Что такое DataFrame и зачем он нужен?
Pandas DataFrame — это, пожалуй, самый полезный инструмент для работы с табличными данными в Python, который появился на свет, когда разработчики поняли, что манипулировать данными в формате Excel-таблиц с помощью обычных списков и словарей — то же самое, что пилить бревно маникюрными ножницами.

В сущности, DataFrame — это двумерная структура данных с метками для строк и столбцов. Если говорить более понятным языком — это таблица на стероидах, в которой каждый элемент имеет свои координаты, а манипулировать ею можно с удивительной легкостью и гибкостью.
- Как установить pandas и начать работу
- Создание DataFrame: основные способы
- Структура и компоненты DataFrame
- Доступ к данным и фильтрация
- Изменение и обновление данных
- Работа с отсутствующими значениями
- Группировка, агрегация и статистика
- Работа с временными рядами
- Визуализация данных с помощью pandas
- Полезные советы и лучшие практики
- Где дальше учиться работе с pandas
- Заключение
- Рекомендуем посмотреть курсы по Python
Что делает DataFrame особенным на фоне других структур данных? Во-первых, в отличие от обычных Python-списков или NumPy-массивов, он позволяет работать с разнородными типами данных в одной таблице — числа, строки, даты — всё может мирно сосуществовать в соседних столбцах. Во-вторых, DataFrame имеет встроенную поддержку работы с отсутствующими данными, что в реальных проектах случается чаще, чем хотелось бы (спойлер: почти всегда).Сравнение возможностей DataFrame и других популярных структур данных в Python. По пяти критериям — от работы с пропущенными значениями до статистических функций — DataFrame демонстрирует наилучшую универсальность.
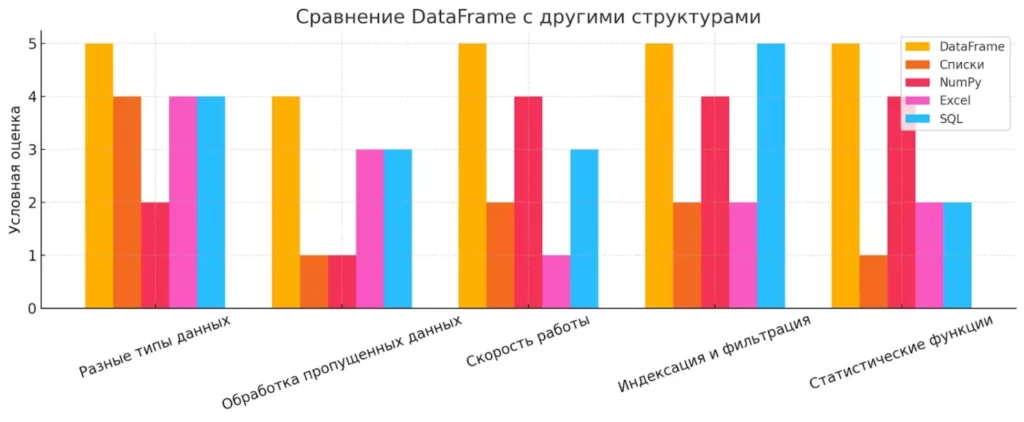
Сравнение возможностей DataFrame и других популярных структур данных в Python. По пяти критериям — от работы с пропущенными значениями до статистических функций — DataFrame демонстрирует наилучшую универсальность.
Сравнивая с Excel, DataFrame выигрывает в скорости обработки больших объемов данных и гибкости операций (попробуйте-ка фильтровать миллион строк в Excel — ваш компьютер превратится в нагревательный прибор). А в отличие от SQL-таблиц, для работы с DataFrame не нужно знать специального языка запросов — всё делается на Python, который вы, скорее всего, уже знаете или изучаете.
| Характеристика | DataFrame | Список Python | Массив NumPy | Excel | SQL |
|---|---|---|---|---|---|
| Разные типы данных | ✅ | ✅ | ❌ | ✅ | ✅ |
| Обработка пропущенных данных | ✅ | ❌ | ❌ | ⚠️ | ⚠️ |
| Скорость работы с большими данными | ✅ | ❌ | ✅ | ❌ | ⚠️ |
| Индексация и фильтрация | ✅ | ⚠️ | ✅ | ⚠️ | ✅ |
| Статистические функции | ✅ | ❌ | ✅ | ⚠️ | ⚠️ |
Как установить pandas и начать работу
Итак, вы решили погрузиться в мир pandas. Первый шаг — установка этой библиотеки, что, к счастью, не требует жертвоприношений или сложных ритуалов (хотя иногда при работе с зависимостями Python может казаться именно так).
Вот пошаговая инструкция для тех, кто хочет быстро начать:
- Установите pandas — откройте командную строку или терминал и введите:
pip install pandas
Если у вас уже есть Anaconda, то, скорее всего, pandas уже установлен — одно из немногих преимуществ этого монструозного дистрибутива, пожирающего гигабайты вашего жесткого диска.
- Импортируйте библиотеку — традиционно pandas импортируют с сокращением pd:
import pandas as pd
Это соглашение настолько устоялось, что использование другого сокращения считается дурным тоном — примерно как ношение носков с сандалиями.
- Создайте свой первый DataFrame — самый простой способ:
data = {'Имя': ['Иван', 'Мария', 'Алексей'],
'Возраст': [28, 34, 41],
'Зарплата': [70000, 85000, 110000]}
df = pd.DataFrame(data)
print(df)
- Убедитесь, что всё работает — вы должны увидеть что-то вроде:
Имя Возраст Зарплата 0 Иван 28 70000 1 Мария 34 85000 2 Алексей 41 110000
Вот и всё! Теперь у вас есть базовая установка pandas и первый DataFrame. Кажется просто, правда? Но не обольщайтесь — это только верхушка айсберга функциональности, которую предоставляет эта библиотека. В дальнейшем мы погрузимся глубже — держите спасательный жилет наготове.
Создание DataFrame: основные способы
Существует несколько способов создания DataFrame, и выбор между ними часто зависит от того, в каком формате у вас уже есть данные. Рассмотрим основные подходы — от примитивных до более продвинутых. И нет, мы не будем использовать телепатию, хотя иногда кажется, что именно это и нужно при работе с данными.Подпись под графиком:
Сравнение способов создания DataFrame: наиболее удобным и гибким способом считается чтение из файлов или словаря Python, в то время как NumPy и список списков требуют больше усилий при подготовке данных.
