Языки для анализа данных — какой язык программирования выбрать
Языки для анализа данных — какой язык программирования выбрать
#Блог
Выбор языка программирования для анализа данных — ключевой шаг на пути к успеху в Data Science. В этом курсе мы рассмотрим особенности и преимущества самых популярных языков, которые помогут сделать осознанный выбор.
Материал будет полезен как новичкам, которые только начинают, так и опытным специалистам, желающим расширить арсенал инструментов для работы с данными. Мы разберем экосистему, производительность и область применения каждого языка, чтобы вы смогли выбрать наиболее подходящий именно вам.
Критерии выбора языка программирования для Data Science
Итак, друзья мои, давайте поговорим о том, как выбрать "того самого" в мире языков программирования для Data Science. Это почти как выбор спутника жизни, только тут вы можете экспериментировать с несколькими одновременно, и никто вас за это не осудит (по крайней мере, в IT-сообществе).
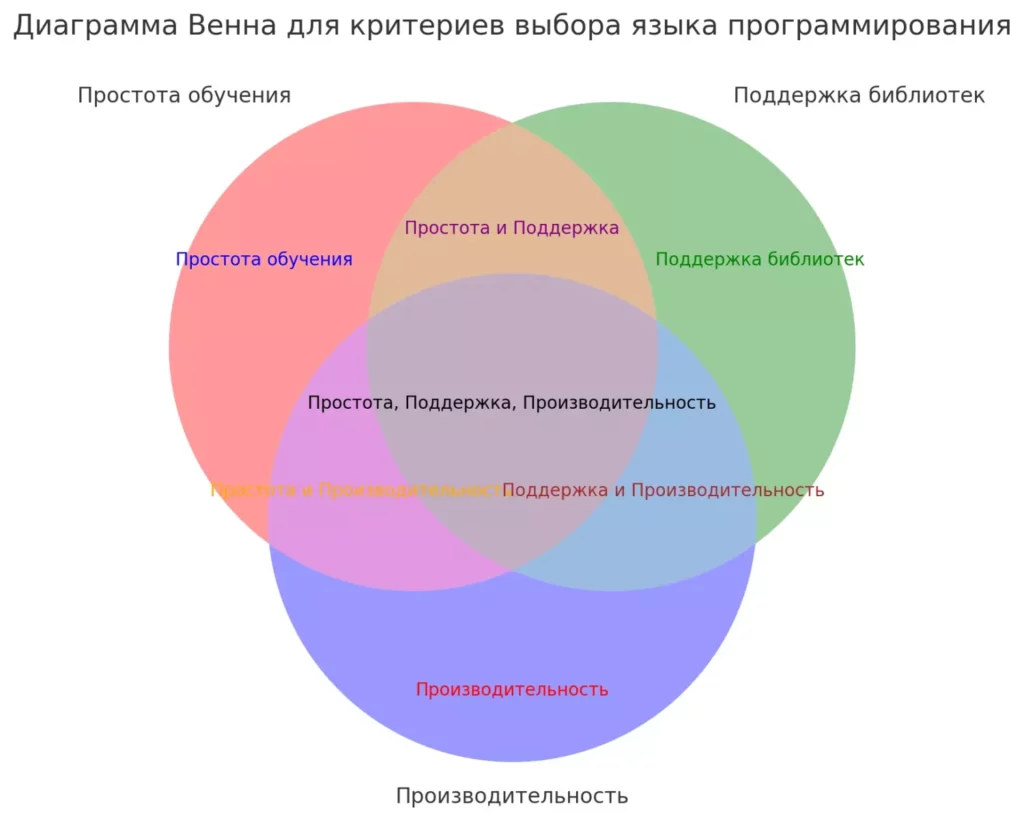
Вот вам список критериев, которые стоит учитывать при выборе языка программирования для анализа данных (спойлер: "потому что так сказал босс" - не входит в этот список):
Производительность: потому что жизнь слишком коротка, чтобы ждать, пока ваш код обработает датасет.
Простота обучения: если вам нужен PhD по квантовой физике, чтобы написать "Hello, World!", возможно, это не ваш язык.
