Собеседование проджект менеджера: актуальные вопросы и темы 2026 года
Ещё три-четыре года назад на интервью проджект менеджера можно было уверенно пройти, если вы знали, чем Scrum отличается от Kanban, умели нарисовать диаграмму Ганта и могли рассказать историю про «сложного стейкхолдера» по модели STAR. Сегодня этого набора категорически недостаточно — и дело не в том, что базовые компетенции обесценились. Дело в том, что планка «базового» резко поднялась вверх.
К 2026 году интервью на позицию PM или Delivery Manager заметно «сценаризировалось». Интервьюеры всё реже задают абстрактные вопросы в духе «расскажите о себе» и всё чаще погружают кандидата в конкретную ситуацию: вот контекст, вот ограничения, вот три конкурирующих приоритета — что делаете? Проверяется уже не набор инструментов, а мышление: как вы структурируете неопределённость, как принимаете решения при неполной информации и — что важно — как коммуницируете эти решения тем, кто не хочет слышать плохих новостей.
Отдельным обязательным треком стала AI-флюентность. Это понятие шире, чем «умеете ли вы пользоваться ChatGPT». Речь идёт о том, насколько осознанно вы встраиваете генеративные инструменты: где они ускоряют работу, где создают риски, как вы контролируете качество их вывода и как не допускаете утечки чувствительных данных через внешние модели. Компании, которые пережили первую волну хаотичного внедрения GenAI, теперь хотят нанимать людей, способных управлять этим процессом — а не тех, кто либо игнорирует AI, либо использует его бесконтрольно.

В этой статье мы разберём все ключевые блоки современного интервью PM: этапы и форматы отбора, вопросы по delivery и планированию, Agile и масштабированию, лидерству и стейкхолдерам, метрикам и управлению рисками. Для каждого блока — логика ответа, примеры формулировок и типичные ошибки, которые стоят кандидатам оффера. В конце — план подготовки на семь дней, который можно запустить прямо сейчас.
Небольшое уточнение по терминологии: когда мы говорим «PM» в контексте этой статьи, мы имеем в виду project/delivery manager в цифровой среде — продуктовые компании, IT-подразделения корпораций, digital-агентства. Однако большинство подходов применимы значительно шире: там, где есть команды, сроки, стейкхолдеры и неопределённость, логика интервью принципиально не меняется.
- Какие этапы и форматы собеседования PM в 2026 и как к ним готовиться?
- Какие вопросы по delivery и планированию задают чаще всего?
- Какие вопросы по Agile/Hybrid и масштабированию актуальны в 2026?
- Какие вопросы про лидерство и стейкхолдеров задают на интервью PM?
- Какие вопросы про метрики, риски и GenAI стали must-have в 2026?
- Как собрать план подготовки за неделю и что повторить за день до интервью
- Рекомендуем посмотреть курсы по управлению проектами
Какие этапы и форматы собеседования PM в 2026 и как к ним готовиться?
Типичная воронка отбора на позицию PM сегодня состоит из трёх-пяти этапов — и каждый из них проверяет принципиально разные вещи. Ошибка многих кандидатов в том, что они готовятся «вообще»: повторяют методологии, освежают в памяти кейсы, листают статьи про Agile. Между тем каждый этап требует отдельной подготовки с отдельной логикой подачи.
Ниже — карта интервью, которую мы рекомендуем держать перед глазами на этапе подготовки.
Таблица 1. Карта интервью PM 2026: этап → что проверяют → как готовиться
| Этап | Цель | Тип вопросов | Что принести / подготовить | Типичные ошибки |
|---|---|---|---|---|
| HR-скрининг (30–45 мин) | Соответствие базовым требованиям, мотивация, культурный фит | Мотивация, ожидания, опыт в цифрах, конфликты/провалы | Самопрезентация на 60–90 сек, зарплатная вилка, 2–3 достижения с метриками | Перечисление инструментов вместо результатов; обвинение команды; «я просто координировал» |
| Техническое / компетентностное интервью (60–90 мин) | Глубина экспертизы: delivery, планирование, методологии, метрики | Поведенческие (STAR), ситуационные, вопросы про процессы и решения | Примеры из практики с цифрами, логика принятия решений, владение терминологией | Абстрактные ответы без контекста; «у нас так было принято» без объяснения почему |
| Кейс / тестовое задание (1–3 дня или live) | Мышление в условиях неопределённости, структура, артефакты | Сценарий: срыв проекта, конфликт стейкхолдеров, рост скоупа, параллельные команды | Mini-план, RAID, RACI, коммуникационный план, статус на 1 страницу | Сразу давать «правильный ответ» без уточнений; игнорировать риски и зависимости |
| Финальное интервью / панель (60–90 мин) | Лидерский профиль, стратегическое мышление, работа с топ-стейкхолдерами | Сложные кейсы, вопросы про влияние без полномочий, AI-флюентность | Портфолио артефактов, готовность обсуждать провалы и выводы, AI use cases | Продавать себя без доказательств; уходить от неудобных вопросов про провалы |
| Offer / back-check | Верификация фактов, референсы | Уточняющие вопросы по резюме и кейсам | Контакты рекомендателей, согласованные формулировки достижений | Расхождение между тем, что сказали на интервью, и тем, что скажут референсы |

Диаграмма показывает типичную последовательность этапов: от HR-скрининга до оффера и back-check. Она помогает быстро увидеть, что на каждом этапе проверяют разные навыки, а значит и готовиться нужно по-разному.
Что проверяют на HR-скрининге и как упаковать опыт за 5–7 минут?
HR-скрининг — это этап, который многие кандидаты недооценивают, считая его формальностью. На практике именно здесь отсеивается значительная часть претендентов: не потому что им не хватает экспертизы, а потому что они не умеют упаковать свой опыт чётко и убедительно за отведённое время.
Структура самопрезентации, которая работает, выглядит так: роль → масштаб → домен → 2–3 достижения в цифрах → «чем полезен именно вам». Это не монолог на пять минут — это ёмкий нарратив на 60–90 секунд, после которого у рекрутера должно сложиться чёткое представление о том, кто вы и почему пришли именно в эту компанию. Пример: «Последние два года я руководил delivery в fintech-команде из 18 человек — три продуктовых стрима, два релиза в квартал. За это время сократили time-to-market с 11 до 7 недель и снизили количество инцидентов после релиза на 40%. Сейчас ищу позицию, где можно масштабировать этот опыт на несколько команд». Коротко, конкретно, с цифрами — и с мостом к позиции.
Типичные вопросы на HR-скрининге делятся на несколько групп. Первая — мотивация и ожидания: почему уходите с текущего места, что привлекает в этой роли, какой формат работы предпочитаете. Вторая — верификация опыта: какими проектами руководили, какой был размер команды и бюджета, с какими методологиями работали. Третья — поведенческие маркеры: расскажите про конфликт с коллегой или стейкхолдером, опишите ситуацию, когда проект шёл не по плану. Четвёртая — практические параметры: ожидания по зарплате, готовность к командировкам, сроки выхода.
