Библиотека TensorFlow: пишем нейросеть и изучаем принципы машинного обучения
В современном мире технологий машинное обучение перестало быть экзотической областью для избранных — оно стало неотъемлемой частью повседневной жизни. От рекомендаций в YouTube до голосовых помощников в смартфонах, нейросети окружают нас повсюду. И если раньше создание собственной модели машинного обучения казалось недостижимой вершиной, требующей глубоких знаний математики и программирования, то сегодня ситуация кардинально изменилась.

TensorFlow — это именно тот инструмент, который делает машинное обучение доступным. Представьте библиотеку как универсальный конструктор: у вас есть готовые блоки (алгоритмы, модели, функции), которые можно собирать в различных комбинациях для решения конкретных задач. Хотите научить компьютер распознавать изображения кошек? Или создать систему прогнозирования цен на недвижимость? ТензорФлоу предоставляет все необходимые инструменты.
- Что такое TensorFlow
- Машинное обучение и место ТензорФлоу
- Установка и настройка
- Основные компоненты и принципы работы
- Как построить модель в TensorFlow (практика)
- Лучшие практики и советы
- Преимущества TensorFlow
- Недостатки
- Заключение
- Рекомендуем посмотреть курсы по Python
Что такое TensorFlow
ТензорФлоу представляет собой открытую библиотеку для машинного обучения, которая кардинально изменила подход к созданию и обучению нейронных сетей. Разработанная компанией Google как продолжение внутренней библиотеки DistBelief, она была выпущена в открытый доступ в 2015 году и с тех пор стала одним из самых популярных инструментов в области искусственного интеллекта.
Скриншот главной страницы официального сайта TensorFlow.
Определение и происхождение
Название «TensorFlow» складывается из двух ключевых понятий: «тензор» (многомерный массив данных) и «поток» (flow — движение данных через граф вычислений). По сути, библиотека организует обработку информации как поток тензоров через математические операции, что позволяет эффективно выполнять сложные вычисления, необходимые для машинного обучения.
Философия открытого исходного кода делает TensorFlow доступным для всех — от студентов, изучающих основы ML, до крупных корпораций, внедряющих AI-решения в производственные процессы. Активное сообщество разработчиков постоянно совершенствует библиотеку, добавляя новые возможности и оптимизации.
Поддерживаемые языки и платформы
Хотя Python остается основным языком для работы с ТензорФлоу (и это неспроста — его синтаксис идеально подходит для прототипирования ML-моделей), библиотека поддерживает множество других языков программирования. Доступны реализации для C++, Java, Go и Swift, что позволяет интегрировать модели в различные типы приложений.
Скриншот раздела «Install» на сайте TensorFlow с доступными вариантами для Python, C++, Java, JS и Lite. Скрин показывает, что библиотека кроссплатформенная, поддерживает множество языков и сред.
Особого внимания заслуживают специализированные версии: TensorFlow.js для выполнения моделей прямо в браузере, TensorFlow Lite для мобильных устройств и интернета вещей, а также TensorFlow Extended для корпоративного применения. Такая экосистема позволяет разработчикам создавать модели один раз и развертывать их практически на любой платформе.
Кто использует
Целевая аудитория библиотеки поразительно широка. Специалисты по машинному обучению ценят её за гибкость и мощные возможности настройки, исследователи — за возможность реализовывать самые смелые эксперименты, а начинающие разработчики — за обширную документацию и множество готовых примеров. Компании от стартапов до технологических гигантов используют TensorFlow для решения задач от персонализации контента до автономного вождения.
Машинное обучение и место ТензорФлоу
Чтобы понять революционность TensorFlow, необходимо осознать принципиальную разницу между традиционным программированием и машинным обучением. Эта разница определяет не только подход к решению задач, но и инструменты, которые мы используем.
Классическое программирование vs машинное обучение
В традиционном программировании мы создаем четкие алгоритмы: получаем входные данные, применяем заранее написанные правила и получаем предсказуемый результат. Представьте программу для вычисления площади квадрата — она всегда будет работать по формуле S = a², никогда не отклоняясь от этого правила и не пытаясь «изобрести» новый способ вычисления.