Поддержка библиотек: чем больше, тем лучше. Ведь зачем изобретать велосипед, когда можно взять готовый спорткар?
Сообщество: потому что даже Data Scientists иногда нужны друзья (особенно когда код не работает в 3 часа ночи).
Совместимость с другими инструментами: ваш язык должен уметь "общаться" с другими, иначе он рискует стать изгоем в мире технологий.
Возможности визуализации: потому что даже самые крутые инсайты бесполезны, если вы не можете их красиво представить (особенно боссу, который не понимает ничего сложнее круговой диаграммы).
Скорость разработки: потому что дедлайны - это не миф, а суровая реальность.
Диаграмма Венна для критериев выбора языка программирования, учитывающая следующие требования: простота обучения, поддержка библиотек и производительность
Помните, идеального языка не существует (как и идеальных отношений, но это уже тема для другого блога). Каждый язык имеет свои сильные и слабые стороны. Ваша задача - найти тот, который подходит именно вам и вашим задачам. И да, это может быть настоящим квестом, но кто сказал, что жизнь data-аналитика должна быть скучной?
Популярные языки программирования для анализа данных и их особенности
Python – ваш швейцарский нож в мире Data Science
Python! Этот язык как тот парень из старшей школы - вроде бы ничем особо не выделяется, но почему-то нравится всем. И, надо признать, не зря.
Python - это как Джек-Воробей в мире программирования: вроде пират, а вроде и джентльмен удачи. Он универсален, прост в освоении (ну, насколько вообще может быть простым язык программирования) и имеет огромное сообщество фанатов. Кажется, половина интернета написана на Python. По крайней мере, такое у меня сложилось оценочное суждение после очередной бессонной ночи за кодом.
Но главная прелесть Python - это его библиотеки. О, эти библиотеки! Их так много, что иногда кажется, будто ты в Хогвартсе, только вместо заклинаний - функции, а вместо волшебных палочек - IDE. Вот вам небольшая таблица самых "магических" библиотек:
Библиотека
Для чего нужна
Магическая сила
NumPy
Для работы с массивами и матрицами
Превращает ваш код в калькулятор на стероидах
Pandas
Для анализа данных
Заставляет Excel нервно курить в сторонке
Scikit-learn
Для машинного обучения
Делает из вас Нео из "Матрицы" (ну почти)
Matplotlib
Для визуализации
Рисует графики лучше, чем вы в Paint
TensorFlow
Для глубокого обучения
Позволяет создавать нейросети, которые умнее некоторых ваших коллег
Python универсален не только в Data Science, но и в смежных областях: автоматизации, веб-разработке и даже DevOps. Его востребованность растет, и это гарантирует поддержку сообщества и адаптацию к новым технологиям.
Но у Python есть и свои недостатки. Например, он может быть медленнее некоторых других языков. Хотя, давайте будем честными, в эпоху, когда люди готовы ждать 5 секунд, пока загрузится видео с котиками, вряд ли кто-то заметит разницу в несколько миллисекунд в работе вашего кода.
В общем, если вы новичок в мире Data Science или просто хотите язык, который сможет справиться практически с любой задачей, Python - ваш верный спутник. Только не привязывайтесь к нему слишком сильно, у нас еще целый зоопарк языков впереди!
R – статистический гений с творческой жилкой
Если Python - это швейцарский нож в мире Data Science, то R - это скальпель нейрохирурга. Точный, острый и немного пугающий, если вы не знаете, как с ним обращаться.
R - это язык, созданный статистиками для статистиков. И, надо сказать, они знали, что делают. Этот язык настолько хорош в статистическом анализе, что порой кажется, будто он может найти корреляцию даже там, где ее нет. (Спойлер: он не может, но иногда так хочется верить...)
Главная фишка R - это его способность превращать сухие цифры в произведения искусства. Серьезно, графики и визуализации, которые можно создать с помощью R, настолько красивы, что их впору вешать на стену вместо картин. Особенно если ваша вторая половинка тоже data scientist.
