Кэширование в Java: что это, как работает и как реализовать
В современной разработке производительность приложений становится критически важным фактором успеха. Когда пользователи ожидают молниеносной реакции от веб-сервисов, а базы данных содержат миллионы записей, каждая миллисекунда на счету. Именно здесь на помощь приходит кэширование — технология, которая может кардинально изменить скорость работы вашего Java-приложения.

Мы рассмотрим кэширование как универсальный инструмент оптимизации, который одинаково полезен как для начинающих разработчиков, изучающих основы Java, так и для опытных программистов, работающих со Spring Framework. В этой статье вы найдете простые объяснения сложных концепций, практические примеры кода и конкретные рекомендации по внедрению кэширования в ваши проекты. Давайте разберемся, как превратить медленные запросы в быстрые ответы.
- Что такое кэш и зачем он нужен
- Как работает кэш: простая логика и механизмы
- Реализация простого кэша в Java (без Spring)
- Кэширование в Spring: аннотации и механизмы
- Как работает CacheManager и какие типы кешей бывают
- Когда лучше использовать готовые библиотеки (Guava, EhCache)
- Кэширование на уровне базы данных: пример Oracle
- Ошибки при работе с кэшем и как их избежать
- Выводы и рекомендации для начинающих Java-разработчиков
- Заключение
- Рекомендуем посмотреть курсы по Java
Что такое кэш и зачем он нужен
Представьте себе библиотекаря, который каждый день отвечает на одни и те же вопросы читателей. Вместо того чтобы каждый раз бегать по залам в поисках нужной книги, опытный библиотекарь держит самые популярные издания под рукой. Именно так работает кэш в программировании — это промежуточное хранилище данных, где размещается часто запрашиваемая информация для быстрого доступа.
В контексте Java-приложений кэш становится особенно ценным при работе с операциями, требующими значительного времени: обращения к базе данных, вызовы внешних API, сложные вычисления. Когда система получает запрос, она сначала проверяет наличие данных в кэше. Если данные найдены — это называется «попаданием в кэш» (cache hit), и ответ возвращается мгновенно. Если данных нет — происходит «промах кэша» (cache miss), система обращается к первоисточнику и обычно сохраняет полученный результат для будущих запросов.
Ключевые преимущества кэширования:
- Существенное сокращение времени отклика приложения.
- Снижение нагрузки на базы данных и внешние сервисы.
- Улучшение пользовательского опыта.
- Экономия вычислительных ресурсов.
- Повышение общей производительности системы.
Однако важно понимать, что кэширование — это не магическая палочка. Неправильно настроенный кэш может привести к проблемам с консистентностью данных и даже замедлить работу приложения.
Как работает кэш: простая логика и механизмы
Механизм работы кэша следует четкой и предсказуемой логике, которую можно сравнить с работой умного секретаря. Когда к нему поступает запрос, он действует по отработанному алгоритму, который обеспечивает максимальную эффективность.
Давайте разберем пошаговый процесс обработки запроса в кэшированной системе. Сначала происходит проверка: есть ли запрашиваемые данные в кэше? Эта операция выполняется очень быстро, поскольку кэш обычно хранится в оперативной памяти. Если данные обнаружены, система немедленно возвращает их пользователю — задача выполнена за доли секунды.
В случае отсутствия данных в кэше система переходит к следующему этапу: обращению к первоисточнику. Это может быть база данных, файловая система, внешний API или результат сложных вычислений. После получения данных из первоисточника происходит двойная операция: данные возвращаются пользователю и одновременно сохраняются в кэше для последующих запросов.
Основные этапы обработки запроса:
- Получение запроса от пользователя.
- Проверка наличия данных в кэше по ключу.
- При попадании — немедленный возврат данных.
- При промахе — обращение к первоисточнику.
- Сохранение полученных данных в кэше.
- Возврат результата пользователю.
