Optuna — что это, зачем нужна и как использовать для подбора гиперпараметров
Современное машинное обучение невозможно представить без тщательного подбора гиперпараметров — тех самых настроек, которые определяют поведение алгоритма еще до начала обучения. Традиционные методы вроде grid search заставляют нас перебирать все возможные комбинации параметров, что при работе с реальными задачами превращается в настоящий кошмар вычислительных затрат. Random search, хоть и экономит время, оставляет нас наедине со случайностью — не лучший спутник для серьезных проектов.

Именно здесь на сцену выходит Optuna — библиотека, которая превращает мучительный процесс подбора гиперпараметров в элегантную оптимизационную задачу. Вместо слепого перебора или случайного блуждания по пространству параметров, Optuna использует современные алгоритмы для интеллектуального поиска оптимальных значений.
Скриншот официальной страницы Optuna.
В этой статье мы детально разберем, как работает Optuna, почему она стала стандартом де-факто для многих ML-инженеров, и главное — как начать использовать ее в своих проектах.
- Зачем нужен подбор гиперпараметров в машинном обучении
- Optuna: обзор и ключевые особенности
- Установка и настройка Optuna
- Как работает Optuna: базовые принципы
- Основные шаги работы с Optuna
- Практические примеры использования Optuna
- Дополнительные возможности Optuna
- Заключение
- Рекомендуем посмотреть курсы по Python
Зачем нужен подбор гиперпараметров в машинном обучении
Представьте себе ситуацию: вы создали модель нейронной сети для классификации изображений, потратили недели на сбор и подготовку данных, но точность модели едва достигает 60%. Проблема может крыться не в архитектуре сети или качестве данных, а в неправильно подобранных гиперпараметрах — тех самых настройках, которые определяют, как именно будет обучаться ваша модель.
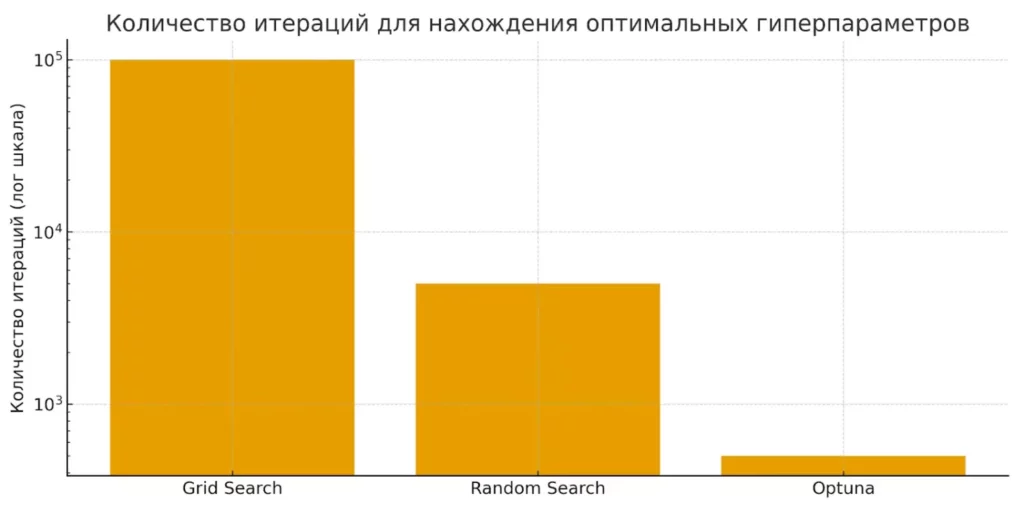
Диаграмма показывает, что Optuna требует на порядок меньше итераций по сравнению с Grid Search и Random Search. Это визуально подчеркивает эффективность байесовского подхода.
Гиперпараметры критически влияют на производительность любого алгоритма машинного обучения. Возьмем простой пример с Ridge регрессией: неправильный коэффициент регуляризации может привести либо к недообучению (слишком большое значение), либо к переобучению (слишком маленькое). В случае с нейронными сетями количество комбинаций растет экспоненциально — learning rate, batch size, количество слоев, функции активации, оптимизаторы — каждый параметр может кардинально изменить результат.
