Как работать с модулем random в Python
Модуль random в Python — это своего рода цифровой кубик с бесконечным количеством граней, предназначенный для генерации случайных чисел и значений. Казалось бы, что может быть проще — дай мне число! Однако за кулисами этой простоты скрывается любопытный парадокс: в мире детерминированных компьютерных систем настоящей случайности не существует. Вместо этого Python, как и другие языки программирования, использует псевдослучайные числа — математически сгенерированные значения, которые лишь имитируют случайность.

В основе этой цифровой иллюзии лежит алгоритм под названием «Вихрь Мерсенна» — криптографический монстр, который выдает последовательности чисел, выглядящие случайными для невооруженного глаза (и даже для некоторых статистических тестов). Области применения этого модуля поражают своим разнообразием: от банальных игр типа «угадай число» до серьезной защиты данных, от имитации физических процессов до обучения искусственного интеллекта, который, возможно, однажды заменит меня на этой работе.
- Основные принципы работы
- Импортирование модуля
- Генерация случайных чисел
- Работа с последовательностями
- Практическое применение
- Заключение
- Рекомендуем посмотреть курсы по Python
Основные принципы работы
В отличие от истинной случайности (которую можно получить, например, измеряя радиоактивный распад или атмосферный шум), модуль random в Python работает строго детерминированно. Он использует алгоритм «Вихрь Мерсенна», который, получив начальное значение (так называемый «seed«), последовательно преобразует его по сложным математическим формулам. Результаты выглядят случайными, хотя на самом деле — это хитрая математическая иллюзия.
Вихрь Мерсенна. Скриншот из статьи в Википедии.
Интересный нюанс: если задать одно и то же начальное значение, Python послушно выдаст одну и ту же «случайную» последовательность. Это как машина времени для случайных чисел — вы всегда можете вернуться к тому же самому «случайному» результату. Для разработчиков это оказывается неожиданно полезной функцией при тестировании приложений и отладке кода.
import random # Зафиксируем начальное значение random.seed(42) print(random.random()) # Всегда выдаст 0.6394267984578837 print(random.random()) # Всегда выдаст 0.025010755222666936 # А теперь с другим начальным значением random.seed(13) print(random.random()) # Всегда выдаст 0.2613830424390329
Если не указать seed явно, Python возьмёт текущее системное время (в миллисекундах) — и это обеспечит достаточно «случайные» результаты для большинства приложений. Хотя, разумеется, для криптографических целей этот алгоритм использовать нельзя — хакеры давно научились предсказывать такие последовательности. Для серьёзной безопасности существует специализированный модуль secrets, но это уже совсем другая история.
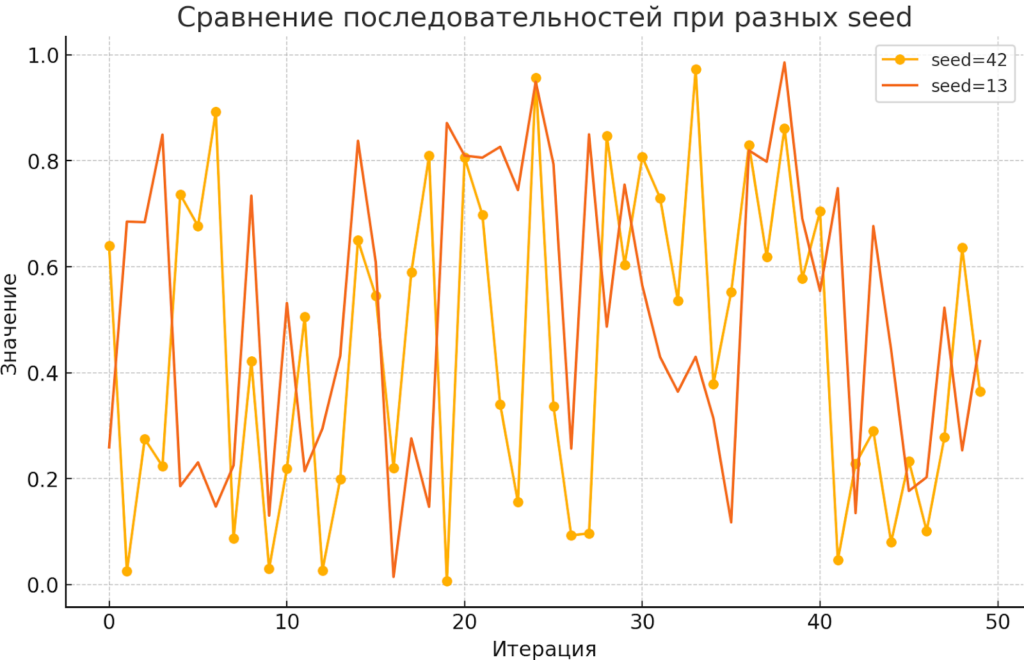
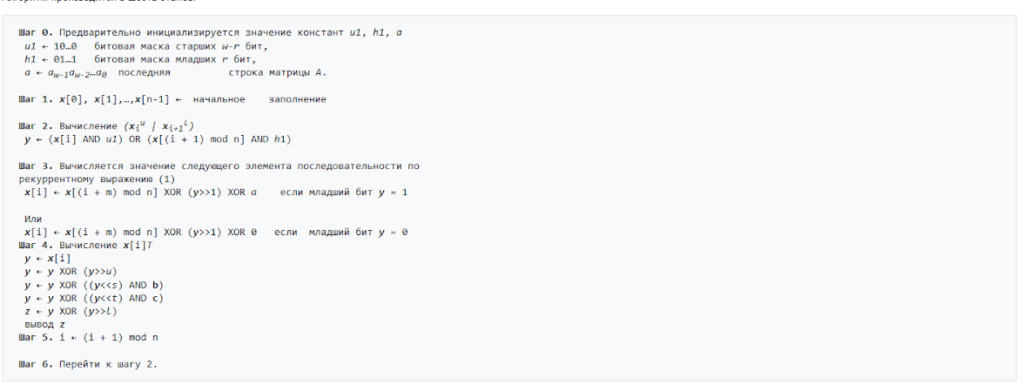