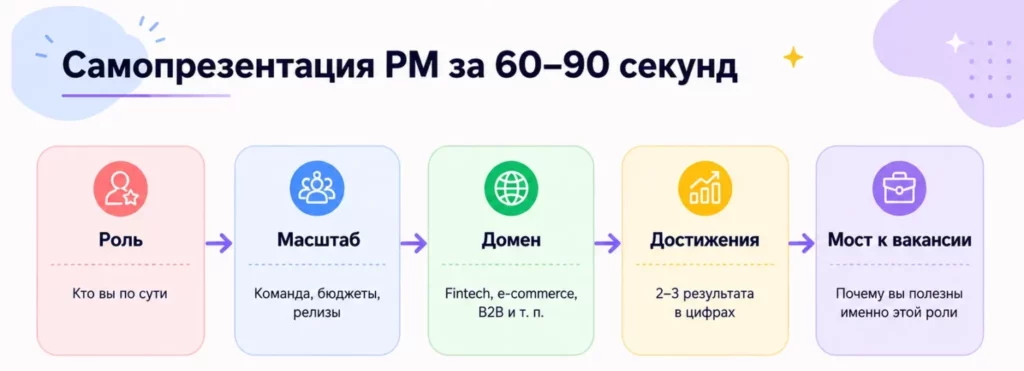
Схема собирает рабочую формулу рассказа о себе: роль, масштаб, домен, достижения и мост к вакансии. Её удобно использовать как шаблон для короткого и структурированного ответа на HR-скрининге.
Три «красных флага», которые немедленно снижают оценку кандидата: перечисление инструментов вместо результатов («я работал в Jira, Confluence, MS Project»), перекладывание ответственности на команду или обстоятельства при рассказе о провалах, и отсутствие метрик — когда на вопрос «каков был результат?» кандидат отвечает «всё прошло хорошо» или «стейкхолдеры остались довольны».
Чек-лист: подготовка к HR-скринингу за 30 минут
- Сформулирована самопрезентация на 60–90 секунд (роль → масштаб → домен → достижения → мост к вакансии).
- Подготовлены 2–3 достижения с конкретными цифрами (сроки, бюджет, метрики качества, бизнес-эффект).
- Готов ответ на вопрос «почему уходите / почему эта компания» — без негатива в сторону текущего работодателя.
- Определена и обоснована зарплатная вилка.
- Подготовлен пример конфликта / провала — с акцентом на личный вклад в решение и выводы.
- Изучены сайт компании, продукт, стек, последние новости (10–15 минут).
- Готов список из 2–3 вопросов рекрутеру — про команду, процессы, ожидания от роли.
Как проходить кейсы и тестовые задания и какие артефакты и AI-сценарии готовить?
Кейс-интервью для PM — это не экзамен на знание правильного ответа. Это наблюдение за тем, как вы думаете в условиях неопределённости: как структурируете проблему, какие вопросы задаёте, как балансируете между скоростью и качеством решения, как обосновываете trade-offs. Именно поэтому первые две минуты кейса критически важны — и именно здесь большинство кандидатов допускают ключевую ошибку: бросаются давать решение, не прояснив контекст.
Схема ответа на кейс, которая демонстрирует зрелость мышления:
Контекст → Ограничения → Варианты → Решение → Риски → Следующий шаг
Сначала уточняем: что за проект, какова цель, кто стейкхолдеры, какие ресурсы и сроки, что уже пробовали. Затем называем ограничения — и только после этого предлагаем варианты с их плюсами и минусами. Финальное решение обосновываем через выбранные критерии, сразу называем риски и формулируем конкретный следующий шаг.
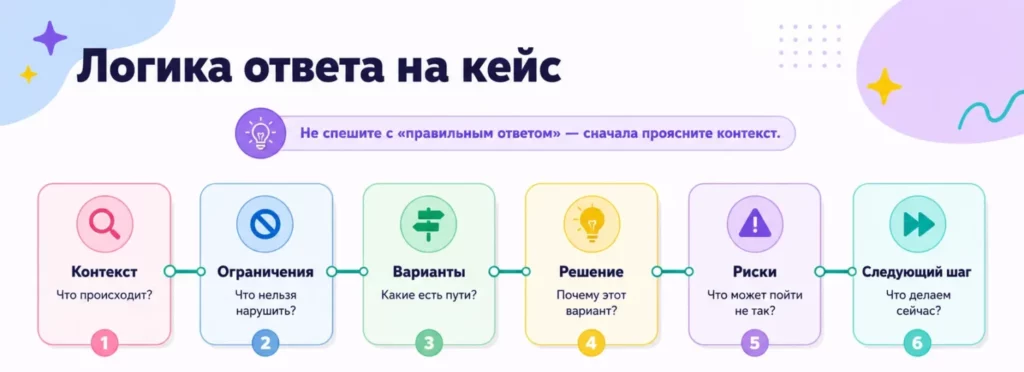
Диаграмма показывает структуру зрелого ответа на кейс: от прояснения контекста до следующего шага. Она помогает не бросаться в решение сразу, а демонстрировать мышление и логику выбора.
Наиболее частые сценарии кейсов в 2026 году: проект срывает сроки и нужно принять решение о релизе; стейкхолдер требует добавить фичу в уже зафиксированный скоуп; две команды имеют конкурирующие зависимости и общий дедлайн; нужно выстроить governance для нового продуктового направления. Для каждого из этих сценариев полезно заранее иметь «скелет» ответа — не готовый скрипт, а логическую рамку.
Отдельного внимания заслуживают артефакты. Многие компании на кейс-этапе явно или неявно ожидают, что кандидат предъявит что-то материальное — не обязательно полноценный документ, но хотя бы структуру. Минимальный набор, который стоит уметь нарисовать или описать за 10–15 минут: RAID-лог (Risks, Assumptions, Issues, Dependencies), RACI-матрица для ключевых решений, коммуникационный план на одну страницу, статус-репорт в формате «светофор», упрощённый timeline с контрольными точками.
