Вопросы системному администратору на собеседовании: полный чек-лист и примеры ответов
Собеседование на позицию системного администратора — это не просто формальная беседа о том, умеете ли вы перезагружать сервер или знаете, что такое IP-адрес. Это полноценное испытание, где работодатель старается выяснить, способны ли вы в три часа ночи восстановить упавшую базу данных, не разбудив при этом половину офиса паникой, а кандидат, в свою очередь, старается понять, не окажется ли новая работа адом с legacy-инфраструктурой, где документация последний раз обновлялась при Горбачёве.

Эта статья — своего рода двусторонний путеводитель. Если вы HR или технический директор, здесь вы найдёте структурированный набор вопросов, которые помогут отличить действительно компетентного специалиста от того, кто просто умеет гуглить коды ошибок. Если же вы соискатель — считайте, что получили шпаргалку с разбором вопросов, примерами ответов и пониманием того, что именно хотят услышать по ту сторону стола. Потому что, признаемся честно, просто знать технологии недостаточно — нужно ещё уметь об этом рассказать так, чтобы не выглядеть ни слишком самоуверенным, ни излишне скромным.
- Как проходит собеседование сисадмина
- Базовые вопросы для системного администратора
- Вопросы по Linux и Unix-системам
- Вопросы по Windows-инфраструктуре
- Вопросы по сетям, серверам и виртуализации
- Мониторинг и управление инфраструктурой
- Вопросы по безопасности и защите данных
- Soft skills и ситуационные вопросы
- Как готовиться к собеседованию системному администратору
- Чек-лист вопросов работодателю от кандидата
- Заключение
- Рекомендуем посмотреть курсы по системному администрированию
Как проходит собеседование сисадмина
Собеседование системного администратора — это не спонтанный разговор за чашкой кофе, а структурированный процесс, состоящий обычно из нескольких этапов, каждый из которых призван выявить определённые качества кандидата (и заодно проверить, не соврал ли он в резюме о своих «глубоких знаниях Kubernetes», хотя на самом деле один раз запустил контейнер по инструкции из интернета).

Пример вакансии на системного администратора с указанным списком обязанностей и требований. Скриншот с сайта hh.ru.
- Первый этап — это вводный разговор, где собеседующий знакомится с кандидатом, уточняет мотивацию, обсуждает опыт работы и ожидания от новой позиции. Здесь важно не столько техническое содержание, сколько общее впечатление: адекватен ли человек, способен ли внятно формулировать мысли, не начнёт ли он через неделю жаловаться, что «это не то, что я ожидал».
- Второй этап — технический блок, где начинается настоящая проверка знаний: вопросы про протоколы, команды, настройку серверов и сетей, иногда с просьбой решить задачу на месте или описать алгоритм действий в той или иной ситуации.
- Третий этап — кейсы и ситуационные вопросы, где кандидату предлагают разобрать реальные (или приближённые к реальным) инциденты: «Упал сервер в пятницу вечером, что делаете?» или «Пользователь жалуется, что не может зайти в почту, ваши действия?». Здесь проверяется не только техническая подкованность, но и умение мыслить логически, расставлять приоритеты и не паниковать.
- Четвёртый этап — оценка soft skills: как кандидат взаимодействует с командой, насколько он стрессоустойчив, готов ли обучать коллег и объяснять технические нюансы руководству, которое искренне не понимает, почему нельзя просто «взять и починить всё за пять минут».
Кто проводит собеседование? Обычно это HR-специалист на первом этапе (проверка адекватности и соответствия базовым требованиям) и технический директор или старший системный администратор на втором и третьем (глубокая техническая экспертиза). Формат может быть разным: очное интервью в офисе, онлайн-встреча по видеосвязи или даже тестовое задание — например, настроить виртуальную машину, поднять DHCP-сервер или написать скрипт для автоматизации рутинных задач.
Базовые вопросы для системного администратора
Эти вопросы охватывают широкий спектр тем: от личного опыта и мотивации до понимания сетевых протоколов, файловых систем и стратегий резервного копирования — то есть всего того, без чего системный администратор превращается в человека с красивым титулом, но без реальных навыков.
Общие вопросы о себе и опыте
Казалось бы, что может быть проще, чем рассказать о себе? Но именно здесь многие кандидаты начинают либо слишком скромничать («ну, я просто настраивал компьютеры»), либо, наоборот, уходят в пространные монологи о каждом проекте за последние десять лет, заставляя интервьюера мысленно проверять почту.
Работодатель хочет услышать конкретику: какие обязанности вы выполняли на предыдущих местах, с какими системами и технологиями работали, какие проекты реализовали (желательно с примерами и результатами — «поднял новый сервер» звучит куда убедительнее, если добавить «что позволило сократить время обработки запросов на 30%»).
Типичные вопросы в этом блоке:
- Расскажите о вашем опыте работы системным администратором
- Какие проекты или задачи вы считаете наиболее значимыми в своей карьере?
- Почему вы хотите работать именно у нас?
- С какими операционными системами вы работали и какая из них вам ближе?
- Приведите пример сложной технической проблемы, которую вам удалось решить.
Ключ к успешному ответу — структура и честность. Не нужно приукрашивать (это всё равно вскроется на практике), но и скромничать излишне тоже не стоит. Если вы действительно в одиночку мигрировали всю инфраструктуру компании на новые серверы без простоев — расскажите об этом, но без пафоса, а с акцентом на конкретные действия и результаты.
Основы сетей и инфраструктуры
Здесь начинается настоящая техническая часть, и если кандидат не может объяснить разницу между DNS и DHCP, это примерно как повар, который не знает, чем соль отличается от сахара — формально оба белые и сыпучие, но результат использования будет радикально разным.
DNS и DHCP — это два базовых протокола, без понимания которых администрировать сеть невозможно.
DNS (Domain Name System) переводит понятные человеку доменные имена (например, google.com) в IP-адреса, которые понимают компьютеры — это своего рода телефонная книга интернета, только автоматическая и гораздо быстрее.
DHCP (Dynamic Host Configuration Protocol) автоматически раздаёт IP-адреса устройствам в сети, чтобы вам не приходилось вручную настраивать каждый компьютер, планшет и чайник с Wi-Fi (да, IoT-устройства тоже нуждаются в IP-адресах, как бы абсурдно это ни звучало).
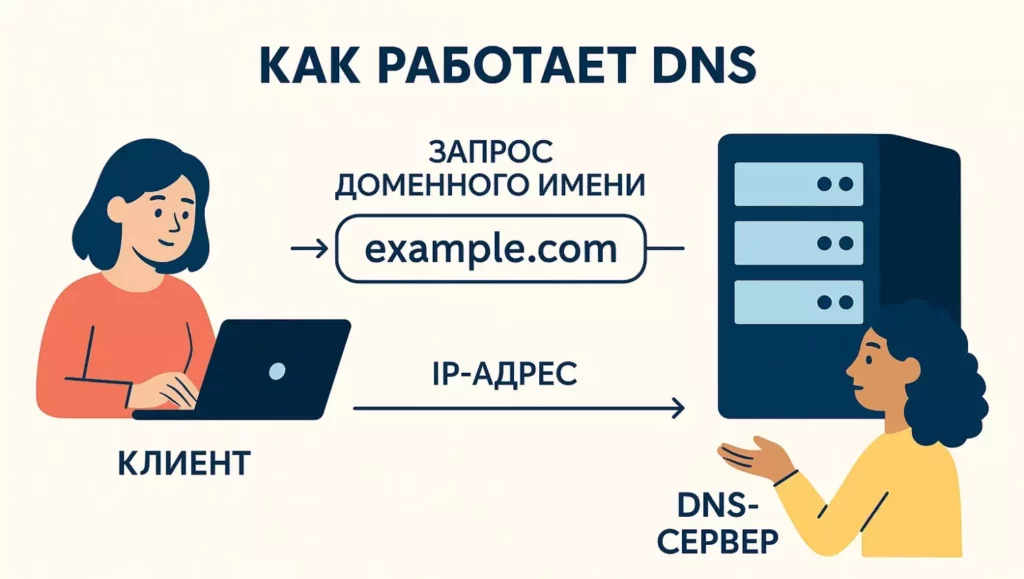
Эта схема показывает, как DNS преобразует доменное имя, введённое пользователем, в соответствующий IP-адрес. Клиент отправляет запрос на DNS-сервер, который возвращает нужный адрес для подключения к сайту. Иллюстрация помогает быстро понять базовый принцип работы доменной системы.