Вот несколько популярных библиотек R, которые превратят вас в настоящего волшебника данных:
ggplot2 - для создания графиков, от которых закружится голова (в хорошем смысле).
dplyr - для манипуляций с данными, которые заставят вас почувствовать себя повелителем цифр.
caret - для машинного обучения, потому что даже R иногда хочет поиграть в AI.
shiny - для создания веб-приложений, чтобы показать всему миру, какой вы крутой аналитик.
R особенно любят в академических кругах и в сфере биостатистики. Если вам нужно проанализировать результаты клинических испытаний или разобраться в геномных данных, R - ваш лучший друг.
Но у R есть и свои недостатки. Например, кривая обучения у него крутая, как американские горки. И синтаксис... ну, скажем так, на любителя. Иногда код на R выглядит как шифровка инопланетян. Но эй, кто сказал, что быть гением статистики должно быть легко?
В общем, если вы любите статистику так же сильно, как я люблю кофе в понедельник утром, R - это ваш язык. Просто будьте готовы к тому, что первое время вы будете чувствовать себя как Алиса в Стране чудес. Но поверьте, оно того стоит!
SQL – дедушка баз данных, который все еще в деле
SQL. Старый добрый SQL. Этот язык как ваш дедушка: вроде бы древний, но все еще может удивить, особенно когда речь заходит о его любимой теме - базах данных.
SQL (произносится "эс-кью-эл" или "сиквел", если вы хотите звучать как крутой хакер из 90-х) - это не просто язык, это целая философия работы с данными. Если бы Платон занимался программированием, он бы точно выбрал SQL.
SQL идеально подходит для корпоративного уровня благодаря своей устойчивости и стандартизации. Это делает его надёжным для работы с критически важными данными и помогает избежать сбоев, поддерживая стабильность даже при масштабировании.
Главная сила SQL в том, что он позволяет работать с реляционными базами данных так же легко, как вы листаете ленту в соцсетях. Ну, может, не совсем так легко, но вы поняли идею. SQL - это как швейцарский нож для работы с большими объемами структурированных данных. Только вместо открывашки для бутылок у него функция JOIN, а вместо ножниц - WHERE.
Вот несколько причин, почему SQL все еще актуален (кажется, по крайней мере таково моё личное оценочное суждение):
Он прост в освоении. Серьезно, его синтаксис похож на обычный английский. SELECT * FROM beers WHERE alcohol_content > 5 - это же практически поэзия!
Он везде. Почти каждая компания, у которой есть данные (а у кого их сейчас нет?), использует SQL в той или иной форме.
Он мощный. С помощью SQL можно делать такие вещи с данными, о которых Excel даже не мечтал.
Он стандартизирован. Хотя, конечно, каждая СУБД любит добавить что-то свое, базовый SQL работает везде.
Конечно, у SQL есть и свои недостатки. Например, он не очень хорош для работы с неструктурированными данными. И да, иногда запросы могут выглядеть как заклинания на латыни. Но эй, разве не в этом половина удовольствия?
В общем, если вы хотите стать настоящим повелителем данных, SQL - это то, что вам нужно. Просто помните: с большой выборкой приходит большая ответственность. И возможно, необходимость в более мощном компьютере.
Java и Scala – когда большие данные становятся действительно большими
Java и Scala - эта парочка напоминает мне старого морского волка и его молодого, амбициозного помощника. Java - это тот самый капитан, который видел всякое и может управлять кораблем даже в шторм. Scala же - это юнга, который знает все новые трюки и может взобраться на мачту быстрее, чем вы скажете "большие данные".
Начнем с Java. Этот язык, кажется, существует столько же, сколько и сами компьютеры (на самом деле нет, но вы поняли). Java - это как черный костюм в мире программирования: всегда уместен и никогда не выходит из моды. Особенно когда речь идет о работе с действительно большими объемами данных.
Scala, с другой стороны, это как модный пиджак с блестками - вроде и классика, но с изюминкой. Она работает на Java Virtual Machine (JVM), что делает ее совместимой со всей экосистемой Java, но при этом добавляет функциональное программирование и более лаконичный синтаксис.