Таблица 2. Артефакты PM для кейса: что это, когда нужно, как выглядит на одной странице
| Артефакт | Что это | Когда нужен | Минимальный формат |
|---|---|---|---|
| RAID-лог | Реестр рисков, допущений, проблем и зависимостей | Любой проект с неопределённостью | Таблица: категория / описание / владелец / статус / план |
| RACI-матрица | Распределение ответственности по решениям/задачам | Несколько команд или стейкхолдеров | Таблица: решение/задача × роль; ячейки: R/A/C/I |
| Коммуникационный план | Кто, что, когда и в каком формате получает информацию | Проекты с множеством аудиторий | Таблица: аудитория / сообщение / канал / частота / владелец |
| Статус-репорт | Срез состояния проекта для стейкхолдеров | Еженедельно / по запросу | Светофор по scope/time/cost/quality + топ-3 риска + решения на этой неделе |
| Timeline / roadmap | Визуализация ключевых этапов и зависимостей | Планирование, согласование скоупа | Этапы + вехи + зависимости + буферы; без лишней детализации |
| Risk heatmap | Визуализация рисков по вероятности и влиянию | Kick-off, ревью рисков | 2×2 или 3×3 матрица: вероятность × влияние; цвет = приоритет |
Наконец, блок, который в 2026 году стал отдельным критерием оценки — AI-сценарии. Интервьюеры всё чаще спрашивают напрямую: как вы используете генеративные инструменты в работе? Ожидается не восторженный рассказ про «я всё делаю через ChatGPT», а зрелая позиция с пониманием границ. Хороший ответ включает три компонента: конкретные use cases (составление черновиков статус-репортов, суммаризация встреч, генерация вариантов для обсуждения), механизмы контроля качества (проверка фактов, верификация выводов, финальное редактирование человеком) и правила безопасности (какие данные нельзя передавать во внешние модели — персональные, коммерческая тайна, NDA-материалы, внутренние финансовые показатели).
Чек-лист: кейс-интервью — что уточнить в первые две минуты
- Какова конечная цель проекта / инициативы?
- Каков текущий статус — что уже сделано, что известно?
- Кто ключевые стейкхолдеры и каковы их приоритеты?
- Какие ресурсы доступны (люди, бюджет, время)?
- Есть ли жёсткие ограничения или зафиксированные договорённости?
- Что уже пробовали и почему не сработало?
- Какой формат ответа ожидается — структура, документ, устное обсуждение?
Какие вопросы по delivery и планированию задают чаще всего?
Delivery — это сердцевина роли PM, и именно здесь интервьюеры копают глубже всего. Поверхностные ответы про «я следил за сроками и координировал команду» не работают: вас будут спрашивать про конкретные решения в конкретных обстоятельствах, про логику выбора подхода и про то, что вы делали, когда план трещал по швам. Причём последнее — про срывы и кризисы — интересует интервьюеров даже больше, чем истории про успехи. Управлять проектом, когда всё идёт по плану, умеют многие. Управлять им, когда всё идёт не так — единицы.
В этом разделе мы разберём два ключевых кластера вопросов: оценка сроков и ресурсов с антикризисным управлением, и работа с изменениями, зависимостями и релизами.
Как вы оцениваете сроки и ресурсы и что делаете при срыве плана?
Вопросы про планирование — одни из самых частых на техническом интервью PM. При этом они одновременно одни из самых «провальных»: кандидаты либо уходят в абстракцию («декомпозировал задачи, оценивал с командой»), либо описывают идеальный процесс, который никак не соотносится с реальностью. Интервьюер, который сам руководил проектами, это чувствует мгновенно.
Каркас ответа на вопросы про планирование строится по следующей логике:
Цель → Ограничения → Декомпозиция → Оценка → Буферы и риски → Контроль исполнения
Сначала фиксируем, что именно нужно доставить и какой бизнес-результат за этим стоит — без понимания цели планирование превращается в упражнение ради упражнения. Затем называем ограничения: жёсткие дедлайны, доступность ресурсов, технические зависимости, регуляторные требования. Только после этого переходим к декомпозиции — и здесь важно показать, что вы декомпозируете не «задачи в Jira», а deliverables с понятными критериями готовности.
Оценка — отдельная тема. Зрелый PM понимает, что любая оценка — это диапазон, а не точка, и умеет объяснить, почему он получился именно таким. На практике хорошо работает комбинация: экспертная оценка коллег, исторические данные по похожим задачам и отдельные буферы на то, что обычно всплывает по ходу работы. Не «заложили 20% сверху», а «выделили буфер на интеграционное тестирование, потому что в прошлый раз именно там потеряли две недели».
Таблица 3. Частые вопросы по delivery и планированию: скелеты ответов
| Вопрос | Скелет ответа (SAO/STAR) | Что обязательно упомянуть | Что не говорить |
|---|---|---|---|
| Как вы оцениваете сроки проекта? | Ситуация: тип проекта и неопределённость → Действие: декомпозиция + оценка с командой + буферы → Результат: точность прогноза, отклонение | Исторические данные, диапазон оценки, явные допущения, риски в плане | «Я просто спрашиваю у разработчиков» / точечные оценки без обоснования |
| Что делаете, когда проект срывает сроки? | Ситуация: момент обнаружения → Действие: диагностика причины, варианты, коммуникация стейкхолдерам → Результат: что изменили, чему научились | Ownership, прозрачность, конкретное решение (scope/time/resources trade-off) | Обвинение коллег или внешних обстоятельств; «мы просто работали больше» |
| Как прогнозируете ход проекта? | Ситуация: метрики и инструменты мониторинга → Действие: регулярные срезы, ранние сигналы → Результат: своевременные решения | Конкретные метрики (burndown, cycle time, риск-реестр), частота ревью | «Интуиция» / «я всегда чувствую, когда что-то идёт не так» |
| Как вы управляете ресурсами при конкурирующих приоритетах? | Ситуация: конкурирующие запросы → Действие: приоритизация через бизнес-ценность, переговоры, trade-offs → Результат: согласованное решение | Явные критерии приоритизации, вовлечённость стейкхолдеров в решение | «Я решал сам» без обоснования / «старался угодить всем» |
Отдельного внимания заслуживает вопрос про провалы и срывы — он звучит в той или иной форме практически на каждом интервью. Типичные формулировки: «расскажите о проекте, который не достиг целей», «был ли у вас опыт срыва дедлайна», «что бы вы сделали иначе». Это не ловушка — это попытка оценить зрелость и способность к рефлексии.
Структура ответа про провал, которая работает: что произошло → какова была моя роль → что я предпринял → каков был результат → что изменил в процессе после. Ключевые элементы — личный ownership («я не увидел ранний сигнал», «я недооценил зависимость», «я слишком долго не эскалировал») и конкретные изменения в процессе, а не абстрактные «сделал выводы». Чего категорически не стоит делать: начинать с контекста, который объясняет, почему это на самом деле была не ваша вина; говорить «команда подвела»; описывать провал как что-то незначительное, чтобы не выглядеть уязвимо.
Как вы управляете изменениями, зависимостями и релизами без хаоса?
Scope creep — тихий убийца большинства проектов. Он редко приходит как официальный запрос на изменение: чаще это серия небольших «а давайте добавим», «это же займёт пять минут», «стейкхолдер очень просит». К моменту, когда PM осознаёт масштаб накопленных изменений, разворачиваться уже поздно. Именно поэтому вопросы про управление изменениями на интервью проверяют не знание процедур, а системное мышление и умение говорить «нет» так, чтобы не разрушить отношения.
Антонио Нието-Родригез, автор «Project Management Handbook» (Harvard Business Review): «Эра "административного" управления проектами мертва. К 2026 году PM либо становится стратегом, способным управлять изменениями через влияние, либо его заменяет алгоритм. Главный навык сегодня — не заполнение бэклога, а выбор того, что в него не попадет».
