Что такое сортировка в Python
В мире Python сортировка — это фундаментальная операция, которая превращает хаотичный набор элементов в упорядоченную последовательность, будь то числа, строки или более сложные объекты. В этом курсе рассмотрим, что такое сортировка питоне, зачем она нужна, как сортировать разные типы данных и как не столкнуться с ошибками.

Зачем вообще сортировать данные? Причин масса:
- Для быстрого поиска — в отсортированном массиве поиск работает в разы эффективнее (привет, бинарный поиск!).
- Для анализа данных — когда нужно быстро определить минимальные/максимальные значения или медиану.
- Для улучшения пользовательского опыта — никто не хочет видеть хаотично расположенные элементы в интерфейсе.
- Для подготовки к другим алгоритмам — некоторые алгоритмы работают только с отсортированными данными.
Python, как язык с «батарейками в комплекте», предлагает нам из коробки два основных инструмента сортировки:
- sorted() — функция, которая создаёт новый отсортированный список из любого итерируемого объекта.
- .sort() — метод списков, который сортирует список «на месте», изменяя оригинал.
Кажется простым, не правда ли? Ну, так только кажется. Как обычно, дьявол кроется в деталях — и именно о них мы сейчас и поговорим.
- Метод .sort() и функция sorted() — в чём разница
- Ключевые параметры сортировки: key и reverse
- Сортировка разных типов данных
- Пользовательские правила сортировки с lambda и operator
- Сортировка пользовательских объектов
- Особенности и ловушки при сортировке
- Как выбрать подходящий способ сортировки
- Заключение
- Рекомендуем посмотреть курсы по Python
Метод .sort() и функция sorted() — в чём разница
Если вы думаете, что .sort() и sorted() — это одно и то же, но с разным синтаксисом, то вы примерно так же правы, как человек, утверждающий, что прыжок с парашютом и без парашюта — одно и то же, но с разным финалом. Технически — да, в обоих случаях вы перемещаетесь вниз, но последствия, мягко говоря, различаются.
Вот краткое сравнение этих двух методов сортировки:
| Характеристика | list.sort() | sorted() |
|---|---|---|
| Что изменяет | Исходный список | Ничего |
| Что возвращает | None (да-да, совсем ничего) | Новый отсортированный список |
| С чем работает | Только со списками | С любым итерируемым объектом |
| Производительность | Немного быстрее (нет создания копии) | Немного медленнее (создаёт копию) |
Разница становится очевидной на примерах. Давайте посмотрим, как это работает в реальном коде:
# Сортировка с использованием .sort() numbers = [6, 9, 3, 1] result = numbers.sort() # Возвращает None print(result) # None print(numbers) # [1, 3, 6, 9] -- исходный список изменён! # Сортировка с использованием sorted() numbers = [6, 9, 3, 1] result = sorted(numbers) # Возвращает новый список print(result) # [1, 3, 6, 9] print(numbers) # [6, 9, 3, 1] -- исходный список не тронут
Вот ещё один пример, демонстрирующий универсальность sorted():
# С кортежами
tuple_val = (6, 9, 3, 1)
print(sorted(tuple_val)) # [1, 3, 6, 9]
# Со множествами
set_val = {5, 10, 1, 0}
print(sorted(set_val)) # [0, 1, 5, 10]
# Даже со строками!
string_val = "hello"
print(sorted(string_val)) # ['e', 'h', 'l', 'l', 'o']
А попробуйте вызвать .sort() на кортеже или множестве — и Python выдаст вам ошибку с таким видом, будто вы попытались научить кота плавать брассом. Не то чтобы это было невозможно, но природой точно не предусмотрено.
Когда использовать что? Как и с большинством инструментов в программировании, выбор зависит от контекста. Используйте .sort(), когда вам не жалко исходных данных и вы хотите сэкономить память. Используйте sorted(), когда вам нужно сохранить исходный порядок элементов или когда вы работаете с чем-то, что не является списком. Если вы хотите углубиться в эту тему, официальная документация Python по сортировке (docs.python.org/3/howto/sorting.html) — отличное место для начала. Там вы найдете ещё больше примеров и объяснений особенностей работы алгоритмов сортировки в Python.
Скриншот официальной документации Python по сортировке
Ключевые параметры сортировки: key и reverse
Если базовая сортировка в Python — это Toyota Corolla программирования (надёжная, предсказуемая, без излишеств), то параметры key и reverse превращают её в тюнингованный спорткар. Они позволяют настроить процесс сортировки под свои специфические нужды, и, поверьте мне, эти нужды возникают чаще, чем вы думаете.