Машинное обучение переворачивает эту логику с ног на голову. Мы предоставляем компьютеру примеры входных данных и желаемых результатов, а затем просим: «Найди закономерность, которая связывает эти данные». Возвращаясь к аналогии с обувью и одеждой: вместо того чтобы программировать правила распознавания (наличие шнурков, форма, материал), мы показываем системе тысячи фотографий обуви и одежды с правильными подписями. Постепенно алгоритм учится выделять признаки, которые позволяют различать эти категории.
Какие задачи решает ML с помощью TensorFlow
ТензорФлоу демонстрирует свою универсальность в широком спектре применений:
Компьютерное зрение: распознавание объектов на изображениях, классификация медицинских снимков, анализ видеопотоков для систем безопасности. Алгоритмы могут не только определить, что на фотографии изображена собака, но и указать её породу.
Системы автономного вождения: современные системы автономного вождения требуют сложной обработки данных в реальном времени. TensorFlow применяется для анализа дорожной обстановки, распознавания объектов, прогнозирования движения и принятия решений на основе потоков информации от множества сенсоров.
Модели, построенные на базе библиотеки, способны учитывать десятки параметров одновременно: от дорожной разметки и пешеходов до сигналов светофора и траекторий других автомобилей. Такой подход делает возможной разработку технологий, которые обеспечивают безопасность и точность движения без участия водителя.
Обработка естественного языка: от простых чат-ботов до сложных систем машинного перевода. Современные языковые модели, построенные с помощью ТензорФлоу, способны генерировать тексты, неотличимые от написанных человеком.
Здравоохранение и диагностика. TensorFlow активно используется в медицинских исследованиях и клинической практике. С его помощью создаются модели для анализа медицинских изображений, распознавания патологий, оценки рисков заболеваний и разработки персонализированных методов лечения.
Библиотека помогает врачам автоматизировать рутинные процессы: от анализа рентгеновских снимков до обработки геномных данных. Такие решения ускоряют диагностику, повышают точность постановки диагноза и открывают новые возможности для применения искусственного интеллекта в медицине.
Прогнозирование и аналитика: предсказание рыночных трендов, анализ потребительского поведения, оптимизация логистических процессов. Финансовые институты используют такие модели для оценки кредитных рисков и обнаружения мошеннических операций.
Рекомендательные системы: персонализация контента в социальных сетях, подбор товаров в интернет-магазинах, формирование музыкальных плейлистов.
Ключевое преимущество ТензорФлоу заключается в том, что он предоставляет единую платформу для всех этих задач, позволяя разработчикам сосредоточиться на логике решения, а не на технических деталях реализации алгоритмов.
Установка и настройка
Первый шаг в освоении любой технологии — правильная настройка рабочей среды. TensorFlow предлагает несколько путей для начала работы, каждый из которых имеет свои преимущества в зависимости от ваших целей и технических возможностей.
Вариант 1: Google Colab — для новичков, быстрый старт
Google Colab представляет собой отличное стартовое решение для тех, кто хочет быстро начать экспериментировать с TensorFlow без локальной настройки
Процесс запуска максимально прост: переходим на colab.research.google.com, создаем новый notebook и можем сразу начинать писать код. Преимущества очевидны — не нужно беспокоиться о совместимости версий, зависимостях или мощности собственного компьютера. Google предоставляет доступ к GPU и даже TPU (специализированным процессорам для машинного обучения), что особенно ценно при обучении сложных моделей.
Вариант 2: локальная установка
Для серьезной работы рано или поздно потребуется локальная установка. Процесс начинается с обновления pip — пакетного менеджера Python:
pip install --upgrade pip pip install tensorflow
Важно убедиться в совместимости версий: ТензорФлоу требует Python 3.7–3.11, а для использования GPU необходимы дополнительные драйверы CUDA. Рекомендуется проверить официальную документацию для вашей операционной системы, поскольку требования могут изменяться с выходом новых версий.
Советы по настройке среды
Создание виртуального окружения — это не просто хорошая практика, а необходимость. Команда python -m venv tf_env создает изолированную среду, где можно устанавливать зависимости без риска конфликтов с другими проектами. Активация окружения (source tf_env/bin/activate на Unix или tf_env\Scripts\activate на Windows) обеспечивает чистую рабочую среду.