Зрелый ответ на вопрос про scope creep строится вокруг трёх элементов: правила входа изменений, impact-analysis и фиксация решений. Правило входа — это не бюрократия, а договорённость: любое изменение скоупа оценивается до включения, а не после. Impact-analysis отвечает на вопросы: что это меняет в сроках, стоимости, качестве и рисках? Какие другие задачи придётся подвинуть? Что мы готовы отдать взамен? Фиксация решений — письменная, с указанием того, кто принял решение и на каком основании. Это защищает и PM, и стейкхолдера.
Чек-лист: scope creep — 10 вопросов для impact-analysis
- Что именно меняется — функциональность, объём, качество или все три?
- Насколько изменение влияет на критический путь?
- Какие уже запланированные задачи придётся сдвинуть или сократить?
- Как это влияет на зависимости других команд или систем?
- Каков дополнительный объём работы в человеко-часах / стори-поинтах?
- Нужны ли дополнительные ресурсы или компетенции?
- Как это влияет на риск-профиль проекта?
- Есть ли регуляторные или архитектурные последствия?
- Что мы готовы исключить из скоупа в обмен?
- Кто принимает финальное решение и в какие сроки?
Управление зависимостями — тема, которая особенно актуальна для кандидатов на роли в крупных организациях с несколькими командами. Вопросы звучат так: «как вы выявляете зависимости между коллегами», «что делаете, когда смежная группа срывает свою часть», «как синхронизируете релизы». Здесь интервьюер ищет признаки системного подхода: карта зависимостей, обозначенные интеграционные точки, регулярные синхронизации и — что важно — явный владелец каждой зависимости с понятным протоколом эскалации.
Релизный сценарий — отдельный блок, который становится всё более частым на интервью. Типичный кейс: «вы на финальной стадии релиза, и за час до деплоя обнаруживается критический баг — ваши действия?» Ответ оценивается по нескольким критериям: скорость диагностики, чёткость процесса принятия решения (кто имеет право сказать «стоп»), коммуникационный протокол (кого уведомляем, в каком порядке, с какой информацией) и post-incident разбор — как мы убеждаемся, что это не повторится.
Хороший ответ на релизный кейс обязательно включает: явное разграничение ролей в принятии решения (PM, tech lead, product owner), заранее согласованные критерии go/no-go, коммуникацию без паники — с фактами и вариантами, а не с эмоциями — и blameless postmortem как стандартную практику, а не исключение.
Какие вопросы по Agile/Hybrid и масштабированию актуальны в 2026?
Тема методологий на интервью PM — это минное поле. С одной стороны, интервьюер ожидает, что вы свободно ориентируетесь в Scrum, Kanban и гибридных подходах. С другой — опытный интервьюер мгновенно распознаёт «agile-театр»: когда кандидат воспроизводит терминологию из учебника, но за ней нет реального понимания того, зачем тот или иной ритуал существует и когда от него стоит отказаться.
К 2026 году ситуация усложнилась: большинство команд работает не в «чистом» Scrum и не в «чистом» Kanban, а в каком-то гибриде, продиктованном спецификой продукта, организационными ограничениями и историческим багажом. Умение осознанно описать свой подход — почему именно так, что работает, что не работает и что вы бы изменили — ценится значительно выше, чем безупречное знание теории.
Scrum vs Kanban vs Hybrid: как выбрать подход под контекст?
Один из самых частых вопросов на техническом интервью звучит так: «Какую методологию вы используете и почему?» Слабый ответ: «Мы делаем Scrum — у нас двухнедельные спринты и ежедневный стендап». Сильный ответ объясняет выбор через контекст: тип работы, уровень неопределённости, характер зависимостей и цену ошибки.
Логика выбора подхода, которую стоит уметь артикулировать, строится на нескольких осях. Тип работы — проектная (фиксированный скоуп, чёткий конец) или потоковая (непрерывный входящий поток разнородных задач). Уровень неопределённости — насколько хорошо понятны требования в начале работы. Зависимости — насколько коллеги автономны или встроены в сеть смежных потоков. Цена ошибки — насколько критична возможность быстро развернуться при обнаружении проблемы.
Scrum хорошо работает там, где есть продуктовый поток с постоянной командой, где важна регулярная переприоритизация и где сотрудники достаточно зрелые, чтобы самоорганизоваться внутри спринта. Kanban эффективен в потоковых контекстах — поддержка, операционные задачи, багфикс — где спринтовый ритм создаёт искусственные ограничения. Гибридный подход оправдан, когда проект имеет фиксированные вехи (проектная логика), но внутри итераций требует гибкости (agile-логика).
Частые вопросы про Scrum, которые стоит проработать отдельно: как вы определяете Definition of Ready и Definition of Done, как управляете backlog refinement, что делаете когда спринт срывается, как работаете с техническим долгом внутри спринтового ритма. По Kanban: как устанавливаете WIP-лимиты и почему, как работаете с блокерами, как визуализируете зависимости на доске.
Ошибка, которую интервьюеры замечают чаще всего — это подмена формы содержанием. «Мы делаем Scrum» при ближайшем рассмотрении оказывается: ежедневный стендап есть, ретроспектив нет, backlog не приоритизирован, Definition of Done отсутствует, а спринты регулярно «переносятся». Это не Scrum — это набор церемоний без понимания их назначения. Если вы работали именно так, честнее назвать это «итеративным подходом с элементами Scrum» и объяснить, почему сложилось именно так и что вы пытались изменить.
Переформулировать такой опыт в терминах ценности можно примерно так: «Формально мы называли это Scrum, но на практике работали в более гибридном режиме: спринтовый ритм использовали для синхронизации с бизнесом, а внутри команды управляли потоком через Kanban-доску с WIP-лимитами. Это решало нашу главную проблему — непредсказуемый поток срочных запросов не взрывал спринтовый скоуп».
Как синхронизировать несколько команд и измерять поток поставки?
Когда команд становится больше одной, сложность управления растёт нелинейно. Появляются зависимости, конкурирующие приоритеты, разные ритмы работы и — самое неприятное — «слепые зоны» между сотрудниками, где задачи зависают без явного владельца. Вопросы про масштабирование на интервью проверяют именно это: умеете ли вы выстроить governance так, чтобы несколько команд двигались в одном направлении без микроменеджмента и без хаоса.
Ключевые элементы синхронизации: общий cadence, прозрачность статусов и явный механизм принятия портфельных решений. Общий cadence — это не «все делают одинаковые спринты», а согласованные контрольные точки: когда сотрудники сверяют зависимости, эскалируют блокеры, синхронизируют релизные окна. Прозрачность статусов означает, что состояние каждого потока видно всем заинтересованным — не в виде разрозненных Jira-досок, а в виде единого портфельного представления. Механизм принятия решений отвечает на вопрос: кто и как разрешает конфликты приоритетов между командами?