Параметр reverse
Начнём с самого простого. Параметр reverse — это ваш переключатель направления сортировки: хотите ли вы двигаться от меньшего к большему (по умолчанию reverse=False) или от большего к меньшему (reverse=True). Это как переключатель передач в автомобиле, только с двумя положениями.
numbers = [10, 3, 7] print(sorted(numbers)) # [3, 7, 10] print(sorted(numbers, reverse=True)) # [10, 7, 3]
Ничего сложного, не правда ли? Но вот где начинается настоящее веселье…
Параметр key
Параметр key — это настоящая швейцарская армейская бритва сортировки. Он принимает функцию, которая будет применяться к каждому элементу перед сравнением. Эта функция должна принимать один аргумент (сам элемент) и возвращать значение, по которому будет производиться сортировка.
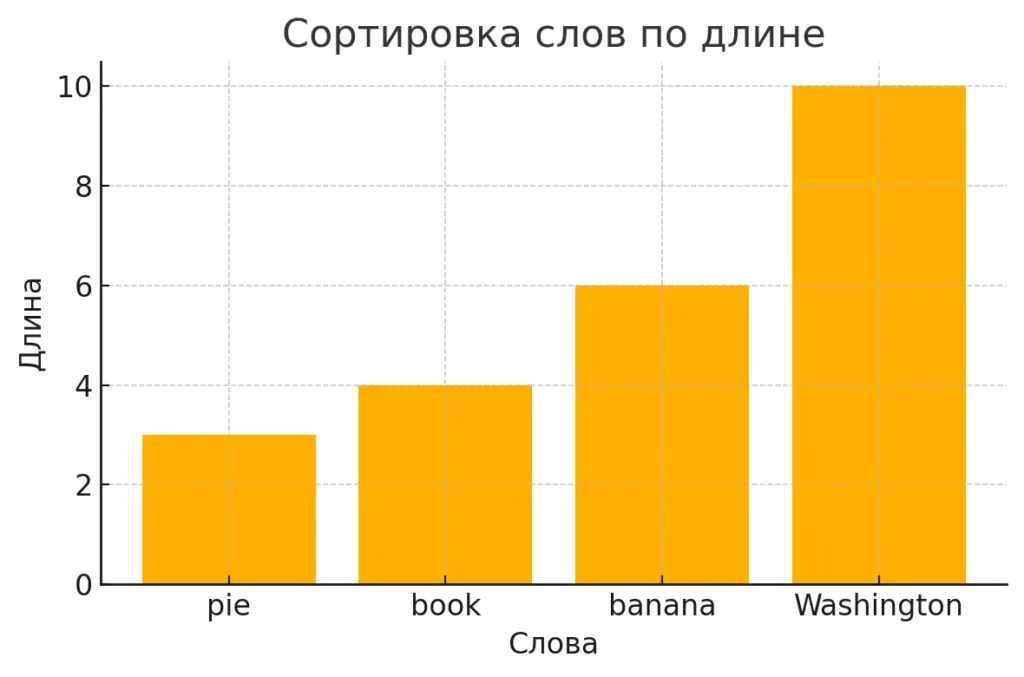
Сортировка слов по длине с использованием параметра key=len
Вот несколько самых распространённых функций, которые можно передать в key:
- len — сортировка по длине (для строк, списков, кортежей).
- str.lower или str.upper — регистронезависимая сортировка строк.
- int — сортировка строковых представлений чисел как чисел.
- abs — сортировка по абсолютному значению.
- Лямбда-функции — для создания собственных правил сортировки на лету.
Давайте рассмотрим несколько примеров:
# Сортировка строк по длине words = ["banana", "pie", "Washington", "book"] print(sorted(words, key=len)) # ['pie', 'book', 'banana', 'Washington'] # Регистронезависимая сортировка mixed_case = ["ape", "Zebra", "elephant"] print(sorted(mixed_case)) # ['Zebra', 'ape', 'elephant'] -- обратите внимание на порядок! print(sorted(mixed_case, key=str.lower)) # ['ape', 'elephant', 'Zebra'] # Сортировка чисел, представленных строками str_numbers = ["10", "2", "1", "20"] print(sorted(str_numbers)) # ['1', '10', '2', '20'] -- лексикографическая сортировка print(sorted(str_numbers, key=int)) # ['1', '2', '10', '20'] -- числовая сортировка
А теперь комбинируем key и reverse:
# Сортировка слов по длине в порядке убывания words = ["banana", "pie", "Washington", "book"] print(sorted(words, key=len, reverse=True)) # ['Washington', 'banana', 'book', 'pie']
Важно помнить, что функция key определяет только значение для сравнения, но в отсортированном результате будут исходные элементы. Это как сортировка людей по росту — в результате вы получите тех же людей, а не набор чисел, представляющих их рост.
Мощь параметра key становится особенно очевидной, когда вы работаете со сложными структурами данных, но об этом мы поговорим в следующих разделах. А пока — экспериментируйте и не бойтесь комбинировать эти параметры для достижения нужного результата!
