Что такое строки в Python
Строки в Python — это не просто набор символов, это целая экосистема возможностей для хранения и обработки текста. В мире Python строка (тип str) представляет собой неизменяемую последовательность символов Unicode, заключенных в кавычки — такой себе текстовый конструктор LEGO, где каждый кубик — отдельный символ. В этом курсе рассмотрим, что такое строки в питоне, как они создаются и как не допустить ошибок при работе с ними.
В отличие от некоторых языков программирования (привет, C!), в Python не нужно заморачиваться с массивами символов и нуль-терминаторами. Здесь строки — это вполне себе первоклассные граждане языка, с которыми можно делать практически всё, что угодно: нарезать, склеивать, искать, заменять и даже (не поверите) умножать.
- Как создаются
- Тип данных str
- Базовые операции с элементами
- Встроенные функции для работы с записями
- Основные методы элементов в Python
- Форматирование
- Распространённые ошибки
- Практические примеры и задачи
- Заключение
- Рекомендуем посмотреть курсы по Python
Как создаются
Python предлагает нам три способа определения записей — на любой вкус, цвет и настроение:
# Одинарные кавычки -- классика жанра name = 'Python' # Двойные кавычки -- для тех, кто хочет разнообразия или пришел из C#/Java quote = "Жизнь - это то, что случается, пока вы строите планы" # Тройные кавычки -- для многострочных любителей поэзии poem = '''Я памятник себе воздвиг нерукотворный, К нему не зарастет народная тропа, Вознесся выше он главою непокорной Александрийского столпа.'''
А что делать, если в элементе нужны сами кавычки? Тут на помощь приходят либо разные типы кавычек, либо экранирование:
# Кавычки внутри кавычек he_said = 'Он сказал: "Привет!"' # Двойные внутри одинарных she_said = "Она ответила: 'Здравствуй!'" # Одинарные внутри двойных # Экранирование -- когда хочется усложнить себе жизнь escaped = 'Он сказал: \"Привет!\"' # Выглядит не очень, но работает
Особый случай — когда нужно использовать специальные символы, которых нет на клавиатуре. Тут в ход идут escape-последовательности:
new_line = "Первая строка\nВторая строка" # \n -- перенос строки tab = "Имя:\tPython" # \t -- табуляция backslash = "Обратный слеш: \\" # \\ -- сам обратный слеш
Тип данных str
Чтобы проверить, что переменная действительно является строкой, в Python есть функция type() — такой маленький детектив, который раскрывает истинную сущность переменной:
x = "Python" print(type(x)) # Выведет: <class 'str'>
Одна из ключевых особенностей записей в Python — их неизменяемость. Это как если бы вы писали текст не карандашом, а высекали его на камне — один раз написали, и всё, изменить нельзя. Можно только создать новую строку на основе старой:
s = "Python" # s[0] = "J" # Этот код вызовет ошибку! # TypeError: 'str' object does not support item assignment # Правильный способ: s = "J" + s[1:] # Создаем новую строку "Jython"
Особенности записей в Python:
- Неизменяемость — нельзя изменить отдельный символ.
- Индексируемость — можно обращаться к отдельным символам по индексу.
- Итерируемость — можно перебирать символы в цикле.
- Поддержка Unicode — работают со всеми языками и символами.
- Богатый набор методов — больше, чем вы когда-либо сможете запомнить.
С Python строки становятся не просто набором символов, а мощным инструментом для работы с текстом, который, кстати, встречается практически в любой программе.
Базовые операции с элементами
Записи в Python — как конструктор LEGO. Вы можете соединять их, повторять, измерять и даже вырезать отдельные кусочки, не говоря уже о поиске нужных комбинаций. Давайте разберем эти волшебные фокусы — каждый программист (даже начинающий) должен их знать наизусть, ведь строки встречаются буквально в каждой программе, которая не является калькулятором из одной строчки кода.
Конкатенация и дублирование
Конкатенация — это когда мы склеиваем элементы с помощью оператора +. Звучит устрашающе, но на практике это банальное сложение:
first_name = "Иван" last_name = "Иванов" full_name = first_name + " " + last_name # Получим "Иван Иванов"
В отличие от людей, строки могут размножаться бесполым путем с помощью оператора *. Это позволяет создавать повторяющиеся последовательности символов:
separator = "-" * 40 # Создаст строку из 40 дефисов "----------------------------------------" echo = "Эхо! " * 3 # Получим "Эхо! Эхо! Эхо! "
А для тех, кто устал от постоянной головной боли с операторами + и множеством переменных, Python придумал f-строки — такой себе шаблонизатор для ленивых (среди которых, не постесняюсь признаться, и я):
name = "Python"
age = 31 # Python появился в 1991 году
intro = f"Язык {name} существует уже {age} лет." # "Язык Python существует уже 34 лет."