На практике хорошо работает модель, при которой у каждой команды есть своя операционная автономия, но есть и общий ритм синхронизации — например, еженедельная на уровне лидов с фиксированной повесткой: блокеры, зависимости, изменения в приоритетах. Портфельные решения (что делать первым, от чего отказаться, куда перераспределить ресурсы) принимаются на уровне выше — со спонсором или product leadership — но с чёткой входной точкой и понятным SLA ответа.
Отдельный блок, который в 2026 году стал обязательным на собеседовании — метрики потока поставки. Интервьюер хочет понять: как вы измеряете эффективность delivery-системы, а не только отдельных сотрудников. Здесь важно уметь объяснить разницу между «командными» и «системными» метриками.
Таблица 4. Метрики delivery: velocity vs flow — в чём разница
| Метрика | Уровень | Что измеряет | Где полезна | Ограничение |
|---|---|---|---|---|
| Velocity | Команда | Объём работы за спринт в стори-поинтах | Планирование спринта, сравнение внутри команды | Не сравнима между командами; легко «оптимизируется» в ущерб качеству |
| Cycle time | Задача/поток | Время от начала работы над задачей до её завершения | Диагностика узких мест, предсказуемость | Не показывает время ожидания до начала работы |
| Lead time | Задача/поток | Полное время от появления запроса до поставки | Измерение реальной скорости доставки ценности | Зависит от политик приоритизации, не только от скорости работы |
| Throughput | Система | Количество завершённых задач за период | Прогнозирование, оценка производительности системы | Не учитывает размер и сложность задач |
| WIP (Work in Progress) | Система | Количество задач в работе одновременно | Выявление перегрузки, управление потоком | Требует дисциплины поддержания; политический вопрос в командах |
| Predictability | Система | Доля задач, выполненных в прогнозируемые сроки | Управление ожиданиями стейкхолдеров | Требует исторических данных для расчёта |
Как говорить об этих метриках на интервью? Избегайте двух крайностей: «мы не измеряем, просто работаем» и «у нас был дашборд с 40 метриками». Зрелая позиция выглядит иначе: «Мы отслеживали три-четыре метрики, которые давали нам реальный сигнал. Lead time показывал, насколько быстро мы доставляем ценность от идеи до продакшена. Cycle time помогал находить узкие места внутри процесса. WIP-лимиты удерживали нас от перегрузки. А предсказуемость — долю задач, закрытых в обещанные сроки — мы использовали как главный KPI для разговора со стейкхолдерами».
Иван Селиховкин (Основатель PMCLUB): «На интервью 2026 года мы ищем "Delivery-детективов". Нам не интересно, как вы проводите дейли. Нам важно, как вы находите аномалии в Cycle Time до того, как они стали проблемой, и как вы продаете это решение команде, которая выгорела».
Важный нюанс, который отличает сильного кандидата: умение объяснить, зачем та или иная метрика нужна бизнесу, а не только команде. Lead time сокращается — значит, бизнес быстрее получает ответ на рыночный вопрос. Predictability растёт — значит, стейкхолдеры могут планировать зависимые активности. WIP снижается — значит, меньше переключений, выше качество. Это перевод delivery-языка на язык бизнеса, и именно он демонстрирует стратегическую зрелость кандидата.
Какие вопросы про лидерство и стейкхолдеров задают на интервью PM?
Если вопросы по delivery проверяют, умеете ли вы управлять работой, то вопросы про лидерство и стейкхолдеров проверяют кое-что более тонкое: умеете ли вы управлять людьми и системами влияния — особенно там, где у вас нет формальных полномочий. PM в большинстве организаций не является прямым руководителем команды. Он не нанимает и не увольняет. Но при этом отвечает за результат, который зависит от десятков людей с конкурирующими интересами. Именно эта коллизия — ответственность без власти — и является центральной темой данного блока интервью.
К 2026 году к этой классической теме добавился новый контекст: распределённые команды стали нормой, а не исключением. Это означает, что навыки управления коммуникациями и ожиданиями в асинхронной, мультикультурной, мультичасовой среде теперь проверяются отдельно — и кандидаты, у которых весь опыт из офисного контекста, нередко здесь проигрывают.
Как вы решаете конфликты и когда эскалируете?
Вопросы про конфликты — пожалуй, самые «психологически нагруженные» на интервью PM. Кандидаты либо уходят в излишнюю дипломатичность («я всегда стараюсь найти компромисс»), либо, напротив, демонстрируют избыточную жёсткость («я чётко обозначил границы и не отступил»). Обе крайности настораживают: первая говорит об избегании конфликта, вторая — о неумении работать с системой интересов.
Зрелый ответ строится на понимании того, что конфликт — это симптом, а не проблема. За конфликтом всегда стоит что-то конкретное: конкурирующие приоритеты, неясные роли, дефицит информации или несовпадение ожиданий. Задача PM — диагностировать причину и работать с ней, а не гасить внешнее проявление.
Модель, которую полезно уметь артикулировать на интервью:
Факты → Влияние → Варианты → Решение
Сначала фиксируем, что именно происходит — без оценок и эмоций, только наблюдаемые факты. Затем описываем влияние на проект, команду или бизнес-результат. После этого предлагаем варианты разрешения — желательно несколько, с их плюсами и минусами. И только затем — решение, которое принимается совместно или эскалируется, если консенсус недостижим.
Протокол эскалации тоже стоит уметь описать чётко:
1:1 → Фасилитация → Эскалация
Первый шаг — прямой разговор один на один с вовлечённой стороной. Большинство конфликтов разрешается именно здесь, если разговор происходит вовремя и без аудитории. Если прямой диалог не даёт результата — фасилитируемая сессия с участием обеих сторон и нейтрального модератора. И только если это не работает — эскалация к спонсору или руководству, но с чётко сформулированным вопросом: не «разберитесь с этим человеком», а «нам нужно решение по приоритету X vs Y, потому что без него проект стоит».
Чек-лист: стейкхолдеры и конфликт — когда эскалировать
- Прямой диалог состоялся и не принёс результата.
- Конфликт блокирует критический путь проекта.
- Решение требует полномочий, которых у PM нет.
- Есть риск нарушения договорённостей с внешними сторонами.
- Конфликт влияет на безопасность данных, compliance или репутацию компании.
- Команда демонстрирует устойчивую дисфункцию, выходящую за рамки рабочего разногласия.
- Стейкхолдер давит на изменение скоупа или сроков в обход согласованного процесса.
- Ситуация повторяется несмотря на предыдущие договорённости.
Типичные формулировки вопросов, которые стоит проработать: «расскажите про сложного человека в команде или среди стейкхолдеров», «был ли у вас опыт, когда сотрудники не соглашались с вашим решением», «что делаете, когда стейкхолдер давит на сроки и требует сократить качество». В каждом из этих случаев ответ должен демонстрировать одно и то же: вы защищаете ценность и качество результата, но делаете это через диалог и прозрачные trade-offs — а не через конфронтацию или капитуляцию.