Дополнительно стоит установить Jupyter Notebook для интерактивной разработки и библиотеки для работы с данными: NumPy для математических операций, Matplotlib для визуализации, Pandas для обработки табличных данных. Эти инструменты образуют стандартный набор для data science и значительно упрощают процесс разработки и отладки моделей.
Основные компоненты и принципы работы
Понимание архитектуры TensorFlow — это ключ к эффективному использованию библиотеки. В отличие от традиционных программ, где код выполняется строка за строкой, ТензорФлоу организует вычисления особым образом, что позволяет достичь высокой производительности и гибкости.
Тензоры — многомерные массивы данных
Тензор в TensorFlow — это фундаментальная структура данных, представляющая собой многомерный массив. Если обычное число можно представить как тензор нулевого ранга, вектор — как тензор первого ранга, а матрицу — как тензор второго ранга, то изображение RGB будет тензором третьего ранга (высота × ширина × количество цветовых каналов).
Тензоры содержат данные одного типа (обычно float32 или int32) и имеют фиксированную форму. Эта структура позволяет эффективно выполнять векторизованные операции — обрабатывать множество данных одновременно, что критически важно для производительности алгоритмов машинного обучения.
Графы вычислений — организация операций
ТензорФлоу организует вычисления в виде направленного графа, где узлы представляют математические операции, а рёбра — тензоры, передаваемые между операциями. Такой подход позволяет оптимизировать выполнение: система может автоматически распараллеливать независимые операции, применять математические оптимизации и даже выполнять части графа на разных устройствах.
Современная версия TensorFlow использует «жадное выполнение» (eager execution), что делает разработку более интуитивной — операции выполняются немедленно, как в обычном Python-коде. Однако возможность компиляции в статический граф остается доступной для продакшн-развертывания, где критична максимальная производительность.
Сессии и переменные — выполнение и хранение состояния
Переменные в ТензорФлоу — это особый тип тензоров, значения которых сохраняются между выполнениями операций. Они используются для хранения обучаемых параметров модели — весов и смещений нейронной сети. В процессе обучения эти значения постепенно корректируются алгоритмами оптимизации для улучшения качества предсказаний.
В ранних версиях TensorFlow требовалось явно создавать сессии для выполнения вычислений, но современный подход значительно упростил этот процесс, скрывая технические детали управления сессиями от разработчика.
Аппаратное ускорение — CPU, GPU, TPU
Одно из ключевых преимуществ ТензорФлоу — возможность прозрачного использования различных вычислительных устройств. Библиотека автоматически определяет доступное оборудование и распределяет операции для максимальной эффективности. Графические процессоры (GPU) с их тысячами вычислительных ядер идеально подходят для параллельных операций машинного обучения, ускоряя обучение в десятки раз по сравнению с CPU.
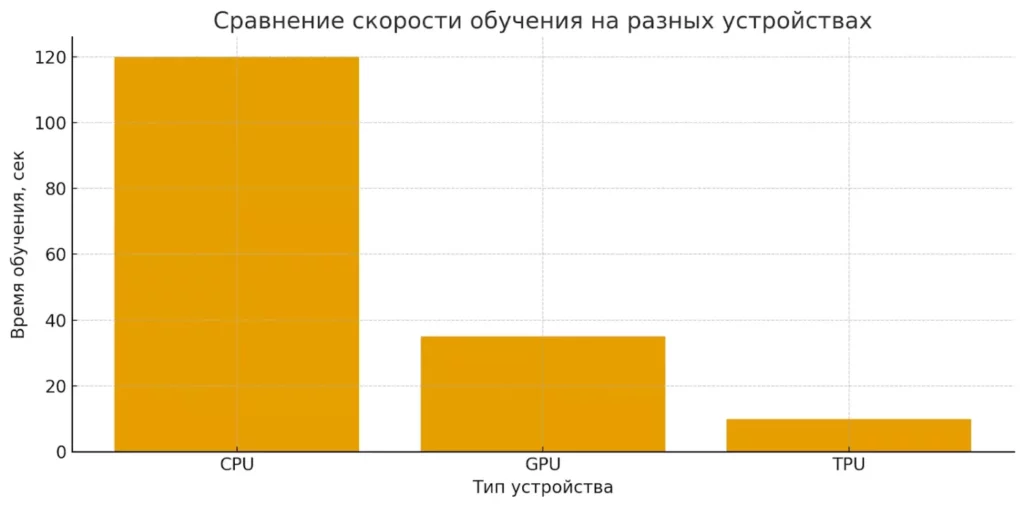
Диаграмма сравнивает скорость обучения модели на разных типах устройств. GPU и TPU значительно ускоряют обучение по сравнению с использованием только центрального процессора.
