей — REQUIRED, REQUIRES_NEW, NESTED), isolation (уровень изоляции — READ_COMMITTED, REPEATABLE_READ и др.), rollbackFor (по умолчанию откат только на RuntimeException).
Самый частый вопрос на интервью: «Почему @Transactional не работает?» Три главные причины:
- Вызов изнутри: метод вызывает транзакционный метод того же класса через this.
- Метод не public: Spring не применяет прокси к приватным и пакетным методам.
- Бин не управляется Spring: объект создан через new, а не через контейнер.
Типовая ловушка: кандидат знает @Transactional, но не может объяснить, почему транзакция не откатилась при проверяемом исключении. Правильный ответ: по умолчанию Spring откатывает транзакцию только на RuntimeException и Error. Для проверяемых нужно явно указать rollbackFor = MyCheckedException.class.
Spring Boot 3: Java 17+, Jakarta — что изменилось и что ломается при миграции?
Коротко: Spring Boot 3 — не просто обновление версии. Это смена базовых зависимостей и минимальных требований, которая ломает код, если к ней не готовиться.
Главные изменения:
- Java 17 — обязательная минимальная версия. Boot 2.x работал на Java 8+. Boot 3 требует Java 17 минимум.
- javax → jakarta. Oracle передала пространство имён Java EE в Eclipse Foundation. Все пакеты javax.* (Servlet, Persistence, Validation) переименованы в jakarta.*. Это ломает импорты, аннотации и конфигурации повсеместно.
- Hibernate 6, Spring Security 6, Micrometer 1.10 — обновлённые мажорные версии со своими критическими изменениями.
| Область | Boot 2 | Boot 3 | Что ломается |
| Пространство имён | javax.servlet, javax.persistence | jakarta.servlet, jakarta.persistence | Все импорты, аннотации JPA/Servlet |
| Минимальная Java | Java 8+ | Java 17+ | Проекты на Java 11 требуют обновления |
| Hibernate | Hibernate 5 | Hibernate 6 | Синтаксис HQL, некоторые маппинги |
| Spring Security | WebSecurityConfigurerAdapter | Бин SecurityFilterChain | Конфигурация безопасности переписывается |
| Actuator / метрики | Micrometer 1.x | Micrometer 1.10+ | API метрик, интеграции |
| Контейнер | Tomcat 9 (javax) | Tomcat 10+ (jakarta) | Развёртывание WAR на старый контейнер невозможно |
План миграции Boot 2 → Boot 3:
- Обновить Java до 17 (или 21)
- Заменить все javax.* импорты на jakarta.* (можно автоматизировать через OpenRewrite).
- Обновить Hibernate: проверить HQL-запросы и маппинги.
- Переписать конфигурацию Spring Security: убрать WebSecurityConfigurerAdapter.
- Проверить сторонние зависимости на совместимость с jakarta-namespace.
- Обновить контейнер развёртывания (Tomcat 10+, Jetty 11+).
- Прогнать интеграционные тесты — они первыми покажут проблемы.
- Проверить наблюдаемость: Micrometer, трейсинг (Micrometer Tracing заменил Spring Cloud Sleuth).
Практический совет для кандидата: если на интервью спрашивают о миграции, не ограничивайтесь «поменял javax на jakarta». Упомяните OpenRewrite — инструмент для автоматизированного рефакторинга, который умеет выполнять большую часть механических замен. Это покажет знакомство с реальной практикой.
Архитектура и практики на продакшене: REST, идемпотентность, кэш, очереди, наблюдаемость, тесты
Коротко: senior-кандидата отличает не знание аннотаций Spring, а понимание того, как сервис ведёт себя в распределённой среде — при сетевых сбоях, пиковой нагрузке, частичных отказах.
- REST и идемпотентность. Идемпотентность — свойство операции давать одинаковый результат при повторных вызовах. GET, PUT, DELETE — идемпотентны. POST — нет. Это важно для логики повторных попыток: безопасно повторять идемпотентные запросы при таймауте, небезопасно — POST без дополнительных мер (например, ключа идемпотентности). Типовые вопросы: версионирование API (URL vs заголовок), правильные HTTP-статусы (201 vs 200, 422 vs 400), обработка ошибок через @ControllerAdvice.