Диаграмма наглядно демонстрирует, что при фиксированном seed последовательность полностью воспроизводима (точки одного цвета повторяются при каждом запуске), а изменение seed приводит к совершенно другой псевдослучайной последовательности. Это подчёркивает важность параметра seed для тестирования и отладки кода.
Импортирование модуля
Импортирование модулей в Python — это как выбор пиццы: можно взять целиком, можно только определённые кусочки, а можно — все ингредиенты россыпью (хотя последнее не рекомендуется диетологами кода). С модулем random работает та же логика.
Самый распространённый и безопасный способ — импортировать модуль целиком:
import random # Теперь обращаемся ко всем функциям через префикс random x = random.randint(1, 10)
Этот подход хорош своей очевидностью: вы всегда знаете, откуда пришла функция. В больших проектах, где может быть десяток модулей с похожими именами функций, такая ясность — на вес золота.
Для ленивых программистов существует импорт отдельных функций:
from random import randint, choice # Используем функции напрямую, без префикса x = randint(1, 10) y = choice(['яблоко', 'груша', 'банан'])
И, наконец, ядерный вариант, который превращает ваш код в минное поле для будущего себя и коллег:
from random import * # Откуда эти функции? Кто это знает? Точно не тот, кто будет читать код через полгода x = randint(1, 10)
Генерация случайных чисел
Целые числа
Целые числа — это фундамент цифрового мира, эдакие атомы вычислений. Модуль random предлагает два основных способа их получения, и между ними есть тонкая, но важная разница — примерно как между «включительно» и «исключительно» в математических неравенствах, которые все мы так «любили» в школе.
Функция random.randint(a, b) — самый интуитивно понятный инструмент. Она генерирует случайное целое число в диапазоне от a до b, включая оба граничных значения. То есть, если вы напишете random.randint(1, 6), это будет эквивалентно броску игрального кубика — любое число от 1 до 6, где все значения равновероятны.
import random
# Бросаем кубик
dice_roll = random.randint(1, 6)
print(f"Выпало {dice_roll}!")
# Генерируем случайный год 20 века
random_year = random.randint(1901, 2000)
print(f"Случайный год 20 века: {random_year}")
Её старший брат, random.randrange(start, stop, step), работает несколько иначе и больше напоминает генерацию случайного элемента из функции range(). Она не включает верхнюю границу и позволяет указать шаг — весьма полезно, если вам нужны, скажем, только чётные или нечётные числа.
# Случайное нечётное число от 1 до 99
odd_number = random.randrange(1, 100, 2)
print(f"Случайное нечётное число: {odd_number}")
# Случайный год из високосных годов 20 века
leap_year = random.randrange(1904, 2001, 4)
print(f"Случайный високосный год: {leap_year}")
В реальных проектах randint чаще используется для простых сценариев (как в играх или при генерации тестовых данных), а randrange — для более сложных случаев, требующих точной настройки диапазона. Например, если вы разрабатываете систему распределения нагрузки на сервера, randrange позволит равномерно раскидывать запросы по доступным IP-адресам с нужным шагом.