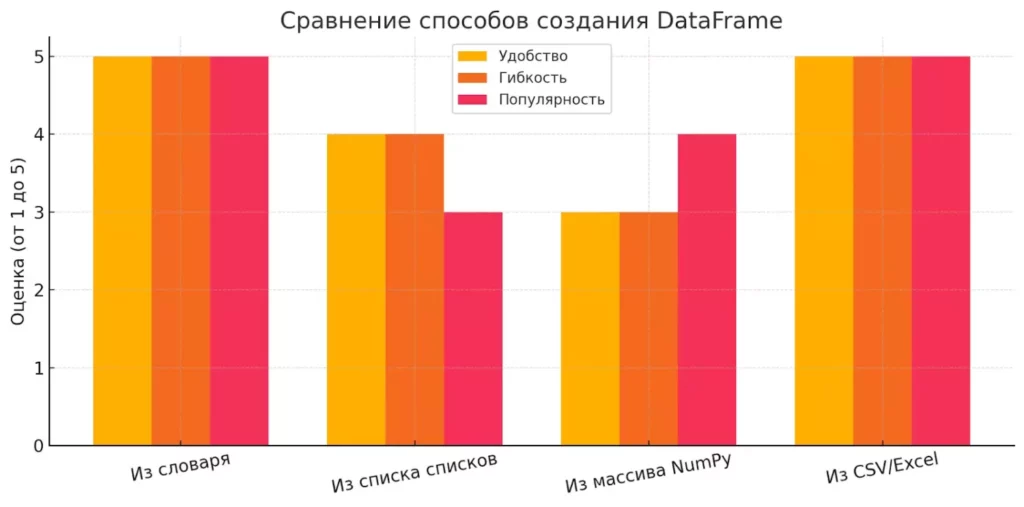
Сравнение способов создания DataFrame: наиболее удобным и гибким способом считается чтение из файлов или словаря Python, в то время как NumPy и список списков требуют больше усилий при подготовке данных.
Из словаря Python
Самый интуитивно понятный способ создания DataFrame — использование словаря, где ключи становятся названиями столбцов, а значения — данными в этих столбцах:
import pandas as pd
данные = {
'имя': ['Иван', 'Мария', 'Алексей', 'Ольга'],
'возраст': [32, 28, 45, 37],
'зарплата': [80000, 90000, 120000, 95000],
'отдел': ['IT', 'Маркетинг', 'Финансы', 'IT']
}
df = pd.DataFrame(данные)
print(df)
Результат будет выглядеть примерно так:
имя возраст зарплата отдел 0 Иван 32 80000 IT 1 Мария 28 90000 Маркетинг 2 Алексей 45 120000 Финансы 3 Ольга 37 95000 IT
Особенно удобно, что в качестве значений можно использовать любые последовательности — списки, кортежи или даже массивы NumPy (если вы из тех, кто предпочитает более вычислительно-эффективные структуры данных).
Из списка списков
Когда у вас данные уже структурированы в виде списка списков (например, строк таблицы), можно создать DataFrame, явно указав метки столбцов:
сотрудники = [ ['Иван', 32, 80000, 'IT'], ['Мария', 28, 90000, 'Маркетинг'], ['Алексей', 45, 120000, 'Финансы'], ['Ольга', 37, 95000, 'IT'] ] столбцы = ['имя', 'возраст', 'зарплата', 'отдел'] df = pd.DataFrame(сотрудники, columns=столбцы) print(df)
Обратите внимание, что если не указать columns, pandas создаст числовые названия столбцов (0, 1, 2, 3), что, согласитесь, выглядит не очень информативно и эстетично — примерно как обозначать людей номерами вместо имен.
Из массива NumPy
Если вы работаете с числовыми данными и используете NumPy (а кто в анализе данных этого не делает?), можно создать DataFrame из массива NumPy:
import numpy as np # Создаём массив с случайными данными данные_np = np.random.rand(4, 3) # 4 строки, 3 столбца случайных чисел print(данные_np) # Преобразуем в DataFrame df = pd.DataFrame(данные_np, columns=['Показатель A', 'Показатель B', 'Показатель C']) print(df)
Примечательно, что при использовании параметра copy=False DataFrame будет использовать тот же участок памяти, что и исходный массив NumPy. Это значит, что изменение исходного массива приведёт к изменению DataFrame — неочевидное поведение, которое может привести к интересным (читай: трудноотлаживаемым) багам.
Из внешнего файла (CSV, Excel)
В реальной жизни вы чаще всего будете получать данные из файлов. Pandas делает этот процесс до неприличия простым:
# Чтение из CSV
df_csv = pd.read_csv('сотрудники.csv')
# Чтение из Excel
df_excel = pd.read_excel('отчет.xlsx', sheet_name='Лист1')
Функции вроде read_csv и read_excel имеют множество параметров для тонкой настройки — от указания разделителя и кодировки до пропуска строк и обработки отсутствующих значений. Поверьте, когда вы столкнетесь с реальными данными (которые обычно грязнее, чем дворовая лужа в марте), эти параметры станут вашими лучшими друзьями.
Итак, теперь у вас есть несколько способов создания DataFrame. Выбирайте тот, который лучше всего подходит для ваших данных, и не бойтесь экспериментировать — pandas достаточно гибок, чтобы выдержать почти любые ваши манипуляции с данными.
Структура и компоненты DataFrame
Прежде чем начать жонглировать данными, давайте разберемся в анатомии DataFrame — как устроен этот зверь «под капотом». Понимание его структуры имеет примерно такое же значение, как знание анатомии для хирурга, только у нас, к счастью, пациент не истекает кровью, а лишь время от времени выдаёт ошибки, от которых кровь стынет у вас в жилах.
DataFrame имеет трехкомпонентную структуру:
- Данные (собственно, наш табличный контент).
- Индексы (метки строк).
- Столбцы (метки столбцов).
Рассмотрим каждый элемент:
Столбцы и строки
DataFrame концептуально похож на Excel-таблицу или таблицу в SQL — у него есть строки и столбцы. Но в отличие от Excel, где вы видите сетку, и всё, DataFrame имеет мета-информацию о каждом столбце и строке.
import pandas as pd
data = {
'имя': ['Василий', 'Мария', 'Алексей'],
'доход': [75000, 85000, 125000],
'бонус': [5000, 10000, 15000],
'отдел': ['IT', 'Маркетинг', 'Финансы']
}
df = pd.DataFrame(data)
print(df)
# Вывод информации о столбцах
print("\nИнформация о столбцах:")
print(df.columns)
# Вывод информации о строках
print("\nКоличество строк:")
print(len(df))
Индексы и метки
По умолчанию pandas назначает строкам целочисленные индексы от 0, как обычные списки Python. Но вы можете установить свои собственные индексы — например, ID сотрудников или даты — и это одна из самых мощных функций DataFrame:
# Установка пользовательского индекса
df = pd.DataFrame(data, index=['emp001', 'emp002', 'emp003'])
print(df)
# Доступ к строке по индексу
print("\nДанные о сотруднике emp002:")
print(df.loc['emp002'])
Индексы могут быть неуникальными (как ни странно), но это обычно создает больше проблем, чем решает — представьте себе почтальона, который пытается доставить письмо в дом, где несколько квартир имеют один и тот же номер.