- Кэш и очереди. Кэш уместен, когда данные читаются значительно чаще, чем обновляются, и допустима небольшая задержка актуальности. Типовые ловушки: шквал запросов при инвалидации кэша, отсутствие TTL, кэширование изменяемых объектов без копирования. Очереди (Kafka, RabbitMQ) решают задачи асинхронной обработки, развязки сервисов и выравнивания нагрузки. Типовой вопрос: «Когда использовать очередь вместо синхронного HTTP?» — когда допустима итоговая согласованность, когда потребитель может быть временно недоступен, когда нужна гарантия доставки.
- Наблюдаемость. Три кита: логи, метрики, трассировка. Идентификатор корреляции — обязательный элемент: сквозной идентификатор запроса, который передаётся между сервисами и позволяет восстановить полную цепочку вызовов в распределённой системе. В Spring Boot 3 Micrometer Tracing (замена Sleuth) даёт интеграцию с Zipkin/Jaeger из коробки.
- Тесты. Пирамида тестирования: модульные (быстро, изолированно) → интеграционные (контекст Spring, реальные зависимости) → сквозные (медленно, хрупко). Testcontainers позволяет поднимать реальные зависимости (PostgreSQL, Kafka, Redis) в Docker прямо из тестов — значительно надёжнее заглушек для интеграционного тестирования. Типовой вопрос: «Когда использовать заглушки, а когда — Testcontainers?» — заглушка уместна для модульных тестов бизнес-логики, Testcontainers — для проверки работы с реальной БД или брокером.
Чек-лист Spring-вопросов перед интервью:
- Объяснить разницу между @Component, @Service, @Repository, @Controller.
- Описать механизм прокси в Spring AOP и проблему вызова изнутри.
- Объяснить, почему @Transactional может не сработать (3 причины).
- Рассказать, что изменилось в Spring Boot 3 (Java 17, jakarta, Security).
- Описать propagation: REQUIRED vs REQUIRES_NEW.
- Объяснить идемпотентность и как её обеспечить для POST.
- Рассказать, когда использовать кэш и какие у него ловушки.
- Объяснить, что такое идентификатор корреляции и зачем он нужен.
- Описать разницу между модульными и интеграционными тестами, привести пример с Testcontainers.
Как закрепить результат: репетиция интервью, портфолио и «карта пробелов»
Знание тем — необходимое, но не достаточное условие успешного интервью. Практика показывает: кандидат, который проработал материал вслух хотя бы несколько раз, проходит технические интервью значительно увереннее того, кто прочитал вдвое больше, но ни разу не объяснял это другому человеку.
Репетиция интервью. Проведите хотя бы 2–3 пробных интервью — с коллегой, наставником или в специализированных сервисах. Цель не в том, чтобы заучить ответы, а в том, чтобы найти темы, где объяснение «рассыпается» под первым уточняющим вопросом. Именно эти темы и есть ваши реальные пробелы — не те, что кажутся слабыми при чтении, а те, что не держатся при разговоре.
Карта пробелов. После каждого пробного интервью или самостоятельной проработки темы фиксируйте: что объяснили уверенно, что — с трудом, что не смогли объяснить вообще. Это живой документ, который показывает, куда направить следующие 2–3 часа подготовки. Типичная ошибка — повторять то, что уже знаешь хорошо, потому что это приятнее, чем разбирать сложное.
STAR-истории. Подготовьте 5–10 коротких историй из своего опыта по схеме: Situation → Task → Action → Result. Полезные темы: ошибка, которую долго не могли найти; оптимизация, которая дала измеримый результат; инцидент на продакшене и как его разбирали; архитектурное решение с компромиссами; технический спор в команде. Эти истории работают на поведенческих вопросах, но также помогают «заземлить» технические ответы реальным контекстом.
Портфолио. Небольшой учебный проект или значимый вклад в открытый исходный код — не обязательное условие, но заметный плюс. Достаточно одного проекта с понятным README, тестами и осознанными архитектурными решениями. Ещё лучше — если вы можете рассказать, какие компромиссы принимали и почему.