Числа с плавающей точкой
Если целые числа — это атомы, то числа с плавающей точкой — это субатомные частицы мира вычислений: менее очевидные, но более гибкие и с более странным поведением (особенно когда дело касается операций типа 0.1 + 0.2 != 0.3, но это уже отдельная трагикомедия).
Функция random.random() — это самый базовый инструмент, выдающий случайное число с плавающей точкой в диапазоне [0.0, 1.0), где верхняя граница не включается. Это как бросить дротик в единичный отрезок, но чтобы он никогда не попадал точно в 1.
# Получаем случайное число от 0 до 1
r = random.random()
print(f"Случайное число между 0 и 1: {r}")
# Используем для создания процентной вероятности
if random.random() < 0.75:
print("Это сообщение появляется с вероятностью 75%")
Когда вам нужен произвольный диапазон, на помощь приходит random.uniform(a, b), генерирующая число в диапазоне [a, b], включая обе границы. Это как если бы вы могли нормализовать тот самый бросок дротика на любой числовой отрезок.
# Случайная температура в Москве зимой (от -30 до +5 градусов)
temp = random.uniform(-30, 5)
print(f"Сегодня на улице {temp:.1f}°C")
# Случайные координаты на карте в заданном регионе
lat = random.uniform(55.5, 56.0)
lon = random.uniform(37.3, 37.8)
print(f"Случайная точка в Москве: {lat:.6f}, {lon:.6f}")
Разница между этими функциями очевидна: random() всегда возвращает число от 0 до 1, тогда как uniform() позволяет указать любой диапазон. В реальных проектах random() часто используется для имитации вероятностей (как в примере выше), а uniform() — для генерации реалистичных значений, например, в симуляциях физических процессов или при создании синтетических данных для машинного обучения.
Специальные распределения
Если обычные случайные числа — это попытка имитировать равномерное распределение вероятностей (как в честном кубике или монетке), то специальные распределения — это попытка смоделировать более сложные процессы реального мира, где вероятности редко бывают равномерными.
Функция random.normalvariate(mu, sigma) реализует нормальное (гауссово) распределение, где mu — это среднее значение, а sigma — стандартное отклонение. В природе это распределение встречается повсеместно: от роста людей до погрешностей измерений. Представьте, что вы бросаете дротики в мишень — большинство попадет около центра, а чем дальше, тем попаданий меньше.
# Генерируем рост случайного взрослого человека в сантиметрах
# (среднее 170, стандартное отклонение 15)
height = random.normalvariate(170, 15)
print(f"Рост случайного человека: {height:.1f} см")
random.expovariate(lambd) даёт экспоненциальное распределение с параметром lambd (который равен 1/среднему). Это распределение хорошо описывает время между независимыми событиями, как время между звонками в колл-центр или между автомобилями на пустой дороге.
# Время (в минутах) до следующего звонка в службу поддержки
# со средним интервалом 5 минут
next_call = random.expovariate(1/5)
print(f"Следующий звонок через {next_call:.2f} минут")
random.lognormvariate(mu, sigma) реализует логнормальное распределение. Оно отлично подходит для моделирования величин, которые не могут быть отрицательными и имеют «длинный хвост» больших значений. Например, доходы населения часто следуют этому распределению — большинство зарабатывает немного, но есть малое количество людей с очень высокими доходами.
# Моделируем годовой доход в тысячах долларов
# (параметры подобраны для реалистичного распределения)
income = random.lognormvariate(3.5, 1.2)
print(f"Годовой доход: ${income:.2f}K")
| Распределение | Когда использовать | Типичные применения |
|---|---|---|
| Нормальное | Для величин, которые имеют «колоколообразное» распределение вероятностей вокруг среднего | Рост и вес людей, ошибки измерений, IQ |
| Экспоненциальное | Для моделирования времени между независимыми событиями | Время между клиентами в очереди, время жизни электронных компонентов |
| Логнормальное | Для величин с «длинным хвостом», которые не могут быть отрицательными | Доходы населения, цены акций, размеры месторождений |
В реальных проектах эти функции незаменимы для моделирования сложных систем — от прогнозирования загрузки серверов до симуляции финансовых рынков или имитации поведения пользователей на сайте. А всего-то делов — подобрать правильное распределение и его параметры.
Работа с последовательностями
Выбор случайного элемента
Если случайные числа — это удел математиков и статистиков, то выбор случайного элемента из коллекции — это повседневная рутина практически каждого программиста. Модуль random предлагает целый арсенал инструментов для решения этой, казалось бы, тривиальной задачи — с нюансами, о которых большинство даже не подозревает.