Если вы застряли на Python версии ниже 3.6, придется использовать старый добрый метод .format():
intro = "Язык {} существует уже {} лет.".format(name, age)
Определение длины
Длину строки можно измерить с помощью функции len(). Это как линейка для текста, которая считает абсолютно все символы, включая пробелы, знаки препинания и специальные символы:
text = "Hello, World!" length = len(text) # Вернет 13 (включая запятую и пробел) multiline = """Строка 1 Строка 2""" print(len(multiline)) # Вернет 18 (включая символ переноса строки)
Будьте внимательны, когда речь идет о Unicode-символах. Эмодзи и некоторые другие символы могут создать иллюзию, что символов меньше, чем показывает len():
emoji = "👨👩👧👦" # Семья print(len(emoji)) # Может вернуть число больше 1, так как эмодзи состоит из нескольких Unicode-символов
Индексация и срезы
Python позволяет обращаться к отдельным символам записи, используя индексы. Причем, чтобы усложнить жизнь новичкам, индексация начинается с 0 (привет из мира C!):
s = "Python" first = s[0] # "P" third = s[2] # "t"
Для тех, кто любит считать с конца, Python предлагает отрицательные индексы. Удобно, если вам нужен, например, последний символ:
s = "Python" last = s[-1] # "n" prelast = s[-2] # "o"
Но это еще не всё! Срезы позволяют извлекать подстроки, указывая начальный и конечный индексы:
s = "Python" first_three = s[0:3] # "Pyt" (символы с индексами 0, 1, 2)
Если опустить начальный индекс, срез начнется с начала строки. Если опустить конечный — срез дойдет до конца:
s = "Python" first_three = s[:3] # "Pyt" last_three = s[3:] # "hon"
А теперь самое интересное — шаг! Третий параметр в срезе указывает, сколько символов нужно пропустить:
s = "0123456789" even = s[::2] # "02468" (каждый второй символ) odd = s[1::2] # "13579" (каждый второй, начиная с индекса 1) reversed_s = s[::-1] # "9876543210" (строка задом наперед)
Проверка вхождения
Когда нужно проверить, содержится ли одна строка внутри другой, на помощь приходит оператор in:
text = "Python -- это язык программирования"
print("Python" in text) # True
print("Java" in text) # False
Есть также оператор not in, который делает ровно противоположное:
print("Java" not in text) # True
print("Python" not in text) # False
Это гораздо удобнее, чем искать подстроку вручную или через методы типа .find(), особенно если вам просто нужно знать факт наличия или отсутствия.
| Операция | Выражение | Результат |
|---|---|---|
| Конкатенация | «Hello» + » » + «World» | «Hello World» |
| Дублирование | «Ha» * 3 | «HaHaHa» |
| Длина строки | len(«Python») | 6 |
| Индексация | «Python»[0] | «P» |
| Отрицательный индекс | «Python»[-1] | «n» |
| Срез | «Python»[1:4] | «yth» |
| Срез с начала | «Python»[:2] | «Py» |
| Срез до конца | «Python»[2:] | «thon» |
| Срез с шагом | «Python»[::2] | «Pto» |
| Проверка вхождения | «th» in «Python» | True |
| Отрицание проверки | «Java» not in «Python» | True |
Вооружившись этими базовыми операциями, вы уже можете творить чудеса со строками в Python. Но это только вершина айсберга — дальше будет еще интереснее!
Встроенные функции для работы с записями
Встроенные функции для строк в Python — это как универсальный набор инструментов, который прилагается к каждой купленной IKEA-строке. Не нужно ничего импортировать или устанавливать — они доступны прямо из коробки. Рассмотрим наиболее полезные из них, которые пригодятся в повседневной работе с текстом.
| Функция | Описание | Пример | Результат |
|---|---|---|---|
| len(s) | Возвращает количество символов в строке | len(«Python») | 6 |
| str(obj) | Преобразует объект в строковое представление | str(42) | «42» |
| ord(c) | Возвращает числовой код символа Unicode | ord(«A») | 65 |
| chr(i) | Возвращает символ по коду Unicode | chr(65) | «A» |
| repr(obj) | Возвращает «официальное» строковое представление объекта | repr(«Hello\n») | «‘Hello\\n'» |
Рассмотрим эти функции подробнее, потому что дьявол (как всегда) кроется в деталях.
Функция len()
Эта функция подсчитывает количество символов, включая пробелы и знаки препинания:
text = "Hello, World!" print(len(text)) # Выведет: 13
Что интересно, len() работает не только со элементами, но и с другими последовательностями — списками, словарями, кортежами. Такая себе швейцарская функция-нож.
Функция str()
Если вам нужно превратить в строку что угодно — числа, списки, словари, даже пользовательские объекты — str() придет на помощь:
num = 42 num_str = str(num) # "42" pi = 3.14159 pi_str = str(pi) # "3.14159" my_list = [1, 2, 3] list_str = str(my_list) # "[1, 2, 3]"
При работе с пользовательскими классами str() вызывает метод __str__() объекта, если он определен. Иначе будет использована стандартная реализация, которая, мягко говоря, не очень информативна (что-то вроде <__main__.MyClass object at 0x7f9a8c0b5fd0>).
Функции ord() и chr()
Эта парочка функций позволяет работать с Unicode-кодами символов. ord() принимает символ и возвращает его числовое значение, а chr() делает обратное — превращает число в символ:
# ASCII-код заглавной буквы 'A'
print(ord('A')) # Выведет: 65
# Символ с кодом 65
print(chr(65)) # Выведет: A
# Можно использовать для работы с Unicode
print(ord('€')) # Выведет: 8364
print(chr(8364)) # Выведет: €
Эти функции незаменимы, когда вы работаете с криптографией, кодировками или просто хотите понять, почему в ASCII-таблице прописные буквы идут до строчных (потому что их коды меньше — 65-90 против 97-122).
Функция repr()
Функция repr() возвращает строковое представление объекта, которое (теоретически) можно использовать для воссоздания этого объекта. В отличие от str(), она сохраняет специальные символы и кавычки:
text = "Hello\nWorld" print(str(text)) # Выведет: Hello # World print(repr(text)) # Выведет: 'Hello\nWorld'
repr() особенно полезна при отладке, когда вам нужно увидеть точное содержимое записи, включая невидимые или управляющие символы.
Другие полезные встроенные функции
Хотя следующие функции не являются специфичными для элементов, они часто используются в связке со строками:
| Функция | Описание | Пример | Результат |
|---|---|---|---|
| bin(i) | Преобразует целое число в двоичную строку | bin(42) | «0b101010» |
| hex(i) | Преобразует целое число в шестнадцатеричную строку | hex(42) | «0x2a» |
| sorted(s) | Возвращает отсортированный список символов строки | sorted(«hello») | [‘e’, ‘h’, ‘l’, ‘l’, ‘o’] |
| list(s) | Преобразует строку в список символов | list(«hello») | [‘h’, ‘e’, ‘l’, ‘l’, ‘o’] |
Встроенные функции — это только первый слой возможностей для работы с записями в Python. Следующий уровень — это методы строк, которые предоставляют гораздо больше специализированных инструментов для текстовой манипуляции. Но это уже тема для следующего раздела.