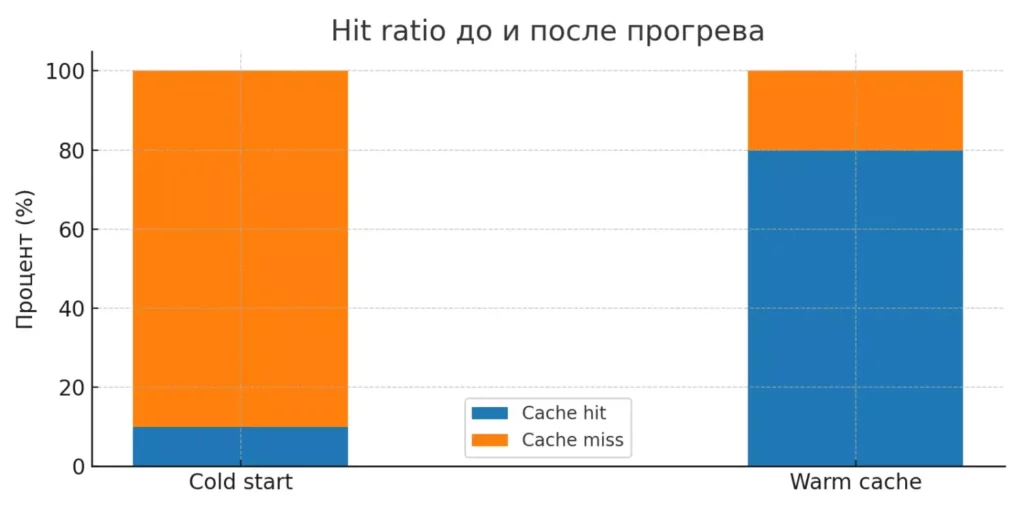
Диаграмма показывает соотношение попаданий и промахов в кэш до и после его прогрева. Хорошо иллюстрирует, как повторные запросы значительно повышают эффективность системы.
Эта простая схема становится основой для более сложных стратегий кэширования, которые мы рассмотрим далее.
Реализация простого кэша в Java (без Spring)
Начнем с самого базового подхода к кэшированию в Java — использования стандартных коллекций. Простейший кэш можно реализовать с помощью HashMap, который хранит пары «ключ-значение» и обеспечивает быстрый доступ к данным.
import java.util.HashMap;
import java.util.Map;
public class SimpleCache<K, V> {
private final Map<K, V> cache = new HashMap<>();
public V get(K key) {
return cache.get(key);
}
public void put(K key, V value) {
cache.put(key, value);
}
public boolean containsKey(K key) {
return cache.containsKey(key);
}
}
Однако для многопоточных приложений лучше использовать ConcurrentHashMap, который обеспечивает потокобезопасность без необходимости внешней синхронизации:
import java.util.concurrent.ConcurrentHashMap;
public class ThreadSafeCache<K, V> {
private final ConcurrentHashMap<K, V> cache = new ConcurrentHashMap<>();
public V getOrCompute(K key, Function<K, V> supplier) {
return cache.computeIfAbsent(key, supplier);
}
}
Пример использования такого кэша в реальном сценарии:
ThreadSafeCache<String, String> userCache = new ThreadSafeCache<>();
public String getUserName(String userId) {
return userCache.getOrCompute(userId, id -> {
// Имитация запроса к базе данных
return database.findUserById(id).getName();
});
}
Анализ простого подхода:
| Плюсы | Минусы |
|---|---|
| Простота реализации | Отсутствие автоматического удаления устаревших данных |
| Высокая скорость доступа | Потенциальные утечки памяти при росте кэша |
| Полный контроль над логикой | Нет встроенной поддержки TTL (время жизни) |
| Минимальные зависимости | Необходимость ручного управления размером |
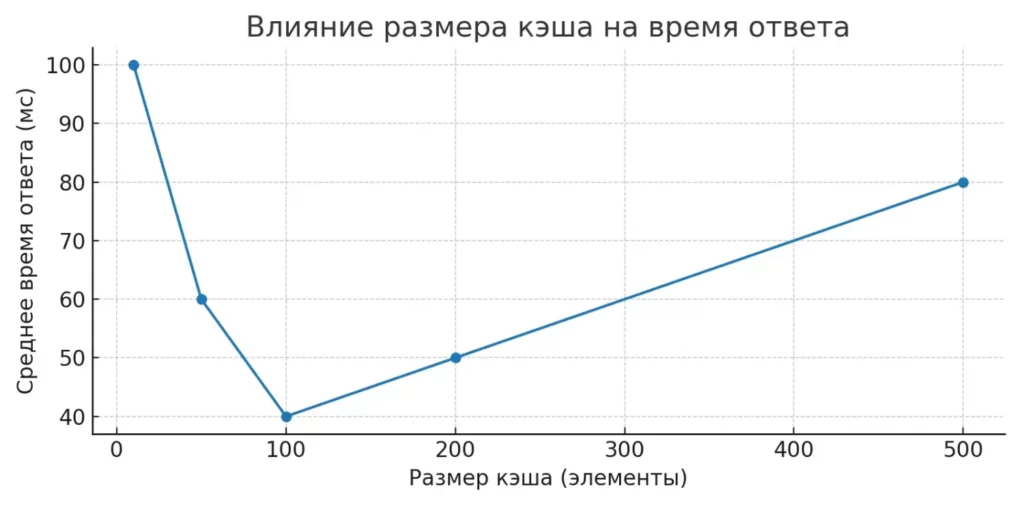
Линейный график показывает, как увеличение размера кэша сначала ускоряет ответы, а затем при чрезмерном росте может привести к замедлению из-за накладных расходов.