- IP-адреса, TCP/UDP, HTTP-коды — ещё одна обязательная область знаний. IP-адрес — это уникальный идентификатор устройства в сети (бывают IPv4 и IPv6, причём переход на последний идёт болезненно медленно, потому что legacy-системы — это вечность).
- TCP и UDP — два транспортных протокола: TCP гарантирует доставку данных и их порядок (используется там, где важна надёжность — например, веб-страницы, почта), а UDP работает быстрее, но без гарантий (используется для стриминга, видеозвонков, онлайн-игр, где важнее скорость, чем стопроцентная точность).
- HTTP-коды — это числовые коды ответов сервера: 200 означает «всё ок», 404 — «страница не найдена», 500 — «что-то сломалось на сервере» (и если админ видит 500, значит, ему предстоит интересный вечер с логами).
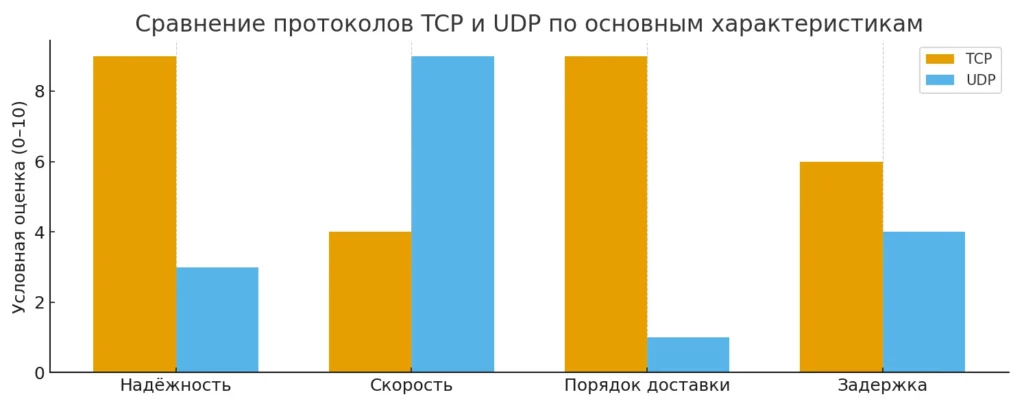
Столбчатая диаграмма сравнивает TCP и UDP по четырём ключевым характеристикам: надёжность, скорость, сохранение порядка доставки и задержка. Визуальное сопоставление помогает читателю быстро понять, почему TCP используют там, где важна гарантированная доставка, а UDP — там, где критична скорость.
Команды диагностики сети: ping (проверяет доступность узла в сети), traceroute (показывает маршрут пакетов до цели — полезно, когда нужно понять, где именно всё тормозит), nslookup (проверяет работу DNS и показывает, какой IP-адрес соответствует домену). Любой системный администратор должен владеть этими инструментами на уровне рефлекса — если сеть не работает, это первое, что запускается.
Быстрые определения базовых сетевых протоколов
| Протокол / понятие | Что делает | Где используется | Что важно знать на собеседовании |
| DNS | Преобразует доменные имена в IP-адреса | Любой интернет-трафик | Уметь диагностировать: nslookup, кэш, запись А/AAAA, проблемы резолвинга |
| DHCP | Автоматически выдаёт IP-адреса клиентам | Локальные сети | Диагностика конфликтов IP, аренда, резервирование |
| TCP | Гарантирует доставку и порядок пакетов | Веб-страницы, почта, API | Отличия от UDP, трёхстороннее рукопожатие |
| UDP | Быстрая передача без гарантий | Видео, игры, звонки | Почему используется там, где важна скорость |
| HTTP-коды | Сообщают статус ответа сервера | Веб-приложения | Изучить 200 / 301 / 400 / 403 / 404 / 500 как основу |
RAID, файловые системы и резервное копирование
RAID (Redundant Array of Independent Disks) — это технология, которая объединяет несколько физических дисков в одну логическую единицу для повышения производительности, надёжности или того и другого одновременно (в зависимости от уровня RAID). RAID 0 увеличивает скорость, но не даёт отказоустойчивости (один диск сгорел — всё пропало). RAID 1 зеркалирует данные на два диска (если один умер, второй продолжает работать).
RAID 5 требует минимум три диска и распределяет данные с контрольными суммами — можно потерять один диск без утраты информации. RAID 6 похож на RAID 5, но выдерживает выход из строя двух дисков. RAID 10 — это комбинация RAID 1 и RAID 0, дающая и скорость, и отказоустойчивость, но требующая минимум четыре диска.
Какой выбрать? Зависит от задач, бюджета и паранойи относительно потери данных (и правильная паранойя в IT — это не психическое расстройство, а профессиональное качество).Сравнение RAID уровней
Диаграмма показывает условное сравнение уровней RAID по двум ключевым параметрам — скорости и отказоустойчивости. Такой визуальный формат помогает читателю быстро понять компромиссы каждого уровня и выбрать подходящий вариант под задачу и бюджет.
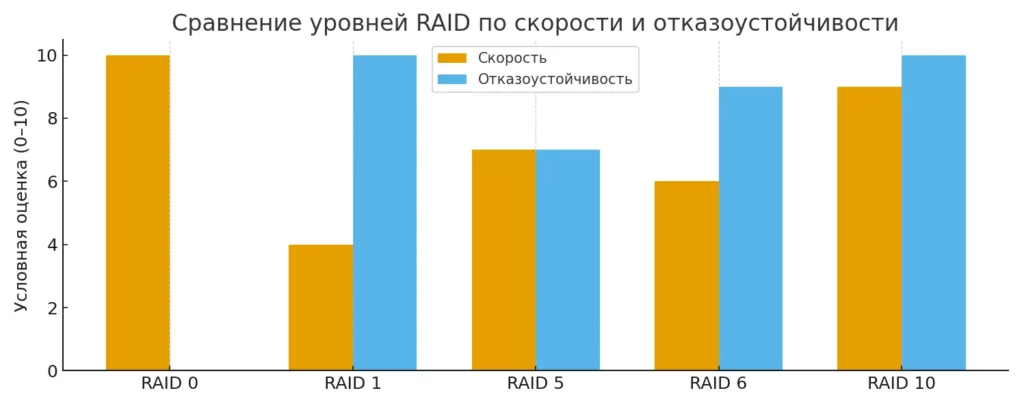
Диаграмма показывает условное сравнение уровней RAID по двум ключевым параметрам — скорости и отказоустойчивости. Такой визуальный формат помогает читателю быстро понять компромиссы каждого уровня и выбрать подходящий вариант под задачу и бюджет.
Файловые системы — это способ организации данных на диске. В Windows это обычно NTFS (современная, с поддержкой прав доступа и шифрования), в Linux — ext4, XFS, Btrfs (каждая со своими особенностями: ext4 стабильна и проверена временем, XFS хороша для больших файлов, Btrfs поддерживает снапшоты и продвинутые функции, но менее распространена).
Резервное копирование — это святое. Не делать бэкапы — это как ездить без страховки и ремня безопасности одновременно: может, повезёт, а может, и нет.