Вот почему эта парочка так хороша для Big Data:
Производительность: Когда у вас петабайты данных, каждая миллисекунда на вес золота. Java и Scala могут обрабатывать огромные объемы данных быстрее, чем вы успеете сказать "IndexOutOfBoundsException".
Масштабируемость: Эти языки отлично работают в распределенных системах. Apache Spark, например, написан на Scala и часто используется с Java.
Стабильность: Java настолько стабильна, что ее можно использовать как фундамент для дома. Ну, или для вашего data pipeline.
Экосистема: Hadoop, Spark, Flink - все эти большие мальчики в мире Big Data говорят на Java или Scala.
Конечно, у этих языков есть и свои недостатки. Java, например, иногда бывает многословной - код на ней может быть длиннее, чем список покупок моей жены перед праздниками. Scala же может быть сложной для новичков - ее синтаксис порой напоминает шифр Энигмы.
Но если вы готовы потратить время на их изучение, Java и Scala могут стать вашими лучшими друзьями в мире больших данных. Просто помните: с большой силой приходит большая ответственность. И, возможно, необходимость в большем количестве кофе.
Julia – новичок с амбициями
Представьте себе вечеринку программистов (да, такое бывает, и нет, это не так скучно, как звучит). Python, R и Java уже давно тусуются у барной стойки, обсуждая свои подвиги в мире Data Science. И тут входит она - Julia. Молодая, амбициозная, с блеском в глазах и кодом, который выполняется быстрее, чем вы успеваете сказать "производительность".
Julia - это как тот вундеркинд, который в 5 лет уже решает дифференциальные уравнения, пока остальные еще учатся считать до 10. Созданная в 2012 году группой энтузиастов из MIT, Julia быстро завоевала симпатии в научных кругах и среди тех, кому нужна скорость выполнения кода и при этом простота Python.
Вот несколько причин, почему Julia заслуживает вашего внимания:
Скорость: Julia может быть такой же быстрой, как C, но при этом такой же понятной, как Python. Это как если бы ваш любимый ленивый кот вдруг начал бегать со скоростью гепарда.
Легкость в изучении: Если вы знаете Python или MATLAB, освоить Julia будет проще простого. Это как пересесть с велосипеда на мотоцикл - принцип тот же, только едешь быстрее.
Математическая ориентированность: Julia просто обожает математику. Если ваша работа связана с научными вычислениями, Julia будет для вас как манна небесная.
Параллельные вычисления: Julia умеет эффективно использовать все ядра вашего процессора. Это как если бы у вас была команда клонов, работающих одновременно.
Но, как и у любого молодого гения, у Julia есть свои проблемы роста. Например, ее экосистема пакетов не такая богатая, как у Python или R. И да, найти ответ на свой вопрос на Stack Overflow может быть сложнее, чем для более популярных языков.
Тем не менее, Julia - это как инвестиция в стартап: рискованно, но потенциальная выгода огромна. Если вы работаете с большими объемами данных, занимаетесь научными вычислениями или просто любите быть на острие технологий, Julia определенно стоит вашего внимания.
Только помните: с большой скоростью приходит большая ответственность. И возможно, необходимость в более мощном кулере для вашего процессора.
Сравнительная таблица языков программирования
Итак, дорогие мои любители цифр и графиков, настало время для главного блюда нашего информационного пира – сравнительной таблицы языков программирования. Приготовьтесь, сейчас будет жарко (и, возможно, немного субъективно).
Критерий
Python
R
SQL
Java
Scala
Julia
Производительность
Средняя
Средняя
Высокая для запросов
Высокая
Высокая
Очень высокая
Простота использования
Очень высокая
Средняя
Высокая
Средняя
Низкая
Высокая
Наличие библиотек
Огромное
Огромное
Ограниченное
Большое
Среднее
Растущее
Объем сообщества
Огромный
Большой
Огромный
Огромный
Средний
Растущий
Применение в Data Science
Универсальное
Статистика
Работа с БД
Big Data
Big Data
Научные вычисления
Машинное обучение
Отлично
Хорошо
Ограниченно
Хорошо
Хорошо
Перспективно
Теперь давайте разберем эту таблицу, как настоящие дата-сайентисты (только без применения машинного обучения, обещаю).