Типы данных в столбцах
Каждый столбец в DataFrame имеет свой тип данных (dtype), и это гораздо важнее, чем может показаться на первый взгляд. От типа данных зависит не только объем занимаемой памяти, но и доступные операции, и даже производительность:
print("\nТипы данных по столбцам:")
print(df.dtypes)
# Преобразование типов данных
df['доход'] = df['доход'].astype('float')
df['бонус'] = df['бонус'].astype('int32') # Экономим память
print("\nОбновленные типы данных:")
print(df.dtypes)
Pandas поддерживает множество типов данных: от базовых числовых (int, float) и строковых (object) до специализированных — datetime64 для дат, timedelta для интервалов времени и категориальных — для перечислимых значений.
Забавно, но оптимизация типов данных может уменьшить размер DataFrame в памяти в разы. Например, если у вас целые числа, которые не превышают 127, вы можете использовать ‘int8’ вместо стандартного ‘int64’, что экономит 8 раз больше памяти. Это как заменить грузовик велосипедом для перевозки одного яблока.
Итак, понимание структуры DataFrame — первый шаг к эффективному манипулированию данными. В следующих разделах мы рассмотрим, как получать доступ, фильтровать и модифицировать данные, используя эту структуру.
Доступ к данным и фильтрация
Доступ к данным в DataFrame — это как поход в магазин: иногда вам нужен весь ассортимент, а иногда — только молоко и сыр, причём строго определенных марок. Pandas предлагает множество способов «доставать» нужные данные, от самых простых до настолько изощрённых, что они заставляют SQL-запросы нервно курить в сторонке.
Доступ по меткам (.loc) и по позициям (.iloc)
В pandas есть два основных аксессора для доступа к данным: .loc (для доступа по меткам) и .iloc (для доступа по позициям). Разницу между ними понять непросто, поэтому я обычно объясняю её так: .loc — это когда вы обращаетесь к человеку по имени, а .iloc — когда вы говорите «эй, третий слева в очереди!».
import pandas as pd
data = {
'имя': ['Василий', 'Мария', 'Алексей', 'Ольга'],
'возраст': [32, 28, 45, 37],
'зарплата': [80000, 90000, 120000, 95000]
}
df = pd.DataFrame(data, index=['id001', 'id002', 'id003', 'id004'])
print(df)
# Доступ по метке - .loc[строка, столбец]
print("\nИнформация о Марии (по метке):")
print(df.loc['id002', 'имя']) # Выведет 'Мария'
# Доступ к нескольким строкам и столбцам
print("\nЗарплаты и возраст сотрудников id001 и id003:")
print(df.loc[['id001', 'id003'], ['возраст', 'зарплата']])
# Доступ по позиции - .iloc[номер_строки, номер_столбца]
print("\nЗарплата третьего сотрудника (по позиции):")
print(df.iloc[2, 2]) # Выведет 120000 (зарплата Алексея)
# Срезы тоже работают
print("\nПервые два сотрудника, все столбцы:")
print(df.iloc[0:2, :])
Важно понимать, что .loc и .iloc работают по-разному с границами диапазонов. .loc включает как начальную, так и конечную метку в результат (включительно с обеих сторон), а .iloc работает как обычные срезы Python — исключает конечный индекс. Это тонкость, о которую спотыкаются даже опытные разработчики (читай: я сам часто забываю).
Фильтрация строк по условиям
Одна из самых мощных возможностей pandas — это фильтрация данных на основе условий, которая работает похоже на оператор WHERE в SQL, но гораздо интуитивнее:
# Выбор всех сотрудников старше 30 лет
сотрудники_старше_30 = df[df['возраст'] > 30]
print("\nСотрудники старше 30 лет:")
print(сотрудники_старше_30)
# Сложные условия (сотрудники старше 30 с зарплатой менее 100000)
опытные_но_бедные = df[(df['возраст'] > 30) & (df['зарплата'] < 100000)]
print("\nОпытные, но недооцененные сотрудники:")
print(опытные_но_бедные)
# Использование нескольких условий с оператором ИЛИ (|)
высокооплачиваемые_или_молодые = df[(df['зарплата'] > 100000) | (df['возраст'] < 30)]
print("\nВысокооплачиваемые или молодые сотрудники:")
print(высокооплачиваемые_или_молодые)
Обратите внимание на скобки вокруг каждого условия. Они необходимы из-за приоритета операторов в Python — без них вы получите не фильтр, а психологическую травму в виде загадочных ошибок.Зарплаты сотрудников в зависимости от возраста. Цвета помогают визуально выделить тех, кто старше 30 лет — именно их выбирает фильтр df[df[‘возраст’] > 30].
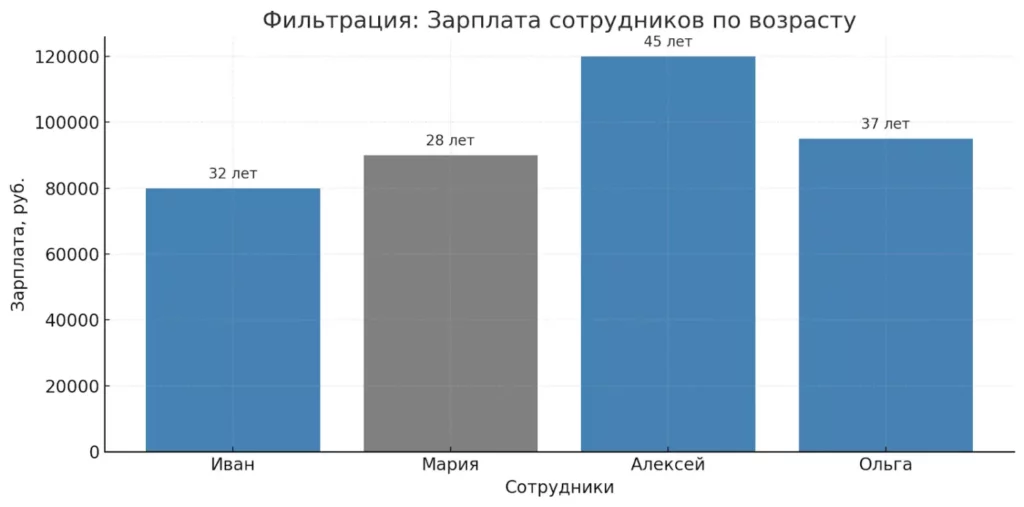
Зарплаты сотрудников в зависимости от возраста. Цвета помогают визуально выделить тех, кто старше 30 лет — именно их выбирает фильтр df[df[‘возраст’] > 30].