Стратегии бывают разные: полное копирование (долго, но надёжно), инкрементное (копируются только изменения с последнего полного бэкапа — быстрее, но восстановление сложнее), дифференциальное (копируются изменения с последнего полного, но каждый раз добавляются новые — компромисс между скоростью и удобством восстановления).
Правило 3-2-1: три копии данных, на двух разных носителях, одна из которых хранится вне офиса. И да, нужно регулярно проверять, что бэкапы действительно работают — потому что резервная копия, которую невозможно восстановить, это просто цифровой хлам, занимающий место.
Вопросы по Linux и Unix-системам
Linux — это ОС, которая либо вызывает у системных администраторов искреннее восхищение (свобода, гибкость, мощь командной строки), либо лёгкую панику у тех, кто всю жизнь работал исключительно в Windows и привык к графическим интерфейсам (хотя и в Linux они есть, просто настоящие профессионалы предпочитают терминал — это быстрее, эффективнее и выглядит солиднее в глазах коллег). На собеседовании вопросы по Linux проверяют не только знание команд, но и понимание философии системы, умение управлять пользователями и процессами, настраивать сеть и безопасность — то есть всё то, что превращает человека с сертификатом в настоящего специалиста.
Основные команды Linux — это азбука системного администратора.
- Для работы с файлами: ls (показать содержимое директории), cp (скопировать файл), mv (переместить или переименовать), rm (удалить — причём rm -rf может уничтожить всё без возможности восстановления, так что осторожнее с этой командой, особенно если вы под root).
- Для управления процессами: ps (показать запущенные задачи), top (интерактивный мониторинг в реальном времени — удобно, когда нужно понять, что именно жрёт все ресурсы), kill (завершить процесс по его ID, причём kill -9 — это уже «убить без вариантов», когда процесс не хочет закрываться по-хорошему).
- Для работы с сетью: ping (проверить доступность узла), netstat (показать сетевые соединения и открытые порты), ifconfig или ip (настройка и просмотр сетевых интерфейсов — ifconfig считается устаревшей, но многие по привычке продолжают её использовать).
- Для управления правами доступа: chmod (изменить права на файл или директорию — помните цифровую нотацию: 755, 644 и так далее?), chown (сменить владельца файла). Это лишь верхушка айсберга, но если кандидат уверенно оперирует этими командами и может объяснить, что делает каждая, это уже хороший знак.
Управление пользователями и группами — ещё одна обязательная область знаний. В Linux пользователи создаются командой adduser или useradd (в зависимости от дистрибутива — первая более дружелюбная и интерактивная, вторая — низкоуровневая), изменяются через usermod (например, добавить пользователя в группу или сменить его домашнюю директорию), удаляются через userdel. Группы управляются командами groupadd (создать), groupmod (изменить), groupdel (удалить). Всё это критично для правильной организации доступа к ресурсам: например, чтобы несколько пользователей могли работать с одними и теми же файлами, но не имели доступа к чужим данным.
Установка и обновление пакетов — это как раз та область, где разные дистрибутивы Linux идут своими путями, и администратор должен знать, какой менеджер пакетов используется в его системе. В Debian и Ubuntu это apt или apt-get (команды вроде apt update для обновления списка пакетов и apt upgrade для установки), в Red Hat, CentOS и Fedora — yum или более современный dnf (по функционалу похожи на apt, но с небольшими отличиями в синтаксисе).
Важно понимать не только как установить пакет, но и как разрешать зависимости, откатывать обновления и добавлять сторонние репозитории (хотя последнее нужно делать осторожно, чтобы не превратить систему в нестабильное месиво из несовместимых версий).
Настройка firewall — это защита системы от внешних угроз, и в Linux для этого используются несколько инструментов.
- iptables — классический, мощный, но довольно сложный в освоении файрвол, работающий на уровне сетевых пакетов (нужно прописывать правила для входящих, исходящих и транзитных соединений, и одна ошибка может либо заблокировать легитимный трафик, либо оставить дыру в безопасности).
- firewalld — более современная и дружелюбная надстройка над iptables, используется в Red Hat-based дистрибутивах и позволяет управлять правилами через зоны и сервисы (проще для новичков, но под капотом всё равно работает iptables).
- ufw (Uncomplicated Firewall) — упрощённый файрвол для Ubuntu, где команды вроде ufw allow 22/tcp делают настройку интуитивно понятной даже для тех, кто только начинает разбираться в сетевой безопасности.
На собеседовании важно не только назвать эти инструменты, но и объяснить, когда какой использовать и как проверить, что правила работают корректно (спойлер: заблокировать себе SSH-доступ к удалённому серверу — классическая ошибка, после которой приходится идти в датацентр с ногами и просить физического доступа к консоли).

Иллюстрация показывает момент технического собеседования: кандидат и интервьюер обсуждают опыт, задачи и ожидаемые компетенции. Такая визуализация помогает читателю почувствовать атмосферу реального интервью и лучше понять контекст вопросов, рассматриваемых в статье.
Вопросы по Windows-инфраструктуре
Active Directory (AD) — это сердце Windows-инфраструктуры, служба каталогов Microsoft, которая позволяет администраторам централизованно управлять пользователями, компьютерами, группами и ресурсами в сети.
Представьте это как единую базу данных, где хранится информация обо всех объектах в домене: кто имеет доступ к файлам, какие права есть у каждого пользователя, что за политики безопасности применяются к конкретным компьютерам. AD работает по принципу домена — все устройства и пользователи входят в единую структуру, управляемую контроллером домена (Domain Controller), и это даёт массу преимуществ: единый вход (пользователь вводит пароль один раз и получает доступ ко всем ресурсам), централизованное управление (не нужно бегать к каждому компьютеру, чтобы создать учётную запись или изменить права), возможность применять групповые политики.
Если кандидат не понимает, что такое Active Directory и как с ним работать, это серьёзный минус для позиции системного администратора в корпоративной среде — потому что AD это не просто технология, это целая экосистема, без которой управление Windows-инфраструктурой превращается в хаос.
Group Policy (групповые политики) — это инструмент Windows для централизованного управления настройками операционной системы и приложений на всех компьютерах в домене. С помощью Group Policy администратор может устанавливать политики безопасности (например, требовать сложные пароли или блокировать USB-порты), управлять установкой программного обеспечения (автоматически разворачивать нужные приложения на всех компьютерах без участия пользователей), настраивать параметры рабочего стола (запретить изменение обоев или отключить доступ к панели управления — полезно, когда пользователи слишком любопытны и постоянно что-то ломают), контролировать обновления и многое другое.
Групповые политики редактируются через консоль Group Policy Management, где можно создавать GPO (Group Policy Objects) и применять их к отдельным пользователям, группам или организационным единицам (OU). Это мощнейший инструмент, но требующий понимания иерархии и наследования политик — потому что неправильно настроенная GPO может либо ничего не сделать (если она перекрыта другой политикой выше по иерархии), либо наоборот, заблокировать что-то важное и вызвать массовые жалобы пользователей (что, конечно, добавит администратору популярности в коллективе).