Сортировка разных типов данных
Сортировка в Python несколько напоминает швейцарский нож — вроде бы инструмент один, но применений масса. В зависимости от типа данных, с которыми вы работаете, сортировка может вести себя по-разному, создавая как приятные сюрпризы, так и неожиданные головные боли. Давайте разберёмся, как Python сортирует различные типы данных и какие особенности нужно учитывать.
Списки чисел и строк
Сортировка чисел в Python — это, пожалуй, самый интуитивно понятный случай. Числа сортируются по их значению, от меньшего к большему:
numbers = [10, 8, 14, 0, 5, 4, 6, 29] print(sorted(numbers)) # [0, 4, 5, 6, 8, 10, 14, 29]
Интереснее становится, когда мы имеем дело со строками. Строки в Python сортируются лексикографически — то есть по значениям Unicode отдельных символов:
strings = ['a', 'v', 'r', 'A', 'd', 'g', 'b', '0', '2', '#', '%', 'ж', 'й'] print(sorted(strings)) # ['#', '%', '0', '2', 'A', 'a', 'b', 'd', 'g', 'r', 'v', 'ж', 'й']
Обратите внимание, что заглавные буквы (‘A’) идут перед строчными (‘a’), потому что их значение Unicode меньше. А ещё раньше идут символы вроде ‘#’ и цифры. Это может быть неинтуитивно, если вы ожидаете алфавитный порядок.
А вот когда мы сортируем строки, представляющие числа, начинается настоящее веселье:
str_numbers = ['10', '8', '14', '0', '5', '4', '6', '29'] print(sorted(str_numbers)) # ['0', '10', '14', '29', '4', '5', '6', '8']
Результат может показаться странным, но он абсолютно логичен, если помнить, что Python сравнивает строки посимвольно. ’10’ идёт раньше ‘8’, потому что первый символ ‘1’ имеет меньшее значение Unicode, чем ‘8’.
Кортежи и множества
Кортежи (tuples) и множества (sets) сортируются аналогично спискам, но с некоторыми нюансами:
# Сортировка кортежа
tuple_values = (7, 28, 4, 22, 6, 10, 7, 18)
print(sorted(tuple_values)) # [4, 6, 7, 7, 10, 18, 22, 28]
# Сортировка множества
set_values = {7, 28, 4, 22, 6, 10, 18}
print(sorted(set_values)) # [4, 6, 7, 10, 18, 22, 28]
Заметьте, что в результате мы получаем списки, а не исходные типы. Это потому, что sorted() всегда возвращает список. Если вам нужен отсортированный кортеж, придётся выполнить дополнительное преобразование:
tuple_sorted = tuple(sorted(tuple_values))
Но когда дело касается множеств, ситуация становится интереснее. Множества в Python — неупорядоченные коллекции, поэтому даже если вы преобразуете отсортированный список обратно в множество, порядок сортировки будет потерян:
set_sorted = set(sorted(set_values)) # Порядок сортировки потерян! print(set_sorted) # Может вывести элементы в любом порядке
Словари
Словари — это отдельная история. Сами по себе словари не имеют определённого порядка (до Python 3.7), но мы можем сортировать их ключи, значения или пары «ключ-значение»:
my_dict = {'b': 1, 'a': 2, 'c': 3}
# Сортировка по ключам
print(sorted(my_dict)) # ['a', 'b', 'c']
# Сортировка по значениям
print(sorted(my_dict.items(), key=lambda x: x[1])) # [('b', 1), ('a', 2), ('c', 3)]
# Создание отсортированного словаря
sorted_dict = {k: my_dict[k] for k in sorted(my_dict)}
print(sorted_dict) # {'a': 2, 'b': 1, 'c': 3}
Вот краткая таблица, что можно сортировать и как:
| Тип данных | Сортировка по умолчанию | Часто используемые параметры key |
|---|---|---|
| Списки чисел | По значению | abs, lambda x: некое_выражение |
| Списки строк | Лексикографически | len, str.lower, str.strip |
| Кортежи | Как списки | Те же, что и для списков |
| Множества | Как списки | Те же, что и для списков |
| Словари | По ключам | lambda item: item[1] (для сортировки по значениям) |
| Списки списков | По первому элементу | lambda x: x[индекс] |
| Списки словарей | Ошибка — несравнимые типы | lambda d: d[‘ключ’] |
Помните, что Python может сортировать только сравнимые между собой элементы. Если вы попытаетесь отсортировать список, содержащий, например, числа и строки, Python выдаст ошибку. В таких случаях спасает параметр key, который может приводить разнотипные элементы к одному типу для сравнения.