Выбор столбцов и подтаблиц
Извлечение определенных столбцов из DataFrame — операция, которую вы будете выполнять постоянно. К счастью, это просто:
# Выбор одного столбца (возвращает Series)
имена = df['имя']
print("\nСписок имен (Series):")
print(имена)
# Выбор нескольких столбцов (возвращает DataFrame)
персональные_данные = df[['имя', 'возраст']]
print("\nИмена и возраст (DataFrame):")
print(персональные_данные)
# Комбинирование выбора столбцов и фильтрации строк
молодые_имена = df.loc[df['возраст'] < 35, 'имя']
print("\nИмена молодых сотрудников:")
print(молодые_имена)
Особенно обратите внимание на разницу между df[‘имя’] и df[[‘имя’]] — первое возвращает Series (одномерную структуру), а второе — DataFrame с одним столбцом. Это как разница между сэндвичем и коробкой с одним сэндвичем — содержимое то же, но упаковка разная, что влияет на доступные операции.
Как видите, pandas предоставляет очень гибкие инструменты для получения именно тех данных, которые вам нужны. Научившись комбинировать различные методы доступа и фильтрации, вы сможете с легкостью извлекать нужную информацию даже из самых сложных и объемных наборов данных — что, в конечном счете, и является сутью анализа данных.
Изменение и обновление данных
Работа с данными — это не только их анализ, но и модификация. В реальной жизни редко бывает так, что данные изначально приходят в идеальном виде (спойлер: никогда). Обычно приходится добавлять новые записи, удалять ненужные строки, обновлять значения или переименовывать столбцы. И pandas даёт нам для этого арсенал инструментов, достойный хирурга, который оперирует таблицы.
Добавление и удаление строк и столбцов
Добавить новый столбец в DataFrame так же просто, как установить новое значение в словаре Python:
import pandas as pd
# Создаём исходный DataFrame
data = {
'имя': ['Василий', 'Мария', 'Алексей'],
'возраст': [32, 28, 45],
'зарплата': [80000, 90000, 120000]
}
df = pd.DataFrame(data)
print("Исходный DataFrame:")
print(df)
# Добавление нового столбца с фиксированным значением
df['бонус'] = 5000
print("\nDataFrame с бонусами:")
print(df)
# Добавление столбца, значения которого зависят от других столбцов
df['итого'] = df['зарплата'] + df['бонус']
print("\nDataFrame с итоговыми суммами:")
print(df)
# Удаление столбца
df = df.drop('бонус', axis=1) # axis=1 означает "удалить столбец", а не строку
print("\nDataFrame после удаления столбца 'бонус':")
print(df)
А вот добавление и удаление строк — процесс немного более сложный, потому что DataFrame — это, по сути, набор столбцов одинаковой длины:
# Добавление новой строки (метод append устаревает, предпочтительнее concat)
новый_сотрудник = pd.DataFrame({'имя': ['Екатерина'],
'возраст': [29],
'зарплата': [95000],
'итого': [95000]})
df = pd.concat([df, новый_сотрудник], ignore_index=True)
print("\nDataFrame с новым сотрудником:")
print(df)
# Удаление строки по индексу
df = df.drop(1) # Удаляем строку с индексом 1 (Мария)
print("\nDataFrame после увольнения Марии:")
print(df)
| До изменений | После добавления столбцов | После удаления строки |
|---|---|---|
| имя | возраст | зарплата |
| ————— | ————————— | ———————— |
| Василий | 32 | 80000 |
| Мария | 28 | 90000 |
| Алексей | 45 | 120000 |
Изменение значений
Изменять существующие значения в DataFrame можно различными способами — от прямого присваивания до использования методов вроде .replace() и .apply():
# Прямое изменение значения по метке
df.loc[0, 'зарплата'] = 85000
print("\nDataFrame после повышения зарплаты Василию:")
print(df)
# Массовая замена значений
df['возраст'] = df['возраст'] + 1 # Все сотрудники стали на год старше
print("\nDataFrame после дня рождения у всех сотрудников:")
print(df)
# Условное изменение значений
df.loc[df['возраст'] > 40, 'зарплата'] *= 1.1 # Повышение на 10% для сотрудников старше 40
df.loc[df['возраст'] > 40, 'итого'] = df.loc[df['возраст'] > 40, 'зарплата'] # Обновляем итого
print("\nDataFrame после повышения зарплаты старшим сотрудникам:")
print(df)
Переименование столбцов
Иногда данные приходят с неудобными или неинформативными названиями столбцов, и вам нужно их переименовать:
# Переименование столбцов
df = df.rename(columns={'имя': 'ФИО', 'зарплата': 'оклад', 'итого': 'к_выплате'})
print("\nDataFrame с переименованными столбцами:")
print(df)
# Сразу задать новые имена всем столбцам
df.columns = ['сотрудник', 'годы', 'базовая_оплата', 'полная_оплата']
print("\nDataFrame с полностью переименованными столбцами:")
print(df)
Важно понимать, что большинство операций в pandas не изменяют исходный DataFrame, а возвращают новый — если вы не указали параметр inplace=True (который доступен во многих методах) или не выполнили прямое присваивание результата. Это поведение отличается от многих других библиотек и может сначала сбивать с толку.
Кроме того, помните, что модификация данных часто является необратимой операцией, поэтому перед значительными изменениями имеет смысл создать копию DataFrame с помощью метода .copy().
Теперь, когда мы научились изменять данные, мы готовы рассмотреть одну из самых распространенных проблем в реальных датасетах — отсутствующие значения.
Работа с отсутствующими значениями
Отсутствующие данные — это как незваные гости на вечеринке: они всегда появляются, когда их меньше всего ждут, и создают массу проблем. В реальных наборах данных пропущенные значения встречаются повсеместно — то датчик сломался, то сотрудник забыл заполнить поле, то система сбоит при определённых условиях. Работа с такими значениями — неизбежная часть анализа данных.
Выявление NaN
Прежде чем что-то делать с пропущенными значениями, нужно их обнаружить. В pandas пропущенные значения обычно представлены как NaN (Not a Number), который импортируется из NumPy:
import pandas as pd
import numpy as np
# Создаём DataFrame с пропущенными значениями
data = {
'имя': ['Василий', 'Мария', 'Алексей', 'Ольга', 'Дмитрий'],
'возраст': [32, 28, np.nan, 37, 45],
'зарплата': [80000, np.nan, 120000, 95000, np.nan],
'отдел': ['IT', 'Маркетинг', np.nan, 'IT', 'Финансы']
}
df = pd.DataFrame(data)
print("DataFrame с пропущенными значениями:")
print(df)
# Проверка наличия NaN
print("\nЕсть ли NaN в DataFrame?")
print(df.isna()) # Возвращает DataFrame с True/False
# Подсчёт количества пропущенных значений по столбцам
print("\nКоличество пропущенных значений по столбцам:")
print(df.isna().sum())
# Строки, содержащие хотя бы одно пропущенное значение
print("\nСтроки с пропущенными значениями:")
print(df[df.isna().any(axis=1)])
Поверьте моему опыту: первым делом всегда проверяйте данные на наличие пропусков. Непроверенные NaN могут привести к неожиданным результатам и ошибкам — я однажды потратил весь день, отлаживая производственный код, только чтобы обнаружить, что проблема была в необработанном NaN, который тихо портил все расчёты.