Функция random.choice(seq) — самый простой и интуитивно понятный инструмент: она выбирает один случайный элемент из последовательности. Это может быть список, строка, кортеж — любой итерируемый объект с возможностью доступа по индексу. Представьте, что вы вслепую вытаскиваете карту из колоды — именно так работает choice().
import random
# Выбираем случайную карту
cards = ['2♠', '3♠', '4♠', '5♠', '6♠', '7♠', '8♠', '9♠', '10♠', 'J♠', 'Q♠', 'K♠', 'A♠']
card = random.choice(cards)
print(f"Вы вытянули карту: {card}")
# Выбираем случайную букву из строки
alphabet = "абвгдеёжзийклмнопрстуфхцчшщъыьэюя"
letter = random.choice(alphabet)
print(f"Случайная буква: {letter}")
Но что если вам нужно выбрать не один, а несколько элементов? На помощь приходит random.choices(population, weights, k), которая выбирает k элементов из популяции с возможностью повторения. Параметр weights позволяет задать вес каждого элемента, влияя на вероятность его выбора — как если бы некоторые карты в колоде были «липкими» и вытягивались чаще.
# Моделируем 10 бросков нечестной кости, где шестерка выпадает вдвое чаще
dice_results = random.choices([1, 2, 3, 4, 5, 6], weights=[1, 1, 1, 1, 1, 2], k=10)
print(f"Результаты 10 бросков: {dice_results}")
# Генерируем случайную строку ДНК длиной 20 нуклеотидов,
# где вероятности нуклеотидов соответствуют их частоте в геноме человека
dna = ''.join(random.choices('ACGT', weights=[0.3, 0.2, 0.2, 0.3], k=20))
print(f"Случайная последовательность ДНК: {dna}")
В реальных проектах choice() часто используется для простых решений (например, выбор случайного баннера на сайте), а choices() — для более сложных сценариев, требующих взвешенного выбора (таких как A/B тестирование или моделирование генетических алгоритмов).
Обратите внимание, что choices() — относительно новый член семейства Python (появился в версии 3.6), поэтому в старом коде вы можете встретить самодельные реализации этой функциональности с использованием choice() в цикле или комбинации random() с бинарным поиском в накопленных вероятностях — эдакие динозавры кода, которые всё ещё бродят в legacy-проектах.
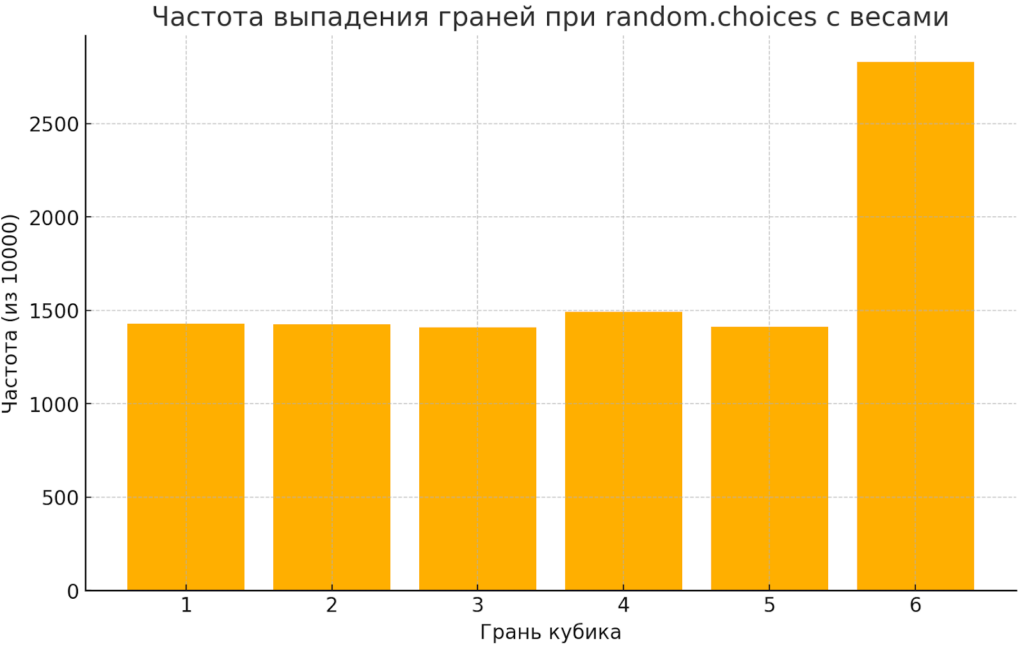
Частоты выпадения граней игрального кубика (1–6) после 10 000 выборок, где грань 6 имеет в два раза больший вес, чем остальные.
Перемешивание элементов
Иногда нам нужно не просто выбрать что-то случайно, а полностью перетасовать колоду или выбрать несколько уникальных элементов. И здесь модуль random снова приходит на помощь с двумя мощными функциями.