Основная проблема такого подхода заключается в том, что кэш будет расти бесконечно, потребляя все больше памяти. В production-системах это может привести к серьезным проблемам производительности.
Кэширование в Spring: аннотации и механизмы
Spring Framework предлагает элегантное решение для кэширования, которое избавляет разработчиков от необходимости писать собственную логику управления кэшем. Декларативный подход Spring позволяет добавить кэширование к существующим методам с помощью простых аннотаций.
Как включить кэширование в Spring
Для активации механизма кэширования достаточно добавить аннотацию @EnableCaching к конфигурационному классу:
@SpringBootApplication
@EnableCaching
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
Эта аннотация включает Spring Cache Abstraction — слой абстракции, который позволяет использовать различные реализации кэша через единый интерфейс.
@Cacheable, @CachePut и @CacheEvict
Spring предоставляет три основные аннотации для управления кэшем, каждая из которых решает конкретные задачи:
@Service
public class UserService {
@Cacheable(cacheNames = "users", key = "#userId")
public User findUser(String userId) {
// Метод выполняется только при отсутствии данных в кэше
return database.findById(userId);
}
@CachePut(cacheNames = "users", key = "#user.id")
public User updateUser(User user) {
// Метод всегда выполняется, результат обновляет кэш
return database.save(user);
}
@CacheEvict(cacheNames = "users", key = "#userId")
public void deleteUser(String userId) {
// Удаляет запись из кэша и базы данных
database.deleteById(userId);
}
}
Для сложных ключей можно использовать SpEL-выражения:
@Cacheable(cacheNames = "userProfiles", key = "#user.id + '_' + #includeDetails")
public UserProfile getUserProfile(User user, boolean includeDetails) {
// Ключ будет формироваться как "123_true" или "456_false"
return buildProfile(user, includeDetails);
}
Сравнение аннотаций кэширования:
| Аннотация | Поведение | Кейс использования |
|---|---|---|
| @Cacheable | Проверяет кэш перед выполнением | Чтение данных, поиск |
| @CachePut | Всегда выполняется, обновляет кэш | Обновление существующих записей |
| @CacheEvict | Удаляет данные из кэша | Удаление записей, очистка устаревших данных |
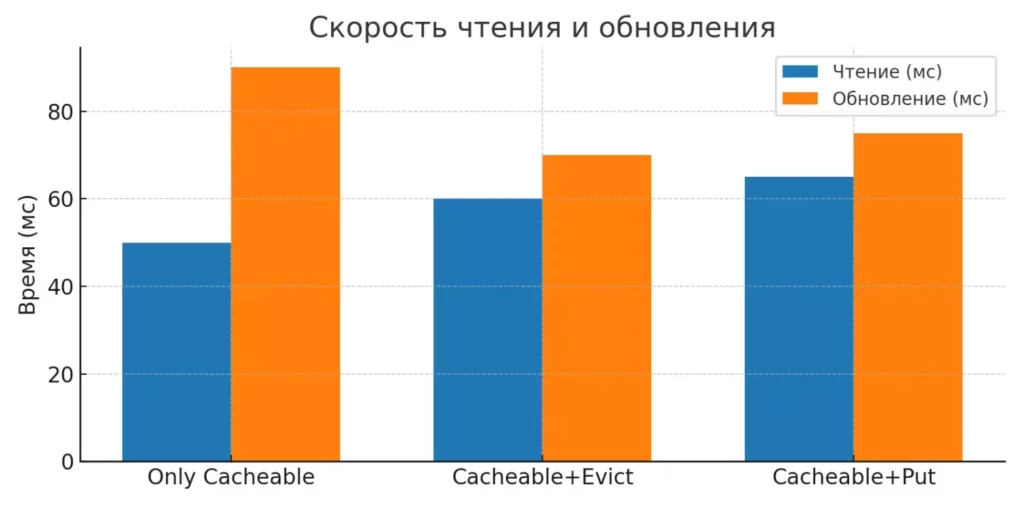
Столбчатая диаграмма сравнивает скорость чтения и обновления данных при разных стратегиях работы с кэшем. Позволяет оценить компромисс между производительностью и актуальностью данных.