Кстати, помните, что в Python вы всегда можете получить справку по любой встроенной функции с помощью команды help(). Например, help(len) покажет вам документацию по функции len(). Это как навигатор по стране Python — всегда под рукой, когда вы заблудились в лесу документации.
Основные методы элементов в Python
Давайте разберём самые полезные методы, разбив их на тематические группы. Уверен, некоторые из них станут вашими верными друзьями в ежедневной борьбе с текстовыми данными.
Изменение регистра
Методы для изменения регистра записей в Python — это как стилисты для текста. Они могут придать вашей строке совершенно новый вид, не меняя её смысла:
| Метод | Назначение | Пример кода | Результат |
|---|---|---|---|
| upper() | Преобразует все символы в верхний регистр | ‘python’.upper() | ‘PYTHON’ |
| lower() | Преобразует все символы в нижний регистр | ‘PYTHON’.lower() | ‘python’ |
| capitalize() | Делает первую букву заглавной, остальные строчными | ‘pYTHON’.capitalize() | ‘Python’ |
| title() | Делает первую букву каждого слова заглавной | ‘hello world’.title() | ‘Hello World’ |
| swapcase() | Меняет регистр на противоположный | ‘PytHon’.swapcase() | ‘pYThON’ |
# Практический пример: нормализация имени пользователя
user_input = " jOHn DOE "
normalized = user_input.strip().title() # 'John Doe'
# Проверка без учёта регистра
password = "PassWord123"
user_entry = "password123"
if password.lower() == user_entry.lower():
print("Совпадение найдено, но регистр отличается!")
Обратите внимание, что методы title() и capitalize() немного наивны — они не знают о правилах грамматики и просто механически изменяют регистр. Например, ‘the iPhone’.title() даст ‘The Iphone’, что неверно для бренда «iPhone».
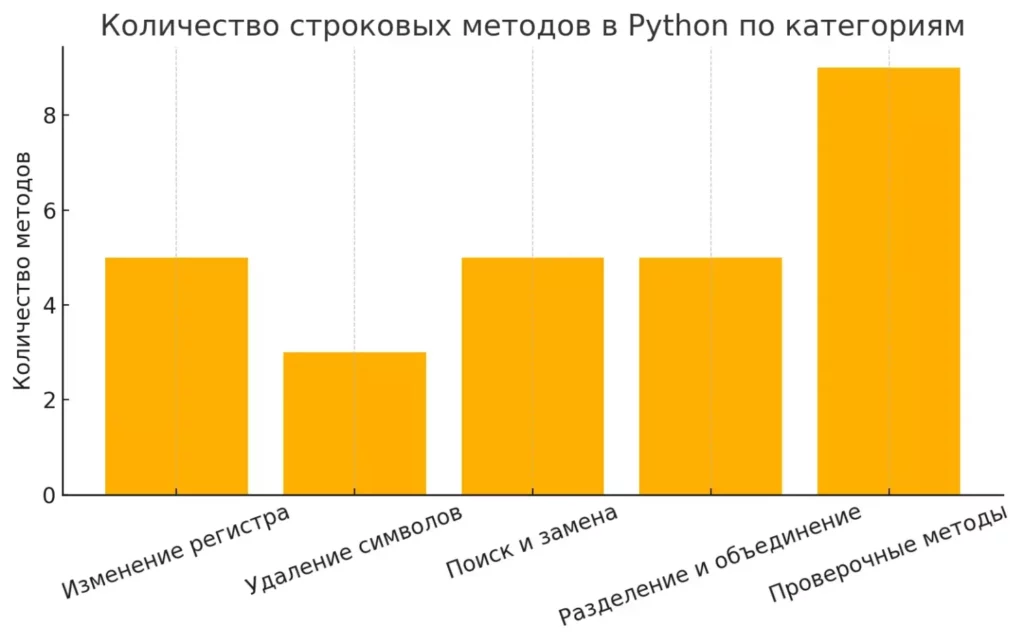
График наглядно демонстрирует, в каких категориях Python предлагает больше всего методов для работы со строками. Это помогает читателю быстро оценить, в каких сферах доступно больше возможностей.
Удаление лишних символов
Вы когда-нибудь получали данные из внешних источников? Если да, то знаете, насколько грязными они могут быть — пробелы, символы табуляции, переводы строк… Методы этой группы помогут привести ваши записи и в порядок:
| Метод | Назначение | Пример кода | Результат |
|---|---|---|---|
| strip([chars]) | Удаляет указанные символы с обоих концов | ‘ python ‘.strip() | ‘python’ |
| lstrip([chars]) | Удаляет указанные символы слева | ‘ python ‘.lstrip() | ‘python ‘ |
| rstrip([chars]) | Удаляет указанные символы справа | ‘ python ‘.rstrip() | ‘ python’ |
Если параметр chars не указан, удаляются пробельные символы (пробелы, табуляции, переносы строк). А если указан — любые символы из заданного набора:
# Удаление знаков пунктуации с концов строки
text = "...python developer..."
clean_text = text.strip('.') # 'python developer'
# Очистка URL от протокола и завершающего слэша
url = "https://www.example.com/"
domain = url.lstrip('https://').rstrip('/') # 'www.example.com'
Интересный факт: метод strip() удаляет любую комбинацию указанных символов, а не точную подстроку. Например, ‘www.example.com’.strip(‘w.moc’) даст ‘example’, потому что удаляются все символы ‘w’, ‘.’, ‘m’, ‘o’, ‘c’ с обоих концов строки.