Функция random.shuffle(seq) перемешивает все элементы последовательности на месте. Это как если бы вы тщательно перетасовали колоду карт — после этой операции порядок элементов становится случайным, но сами элементы остаются теми же.
import random
# Перемешиваем колоду карт
deck = ['2♠', '3♠', '4♠', '5♠', '6♠', '7♠', '8♠', '9♠', '10♠', 'J♠', 'Q♠', 'K♠', 'A♠']
random.shuffle(deck)
print(f"Перемешанная колода: {deck}")
# Создаем случайный плейлист из списка песен
playlist = ['Highway to Hell', 'Stairway to Heaven', 'Sweet Child o\' Mine', 'Bohemian Rhapsody', 'Smells Like Teen Spirit']
random.shuffle(playlist)
print(f"Случайный плейлист на сегодня: {playlist}")
Важный нюанс: shuffle() изменяет оригинальный список, а не создает новый. Если вам нужно сохранить исходный порядок, сначала создайте копию списка:
original_list = [1, 2, 3, 4, 5] shuffled_list = original_list.copy() # Создаем копию random.shuffle(shuffled_list) # Перемешиваем копию
Функция random.sample(population, k) — это как выбор лотерейных билетов: она выбирает k уникальных элементов из популяции без повторений. В отличие от shuffle(), она не меняет оригинальную последовательность, а возвращает новый список.
# Выбираем 5 уникальных случайных чисел от 1 до 90 (как в лото)
lottery_numbers = random.sample(range(1, 91), 5)
print(f"Выигрышные номера лотереи: {lottery_numbers}")
# Выбираем 3 случайных участника из списка для тестирования новой функции
users = ['Алексей', 'Борис', 'Вадим', 'Галина', 'Дмитрий', 'Елена', 'Жанна']
beta_testers = random.sample(users, 3)
print(f"Бета-тестеры: {beta_testers}")
Главное отличие между shuffle() и sample(): первая функция меняет порядок всех элементов на месте, вторая — выбирает подмножество элементов, не меняя оригинал. Это как разница между перетасовкой колоды и выбором нескольких карт из неё.
В реальных проектах shuffle() часто используется для рандомизации данных при машинном обучении или создания случайных последовательностей (например, генерации тестов с разным порядком вопросов), а sample() — для случайной выборки из большого набора данных или для реализации алгоритмов типа бутстрэппинга в статистике.
Практическое применение
Генерация случайных паролей
Когда речь заходит о безопасности, случайность становится нашим лучшим другом. Хороший пароль должен быть непредсказуемым, а значит — случайным. Вот пример генератора паролей с гибкими настройками:
В приведенном коде есть несколько интересных моментов:
- Мы используем модуль string, который предоставляет наборы символов разных типов.
- Функция не просто генерирует случайную строку, но и гарантирует, что в пароле есть хотя бы один символ каждого запрошенного типа — это важно для соответствия распространенным требованиям к паролям.
- Мы заменяем случайные символы, если нужного типа не оказалось в первоначально сгенерированном пароле.
Такой генератор можно легко интегрировать в веб-приложение для регистрации пользователей или использовать как часть системы управления доступом.
Важное замечание: хотя этот генератор достаточно хорош для большинства обычных приложений, для действительно критичных систем вам стоит использовать модуль secrets вместо random, который специально разработан для криптографических применений.
import random import string
def generate_password(length=12, include_uppercase=True, include_digits=True, include_special=True): """ Генерирует случайный пароль заданной длины и сложности.