Традиционный grid search работает по принципу «грубой силы»: он методично перебирает все возможные комбинации из заданного набора значений. Звучит надежно, но на практике превращается в вычислительный кошмар. Если у нас есть всего 5 гиперпараметров по 10 возможных значений каждый, получаем 100 000 комбинаций для проверки. Random search ускоряет процесс, случайно выбирая подмножество комбинаций, но остается вопрос: насколько эффективно мы используем вычислительные ресурсы?
Современные байесовские методы оптимизации, включая те, что использует Optuna, работают принципиально иначе. Они строят вероятностную модель зависимости между гиперпараметрами и целевой метрикой, используя результаты предыдущих экспериментов для предсказания наиболее перспективных областей поиска. Это позволяет сократить количество необходимых итераций в разы, сосредоточившись на действительно важных комбинациях параметров.
Optuna: обзор и ключевые особенности
Optuna — это библиотека Python с открытым исходным кодом, которая превратила мучительный процесс подбора гиперпараметров в элегантную задачу автоматической оптимизации. Разработанная командой из Preferred Networks, она быстро завоевала признание ML-сообщества благодаря своей простоте использования и впечатляющей эффективности.
Главная сила Optuna заключается в универсальности — библиотека seamlessly интегрируется практически со всеми популярными фреймворками машинного обучения. Scikit-learn, XGBoost, LightGBM, CatBoost, PyTorch, TensorFlow, Keras — список поддерживаемых инструментов охватывает весь спектр современного ML-стека. Это означает, что вам не придется изучать новый инструмент для каждого фреймворка или переписывать существующий код.
Архитектура Optuna построена вокруг концепции «study» (исследование) и «trial» (испытание). Study представляет собой процесс оптимизации в целом, в то время как каждый trial — это одна попытка обучения модели с конкретным набором гиперпараметров. Такой подход обеспечивает гибкость и масштабируемость: можно запускать multiple studies параллельно, сохранять результаты в различных storage backends и даже распределять вычисления между несколькими машинами.
Если сравнивать Optuna с конкурентами вроде Hyperopt или scikit-optimize, то ключевые преимущества становятся очевидными. Hyperopt, хоть и была пионером в области байесовской оптимизации для ML, страдает от сложности API и ограниченной функциональности. Scikit-optimize предлагает хорошие алгоритмы, но требует значительно больше boilerplate-кода. Optuna же сочетает мощные алгоритмы оптимизации с интуитивно понятным API — принцип «define-by-run» позволяет описывать пространство поиска прямо в коде целевой функции, что делает процесс максимально прозрачным и гибким.
Установка и настройка Optuna
Процесс установки Optuna максимально straightforward и не требует сложных конфигураций. Библиотека поддерживает Python 3.7 и выше, что покрывает практически все современные рабочие окружения.
Наиболее простой и рекомендуемый способ установки — через пакетный менеджер pip:
pip install optuna
Для пользователей conda альтернативный вариант выглядит следующим образом:
conda install -c conda-forge optuna
Если вы работаете с cutting-edge версией и хотите получить доступ к самым последним features, можно установить библиотеку напрямую из GitHub-репозитория:
pip install git+https://github.com/optuna/optuna.git
После установки рекомендуем проверить корректность инсталляции простой командой:
import optuna print(optuna.__version__)
Дополнительные зависимости (например, для визуализации или интеграции с конкретными фреймворками) устанавливаются по мере необходимости. Optuna следует философии минимальных требований — базовая функциональность работает из коробки, а specialized features подключаются опционально.
Как работает Optuna: базовые принципы
Sampling (выбор promising-наборов)
В основе эффективности Optuna лежит интеллектуальная стратегия sampling — процесс выбора наиболее перспективных комбинаций гиперпараметров. Вместо равномерного исследования всего пространства параметров, библиотека концентрирует усилия на областях, которые показали наилучшие результаты в предыдущих экспериментах.
Ключевой принцип работы заключается в построении вероятностной модели зависимости между гиперпараметрами и целевой метрикой. Каждый новый trial использует информацию из всех предыдущих экспериментов для предсказания наиболее вероятных локаций оптимума. Это кардинально отличается от grid search, который слепо перебирает предопределенную сетку значений, не учитывая полученные ранее результаты.