Поиск и замена
Когда вам нужно найти подстроку или заменить её на что-то другое, эти методы станут вашими лучшими друзьями:
| Метод | Назначение | Пример кода | Результат |
|---|---|---|---|
| find(sub[, start[, end]]) | Ищет подстроку, возвращает индекс или -1 | ‘python’.find(‘th’) | 2 |
| rfind(sub[, start[, end]]) | Ищет подстроку с конца | ‘pythonpy’.rfind(‘py’) | 6 |
| index(sub[, start[, end]]) | Как find, но вызывает ValueError при отсутствии | ‘python’.index(‘on’) | 4 |
| replace(old, new[, count]) | Заменяет подстроку на новую | ‘python’.replace(‘p’, ‘j’) | ‘jython’ |
| count(sub[, start[, end]]) | Считает количество вхождений подстроки | ‘python’.count(‘p’) | 1 |
Параметры start и end задают диапазон для поиска, а count в методе replace() ограничивает количество замен:
# Найти все вхождения 'py' в строке
text = "python is great, and python is powerful"
start = 0
while True:
pos = text.find('py', start)
if pos == -1:
break
print(f"Найдено на позиции {pos}")
start = pos + 1
# Заменить только первые 2 вхождения
new_text = text.replace('python', 'Python', 2)
Метод replace() — один из моих любимых, потому что его можно использовать для «удаления» подстроки, заменяя её на пустую запись: text.replace(‘unwanted’, »).
Разделение и объединение
Эти методы позволяют разбивать записи на части или собирать их из списка подстрок:
| Метод | Назначение | Пример кода | Результат |
|---|---|---|---|
| split([sep[, maxsplit]]) | Разбивает строку по разделителю | ‘a,b,c’.split(‘,’) | [‘a’, ‘b’, ‘c’] |
| rsplit([sep[, maxsplit]]) | Разбивает строку справа налево | ‘a,b,c’.rsplit(‘,’, 1) | [‘a,b’, ‘c’] |
| splitlines([keepends]) | Разбивает по символам новой строки | ‘a\nb\nc’.splitlines() | [‘a’, ‘b’, ‘c’] |
| join(iterable) | Объединяет строки из итерируемого объекта | ‘,’.join([‘a’, ‘b’, ‘c’]) | ‘a,b,c’ |
| partition(sep) | Разбивает на 3 части по первому разделителю | ‘a:b:c’.partition(‘:’) | (‘a’, ‘:’, ‘b:c’) |
# Парсинг CSV строки
csv_line = "John,Doe,42,New York"
name, surname, age, city = csv_line.split(',')
# Объединение элементов списка в строку
tags = ['python', 'programming', 'tutorial']
hashtags = ' '.join(['#' + tag for tag in tags]) # '#python #programming #tutorial'
# Разделение имени файла на имя и расширение
filename = "document.pdf"
name, ext = filename.partition('.')[-1] if '.' in filename else (filename, '')
Обратите внимание на интересную особенность метода join() — он вызывается у строки-разделителя, а не у списка строк. Это может показаться контринтуитивным для новичков, но имеет смысл с точки зрения объектно-ориентированного программирования.
Проверочные методы
Эти методы проверяют, соответствует ли запись определенным критериям, и возвращают булево значение (True или False):
| Метод | Назначение | Пример кода | Результат |
|---|---|---|---|
| startswith(prefix[, start[, end]]) | Проверяет, начинается ли строка с префикса | ‘python’.startswith(‘py’) | True |
| endswith(suffix[, start[, end]]) | Проверяет, заканчивается ли строка суффиксом | ‘python’.endswith(‘on’) | True |
| isdigit() | Проверяет, состоит ли строка только из цифр | ’42’.isdigit() | True |
| isalpha() | Проверяет, состоит ли строка только из букв | ‘Python’.isalpha() | True |
| isalnum() | Проверяет, состоит ли строка из букв и цифр | ‘Python3’.isalnum() | True |
| isspace() | Проверяет, состоит ли строка только из пробельных символов | ‘ \t\n’.isspace() | True |
| islower() | Проверяет, все ли буквы в нижнем регистре | ‘python’.islower() | True |
| isupper() | Проверяет, все ли буквы в верхнем регистре | ‘PYTHON’.isupper() | True |
| istitle() | Проверяет, начинается ли каждое слово с заглавной буквы | ‘Python Is Great’.istitle() | True |
Эти методы удобно использовать в условиях:
# Проверка ввода пользователя
user_input = input("Введите число: ")
if user_input.isdigit():
number = int(user_input)
else:
print("Это не число!")
# Проверка расширения файла
filename = "document.pdf"
if filename.lower().endswith(('.pdf', '.doc', '.docx')):
print("Это документ!")
Обратите внимание, что метод endswith() может принимать кортеж суффиксов, что очень удобно для проверки нескольких вариантов.
Методы элементов делают Python невероятно мощным инструментом для обработки текста. И это лишь верхушка айсберга — в стандартной библиотеке есть ещё модули re (для регулярных выражений), textwrap (для форматирования текста), difflib (для сравнения записей) и многие другие.
Возможно, я переборщил с деталями, но поверьте — освоив эти методы, вы значительно сократите количество кода, который пишете для обработки текста. И ваши коллеги будут благодарны за то, что не нужно расшифровывать ваши самописные функции для манипуляции строками.
Форматирование
Форматирование строк в Python — это как искусство создания идеальной чашки капучино. Вы можете делать это разными способами, но результат должен быть одинаково прекрасным. Со временем я пережил эволюцию форматирования от конкатенации до f-строк, и это, поверьте, было не менее болезненно, чем переход от Java к Python.