Args:
length (int): Длина пароля (по умолчанию 12)
include_uppercase (bool): Включать ли заглавные буквы (по умолчанию True)
include_digits (bool): Включать ли цифры (по умолчанию True)
include_special (bool): Включать ли специальные символы (по умолчанию True)
Returns:
str: Сгенерированный пароль
"""
# Начинаем с маленьких букв
chars = string.ascii_lowercase
# Добавляем другие типы символов в соответствии с параметрами
if include_uppercase:
chars += string.ascii_uppercase
if include_digits:
chars += string.digits
if include_special:
chars += string.punctuation
# Проверяем, чтобы длина была достаточной
if length < 4:
length = 4
# Генерируем пароль
password = ''.join(random.choice(chars) for _ in range(length))
# Убеждаемся, что пароль содержит хотя бы по одному символу каждого запрошенного типа
if include_uppercase and not any(c.isupper() for c in password):
# Заменяем случайный символ на заглавную букву
replace_idx = random.randint(0, length - 1)
uppercase_char = random.choice(string.ascii_uppercase)
password = password[:replace_idx] + uppercase_char + password[replace_idx+1:]
if include_digits and not any(c.isdigit() for c in password):
# Заменяем случайный символ на цифру
replace_idx = random.randint(0, length - 1)
digit_char = random.choice(string.digits)
password = password[:replace_idx] + digit_char + password[replace_idx+1:]
if include_special and not any(c in string.punctuation for c in password):
# Заменяем случайный символ на специальный
replace_idx = random.randint(0, length - 1)
special_char = random.choice(string.punctuation)
password = password[:replace_idx] + special_char + password[replace_idx+1:]
return password
Примеры использования
if name == "main": # Простой пароль из 8 символов (только маленькие буквы) simple_password = generate_password(8, False, False, False) print(f"Простой пароль: {simple_password}")
# Стандартный пароль (12 символов, все типы)
standard_password = generate_password()
print(f"Стандартный пароль: {standard_password}")
# Сложный пароль из 16 символов
complex_password = generate_password(16)
print(f"Сложный пароль: {complex_password}")
# Пароль для числовой системы (только цифры)
numeric_password = generate_password(6, False, True, False)
print(f"Числовой пароль: {numeric_password}")
Создание случайных аватарок
Если вы когда-нибудь регистрировались на GitHub, вы наверняка заметили, что система автоматически генерирует для вас случайную пиксельную аватарку. Давайте создадим нечто подобное с помощью random и библиотеки Pillow для работы с изображениями.
Этот код генерирует симметричные пиксельные аватарки с случайными цветами, что делает их узнаваемыми и уникальными. Симметрия достигается путем создания только половины изображения и зеркального отражения второй половины — изящный трюк, который делает аватарки более привлекательными.
Несколько интересных деталей:
- Мы используем random не только для выбора, какие пиксели закрашивать, но и для определения основного цвета и его вариаций.
- Мы ограничиваем диапазон случайных цветов, чтобы избежать слишком темных или слишком светлых оттенков, которые будут плохо видны.
- Мы добавляем более темную рамку для визуальной завершенности.
Такой генератор аватарок можно использовать в любой системе, где пользователям нужны уникальные изображения профиля по умолчанию. Вы даже можете модифицировать его, добавив больше цветовых вариаций или изменив алгоритм генерации узора.
Если вы хотите сделать генератор еще более продвинутым, можно добавить возможность создания аватарок, основанных на уникальном идентификаторе пользователя (например, его имени пользователя или email). Таким образом, один и тот же пользователь всегда будет получать одну и ту же аватарку — как это реализовано в Gravatar.
from PIL import Image, ImageDraw import random import os
def generate_avatar(size=100, pixel_size=20, save_path=None): """ Генерирует случайную пиксельную аватарку в стиле GitHub.
Args:
size (int): Размер изображения в пикселях (по умолчанию 100)
pixel_size (int): Размер каждого пикселя (по умолчанию 20)
save_path (str): Путь для сохранения файла (по умолчанию None - не сохранять)
Returns:
PIL.Image.Image: Объект изображения
"""
# Убеждаемся, что size делится на pixel_size
if size % pixel_size != 0:
size = (size // pixel_size) * pixel_size
# Определяем, сколько пикселей будет в нашей сетке
grid_size = size // pixel_size
# Создаем новое изображение с белым фоном
image = Image.new('RGB', (size, size), color='white')
draw = ImageDraw.Draw(image)
# Генерируем основной цвет аватарки (не слишком темный)
main_color_r = random.randint(30, 230)
main_color_g = random.randint(30, 230)
main_color_b = random.randint(30, 230)
main_color = (main_color_r, main_color_g, main_color_b)
# Делаем более темную версию для вариаций
darker_color = (max(0, main_color_r - 50),
max(0, main_color_g - 50),
max(0, main_color_b - 50))
# Создаем матрицу для половины пикселей (будет зеркально отражена)
half_grid = grid_size // 2
pixel_matrix = []
# Заполняем первую половину матрицы
for y in range(grid_size):
row = []
for x in range(half_grid):
# С вероятностью 50% закрашиваем пиксель
if random.random() > 0.5:
# С вероятностью 30% используем темный вариант цвета
if random.random() < 0.3:
row.append(darker_color)
else:
row.append(main_color)
else:
row.append(None) # Пустой пиксель (будет белым)
pixel_matrix.append(row)
# Отрисовываем пиксели с зеркальным отражением для симметрии
for y in range(grid_size):
for x in range(grid_size):
# Определяем, какой цвет использовать
if x < half_grid:
color = pixel_matrix[y][x]
else:
# Зеркально отражаем для правой половины
mirror_x = grid_size - x - 1
color = pixel_matrix[y][mirror_x]
# Если цвет определен, рисуем пиксель
if color:
draw.rectangle(
[(x * pixel_size, y * pixel_size),
((x + 1) * pixel_size - 1, (y + 1) * pixel_size - 1)],
fill=color
)
# Добавляем рамку
border_color = (max(0, main_color_r - 80),
max(0, main_color_g - 80),
max(0, main_color_b - 80))
draw.rectangle([(0, 0), (size-1, size-1)], outline=border_color, width=2)
# Сохраняем изображение, если указан путь
if save_path:
image.save(save_path)
print(f"Аватарка сохранена по пути: {save_path}")
return image
Пример использования
if name == "main": # Создаем директорию для аватарок, если её нет avatars_dir = "avatars" if not os.path.exists(avatars_dir): os.makedirs(avatars_dir)
# Генерируем 5 случайных аватарок
for i in range(5):
avatar_path = os.path.join(avatars_dir, f"avatar_{i+1}.png")
generate_avatar(save_path=avatar_path)
Игра «Угадай число»
А теперь перейдем к классике жанра — консольной игре «Угадай число». Это, пожалуй, первый проект, который делает каждый начинающий программист, и одновременно прекрасный пример использования модуля random в интерактивном приложении.