Python выглядит как золотая середина – этакий швейцарский нож в мире Data Science. Он не самый быстрый, зато с ним справится даже ваша бабушка (ну, может быть, не сразу, но точно быстрее, чем освоит TikTok).
R – это как спортивная машина для статистиков. Быстрая, мощная, но требует навыков вождения. И да, иногда может быть капризной, как итальянское спорткупе.
SQL – дедушка в мире баз данных, который все еще может дать фору молодежи. Особенно если речь идет о работе с реляционными базами данных. Он как старый рок-н-ролл – никогда не выйдет из моды.
Java и Scala – это как отец и сын в мире Big Data. Java – надежный, проверенный временем. Scala – молодой, амбициозный, с нотками функционального программирования.
Julia – новичок в этой компании, но с большими амбициями. Она как тот вундеркинд в классе, который уже в первом классе решает задачи за 11-й. Перспективная, но пока не всем понятная.
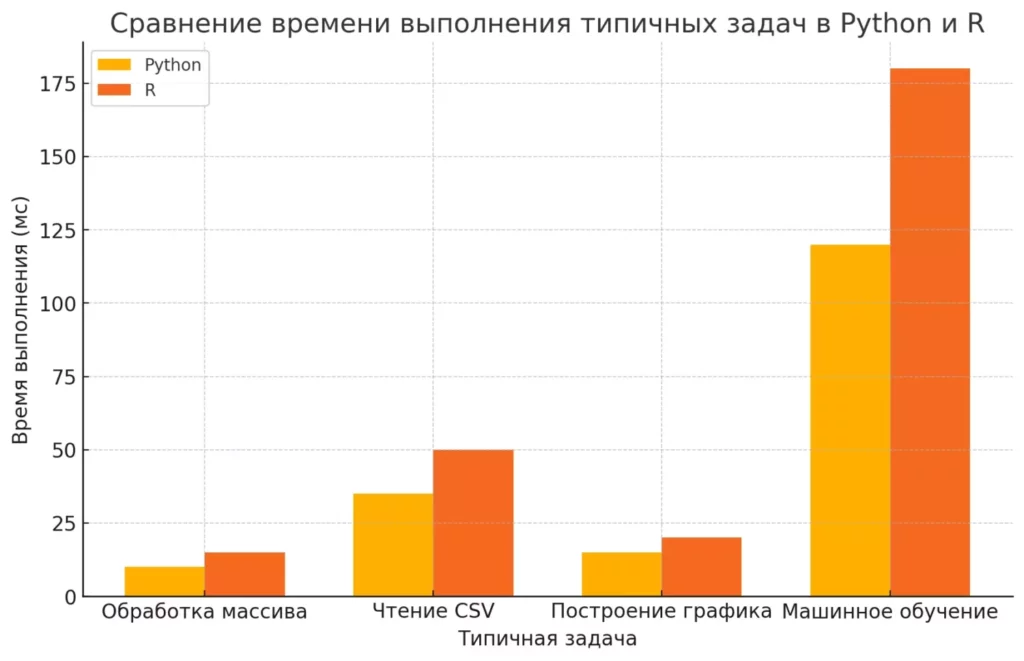
Время выполнения типичных задач в Python и R
Помните, выбор языка – это как выбор инструмента для ремонта. Молотком можно забить гвоздь, но вряд ли у вас получится закрутить шуруп. Так что выбирайте мудро, и пусть сила больших данных будет с вами!
Выбор языка в зависимости от задачи
Друзья мои, выбор языка программирования для анализа данных - это как выбор оружия для битвы с драконом. Неправильный выбор может привести к тому, что вы окажетесь не героем, а горячим обедом. Давайте разберемся, какой язык подойдет для разных сценариев.
Анализ данных и визуализация
Когда речь заходит о том, чтобы превратить огромные массивы данных в красивые картинки, которые поймет даже ваш босс (ну, или хотя бы сделает вид, что понял), у нас есть два главных претендента: Python и R.