Типичные вопросы по Windows-инфраструктуре и что ожидают услышать
| Тема | Пример вопроса | Что хочет услышать интервьюер | Ошибки кандидатов |
| Active Directory | «Как создаётся пользователь и что такое OU?» | Понимание структуры домена, ролей контроллеров, делегирования прав | Путаница между локальными и доменными пользователями |
| Group Policy (GPO) | «Как запретить USB-накопители для отдела?» | Знание наследования, приоритетов, работы с GPMC | Попытка менять настройки не там (вручную на ПК) |
| Реестр Windows | «Как изменить параметр, недоступный в GUI?» | Знание ключевых веток (HKLM/HKCU), умение работать безопасно | Изменение ключей без резервной копии |
| WSUS / обновления | «Как вы раскатываете обновления?» | Понимание этапов: тест → одобрение → развёртывание, групповая политика | «Мы просто ставим обновления вручную» |
| Управление пользователями | «Как сбросить пароль и заставить сменить при входе?» | Уверенная работа с ADUC, атрибутами пользователя | Путаница с политиками паролей или отсутствие понимания ролей |
Управление пользователями и группами в Windows выполняется через несколько инструментов. Для локальных пользователей (на отдельном компьютере, не входящем в домен) используется оснастка «Управление компьютером» (compmgmt.msc), где можно создавать, изменять и удалять учётные записи, назначать их в группы, устанавливать права.
Для доменных пользователей используется консоль «Active Directory Users and Computers» (dsa.msc) — здесь администратор управляет всеми объектами в AD: создаёт пользователей, группы, организационные единицы, назначает права и атрибуты, сбрасывает пароли (что, кстати, одна из самых частых задач, потому что пользователи забывают пароли с завидной регулярностью).
Важно понимать разницу между локальными и доменными учётными записями, знать типы групп (безопасности для управления доступом, рассылки для email), понимать принципы делегирования прав (чтобы не давать всем подряд права администратора домена, а выдавать только минимально необходимые привилегии).
- Установка и обновление ПО в Windows-среде может осуществляться несколькими способами. Для установки программ используются загрузчики MSI (Microsoft Installer — стандартный формат, поддерживающий автоматизацию и развёртывание через групповые политики) или EXE (обычные исполняемые файлы, часто требующие ручного запуска).
- Обновления операционной системы управляются через Windows Update (для домашних пользователей и малых организаций) или WSUS (Windows Server Update Services — для корпоративной среды, где нужно контролировать, какие обновления устанавливаются, когда и на какие компьютеры).
- WSUS позволяет администратору тестировать обновления на отдельных машинах перед массовым развёртыванием — это критично, потому что Microsoft имеет славную традицию выпускать обновления, которые иногда ломают больше, чем исправляют (и каждый опытный администратор хотя бы раз в жизни сталкивался с ситуацией, когда после обновления половина компьютеров не загружается).
- Работа с реестром Windows — это область, где одно неверное движение может превратить рабочую систему в нечто нефункциональное (именно поэтому перед любыми изменениями нужно делать резервную копию реестра).
- Реестр (Windows Registry) — это иерархическая база данных, где хранятся настройки операционной системы, установленных программ, параметры оборудования и пользовательские предпочтения. Редактируется через regedit.exe — инструмент, который выглядит обманчиво просто, но требует точного понимания, что делает каждый ключ и параметр.
Типичные задачи: изменение настроек, недоступных через графический интерфейс, исправление ошибок после неудачной установки программ, тонкая настройка производительности.
Важно знать основные разделы реестра: HKEY_LOCAL_MACHINE (настройки системы), HKEY_CURRENT_USER (настройки текущего пользователя), HKEY_CLASSES_ROOT (ассоциации файлов и COM-объекты) и другие. И да, если администратор лезет в реестр без понимания, что он делает, последствия могут быть катастрофическими — от потери данных до полной переустановки системы.
Вопросы по сетям, серверам и виртуализации
На собеседовании эти темы проверяют глубину технических знаний, понимание архитектуры систем и способность кандидата проектировать, настраивать и поддерживать сложную инфраструктуру, которая должна работать стабильно, быстро и безопасно (а ещё желательно не требовать вмешательства администратора каждые пять минут).
Сетевые устройства и протоколы
Сетевые устройства — это оборудование, которое связывает компьютеры, серверы и другие устройства в единую инфраструктуру, и понимание того, как они работают и чем отличаются друг от друга, это базовое требование к системному администратору.
Switch (коммутатор) и router (маршрутизатор) — два устройства, которые часто путают новички, хотя они выполняют разные функции. Switch работает на канальном уровне (Layer 2 модели OSI) и соединяет устройства внутри одной локальной сети, пересылая пакеты на основе MAC-адресов — это как почтальон, который доставляет письма внутри одного дома. Router работает на сетевом уровне (Layer 3) и соединяет разные сети между собой, маршрутизируя пакеты на основе IP-адресов — это как почтальон, который развозит письма между разными городами.
Есть ещё управляемые (managed) и неуправляемые (unmanaged) свитчи: первые позволяют настраивать VLAN, мониторить трафик, управлять портами, а вторые просто работают «из коробки» без возможности тонкой настройки (подходят для домашнего использования, но не для серьёзной инфраструктуры).
VLAN (Virtual Local Area Network) — это технология, которая позволяет разделить одну физическую сеть на несколько виртуальных для улучшения производительности и безопасности.
Представьте офис, где в одной сети работают бухгалтерия, отдел разработки и гости с Wi-Fi — без VLAN все эти устройства видят друг друга, что создаёт риски безопасности и лишний broadcast-трафик(который снижает производительность). С помощью VLAN можно изолировать эти группы: бухгалтерия в одном VLAN, разработчики в другом, гости в третьем — и даже если физически все подключены к одному свитчу, логически они находятся в разных сетях и не могут напрямую обмениваться данными (если только не настроить маршрутизацию между VLAN, но это уже отдельная история).
BGP (Border Gateway Protocol) — это протокол маршрутизации, который используется для обмена информацией о маршрутах между автономными системами в интернете. Для большинства системных администраторов BGP — это экзотика, которая нужна только в крупных организациях с собственными AS-номерами или в дата-центрах, но знание хотя бы базовых принципов (что BGP выбирает маршруты на основе политик, а не метрик, и что неправильная конфигурация BGP может уронить значительную часть интернета) добавляет солидности на собеседовании.
Мониторинг сети — это критически важная задача, потому что проблемы нужно обнаруживать до того, как пользователи начнут жаловаться (или, что ещё хуже, до того, как бизнес-процессы встанут).
Инструменты мониторинга отслеживают доступность устройств, загрузку каналов, ошибки на интерфейсах, задержки и потери пакетов. Популярные решения включают SNMP-мониторинг (Simple Network Management Protocol — стандартный протокол для сбора информации с сетевого оборудования), анализаторы трафика (например, Wireshark для глубокого разбора пакетов) и системы визуализации (графики, дашборды, алерты). Хороший администратор настраивает мониторинг так, чтобы получать уведомления о проблемах заранее, а не узнавать о них от разгневанного директора, у которого перестала открываться почта.
Виртуализация и облака
Виртуализация — это технология, которая позволяет запускать несколько виртуальных машин (VM) на одном физическом сервере, каждая со своей операционной системой и приложениями, но при этом изолированными друг от друга. Это революция в IT-инфраструктуре, потому что раньше для каждого сервиса нужен был отдельный физический сервер (что дорого, неэффективно и занимает много места), а теперь можно консолидировать всё на нескольких мощных машинах и гибко перераспределять ресурсы.
Типы включают: виртуализацию серверов (самая распространённая — VMware vSphere, Microsoft Hyper-V, KVM), сетей (создание виртуальных коммутаторов и маршрутизаторов), хранилищ (объединение физических дисков в пулы с гибким распределением), приложений (запуск программ в изолированной среде без полноценной установки) и виртуализацию рабочих станций (VDI — Virtual Desktop Infrastructure, когда пользователи работают с виртуальными десктопами, размещёнными на сервере).
- Гипервизоры — это программное обеспечение, которое создаёт и управляет виртуальными машинами. Бывают два типа: Type 1 (bare-metal) устанавливается непосредственно на оборудование без промежуточной операционной системы (примеры: VMware ESXi, Microsoft Hyper-V, Xen, KVM) — это производительнее и надёжнее, используется в корпоративной среде; Type 2 (hosted) работает поверх обычной операционной системы (примеры: VMware Workstation, Oracle VirtualBox) — проще в установке, но менее производительный, подходит для тестирования и разработки, но не для продакшена.