Игра проста: компьютер загадывает число, а пользователь пытается его угадать, получая подсказки «больше» или «меньше» после каждой попытки. Несмотря на кажущуюся простоту, в этой игре можно продемонстрировать множество важных программистских концепций: циклы, условия, обработку ввода, управление игровым состоянием и, конечно же, генерацию случайных чисел.
В представленной реализации есть несколько интересных особенностей:
- Мы добавили немного «характера» игре: компьютер «задумывается» над числом, выводя точки с задержкой, что создает иллюзию размышления.
- В игре ведется статистика — число попыток и затраченное время, что добавляет соревновательный элемент при повторных прохождениях.
- История догадок отображается после игры, позволяя пользователю проанализировать свою стратегию.
- Реализована защита от неверного ввода — игра не ломается, если пользователь введет буквы вместо цифр.
Эта игра может стать отличной основой для более сложных проектов. Например, вы можете добавить:
- Разные уровни сложности (изменение диапазона чисел и количества попыток);
- Таблицу рекордов;
- Режим «компьютер угадывает число пользователя», где вы можете реализовать разные алгоритмы поиска (например, бинарный поиск);
- Графический интерфейс с помощью Tkinter или Pygame.
В контексте модуля random эта игра показывает, как простая функция randint() может стать основой для увлекательного интерактивного приложения. Кроме того, она наглядно демонстрирует важность начального значения (seed) — если бы мы установили фиксированное начальное значение, игра загадывала бы одно и то же число при каждом запуске, что не очень интересно.
import random import time
def guess_the_number(): """ Игра "Угадай число" - классический пример использования модуля random. Компьютер загадывает случайное число, а пользователь пытается его угадать. """ # Настройки игры min_number = 1 max_number = 100 max_attempts = 10
print("\n" + "=" * 40)
print(f"{'ИГРА «УГАДАЙ ЧИСЛО»':^40}")
print("=" * 40)
print(f"Я загадал число от {min_number} до {max_number}.")
print(f"У тебя есть {max_attempts} попыток, чтобы его угадать.")
print("=" * 40)
# Загадываем число
secret_number = random.randint(min_number, max_number)
# Немного искусственной "задумчивости"
print("Думаю над числом", end="")
for _ in range(3):
time.sleep(0.5)
print(".", end="", flush=True)
print("\nГотово! Число загадано.")
# Статистика игры
attempts = 0
start_time = time.time()
guesses = []
# Основной игровой цикл
while attempts < max_attempts:
try:
# Получаем догадку пользователя
guess = input(f"\nПопытка {attempts + 1}/{max_attempts}. Введите число: ")
guess = int(guess)
# Проверяем, что число в допустимом диапазоне
if guess < min_number or guess > max_number:
print(f"Пожалуйста, введите число от {min_number} до {max_number}.")
continue
# Увеличиваем счетчик попыток и сохраняем догадку
attempts += 1
guesses.append(guess)
# Проверяем догадку
if guess < secret_number:
print("Мое число БОЛЬШЕ.")
elif guess > secret_number:
print("Мое число МЕНЬШЕ.")
else:
# Победа!
end_time = time.time()
print("\n" + "*" * 40)
print(f"{'ПОЗДРАВЛЯЮ! ВЫ УГАДАЛИ!':^40}")
print("*" * 40)
print(f"Загаданное число: {secret_number}")
print(f"Количество попыток: {attempts}")
print(f"Затраченное время: {end_time - start_time:.1f} секунд")
# Показываем историю догадок
print("\nВаши догадки:", end=" ")
for i, g in enumerate(guesses):
marker = "✓" if g == secret_number else "✗"
print(f"{g}{marker}", end=" ")
print("\n")
return True
except ValueError:
print("Пожалуйста, введите корректное целое число.")