Заполнение значений (fillna, ffill, bfill)
У pandas есть несколько стратегий заполнения пропущенных значений. Выбор конкретной стратегии зависит от характера ваших данных и целей анализа:
# Заполнение конкретным значением
df_filled = df.fillna(value={'возраст': 30, 'зарплата': 85000, 'отдел': 'Неизвестен'})
print("\nDataFrame с заполненными значениями:")
print(df_filled)
# Заполнение значением, вычисленным для столбца
df_mean = df.copy()
df_mean['возраст'] = df_mean['возраст'].fillna(df_mean['возраст'].mean())
df_mean['зарплата'] = df_mean['зарплата'].fillna(df_mean['зарплата'].mean())
print("\nDataFrame с заполнением средними значениями:")
print(df_mean)
# Заполнение предыдущим (ffill) или следующим (bfill) значением
print("\nЗаполнение методом forward fill (ffill):")
print(df.fillna(method='ffill'))
print("\nЗаполнение методом backward fill (bfill):")
print(df.fillna(method='bfill'))
Удаление пропущенных данных
Иногда проще избавиться от данных с пропусками, чем пытаться их заполнить. Это особенно верно, если у вас много данных и относительно мало пропусков:
# Удаление строк с пропущенными значениями
df_dropped = df.dropna()
print("\nDataFrame после удаления строк с NaN:")
print(df_dropped)
# Удаление только строк, где все значения пропущены
df_all_na = df.dropna(how='all')
print("\nDataFrame после удаления строк, где все значения NaN:")
print(df_all_na)
# Удаление столбцов с пропущенными значениями
df_dropped_cols = df.dropna(axis=1)
print("\nDataFrame после удаления столбцов с NaN:")
print(df_dropped_cols)
| Метод заполнения | Плюсы | Минусы |
|---|---|---|
| Конкретное значение | Просто и понятно | Не учитывает паттерны в данных |
| Среднее/медиана | Статистически обоснованно | Может исказить распределение |
| ffill/bfill | Сохраняет тренды во временных рядах | Неточно при резких изменениях |
| Удаление | Оставляет только достоверные данные | Потеря информации |
Выбор метода обработки отсутствующих данных может существенно повлиять на результаты вашего анализа. Например, если вы заполните отсутствующие значения зарплаты средней, это может создать ложное впечатление о «типичной» зарплате в компании. С другой стороны, если вы просто удалите все строки с пропущенными значениями, вы можете потерять ценную информацию о, скажем, новых сотрудниках, зарплата которых ещё не внесена в систему.
Одна из негласных истин в анализе данных: выбор метода обработки пропущенных значений часто оказывает большее влияние на результаты, чем выбор алгоритма машинного обучения. Поэтому относитесь к этому этапу с должным вниманием и всегда документируйте свои решения — ваше будущее «я» скажет вам спасибо.
Группировка, агрегация и статистика
Если собрать все данные в таблицу — это только половина дела. Настоящая магия начинается, когда вы группируете данные и извлекаете из них значимые статистические показатели. Это как разница между складом, заваленным коробками с деталями, и аккуратно организованным магазином, где все разложено по категориям и снабжено ценниками.
Группировка данных с помощью groupby
Метод groupby в pandas — это, пожалуй, самый мощный инструмент для анализа сгруппированных данных, эквивалент оператора GROUP BY в SQL, но гораздо более гибкий и удобный:
import pandas as pd
import numpy as np
# Создаём DataFrame для примера
data = {
'имя': ['Василий', 'Мария', 'Алексей', 'Ольга', 'Дмитрий', 'Ирина'],
'отдел': ['IT', 'Маркетинг', 'Финансы', 'IT', 'Финансы', 'Маркетинг'],
'стаж': [3, 5, 8, 2, 10, 4],
'зарплата': [85000, 95000, 120000, 90000, 130000, 92000]
}
df = pd.DataFrame(data)
print("Исходный DataFrame:")
print(df)
# Группировка по отделу и расчёт средней зарплаты
группы_по_отделу = df.groupby('отдел')
print("\nСредняя зарплата по отделам:")
print(группы_по_отделу['зарплата'].mean())
# Несколько агрегатных функций одновременно
print("\nСтатистика по отделам:")
print(группы_по_отделу['зарплата'].agg(['mean', 'min', 'max', 'count']))
# Разные агрегатные функции для разных столбцов
print("\nРазличные агрегации по столбцам:")
print(группы_по_отделу.agg({
'зарплата': ['mean', 'min', 'max'],
'стаж': ['mean', 'max']
}))
Особенно интересно, что groupby возвращает объект GroupBy, который можно использовать как генератор для перебора групп и каждая группа — это полноценный DataFrame:
# Перебор групп
print("\nОтдельный анализ для каждого отдела:")
for название_отдела, группа in группы_по_отделу:
print(f"\nОтдел: {название_отдела}, сотрудников: {len(группа)}")
print(f"Средняя зарплата: {группа['зарплата'].mean()}")
print(группа)
Комплексные агрегации с помощью agg и пользовательских функций
Метод agg позволяет применять как стандартные статистические функции, так и собственные:
# Пользовательская функция расчёта среднего без учёта крайних значений
def trimmed_mean(series):
return series.sort_values()[1:-1].mean()
# Применение пользовательской функции
print("\nСредняя зарплата без учёта крайних значений:")
print(df.groupby('отдел')['зарплата'].agg(trimmed_mean))
# Создание новых столбцов с помощью функции transform
df['средняя_по_отделу'] = df.groupby('отдел')['зарплата'].transform('mean')
df['отклонение'] = df['зарплата'] - df['средняя_по_отделу']
print("\nDataFrame с расчётом отклонения от средней по отделу:")
print(df)
Описательная статистика с помощью describe
Pandas предоставляет удивительно простой способ получить основные статистические показатели для всего DataFrame или его части с помощью метода describe:
# Общая статистика DataFrame
print("\nОбщая статистика по всем числовым столбцам:")
print(df.describe())
# Статистика по категориальным/строковым столбцам
print("\nСтатистика по категориальным столбцам:")
print(df.describe(include=['object']))
# Статистика для конкретного столбца
print("\nСтатистика по столбцу 'зарплата':")
print(df['зарплата'].describe())
| Отдел | Сотрудников | Средняя зарплата | Минимальная зарплата | Максимальная зарплата |
|---|---|---|---|---|
| IT | 2 | 87 500 | 85 000 | 90 000 |
| Маркетинг | 2 | 93 500 | 92 000 | 95 000 |
| Финансы | 2 | 125 000 | 120 000 | 130 000 |
Группировка и агрегация данных — это сердце любого серьёзного анализа. Они позволяют выявлять паттерны и тренды, которые не видны при поверхностном взгляде на сырые данные.