Пример формулировки, которая работает: «Стейкхолдер настаивал на сокращении сроков тестирования, ссылаясь на рыночное окно. Я не стал спорить о сроках — вместо этого мы прошлись по тому, что именно мы тестируем и почему. Оказалось, что три из семи тест-кейсов покрывали сценарии с минимальной вероятностью и максимальным временем выполнения. Мы договорились исключить их из первого релиза, зафиксировали это решение письменно и выпустились в срок — но осознанно, а не случайно». Здесь есть всё: факты, совместный анализ, явный trade-off, фиксация решения и личный ownership.
Как вы управляете ожиданиями и коммуникациями в распределённой среде?
Коммуникации — это инфраструктура проекта. Когда она работает незаметно, никто не говорит «отличная коммуникация». Когда она ломается — все сразу знают, кто виноват. PM, который не выстроил коммуникационную систему осознанно, рано или поздно оказывается в режиме постоянного «тушения пожаров»: отвечает на одни и те же вопросы по несколько раз, участвует в конфликтах, причиной которых был дефицит информации, и теряет доверие стейкхолдеров из-за сюрпризов, которых можно было избежать.
Зрелый коммуникационный план строится вокруг четырёх вопросов: кому, что, когда и в каком формате. Аудитории различаются по уровню детализации и частоте: спонсор получает еженедельный статус на одну страницу с фокусом на решения и риски; команда — ежедневную синхронизацию с фокусом на блокеры и зависимости; внешние стейкхолдеры — адаптированные обновления по milestone. Единый источник правды — одно место, где всегда актуальная информация о статусе проекта — снижает количество запросов и уровень тревожности у всех участников.
В распределённой среде к этому добавляются специфические вызовы: разные часовые пояса, культурные нормы коммуникации, асинхронность как основной режим работы и повышенный риск «испорченного телефона» в длинных переписках. Практика показывает, что здесь особенно важны три вещи: явные SLA ответа (в течение какого времени ожидается реакция на разные типы сообщений), документирование решений (не только что решили, но и почему — для тех, кто не присутствовал на встрече) и регулярные синхронные точки — не для обмена статусами, которые можно прочитать, а для укрепления контакта и раннего выявления напряжений.
Иллюстрация показывает, как PM удерживает прозрачность и ритм коммуникаций в распределённой команде. Она хорошо поддерживает мысль статьи о том, что коммуникации — это инфраструктура проекта, а не второстепенная задача.
Таблица 5. Частые вопросы про лидерство и стейкхолдеров: скелеты ответов
| Вопрос | Скелет ответа | Что обязательно упомянуть | Что не говорить |
|---|---|---|---|
| Расскажите про сложного стейкхолдера | Контекст → в чём проявлялась сложность → что я предпринял → результат → вывод | Конкретные действия, не характеристика человека; что изменилось в вашем подходе | «Он просто был сложным человеком» / «я с ним не работаю больше» |
| Как управляете ожиданиями при неопределённости? | Как фиксируете допущения → как обновляете прогноз → как коммуницируете диапазон, а не точку | Проактивная коммуникация, заранее согласованные критерии успеха, прозрачность про риски | «Стараюсь не давать прогнозов, пока не уверен» |
| Как мотивируете команду без формальных полномочий? | Через что создаёте вовлечённость → как убираете препятствия → как признаёте вклад | Конкретные примеры; связь работы команды с бизнес-результатом | «Я просто хорошо прошу» / апелляция к полномочиям, которых нет |
| Что делаете, когда команда не согласна с решением? | Как слушаете аргументы → как принимаете решение → как обеспечиваете исполнение | Разница между «не согласен» и «не буду делать»; disagree and commit | «Голосуем» / «я всегда прислушиваюсь к команде» без финального решения |
Отдельного разговора заслуживает тема управления без формальной власти — «политика» решений в организационном смысле. Это не интриги и не манипуляции, а понимание того, как на самом деле принимаются решения в конкретной организации: кто имеет реальное влияние вне зависимости от должности, какие коалиции существуют, где находятся неформальные центры сопротивления изменениям. PM, который игнорирует эту реальность, регулярно сталкивается с ситуацией, когда формально согласованное решение «не исполняется» — без очевидных причин.
На интервью этот навык проверяется косвенно: через вопросы про то, как вы добивались поддержки инициативы, как преодолевали сопротивление, как выстраивали отношения с людьми, от которых зависел проект, но которые формально не входили в команду. Здесь важно говорить честно, но без цинизма: показывать, что вы понимаете организационную динамику и умеете с ней работать — через прозрачность, диалог и демонстрацию ценности, а не через обходные манёвры.
Какие вопросы про метрики, риски и GenAI стали must-have в 2026?
Этот блок — пожалуй, наиболее показательный индикатор зрелости кандидата в 2026 году. Вопросы про метрики и риски существовали всегда, но сегодня к ним добавился принципиально новый пласт: как вы работаете с генеративным AI — не как пользователь инструмента, а как менеджер, который несёт ответственность за качество, безопасность и управляемость этого использования. Компании, которые пережили первые два года массового внедрения GenAI, накопили достаточно болезненного опыта — утечки данных, галлюцинирующие сводки, решения на основе непроверенных AI-выводов — чтобы теперь задавать на интервью очень конкретные вопросы.
KPI vs OKR vs outcome: как вы измеряете успех без «метрик ради метрик»?
Начнём с вопроса, который звучит почти на каждом финальном интервью PM: «Как вы измеряете успех проекта?» Слабый ответ перечисляет метрики. Сильный ответ объясняет логику их выбора — и, что важно, демонстрирует понимание разницы между output, outcome и impact.
Output — это то, что мы произвели: фича выпущена, документ написан, интеграция завершена. Outcome — это изменение в поведении или состоянии системы, которое произошло в результате: пользователи стали чаще завершать онбординг, время обработки заявки сократилось, команда поддержки получает на 30% меньше однотипных обращений. Impact — это бизнес-результат более высокого уровня: выросла выручка, снизился отток, укрепилась рыночная позиция. Интервьюеры ловят кандидатов именно на этой лестнице: PM, который отчитывается только outputs, управляет не результатом, а производством.
Разница между KPI и OKR тоже регулярно всплывает на интервью. KPI — это индикатор состояния процесса или системы, который нужно удерживать в норме: time-to-market не выше X недель, процент дефектов не выше Y, satisfaction score не ниже Z. OKR — это инструмент фокусировки на амбициозном изменении: objective задаёт направление («стать лидером по скорости онбординга в сегменте»), key results определяют измеримые маркеры достижения. Путаница между ними — когда OKR превращается в список KPI или когда KPI начинают «оптимизировать» ради самих себя — это классический симптом «метрик ради метрик».