Тензорные процессоры (TPU), разработанные Google специально для машинного обучения, представляют следующий уровень оптимизации. Эти специализированные чипы оптимизированы именно для операций с тензорами и могут обеспечить еще большее ускорение при работе с крупными моделями.
Как построить модель в TensorFlow (практика)
Теория без практики остается лишь абстракцией. Давайте создадим простую, но работающую нейросеть, которая научится находить математическую закономерность между числами. Этот пример демонстрирует все ключевые этапы разработки модели машинного обучения.
Импорт библиотек
Начинаем с подключения необходимых инструментов:
import tensorflow as tf import numpy as np from tensorflow import keras
ТензорФлоу предоставляет основную функциональность, NumPy обеспечивает эффективную работу с массивами данных, а Keras — высокоуровневый API для построения нейронных сетей, интегрированный в TensorFlow.
Создание модели
Определяем архитектуру нашей нейросети:
model = tf.keras.Sequential([ keras.layers.Dense(units=1, input_shape=[1]) ])
Sequential указывает на последовательную архитектуру — данные проходят через слои один за другим. Dense создает полносвязный слой с одним нейроном (units=1), который принимает на вход одно число (input_shape=[1]). Эта простейшая архитектура способна изучать линейные зависимости вида y = ax + b.
Компиляция модели
Настраиваем процесс обучения:
model.compile(optimizer='sgd', loss='mean_squared_error')
Оптимизатор SGD (Stochastic Gradient Descent) определяет, как модель будет корректировать свои параметры для улучшения предсказаний. Функция потерь mean_squared_error измеряет разность между предсказанными и реальными значениями — чем меньше эта разность, тем лучше работает модель.
Подготовка данных
Создаем обучающий набор данных:
xs = np.array([-1.0, 0.0, 1.0, 2.0, 3.0, 4.0], dtype=float) ys = np.array([-4.0, 1.0, 6.0, 11.0, 16.0, 21.0], dtype=float)
Эти числа связаны формулой y = 5x + 1, но модель этого не знает. Её задача — самостоятельно выявить эту закономерность, анализируя примеры.
Обучение
Запускаем процесс обучения:
model.fit(xs, ys, epochs=500)
На каждой эпохе модель проходит весь набор данных, делает предсказания, сравнивает их с правильными ответами и корректирует свои параметры. 500 эпох обеспечивают достаточно времени для сходимости к оптимальному решению.
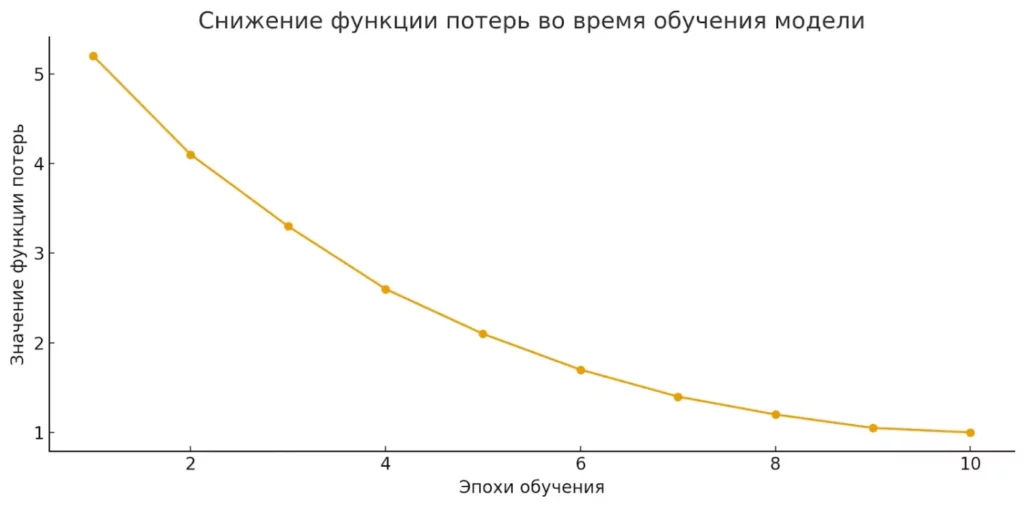
На графике показано, как уменьшается значение функции потерь при обучении модели. Чем ниже линия, тем точнее становится модель с каждой новой эпохой.