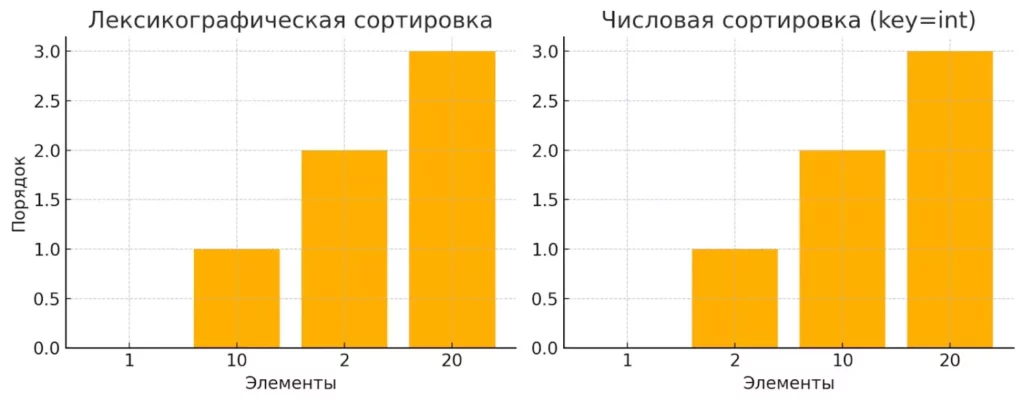
Разница между лексикографической и числовой сортировкой строковых чисел.
Пользовательские правила сортировки с lambda и operator
Когда стандартные методы сортировки уже не справляются с вашими изощрёнными требованиями, на сцену выходят более продвинутые инструменты — lambda-функции и модуль operator. Это как перейти от обычной отвёртки к электрическому шуруповёрту — те же базовые принципы, но возможностей куда больше.
Лямбда-функции в сортировке
Лямбда-функции — это анонимные функции «одноразового использования», которые идеально подходят для передачи в параметр key. Они позволяют определить собственное правило сортировки прямо на месте, без необходимости создавать отдельную именованную функцию:
# Сортировка по последней букве слова
words = ["cookie", "banana", "donut", "pizza"]
print(sorted(words, key=lambda word: word[-1]))
# Результат: ['banana', 'pizza', 'cookie', 'donut']
# Сортировка списка кортежей по второму элементу
data = [('John', 25), ('Alice', 22), ('Bob', 30)]
print(sorted(data, key=lambda x: x[1]))
# Результат: [('Alice', 22), ('John', 25), ('Bob', 30)]
# Сортировка списка словарей по вложенному значению
users = [
{'name': 'Helen', 'profile': {'age': 24, 'score': 85}},
{'name': 'John', 'profile': {'age': 21, 'score': 90}},
{'name': 'Sam', 'profile': {'age': 19, 'score': 80}}
]
print(sorted(users, key=lambda user: user['profile']['score']))
# Результат: [Sam, Helen, John] (сортировка по score)
Лямбда-функции могут содержать любую логику, которая вам нужна, но их синтаксис ограничен одним выражением. Если вам нужна более сложная логика, лучше определить именованную функцию и использовать её:
def custom_sort_key(item): # Сложная логика сортировки if some_condition: return value1 else: return value2 sorted_data = sorted(data, key=custom_sort_key)
Модуль operator для более лаконичного кода
Если вы часто сортируете списки кортежей или словарей по определенным полям, ваш код может быстро зарасти однотипными лямбда-функциями. Модуль operator предлагает более лаконичные альтернативы:
from operator import itemgetter, attrgetter, methodcaller
# Сортировка списка кортежей по второму и затем первому элементу
data = [('John', 25), ('Alice', 22), ('Bob', 30), ('Eve', 22)]
print(sorted(data, key=itemgetter(1, 0)))
# Результат: [('Alice', 22), ('Eve', 22), ('John', 25), ('Bob', 30)]
# То же самое с lambda выглядело бы так:
# sorted(data, key=lambda x: (x[1], x[0]))
Основные функции модуля operator для сортировки:
- itemgetter(index1, index2, …) — для получения значений по индексам (для списков, кортежей) или ключам (для словарей).
- attrgetter(‘attr1’, ‘attr2’, …) — для получения значений атрибутов объектов.
- methodcaller(‘method’, *args) — для вызова методов объектов с аргументами.
Сравнение lambda и функций из operator:
| Задача | С использованием lambda | С использованием operator |
|---|---|---|
| Сортировка по второму элементу | key=lambda x: x[1] | key=itemgetter(1) |
| Сортировка по нескольким полям | key=lambda x: (x[1], x[0]) | key=itemgetter(1, 0) |
| Сортировка объектов по атрибуту | key=lambda obj: obj.attr | key=attrgetter(‘attr’) |
| Вызов метода объекта | key=lambda obj: obj.method() | key=methodcaller(‘method’) |
Преимущество функций из модуля operator не только в лаконичности, но и в производительности — они работают быстрее, чем эквивалентные лямбда-функции.