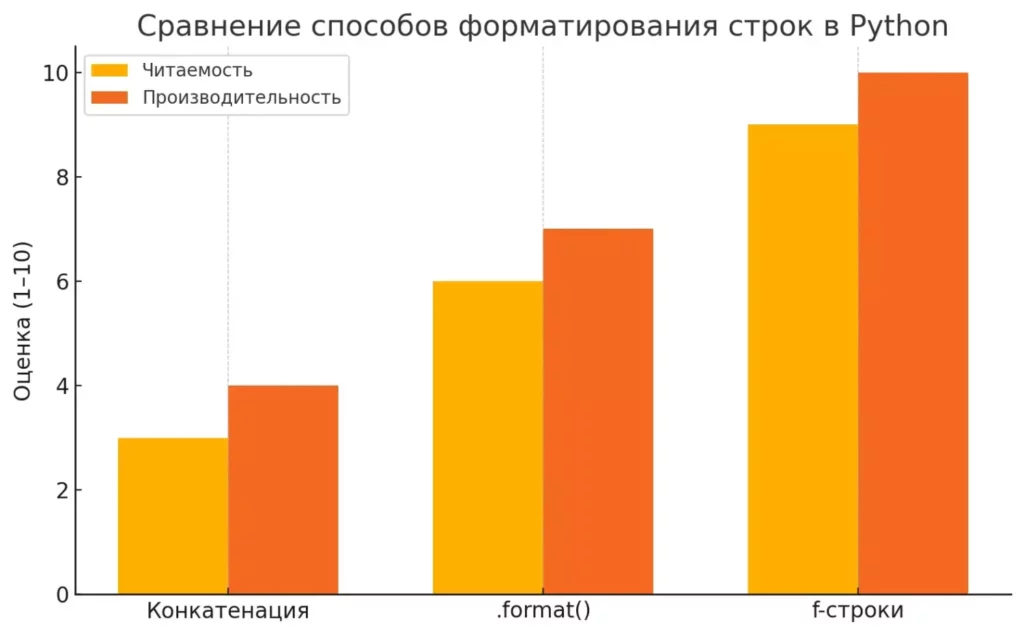
Столбчатая диаграмма сравнивает три метода форматирования строк по двум критериям: читаемость и производительность. Оценки условные, по 10-балльной шкале.
Существует три основных способа форматирования в Python, и каждый из них имеет свои преимущества и недостатки. Давайте разберем их от старого к новому — чтобы вы могли понять, как мы дошли до текущего состояния «строкового рая».
1. Конкатенация с помощью оператора +
Самый примитивный способ — просто склеивать записи:
name = "John" age = 30 greeting = "Привет, " + name + "! Тебе " + str(age) + " лет."
Работает? Да. Красиво? Вряд ли. У этого подхода есть несколько проблем:
- Необходимо явно преобразовывать нестроковые типы в строки.
- При большом количестве переменных код становится нечитаемым.
- Каждый раз при использовании + создается новая строка, что неэффективно.
Это как печатать на пишущей машинке в эпоху компьютеров — работает, но вызывает вопросы.
2. Метод .format()
В Python 2.6 появился метод .format(), который значительно улучшил ситуацию:
name = "John"
age = 30
greeting = "Привет, {}! Тебе {} лет.".format(name, age)
А еще можно использовать именованные аргументы, что делает код более понятным:
greeting = "Привет, {name}! Тебе {age} лет.".format(name=name, age=age)
Или даже передавать порядковые номера аргументов:
greeting = "Привет, {0}! Тебе {1} лет. Рад встрече, {0}!".format(name, age)
Кроме того, .format() поддерживает различные опции форматирования:
# Форматирование чисел
price = 42.5678
formatted_price = "Цена: {:.2f} руб.".format(price) # "Цена: 42.57 руб."
# Выравнивание текста
title = "Заголовок"
centered = "{:^20}".format(title) # " Заголовок "
Метод .format() был огромным шагом вперед, но синтаксис все еще казался немного громоздким.
3. f-строки (форматированные строки литералы)
В Python 3.6 появились f-строки, которые сделали форматирование еще более интуитивным и лаконичным:
name = "John"
age = 30
greeting = f"Привет, {name}! Тебе {age} лет."
F-строки не только короче, но и более производительны, так как вычисляются во время компиляции, а не выполнения. Кроме того, они поддерживают выражения прямо внутри фигурных скобок:
a = 5
b = 10
result = f"{a} + {b} = {a + b}" # "5 + 10 = 15"
И, конечно, все те же функции форматирования, что и в .format():
import math
formatted = f"Значение π: {math.pi:.4f}" # "Значение π: 3.1416"
Сравнение подходов к форматированию:
| Способ | Синтаксис | Преимущества | Недостатки |
|---|---|---|---|
| Конкатенация | «Hello, » + name | Прост для понимания | Неэффективен, требует ручного преобразования типов |
| .format() | «Hello, {}».format(name) | Гибкий, поддерживает опции форматирования | Более многословен, чем f-строки |
| f-строки | f»Hello, {name}» | Лаконичные, мощные, производительные | Работают только в Python 3.6+ |
Когда я впервые увидел f-строки, мне казалось, что это какое-то колдовство. После долгих лет работы с .format() и конкатенацией они выглядели слишком просто и элегантно, чтобы быть правдой. Но это был долгожданный прорыв в удобстве разработки.
Мой совет: если вы пишете код для Python 3.6 и новее — используйте f-строки. Они более читаемые, их проще поддерживать, и они более эффективны с точки зрения производительности. Если же вам нужна обратная совместимость со старыми версиями Python — используйте .format(). А конкатенацию оставьте для очень простых случаев или для образовательных целей, чтобы показать, как не надо делать.
Помните: хорошее форматирование — это не просто вопрос эстетики, это вопрос читаемости и поддерживаемости кода. Выбирайте инструменты мудро!
Распространённые ошибки
В мире Python строковые ошибки — это как грабли, на которые наступают все от мала до велика. Я видел, как даже опытные разработчики тратили часы на отладку из-за какой-нибудь чепухи вроде забытого .strip(). Давайте пройдемся по самым коварным ошибкам, чтобы вы могли распознать их издалека и уклониться, как от брошенного в вас ноутбука на совещании.