Важная особенность Spring Cache — он работает через AOP (Aspect-Oriented Programming), поэтому аннотации действуют только при вызове методов извне класса. Внутренние вызовы методов того же класса не активируют кэширование.
Скриншот показывает «каноническую» форму использования аннотации; визуальный якорь для начинающих.
Как работает CacheManager и какие типы кешей бывают
В основе механизма кэширования Spring лежит CacheManager — центральный компонент, который управляет созданием и конфигурацией кэшей. По умолчанию Spring использует ConcurrentMapCacheManager, который создает кэши на основе ConcurrentHashMap, но мы можем легко настроить собственную конфигурацию.
Пример настройки через Java-конфигурацию:
@Configuration
@EnableCaching
public class CacheConfig {
@Bean
public CacheManager cacheManager() {
SimpleCacheManager cacheManager = new SimpleCacheManager();
cacheManager.setCaches(Arrays.asList(
new ConcurrentMapCache("users"),
new ConcurrentMapCache("products"),
new ConcurrentMapCache("orders")
));
return cacheManager;
}
}
Альтернативный способ через XML-конфигурацию:
| <cache:annotation-driven cache-manager=»cacheManager»/>
<bean id=»cacheManager» class=»org.springframework.cache.support.SimpleCacheManager»> <property name=»caches»> <set> <bean class=»org.springframework.cache.concurrent.ConcurrentMapCache»> <constructor-arg value=»users»/> </bean> </set> </property> </bean> |
Основные типы кэш-менеджеров:
- ConcurrentMapCacheManager — простейший вариант для разработки и тестирования, хранит данные в памяти приложения.
- CompositeCacheManager — позволяет комбинировать несколько кэш-менеджеров с различными стратегиями.
- NoOpCacheManager — используется для отключения кэширования без изменения кода.
- EhCacheCacheManager — интеграция с популярной библиотекой EhCache.
- RedisCacheManager — для работы с Redis в качестве распределенного кэша.
Разграничение кэшей по типам данных помогает оптимизировать производительность и управление памятью. Например, кэш пользователей может иметь долгое время жизни, а кэш актуальных курсов валют — короткое.
Выбор конкретного типа кэша зависит от требований приложения: для простых случаев достаточно встроенного ConcurrentMapCache, для enterprise-решений лучше рассмотреть Redis или Hazelcast.
Когда лучше использовать готовые библиотеки (Guava, EhCache)
Простые решения на основе HashMap хорошо работают для базовых сценариев, но при росте требований к приложению становятся очевидными их ограничения. Отсутствие автоматического управления памятью, невозможность настройки времени жизни записей и примитивные стратегии вытеснения — все это указывает на необходимость перехода к специализированным решениям.
Google Guava предлагает мощный LoadingCache, который элегантно решает большинство задач локального кэширования:
LoadingCache<String, User> userCache = CacheBuilder.newBuilder()
.maximumSize(1000)
.expireAfterWrite(10, TimeUnit.MINUTES)
.build(new CacheLoader<String, User>() {
public User load(String userId) {
return database.findUserById(userId);
}
});
EhCache, в свою очередь, предоставляет enterprise-уровень функциональности с поддержкой персистентности, кластеризации и детальной настройки производительности. Для Spring-приложений интеграция выглядит следующим образом:
@Bean
public CacheManager ehCacheManager() {
EhCacheCacheManager cacheManager = new EhCacheCacheManager();
cacheManager.setCacheManager(ehCacheManagerFactory().getObject());
return cacheManager;
}
Когда объемы данных превышают возможности одного сервера, стоит рассмотреть распределенные решения: Redis для быстрого доступа к данным через сеть, Apache Ignite для in-memory computing, или Hazelcast для построения кластерных кэшей.