Таблица 6. Словарь метрик: delivery vs outcome vs quality
| Метрика | Что означает | Где полезна | Опасность «игры в метрику» |
|---|---|---|---|
| Time-to-market | Время от идеи до поставки в продакшен | Delivery efficiency, конкурентоспособность | Команды начинают дробить фичи на мелкие части ради улучшения показателя без реального ускорения |
| Deployment frequency | Как часто деплоим в продакшен | CI/CD зрелость, скорость обратной связи | Частые деплои мелких изменений при низком качестве создают операционный хаос |
| Change failure rate | Доля деплоев, вызвавших инциденты | Стабильность, качество процесса | Занижается через переклассификацию инцидентов или снижение частоты деплоев |
| MTTR (Mean Time to Restore) | Среднее время восстановления после инцидента | Операционная зрелость, resilience | Улучшается через «быстрое закрытие» без устранения первопричин |
| Customer satisfaction (CSAT/NPS) | Удовлетворённость пользователей | Качество продукта, business outcome | Зависит от момента измерения; легко манипулировать выборкой |
| Feature adoption rate | Доля пользователей, использующих новую фичу | Валидация product decisions | Растёт через навязывание, а не через реальную ценность |
| Escape defect rate | Доля дефектов, обнаруженных в продакшене | Качество тестирования | Улучшается через занижение severity или переклассификацию |
| Business value delivered | Бизнес-эффект от поставленного инкремента | Связь delivery с бизнес-результатом | Сложно измерить честно; часто подменяется story points или velocity |
Мини-шаблон, который помогает структурировать разговор о метриках на интервью:
Метрика → Зачем → Как измеряем → Какой сигнал даёт → Какое действие триггерит
Например: «Мы отслеживали escape defect rate — долю дефектов, которые добирались до продакшена. Зачем: это был индикатор зрелости нашего процесса тестирования, а не просто качества кода. Измеряли через инцидент-тикеты с меткой "не пойман в QA". Сигнал: рост выше 15% за квартал означал, что что-то системно сломано в процессе ревью или тестирования. Действие: запускали разбор — не «кто виноват», а «где дыра в процессе»». Такой ответ демонстрирует, что метрика встроена в систему принятия решений, а не существует сама по себе.
Риски, postmortem и AI-governance: как использовать GenAI безопасно?
Risk management на интервью проверяется через очень конкретный вопрос: не «знаете ли вы, что такое риск-реестр», а «покажите, как вы с ним работаете». Разница принципиальная. Риск-реестр, который заполняется на kick-off и больше не открывается — это артефакт для галочки. Живой риск-менеджмент выглядит иначе.
Петля управления рисками, которую стоит уметь описать:
Идентификация → Оценка (вероятность × влияние) → План реагирования → Мониторинг → Триггеры → Активация плана → Пересмотр реестра
Каждый риск в реестре имеет владельца — не «команду», а конкретного человека, который мониторит триггеры и отвечает за активацию плана реагирования. Триггеры — это измеримые условия, при наступлении которых риск переходит в активную фазу: не «если что-то пойдёт не так», а «если к пятнице интеграция не завершена на 80% — переходим к плану Б». Регулярность пересмотра реестра зависит от динамики проекта: на активной фазе — еженедельно, на стабильной — раз в две недели.
Postmortem — тема, которую многие кандидаты обходят стороной или описывают поверхностно. Между тем именно здесь проявляется организационная культура: умеет ли команда учиться на ошибках системно, а не искать виноватых. Blameless postmortem — это не про то, чтобы «никого не наказывать», а про то, чтобы фокус анализа был на системных причинах, а не на человеческих ошибках. Потому что человеческие ошибки — это почти всегда симптом системного сбоя: недостаточной автоматизации, неясных процессов, дефицита информации или избыточного давления.
Структура хорошего postmortem: что произошло → таймлайн событий → первопричины → что сработало → что не сработало → action items с владельцами и дедлайнами → контроль исполнения. Последний пункт критичен: postmortem без контроля исполнения action items — это ритуал, а не инструмент улучшения.
Теперь — блок, который в 2026 году стал отдельным обязательным треком на финальных интервью: AI-governance для PM.
Схема, которую стоит уметь описать:
Use case → Данные → Политика → Проверка качества → Логирование / Ответственность
- Use case — для чего именно вы используете GenAI в проектной работе. Типичные применения: суммаризация встреч и создание черновиков протоколов, генерация вариантов для обсуждения (структура плана, варианты коммуникаций, шаблоны документов), первичный анализ больших массивов текстовых данных (фидбек пользователей, результаты ретроспектив), помощь в формулировке технических заданий и acceptance criteria.
- Данные — что именно вы передаёте в модель. Здесь начинается зона риска. Категории данных, которые нельзя передавать во внешние GenAI-системы без явного согласования с юридическим или security-отделом: персональные данные пользователей и сотрудников (PII), коммерческая тайна и NDA-материалы, финансовые показатели до публичного раскрытия, данные о безопасности систем и инфраструктуре, стратегические планы и конкурентные исследования.
- Политика — корпоративные правила использования AI-инструментов. Зрелый PM не просто следует политике — он участвует в её формировании для своей команды: какие инструменты согласованы к использованию, какие данные можно обрабатывать, как хранятся и удаляются результаты работы с AI, как фиксируется факт использования AI при создании артефактов.
- Проверка качества — пожалуй, самый важный элемент. GenAI уверенно генерирует правдоподобный текст, который может содержать фактические ошибки, устаревшие данные или логические противоречия. PM, который принимает AI-вывод без верификации и транслирует его стейкхолдерам, создаёт репутационный и операционный риск. Стандарт проверки: любой AI-генерированный артефакт, покидающий личное рабочее пространство PM, должен быть проверен на фактическую точность, соответствие контексту и отсутствие чувствительных данных.
- Shadow AI — отдельная тема, которую интервьюеры поднимают всё чаще. Это использование AI-инструментов сотрудниками в обход корпоративных политик: личные аккаунты ChatGPT, Gemini или Claude для обработки рабочих данных, несогласованные браузерные плагины, локальные модели без прохождения security-ревью. PM, осведомлённый об этой проблеме, — это PM, который активно обсуждает её с командой, формирует явные договорённости и создаёт «легальный» путь для использования AI-инструментов, чтобы снизить мотивацию обходить ограничения.
Чек-лист: безопасное использование GenAI проджект менеджером
Перед использованием:
- Инструмент согласован корпоративной политикой или IT/security-отделом.
- Понятно, как обрабатываются и хранятся данные провайдером.
- Определён тип данных, которые планируется передавать.
Что нельзя передавать во внешние модели:
- Персональные данные пользователей, клиентов, сотрудников (PII).
- Материалы под NDA или коммерческую тайну.
- Финансовые показатели до публичного раскрытия.
- Данные о безопасности, уязвимостях, инфраструктуре.
- Стратегические планы и конкурентные материалы.
Контроль качества вывода:
- Фактическая точность проверена по первоисточникам.
- Логика и выводы верифицированы человеком.