# Пример с сортировкой объектов
class Student:
def __init__(self, name, grade, age):
self.name = name
self.grade = grade
self.age = age
def __repr__(self):
return f"Student({self.name}, {self.grade}, {self.age})"
students = [
Student('John', 'A', 15),
Student('Jane', 'B', 12),
Student('Dave', 'B', 10)
]
# Сортировка по возрасту, затем по оценке
print(sorted(students, key=attrgetter('age', 'grade')))
# Результат: [Student(Dave, B, 10), Student(Jane, B, 12), Student(John, A, 15)]
Выбор между лямбда-функциями и operator — это часто компромисс между гибкостью и лаконичностью. Лямбды дают вам больше свободы в определении правил сортировки, но для простых случаев функции из operator делают код более чистым и понятным.
Сортировка пользовательских объектов
Если обычная сортировка чисел и строк — это езда на велосипеде, то сортировка пользовательских объектов — это управление космическим кораблём. Технически принципы те же, но уровень сложности и возможностей возрастает в разы. Когда вы работаете с собственными классами, Python не может автоматически понять, как их сравнивать — ведь что означает «больше» для объекта типа Person или Student? Здесь на помощь приходят уже знакомые нам инструменты: параметр key, лямбда-функции и модуль operator.
Создание собственного класса для демонстрации
Давайте создадим класс Person, чтобы понять, как работает сортировка пользовательских объектов:
class Person:
def __init__(self, name, age, salary):
self.name = name
self.age = age
self.salary = salary
def __repr__(self):
return f"Person('{self.name}', {self.age}, {self.salary})"
# Создаём список людей
people = [
Person('Alice', 30, 70000),
Person('Bob', 25, 50000),
Person('Charlie', 35, 80000),
Person('Diana', 28, 65000)
]
Метод __repr__ здесь не просто украшение — он делает вывод результатов сортировки читаемым и понятным. Без него вы увидели бы что-то вроде <__main__.Person object at 0x7f8b8c0b4f40>, что не очень информативно.
Теперь попробуем отсортировать наш список:
# Это НЕ сработает! sorted(people) # TypeError: '<' not supported between instances of 'Person' and 'Person'
Python не знает, как сравнивать объекты Person между собой. Нам нужно явно указать, по какому критерию сортировать.
Сортировка по одному атрибуту
Самый простой случай — сортировка по одному полю объекта:
# Сортировка по возрасту
by_age = sorted(people, key=lambda person: person.age)
print(by_age)
# [Person('Bob', 25, 50000), Person('Diana', 28, 65000),
# Person('Alice', 30, 70000), Person('Charlie', 35, 80000)]
# Сортировка по зарплате (по убыванию)
by_salary = sorted(people, key=lambda person: person.salary, reverse=True)
print(by_salary)
# [Person('Charlie', 35, 80000), Person('Alice', 30, 70000),
# Person('Diana', 28, 65000), Person('Bob', 25, 50000)]
# Сортировка по имени (алфавитный порядок)
by_name = sorted(people, key=lambda person: person.name)
print(by_name)
# [Person('Alice', 30, 70000), Person('Bob', 25, 50000),
# Person('Charlie', 35, 80000), Person('Diana', 28, 65000)]
Использование attrgetter делает код более лаконичным:
from operator import attrgetter
# То же самое, но короче и быстрее
by_age = sorted(people, key=attrgetter('age'))
by_salary = sorted(people, key=attrgetter('salary'), reverse=True)
by_name = sorted(people, key=attrgetter('name'))
Сортировка по нескольким критериям
Реальная жизнь редко позволяет ограничиться одним критерием сортировки. Представьте HR-отдел, который хочет отсортировать кандидатов сначала по возрасту, а затем по зарплатным ожиданиям:
# Сортировка по возрасту, затем по зарплате
multi_sort = sorted(people, key=lambda person: (person.age, person.salary))
print(multi_sort)
# С использованием attrgetter (более эффективно)
multi_sort = sorted(people, key=attrgetter('age', 'salary'))
print(multi_sort)
Но что, если нам нужно сортировать по возрасту по возрастанию, а по зарплате — по убыванию? Здесь придётся проявить изобретательность:
# Сортировка по возрасту (возрастание), затем по зарплате (убывание) complex_sort = sorted(people, key=lambda person: (person.age, -person.salary)) print(complex_sort)
Трюк с отрицательным значением работает только для чисел. Для строк можно использовать более сложную логику или несколько этапов сортировки.