Сравнение подходов к кэшированию:
| Решение | Сложность настройки | Производительность | Масштабируемость | Подходит для |
|---|---|---|---|---|
| HashMap/ConcurrentHashMap | Минимальная | Высокая | Ограниченная | Простые случаи, прототипы |
| Google Guava | Низкая | Высокая | Одиночные узлы | Большинство приложений |
| EhCache | Средняя | Высокая | Кластеры | Enterprise-приложения |
| Redis/Hazelcast | Высокая | Средняя | Распределенные системы | Микросервисы, большие нагрузки |
Критерием выбора должна стать не мощность библиотеки, а соответствие реальным потребностям проекта. Во многих случаях Guava Cache покрывает большинство стандартных задач кэширования, предлагая отличный баланс между функциональностью и простотой внедрения
Кэширование на уровне базы данных: пример Oracle
Эффективная архитектура кэширования не ограничивается только уровнем приложения. Современные СУБД предлагают собственные механизмы кэширования, которые могут существенно дополнить или даже заменить кэширование в Java-коде. Oracle Database предоставляет особенно мощный инструмент — RESULT_CACHE, который позволяет кэшировать результаты PL/SQL функций прямо в памяти сервера базы данных.
Классическая PL/SQL функция преобразуется в кэшированную версию добавлением всего одного ключевого слова:
CREATE OR REPLACE FUNCTION GET_COUNTRY_NAME(P_CODE IN VARCHAR2) RETURN VARCHAR2 RESULT_CACHE IS CODE_RESULT VARCHAR2(50); BEGIN SELECT COUNTRY_NAME INTO CODE_RESULT FROM COUNTRIES WHERE COUNTRY_ID = P_CODE; -- Имитация сложных вычислений dbms_lock.sleep(1); RETURN(CODE_RESULT); END;
При первом вызове функция выполняется полностью, но результат сохраняется в специальной области памяти Oracle. Последующие вызовы с теми же параметрами возвращают кэшированный результат мгновенно, минуя выполнение SQL-запросов.
Для более тонкого управления можно использовать директиву RELIES_ON, которая указывает Oracle автоматически очищать кэш при изменении определенных таблиц:
CREATE OR REPLACE FUNCTION GET_USER_PROFILE(USER_ID IN NUMBER) RETURN VARCHAR2 RESULT_CACHE RELIES_ON (USERS, USER_PROFILES) IS -- функция будет автоматически очищена из кэша -- при изменении таблиц USERS или USER_PROFILES
Преимущества и ограничения кэширования в Oracle:
Преимущества:
- Автоматическое управление памятью на уровне СУБД.
- Высокая производительность за счет близости к данным.
- Прозрачность для приложения — никаких изменений в Java-коде.
- Автоматическая инвалидация при изменении базовых таблиц.
Ограничения:
- Привязка к конкретной СУБД (Oracle).
- Ограниченный контроль над политиками кэширования.
- Невозможность использования в распределенных системах.
- Дополнительная нагрузка на сервер базы данных.
Такой подход особенно эффективен для функций, которые часто вызываются с одинаковыми параметрами и обрабатывают относительно стабильные справочные данные.
Ошибки при работе с кэшем и как их избежать
Кэширование может стать источником серьезных проблем, если не учитывать его подводные камни. Мы рассмотрим наиболее распространенные ошибки, которые могут превратить оптимизацию в источник головной боли.
Утечки памяти — классическая проблема самодельных кэшей. Без ограничения размера и механизма автоматической очистки кэш будет расти до исчерпания памяти:
// Опасный код - кэш растет бесконечно private static final Map<String, Object> cache = new ConcurrentHashMap<>(); // Безопасная альтернатива с ограничением размера private static final Cache<String, Object> cache = CacheBuilder.newBuilder() .maximumSize(10000) .expireAfterWrite(1, TimeUnit.HOURS) .build();
Конфликты версий данных возникают, когда кэш содержит устаревшую информацию. Особенно критично это для данных, которые могут изменяться в других частях системы или внешними процессами. Решение — продуманная стратегия инвалидации кэша при обновлении данных.