- Артефакт адаптирован под контекст, а не использован «как есть».
- При публикации/передаче зафиксировано, что использовался AI.
Управление командой:
- Команда знает корпоративную политику использования AI.
- Определены согласованные инструменты и сценарии использования.
- Создан «легальный» путь для AI-инструментов, снижающий риск Shadow AI.
- Договорённости зафиксированы и периодически пересматриваются.
Как собрать план подготовки за неделю и что повторить за день до интервью
Подготовка к интервью PM — это тоже проект. И как любой проект, он выигрывает от структуры, явных приоритетов и реалистичного планирования. Попытка «повторить всё за вечер» работает примерно так же, как попытка сделать весь спринт за последний день: технически возможно, но качество предсказуемо.
Ниже — план на семь дней, который охватывает все ключевые блоки интервью и заканчивается боевой репетицией.
- День 1 — Артефакты. Достаньте из прошлых проектов или восстановите по памяти три-четыре ключевых артефакта: RAID-лог, RACI-матрицу, коммуникационный план и пример статус-репорта. Если реальных артефактов нет — создайте учебные на основе любого знакомого проекта. Цель не в том, чтобы принести «правильный» документ, а в том, чтобы уметь объяснить логику каждого артефакта и показать, как он работал на практике.
- День 2 — Кейсы. Разберите четыре базовых сценария: срыв сроков, конфликт стейкхолдеров, рост скоупа, параллельные команды с зависимостями. Для каждого сценария пропишите каркас ответа по схеме «Контекст → Ограничения → Варианты → Решение → Риски → Следующий шаг». Не заучивайте скрипт — отрабатывайте логику рассуждения вслух.
- День 3 — Метрики. Сформулируйте три-четыре метрики, которые вы реально использовали в работе, и прогоните каждую через шаблон: метрика → зачем → как измеряли → какой сигнал → какое действие. Проработайте разницу output/outcome/impact на конкретных примерах из своего опыта. Повторите логику KPI vs OKR и подготовьте ответ на вопрос «как вы измеряли успех проекта» — конкретно, с цифрами.
- День 4 — Стейкхолдеры и лидерство. Подготовьте две-три истории по модели STAR: конфликт с трудным стейкхолдером, ситуация управления без полномочий, случай когда пришлось эскалировать. Проверьте каждую историю на наличие личного ownership, конкретных действий и измеримого результата. Отдельно сформулируйте, как вы выстраивали коммуникационную систему в последнем крупном проекте.
- День 5 — Agile и масштабирование. Повторите логику выбора методологии через контекст: тип работы, неопределённость, зависимости, цена ошибки. Подготовьте честный ответ о том, как реально работала ваша команда — без приукрашивания и без излишней самокритики. Проработайте метрики потока: lead time, cycle time, throughput, predictability — и уметь объяснить каждую через бизнес-ценность.
- День 6 — AI-сценарии. Сформулируйте три-четыре конкретных use case использования GenAI в вашей проектной практике. Для каждого — что именно делали, как проверяли качество, какие данные не передавали и почему. Проработайте позицию по Shadow AI: как обсуждали тему с командой, какие договорённости были или могли бы быть. Если реального опыта мало — честно обозначьте это и сформулируйте, как подошли бы к вопросу.
- День 7 — Репетиция. Проведите полноценную mock-интервью: попросите коллегу или используйте запись на камеру. Прогоните самопрезентацию на 90 секунд, два-три поведенческих вопроса, один кейс и вопрос про AI. Обратите внимание не только на содержание, но и на темп, структуру ответов и умение остановиться, когда ответ дан — не заполнять тишину лишними словами.
За день до интервью повторять теорию уже поздно и бессмысленно. Вместо этого — три простых действия. Перечитайте свои ключевые истории: не для того, чтобы вспомнить детали, а чтобы они «лежали под рукой». Изучите компанию — продукт, стек, последние публичные новости, вакансию ещё раз — и сформулируйте два-три вопроса, которые покажут, что вы готовились вдумчиво. Обеспечьте себе нормальный сон и минимум стрессовых факторов утром: технические проблемы со связью за пять минут до начала звонка стоили многим кандидатам первого впечатления.
И последнее — относитесь к интервью как к проекту с собственным управлением. Уточняйте вопросы, если формулировка неоднозначна. Фиксируйте договорённости в конце: «правильно ли я понимаю, что дальше — техническое интервью на следующей неделе?» Управляйте таймингом: если видите, что уходите в детали, умейте остановиться и предложить пойти глубже только при необходимости. Это именно те навыки, которые проверяются на интервью — и именно они должны проявляться в самом процессе разговора.
Финальный практический совет: соберите «папку кандидата» — портфолио из пяти-семи артефактов и четырёх-шести историй в формате STAR, охватывающих все ключевые темы. Это не то, что вы обязательно покажете на интервью. Это то, что даёт уверенность: вы знаете, что за каждым вашим ответом стоит реальный опыт, оформленный чётко и конкретно. А уверенность на интервью — это не самопрезентация. Это результат подготовки.
Если вы только начинаете осваивать профессию проджект менеджера, рекомендуем обратить внимание на подборку курсов по project management. В таких программах обычно есть теоретическая и практическая часть: вы разберёте методологии, планирование, управление рисками, коммуникации и подготовите реальные артефакты для портфолио.
Рекомендуем посмотреть курсы по управлению проектами
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
Менеджер проектов | Академия Эдюсон 123 отзыва | Цена 119 600 ₽ Ещё -5% по промокоду | От 9 966 ₽/мес Беспроцентная. На 1 год. | Длительность 3 месяца | Старт 26 июля | |
Project manager | Нетология 47 отзывов | Цена 98 400 ₽ 198 780 ₽ с промокодом kursy-online | От 3 036 ₽/мес Без переплат на 2 года. | Длительность 10 месяцев | Старт 12 августа | |
Профессия Менеджер проектов + ИИ | Skillbox 259 отзывов | Цена 105 903 ₽ 211 807 ₽ Ещё -20% по промокоду | От 3 416 ₽/мес Без переплат на 31 месяц с отсрочкой платежа 6 месяцев. 9 572 ₽/мес | Длительность 12 месяцев | Старт 29 июля | |
Менеджер проектов | Яндекс Практикум 102 отзыва | Цена 161 000 ₽ | От 19 000 ₽/мес На 2 года. | Длительность 6 месяцев Можно взять академический отпуск | Старт 30 июля | |
Управление проектами в современных компаниях | Moscow Business School 11 отзывов | Цена 53 900 ₽ | От 2 246 ₽/мес 0% на 12 месяцев | Длительность 3 дня | Старт 12 августа |

Партнёрские программы: как заработать на рекомендациях и не прогореть

Яндекс Практикум vs GeekBrains: фронтенд — где лучше база и где быстрее выход на первые проекты

Лучшие антиплагиат-сервисы — где проверять, чтобы не прогадать?