Python, со своими библиотеками вроде Matplotlib, Seaborn и Plotly, - это как швейцарский нож в мире визуализации. С ним вы можете создать практически любой график, от простой гистограммы до интерактивной 3D-модели распределения продаж мороженого в зависимости от температуры воздуха и фазы луны.
R, с другой стороны, - это как магическая палочка для создания статистических графиков. Библиотека ggplot2 в R настолько мощная, что может превратить самый скучный набор данных в произведение искусства. Серьезно, я видел графики, сделанные в R, которые выглядели лучше, чем некоторые современные картины.
Но помните: красивая визуализация - это хорошо, но если ваши данные - мусор, то вы просто создадите очень красивый мусор. Как говорится, garbage in - garbage out, только теперь в HD-качестве.
Машинное обучение и глубокое обучение
Машинное обучение - эта модная штука, которая обещает решить все проблемы человечества (спойлер: нет, не решит, но попытается).
Здесь у нас снова лидирует Python. Благодаря таким библиотекам, как scikit-learn, TensorFlow и PyTorch, Python стал de facto стандартом в мире ML и DL. Это как если бы вы пришли на вечеринку супергероев, и все были бы в костюмах Железного человека.
R тоже неплох в машинном обучении, особенно когда дело касается статистических моделей. Но давайте будем честными: если вы хотите построить нейронную сеть, которая будет генерировать мемы или распознавать котиков на фотографиях, Python - ваш лучший друг.
Java и Scala тоже имеют свое место под солнцем ML, особенно когда речь идет о больших данных и распределенных вычислениях. Они как те крепкие парни, которые могут поднять что угодно, но, возможно, не так изящно, как Python.
Работа с большими данными
Когда ваши данные становятся настолько большими, что их можно увидеть из космоса, на сцену выходят Java и Scala.
Java - это как танк в мире больших данных. Он может быть не самым быстрым или изящным, но он надежен и может обработать практически что угодно. Плюс, половина экосистемы больших данных (привет, Hadoop!) написана на Java.
Scala - это как более молодой и модный кузен Java. Он работает на той же Java Virtual Machine, но добавляет функциональное программирование и более лаконичный синтаксис. Apache Spark, один из самых популярных инструментов для обработки больших данных, написан на Scala.
Помните: с большой силой приходит большая ответственность. И необходимость в более мощном железе. И, возможно, в дополнительном кондиционере для вашего дата-центра.
Выбор языка для вашей задачи - это как выбор правильного инструмента из ящика с инструментами. Иногда вам нужен молоток (Python), иногда - точный скальпель (R), а иногда - целый экскаватор (Java/Scala). Главное - не пытаться забивать гвозди микроскопом. Хотя, признаюсь, звучит забавно.
Советы для новичков: с чего начать
Итак, дорогие мои будущие повелители данных, вы решили ступить на скользкую дорожку Data Science. Поздравляю! Теперь вам предстоит провести бессонные ночи, споря с компьютером и пытаясь понять, почему ваша модель предсказывает, что завтра наступит 1873 год. Но не волнуйтесь, я здесь, чтобы помочь вам начать этот увлекательный путь.
Начните с Python. Серьезно, это как научиться кататься на велосипеде перед тем, как сесть за руль Formula 1. Python прост, понятен и невероятно полезен. Плюс, вы всегда сможете похвастаться друзьям, что "говорите на языке змей".
Освойте основы статистики. Да, я знаю, звучит скучно. Но поверьте, без этого в мире Data Science вы будете как рыба на велосипеде - технически возможно, но выглядит странно и неэффективно.
Научитесь работать с данными в Excel. Да-да, в том самом Excel, который вы использовали для составления списка покупок. Это как научиться ходить, прежде чем бежать марафон.
Познакомьтесь с SQL. Потому что данные где-то должны храниться, и чаще всего это "где-то" - база данных. SQL - это как азбука для работы с данными. Без нее вы будете как Тарзан, пытающийся заказать кофе в Старбаксе.
Изучите основы визуализации данных. Потому что красивый график может рассказать историю лучше, чем тысяча строк кода. И да, это поможет вам впечатлить босса на следующей презентации.