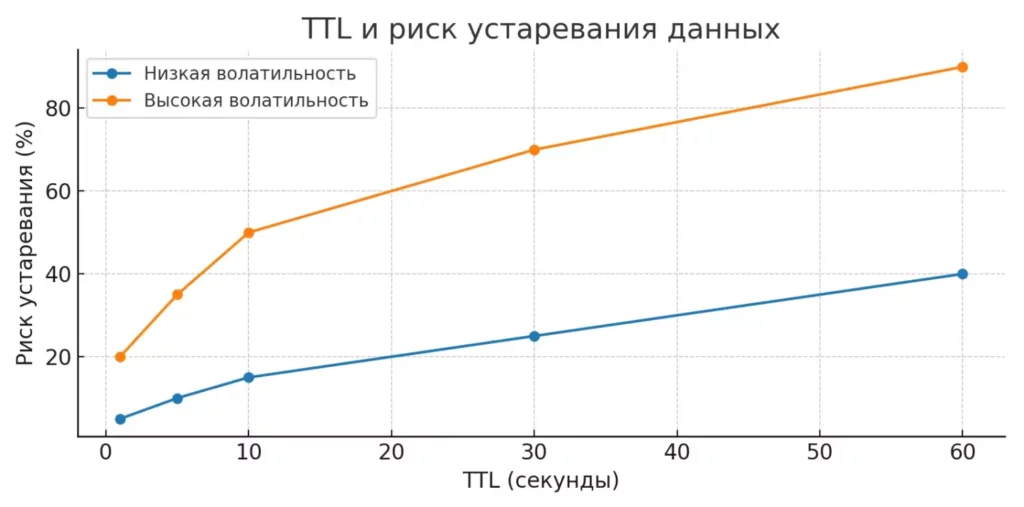
График демонстрирует, как выбор времени жизни данных влияет на риск работы с устаревшей информацией при разной скорости изменения данных. Видно, что для «быстрых» данных риск растёт намного быстрее.
Неправильное время жизни (TTL) данных может привести к двум крайностям: слишком короткий TTL нивелирует преимущества кэширования, слишком длинный — приводит к работе с устаревшими данными. Время жизни должно соответствовать частоте изменения кэшируемых данных.
Отсутствие мониторинга делает кэш «черным ящиком». Без метрик hit ratio, размера кэша и времени выполнения запросов невозможно оценить эффективность кэширования и выявить проблемы.
Основные рекомендации по избежанию ошибок:
- Всегда устанавливайте ограничения на размер кэша и время жизни данных.
- Используйте слабые ссылки (WeakReference) для кэширования объектов, которые могут быть собраны сборщиком мусора.
- Реализуйте стратегию инвалидации кэша при изменении базовых данных.
- Добавьте логирование и метрики для мониторинга производительности кэша.
- Избегайте кэширования изменяемых объектов без создания их копий.
- Не кэшируйте null-значения без явной необходимости — это может маскировать ошибки.
- Тестируйте поведение приложения при «холодном» кэше (когда он пуст).
Помните: кэширование должно улучшать производительность, а не создавать дополнительную сложность в системе.
Выводы и рекомендации для начинающих Java-разработчиков
Путешествие в мир кэширования лучше начинать с простых решений, постепенно наращивая сложность по мере роста требований к приложению. Мы рекомендуем следующий поэтапный подход к освоению технологий кэширования.
Начальный этап:
Изучите принципы работы кэша на простых примерах с HashMap или ConcurrentHashMap. Это поможет понять базовую логику и потенциальные проблемы. Экспериментируйте с созданием собственного кэша — даже если вы не будете использовать его в production, понимание внутренних механизмов окажется бесценным.
Переход к Spring:
Как только освоите основы, переходите к аннотациям Spring Cache. Начните с @Cacheable для простых случаев чтения данных, затем добавьте @CacheEvict для управления жизненным циклом кэша. Этот этап покроет большинство практических потребностей в кэшировании.
Развитие архитектуры:
При росте нагрузки рассмотрите специализированные библиотеки. Google Guava Cache станет отличным следующим шагом благодаря простоте интеграции и богатым возможностям настройки. Для enterprise-приложений изучите EhCache или Redis.
- Ключевые принципы для успешного внедрения:
- Не переусложняйте архитектуру преждевременно — начинайте с простейших решений.
- Всегда измеряйте производительность до и после внедрения кэширования.
- Уделяйте особое внимание стратегии инвалидации данных.
- Документируйте решения по кэшированию для команды.
- Регулярно мониторьте метрики кэша в production.