- Облачные платформы — это следующий уровень абстракции после виртуализации, где инфраструктура предоставляется как сервис и администратор может создавать, удалять и масштабировать ресурсы буквально за минуты (вместо недель ожидания закупки оборудования). Три главных игрока: AWS (Amazon Web Services) — самая большая и функциональная платформа с сотнями сервисов для любых задач; Microsoft Azure — сильна в интеграции с корпоративными продуктами Microsoft (Active Directory, Office 365, SQL Server); Google Cloud Platform — хороша для аналитики, машинного обучения и Kubernetes. На собеседовании важно не просто назвать эти платформы, но и показать, что вы понимаете основные сервисы: виртуальные машины (EC2 в AWS, Virtual Machines в Azure), объектное хранилище (S3, Azure Blob Storage), базы данных (RDS, Azure SQL), сети (VPC, Virtual Networks), и хотя бы базово ориентируетесь в консоли и инструментах управления.
- Контейнеризация — это более лёгкая альтернатива полноценной виртуализации, где приложение и все его зависимости упаковываются в контейнер, который можно запустить на любом сервере с контейнерной платформой. Docker — самая популярная технология контейнеризации, которая позволяет разработчикам создавать образы приложений, а администраторам — быстро разворачивать и масштабировать их. Контейнеры запускаются быстрее виртуальных машин (секунды против минут), потребляют меньше ресурсов (не нужна отдельная ОС для каждого приложения), но требуют понимания оркестрации (управления множеством контейнеров) — для этого используется Kubernetes, который автоматизирует развёртывание, масштабирование и управление контейнерными приложениями (правда, Kubernetes сам по себе довольно сложен и требует отдельного изучения, так что начинать лучше с базового Docker).
Мониторинг и управление инфраструктурой
Мониторинг инфраструктуры — это не просто «посмотреть, всё ли работает», а комплексная система сбора метрик, анализа производительности, обнаружения аномалий и оповещения о проблемах, желательно до того, как они станут критическими. Без мониторинга администратор работает вслепую и узнаёт о проблемах постфактум (обычно от пользователей или руководства, что не добавляет радости ни тем, ни другим).
Zabbix — это open-source система мониторинга, популярная в России и СНГ, которая умеет отслеживать практически всё: серверы, сети, приложения, базы данных. Настраивается через веб-интерфейс, поддерживает агенты (для детального сбора метрик с хостов) и SNMP (для мониторинга сетевого оборудования), позволяет создавать дашборды с графиками, настраивать триггеры (условия, при которых система отправляет алерты) и автоматические действия (например, перезапуск сервиса при падении).
- Плюсы: бесплатная, гибкая, много русскоязычной документации.
- Минусы: интерфейс может показаться перегруженным новичкам, требует времени на освоение.
Nagios — классическая система мониторинга, проверенная временем (существует с начала 2000-х), но довольно архаичная по современным меркам. Работает на основе плагинов, которые проверяют доступность и состояние сервисов, и отправляет уведомления при проблемах.
- Плюсы: стабильная, огромное количество готовых плагинов.
- Минусы: интерфейс выглядит как привет из прошлого, конфигурация через текстовые файлы может отпугнуть тех, кто привык к современным веб-интерфейсам.
Prometheus — современная система мониторинга, особенно популярная в мире DevOps и Kubernetes. Работает по принципу pull (сама забирает метрики с целевых систем), хранит данные в time-series БД (оптимизированной для временных рядов), интегрируется с Grafana (инструмент для красивой визуализации данных — графики, дашборды, которые можно показывать хоть на большом экране в офисе).
Prometheus отлично подходит для динамичных облачных сред, где серверы и контейнеры постоянно создаются и удаляются, но требует понимания специфики работы (например, язык запросов PromQL для выборки метрик).
Вопросы по безопасности и защите данных
Firewall (брандмауэр) — это первая линия обороны, которая фильтрует сетевой трафик на основе заданных правил: что пропускать, что блокировать, откуда и куда разрешены соединения. Файрволы бывают аппаратные (физические устройства на границе сети) и программные (встроенные в операционную систему или установленные как отдельное ПО). Правильно настроенный firewall блокирует все входящие соединения по умолчанию (принцип deny all) и разрешает только те, которые действительно необходимы для работы сервисов — например, порт 80 и 443 для веб-сервера, порт 22 для SSH, порт 3389 для RDP.
Важно регулярно аудировать правила файрвола, потому что они обрастают «костылями» и временными исключениями, которые забывают удалить, и в итоге безопасность превращается в дырявое решето (где каждое правило было добавлено «срочно для одного проекта», а потом все про него забыли).
IDS и IPS — это системы обнаружения (Intrusion Detection System) и предотвращения (Intrusion Prevention System) вторжений, которые анализируют сетевой трафик и поведение систем в поисках подозрительной активности. IDS работает в режиме мониторинга: обнаруживает атаки и отправляет алерты администратору, но сама не блокирует трафик (пассивная защита — полезно для анализа, но не останавливает атаку в реальном времени). IPS идёт дальше: не только обнаруживает, но и блокирует вредоносный трафик (активная защита — эффективнее, но есть риск ложных срабатываний, когда легитимный трафик принимается за атаку и блокируется).
Популярные решения: Snort, Suricata (open-source), коммерческие продукты от Palo Alto Networks, Cisco, Check Point. На собеседовании важно не просто назвать эти технологии, но и объяснить, как вы бы их настроили и что делать с бесконечным потоком алертов (потому что в реальности IDS генерирует столько уведомлений, что разбираться с каждым физически невозможно, и нужно уметь фильтровать шум от реальных угроз).
SSL/TLS — это криптографические протоколы, которые обеспечивают безопасную передачу данных по сети (шифрование трафика между клиентом и сервером, чтобы никто посередине не мог прочитать или изменить передаваемую информацию). SSL (Secure Sockets Layer) — устаревший протокол с известными уязвимостями, который уже не должен использоваться (хотя по привычке всё ещё говорят «SSL-сертификат»). TLS (Transport Layer Security) — современный преемник SSL, актуальная версия TLS 1.3.
Администратор должен уметь настраивать HTTPS на веб-серверах, устанавливать и обновлять сертификаты (можно использовать бесплатные от Let’s Encrypt или купить коммерческие от профильных центров), следить за сроками действия сертификатов (просроченный — это не только предупреждение в браузере, но и потенциальная потеря доверия пользователей) и отключать устаревшие версии протоколов и слабые шифры (чтобы не оставлять дыр для атак).
DDoS-атаки (Distributed Denial of Service) — это попытка перегрузить сервер или сеть огромным количеством запросов с множества устройств, чтобы легитимные пользователи не могли получить доступ к сервису. Защита от DDoS — это многоуровневая задача: на уровне сети используются rate limiting (ограничение числа запросов с одного IP), фильтрация трафика на основе геолокации или репутации адресов, использование CDN и специализированных сервисов защиты (Cloudflare, AWS Shield, Akamai), которые распределяют и фильтруют трафик до того, как он достигнет вашего сервера.
На уровне приложений важно оптимизировать код и кэширование, чтобы сервер мог обрабатывать больше запросов без падения. Полностью защититься от мощных DDoS-атак сложно (особенно если атакующие располагают огромными ботнетами), но грамотная настройка может значительно снизить ущерб.
Политика паролей — это набор правил, определяющих требования к паролям пользователей: минимальная длина (не менее 8-12 символов, а лучше больше), сложность (сочетание букв, цифр, спецсимволов), частота смены (хотя современные рекомендации NIST говорят, что регулярная принудительная смена паролей скорее вредит, чем помогает, потому что юзеры начинают использовать простые предсказуемые схемы вроде «Parol123», «Parol124»), блокировка учётной записи после нескольких неудачных попыток входа (защита от брутфорса), запрет на использование паролей из словарей и утёкших баз.