Индексация вне диапазона
Самая распространенная ошибка — это попытка получить доступ к символу по индексу, которого не существует:
text = "Python"
try:
last_char = text[6] # IndexError: string index out of range
except IndexError as e:
print(f"Поймал ошибку: {e}")
В отличие от некоторых языков программирования (кхм, C/C++, кхм), Python не позволит вам просто так выйти за границы строки и разрушить стек вызовов. Вместо этого он любезно выбросит исключение IndexError. Здесь есть простые решения:
- Используйте отрицательные индексы для доступа к последним символам:
text = "Python" last_char = text[-2] # "n"
- Проверяйте длину строки перед обращением к индексу:
if len(text) > index: char = text[index]
- Используйте срезы вместо индексов — они не вызывают ошибок:
text = "Python" # Даже если начало или конец выходят за границы, срез работает print(text[5:10]) # "n" (без ошибки)
Путаница с кавычками
Еще одна головная боль — неправильное использование кавычек. Python позволяет использовать как одинарные, так и двойные кавычки, но они должны быть парными:
# Ошибки синтаксиса из-за кавычек # wrong_string = 'It's a mistake' # SyntaxError: invalid syntax # another_wrong = "He said "hello" to me" # SyntaxError: invalid syntax
Решения:
- Используйте разные типы кавычек снаружи и внутри:
correct_string = "It's a correct string" another_correct = 'He said "hello" to me'
- Экранируйте кавычки с помощью обратного слеша:
escaped_string = 'It\'s also correct' double_escaped = "He said \"hello\" to me"
- Используйте тройные кавычки для строк с несколькими типами кавычек:
triple_quotes = '''It's a "complicated" string'''
Попытка изменить строку
Я не могу сосчитать, сколько раз я сам попадался на эту удочку в начале карьеры. Строки в Python — неизменяемые объекты. Это значит, что вы не можете изменить существующую строку, а можете только создать новую:
text = "Python"
try:
text[0] = "J" # TypeError: 'str' object does not support item assignment
except TypeError as e:
print(f"Поймал ошибку: {e}")
Решения:
- Создавайте новую строку с нужными изменениями:
text = "Python" new_text = "J" + text[1:] # "Jython"
- Используйте метод replace() для замены символов:
new_text = text.replace("P", "J") # "Jython"
- Преобразуйте строку в список, измените его и соберите обратно:
chars = list(text) chars[0] = "J" new_text = "".join(chars) # "Jython"
Последний способ я крайне не рекомендую использовать без острой необходимости — это неэффективно и выглядит как будто вы пытаетесь писать на Java, используя синтаксис Python.
Проблемы с кодировкой
Кодировки — это та сфера, где даже опытные разработчики начинают нервно посмеиваться. Unicode сделал жизнь проще, но не избавил от всех проблем:
# В Python 3 строки по умолчанию в UTF-8, но проблемы все равно возникают
try:
with open("file.txt", "r") as f: # UnicodeDecodeError, если файл в другой кодировке
content = f.read()
except UnicodeDecodeError as e:
print(f"Ошибка кодировки: {e}")
Решения:
- Явно указывайте кодировку при работе с файлами:
with open("file.txt", "r", encoding="utf-8") as f:
content = f.read()
- Используйте байтовые строки для работы с бинарными данными:
binary_data = b"This is binary data"
- Используйте функции encode() и decode() для явного преобразования:
text = "Привет"
encoded = text.encode("utf-8") # Преобразование в байты
decoded = encoded.decode("utf-8") # Обратно в строку
Забытое преобразование типов
Еще одна распространенная ошибка — забыть преобразовать другие типы данных в строки при конкатенации:
age = 30
try:
message = "Мне " + age + " лет" # TypeError: can only concatenate str (not "int") to str
except TypeError as e:
print(f"Ошибка типов: {e}")
Решения:
- Явное преобразование с помощью str():
message = "Мне " + str(age) + " лет"
- Использование форматирования строк:
message = f"Мне {age} лет" # Лучший вариант
# или
message = "Мне {} лет".format(age)
Я надеюсь, что вы никогда не столкнетесь с этими ошибками, но если столкнетесь — теперь вы знаете, как их исправить. Помните: ошибки — это не повод опускать руки, а возможность стать лучше. Хотя, кого я обманываю? Все мы иногда чертыхаемся, когда видим ‘str’ object does not support item assignment в сотый раз.
А теперь – переходим к самому интересному: практическим примерам, где вы можете увидеть, как все эти строковые операции, методы и функции работают вместе, создавая что-то действительно полезное!
Практические примеры и задачи
Теория без практики — как GitHub без коммитов: вроде бы есть, но толку ноль. Давайте применим наши знания о строках в реальных задачах, с которыми вы наверняка столкнетесь (или уже сталкивались) в своей разработческой карьере. Я отобрал несколько классических примеров, которые часто встречаются на собеседованиях и в реальных проектах — от простых до умеренно сложных.
Проверка палиндрома
Палиндром — это строка, которая читается одинаково слева направо и справа налево. Например, «шалаш», «а роза упала на лапу Азора» (без учета пробелов и регистра). Вот элегантное решение:
def is_palindrome(text):
"""Проверяет, является ли строка палиндромом.
Args:
text (str): Исходная строка
Returns:
bool: True, если строка -- палиндром, иначе False
"""
# Приводим к нижнему регистру и удаляем все, кроме букв и цифр
cleaned_text = ''.join(char.lower() for char in text if char.isalnum())
# Сравниваем строку с её перевёрнутой версией
return cleaned_text == cleaned_text[::-1]
# Примеры использования
inputs = [
"А роза упала на лапу Азора",
"Python",
"Madam, I'm Adam",
"12321"
]
for text in inputs:
result = is_palindrome(text)
print(f"'{text}': {'✓' if result else '✗'}")
Output:
'А роза упала на лапу Азора': ✓ 'Python': ✗ 'Madam, I'm Adam': ✓ '12321': ✓
Обратите внимание на элегантность решения: мы сначала очищаем запись от всего, что не является буквой или цифрой, а затем используем срез с отрицательным шагом для получения перевернутой строки. Никаких циклов, никаких временных переменных — чистая функциональщина!