Например, простая группировка по отделам может показать, что в вашей компании наибольший разброс зарплат наблюдается в IT (где разница между junior и senior специалистами часто огромна), а маркетинг имеет самые стабильные показатели. Или можно обнаружить, что наиболее опытные сотрудники почему-то концентрируются в одном отделе — возможно, это говорит о проблемах с текучкой в других.
Владение методами группировки и агрегации данных делает разницу между дилетантом, просто показывающим таблицы, и настоящим аналитиком, способным извлечь из данных ценные инсайты. А если вы ещё научитесь эффективно визуализировать результаты такого анализа — вам цены не будет.
Работа с временными рядами
Если вы когда-нибудь работали с финансовыми данными, метеорологическими наблюдениями или любыми другими измерениями, меняющимися во времени, вы знаете, насколько важна грамотная обработка временных рядов. К счастью, pandas имеет мощный набор инструментов для работы со временем и датами, который превращает анализ временных рядов из кошмара в приятную прогулку — ну, почти.
Конвертация дат
Первое, с чем сталкиваются все при анализе временных данных — это необходимость преобразования строк в даты. Pandas делает это элегантнее, чем встроенный модуль datetime:
import pandas as pd
import numpy as np
from datetime import datetime
# Создаём DataFrame с датами в строковом формате
data = {
'дата': ['2023-01-15', '2023-02-20', '2023-03-10', '2023-04-05'],
'продажи': [120, 150, 135, 180],
'расходы': [80, 95, 88, 105]
}
df = pd.DataFrame(data)
print("Исходный DataFrame:")
print(df)
print(f"Тип данных в столбце 'дата': {df['дата'].dtype}")
# Преобразуем строки в даты
df['дата'] = pd.to_datetime(df['дата'])
print("\nDataFrame после конвертации дат:")
print(df)
print(f"Новый тип данных в столбце 'дата': {df['дата'].dtype}")
# Более сложный случай - разные форматы дат
разные_даты = pd.Series(['2023/05/12', '12-06-2023', 'March 15, 2023'])
print("\nКонвертация разных форматов дат:")
print(pd.to_datetime(разные_даты))
Функция to_datetime настолько умна, что может распознавать множество форматов автоматически. Но иногда она всё же требует подсказки:
# Даты с нестандартным форматом
нестандартные_даты = pd.Series(['15-01-23', '20-02-23'])
print("\nКонвертация нестандартных форматов:")
print(pd.to_datetime(нестандартные_даты, format='%d-%m-%y'))
Индексация по дате
Одна из главных фишек pandas — возможность использовать даты в качестве индекса, что позволяет естественным образом получать временные срезы данных:
# Устанавливаем дату в качестве индекса
df = df.set_index('дата')
print("\nDataFrame с датой в качестве индекса:")
print(df)
# Выбор данных за конкретный период
print("\nДанные за период с 1 февраля по 15 марта 2023:")
print(df.loc['2023-02-01':'2023-03-15'])
# Выбор данных за конкретный месяц
print("\nДанные за март 2023:")
print(df.loc['2023-03'])
Ресемплирование (resample)
Часто бывает, что данные приходят с неравными интервалами или нужно изменить частоту временного ряда. Например, преобразовать ежедневные данные в ежемесячные. Для этого служит метод resample:
# Создаём более подробный временной ряд
rng = pd.date_range('2023-01-01', periods=100, freq='D')
ts = pd.Series(np.random.randn(len(rng)), index=rng)
print("\nИсходный временной ряд (ежедневно):")
print(ts.head())
# Преобразуем в еженедельные данные
еженедельные = ts.resample('W').mean()
print("\nЕженедельный временной ряд (средние значения):")
print(еженедельные.head())
# Преобразуем в ежемесячные данные
ежемесячные = ts.resample('M').sum()
print("\nЕжемесячный временной ряд (суммы):")
print(ежемесячные)
Скользящие функции
Ещё одна важная операция при работе с временными рядами — вычисление скользящих (бегущих) статистик, таких как скользящее среднее, которое позволяет сгладить шум и выявить тренды:
# Скользящее среднее с окном 7 дней
скользящее_среднее = ts.rolling(window=7).mean()
print("\nСкользящее среднее с окном 7 дней:")
print(скользящее_среднее.head(10))
# Экспоненциально взвешенное скользящее среднее
ewma = ts.ewm(span=7).mean()
print("\nЭкспоненциально взвешенное скользящее среднее:")
print(ewma.head(10))
Работа с временными рядами кажется сложной отчасти потому, что она и есть сложная — от разных форматов дат до учёта часовых поясов и високосных лет. Однако pandas абстрагирует большую часть этой сложности, позволяя сосредоточиться на анализе данных, а не на борьбе с техническими деталями.
Важно помнить, что правильная подготовка временных данных — это основа качественного анализа. Преобразование строк в даты, установка подходящего индекса, выбор правильного метода ресемплирования — всё это может значительно повлиять на результаты ваших исследований.
И ещё один совет из личного опыта: всегда проверяйте наличие пропусков во временных рядах. Отсутствие данных за какой-то период может серьёзно исказить результаты анализа, особенно если вы применяете сложные методы вроде сезонной декомпозиции или авторегрессии.
Визуализация данных с помощью pandas
Если данные — это новая нефть, то визуализация — это НПЗ, превращающий сырую нефть в полезные продукты. Можно сколько угодно анализировать числа в таблицах, но человеческий мозг гораздо лучше воспринимает графики и диаграммы. К счастью, pandas имеет встроенные возможности для создания базовых (и не только) визуализаций.