Сисадмин должен не только установить эти требования в групповых политиках или настройках системы, но и обучать юзеров основам цифровой гигиены (не использовать один пароль везде, не записывать их на стикерах, использовать менеджеры паролей) — хотя, если честно, это битва с ветряными мельницами, потому что пользователи всё равно будут использовать «123456» или «qwerty», если им дать хоть малейшую возможность.
Принцип наименьших привилегий (Principle of Least Privilege) — это фундаментальный принцип безопасности, согласно которому каждый пользователь, приложение или процесс должен иметь только те права доступа, которые необходимы для выполнения его задач, и ни на йоту больше.
На практике это означает: не давать всем подряд права администратора (даже если это упрощает работу), создавать отдельные учётные записи с ограниченными правами для повседневных задач, использовать sudo в Linux или UAC в Windows для временного повышения привилегий только когда это нужно, регулярно аудировать права доступа и отзывать лишние (особенно у уволенных сотрудников или тех, кто сменил должность).
Следование этому принципу снижает ущерб от взлома: если атакующий получает доступ к учётной записи с минимальными правами, он не сможет сделать многого; если же он взламывает аккаунт с правами администратора — всё, игра окончена.
Антивирусное ПО — это базовая защита от вредоносного ПО (вирусы, трояны, черви, шифровальщики, шпионские программы и прочие прелести современной киберпреступности). Антивирусы работают на основе сигнатур (базы данных известных угроз — быстро, но не защищает от новых вирусов), эвристического анализа (поиск подозрительного поведения — ловит больше, но даёт ложные срабатывания) и облачных технологий (проверка файлов на серверах антивирусной компании в реальном времени).
Важно не просто установить антивирус, но и регулярно обновлять базы, настраивать автоматические проверки, мониторить алерты и, что критично, обучать пользователей не открывать подозрительные вложения и не скачивать программы с сомнительных сайтов (хотя, опять же, это вечная борьба, потому что «письмо от директора с важным документом.exe» всегда найдётся желающий открыть).
VPN (Virtual Private Network) — это технология, которая создаёт защищённый туннель для передачи данных через незащищённые сети (например, интернет), шифруя трафик и скрывая реальный IP-адрес. VPN используется для безопасного удалённого доступа сотрудников к корпоративной сети (чтобы они могли работать из дома или командировки, не опасаясь перехвата данных), для соединения филиалов компании через интернет (site-to-site VPN вместо дорогих выделенных каналов), для обхода географических ограничений (хотя это скорее побочный эффект, чем основная цель в корпоративной среде).
Популярные протоколы VPN: OpenVPN (open-source, гибкий, надёжный), IPsec (стандартизированный, но сложный в настройке), WireGuard (современный, быстрый, с минималистичным кодом — набирает популярность).
На собеседовании могут спросить, как вы настраивали VPN, что за протоколы использовали, как решали проблемы с подключением (а они всегда есть — то файрвол блокирует, то NAT не пускает, то сертификаты не совпадают).
Soft skills и ситуационные вопросы
Техническая экспертиза — это, безусловно, основа профессии системного администратора, но если человек знает все команды Linux наизусть, умеет настраивать RAID с закрытыми глазами и может цитировать RFC по памяти, но при этом не способен нормально общаться с коллегами, теряется в стрессовых ситуациях или не умеет расставлять приоритеты — его ценность для компании резко падает (потому что администратор работает не в вакууме, а в живой организации, где нужно взаимодействовать с людьми, объяснять сложные вещи простым языком и быстро принимать решения в условиях хаоса).
Именно поэтому на собеседовании обязательно проверяют soft skills — коммуникативные навыки, стрессоустойчивость, умение работать в команде и способность сохранять холодную голову, когда всё вокруг горит.
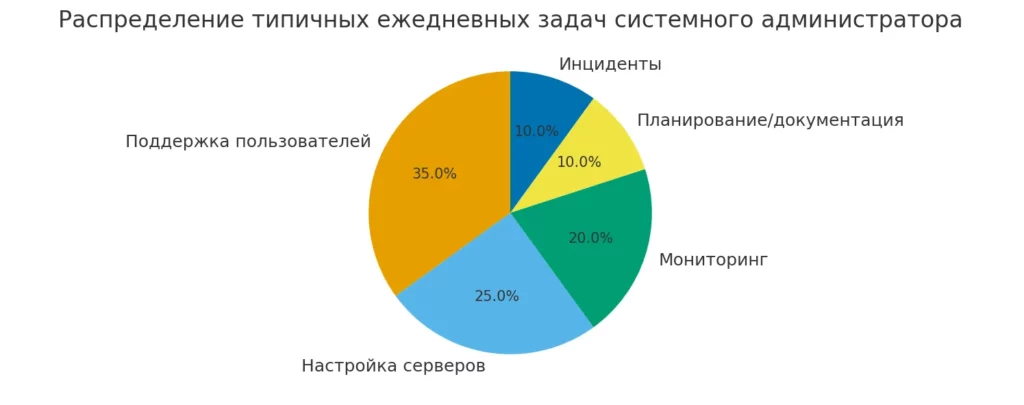
Диаграмма отражает примерное распределение ежедневных задач сисадмина: поддержка пользователей, настройка серверов, мониторинг, документация и инциденты. Такой визуальный обзор помогает кандидатам соотнести свои навыки с реальными требованиями профессии.
Взаимодействие с пользователями — это, пожалуй, один из самых недооценённых (и при этом критически важных) навыков системного администратора. Пользователи — это не враги (хотя иногда так кажется), а люди, которым нужна помощь, и от того, как администратор с ними общается, зависит атмосфера в коллективе и репутация IT-отдела.
Типичный вопрос на собеседовании:
«Пользователь жалуется, что у него не работает интернет. Опишите ваши действия.»
Правильный ответ включает не только техническую часть (проверить физическое подключение, пропинговать шлюз, посмотреть настройки сети, чекнуть DNS), но и коммуникативную: спокойно выяснить детали проблемы, не использовать технический жаргон (пользователю не нужно знать, что такое ARP-таблица или TTL), объяснить, что вы делаете и сколько примерно это займёт времени, сохранять доброжелательный тон даже если человек в десятый раз забыл пароль или случайно удалил важный файл (хотя внутри вы уже кипите). Хороший администратор не просто решает техническую проблему, но и оставляет пользователя с ощущением, что ему действительно помогли, а не отмахнулись.
Реакция на инциденты — это способность быстро и эффективно реагировать на критические ситуации: упал сервер, произошла утечка данных, сеть атакована вирусом, или БД почему-то решила, что жить больше не хочет.
На собеседовании часто задают ситуационные вопросы:
«В пятницу вечером, когда вы уже почти вышли из офиса, падает критически важный сервер. Что делаете?»
Правильный подход: оценить масштаб проблемы (насколько это критично, какое количество пользователей затронуто, есть ли обходные пути), собрать информацию (проверить логи, мониторинг, попытаться понять причину), принять решение (попробовать восстановить сервис на месте или переключиться на резервный, если он есть), информировать заинтересованные стороны (пользователей, руководство — главное не молчать, потому что неизвестность раздражает сильнее, чем сама проблема), задокументировать инцидент и провести post-mortem анализ (чтобы понять, что пошло не так и как предотвратить подобное в будущем).
Паника, хаотичные действия и попытки скрыть проблему — это худшие варианты поведения, и именно это проверяют на собеседовании.