Заключение
Кэширование — это мощный инструмент оптимизации, но он требует вдумчивого подхода. Правильно реализованный кэш может увеличить производительность в разы, неправильный — создать трудно диагностируемые проблемы. Начинайте с малого, изучайте поведение вашего приложения и постепенно наращивайте сложность решений. Именно такой подход позволит вам стать экспертом в области кэширования и создавать действительно быстрые и надежные Java-приложения. Подведем итоги:
- Кэширование — это ключ к высокой скорости работы приложений. Оно сокращает время отклика и снижает нагрузку на ресурсы.
- Spring упрощает внедрение кэша с помощью аннотаций. Это экономит время и упрощает поддержку кода.
- Разные библиотеки решают разные задачи. Guava подойдёт для локального кэша, Redis — для распределённых систем.
- Кэширование в СУБД полезно для редко изменяемых данных. Это разгружает приложение и ускоряет запросы.
- Контроль размера, времени жизни и очистки кэша обязателен. Это предотвращает утечки памяти и устаревшие данные.
Если вы только начинаете осваивать Java-разработку, рекомендуем обратить внимание на подборку курсов по Java. В этих курсах есть как теоретическая, так и практическая часть, что позволит вам быстро перейти от понимания принципов к их применению в проектах.
Рекомендуем посмотреть курсы по Java
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Java-разработчик
|
Eduson Academy
112 отзывов
|
Цена
133 900 ₽
|
От
11 158 ₽/мес
0% на 24 месяца
15 476 ₽/мес
|
Длительность
8 месяцев
|
Старт
скоро
Пн,Ср, 19:00-22:00
|
Подробнее |
|
Профессия Java-разработчик
|
Skillbox
226 отзывов
|
Цена
190 971 ₽
381 943 ₽
Ещё -20% по промокоду
|
От
5 617 ₽/мес
Это минимальный ежемесячный платеж. От Skillbox без %.
8 692 ₽/мес
|
Длительность
9 месяцев
Эта длительность обучения очень примерная, т.к. все занятия в записи (но преподаватели ежедневно проверяют ДЗ). Так что можно заниматься более интенсивно и быстрее пройти курс или наоборот.
|
Старт
15 марта
|
Подробнее |
|
Java-разработчик с нуля
|
Нетология
46 отзывов
|
Цена
143 700 ₽
266 020 ₽
с промокодом kursy-online
|
От
4 433 ₽/мес
Без переплат на 2 года.
|
Длительность
14 месяцев
|
Старт
16 марта
|
Подробнее |
|
Java-разработчик
|
Академия Синергия
36 отзывов
|
Цена
103 236 ₽
|
От
4 302 ₽/мес
0% на 24 месяца
|
Длительность
6 месяцев
|
Старт
17 марта
|
Подробнее |
|
Java-разработка
|
Moscow Digital Academy
66 отзывов
|
Цена
132 720 ₽
165 792 ₽
|
От
5 530 ₽/мес
на 12 месяца.
6 908 ₽/мес
|
Длительность
12 месяцев
|
Старт
в любое время
|
Подробнее |

Skillbox vs ProductStar: где продакт-трек более прикладной (кейсы, метрики, решения)
Skillbox или ProductStar — где на самом деле больше практики для продакт-менеджера? Разбираем формат кейсов, работу с метриками, стажировки и портфолио, чтобы понять, какой курс действительно готовит к работе product manager.

Skypro vs ProductStar: куда идти аналитику, чтобы стать продактом — траектория и кейсы
Если вы аналитик и хотите перейти в продакт-менеджмент, но не знаете, с чего начать, эта статья для вас. Мы расскажем, какие шаги и курсы помогут вам освоить нужные навыки, чтобы успешно перейти в продуктовую роль. Задайтесь вопросом: готовы ли вы на решение проблем, а не просто на анализ данных?

Собеседование Devops Junior и Middle: актуальные вопросы и темы 2026 года
Вопросы на собеседовании DevOps могут сильно различаться в зависимости от уровня кандидата. Какие навыки и знания проверяют у Junior и Middle в 2026 году? Мы расскажем, как подготовиться к собеседованию и что важно знать для успешного прохождения интервью.

Собеседование по Python: частые вопросы и как на них отвечать
Готовитесь к техническому интервью и хотите понять, какие вопросы на собеседование Python разработчик слышит чаще всего? Разбираем реальные примеры задач, вопросы для junior, middle и senior, а также типичные ошибки кандидатов и стратегию подготовки.