Основные типы графиков
Метод .plot() — это входные ворота в мир визуализации с pandas. По сути, это обёртка над matplotlib, но с удобными интерфейсом и разумными настройками по умолчанию:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Создаём данные для визуализации
даты = pd.date_range('2023-01-01', periods=12, freq='M')
продажи = pd.Series(np.random.randint(100, 200, 12), index=даты)
расходы = pd.Series(np.random.randint(50, 150, 12), index=даты)
прибыль = продажи - расходы
df = pd.DataFrame({'Продажи': продажи, 'Расходы': расходы, 'Прибыль': прибыль})
print("Данные для визуализации:")
print(df.head())
# Линейный график
plt.figure(figsize=(12, 6))
df.plot(title='Финансовые показатели за 2023 год')
plt.ylabel('Значение, тыс. руб.')
plt.grid(True)
plt.tight_layout()
plt.savefig('line_plot.png')
plt.show()
# Столбчатая диаграмма
plt.figure(figsize=(12, 6))
df.plot.bar(title='Сравнение показателей по месяцам')
plt.ylabel('Значение, тыс. руб.')
plt.xticks(rotation=45)
plt.tight_layout()
plt.savefig('bar_plot.png')
plt.show()
# Гистограмма
plt.figure(figsize=(10, 5))
df['Прибыль'].plot.hist(bins=6, alpha=0.7, title='Распределение прибыли')
plt.xlabel('Прибыль, тыс. руб.')
plt.ylabel('Частота')
plt.tight_layout()
plt.savefig('histogram.png')
plt.show()
Настройки графиков
Базовые графики хороши для быстрого анализа, но профессиональная визуализация часто требует тонкой настройки:
# График с дополнительными настройками
plt.figure(figsize=(12, 6))
ax = df.plot(kind='line',
style=['-', '--', '-.'],
color=['blue', 'red', 'green'],
marker='o',
markersize=8,
alpha=0.7,
title='Подробный финансовый анализ')
# Добавляем линию тренда для прибыли
z = np.polyfit(range(len(даты)), df['Прибыль'], 1)
p = np.poly1d(z)
ax.plot(range(len(даты)), p(range(len(даты))), "r--", alpha=0.3,
label=f'Тренд: {z[0]:.2f}x + {z[1]:.2f}')
# Настройки осей и сетки
plt.grid(True, linestyle='--', alpha=0.7)
plt.xticks(range(len(даты)), [д.strftime('%b-%Y') for д in даты], rotation=45)
plt.ylabel('Значение, тыс. руб.')
plt.legend(title='Показатели')
# Аннотации
max_profit_idx = df['Прибыль'].idxmax()
max_profit = df['Прибыль'].max()
plt.annotate(f'Макс: {max_profit}',
xy=(df.index.get_loc(max_profit_idx), max_profit),
xytext=(df.index.get_loc(max_profit_idx)-1, max_profit+20),
arrowprops=dict(facecolor='black', shrink=0.05, width=1.5),
fontsize=10)
plt.tight_layout()
plt.savefig('advanced_plot.png', dpi=300)
plt.show()
Альтернативы – matplotlib, seaborn, plotly
Хотя встроенные возможности визуализации pandas достаточны для многих задач, серьёзные проекты часто требуют более мощных инструментов:
import seaborn as sns
# Использование seaborn для более красивых графиков
plt.figure(figsize=(12, 6))
sns.set_style("whitegrid")
sns.lineplot(data=df, markers=True, dashes=False)
plt.title('Визуализация через Seaborn')
plt.tight_layout()
plt.savefig('seaborn_plot.png')
plt.show()
# Тепловая карта корреляций между показателями
plt.figure(figsize=(8, 6))
sns.heatmap(df.corr(), annot=True, cmap='coolwarm', vmin=-1, vmax=1)
plt.title('Корреляционная матрица')
plt.tight_layout()
plt.savefig('correlation_heatmap.png')
plt.show()
| Библиотека | Преимущества | Ограничения |
|---|---|---|
| pandas.plot | Простота, интеграция с DataFrame | Базовые возможности, ограниченные настройки |
| matplotlib | Полный контроль, гибкость | Сложный синтаксис, много кода |
| seaborn | Красивый дизайн, статистические графики | Не подходит для интерактивных графиков |
| plotly | Интерактивность, веб-интеграция | Сложнее в освоении, тяжелее для документов |
Выбор инструмента визуализации — это всегда компромисс между скоростью создания, красотой результата и уровнем контроля. Для быстрого исследовательского анализа достаточно встроенных методов pandas, для презентаций лучше использовать seaborn или plotly, а когда нужен полный контроль — matplotlib остаётся незаменимым.
Впрочем, независимо от выбранного инструмента, помните главное правило визуализации: графики должны делать данные понятнее, а не запутывать ещё больше. Избегайте 3D-пирогов, перегруженных легенд и слишком ярких цветов — лучше простой и понятный график, чем эффектный, но непонятный.
И последний совет: всегда добавляйте подписи к осям, заголовок и, если необходимо, аннотации к важным точкам на графике. Хороший график должен быть самодостаточным и понятным даже без сопроводительного текста.
Полезные советы и лучшие практики
После нескольких лет работы с pandas (и множества седых волос, заработанных методом проб и ошибок) я могу с уверенностью сказать: эффективное использование этой библиотеки — это искусство, которому нужно учиться. Вот набор советов, которые помогут вам избежать распространенных ловушек и написать код, который не будет вызывать приступы раздражения ни у вас, ни у ваших коллег через полгода.
Как писать читаемый код
Читаемость кода — это не роскошь, а необходимость, особенно когда речь идет о манипуляциях с данными:
# Плохо: непонятный код с цепочкой операций
result = df[(df['col1'] > 10) & (df['col2'] < 100)].groupby('col3').agg({'col4': 'mean', 'col5': 'sum'}).reset_index().sort_values('col4', ascending=False)
# Хорошо: разбитый на части с объяснениями
# Фильтруем данные по условиям
filtered_df = df[(df['col1'] > 10) & (df['col2'] < 100)]
# Группируем и агрегируем
grouped = filtered_df.groupby('col3').agg({
'col4': 'mean', # Среднее значение
'col5': 'sum' # Сумма значений
})
# Сбрасываем индекс для удобства дальнейшей работы
result = grouped.reset_index()
# Сортируем по среднему значению col4
sorted_result = result.sort_values('col4', ascending=False)
Использование промежуточных переменных с говорящими названиями и комментарии для объяснения сложных операций делают код гораздо понятнее. Кроме того, такой подход облегчает отладку при возникновении проблем.
В каких случаях лучше использовать DataFrame
DataFrame не всегда является оптимальным выбором:
- Используйте DataFrame, когда работаете с табличными данными, особенно если нужны операции группировки, фильтрации, или данные разнородны по типам.
- Используйте массивы NumPy, если все данные одного типа и вам нужна максимальная производительность для матричных операций.
- Используйте списки Python, когда данных мало и структура простая — нет смысла загружать тяжелую артиллерию для стрельбы по воробьям.
- Используйте словари Python, когда вам нужно просто хранить пары «ключ-значение» без сложных манипуляций.