Работа в команде — системный администратор редко работает в полной изоляции (разве что в совсем маленьких компаниях, где он один на всё), и умение координировать действия с коллегами, делиться знаниями, просить помощи, когда нужно, и предлагать её другим — это важная часть профессии.
Типичные вопросы:
«Приведите пример, когда вам пришлось работать в команде для решения сложной задачи» или «Как вы поступите, если ваш коллега сделал ошибку, которая привела к проблемам в инфраструктуре?».
Правильный ответ показывает способность к конструктивному взаимодействию: не искать виноватых, а сосредоточиться на решении проблемы, открыто обсуждать сложности, уважать чужое мнение и находить компромиссы. Токсичные администраторы, которые считают себя незаменимыми гениями и презирают всех вокруг, могут быть технически сильными, но они разрушают команду и создают атмосферу, в которой никто не хочет работать (а это ведёт к текучке кадров и снижению общей эффективности).
Приоритизация задач — это умение отличать важное от срочного, критическое от второстепенного и не распыляться на всё сразу. У системного администратора всегда больше задач, чем времени: тут нужно настроить новый сервер, там — обновить ПО, здесь — помочь пользователю с принтером, а ещё нужно планировать резервное копирование, мониторить безопасность и отвечать на письма.
На собеседовании могут спросить:
«У вас одновременно несколько задач: обновить критический патч безопасности на сервере, помочь директору с проблемой на ноутбуке и настроить нового сотрудника. Как вы расставите приоритеты?».
Правильный подход: оценить критичность каждой задачи (патч безопасности на production-сервере — высший приоритет, потому что уязвимость может быть использована злоумышленниками; проблема директора — вероятно, тоже важна, но нужно выяснить, насколько она блокирует его работу; настройка нового сотрудника может немного подождать), согласовать ожидания (объяснить директору, что вы займётесь его проблемой сразу после критического обновления, предложить временное решение, если возможно), делегировать задачи, если есть кому (например, попросить коллегу помочь с настройкой нового сотрудника).
Неумение расставлять приоритеты ведёт либо к выгоранию (когда пытаешься делать всё сразу и ничего не успеваешь), либо к конфликтам (когда кто-то считает, что его проблема важнее, а вы её игнорируете).
Обучение коллег — это способность делиться знаниями с теми, кто знает меньше (будь то стажёры, пользователи или даже руководство, которое не понимает, зачем тратить деньги на обновление инфраструктуры). Хороший администратор не держит знания при себе (синдром «незаменимого специалиста» — это путь в никуда, потому что если вы единственный, кто знает, как всё устроено, вас никогда не отпустят в отпуск, не повысят и не дадут заняться интересными проектами), а активно документирует процессы, пишет инструкции, проводит внутренние тренинги.
На собеседовании могут спросить:
«Как вы объясните техническую концепцию человеку без IT-бэкграунда?» или «Приведите пример, когда вы помогли коллеге освоить новую технологию».
Правильный ответ показывает умение адаптировать сложность объяснения под аудиторию, использовать аналогии и примеры из реальной жизни, терпеливо отвечать на вопросы и не демонстрировать снисходительность (потому что все когда-то были новичками, и нет ничего хуже, чем эксперт, который смотрит на вас как на идиота за то, что вы чего-то не знаете).
Как готовиться к собеседованию системному администратору
Подготовка включает не только повторение технических знаний, но и работу над резюме, портфолио, умением формулировать ответы и пониманием того, какие вопросы задавать самому работодателю — потому что собеседование это двусторонний процесс, и вы тоже оцениваете компанию, а не только компания вас.
Подготовка резюме и портфолио — это первое, что видит работодатель, и если резюме составлено небрежно, содержит ошибки или написано шаблонными фразами вроде «ответственный, коммуникабельный, стрессоустойчивый» без конкретики, шансы получить приглашение на интервью резко снижаются.
Резюме системного администратора должно содержать: краткую информацию о себе, список технических навыков, опыт работы с конкретными проектами и достижениями, используемые инструменты и технологии (перечислите конкретные продукты.
Портфолио для системного администратора — это необязательный, но полезный элемент, особенно если у вас есть открытые проекты на GitHub, сертификаты, статьи или доклады на профильных конференциях. Всё это демонстрирует не просто знания, а активную позицию и стремление развиваться.
Повторение ключевых команд и инструментов — даже если вы работаете системным администратором много лет, перед собеседованием стоит освежить в памяти базовые вещи, которые в повседневной работе уже выполняются на автомате и не требуют осознанного вспоминания.
Пройдитесь по основным командам Linux и Windows, повторите сетевые протоколы и их назначение, вспомните уровни RAID и их отличия, типы виртуализации и популярные гипервизоры, основы безопасности .
Если в вакансии упоминаются конкретные технологии, которыми вы давно не пользовались — найдите время освежить знания, хотя бы поверхностно. Лучше признаться на собеседовании, что работали с технологией год назад и сейчас нужно будет немного вспомнить, чем говорить «да, конечно, знаю», а потом не суметь ответить на базовый вопрос.
Как формулировать ответы: метод STAR — это структурированный подход к ответам на поведенческие и ситуационные вопросы, который помогает избежать сумбурных рассказов и даёт чёткую, логичную структуру. STAR расшифровывается как Situation (ситуация), Task (задача), Action (действие), Result (результат).
Когда вас просят привести пример из практики — скажем, «расскажите о сложной технической проблеме, которую вам удалось решить» — стройте ответ по этой схеме: сначала опишите ситуацию, затем задачу, потом действия, и, наконец, результат.
Такой ответ показывает не только технические навыки, но и способность структурировать мысли, анализировать ситуацию и извлекать уроки.
Примеры правильных ответов на частые вопросы — не нужно зубрить ответы слово в слово, но полезно заранее продумать, как вы будете отвечать на типичные вопросы.
- «Почему вы хотите работать у нас?» — не говорите общие фразы вроде «у вас интересная компания», а покажите, что вы изучили работодателя: упомяните конкретные проекты, технологии, которые они используют, ценности или культуру, которые вам близки.
- «Каковы ваши слабые стороны?» — не говорите «я перфекционист» (это банально и неправдоподобно), лучше назовите реальную область, над которой вы работаете: например, «Раньше мне было сложно делегировать задачи, я пытался всё делать сам, но я понял, что это ведёт к выгоранию, и сейчас активно работаю над тем, чтобы доверять коллегам и правильно распределять нагрузку».
- «Где вы видите себя через пять лет?» — покажите амбиции, но реалистичные: может быть, вы хотите вырасти до старшего администратора или руководителя IT-отдела, освоить облачные технологии или специализироваться в безопасности — главное, чтобы это соответствовало траектории развития в компании.
Чек-лист подготовки — перед собеседованием пройдитесь по этому списку, чтобы ничего не упустить:
- Обновите резюме, проверьте на ошибки, адаптируйте под конкретную вакансию.
- Изучите компанию: чем занимается, какие технологии использует, какие ценности декларирует
- Повторите базовые технические знания: команды, протоколы, инструменты.
- Подготовьте примеры из практики для ответов на поведенческие вопросы (используйте метод STAR)
- Подготовьте вопросы работодателю (об этом подробнее в следующем разделе).
- Проверьте техническую готовность, если собеседование онлайн: работает ли камера, микрофон, интернет стабилен.
- Выспитесь накануне и приходите (или подключайтесь) вовремя — банально, но пунктуальность и свежий вид имеют значение.
Чек-лист вопросов работодателю от кандидата
Собеседование — это не односторонний допрос, где только работодатель задаёт вопросы, а кандидат послушно отвечает и надеется, что его возьмут (хотя многие воспринимают процесс именно так, особенно если отчаянно ищут работу). На самом деле это диалог двух заинтересованных сторон, и у вас, как у кандидата, есть полное право — более того, обязанность перед самим собой — задавать вопросы, чтобы понять, подходит ли вам эта компания, эта команда, эти условия работы.