Пример с классом Student
Давайте рассмотрим более реалистичный пример с классом Student:
class Student:
def __init__(self, name, grade, gpa, age):
self.name = name
self.grade = grade # Класс обучения (9, 10, 11)
self.gpa = gpa # Средний балл
self.age = age
def __repr__(self):
return f"Student('{self.name}', {self.grade}, {self.gpa}, {self.age})"
students = [
Student('Emma', 11, 4.0, 17),
Student('Liam', 10, 3.8, 16),
Student('Olivia', 11, 3.9, 17),
Student('Noah', 9, 3.7, 15),
Student('Ava', 10, 4.0, 16),
Student('William', 11, 3.6, 18)
]
# Сортировка по классу, затем по среднему баллу (по убыванию)
sorted_students = sorted(students,
key=lambda s: (s.grade, -s.gpa))
for student in sorted_students:
print(f"{student.name}: {student.grade} класс, GPA: {student.gpa}")
# Результат:
# Noah: 9 класс, GPA: 3.7
# Ava: 10 класс, GPA: 4.0
# Liam: 10 класс, GPA: 3.8
# Emma: 11 класс, GPA: 4.0
# Olivia: 11 класс, GPA: 3.9
# William: 11 класс, GPA: 3.6
Сортировка объектов с вложенными атрибутами
Иногда объекты содержат другие объекты, и нужно сортировать по их атрибутам:
class Address:
def __init__(self, city, street):
self.city = city
self.street = street
class Employee:
def __init__(self, name, department, address):
self.name = name
self.department = department
self.address = address
def __repr__(self):
return f"Employee('{self.name}', '{self.department}', '{self.address.city}')"
employees = [
Employee('John', 'IT', Address('Moscow', 'Tverskaya')),
Employee('Jane', 'HR', Address('Saint Petersburg', 'Nevsky')),
Employee('Mike', 'IT', Address('Moscow', 'Arbat'))
]
# Сортировка по городу, затем по отделу
sorted_employees = sorted(employees,
key=lambda emp: (emp.address.city, emp.department))
# С использованием attrgetter для вложенных атрибутов
sorted_employees = sorted(employees,
key=attrgetter('address.city', 'department'))
Полезные паттерны для сортировки объектов
Вот несколько часто используемых паттернов:
# 1. Сортировка с обработкой None значений
people_with_none = [
Person('Alice', 30, None),
Person('Bob', None, 50000),
Person('Charlie', 35, 80000)
]
safe_sort = sorted(people_with_none,
key=lambda p: (p.age is None, p.age or 0))
# 2. Регистронезависимая сортировка по строковому полю
sorted_by_name = sorted(people, key=lambda p: p.name.lower())
# 3. Сортировка по длине строкового атрибута
sorted_by_name_length = sorted(people, key=lambda p: len(p.name))
# 4. Комбинированная сортировка с приоритетом
priority_sort = sorted(students,
key=lambda s: (s.grade != 11, # 11 класс в приоритете
-s.gpa, # Высокий GPA в приоритете
s.name)) # Алфавитный порядок
Работа с пользовательскими объектами требует более вдумчивого подхода к сортировке, но открывает огромные возможности для создания сложной логики упорядочивания данных. Главное — чётко понимать, по каким критериям нужно сортировать, и не забывать про граничные случаи вроде None значений или пустых строк.
Особенности и ловушки при сортировке
Сортировка в Python — это как минное поле: кажется, что всё просто, пока не наступишь на одну из многочисленных скрытых ловушек. Я столкнулся с большинством из них, и, поверьте, некоторые баги, связанные с сортировкой, могут заставить вас рвать на себе волосы часами. Давайте рассмотрим самые коварные подводные камни.
Несовместимые типы данных
Python не может сравнивать яблоки с апельсинами — в буквальном смысле. Если вы попытаетесь отсортировать список, содержащий элементы несовместимых типов, Python вежливо (а иногда не очень) сообщит вам об ошибке:
mixed_types = [1, "hello", 3.14, True] sorted(mixed_types) # TypeError: '<' not supported between instances of 'str' and 'int'
Проблема в том, что Python не знает, как сравнивать строку «hello» с числом 1. Они относятся к разным типам данных, которые не имеют естественного порядка между собой.
Решение? Используйте параметр key для приведения всех элементов к одному типу:
# Например, превращаем всё в строки sorted(mixed_types, key=str) # [1, 3.14, True, "hello"]
Сортировка с учётом регистра
По умолчанию Python сортирует строки с учётом регистра, и заглавные буквы идут перед строчными:
sorted(["Apple", "banana", "Cherry"]) # ["Apple", "Cherry", "banana"]
Это может быть неожиданно, если вы ожидаете алфавитный порядок независимо от регистра. Решение простое:
sorted(["Apple", "banana", "Cherry"], key=str.lower) # ["Apple", "banana", "Cherry"]
Неочевидное поведение при сортировке чисел в виде строк
Если у вас есть числа, представленные в виде строк, они будут сортироваться лексикографически, а не по числовому значению:
sorted(["1", "10", "2", "20"]) # ["1", "10", "2", "20"]
Это происходит потому, что «10» лексикографически меньше «2», так как первый символ «1» меньше «2». Для числовой сортировки:
sorted(["1", "10", "2", "20"], key=int) # ["1", "2", "10", "20"]
Сортировка с None значениями
Если в вашем списке есть None значения, сортировка может стать проблематичной:
data = [3, 1, None, 5, None] sorted(data) # TypeError: '<' not supported between instances of 'NoneType' and 'int'
Решение — использовать функцию, которая обрабатывает None особым образом:
sorted(data, key=lambda x: (x is None, x)) # [1, 3, 5, None, None]
Это работает, потому что кортежи сравниваются поэлементно, и False (результат x is None для чисел) всегда меньше, чем True (для None).