Погрузитесь в машинное обучение. Но помните: ML - это не магия, это математика в модном плаще. Не ждите, что оно решит все ваши проблемы (хотя может создать парочку новых, весьма интересных).
Практикуйтесь, практикуйтесь и еще раз практикуйтесь. Потому что теория без практики - это как рецепт без ингредиентов: выглядит красиво, но не очень-то полезно.
А теперь обещанный список ресурсов для начинающих:
Coursera: курсы по Data Science от ведущих университетов. Потому что учиться никогда не поздно, особенно когда можно делать это в пижаме.
Kaggle: соревнования по анализу данных и машинному обучению. Здесь вы можете попробовать свои силы в реальных проектах и, возможно, даже выиграть немного денег.
DataCamp: интерактивные курсы по программированию для анализа данных. Потому что лучший способ научиться плавать - это нырнуть в воду (желательно, не в бассейн с акулами).
GitHub: здесь вы найдете множество проектов с открытым исходным кодом. Это как огромная песочница для взрослых программистов.
Stack Overflow: потому что даже опытные программисты иногда застревают, и нет ничего постыдного в том, чтобы попросить помощи (или провести три часа, пытаясь понять, почему ваш код не работает, только чтобы обнаружить лишнюю запятую).
Заключение
Итак, дорогие мои будущие повелители данных, мы с вами совершили увлекательное путешествие по джунглям языков программирования для анализа данных. Надеюсь, теперь вы чувствуете себя не как потерянный турист, а как опытный следопыт, готовый к любым приключениям в мире Big Data. Подведем итоги:
Python — универсальный язык для анализа данных. Он обладает широкой экосистемой библиотек и подходит как новичкам, так и опытным специалистам.
R — специализированный язык с мощными статистическими и визуализационными возможностями. Он популярен в научных кругах и для глубокой статистики.
SQL — незаменимый язык для работы с реляционными базами данных. Он позволяет эффективно извлекать и обрабатывать структурированные данные.
Java и Scala — выбор для обработки больших данных и корпоративных решений. Они обеспечивают высокую производительность и масштабируемость.
Julia — молодой, но перспективный язык с высокой скоростью исполнения. Он идеален для научных и численных вычислений, хотя требует времени для освоения.
Рекомендуем обратить внимание на подборку лучших курсов по Python, и другим языкам программирования для анализа данных. Если вы только начинаете или хотите повысить квалификацию, эти курсы предлагают теорию и практику для комплексного освоения.
Курсы Linux помогают разобраться, как устроены серверы, доступы, логи и сети. Хотите понять, с чего начать и как не уйти слишком рано в сложный DevOps? В статье — короткий маршрут, полезные ориентиры и практические советы.
Трудоголизм это не просто желание работать больше. Почему он превращается в зависимость, как распознать тревожные сигналы и какие шаги помогут вернуть баланс?
Видели идеальный шрифт, но не знаете, как он называется? Онлайн-сервисы, визуальный анализ и нейросети помогут вам найти нужный вариант. В этом гайде мы разберем проверенные методы поиска шрифтов, подскажем, как подготовить изображение для точного распознавания и где искать бесплатные аналоги.
Графика — ключ к созданию увлекательных миров. Узнайте, как использовать рендеринг, освещение и постобработку в Unity для достижения реалистичных эффектов.
Мы используем cookies: необходимые — для работы сайта, а дополнительные — для аналитики и улучшения сервиса.
Можно принять все cookies, отклонить дополнительные или оставить только необходимые.
Подробнее
 Материал будет полезен как новичкам, которые только начинают, так и опытным специалистам, желающим расширить арсенал инструментов для работы с данными. Мы разберем экосистему, производительность и область применения каждого языка, чтобы вы смогли выбрать наиболее подходящий именно вам.
Материал будет полезен как новичкам, которые только начинают, так и опытным специалистам, желающим расширить арсенал инструментов для работы с данными. Мы разберем экосистему, производительность и область применения каждого языка, чтобы вы смогли выбрать наиболее подходящий именно вам.