Структура команды и организация работы:
- Какова структура IT-отдела? Сколько человек в команде, какие роли распределены?
- Кому непосредственно подчиняется системный администратор? Есть ли технический директор или руководитель IT?
- Как организована поддержка пользователей? Есть ли система тикетов (helpdesk) или всё работает по принципу «пришёл, пожаловался, получил помощь»?
- Какие задачи будут приоритетными в первые месяцы работы?
- Есть ли процесс онбординга для новых сотрудников или придётся разбираться во всём самостоятельно?
Эти вопросы помогают понять, насколько структурирована работа IT-отдела — если в компании работают несколько администраторов, но никто толком не знает, кто за что отвечает, это тревожный сигнал; если поддержка пользователей идёт хаотично, без системы приоритизации, готовьтесь к постоянным отвлечениям и невозможности планировать свой день.
Оборудование, инфраструктура и технологии:
- Какое оборудование используется в компании? Серверы, сетевое оборудование, рабочие станции — насколько современное, как часто обновляется?
- Какие операционные системы администрируются? Windows, Linux, или гибридная среда?
- Используется ли виртуализация? Если да, какие платформы (VMware, Hyper-V, KVM)?
- Есть ли облачная инфраструктура? Какие сервисы используются (AWS, Azure, Google Cloud)?
- Какие системы мониторинга и управления применяются?
- Какова политика резервного копирования? Как часто делаются бэкапы, где хранятся, проверяется ли возможность восстановления?
Ответы на эти вопросы покажут, с чем вам предстоит работать — если компания экономит на инфраструктуре и до сих пор использует серверы десятилетней давности с операционными системами, для которых давно закончилась поддержка, работа превратится в постоянную борьбу с техническим долгом; если же компания инвестирует в современные технологии, автоматизацию и мониторинг, это признак зрелой IT-культуры.
Планы по автоматизации и развитию инфраструктуры:
- Есть ли планы по модернизации инфраструктуры? Какие проекты запланированы на ближайший год?
- Используется ли автоматизация рутинных задач? Приветствуется ли написание скриптов для оптимизации работы?
- Как компания относится к внедрению новых технологий? Есть ли бюджет на эксперименты и пилотные проекты?
- Поддерживается ли профессиональное развитие сотрудников? Оплачиваются ли курсы, сертификации, конференции?
Эти вопросы помогают понять, есть ли у вас возможность расти профессионально или вы застрянете в рутине поддержки устаревших систем без шанса освоить что-то новое — потому что если компания не инвестирует в развитие инфраструктуры и сотрудников, через пару лет ваши навыки устареют, и вы окажетесь менее конкурентоспособны на рынке труда.
Безопасность и политики:
- Какие меры безопасности применяются в компании? Есть ли политики информационной безопасности?
- Как организован доступ к критичным системам? Используется ли двухфакторная аутентификация?
- Проводятся ли регулярные аудиты безопасности? Были ли инциденты в прошлом, и как компания на них реагировала?
- Какова политика по отношению к удалённой работе и использованию личных устройств (BYOD)?
Вопросы безопасности показывают, насколько серьёзно компания относится к защите данных — если в организации нет базовых политик безопасности, вам, скорее всего, придётся всё это выстраивать с нуля (что может быть интересным вызовом, а может и головной болью, если руководство не понимает важности этого и не выделяет ресурсы).
Культура и атмосфера:
- Как выглядит типичный рабочий день системного администратора в вашей компании?
- Бывают ли ночные дежурства или вызовы в нерабочее время? Как это компенсируется?
- Насколько часто возникают авральные ситуации? Что обычно их вызывает?
- Почему открыта эта вакансия? Это новая позиция или замена предыдущего сотрудника (и если замена, почему он ушёл)?
Последний вопрос — один из самых важных, потому что если предыдущий администратор уволился из-за выгорания, токсичного руководства или невозможных условий работы, с высокой вероятностью вы столкнётесь с тем же самым (и если работодатель уклоняется от ответа или говорит что-то расплывчатое, это повод насторожиться).
Заключение
Системный администратор — это не просто человек, который умеет перезагружать серверы и сбрасывать пароли (хотя и это тоже входит в обязанности, причём с удручающей регулярностью). Это специалист широкого профиля, который совмещает в себе технические знания из множества областей — сетей, операционных систем, виртуализации, безопасности, облачных технологий — с умением быстро учиться, адаптироваться к изменениям и решать проблемы, которые возникают в самый неподходящий момент. Давайте подведем итоги:
- Собеседование для системного администратора требует уверенного понимания сетей, ОС и инфраструктурных технологий. Это помогает работодателю оценить глубину вашей технической подготовки.
- Поведенческие и ситуационные вопросы показывают, как специалист реагирует на инциденты и взаимодействует с пользователями. Это важно для оценки стрессоустойчивости и навыков общения.
- Практические примеры и структурированные ответы позволяют продемонстрировать реальный опыт. Это повышает доверие со стороны интервьюеров.
- Хорошая подготовка включает повторение базовых команд, разбор типичных кейсов и понимание ожиданий работодателя. Это увеличивает шансы успешно пройти все этапы собеседования.
- Грамотно составленные вопросы работодателю помогают понять условия работы и структуру команды. Это позволяет кандидату оценить, подходит ли ему компания
Если вы только начинаете осваивать профессию сисадмина, рекомендуем обратить внимание на подборку курсов по системному администрированию. В них есть и теоретическая база, и практическая часть, которые помогут подготовиться к реальным задачам и собеседованиям.
Рекомендуем посмотреть курсы по системному администрированию
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
DevOps-инженер
|
Eduson Academy
114 отзывов
|
Цена
119 900 ₽
|
От
9 992 ₽/мес
0% на 24 месяца
14 880 ₽/мес
|
Длительность
8 месяцев
|
Старт
18 мая
Пн, Ср, 19:00-22:00 по МСК
|
Подробнее |
|
Инженер по автоматизации
|
Нетология
46 отзывов
|
Цена
102 700 ₽
190 197 ₽
с промокодом kursy-online
|
От
3 169 ₽/мес
Без переплат на 2 года.
|
Длительность
13 месяцев
|
Старт
5 апреля
|
Подробнее |
|
Старт в DevOps: системное администрирование для начинающих
|
Skillbox
232 отзыва
|
Цена
87 035 ₽
174 070 ₽
Ещё -20% по промокоду
|
От
3 956 ₽/мес
Без переплат на 22 месяца.
|
Длительность
4 месяца
|
Старт
23 марта
|
Подробнее |
|
DevOps для эксплуатации и разработки
|
Яндекс Практикум
102 отзыва
|
Цена
160 000 ₽
|
От
23 000 ₽/мес
|
Длительность
6 месяцев
Можно взять академический отпуск
|
Старт
9 апреля
|
Подробнее |
|
Системный Администратор Linux. Базовый уровень
|
Otus
76 отзывов
|
Цена
93 600 ₽
104 000 ₽
|
От
9 360 ₽/мес
|
Длительность
5 месяцев
|
Старт
25 апреля
|
Подробнее |

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.

OTUS vs GeekBrains для backend: где строже к качеству кода и полезнее ревью
OTUS или GeekBrains — где обучение backend-разработке даёт более строгий подход к качеству кода? Разбираем, как устроено code review, какие инженерные практики используют школы и как проверить уровень ревью до оплаты курса.

Яндекс Практикум vs Contented: Figma/UI — где быстрее собрать 3 кейса и получить внятные правки
Выбираете между курсами UX/UI дизайна в Яндекс Практикуме и Contented? Разбираем, где быстрее собрать три сильных кейса в портфолио, как устроены ревью проектов и на что обратить внимание при выборе обучения.