Советы по производительности
Производительность — один из тех аспектов, которые часто становятся критичными, когда ваши данные растут от нескольких мегабайт до гигабайтов:
# Медленно: итерации по строкам
for index, row in df.iterrows():
df.at[index, 'new_col'] = row['col1'] * row['col2']
# Быстро: векторизованные операции
df['new_col'] = df['col1'] * df['col2']
# Медленно: постоянное конкатенирование DataFrame
for i in range(100):
df = pd.concat([df, pd.DataFrame({'A': [i], 'B': [i*2]})])
# Быстро: создание списка и однократная конкатенация
frames = [df]
for i in range(100):
frames.append(pd.DataFrame({'A': [i], 'B': [i*2]}))
df = pd.concat(frames)
Типичные ошибки
В моей практике есть несколько ошибок, которые совершают почти все новички (и даже опытные разработчики время от времени):
- Забывать о копии и представлении
# Это не создает копию! subset = df[df['column'] > 10] subset['new_col'] = 1 # SettingWithCopyWarning! # Правильно: subset = df[df['column'] > 10].copy() subset['new_col'] = 1
- Игнорировать типы данных
# Проблема: числа хранятся как строки df['number'] = ['1', '2', '3'] result = df['number'].sum() # Результат: '123' (конкатенация строк) # Решение: df['number'] = pd.to_numeric(df['number']) result = df['number'].sum() # Результат: 6
- Неэффективная обработка пропусков
# Плохо: потеря данных df = df.dropna() # Лучше: разберитесь, почему данные отсутствуют # и примените соответствующую стратегию заполнения
- Использование неиндексированного DataFrame в запросах к большим данным
# Создаем индекс для быстрого поиска
df.set_index('key_column', inplace=True)
# Теперь поиск будет гораздо быстрее
result = df.loc['search_value']
Избегая этих ошибок и следуя лучшим практикам, вы сможете писать код, который не только работает правильно, но и делает это эффективно. А в мире данных, где объемы постоянно растут, эффективность — это не просто хорошая идея, это необходимость. Кроме того, написание чистого, понятного кода сэкономит вам массу времени при отладке и поддержке — поверьте, ваше будущее «я» будет очень благодарно за это.
Где дальше учиться работе с pandas
После того, как вы освоили основы pandas, закономерно возникает вопрос: «А что дальше?». Возможно, вам нужно углубить знания или изучить продвинутые техники для работы с большими и сложными наборами данных. Ниже я собрал ресурсы, которые помогли мне самому (и множеству моих коллег) преодолеть барьер от «я умею импортировать CSV» до «я могу переформатировать данные отдела аналитики за пять минут на коленке».
Официальная документация
Официальная документация pandas — это золотая жила информации. Да, она может показаться немного технической и сухой, но трудно найти более полный и надежный источник:
- Официальная документация pandas — подробное описание всех функций и методов.
- Примеры из документации — множество примеров для всех функций.
Курсы и книги
Когда документация не дает полной картины или вам нужна более структурированная подача:
- “Pandas в действии” Борис Пасхавер.
- “Изучаем pandas. Высокопроизводительная обработка и анализ данных в Python” Артем Груздев, Майкл Хейдт.
- Подборка курсов по Python-разработке от различных школ.
Проекты и практика
Наконец, лучший способ по-настоящему освоить pandas — это использовать его в реальных проектах:
- Найдите открытые данные на порталах вроде data.gov или kaggle.com.
- Поставьте себе конкретную задачу анализа (например, изучить тренды, найти корреляции).
- Попробуйте воспроизвести анализ из научной статьи или журналистского расследования.
Помните: pandas — это инструмент, который становится действительно мощным только когда вы применяете его к реальным задачам. Теория важна, но именно на практике вы столкнетесь с нюансами и трудностями, преодоление которых сделает вас настоящим экспертом.
- Python на Stack Overflow на русском
→ Самое активное русскоязычное сообщество с метками pandas, python, numpy и т.д.
→ Много дубликатов вопросов с английского SO, но есть уникальные кейсы из российской/СНГ-практики. - Пикабу / Хабр Q&A / VC в разделе Разработка
Заключение
Работа с pandas — это не просто навык, а фундамент для любой деятельности, связанной с анализом данных. Освоив базу, важно не останавливаться: настоящая экспертиза приходит с практикой, ошибками, проектами и, конечно, помощью сообщества.
Вот что особенно важно запомнить:
- Часто возвращайтесь к документации — она самая полная и регулярно обновляется.
- Читайте проверенные книги на русском: «Pandas в действии», «Изучаем pandas» и другие переводы дадут глубину.
- Проходите курсы — они помогут закрепить знания на практике.
- Делайте проекты — берите открытые данные, анализируйте, визуализируйте, пробуйте всё вручную.
- Общайтесь с сообществом — на vc, пикабу или на Habr Q&A всегда можно найти помощь и обменяться опытом.
- Не бойтесь экспериментировать — пробуйте нестандартные подходы и задачи, именно это делает pandas таким гибким инструментом.
Хочется больше практики? Посмотрите курсы по Python, чтобы научиться применять DataFrame в реальных задачах.
Рекомендуем посмотреть курсы по Python
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Профессия Python-разработчик
|
Eduson Academy
114 отзывов
|
Цена
116 400 ₽
|
От
9 700 ₽/мес
|
Длительность
6 месяцев
|
Старт
25 марта
|
Подробнее |
|
Fullstack-разработчик на Python
|
Нетология
46 отзывов
|
Цена
161 200 ₽
325 635 ₽
с промокодом kursy-online
|
От
4 975 ₽/мес
|
Длительность
18 месяцев
|
Старт
26 марта
|
Подробнее |
|
Python-разработчик
|
Академия Синергия
38 отзывов
|
Цена
89 800 ₽
224 500 ₽
с промокодом KURSHUB
|
От
3 742 ₽/мес
0% на 24 месяца
|
Длительность
6 месяцев
|
Старт
31 марта
|
Подробнее |
|
Профессия Python-разработчик
|
Skillbox
232 отзыва
|
Цена
157 107 ₽
285 648 ₽
Ещё -27% по промокоду
|
От
4 621 ₽/мес
9 715 ₽/мес
|
Длительность
12 месяцев
|
Старт
23 марта
|
Подробнее |
|
Python-разработчик
|
Яндекс Практикум
102 отзыва
|
Цена
159 000 ₽
|
От
18 500 ₽/мес
|
Длительность
9 месяцев
Можно взять академический отпуск
|
Старт
26 марта
|
Подробнее |

OTUS vs SkillFactory: автотесты — где больше «пишем код», а где больше «разбираем подходы»
Если вы ищете курс по автоматизации тестирования, который сочетает теорию и практику, вы попали по адресу. В этой статье мы сравниваем два популярных курса: OTUS и SkillFactory, чтобы помочь вам определиться с выбором. Какой из них поможет вам быстрее освоить важнейшие навыки тестирования? Читайте и узнайте все подробности!

OTUS vs ProductStar: куда идти технарю, чтобы стать продактом — честное сравнение подходов
OTUS или ProductStar — что выбрать, если вы хотите перейти в продакт-менеджмент? Разбираем разницу в обучении, практике и результате, чтобы вы не потратили время зря.

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.