Предсказание
Тестируем обученную модель:
print(model.predict([10.0]))
Результат будет близок к 51 (5 × 10 + 1), но не точен — например, 50.987. Это фундаментальная особенность машинного обучения: модели находят приближения, а не точные математические формулы.
Почему результат может отличаться от идеала
Неточность обусловлена несколькими факторами: ограниченной точностью вычислений с плавающей запятой, случайной инициализацией параметров и стохастической природой алгоритмов оптимизации. Модель может найти формулу вида 4.999x + 0.998, которая практически идентична истинной зависимости, но формально отличается от неё. В реальных задачах такая точность более чем достаточна, а стремление к абсолютной точности может привести к переобучению.
Лучшие практики и советы
Успешная работа требует не только понимания технических аспектов, но и следования проверенным практикам, которые помогают избежать типичных ошибок и максимизировать эффективность разработки. Наш опыт показывает, что соблюдение этих принципов критически важно для создания надежных и производительных моделей.
Работа с данными — основа успеха
Качество данных напрямую определяет качество модели. Предобработка должна включать несколько ключевых этапов: очистку от выбросов и аномальных значений, обработку пропущенных данных, нормализацию численных признаков. Масштабирование входных данных к диапазону [0,1] или стандартизация со средним значением 0 и стандартным отклонением 1 значительно ускоряют сходимость алгоритмов обучения.
Разделение данных на обучающую, валидационную и тестовую выборки — это не формальность, а необходимость. Стандартное соотношение 70%/15%/15% позволяет объективно оценить производительность модели. Тестовая выборка должна оставаться «невидимой» до финального тестирования, иначе возникает риск переобучения на тестовых данных.
Структурирование кода
Модульная архитектура значительно упрощает разработку и отладку. Выделяйте отдельные функции для загрузки данных, предобработки, создания модели, обучения и оценки. Такой подход позволяет легко экспериментировать с различными архитектурами и параметрами, не переписывая весь код.
Использование конфигурационных файлов для хранения гиперпараметров (learning rate, batch size, количество эпох) делает эксперименты воспроизводимыми. Версионирование не только кода, но и данных с помощью инструментов типа DVC (Data Version Control) становится критически важным при работе в команде.
Визуализация и диагностика
TensorBoard — встроенный инструмент визуализации TensorFlow — должен стать вашим постоянным спутником. Отслеживание метрик обучения в реальном времени позволяет вовремя обнаружить проблемы: переобучение, недообучение, градиентные взрывы или затухания. Графики loss и accuracy на обучающей и валидационной выборках расскажут больше, чем сотни строк логов.
Визуализация архитектуры модели помогает понять поток данных и выявить потенциальные узкие места. Современные возможности TensorBoard включают профилирование производительности, что особенно полезно при оптимизации моделей для продакшена.
Настройка гиперпараметров
Систематический подход к настройке гиперпараметров экономит время и улучшает результаты. Начинайте с простых техник: grid search для небольшого количества параметров, random search для более обширного пространства поиска. Более продвинутые методы, такие как Bayesian optimization, могут значительно ускорить процесс поиска оптимальной конфигурации.
Регуляризация — ваш инструмент борьбы с переобучением. L1 и L2 регуляризация, dropout, batch normalization — каждый метод имеет свои преимущества в зависимости от типа задачи и архитектуры модели. Early stopping с мониторингом валидационной метрики предотвращает излишне долгое обучение и помогает найти оптимальную точку остановки.