Pruning (раннее прекращение неудачных экспериментов)
Механизм pruning представляет собой elegant решение проблемы вычислительных затрат. Optuna постоянно мониторит промежуточные результаты обучения модели и принимает решение о досрочном прекращении явно неперспективных trials. Если на ранних этапах обучения модель показывает значительно худшие результаты по сравнению с уже найденными лучшими вариантами, эксперимент останавливается, высвобождая ресурсы для более перспективных направлений.
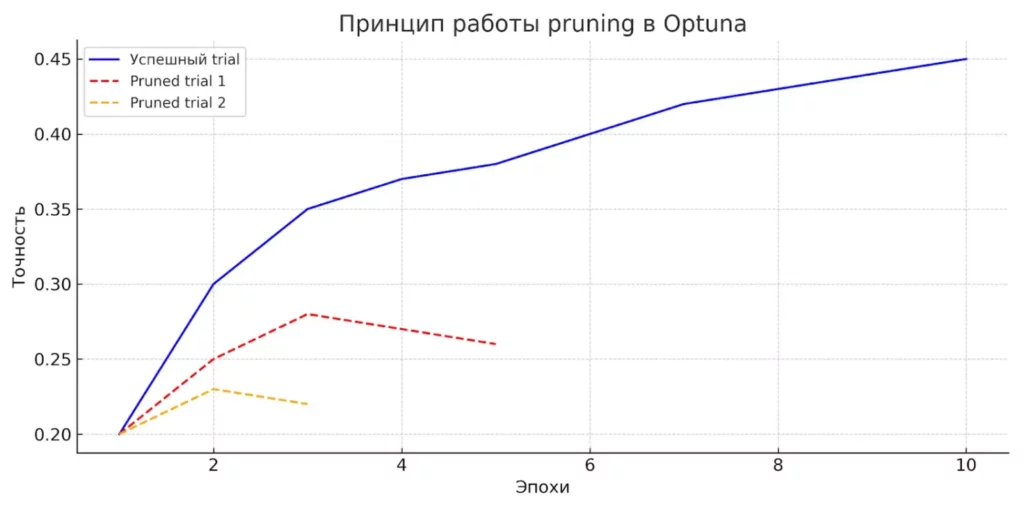
На графике видно, как Optuna досрочно останавливает неудачные эксперименты (красные пунктирные линии), фокусируясь на перспективных параметрах и экономя ресурсы.
Этот подход особенно эффективен при работе с deep learning моделями, где одна эпоха обучения может занимать часы. Вместо ожидания полного завершения заведомо неудачного эксперимента, система переключается на исследование других комбинаций параметров.
Используемые алгоритмы оптимизации
Optuna использует несколько sophisticated алгоритмов оптимизации, адаптируясь к специфике конкретной задачи. По умолчанию применяется TPE (Tree-structured Parzen Estimator) — байесовский метод, который моделирует вероятностное распределение «хороших» и «плохих» гиперпараметров отдельно, а затем максимизирует отношение этих распределений для выбора следующих кандидатов.
Альтернативно доступен CMA-ES (Covariance Matrix Adaptation Evolution Strategy) — эволюционный алгоритм, особенно эффективный для continuous optimization problems. Выбор алгоритма зависит от природы оптимизируемых параметров и требований к вычислительной эффективности.
Основные шаги работы с Optuna
Workflow с Optuna следует четкой и логичной последовательности, которая делает процесс оптимизации гиперпараметров максимально прозрачным. Давайте разберем каждый этап этого процесса:
- Определение objective-функции
Первый и самый важный шаг — создание целевой функции, которая инкапсулирует логику обучения и оценки модели. Эта функция принимает объект trial в качестве аргумента и возвращает метрику, которую необходимо оптимизировать (минимизировать или максимизировать). Внутри функции мы используем методы trial.suggest_*() для определения значений гиперпараметров — suggest_float() для вещественных чисел, suggest_int() для целых, suggest_categorical() для категориальных переменных. - Создание Study объекта
Study представляет собой центральный объект, который управляет всем процессом оптимизации. При создании мы указываем направление оптимизации (direction=»minimize» или direction=»maximize»), выбираем алгоритм sampling и pruning стратегию. Можно также настроить storage backend для сохранения результатов экспериментов. - Запуск optimize()
Метод optimize() запускает итеративный процесс поиска оптимальных гиперпараметров. Мы передаем ему objective-функцию и указываем количество trials или временные ограничения. Optuna автоматически генерирует новые комбинации параметров, основываясь на результатах предыдущих экспериментов. - Извлечение лучших параметров
После завершения оптимизации получаем доступ к результатам через атрибуты Study объекта: best_params содержит оптимальную комбинацию гиперпараметров, best_value — соответствующее значение метрики, а trials предоставляет полную историю экспериментов для дальнейшего анализа.