Подсчёт количества слов
Еще одна классическая задача — подсчет слов в тексте. В простейшем случае можно считать, что слова разделены пробелами:
def count_words(text):
"""Подсчитывает количество слов в тексте.
Args:
text (str): Исходный текст
Returns:
dict: Словарь, где ключи -- слова, значения -- количество вхождений
"""
# Приводим к нижнему регистру и разбиваем на слова
words = text.lower().split()
# Очищаем слова от знаков препинания
cleaned_words = [word.strip('.,!?;:()[]{}"\'-') for word in words]
# Считаем вхождения каждого слова
word_counts = {}
for word in cleaned_words:
if word: # Проверяем, что слово не пустое после очистки
word_counts[word] = word_counts.get(word, 0) + 1
return word_counts
# Пример использования
text = """Python -- высокоуровневый язык программирования общего назначения.
Python -- один из самых популярных языков программирования в мире."""
word_counts = count_words(text)
for word, count in sorted(word_counts.items(), key=lambda x: x[1], reverse=True):
if count > 1: # Показываем только слова, которые встречаются больше одного раза
print(f"{word}: {count}")
Output:
python: 2 программирования: 2 языков: 2 язык: 2 в: 2
Этот пример демонстрирует несколько полезных техник: преобразование в нижний регистр, разбиение строки на слова, очистку от знаков препинания и использование словаря для подсчета вхождений. В реальных проектах вы, вероятно, захотите использовать регулярные выражения для более точной обработки текста, но это уже тема для отдельной статьи.
Цензура текста (замена слов)
А теперь представим, что нам нужно отцензурировать текст, заменив определенные слова на звездочки. Это может пригодиться, например, в чатах или комментариях:
def censor_text(text, banned_words):
"""Заменяет запрещенные слова звездочками.
Args:
text (str): Исходный текст
banned_words (list): Список запрещенных слов
Returns:
str: Отцензурированный текст
"""
words = text.split()
result = []
for word in words:
# Отделяем знаки препинания для правильной замены
# Это упрощенная версия, в реальности нужно использовать регулярные выражения
prefix = ''
suffix = ''
while word and not word[0].isalnum():
prefix += word[0]
word = word[1:]
while word and not word[-1].isalnum():
suffix = word[-1] + suffix
word = word[:-1]
# Проверяем, является ли слово запрещенным (без учета регистра)
if word.lower() in [w.lower() for w in banned_words]:
censored = '*' * len(word)
result.append(prefix + censored + suffix)
else:
result.append(prefix + word + suffix)
return ' '.join(result)
# Пример использования
text = "Java и JavaScript -- разные языки программирования, хотя это не очевидно для новичков."
banned_words = ["Java", "JavaScript", "новичков"]
censored_text = censor_text(text, banned_words)
print(f"До: {text}")
print(f"После: {censored_text}")
Output:
До: Java и JavaScript -- разные языки программирования, хотя это не очевидно для новичков. После: **** и ********** -- разные языки программирования, хотя это не очевидно для ********.
Этот пример демонстрирует, как можно обрабатывать отдельные слова, сохраняя при этом оригинальную пунктуацию. В реальном проекте вы, вероятно, захотите использовать более сложные правила для определения слов и их границ, но идея остается той же.
Преобразование регистра текста
Последний пример — функция для преобразования текста в различные форматы регистра:
def convert_case(text, case_type):
"""Преобразует текст в указанный формат регистра.
Args:
text (str): Исходный текст
case_type (str): Тип преобразования: 'upper', 'lower', 'title', 'sentence', 'camel', 'snake'
Returns:
str: Преобразованный текст
"""
if case_type == 'upper':
return text.upper()
elif case_type == 'lower':
return text.lower()
elif case_type == 'title':
return text.title()
elif case_type == 'sentence':
# Делаем первую букву каждого предложения заглавной
sentences = text.lower().split('. ')
return '. '.join(s.capitalize() for s in sentences)
elif case_type == 'camel':
# CamelCase: первое слово с маленькой буквы, остальные с большой, без пробелов
words = text.split()
return words[0].lower() + ''.join(word.capitalize() for word in words[1:])
elif case_type == 'snake':
# snake_case: все буквы маленькие, слова разделены подчеркиваниями
return '_'.join(word.lower() for word in text.split())
else:
return text # Возвращаем исходный текст, если тип не распознан
# Примеры использования
text = "Python is an amazing programming language"
print(f"Исходный текст: {text}")
print(f"UPPER CASE: {convert_case(text, 'upper')}")
print(f"lower case: {convert_case(text, 'lower')}")
print(f"Title Case: {convert_case(text, 'title')}")
print(f"Sentence case: {convert_case(text, 'sentence')}")
print(f"camelCase: {convert_case(text, 'camel')}")
print(f"snake_case: {convert_case(text, 'snake')}")
Output:
Исходный текст: Python is an amazing programming language UPPER CASE: PYTHON IS AN AMAZING PROGRAMMING LANGUAGE lower case: python is an amazing programming language Title Case: Python Is An Amazing Programming Language Sentence case: Python is an amazing programming language camelCase: pythonIsAnAmazingProgrammingLanguage snake_case: python_is_an_amazing_programming_language
Этот пример показывает, как можно использовать различные строковые методы и техники для создания универсального конвертера регистра. Такая функция может быть полезна в разных контекстах — от предварительной обработки данных до генерации кода.