Чек-лист ответов: как структурировать объяснение
Универсальная схема, которая работает для любой технической темы на интервью:
Определение └── Что это такое — одним-двумя предложениями, без лишних оговорок Пример └── Конкретный сценарий или короткий фрагмент кода, который иллюстрирует суть Компромиссы └── Плюсы и минусы, при каких условиях подход работает, а при каких — нет Уточнение (опционально) └── Если вопрос неоднозначен — спросите контекст: «Вы имеете в виду в контексте многопоточности или просто структуры данных?»
Эта схема решает главную проблему большинства кандидатов — ответы без структуры, которые либо слишком короткие («это когда объект нельзя изменить»), либо слишком длинные и уходят в сторону. Определение показывает, что вы знаете тему. Пример показывает, что применяли. Компромиссы показывают инженерную зрелость.
Если вы готовитесь к интервью и только начинаете осваивать профессию разработчика, рекомендуем обратить внимание на подборку курсов по Java-разработке. В них обычно есть теоретическая часть с разбором ключевых тем и практическая часть с задачами и проектами, которые помогают подготовиться к реальным собеседованиям.
Рекомендуем посмотреть курсы по Java
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Java-разработчик
|
Eduson Academy
112 отзывов
|
Цена
133 900 ₽
|
От
11 158 ₽/мес
0% на 24 месяца
15 476 ₽/мес
|
Длительность
8 месяцев
|
Старт
скоро
Пн,Ср, 19:00-22:00
|
Подробнее |
|
Профессия Java-разработчик
|
Skillbox
226 отзывов
|
Цена
190 971 ₽
381 943 ₽
Ещё -20% по промокоду
|
От
5 617 ₽/мес
Это минимальный ежемесячный платеж. От Skillbox без %.
8 692 ₽/мес
|
Длительность
9 месяцев
Эта длительность обучения очень примерная, т.к. все занятия в записи (но преподаватели ежедневно проверяют ДЗ). Так что можно заниматься более интенсивно и быстрее пройти курс или наоборот.
|
Старт
11 марта
|
Подробнее |
|
Java-разработчик с нуля
|
Нетология
46 отзывов
|
Цена
114 900 ₽
319 224 ₽
с промокодом kursy-online
|
От
3 546 ₽/мес
Без переплат на 2 года.
|
Длительность
14 месяцев
|
Старт
16 марта
|
Подробнее |
|
Java-разработчик
|
Академия Синергия
36 отзывов
|
Цена
103 236 ₽
|
От
4 302 ₽/мес
0% на 24 месяца
|
Длительность
6 месяцев
|
Старт
17 марта
|
Подробнее |
|
Java-разработка
|
Moscow Digital Academy
66 отзывов
|
Цена
132 720 ₽
165 792 ₽
|
От
5 530 ₽/мес
на 12 месяца.
6 908 ₽/мес
|
Длительность
12 месяцев
|
Старт
в любое время
|
Подробнее |

Skypro vs Karpov.Courses: где проще освоить A/B и статистику без боли
Курсы A/B-тестирования обещают научить работать с экспериментами и статистикой, но форматы обучения могут сильно отличаться. Какая программа подойдет новичкам, а какой курс лучше выбрать специалистам с опытом? В статье разбираем ключевые критерии выбора и базовые принципы экспериментов.

Яндекс Практикум vs Eduson Academy: project management — где больше инструментов и симуляций
Выбираете курсы по управлению проектами и пытаетесь понять, где больше практики, инструментов и реального опыта работы? В этом материале разбираем программы Яндекс Практикума и Eduson Academy: какие навыки вы получите, какие инструменты освоите и какой формат обучения подойдёт именно вам.

Skillbox vs Eduson Academy: менеджер маркетплейсов — где больше шаблонов и прикладных задач
Курсы менеджера маркетплейсов обещают практику, шаблоны и быстрый старт, но что из этого действительно работает? Разбираем, как проверить программу до оплаты и выбрать обучение под свою цель.

Skypro vs Нетология: где наставники помогают по делу, а где поддержка формальная
Skypro или Нетология — где наставники действительно помогают разобраться в заданиях, а где поддержка может оказаться формальной? Разбираем роли наставников, качество фидбэка, сроки проверки домашних работ и карьерное сопровождение, чтобы понять, как проверить онлайн-курс до оплаты.