Документирование всех экспериментов — не роскошь, а необходимость. Записывайте не только финальные результаты, но и промежуточные наблюдения, неудачные попытки и инсайты. Это знание становится бесценным при работе над следующими проектами.
Преимущества TensorFlow
ТензорФлоу завоевал лидирующие позиции в области машинного обучения не случайно — библиотека предлагает уникальное сочетание мощности и доступности, которое делает её привлекательной как для исследователей, так и для промышленных разработчиков.
Высокий уровень абстракции
Одно из главных достоинств — возможность сосредоточиться на логике решения, не углубляясь в технические детали реализации. Разработчику не нужно писать код для вычисления градиентов, распределения операций по устройствам или оптимизации памяти — библиотека берёт эти задачи на себя. API Keras, интегрированный в TensorFlow, позволяет создавать сложные нейронные сети буквально в несколько строк кода, скрывая математическую сложность за интуитивно понятными методами.
Интерактивная разработка
Современная архитектура ТензорФлоу поддерживает eager execution — режим, при котором операции выполняются немедленно, как в обычном Python-коде. Это кардинально упрощает отладку и экспериментирование: можно проверить результат любой операции, вывести промежуточные значения, динамически изменять архитектуру модели. Интеграция с Jupyter Notebook создаёт идеальную среду для исследовательской работы, где каждый шаг можно документировать и воспроизводить.
Кроссплатформенность
Экосистема ТензорФлоу охватывает практически все современные платформы. Модель, разработанная на рабочей станции с GPU, может быть легко адаптирована для мобильного приложения (TensorFlow Lite), веб-браузера (TensorFlow.js) или встроенных систем. Такая универсальность особенно ценна в эпоху edge computing, когда AI-решения должны работать не только в облаке, но и на устройствах пользователей.
Большое сообщество
Активное сообщество разработчиков — это не просто преимущество, а критически важный фактор успеха любой технологии. Вокруг ТензорФлоу сформировалась обширная экосистема: от официальной документации и туториалов до специализированных библиотек и готовых моделей в TensorFlow Hub. Stack Overflow содержит десятки тысяч вопросов и ответов по ТензорФлоу, а GitHub полон примеров и расширений. Эта поддержка сообщества значительно снижает порог входа и ускоряет решение возникающих проблем.
Регулярные обновления и долгосрочная поддержка от Google гарантируют, что инвестиции в изучение TensorFlow окупятся в долгосрочной перспективе. Библиотека активно развивается, интегрируя последние достижения в области машинного обучения и поддерживая новые типы моделей — от классических CNN до современных трансформеров.
Недостатки
Несмотря на множество преимуществ, TensorFlow не лишен недостатков, которые важно учитывать при выборе инструментов для конкретных проектов. Объективная оценка этих ограничений поможет принять взвешенное решение и избежать неприятных сюрпризов в процессе разработки.
Сложность в освоении
ТензорФлоу требует значительных временных инвестиций для полноценного освоения. Новичкам приходится одновременно изучать концепции машинного обучения, особенности архитектуры библиотеки и специфику её API. Переход от версии 1.x к 2.x изменил многие подходы, что создаёт дополнительную путаницу при изучении устаревших материалов.
Документация, хотя и обширная, иногда страдает от избыточной технической детализации, которая может отпугнуть начинающих разработчиков. Многослойность API (низкоуровневые операции, Keras, tf.function) создаёт множество способов решения одной задачи, что усложняет выбор оптимального подхода для конкретной ситуации.
Высокие требования к ресурсам
TensorFlow известен своим «аппетитом» к системным ресурсам, особенно при работе с GPU. Библиотека по умолчанию захватывает всю доступную видеопамять, что может создавать проблемы при работе с несколькими моделями одновременно или при использовании других GPU-зависимых приложений. Хотя это поведение можно настроить, требуется дополнительная конфигурация и понимание внутренней работы системы управления памятью.
Высокое потребление оперативной памяти также может стать ограничивающим фактором, особенно при работе с большими наборами данных. Оптимизация использования ресурсов часто требует глубокого понимания внутренних механизмов библиотеки и может значительно усложнить код.