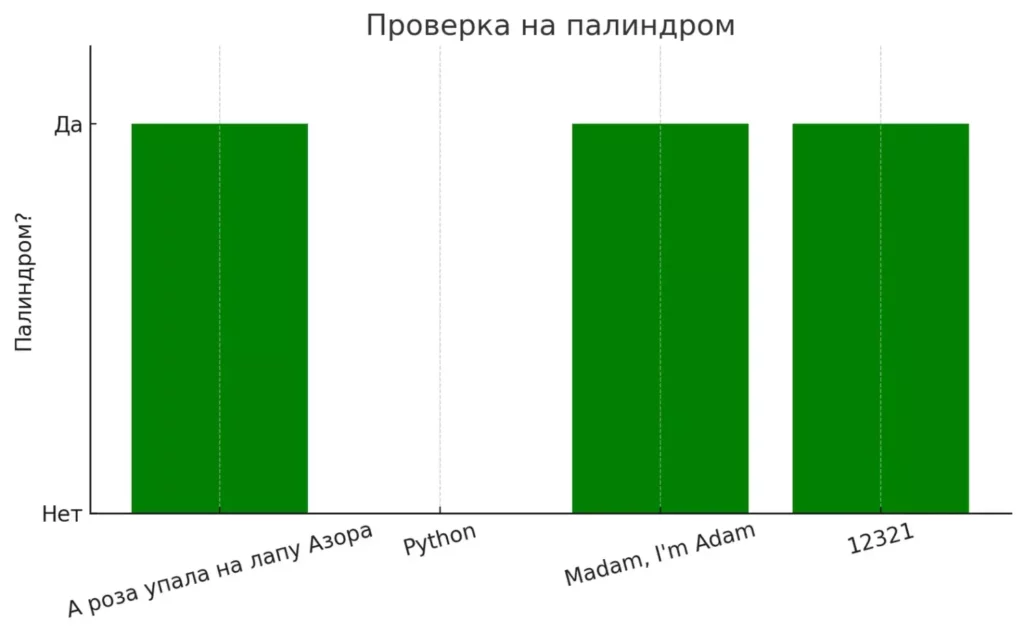
Цветовая индикация (зелёный/красный) помогает быстро понять, какие строки являются палиндромами. Это укрепляет визуальную связь с логикой функции и результатами вывода.
Заключение
Строки в Python — это гораздо больше, чем просто последовательности символов. Это мощные объекты с богатым набором методов и функций, которые позволяют эффективно решать самые разнообразные задачи обработки текста. От простой конкатенации до сложных преобразований — Python предоставляет инструменты на все случаи жизни.
- Строки в Python — это не просто последовательности символов, а мощные объекты с богатым набором методов.
- Строки создаются с помощью одинарных, двойных и тройных кавычек и обладают неизменяемостью.
- Базовые операции — такие как конкатенация, индексация и срезы — лежат в основе работы со строками.
- Встроенные функции и методы позволяют выполнять широкий спектр задач обработки текста.
- Современные подходы к форматированию, включая f-строки, делают код лаконичным и удобочитаемым.
- Знание типичных ошибок помогает избежать распространённых проблем при работе со строками.
- Практика через задачи — лучший способ закрепить полученные знания.
- Рекомендуется продолжить изучение с модуля re (регулярные выражения) для продвинутой работы с текстом.
- Обратите внимание на модули string, codecs, difflib, textwrap и unicodedata — они расширяют возможности обработки строк.
- Регулярная работа со строками делает методы и приёмы естественными и интуитивными.
Если вам понравилось разбираться в строках и хочется копнуть глубже, самое время перейти от теории к практике. Освойте Python с нуля до уверенного уровня на структурированных онлайн-курсах, где вы не просто изучите синтаксис, но и научитесь применять язык в реальных проектах — от парсинга данных до веб-разработки и машинного обучения. Запишитесь на курсы Python-разработчика — и пусть строки, функции и модули станут вашим инструментом, а не головной болью.
Рекомендуем посмотреть курсы по Python
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Профессия Python-разработчик
|
Eduson Academy
83 отзыва
|
Цена
Ещё -5% по промокоду
95 000 ₽
|
От
7 917 ₽/мес
|
Длительность
6 месяцев
|
Старт
23 декабря
|
Ссылка на курс |
|
Go-разработчик (Junior)
|
Level UP
36 отзывов
|
Цена
45 500 ₽
|
От
11 375 ₽/мес
|
Длительность
3 месяца
|
Старт
27 января
|
Ссылка на курс |
|
Fullstack-разработчик на Python
|
Нетология
45 отзывов
|
Цена
с промокодом kursy-online
146 500 ₽
308 367 ₽
|
От
4 282 ₽/мес
|
Длительность
18 месяцев
|
Старт
1 января
|
Ссылка на курс |
|
Python-разработчик
|
Академия Синергия
34 отзыва
|
Цена
91 560 ₽
228 900 ₽
|
От
3 179 ₽/мес
4 552 ₽/мес
|
Длительность
6 месяцев
|
Старт
23 декабря
|
Ссылка на курс |
|
Профессия Python-разработчик
|
Skillbox
205 отзывов
|
Цена
Ещё -20% по промокоду
74 507 ₽
149 015 ₽
|
От
6 209 ₽/мес
9 715 ₽/мес
|
Длительность
12 месяцев
|
Старт
25 декабря
|
Ссылка на курс |

CSS-анимации — что это такое, как работают и зачем нужны
Хотите сделать интерфейс динамичнее и живее, но не знаете, с чего начать? В этой статье разберём, как сделать анимацию в CSS — от простых fade-in эффектов до сложных сценариев с множественными анимациями.

map в Python: как работает и зачем нужна функция преобразования
Функция map() часто вызывает вопросы: когда её использовать, зачем и в чём преимущества? В этом руководстве — практические примеры и честный разбор плюсов и минусов.

Почему одни бренды помнят все, а другие — никто?
Узнаваемость бренда — это не просто модный термин, а реальный инструмент роста. Как сделать так, чтобы ваше имя первым всплывало в голове клиента? В этой статье — конкретные примеры, советы и метрики.

Какие курсы пройти, чтобы хорошо зарабатывать и найти работу в 2025 году
Хотите выбрать курсы, после которых можно работать без долгих поисков и проб? Мы расскажем, какие профессии будут востребованы в 2025 году, сколько реально можно зарабатывать и на что обратить внимание при выборе программы.