Такая структура обеспечивает как простоту использования для базовых сценариев, так и гибкость для сложных research задач.
Практические примеры использования Optuna
Пример 1: минимизация простой функции
Начнем с демонстрации базовых принципов на простейшем примере — оптимизации математической функции. Рассмотрим квадратичную функцию (x-2)², где нам необходимо найти значение x, минимизирующее результат:
import optuna
def objective(trial):
x = trial.suggest_float("x", -10, 10)
return (x - 2) ** 2
study = optuna.create_study()
study.optimize(objective, n_trials=100)
print(f"Лучший параметр: {study.best_params}")
Этот пример иллюстрирует фундаментальные концепции: trial объект предлагает значения параметров, objective функция возвращает метрику для оптимизации, а study управляет процессом поиска.
Пример 2: Ridge Regression (регрессия)
Переходим к реальной ML-задаче с использованием Boston Housing dataset. Оптимизируем гиперпараметры Ridge регрессии:
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_squared_error
def objective(trial):
alpha = trial.suggest_float("alpha", 0.1, 10.0)
solver = trial.suggest_categorical("solver", ["auto", "svd", "cholesky"])
model = Ridge(alpha=alpha, solver=solver)
model.fit(X_train, y_train)
predictions = model.predict(X_test)
return mean_squared_error(y_test, predictions)
Наш опыт показывает, что Optuna находит оптимальные параметры за 15-20 trials, в то время как grid search потребовал бы сотни итераций для покрытия того же пространства параметров.
Пример 3: Logistic Regression (классификация)
Для задач классификации принцип остается тем же, меняется только метрика оптимизации:
from sklearn.linear_model import LogisticRegression
def objective(trial):
C = trial.suggest_float("C", 1e-5, 1e2, log=True)
penalty = trial.suggest_categorical("penalty", ["l1", "l2"])
model = LogisticRegression(C=C, penalty=penalty, solver="liblinear")
model.fit(X_train, y_train)
return model.score(X_test, y_test) # accuracy для максимизации
study = optuna.create_study(direction="maximize")
study.optimize(objective, n_trials=100)
print(f"Лучшие параметры: {study.best_params}")
Пример 4: внедрение Pruning (California Housing Dataset)
Механизм pruning становится особенно ценным при работе с итеративными алгоритмами. Рассмотрим пример с MLPRegressor, где мы можем отслеживать промежуточные результаты и прерывать неперспективные эксперименты:
from sklearn.neural_network import MLPRegressor
def objective(trial):
hidden_layers = trial.suggest_categorical("hidden_layer_sizes",
[(50,), (100,), (50, 100)])
learning_rate = trial.suggest_float("learning_rate_init", 0.001, 0.1)
model = MLPRegressor(hidden_layer_sizes=hidden_layers,
learning_rate_init=learning_rate,
max_iter=100)
# Промежуточная оценка каждые 10 итераций
for i in range(10, 101, 10):
model.set_params(max_iter=i)
model.fit(X_train, y_train)
intermediate_score = model.score(X_val, y_val)
trial.report(intermediate_score, i)
if trial.should_prune():
raise optuna.TrialPruned()
return model.score(X_test, y_test)
Этот подход может сократить время оптимизации в разы, автоматически отсеивая заведомо неудачные комбинации параметров на ранних стадиях обучения.