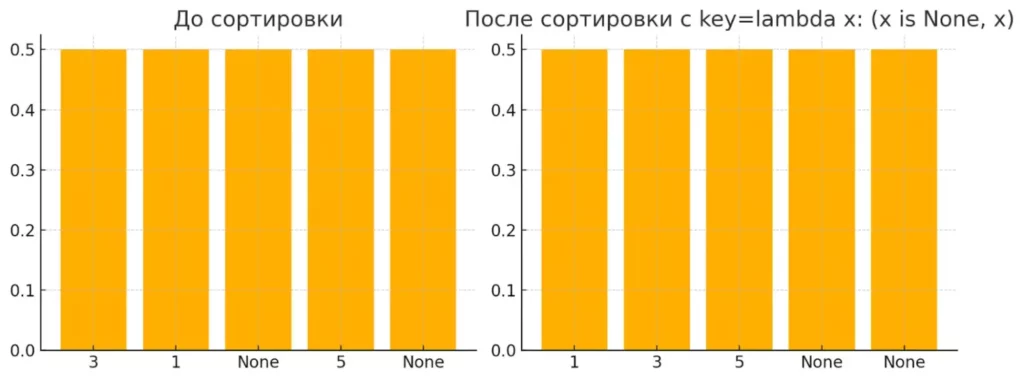
Как влияет параметр key на сортировку элементов с None.
Стабильность сортировки
Одна из особенностей сортировки в Python (которая на самом деле является преимуществом) — это её стабильность. Это означает, что если два элемента равны по ключу сортировки, их относительный порядок сохраняется:
data = [("red", 1), ("blue", 1), ("red", 2), ("blue", 2)]
sorted(data, key=lambda x: x[1]) # [("red", 1), ("blue", 1), ("red", 2), ("blue", 2)]
Обратите внимание, что «red» остаётся перед «blue» для элементов с одинаковым вторым значением, потому что так они были расположены в исходном списке.
Многоуровневая сортировка по нескольким критериям
Если вы хотите сортировать по нескольким критериям (например, сначала по возрасту, затем по имени), создание кортежа в функции key может привести к неожиданным результатам, если один из критериев может быть None:
users = [
{"name": "Alice", "age": 25},
{"name": "Bob", "age": None},
{"name": "Charlie", "age": 30}
]
# Это НЕ сработает
sorted(users, key=lambda x: (x["age"], x["name"])) # TypeError
Решение — обрабатывать None отдельно или использовать более сложную логику сортировки.
Помните: когда дело касается сортировки в Python, доверяй, но проверяй. Всегда тестируйте ваш код с разными входными данными, включая граничные случаи, чтобы избежать неприятных сюрпризов в продакшене.
Как выбрать подходящий способ сортировки
Выбор между .sort() и sorted() подобен извечной дилемме «пицца с ананасами или без». У каждого варианта есть свои ярые поклонники, но правильный ответ часто зависит от конкретной ситуации (хотя, если честно, ананас на пицце — это преступление против всего итальянского наследия, но я отвлёкся).
Вот несколько ключевых критериев, которые помогут вам принять решение:
Нужна ли вам неизменяемость исходных данных
Это, пожалуй, самый важный вопрос. Если вы работаете с данными, которые ни в коем случае нельзя изменять (например, они используются в другом месте программы или передаются в другие функции), то sorted() — ваш единственный безопасный выбор.
Важна ли производительность
Метод .sort() немного эффективнее, чем sorted(), поскольку ему не нужно создавать копию списка. Разница минимальна для небольших списков, но может стать заметной при работе с огромными объёмами данных.
С каким типом данных вы работаете
Если у вас не список, а, например, кортеж или множество, то у вас просто нет выбора — только sorted().