Собственные стандарты Google
Будучи продуктом Google, TensorFlow иногда демонстрирует подходы, которые могут показаться неочевидными разработчикам, привыкшим к стандартным Python-практикам. Некоторые дизайнерские решения продиктованы внутренними потребностями Google и не всегда оптимальны для внешних пользователей.
Эволюция API между версиями иногда нарушает обратную совместимость, что требует переписывания существующего кода. Хотя команда разработки прилагает усилия для поддержания стабильности, кардинальные изменения между мажорными версиями остаются реальностью.
Важно понимать, что эти недостатки не делают ТензорФлоу плохим выбором — скорее, они подчёркивают важность правильной оценки требований проекта и готовности команды к инвестициям в обучение. Для многих задач преимущества TensorFlow значительно перевешивают его ограничения, особенно когда речь идёт о масштабных проектах или исследовательской работе.
Заключение
Наше путешествие через экосистему TensorFlow подходит к концу, и пришло время систематизировать полученные знания. ТензорФлоу представляет собой не просто библиотеку для машинного обучения — это комплексная платформа, которая демократизирует доступ к передовым технологиям искусственного интеллекта.
- TensorFlow — это мощная библиотека для создания и обучения нейросетей. Она облегчает работу с машинным обучением и позволяет строить модели любой сложности.
- Библиотека поддерживает разные языки и платформы. Python, C++, Java, JS, TensorFlow Lite и другие версии делают её кроссплатформенной.
- С помощью TensorFlow можно решать широкий спектр задач. От компьютерного зрения и NLP до автономного вождения, медицины и аналитики данных.
- TensorFlow сочетает простоту и гибкость. Подходит новичкам благодаря готовым примерам и удобному API, но при этом содержит инструменты для профессиональной разработки.
- Активное сообщество и документация делают обучение проще. Поддержка Google и регулярные обновления гарантируют актуальность и долгосрочную ценность библиотеки.
Рекомендуем обратить внимание на подборку курсов по Python, если вы только начинаете осваивать разработку. В них есть и теоретическая база, и практические задания, которые помогут быстрее освоить создание нейросетей и работу с библиотекой. Такой подход упростит обучение и ускорит первый результат.
Рекомендуем посмотреть курсы по Python
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Профессия Python-разработчик
|
Eduson Academy
114 отзывов
|
Цена
116 400 ₽
|
От
9 700 ₽/мес
|
Длительность
6 месяцев
|
Старт
25 марта
|
Подробнее |
|
Fullstack-разработчик на Python
|
Нетология
46 отзывов
|
Цена
161 200 ₽
325 635 ₽
с промокодом kursy-online
|
От
4 975 ₽/мес
|
Длительность
18 месяцев
|
Старт
26 марта
|
Подробнее |
|
Python-разработчик
|
Академия Синергия
38 отзывов
|
Цена
89 800 ₽
224 500 ₽
с промокодом KURSHUB
|
От
3 742 ₽/мес
0% на 24 месяца
|
Длительность
6 месяцев
|
Старт
31 марта
|
Подробнее |
|
Профессия Python-разработчик
|
Skillbox
232 отзыва
|
Цена
157 107 ₽
285 648 ₽
Ещё -27% по промокоду
|
От
4 621 ₽/мес
9 715 ₽/мес
|
Длительность
12 месяцев
|
Старт
23 марта
|
Подробнее |
|
Python-разработчик
|
Яндекс Практикум
102 отзыва
|
Цена
159 000 ₽
|
От
18 500 ₽/мес
|
Длительность
9 месяцев
Можно взять академический отпуск
|
Старт
26 марта
|
Подробнее |

OTUS vs ProductStar: куда идти технарю, чтобы стать продактом — честное сравнение подходов
OTUS или ProductStar — что выбрать, если вы хотите перейти в продакт-менеджмент? Разбираем разницу в обучении, практике и результате, чтобы вы не потратили время зря.

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.

OTUS vs GeekBrains для backend: где строже к качеству кода и полезнее ревью
OTUS или GeekBrains — где обучение backend-разработке даёт более строгий подход к качеству кода? Разбираем, как устроено code review, какие инженерные практики используют школы и как проверить уровень ревью до оплаты курса.