Дополнительные возможности Optuna
Визуализация результатов
Optuna предоставляет богатый набор инструментов для визуализации результатов оптимизации, что критически важно для понимания поведения алгоритма и принятия обоснованных решений. Библиотека включает встроенные функции визуализации, работающие на базе Plotly и Matplotlib.
График истории оптимизации (plot_optimization_history()) показывает эволюцию лучшего найденного значения с течением времени, позволяя оценить скорость сходимости алгоритма. Диаграмма важности параметров (plot_param_importances()) выявляет наиболее влиятельные гиперпараметры — информация, которая может кардинально изменить подход к настройке модели.
Контурные графики (plot_contour()) демонстрируют взаимосвязи между парами гиперпараметров, выявляя области оптимума и возможные корреляции. Диаграммы параллельных координат помогают визуализировать многомерные зависимости, что особенно ценно при работе с большим количеством параметров.
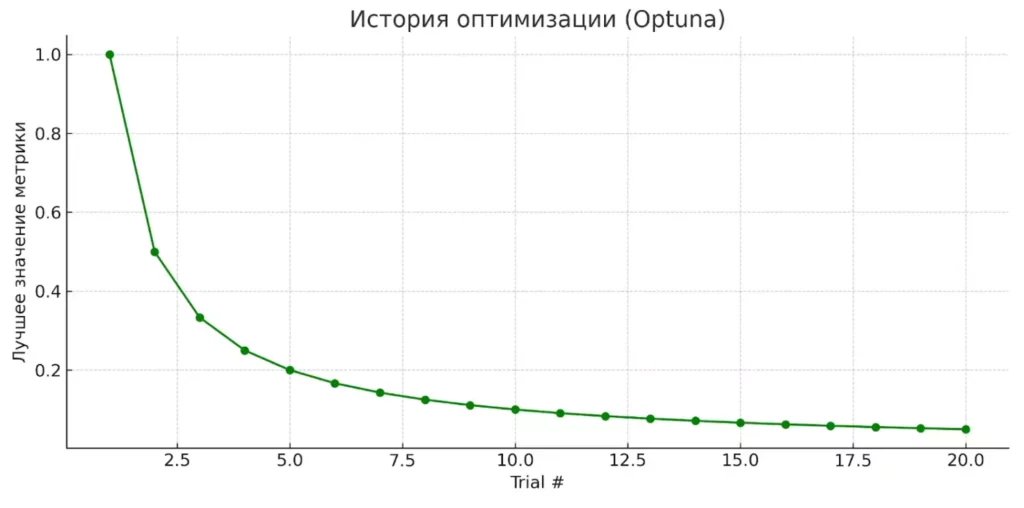
График демонстрирует, как с каждой итерацией Optuna улучшает найденные результаты, постепенно приближаясь к оптимальному решению.
Логирование экспериментов
Система логирования Optuna обеспечивает полную прозрачность процесса оптимизации. Каждый trial автоматически сохраняется с timestamp, использованными параметрами, полученными результатами и метаданными. Это создает comprehensive audit trail всех экспериментов.
Уровень детализации логов настраивается через функции optuna.logging.set_verbosity() — от минимального вывода только итоговых результатов до подробного отчета о каждом шаге оптимизации. Такая гибкость особенно важна в production-окружениях, где избыточное логирование может замедлить процесс.
Многокритериальная оптимизация
Реальные ML-задачи часто требуют балансировки между несколькими метриками — точностью и скоростью inference, recall и precision, качеством модели и размером. Optuna поддерживает multi-objective optimization через создание study с параметром directions=["minimize", "maximize"].
Алгоритм строит Pareto-фронт оптимальных решений, где улучшение одной метрики невозможно без ухудшения другой. Это дает нам set of trade-off solutions, из которых можно выбрать наиболее подходящий для конкретного use case.
Интеграция с MLflow
Интеграция с MLflow превращает Optuna в полноценный инструмент для MLOps workflows. После установки pip install optuna mlflow можно настроить автоматическое логирование всех experiments в MLflow tracking server:
import mlflow from optuna.integration.mlflow import MLflowCallback mlflc = MLflowCallback(tracking_uri="http://localhost:5000", metric_name="accuracy") study.optimize(objective, n_trials=100, callbacks=[mlflc])
Это обеспечивает централизованное хранение результатов экспериментов, version control моделей и collaborative research capabilities для команды разработчиков.