Вот таблица, которая поможет вам быстро определиться:
| Ситуация | Рекомендация |
|---|---|
| Вы работаете не со списком | sorted() — единственный вариант |
| Вам нужно сохранить оригинальные данные | sorted() — создаст копию |
| Вам не нужен оригинал и важна производительность | .sort() — быстрее и экономнее по памяти |
| Вы хотите использовать результат в выражении | sorted() — возвращает новый список |
| Вы хотите сортировать список большой размер на месте | .sort() — меньше накладных расходов |
| Вам нужно сортировать список в цепочке методов | Ни один не подходит напрямую, .sort() вернёт None |
Вот пример с реальной ситуацией, которая иллюстрирует важность правильного выбора:
# Представим, что у нас есть данные о заказах
orders = [
{"id": 1, "customer": "Alice", "amount": 150, "status": "new"},
{"id": 2, "customer": "Bob", "amount": 200, "status": "processing"},
{"id": 3, "customer": "Charlie", "amount": 100, "status": "new"}
]
# Мы хотим отфильтровать новые заказы и отсортировать их по сумме
new_orders = [order for order in orders if order["status"] == "new"]
# Неправильный подход:
new_orders.sort(key=lambda x: x["amount"])
sorted_orders = new_orders # sorted_orders и new_orders -- это один и тот же список!
# Правильный подход, если мы хотим сохранить оригинал:
sorted_orders = sorted(new_orders, key=lambda x: x["amount"])
# Теперь new_orders содержит исходные данные, а sorted_orders -- отсортированную копию
Помните, что выбор метода сортировки — это часть более широкого контекста проектирования вашего кода. Думайте не только о текущей задаче, но и о том, как ваш код будет использоваться и изменяться в будущем. Иногда стоит пожертвовать небольшим преимуществом в производительности ради большей ясности и безопасности кода.
Заключение
Сортировка в Python — это мощный инструмент, который при правильном использовании может значительно упростить работу с данными. Мы рассмотрели два основных способа сортировки — встроенную функцию sorted() и метод списков .sort(). Первый создаёт новый отсортированный список, оставляя оригинал нетронутым, второй изменяет исходный список на месте.
Ключевые моменты, которые стоит запомнить:
- Используйте sorted(), когда нужно сохранить оригинальные данные или когда работаете с не-списками.
- Метод .sort() подходит, когда важна производительность и не нужно сохранять исходный порядок.
- Параметры key и reverse позволяют настроить логику сортировки под ваши конкретные нужды.
- При работе с разными типами данных или сложными структурами будьте внимательны к возможным ловушкам.
Мой совет — не ограничивайтесь теорией. Экспериментируйте с кодом, пробуйте разные комбинации параметров и типов данных. Только так можно по-настоящему понять все нюансы сортировки в Python. А если хотите стать айтишником, то изучите курсы по Python-разработке. На странице с подборкой найдете несколько вариантов, так что сможете выбрать на свой вкус.
Рекомендуем посмотреть курсы по Python
| Курс | Школа | Цена | Рассрочка | Длительность | Дата начала | Ссылка на курс |
|---|---|---|---|---|---|---|
|
Профессия Python-разработчик
|
Eduson Academy
83 отзыва
|
Цена
Ещё -5% по промокоду
95 000 ₽
|
От
7 917 ₽/мес
|
Длительность
6 месяцев
|
Старт
27 декабря
|
Ссылка на курс |
|
Go-разработчик (Junior)
|
Level UP
36 отзывов
|
Цена
45 500 ₽
|
От
11 375 ₽/мес
|
Длительность
3 месяца
|
Старт
27 января
|
Ссылка на курс |
|
Fullstack-разработчик на Python
|
Нетология
45 отзывов
|
Цена
с промокодом kursy-online
146 500 ₽
308 367 ₽
|
От
4 282 ₽/мес
|
Длительность
18 месяцев
|
Старт
1 января
|
Ссылка на курс |
|
Python-разработчик
|
Академия Синергия
34 отзыва
|
Цена
91 560 ₽
228 900 ₽
|
От
3 179 ₽/мес
4 552 ₽/мес
|
Длительность
6 месяцев
|
Старт
6 января
|
Ссылка на курс |
|
Профессия Python-разработчик
|
Skillbox
205 отзывов
|
Цена
Ещё -20% по промокоду
74 507 ₽
149 015 ₽
|
От
6 209 ₽/мес
9 715 ₽/мес
|
Длительность
12 месяцев
|
Старт
25 декабря
|
Ссылка на курс |

Что такое продуктивность и как её повысить
Продуктивность это не гонка за количеством задач, а умение достигать значимых целей. В статье разберёмся, как измерять её правильно и какие привычки помогают работать эффективнее.

Стратегия автоматизации тестирования: этапы успеха
Хотите, чтобы автоматизация тестирования приносила реальную пользу, а не становилась тратой времени? Расскажем о каждом этапе стратегии и поделимся

Как развивалось тестирование ПО: от начала до наших дней
Как тестировали программы в 1940-х? Когда появилась автоматизация? Что такое пирамида тестирования? Разбираем ключевые этапы истории тестирования ПО.

От веба к десктопу: как PHP помогает создавать приложения для Windows
PHP как инструмент для десктопной разработки? Узнайте, как PHP Desktop помогает создавать приложения на Windows без переписывания кода