# Если дошли сюда, значит попытки закончились
print("\n" + "x" * 40)
print(f"{'ИГРА ОКОНЧЕНА':^40}")
print("x" * 40)
print(f"Загаданное число было: {secret_number}")
print("У вас закончились попытки.")
# Показываем историю догадок
print("\nВаши догадки:", end=" ")
for g in guesses:
print(g, end=" ")
print("\n")
return False
def play_again(): """Спрашивает пользователя, хочет ли он сыграть еще раз.""" response = input("Хотите сыграть еще раз? (да/нет): ").lower() return response in ["да", "д", "yes", "y"]
Запуск игры
if name == "main": while True: guess_the_number() if not play_again(): print("Спасибо за игру! До новых встреч!") break
Заключение
Модуль random в Python — это как швейцарский нож для работы со случайностью: компактный, многофункциональный и поразительно полезный. От простой генерации чисел до сложного моделирования реальных процессов, от игр до критически важных приложений — этот модуль находит применение практически в любой области программирования.
- Модуль random в Python — это универсальный инструмент для работы со случайностью, который подходит для множества задач в программировании.
- Он используется в генерации случайных чисел, работе с последовательностями и распределениями, а также для моделирования реальных процессов.
- Мы рассмотрели основные функции модуля, включая генерацию случайных чисел, выбор элементов и работу с распределениями.
- Правильное использование случайности может улучшить приложения, сделав их более интересными, устойчивыми и реалистичными.
- Модуль random становится верным помощником в решении множества задач, от генерации паролей до моделирования физических процессов.
- Возможности модуля неограниченны, и каждый разработчик может найти для него свой уникальный способ применения.
Хотите освоить новую востребованную профессию? Тогда изучите курсы Python разработчика и станьте классным айтишником уже сегодня!
Рекомендуем посмотреть курсы по Python
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Профессия Python-разработчик
|
Eduson Academy
114 отзывов
|
Цена
116 400 ₽
|
От
9 700 ₽/мес
|
Длительность
6 месяцев
|
Старт
25 марта
|
Подробнее |
|
Fullstack-разработчик на Python
|
Нетология
46 отзывов
|
Цена
161 200 ₽
325 635 ₽
с промокодом kursy-online
|
От
4 975 ₽/мес
|
Длительность
18 месяцев
|
Старт
26 марта
|
Подробнее |
|
Python-разработчик
|
Академия Синергия
38 отзывов
|
Цена
89 800 ₽
224 500 ₽
с промокодом KURSHUB
|
От
3 742 ₽/мес
0% на 24 месяца
|
Длительность
6 месяцев
|
Старт
31 марта
|
Подробнее |
|
Профессия Python-разработчик
|
Skillbox
232 отзыва
|
Цена
157 107 ₽
285 648 ₽
Ещё -27% по промокоду
|
От
4 621 ₽/мес
9 715 ₽/мес
|
Длительность
12 месяцев
|
Старт
23 марта
|
Подробнее |
|
Python-разработчик
|
Яндекс Практикум
102 отзыва
|
Цена
159 000 ₽
|
От
18 500 ₽/мес
|
Длительность
9 месяцев
Можно взять академический отпуск
|
Старт
26 марта
|
Подробнее |

OTUS vs SkillFactory: автотесты — где больше «пишем код», а где больше «разбираем подходы»
Если вы ищете курс по автоматизации тестирования, который сочетает теорию и практику, вы попали по адресу. В этой статье мы сравниваем два популярных курса: OTUS и SkillFactory, чтобы помочь вам определиться с выбором. Какой из них поможет вам быстрее освоить важнейшие навыки тестирования? Читайте и узнайте все подробности!

OTUS vs ProductStar: куда идти технарю, чтобы стать продактом — честное сравнение подходов
OTUS или ProductStar — что выбрать, если вы хотите перейти в продакт-менеджмент? Разбираем разницу в обучении, практике и результате, чтобы вы не потратили время зря.

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!

Каждый третий россиянин уверен: он справился бы с работой своего начальника лучше
Исследование Работа.ру выявило интригующий разрыв: треть россиян уверена в своих управленческих способностях, но большинство не готово брать на себя реальную ответственность. Рассказываем, что за этим стоит и что делать тем, кто действительно хочет вырасти до руководителя.