Заключение
Optuna представляет собой мощный инструмент, который кардинально меняет подход к оптимизации гиперпараметров в машинном обучении. Главная сила библиотеки заключается в сочетании sophisticated алгоритмов оптимизации с простотой использования — принцип «define-by-run» делает процесс настройки интуитивно понятным даже для начинающих специалистов. Подведем итоги:
- Optuna автоматизирует подбор гиперпараметров. Это позволяет экономить время и вычислительные ресурсы при обучении моделей.
- Алгоритмы TPE и CMA-ES обеспечивают точный и эффективный поиск параметров. Они адаптируются под задачу и ускоряют сходимость.
- Механизм pruning прекращает неудачные эксперименты. Это повышает эффективность обучения и освобождает ресурсы.
- Optuna интегрируется с популярными ML-фреймворками. Это делает её удобной частью любого рабочего процесса.
- Использование Optuna повышает качество итоговых моделей. Это делает библиотеку стандартом для инженеров машинного обучения.
Если вы только начинаете осваивать работу с Optuna и машинным обучением, рекомендуем обратить внимание на курсы по ML. В них вы найдете теорию и практику оптимизации моделей с примерами реальных экспериментов.
Рекомендуем посмотреть курсы по Python
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Профессия Python-разработчик
|
Eduson Academy
114 отзывов
|
Цена
116 400 ₽
|
От
9 700 ₽/мес
|
Длительность
6 месяцев
|
Старт
25 марта
|
Подробнее |
|
Fullstack-разработчик на Python
|
Нетология
46 отзывов
|
Цена
161 200 ₽
325 635 ₽
с промокодом kursy-online
|
От
4 975 ₽/мес
|
Длительность
18 месяцев
|
Старт
26 марта
|
Подробнее |
|
Python-разработчик
|
Академия Синергия
38 отзывов
|
Цена
89 800 ₽
224 500 ₽
с промокодом KURSHUB
|
От
3 742 ₽/мес
0% на 24 месяца
|
Длительность
6 месяцев
|
Старт
31 марта
|
Подробнее |
|
Профессия Python-разработчик
|
Skillbox
232 отзыва
|
Цена
157 107 ₽
285 648 ₽
Ещё -27% по промокоду
|
От
4 621 ₽/мес
9 715 ₽/мес
|
Длительность
12 месяцев
|
Старт
23 марта
|
Подробнее |
|
Python-разработчик
|
Яндекс Практикум
102 отзыва
|
Цена
159 000 ₽
|
От
18 500 ₽/мес
|
Длительность
9 месяцев
Можно взять академический отпуск
|
Старт
26 марта
|
Подробнее |

Hexlet vs Skillbox: что выгоднее по цене «за навык», если считать проекты и ревью?
Что лучше — Hexlet или Skillbox, если считать не цену курса, а результат? Где быстрее прокачать навыки, получить проекты в портфолио и не потерять деньги — разберём в статье.

OTUS vs SkillFactory: автотесты — где больше «пишем код», а где больше «разбираем подходы»
Если вы ищете курс по автоматизации тестирования, который сочетает теорию и практику, вы попали по адресу. В этой статье мы сравниваем два популярных курса: OTUS и SkillFactory, чтобы помочь вам определиться с выбором. Какой из них поможет вам быстрее освоить важнейшие навыки тестирования? Читайте и узнайте все подробности!

OTUS vs ProductStar: куда идти технарю, чтобы стать продактом — честное сравнение подходов
OTUS или ProductStar — что выбрать, если вы хотите перейти в продакт-менеджмент? Разбираем разницу в обучении, практике и результате, чтобы вы не потратили время зря.

Яндекс Практикум vs SF Education: где лучше стартовать в финтехе на стыке данных и финансов
Если вы хотите начать карьеру в финтехе, но не знаете, какой курс выбрать, наша статья поможет вам разобраться. Мы сравнили два популярных образовательных провайдера — Яндекс Практикум и SF Education — и расскажем, какой курс лучше подойдет для освоения аналитики данных или финансов. Читайте, чтобы выбрать подходящий путь для вашего старта в финтехе!